개요
일반 게시판처럼 DB Table Key를 이용하여 parameter로 화면 접근이 필요한 상황이 있었습니다.
하지만 해당 화면에는 구매 정보가 포함되어있어 유추가 가능할 수 있는 Sequential한 Key를 피하고자 UUID를 선택하였습니다.
그때 UUID 사용할때 고려했던 부분이나 UUID의 사용성, 장단점에 대해서 공유하고자 합니다.
WHAT IS UUID
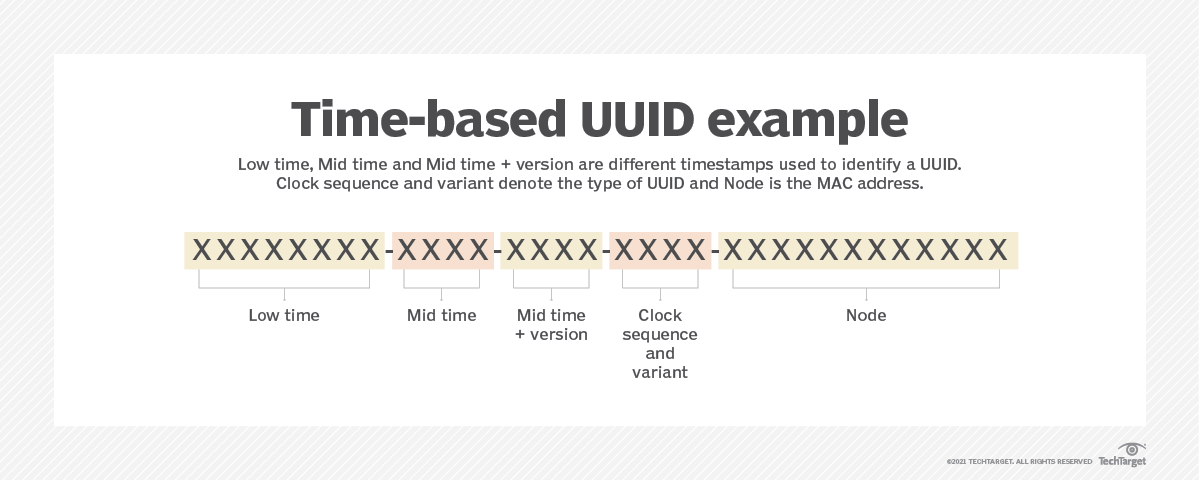
UUID (Universally Unique Identifier)
16진수 32개로 되어있는 조합으로 구성되어있고
고유성과 보안, 분산 시스템에서의 유용성, 쉬운 생성, 데이터베이스 인덱싱, 일관성 유지 및 충돌 가능성이 낮다는 장점으로 매우 유용하게 사용되고 있습니다.
사용 방법
- randomUUID(): 버전 4의 랜덤한 UUID를 생성
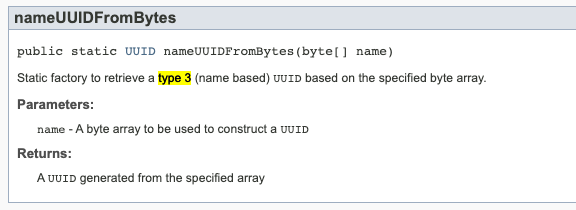
- nameUUIDFromBytes(byte[] name): 버전 3의 이름 기반의 UUID를 생성
- fromString(String name): 문자열 형식의 UUID를 객체로 변환
- toString(): 객체 형식의 UUID를 문자열로 변환
- variant(): UUID의 변형을 반환 (0: NCS, 2: RFC 4122, 6: Microsoft, 7: reserved)
- version(): UUID의 버전을 반환 (1: time-based, 2: DCE security, 3: name-based MD5, 4: random, 5: name-based SHA-1)
public class UuidExample {
public static void main(String[] args) {
// 버전 4의 랜덤한 UUID 생성
UUID uuid1 = UUID.randomUUID();
System.out.println("uuid1 = " + uuid1);
System.out.println("uuid1 variant = " + uuid1.variant());
System.out.println("uuid1 version = " + uuid1.version());
// 버전 3의 이름 기반의 UUID 생성
byte[] name = "byte_sample".getBytes();
UUID uuid2 = UUID.nameUUIDFromBytes(name);
System.out.println("uuid2 = " + uuid2);
System.out.println("uuid2 variant = " + uuid2.variant());
System.out.println("uuid2 version = " + uuid2.version());
// 문자열 형식의 UUID를 객체로 변환
String strUuid = "00ee3655-34d0-4121-a2c0-b4b3a4f9053e";
UUID uuid3 = UUID.fromString(strUuid);
System.out.println("uuid3 = " + uuid3);
}
}# Output
uuid1 = 3f0f0cea-195b-4b7f-82d5-966ba4f2ab94
uuid1 variant = 2
uuid1 version = 4
uuid2 = 598518d7-2590-332c-8c5a-0fcd8be842d2
uuid2 variant = 2
uuid2 version = 3
uuid3 = 00ee3655-34d0-4121-a2c0-b4b3a4f9053e평상시의 경우라면 단지 UUID.randomUUID();로만 생성하여 사용해도 큰 문제가 없습니다.
