알고리즘
1.최소값 찾기 + (알고리즘 하는 이유)

=> 초기값을 null로 잡고 하나씩 비교해서 찾기=> 알고리즘은 문제 해결 방식을 연구하는 학문으로써, 꾸준히 공부를 해야한다고 생각한다. 특히 이번에 친구 프로그래밍 과제를 도와주면서 나의 부족한 실력을 깨닫게 되었고, 쉬운 문제부터 어려운 문제까지 하나씩 정복하기
2.삼각형 판별하기
=> 가장 긴 변을 찾고, 나머지 두 변의 길이가 가장 긴 변보다 크면 무조건 그릴 수 있다.
3.연필개수
=> 수의 버림과 올림의 활용은 항상 고려해야 하는 수학적인 기법이다.
4.1부터 N까지의 합
=> 클로저를 활용하기 좋은 문제다.
5.홀수
=> reduce를 통해 홀수 합, 최소 홀수값 추출
6.숫자 문자열과 영단어 (프로그래머스)
=> 1차시도 테스트 케이스 10번 박살남=> 2차시도 해결, JS에서 0은 false로 분류
7.없는 숫자 더하기 (프로그래머스)
=> 1차시도에서 성공
8.최소직사각형 (프로그래머스)
=> 정렬 활용하면 더 깔끔한 코드가 나왔을 텐데.. 좀 아쉽다는 생각이 들었다..
9.나머지가 1이 되는 수 찾기 (프로그래머스)
=> 1차 시도 성공
10.위장 (프로그래머스)
=> 처음 잘못 생각했던 것이 옷을 안 입는 경우 때문에 안 입는 경우 + 나오게 되는 경우의 수로 계산해서 틀림=> 옷을 안 입는 경우까지 모두 경우의 수로 구한 뒤, 아에 안 입는 케이스 1을 빼야 정답
11.Rate limit
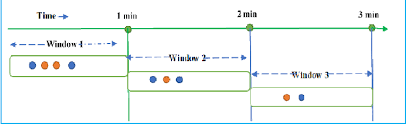
Rate limit은 말 그래도 요청의 한계를 주는 것이다. 한계를 주는 이유는 Dos 공격처럼 가용성 공격을 주는 공격 기법이나 트래픽 급증으로 인한 서버 다운을 막는 것이다. 주요 방식으로는 4가지가 있다.Fixed window정해진 시간 (간격)을 넘어서 요청을
12.올바른 괄호 (프로그래머스)
=> 1차시도는 그냥 스택 써서 풀려고 하다가 틀림))))(((()))) 경우를 True로 뱉는 경우 발생함. 2차 시도에서는 마지막 인덱싱이 (일 떄만 pop하는 구조로 변경하고 통과
13.프린터 (프로그래머스)
=> queue를 활용하여 구한 문제이다. node는 queue 내장 모듈이 없어서 그냥 배열로 구하였다. 1차시도에는 while문을 활용하지 않고 for문으로 연산하여 요소의 마지막까지 구하지 못하였다. 이 점을 캐치해서 2차 시도 끝에 통과하였다.
14.베스트 앨범 (프로그래머스)
=> 어떤 앨범이 가장 합이 높은지 순서를 구해야 했다. 그 순서를 구한 다음 처음 index를 반환해야 한다. 처음에 생각은 했는데, 그냥 구현체나 자료형 고민을 좀 많이 했던 거 같다. Map써도 될 거 같다는 생각??
15.배상 비용 최소화 (프로그래머스)
=> 처음에 최대값 추출해서 풀기, 매번 정렬해서 풀기를 선택했는데, 효율성 ㅁ측면에서 실패하였다. 매번 최대값을 추출할 때에는 힙 자료구조를 활용하는 것이 좋다. 힙은 이진 트리인데 요소가 추가되고 삭제 될 때마다 루트에 그 값이 갱신되기 때문에 logn 복잡도로 요
16.자동완성 (프로그래머스)
=> 사전에 쓰는 트라이 자료구조를 이용하는 문제이다. 솔직히 처음 봤을 때... 감도 안 왔다. 노드는 마지막 요소인지와 카운트 그리고 자식 요소를 저장한다. 그 다음 트라이 구조체는 트리와 유사하지만, 단어를 저장하는 점에서 차이를 보인다. 요소를 추가하는 것과 단
17.가장 먼 노드 (프로그래머스)
=> 2차원 배열을 통해 그래프를 생성한다. 생성 한 뒤, 첫 요소를 큐에 넣고 BFS를 수행한다. BFS를 수행할 때에는 거리가 0일 때만 삽입하고 거리에는 이전에 왔던 거리 + 1을 넣어준다.
