업스테이지 과정에 들어와서 가장 크게 달라진 것은 스터디를 중심으로 운영된다는 점이었다.
일주일 간 동영상 강의 + 주어진 스터디 과제를 수행하고 주기적으로 스터디 결과를 공유하는 공유회 시간을 갖는다.
1번째 과제
핵심 주제
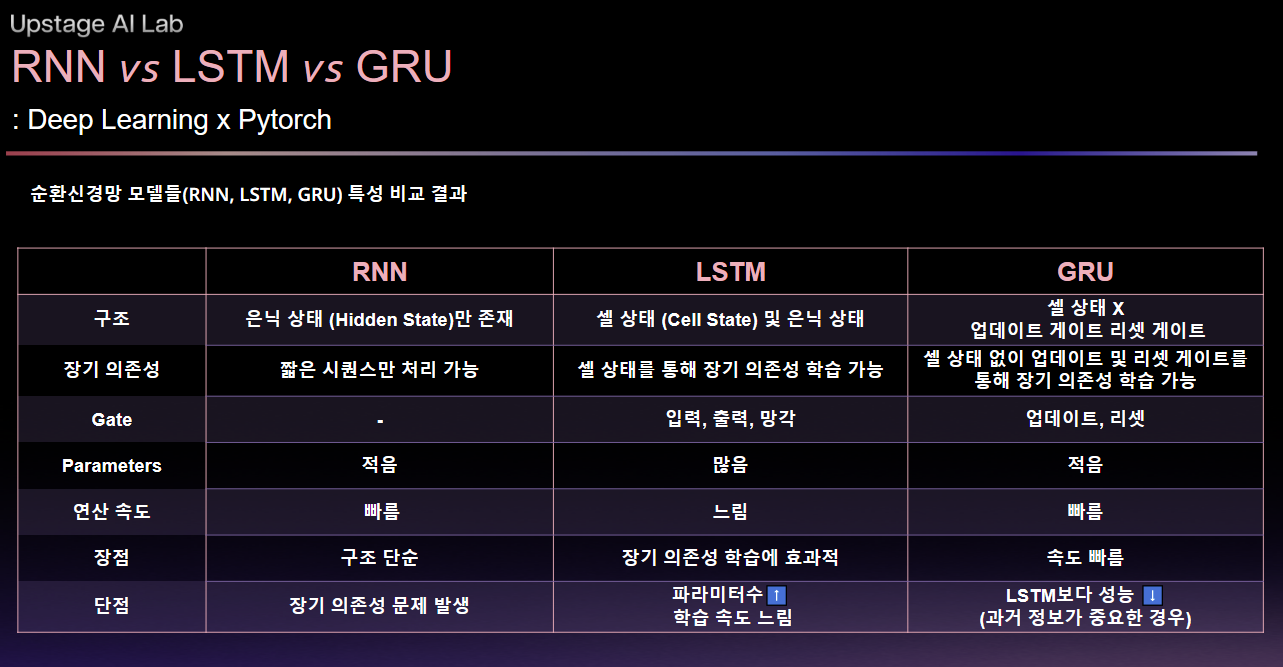
- RNN, LSTM, 그리고 GRU에 대해 이해하기
- 각각을 이용하여 MNIST에 분류기를 구현하며 각 모듈이 실무에서의 활용될 때 어떤 장/단점이 있는지 이해하기
학습 내용 정리
-
순환신경망의 등장
-
기존의 CNN, DNN의 경우, 고정된 크기의 입출력을 처리하도록 설계되어 이미지분류와 같은 task에서 좋은 성능을 보여줬음
-
텍스트, 음성, 주가와 같은 시퀀스 데이터를 다루기 위해 과거의 정보를 기억하면서 가변적인 현재의 입력도 동시에 처리할 필요성이 생김
→ 이런 배경에 따라 순환신경망(Recurrent Neural Network, RNN)이 등장
-
-
RNN
-
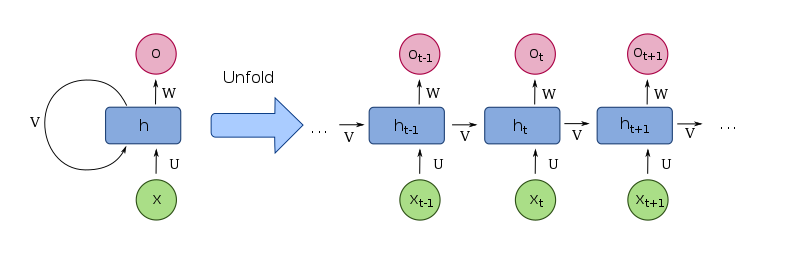
이전 시점의 정보를 현재 시점의 입력과 같이 처리하는 순환 구조가 핵심
-
순환 구조를 통해 rnn은 시퀀스내의 정보를 기억할 수 있음
-
hidden state는 rnn의 핵심적인 요소로, 네트워크가 시간에 따라 어떤 정보를 기억할지 결정
