개요
진행하고 있는 프로젝트의 핵심 API들이 대부분 마무리 되었다. 비록 실제로 운영 계획은 없는 프로젝트지만, 미리 운영 환경에서의 장애 대응을 위한 로깅 파이프라인을 구축해보기로 했다.
설계
ELK + Filebeat
로그 파이프라인은 다양하지만 가장 대중적으로 많이 사용하는 ELK(Elasticsearch + Logstash + Kibana)와 Filebeat를 활용하여 구축하였다.
각 서비스의 역할은 다음과 같다.
- Elasticsearch - 데이터(로그) 저장소
- Logstash - 데이터 필터
- Kibana - 데이터 시각화
- Filebeat - 데이터 전송
옛날에는 Logstash가 데이터 전송/필터를 모두 처리했지만, 부담을 줄이기 위해 데이터 전송 역할을 맡는 Filebeat가 도입되었다.
단순히 필터링 없이 데이터 전송이 목적이라면 Logstash, Filebeat 중 하나만 사용해도 무방하다.
Filebeat
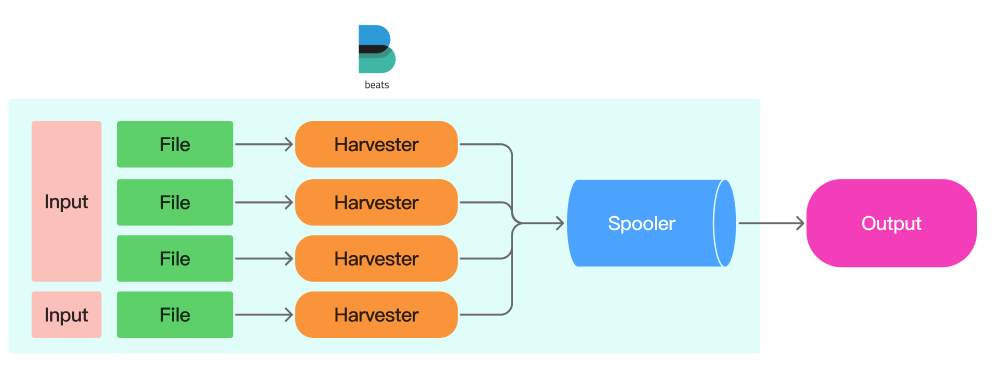
그렇다면 Filebeat는 로그를 어떻게 수집할까?
Filebeat는 크게 Input, Harvester, Spooler 구성되어있다.
- Input - 수집할 데이터의 파일 위치
- Harvester - 개별 파일(Input)마다 생성되어 주기적으로 데이터를 읽고, 새로운 데이터를 수집하여 Spooler로 전송
- Spooler - 데이터를 적재하는 메모리 큐로 저장된 데이터를 타겟 Output으로 출력
Logback
이제 애플리케이션 내에서 Filebeat가 수집할 수 있도록 로그를 저장해두면 된다.
Logback 프레임워크를 활용하여 다음과 같은 기능을 적용하였다
- Log Level에 따른 로그 저장 위치 설정
- Log Level 또는 콘솔에 따른 로그 출력 방식 설정
- 로그 파일 롤링 설정
로그 롤링(Rolling)
로그를 특정 정책으로 분리하여 관리하고, 무한히 쌓이지 않도록 삭제/압축하는 방식을 의미한다
그렇다면 Logback의 롤링은 어떻게 처리될까?
Logback에서는 롤링을 처리하기 위해 RollingFileAppender<E> extends FileAppender<E>를 사용한다.
RollingFileAppender는 어떻게 롤링을 처리할지에 대한 정책 RollingPolicy와 언제 롤링을 처리할지에 대한 정책 TriggeringPolicy을 가지고 있다.
가장 많이 사용되고, 내가 적용한 정책 TimeBasedRollingPolicy은 RollingPolicy and TriggeringPolicy을 모두 상속받아 구현되어 있다.
이름에서 알 수 있듯이 시간을 통해 롤링이 적용된다.
가장 중요한 옵션을 살펴보면, <fileNamePattern>을 통해 로그를 롤링하여 어떤 파일 이름의 패턴을 적용할지 정하고, <maxHistory>를 통해 로그 보관 주기를 정한다.
<fileNamePattern>의 형식에 최소 단위에 따라 롤오버 주기가 결정된다.
- %d{yyyy-MM} → 한 달 단위로 롤오버
- %d{yyyy-MM-dd} → 하루 단위로 롤오버
- %d{yyyy-MM-dd_HH} → 시간 단위 롤오버
실제 호출 메소드를 살펴보면 롤오버 주기가 정해졌다고 해서 스케쥴러처럼 정확하게 해당 주기에 롤오버가 발생하진 않는다.
롤오버는 트리거를 통해 호출되는데, 이 트리거는 로그 파일 작성 시점에 검증되기 때문에, 새로운 로그가 작성될 때 롤오버가 진행된다.
