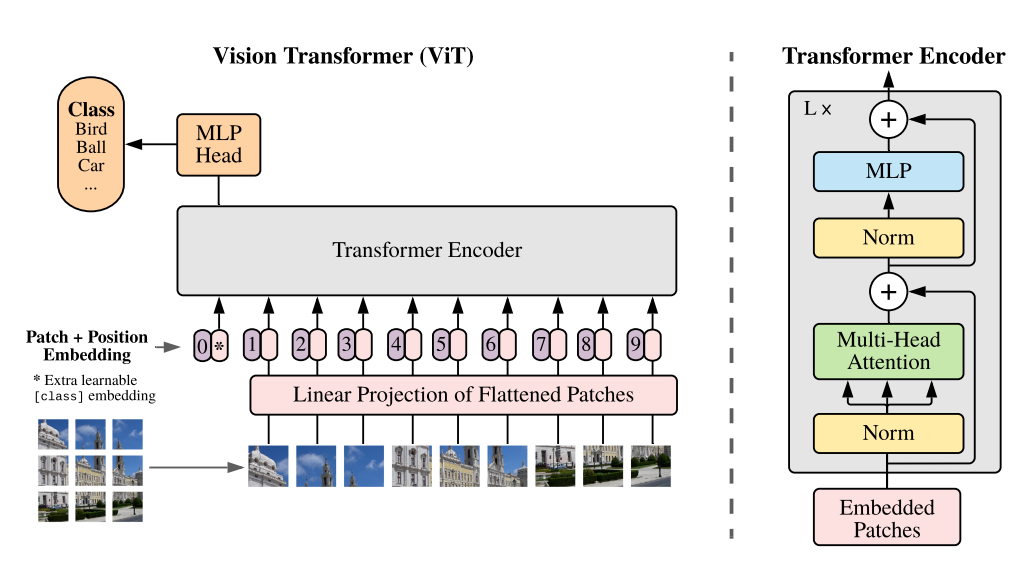
nlp에서 큰 성과를 거둔 transformer 모델이 이미지에서도 이용된 것이 vit이다.
(이미 이를 기본으로 해서 다양한 모델들이 넘쳐나지만..)기본부터 공부할겸 정리해봤다.
Patch embedder
이미지를 패치로 변경 후 Flatten시킨다.
그 후 Embedding을 거침.
class token과 positional encoding 을 추가함으로서 특정 패치 단위로 학습되게끔.
class PatchLayer(nn.Module):
"""
Input _ : B * image (C, H, W) : H == W
1. Into patch --> B , N , (C, P, P)
2. Flatten --> B, N , C*P*P
3. Embedding --> B, N, Em_dim
4. Class token , positional Encoding --> N+1, Em_dim
"""
def __init__(self, img_size : int ,patch_size : int, emb_vec_size : int, channel_size = 3):
super().__init__()
feature_vector_size = (patch_size ** 2) * channel_size
patch_num = (img_size // patch_size) ** 2
assert img_size % patch_size == 0
self.patch_size = patch_size
self.projection_layer = nn.Sequential(nn.Linear(feature_vector_size, emb_vec_size))
self.class_token = nn.Parameter(torch.randn(1, emb_vec_size))
self.positional_emb = nn.Parameter(torch.randn(1, patch_num+1, emb_vec_size))
def patch_embedding(self, input):
patchs = rearrange(input, 'b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1 = self.patch_size , s2 = self.patch_size)
return patchs
def forward(self, x: torch.Tensor):
batch_size = x.size(0)
patchs =self.patch_embedding(x)
out = self.projection_layer(patchs)
out = torch.concat([self.class_token.repeat(batch_size, 1, 1), out], dim = 1)
out = out + self.positional_emb
return out
가로 세로 96인 3channel 이미지를 패치사이즈 6, emb_vec_size 64로 설정할 경우,
1) patch_embedding을 지나면
96//6 = 6 이므로 가로 ,세로 6*6 총 36개의 6 6 3 (channel)의 vector가 나온다. (B, 36, 768)
2) 그 후 projection layer를 통해 768 -> emb_vec_size로 임베딩해준 후
3) class token을 첫번째 줄에 추가, 같은 사이즈의 positional emb 더해주면
4) (B, 37, 64) 의 아웃풋을 가진다.
multi head self attention
트랜스포머를 이루는 어텐션 계층.