- 이는 네트워크의 기억으로 볼 수 있으며, 각 시점에서 업데이트 됨

- 이는 네트워크의 기억으로 볼 수 있으며, 각 시점에서 업데이트 됨
-
지금까지의 one to one 구조에서 벗어나 여러 구조로 확장시켜 생각해보자
- ex) 입력 이미지에 대해 설명하는 텍스트를 출력하는 모델 - one to many
- 역으로 시퀸스를 입력으로 받아 하나의 출력을 생성할 수 있음 - many to one
- 아니면 번역과 같이 시퀸스를 받아 시퀸스를 결과로 낼 수 있음 - many to many
-
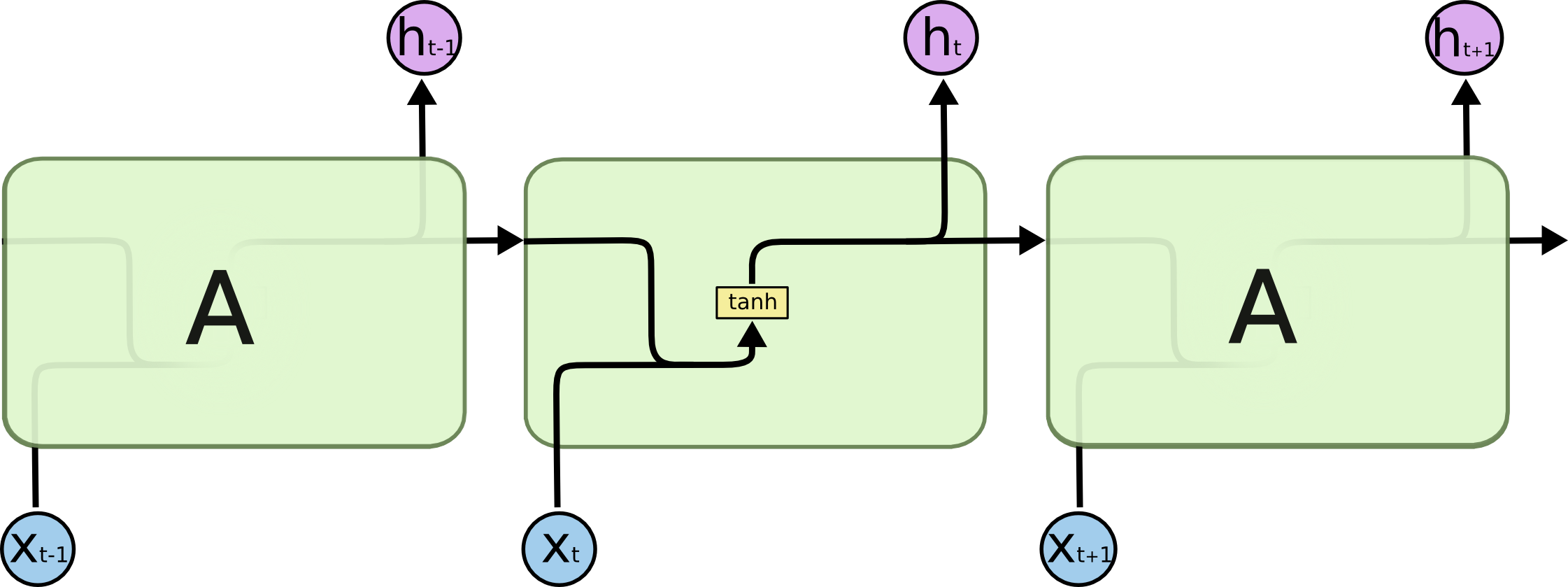
RNN의 구조
-
RNN의 한계
-
시퀸스가 길어질수록 앞부분의 정보를 잊는 문제가 발생 - Long-Term Dependency 문제
→ 이를 해결하기 위해 LSTM이나 GRU등이 등장
-
-
-
LSTM(Long Short-Term Memory)
- RNN의 장기 의존성 문제를 완화하기 위해 설계
- 입력, 출력, 망각 3개의 Gate를 통해 정보의 흐름을 조절해 시퀸스릐 장기적인 정보를 잘 학습하고 유지할 수 있음
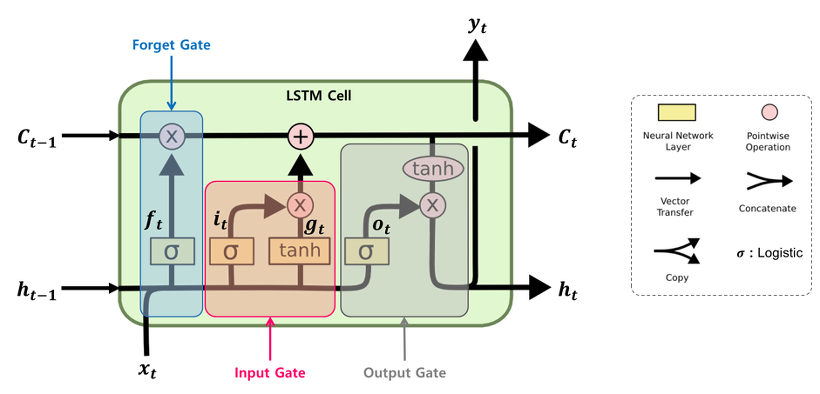
- Forget gate : 가장 첫 번째 단계 중 하나이며 기존 정보 중 어떤 정보를 버릴지 선택