우려 상황
개발할때 UUID를 사용함에 앞서 의구심을 품었던게 몇가지 있었습니다.
혹시나 발생 할 수 있는 중복 확률과 동일 환경에서 생성할때의 중복 가능성이였는데
해당 우려를 찾아봤던 결과에 대해서 설명드리겠습니다.
중복 확률
일반적인 UUID는
340,282,366,920,938,463,463,374,607,431,768,211,456 개 (3.4 x 10^38)를 생성 할 수 있습니다.
매 초 100만개의 UUID를 100년동안 생성할때 0.00009% 확률로 중복이 발생합니다.
(퍼온거라 확실하진 않습니다 ㅎㅎ;;)
위키피디아에 UUID Collisions 부분을 확인해보면
매 초 10억개씩 85년동안 생성하면 중복이 발생할 확률은 50%라고 합니다
하지만 이렇게까지 저장한다면 UUID의 저장소는 45엑사바이트라고 하니 충돌보다는 저장소가 먼저 버티지 못할 확률이 높습니다. ( 링크 )
이정도 확률이면 중복이 발생하는건 비트 플립같은 자연재해로 봐야하는게 더 좋지 않을까요?
DB Table key로 사용하는 경우 key 중복에 대한 Exception처리만해도 매우매우충분해 보입니다.
비트플립에 대한 재밌는 영상 보기
https://www.youtube.com/watch?v=QWvDOot3Etw
동일 환경에서 생성할때의 중복 가능성
제가 uuid를 도입하려 했을때 가장 우려스러웠던 점이 UUID의 생성은 랜덤이다보니
여러 서버에서 동일 환경, 동일 시간에 UUID를 생성할때 중복이 가능하지 않을까 였습니다.
그래서 Java에서 사용하는 UUID에 대해서 알아보았습니다.
Java java.util 라이브러리에서 지원하는 UUID 객체에서
UUID를 쉽게 생성할 수 있는 randomUUID() 메소드는 버전4를 사용하고 있다고 명시되어 있습니다.
https://docs.oracle.com/javase/7/docs/api/java/util/UUID.html

버전4가 뭐하는놈인지부터 알아야 할것 같습니다.
UUID는 버전 1부터 5까지 총 5가지의 버전이 있습니다. 각 버전은 아래와 같이 구성되어 있습니다
- 버전 1: 시간 기반 UUID로, 타임스탬프와 MAC 주소를 기반으로 생성
- 버전 2: DCE 보안 UUID로, POSIX UID, GID 또는 식별자를 기반으로 생성
- 버전 3: 이름 기반 UUID로, 해시 함수를 사용하여 생성
- 버전 4: 무작위 기반 UUID로, 난수 생성기를 사용하여 생성
- 버전 5: 이름 기반 UUID로, SHA-1 해시 함수를 사용하여 생성
버전 4 설명만 보아서는 난수 생성기를 사용한다는건 의사 난수가 발생하여 특정 상황일경우 동일한 UUID가 생성될 수 있다는 이야기입니다.
하지만 자바에서는 UUID 생성로직 내부에서 SecureRandom을 이용하고 있어 의사 난수가 발생하지 않는 환경이였습니다.
SecureRandom, 의사난수에 대해 이해하기 좋은 블로그
[Java] Random보단 SecureRandom 를 사용하자.
혹시나 JAVA에서 다른 버전 UUID사용할 경우
3버전을 사용하기 위해서는 아래와 메서드를 사용하면 됩니다.
그래도 중복 확률이 불안하다면...?
UUID 버전1을 사용하면 됩니다.
네트워크 카드의 MAC주소와 timestamp를 통해서 UUID 생성이 가능해서 중복확률이 매우 작기 때문입니다.
하지만 UUID를 통해서 MAC 주소를 알아낼 수 있는 보안적인 이슈가 있습니다.
MAC 주소와 생성시간 유추를 통해서 UUID 역시 유추가 가능하기 때문에 내부 시스템에서 사용하는 조건이 있는경우 검토하기 좋을것 같습니다.
JAVA에서 version1을 사용하려면 해당 링크 참조하여 구현할 수 있습니다. 링크
UUID Column schema
32자리에 하이픈까지 36자리의 문자열로 보자면 DB입장에서는 너무 큰 key 값입니다.
이걸 key로 지정해서 비교를한다면 select 할때마다 비용이 크게 발생할 여지가 있습니다.
하지만 UUID의 구성을 보면 아래와 같이 추론할 수 있습니다.