18.큰 수 만들기 (프로그래머스)
=> 1차시도 배열에 삭제 및 초기화 작업을 계속해서 시간 초과 발생=> 2차시도 문자열로 자료형 변경 후 수행해도 여전히 시간 초과 발생=> 3차시도 주어진 문자열을 계속 변경하는 것 보다, 배열을 하나 선언해놓고 더하는 방식이 더 효율적이기에 통과
19.소수 찾기, 에라토스테네스의 체 (프로그래머스)
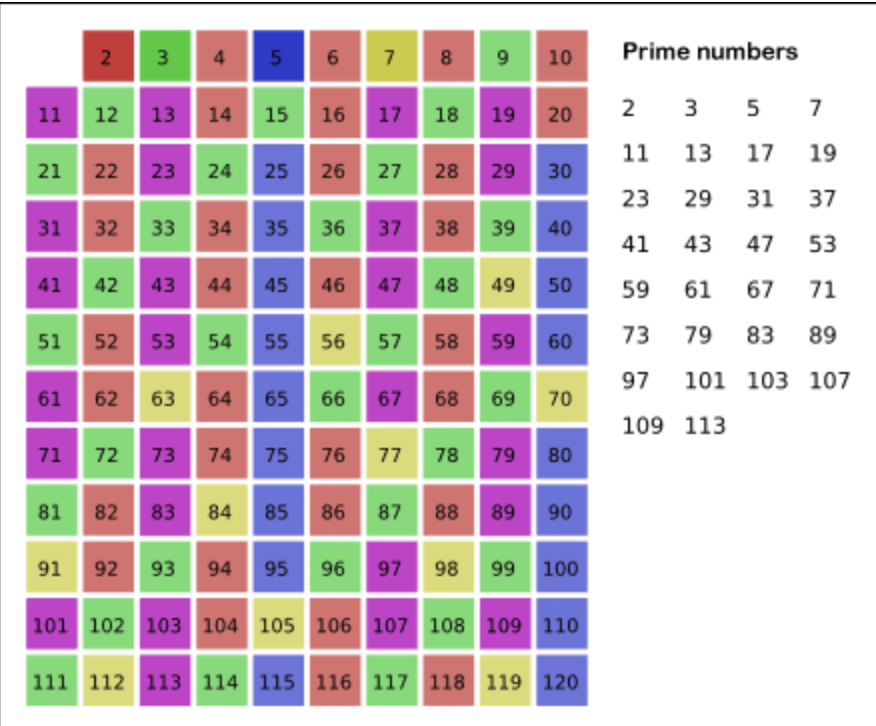
=> 에라토스테네스의 체는 고대 그리스 수학자가 발견한 알고리즘으로 제곱근의 배수를 지우면 소수만 남는 알고리즘이다.
20.병합정렬 with 재귀함수
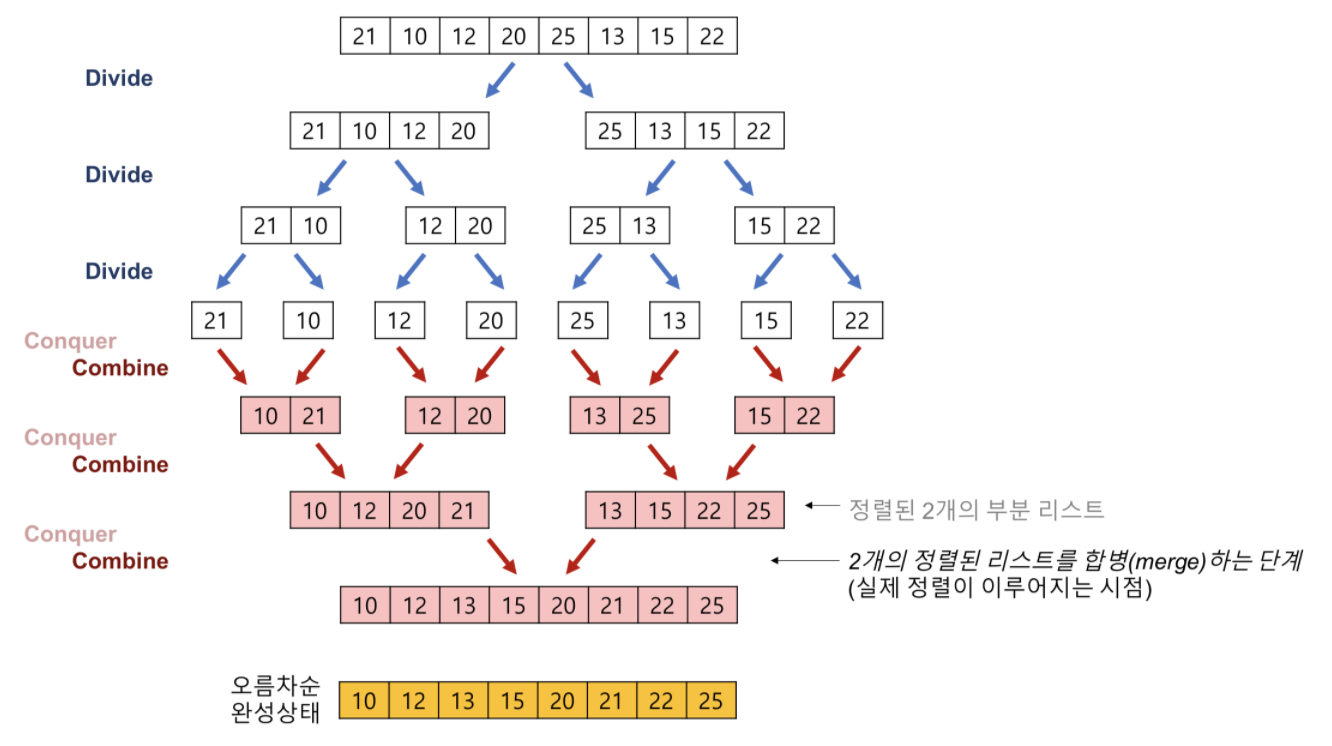
=> 병합정렬은 합병정렬이라고도 불리며 그 놀라운 수학자 존 폰 노이만이 만든 알고리즘이다. 어떠한 경우에도 시간 복잡도가 크게 다르지 않은 안정 알고리즘이며 분할 정복 기법을 사용한다.=> 나누는 부분과 합치는 부분을 재귀함수로 구현할 수 있다. 나눌 때 로직은 가운
21.순열과 조합
순열과 조합은 코테에서 지겹도록 봐왔지만, 그떄마다 쉽게 끝낸 적이 없는 것 같다. 이번 기회에 그냥 외워버리자.순열 (중복허용), 조합 (중복비허용)=> 1일 경우에는 1... 으로 나오게 한다. fixed를 제외하고 n - 1하여 재귀를 돌린다. 나온 결과를 fix
22.이진탐색