- Input gate : 입력 데이터 중 어떤 정보를 다음 상태로 저장할지 결정
- Output gate : 다음 상태로 어떤 정보를 내보낼지 선택
-
GRU (Gated Rucurrent Unit)
- LSTM을 단순화 한 구조로 Reset gate와 Update gate만을 가지고 유사한 성능을 확보
- LSTM보다 적은 파라미터로 유사 성능을 낼 수 있어 비용면에서 보다 효율적

- Reset gate : 이전 상태의 정보가 얼마나 현재 상태의 계산에 사용될지 결정(이전 정보를 얼마나 리셋 할지 결정)
- Update gate : 이전 상태를 얼마나 현재 상태에 보존할지, 새로운 정보를 얼마나 현재 상태에 반영할지 결정 (LSTM의 forget gate와 input gate를 하나로 합친 것과 유사)
2주차 과제
핵심 주제
- MNIST 데이터셋을 MLP로 학슴하는 코드를 실습함으로써 Pytorch의 기능과 supervised learning의 기본적인 구조와 코드 구성에 대해 이해 한다.
학습 내용 정리
-
파이토치 소개
- 딥러닝 프레임워크
- 모델을 구성하는데 필요한 모든 구성 요소를 제공
- 데이터, 머신러닝 직군의 자격 요건
- 딥러닝 프레임워크 트렌드
- TensorFlow
- PyTorch - 사용자 크게 증가 (대부분의 SOTA가 PyTorch로 구현)
- JAX
- MXNet
- Why PyTorch?