롤오버가 호출되면 로그 파일을 <fileNamePattern>에 맞게 교체하고, archiveRemover.cleanAsynchronously()를 통해 비동기적으로 오래된 로그 파일을 찾아 삭제한다.
public class TimeBasedRollingPolicy<E> extends RollingPolicyBase implements TriggeringPolicy<E> {
// 트리거 확인
public boolean isTriggeringEvent(File activeFile, E event) {
return this.timeBasedFileNamingAndTriggeringPolicy.isTriggeringEvent(activeFile, event);
}
public void rollover() throws RolloverFailure {
String elapsedPeriodsFileName = this.timeBasedFileNamingAndTriggeringPolicy.getElapsedPeriodsFileName();
String elapsedPeriodStem = FileFilterUtil.afterLastSlash(elapsedPeriodsFileName);
if (this.compressionMode == CompressionMode.NONE) {
if (this.getParentsRawFileProperty() != null) {
this.renameUtil.rename(this.getParentsRawFileProperty(), elapsedPeriodsFileName);
}
} else if (this.getParentsRawFileProperty() == null) {
this.compressionFuture = this.compressor.asyncCompress(elapsedPeriodsFileName, elapsedPeriodsFileName, elapsedPeriodStem);
} else {
this.compressionFuture = this.renameRawAndAsyncCompress(elapsedPeriodsFileName, elapsedPeriodStem);
}
if (this.archiveRemover != null) {
Instant now = Instant.ofEpochMilli(this.timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());
this.cleanUpFuture = this.archiveRemover.cleanAsynchronously(now); // 비동기 삭제 호출
}
}
}참고 - Logback Docs(timebasedrollingpolicy)
MDC
또한, 멀티스레드 환경에서 다양한 스레드의 로그 순서가 섞이게 된다. MDC를 활용하면 스레드 단위로 로그를 묶어서 관리가 가능하다.
// MDC 적용 전
Thread-1: Step 0
Thread-3: Step 0
Thread-2: Step 0
Thread-3: Step 1
Thread-1: Step 1
Thread-2: Step 1
Thread-1: Step 2
Thread-3: Step 2
Thread-2: Step 2
// MDC 적용 후
INFO REQ-1 Step 0
INFO REQ-1 Step 1
INFO REQ-1 Step 2
INFO REQ-2 Step 0
INFO REQ-2 Step 1
INFO REQ-2 Step 2
INFO REQ-3 Step 0
INFO REQ-3 Step 1
INFO REQ-3 Step 2동작 원리는 간단하다.
각각의 스레드에 대한 로그 정보를 스레드에 저장해서 한 번에 출력해주면 된다.
그런 의미에서 ThreadLocal과 큰 차이가 없다.
MDC도 내부적으로 ThreadLocal을 활용한 로깅 목적으로 설계된 구현체이다.
public class LogbackMDCAdapterSimple implements MDCAdapter {
final ThreadLocal<Map<String, String>> threadLocalUnmodifiableMap = new ThreadLocal();
private final ThreadLocalMapOfStacks threadLocalMapOfDeques = new ThreadLocalMapOfStacks();
...
}
public class LogbackMDCAdapter implements MDCAdapter {
final ThreadLocal<Map<String, String>> readWriteThreadLocalMap = new ThreadLocal();
final ThreadLocal<Map<String, String>> readOnlyThreadLocalMap = new ThreadLocal();
private final ThreadLocalMapOfStacks threadLocalMapOfDeques = new ThreadLocalMapOfStacks();
...
}웹훅을 통한 알림 메시지
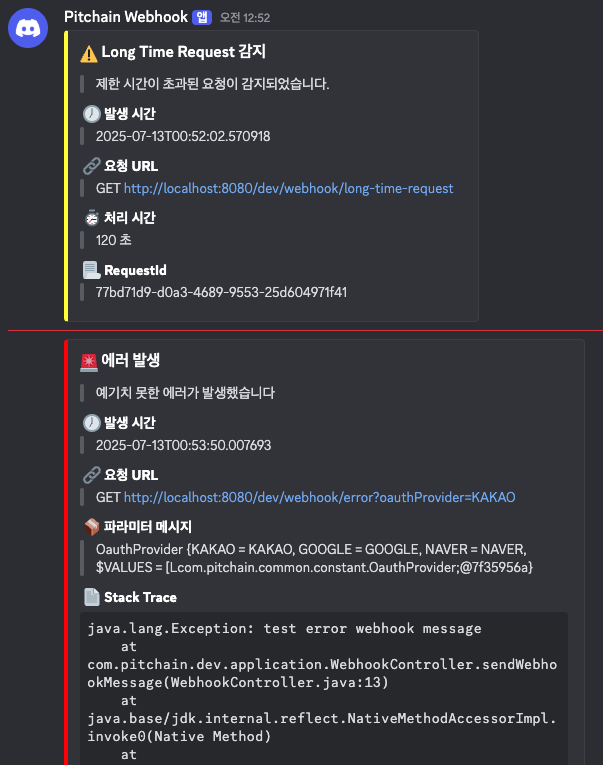
Kibana에도 특정 로그가 저장됐을 때, 설정해둔 webhook으로 경고 알림을 받을 수 있다.