=> 이진 탐색 알고리즘은 정렬되어있는 자료구조에서 요소를 찾을 때 logn 복잡도로 찾을 수 있는 알고리즘이다. 배열과 이진트리 방식으로 구현이 가능한데, 배열을 쓰도록 하자
23.입국심사 (프로그래머스)
=> 대표적인 결정문제 = 이진탐색 = 파라메트릭서치 문제이다. 최소 시간 안에 입국 심사를 해야하는데, 1 ~ 제일 늦게 하는 사람 \* 사람 수까지에서 이진 탐색으로 찾으면 된다. 사람 수를 구하면서 mid를 갱신하면 된다.
24.배달 (프로그래머스)
=> 위 코드는 다음의 절차를 따른다.1\. 모든 그래프 문제처럼 거리와 그래프를 만든다.2\. 초기 값을 선언한다.3\. 문제 조건대로 그래프를 구성한다.4\. BFS돌면서 순회한다.5\. 순회를 도는 노드에 연결된 거리 > 해당 노드의 거리 + 가중치이면 순회를 도
25.타겟 넘버 (프로그래머스)
=> 대표적인 DFS문제이다. 배열을 탐색하면서 모든 결과를 dist에 저장한다!
26.백트래킹
=> 모든 경우를 탐색하는 DFS, BFS 알고리즘 등을 활용할 때, 탐색하지 않아도 되는 곳을 막는 가지치기를 하는 것을 의미한다. 즉, 답이 될 수 없는 케이스의 확장을 막아야 한다.대표적으로 N-Queen 문제가 있다.
27.카펫 (프로그래머스)
=> 수학적인 센스와 반복문을 활용하여 구함
28.네트워크 (프로그래머스)
=> 아오, 최단 거리 구하는 문제가 아니라 방문 여부만 따져보면 되는데 진짜 완전 삽질했다. 그래도 하나 배운게, 최초 방문할 때마다 집합 개념이 발생한다고 보면 된다.