- NLP - Hugging Face가 가장 대중적인 커뮤니티이며, 대부분의 공개모델은 PyTorch가 사용됨
- CV - timm, segementation_models_pytorch 라이브러리 등 사전 학습 모델을 편리하게 사용할 수 있도록 PyTorch 생태계가 구축되어 있음
- LLM - 최근의 LLM 모델들 또한 PyTorch로 공개되어 있음
- 딥러닝 프레임워크
-
Tensor
-
Tensor란? 데이터 배열을 의미
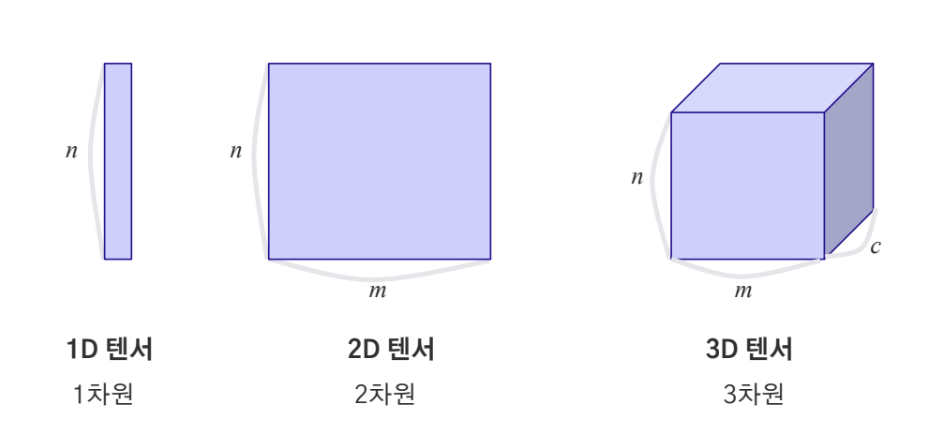
-
텐서의 사칙연산 - 원소 단위로

-
내적 - 1D 단위에서만 가능

-
행렬 곱 - 앞 행렬의 열과 뒤 행렬의 행의 길이가 같아야 함
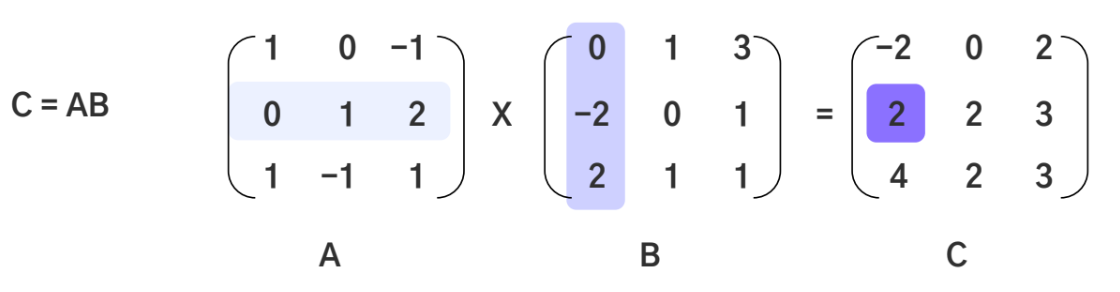
-
Broadcasting - 차원이 다른 두 텐서 혹은 텐서와 스칼라간 연산을 가능하게 해주는 기능(불가능한 경우 존재)
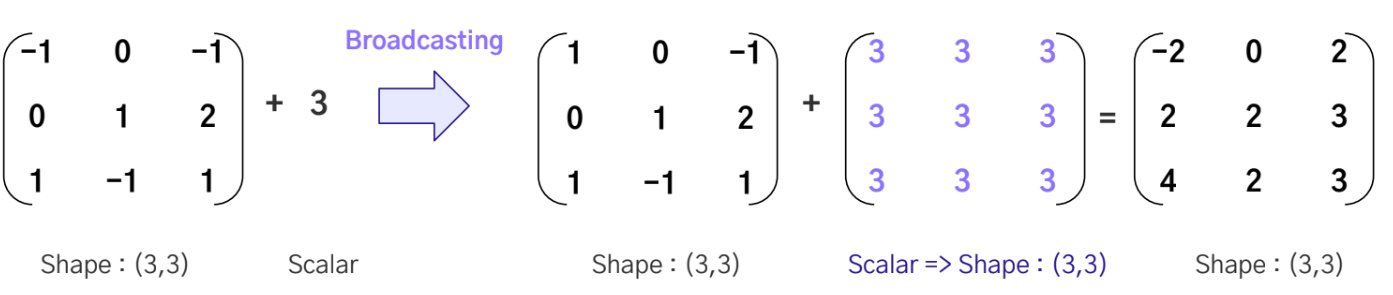
-
Broadcasting을 이용해 2D와 1D의 연산
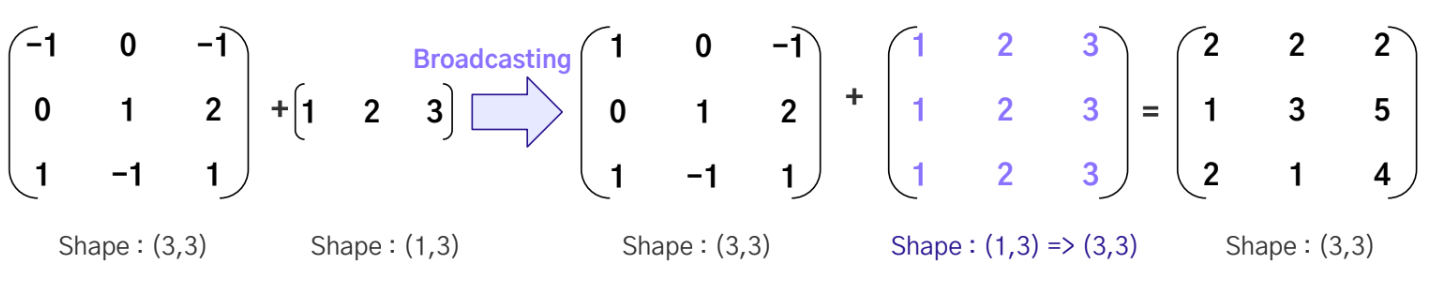
-
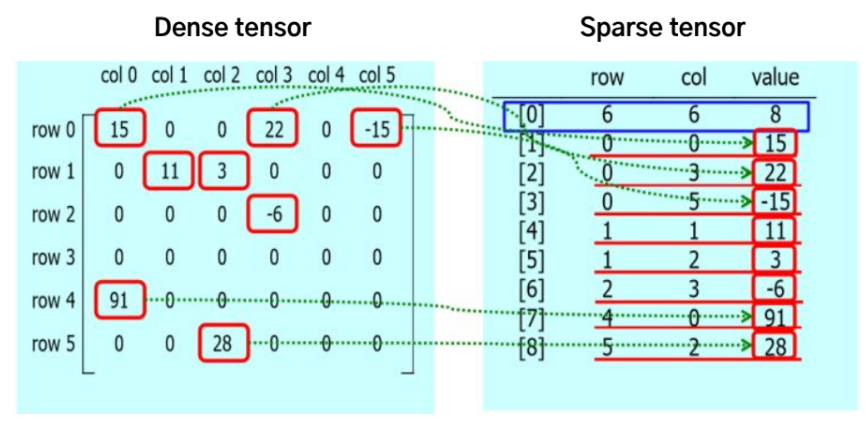
Dense tensor : 배열의 모든 위치에 값을 가지는 텐서
- 생략 가능한 원소까지 모두 저장해 tensor의 크기와 메모리의 사용량이 비례
- Out of Memory 문제 발생 가능
- 계산량 증가
-
Sparse tensor : 0이 아닌 원소와 그 위치를 저장하는 텐서
-
tensor에 0이 많을 경우 효율적
-
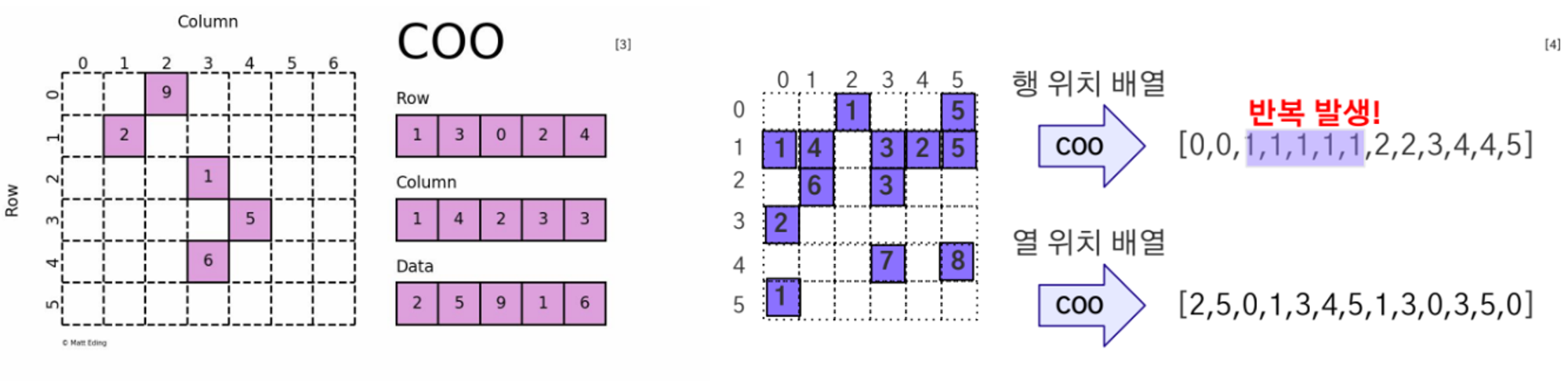
