1. Numpy
about Numpy
-
2005년에 만들어진 100% 오픈소스
-
최적화된 c 코드로 구성되어 좋은 성능
-
수치연산의 안정성이 보장됨
-
N차원 실수값 연산에 최적화
import numpy as np사용하는 이유
-
데이터는 벡터로 표현됨. 데이터 분석 = 벡터 분석 => 벡터연산을 잘 해야 데이터 분석을 잘함
-
네이티브 파이썬은 수치연산에 매우 약함. 실수값 연산에 오류가 생기면 원하는 결과를 얻을 수 있어 많은 실수 연산이 요구되는 머신러닝에서 성능 저하로 이어질 수 있음
-
벡터연산을 빠르게 처리하는 것에 최적화 되어 있음. 파이썬 리스트보다 월등히 빠름
2. Numpy array
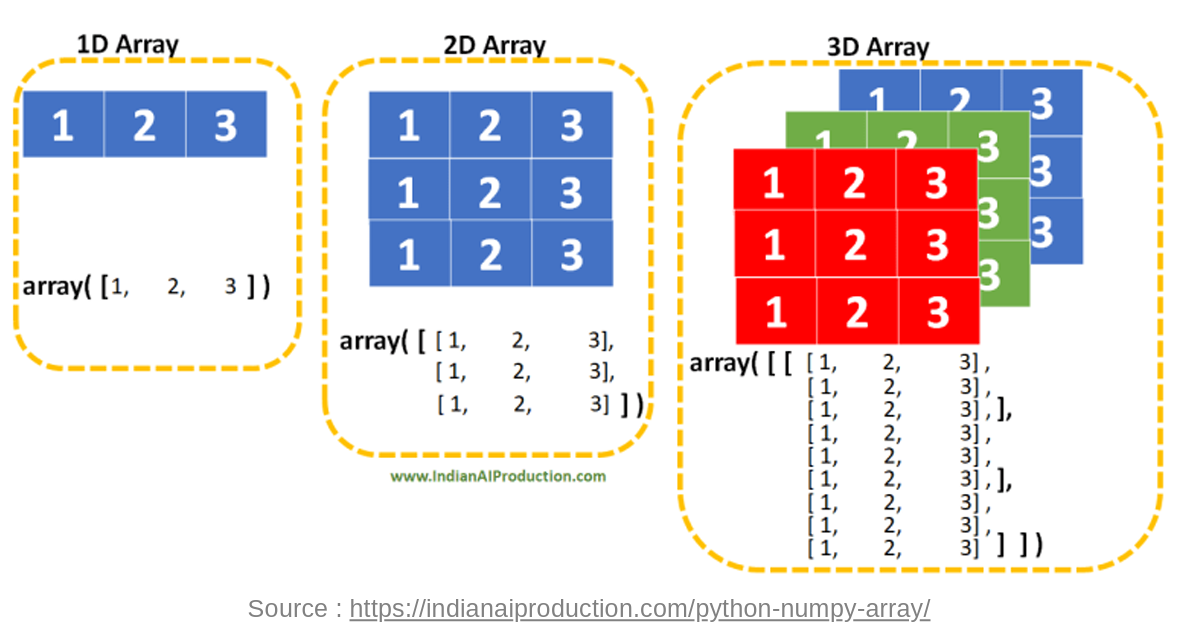
-
c언어의 array 구조와 동일한 개념
-
python list와 비슷한 구조이나, 세부적인 특징이 많이 다름
-
np.array는 생성된 이후에 크기 변경 불가능
-
np.array는 무조건 모든 원소의 data type이 동일해야 함
- 위의 조건으로 사용할 연산자와 연산횟수가 고정되는 이점이 있음