전체 q, k, v를 embedding 을 거쳐 구한 후, num head만큼 나눠서 어텐션 계산 후 합쳐준다.
class MultiheadSelfAttention(nn.Module):
def __init__(self, latent_size, num_head, dropout):
"""
return attention - hidden emb size is same to input patch emb size
emb_vec_size : patch_emb_dim
num_head : multi head 개수
dropout : attention score drop out
# TODO >... projection layer
"""
super().__init__()
self.emb_vec_size = latent_size
self.qkv_dim = latent_size
self.Uqkv = nn.Linear(latent_size, latent_size*3 )
self.num_head = num_head
self.scale = latent_size ** -0.5
self.atten_drop = nn.Dropout(dropout)
#self.projection = nn.Linear(qkv_dim, )
def forward(self, x):
Uqkv = self.Uqkv(x).chunk(3, dim = -1) ## Uq, Uk, Uv
q,k,v = map(lambda x : rearrange(x, 'b n (h d) -> b h n d', h= self.num_head ), Uqkv) ## (B, num_head, N, qkv_dim)--> key, query, value #MULTI HEAD
score = torch.matmul(q, k.transpose(-1, -2)) * self.scale
score = nn.Softmax(dim=-1)(score)
score = self.atten_drop(score)
out = torch.matmul(score, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return out
FeedForward
GELU를 사용한다.
expantion 만큼 확장 후 다시 원래의 latent size로 줄인다.
class FeedForward(nn.Module):
"""
Activation Function :: GELU
"""
def __init__(self, latent_size, expantion, dropout):
super().__init__()
self.mlp = nn.Sequential(nn.Linear(latent_size, latent_size * expantion),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(latent_size*expantion, latent_size))
def forward(self, x):
return self.mlp(x)
Transformer
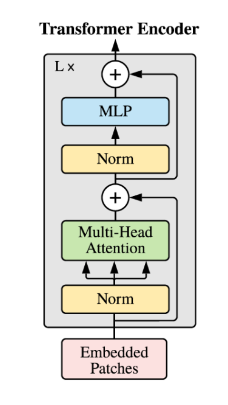
depth 만큼 attention 거치고 합치고, mlp 거치고 합치고,,를 반복한다.
class PreNorm(nn.Module):
def __init__(self, latent_size, fn):
super().__init__()
self.norm = nn.LayerNorm(latent_size)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class Transformer(nn.Module):
def __init__(self, latent_size, num_head, dropout, ff_dropout, expantion, depth):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(
nn.ModuleList([
PreNorm(latent_size, MultiheadSelfAttention(latent_size=latent_size, num_head=num_head, dropout=dropout)),
PreNorm(latent_size, FeedForward(latent_size=latent_size, expantion=expantion, dropout=ff_dropout))
])
)
def forward(self, x):
for atten, ff in self.layers:
x = atten(x) + x
x = ff(x) + x
return xtransformer를 depth 만큼 지난 후 최종 class예측으로는 맨 처음에 설정해둔 class token만을 사용한다.
즉 최종 결과의 0번 인덱스를 뽑아 mlp를 거쳐 예측한다.
위의 레이어를 모아 최종적인 Vision Transformer는 다음과 같다.
class VIT(nn.Module):
def __init__(self,
img_size,
patch_size,
emb_vec_size,#patch embedding할 사이즈
num_head, #multihead 개수
att_dropout, #attention score drop
ff_dropout, #feed forward dropout 비율
expantion, #feed forward에서 expantion 만큼 배로 늘렸다가 원상복귀
depth, #transformer encoder 반복 횟수
class_num): #최종 class 개수
super().__init__()
self.patch_embedder = PatchLayer(img_size , patch_size, emb_vec_size, channel_size = 3)
self.transformer = Transformer(emb_vec_size, num_head, att_dropout, ff_dropout, expantion, depth)
self.mlp = nn.Sequential(nn.LayerNorm(emb_vec_size), nn.Linear(emb_vec_size, emb_vec_size),
nn.Linear(emb_vec_size, class_num))
def forward(self, x):
x = self.patch_embedder(x)
x = self.transformer(x)
class_token = x[:,0]
out = self.mlp(class_token)
return out참고 - 파이토치 vit,