COO(Coordinate list), CSR/CSC(Compressed Sparse Row/Column) 방식 등 존재
-
-
Sparse COO Tensor
- (row_index, column_index, value)의 형태로 저장 (index는 0이 아닌 값의 위치)
- 장점 - 직관적
- 단점
-
인덱스를 별도로 저장해 반복되어 저장하는 값이 발생 → 비효율적
-
원소에 접근시 인덱스를 찾아야함 → 반복 접근시 성능 저하
-
-
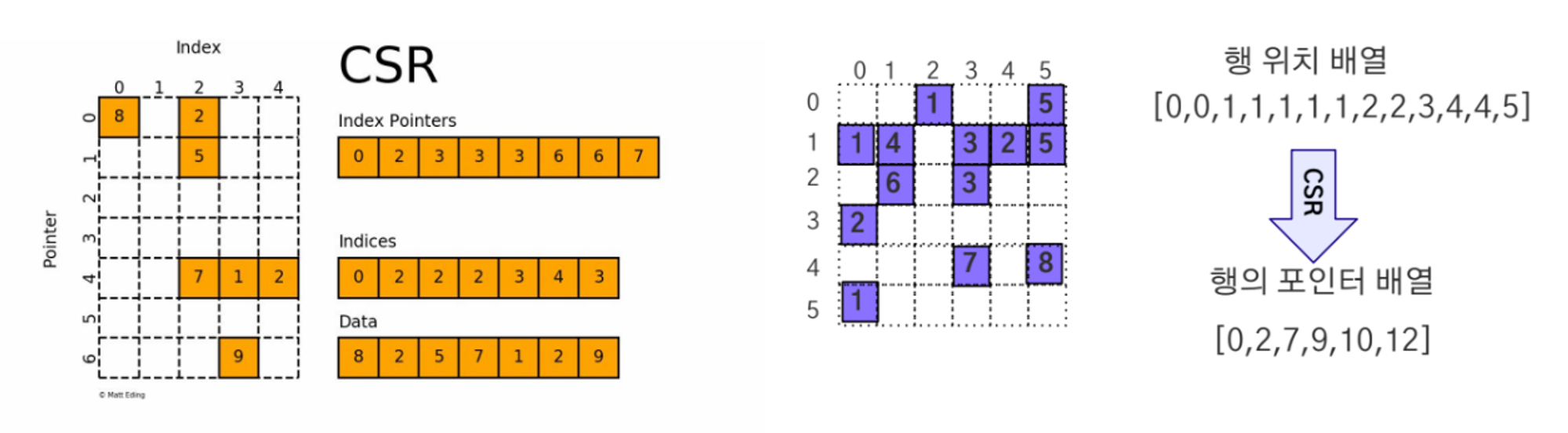
Sparse CSR/CSC Tensor
- CSR(row_pointer, column_index, value), CSC(column_pointer, row_index, value)의 형태로 저장
-
index : 0이 아닌 원소 순서대로 인덱스를 정렬한 배열
-
pointer : 경계를 표시하는 배열(0~1, 1~2)
-
- 장점 - 원소를 순회하는 방식으로 효율적
- 단점 - 구조가 복잡해 직관적이지 않음
- CSR(row_pointer, column_index, value), CSC(column_pointer, row_index, value)의 형태로 저장
-
rand : 0과 1 사이의 균일한 분포 (Uniform Distribution) 에서 무작위로 생성된 텐서를 반환
-
randn : 평균이 0이고 표준 편차가 1인 정규 분포(가우시안 분포)에서 무작위로 생성된 텐서를 반환
-
randint : 주어진 범위 내에서 정수값을 무작위로 선택하여 텐서를 생성 (단, 최솟값을 포함하고, 최댓값은 포함하지 않음)
-
zeros : 모든 요소가 0인 텐서 반환
-
