segmentation model FGSM 공격과 방어
이번에 간단하게 진행한 연구이다.
brain tumor segmentation 에서 FGSM 공격을 진행한후 전처리 과정에서 노이즈 제거단계를 추가하여 FGSM 노이즈를 제거를 목적으로 하였다.
brain tumor segmentation 모델은 이전의 atten-unet모델을 사용하였다.
데이터는 kaggle 그대로.
공격은 파이토치 홈페이지의 fgsm 을 참고하였다.
대신 loss를 segmentation loss로 하였고, 픽셀마다의 label을 이용한다는게 홈페이지와 다르다.
"""loss 부분 """
def dice_coef_loss(inputs, target):
smooth = 1.0
intersection = 2.0 * ((target * inputs).sum()) + smooth
union = target.sum() + inputs.sum() + smooth
return 1 - (intersection / union)
def dice_coef_metric(inputs, target):
intersection = 2.0 * (target * inputs).sum()
union = target.sum() + inputs.sum()
if target.sum() == 0 and inputs.sum() == 0:
return 1.0
return intersection / union
def bce_dice_loss(inputs, target):
dicescore = dice_coef_loss(inputs, target)
bcescore = nn.BCELoss()
bceloss = bcescore(inputs, target)
return bceloss + dicescore
"""ATTACK"""
def fgsm_attack(image, data_grad, epsilon):
sign_data_grad = data_grad.sign()
perturbed_image = image + epsilon*sign_data_grad
perturbed_image = torch.clamp(perturbed_image, 0, 1)
return perturbed_image
"""테스트"""
def test( model, device, test_loader, epsilon,train_loss = bce_dice_loss):
"""
원래 이미지 데이터에서 fgsm 수행하고, 적대적 예제를 생성.
원래 이미지와 적대적 이미지 , 라벨이미지 return
"""
origin_exmple = []
adv_examples = []
befor_attack_list = []
after_attack_list =[]
label_list = []
for data, target in test_loader:
data, target = data.to(device), target.to(device)
data.requires_grad = True
outputs = model(data)
out_cut = np.copy(outputs.data.cpu().numpy())
out_cut[np.nonzero(out_cut < 0.5)] = 0.0
out_cut[np.nonzero(out_cut >= 0.5)] = 1.0
train_dice = dice_coef_metric(out_cut, target.data.cpu().numpy())
# print('before : ', train_dice)
befor_attack_list.append(train_dice)
loss = train_loss(outputs, target)
model.zero_grad()
loss.backward()
data_grad = data.grad.data
perturbed_data = fgsm_attack(data, data_grad, epsilon)
outputs = model(perturbed_data)
out_cut = np.copy(outputs.data.cpu().numpy())
out_cut[np.nonzero(out_cut < 0.5)] = 0.0
out_cut[np.nonzero(out_cut >= 0.5)] = 1.0
train_dice = dice_coef_metric(out_cut, target.data.cpu().numpy())
after_attack_list.append(train_dice)
# print('after : ', train_dice)
orr = data.squeeze().detach().cpu().numpy()
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
target = target.squeeze().detach().cpu().numpy()
adv_examples.append(adv_ex)
origin_exmple.append(orr)
label_list.append(target)
print("Epsilon: ", epsilon)
print(np.mean(np.array(befor_attack_list)))
print(np.mean(np.array(after_attack_list
)))
return adv_examples, origin_exmple, label_list이젠 위에서 생성한 example에 데이터 변환을 시켜 노이즈 제거를 하였다.
class FSGM_dataset(Dataset):
from art.defences.preprocessor import *
def __init__(self, ex, label):
self.ex = ex
self.label = label
def __len__(self):
return len(self.label)
def __getitem__(self, idx):
#pre = SpatialSmoothing()
pre = JpegCompression((0, 1), channels_first=True)
image = ex[idx]
image = np.expand_dims(image, axis=0)
image = pre(image)[0]
mask = label[idx]
return torch.from_numpy(image).squeeze(0), torch.from_numpy(mask)
이 JpegCompression는 art module에서 제공하는 함수이다.
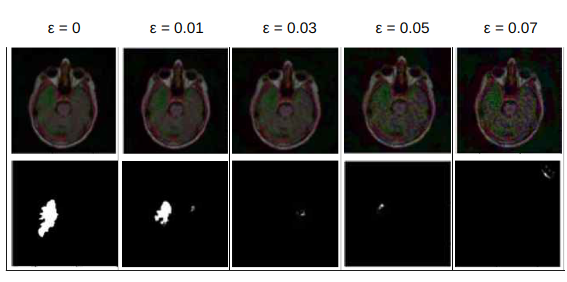
공격과 방어 효능은 다음과 같이 나온다.
-
입실론에 따른 모델 성능 하락
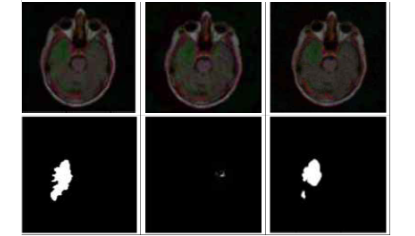
-
위의 변환을 거친 이미지에서의 모델 분할 모습
왼쪽부터 차례대로 원래이미지 - 공격이미지 - 방어 적용이미지와 밑에는 모델 분할..
-- 성능이 좋아졌다!