16진수(4bit) * 32자리 = 128 bit = 16 byte
uuid는 곧 16바이트로 나타낼 수 있습니다.
그래서 BINARY(16)을 사용하는것이 mysql 에서 적당한 UUID를 사용하는 제일 적절한 type이라고 설명드릴 수 있습니다.
만약 mysql에서 uuid를 varchar 형식으로 저장한다면 아래와 같은 이슈를 만날 수 있습니다.
- UUID의 스키마를
BINARY(16)로 해야 하는 이유 (링크)
위 링크를 보고 왔는데도 아직까지 BINARY(16) 으로 저장하는게 조금 찝찝하시다면 아래 링크도 같이 보시면 좀더 확신을 가질 수 있을겁니다
사용시 단점
WorkBench 사용시
사내에서 자주 사용하는 WorkBench에서 uuid 조회시 아래와 같이 BLOB으로 보여지는게 단점입니다.
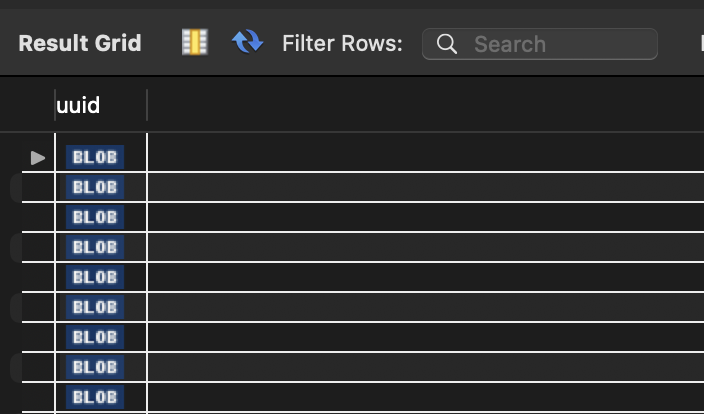
Blob으로 깨져보이는 상황에서는 아래와 같이 변환하여 조회가 가능합니다.
select LOWER(CONCAT(
SUBSTR(HEX(uuid), 1, 8), '-',
SUBSTR(HEX(uuid), 9, 4), '-',
SUBSTR(HEX(uuid), 13, 4), '-',
SUBSTR(HEX(uuid), 17, 4), '-',
SUBSTR(HEX(uuid), 21)
)), test_table.*
from test_table;같은 데이터를 IntelliJ에 내장되어있는 DataGrip으로 확인하면 정상적으로 보이긴합니다.
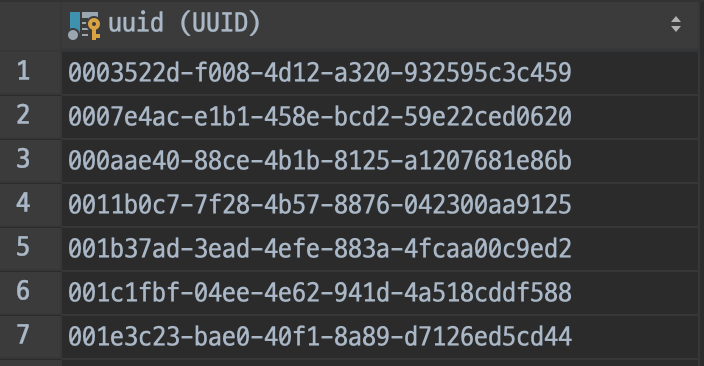
특정 UUID 조회시
특정 UUID 조회시에는 아래와 같이 두번 변환하여 조회가 가능합니다.
- 하이픈(
-) 제거 - unhex 함수 사용
select * from test_table where uuid = unhex(replace('104ab528-XXXX-YYYY-ZZZZ-03d2710a4a8c','-',''))적응되면 그나마 괜찮지만 초반에는 매우 귀찮은일이 아닐 수 없습니다....
외부 서비스와 연동시
이건 UUID의 단점이라기보다는 서비스간 연동시에 단점이 될 수 있는데
uuid를 이용하여 transaction key형식으로 다른 서비스와도 연동할때 고유값으로 사용 했었습니다.
그러다보니 다른 서비스에서 해당 정보를 저장할때 테이블 크기가 넘치는 경우가 많이 있었습니다
그래서 다른 서비스에 table column 정보를 변경하기 위한 작업이 추가로 되어있어
다른 서비스와 연동할때 허용 가능한 key의 length를 확인해보셔야 합니다.
sorting 불가능
uuid는 랜덤으로 생성되다보니 순서에 대한 정렬을 할 수 없습니다.
그래서 key로 사용될때 정렬에 대한 column이 하나 더 필요합니다. (데이터 등록일 같은것과 같이 사용 필요)
끝!
UUID는 생각보다 매우 안전하고 유용합니다.
중복확률도 매우 낮고 무척 편리합니다.
uuid를 사용할지말지 고민할때 한번 사용해보는걸 권장합니다.