ones : 모든 요소가 1인 텐서 반환
-
full: 모든 요소가 지정된 값인 텐서 반환
-
eye : 단위 행렬 반환 (※ 단위 행렬이란? 대각선 요소가 1이고, 나머지 요소가 0인 행렬)
-
tensor : 주어진 데이터를 텐서로 변환. 데이터는 list, tuple, numpy array 등의 형태일 수 있음
-
from_numpy : numpy array 를 텐서로 변환
-
as_tensor: 변환 전 데이터와의 메모리 공유(memory sharing)를 사용하므로, 변환 전 데이터 변경 시 변환되어 있는 텐서에도 반영됨
-
Tensor : float32 type으로 텐서 변환
-
Indexing 기본 : 대괄호("[ ]")를 통해 이뤄지며, ":" 는 특정 범위의 접근을 의미
-
index_select : 선택한 차원에서 인덱스에 해당하는 요소만 추출하는 함수
-
Masking 을 이용한 Indexing : 조건에 따른 텐서의 요소를 사용하기 위한 방법으로 조건에 맞는 요소들만 반환하는 방법
-
masked_select : 주어진 mask에 해당하는 요소들을 추출하여 1차원으로 펼친 새로운 텐서를 반환하는 함수
-
take : 주어진 인덱스를 사용하여 텐서에서 요소를 선택하는 함수. 인덱스 번호는 텐서를 1차원으로 늘려졌을 때 기준으로 접근해야함
-
gather : 주어진 차원에서 인덱스에 해당하는 요소들을 선택하여 새로운 텐서를 반환
-
size : 텐서의 모양을 확인
-
reshape : 텐서의 모양을 변경합니다. 메모리를 공유하지 않음
-
view : 텐서의 모양을 변경
-
transpose : 텐서의 차원을 전치
-
permute : 텐서 차원의 순서를 재배열
-
unsqueeze : 텐서에 특정 차원에 크기가 1인 차원을 추가
-
squeeze : 텐서에 차원의 크기가 1인 차원을 제거
-
expand : 텐서의 값을 반복하여 크기를 확장
- A 텐서가 1차원일 경우 : A 텐서의 크기가 (m,) 이면 m은 고정하고 (x,m)의 크기로만 확장 가능
- A 텐서가 2차원 이상일 경우 : 크기가 1인 차원에 대해서만 적용 가능. A 텐서의 크기가 (1,m) 이면 (x,m) , (m,1) 이면 (m,y) 로만 확장 가능
-
repeat : 텐서를 반복하여 크기를 확장
- ex) A 텐서가 (m,n) 크기를 가진다하고, A 텐서를 repeat(i,j) 를 하면 결과값으로 (m x i, n x j)의 크기의 텐서가 생성
-
flatten : 다차원 텐서를 1차원 텐서로 변경
-
ravel : 다차원 텐서를 1차원 텐서로 변경
-
모양 변경 : view vs. reshape vs. unsqueeze
- ※ contiguous 란?
- 텐서의 메모리 상에 연속적인 데이터 배치를 갖는 것
- 텐서를 처음 생성 후 정의하면 기본적으로 contiguous 하지만, 이에 대해 차원의 순서를 변경하는 과정을 거치면 contiguous 하지 않음
- 텐서의 contiguous 함을 확인하기 위해선 is_contiguous() 를 사용
- view 는 contiguous 하지 않은 텐서에 대해서 동작하지 않음
- reshape 는 contiguous 하지 않은 텐서를 contiguous 하게 만들어주고, 크기를 변경
- unsqueeze 는 차원의 크기가 1인 차원을 추가하지만, 차원의 크기가 1이 아니면 차원의 모양을 변경할 수 없음
- ※ contiguous 란?
-
차원 변경 : transpose vs. permute
- transpose : 두 차원에 대해서만 변경이 가능
- 인자가 총 2개여야함
- permute : 모든 차원에 대해서 변경이 가능
- 인자가 차원의 개수와 동일해야 함
- transpose : 두 차원에 대해서만 변경이 가능
-
반복을 통한 텐서 크기 확장 : expand vs. repeat
- expand
- 원본 텐서와 메모리를 공유
- repeat
- 원본 텐서와 메모리를 공유하지 않음
- expand
-
cat : 주어진 차원을 따라 텐서들을 연결
-
stack : 주어진 차원을 새로운 차원으로 추가하여 텐서들을 쌓음
- 합쳐질 텐서들의 크기는 모두 같아야함
-
chunk : 나누고자 하는 텐서의 개수를 지정하여 원래의 텐서를 개수에 맞게 분리
- chunks 인자
- 몇 개의 텐서로 나눌 것인지
- chunks 인자
-
split : 입력한 크기로 여러 개의 작은 텐서로 나눔
- split_size_or_sections 인자
- split_size (int): 얼마만큼의 크기로 자를 것인지
- sections (list): 얼마만큼의 크기로 각각 자를 것인지 (리스트 형태로 각 텐서의 크기를 각각 지정해 줄 수 있음)
- split_size_or_sections 인자
-
add : 텐서 간의 덧셈을 수행(+)
- torch.add(a, b)
- a.add(b)
- a + b
-
sub : 텐서 간의 뺄셈을 수행 (-)
- torch.sub(a, b)
- a.sub(b)
- a - b
-
mul : 텐서 간의 곱셈을 수행 (*)
- torch.mul(a, b)
- a.mul(b)
- a * b
-
div : 텐서 간의 나눗셈을 수행 (/)
- torch.div(a, b)
- a.div(b)
- a / b
-
sum : 텐서의 원소들의 합을 반환
-
mean : 텐서의 원소들의 평균을 반환
-
max : 텐서의 원소들의 가장 큰 값을 반환
-
min : 텐서의 원소들의 가장 작은 값을 반환
-
argmax : 텐서의 원소들의 가장 큰 값의 위치 반환
-
argmin : 텐서의 원소들의 가장 작은 값의 위치 반환
-
dot : 벡터의 내적 (inner product) 반환
- torch.dot(a,b)
- a.dot(b)
-
matmul : 두 텐서 간의 행렬곱 반환 ※ 원소 곱과 다름 주의❗
- torch.matmul(a,b)
- a.matmul(b)
-
sparse_coo_tensor : COO 형식의 sparse tensor 를 생성하는 함수
- indices : 0 이 아닌 값을 가진 행,열의 위치
- values : 0 이 아닌 값
- nnz : 0 이 아닌 값의 개수
-
to_sparse_csr : Dense tensor를 CSR 형식의 Sparse tensor로 변환하는 함수
- crow_indices : 0 이 아닌 값을 가진 행의 위치 (첫번째는 무조건 0)
- col_indices : 0 이 아닌 값을 가진 열의 위치
- values : 0 이 아닌 값
- nnz : 0 이 아닌 값의 개수
-
to_sparse_csc : Dense tensor를 CSC 형식의 Sparse tensor로 변환하는 함수
- ccol_indices : 0 이 아닌 값의 열 위치 (첫번째 원소는 무조건 0)
- row_indices : 0 이 아닌 값의 행 위치
- values : 0 이 아닌 값들
- nnz : 0 이 아닌 값의 개수
-
sparse_csr_tensor : CSR 형식의 Sparse tensor 를 생성하는 함수
-
sparse_csc_tensor : CSC 형식의 Sparse tensor 를 생성하는 함수
-
to_dense() : sparse tensor 를 dense tensor 로 만드는 함수
-
2차원 sparse tensor 간에는 일반 텐서와 동일하게 사칙연산 함수들과 행렬곱을 사용할 수 있음
-
3차원 sparse tensor 에는 일반 텐서와 동일하게 사칙연산 함수들은 사용 가능하지만 행렬곱을 사용할 수 없음
- CSR/CSC 형식에서는 곱셈도 3차원에선 불가능
-
이는 sparse tensor 와 sparse tensor 간에도 적용이 되고, sparse tensor 와 dense tensor 간의 연산에도 적용 됨
-
slicing (":" 을 사용)은 불가능
-
공유회