하지만, kibana 알림은 주기적으로 Elasticsearchd에 인덱스 조회 쿼리를 날리는 모니터링을 설정하고, 식별되면 트리거를 발생시켜 웹훅으로 알림을 발송시키는 메커니즘이다.
따라서 앱에서 에러가 발생했을 때 kibana로 알림을 통해 처리한다면 모니터링 주기에 의해, 실제 에러 발생 시점 이후에 알림을 전달받을 것이다. 이 주기를 짧게 가진다면 어느정도 실시간성을 보장받겠지만, 서버에 더 부담이 갈 수 있다고 생각했기 때문에, 앱에서 에러 식별 시 바로 알림을 전달 받을 수 있도록 구현했다.
웹훅은 디스코드 플랫폼을 활용하였고, 내가 적용한 메시지 발생 조건은 다음과 같다.
- 요청에 대한 처리 시간이 긴 경우
- 정의되지 않은 서버 에러가 발생한 경우
파이프라인 구축
배포 환경에서는 다음과 같이 ELK 서버를 따로 구축하는 것이 적절하겠지만, 현재 프로젝트에선 실제로 운영은 안 하기 때문에 인프라 구축 및 비용을 고려하여 Spring Server에 도커 컴포즈를 활용하여 구축해보았다.
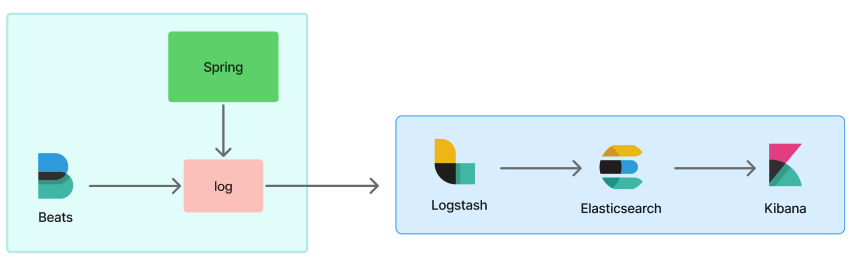
docker-compose로 ELK를 구축하는 방법은 docker-elk를 참고하였고, Filebeat는 elastic-filebeat-reference를 참고했다.
version: "3.8"
services:
elasticsearch:
container_name: pitchain_elasticsearch
build:
context: ./elk/elasticsearch
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./elk/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro,Z
- elasticsearch:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
environment:
ES_JAVA_OPTS: "-Xmx256m -Xms256m"
ELASTIC_PASSWORD: ${ELASTIC_PASSWORD:-}
discovery.type: single-node
networks: [elk]
logstash:
container_name: pitchain_logstash
build:
context: ./elk/logstash/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./elk/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro,Z
- ./elk/logstash/pipeline:/usr/share/logstash/pipeline:ro,Z
ports:
- "5044:5044"
- "50000:50000/tcp"
- "50000:50000/udp"
- "9600:9600"
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
LOGSTASH_USERNAME: ${LOGSTASH_USERNAME:-}
LOGSTASH_PASSWORD: ${LOGSTASH_PASSWORD:-}
networks: [elk]
depends_on: [elasticsearch]
kibana:
container_name: pitchain_kibana
build:
context: ./elk/kibana/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./elk/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml:ro,Z
ports:
- "5601:5601"
environment:
KIBANA_SYSTEM_PASSWORD: ${KIBANA_SYSTEM_PASSWORD:-}
networks: [elk]
depends_on: [elasticsearch]
filebeat:
container_name: pitchain_filebeat
user: root
build:
context: ./elk/filebeat/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./logs:/logs
- ./elk/filebeat/config/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro,Z
networks: [elk]
depends_on: [logstash]
networks:
elk:
driver: bridge
volumes:
elasticsearch:
ELK는 인증 없이 단순 경험 목적이라면 비교적 쉽지만, 최대한 배포 환경과 비슷하게 구축하기 위해 인증을 추가하였다.
인증은 elasticsearch가 실행된 후 setup을 통해 처리되도록 했다.
setup:
profiles: [setup]
init: true
build:
context: elk/setup/
args:
ELASTIC_VERSION: ${ELASTIC_VERSION}
volumes:
- ./elk/setup/sh/entrypoint.sh:/entrypoint.sh:ro,Z
- ./elk/setup/sh/lib.sh:/lib.sh:ro,Z
- ./elk/setup/roles:/roles:ro,Z
environment:
ELASTIC_PASSWORD: ${ELASTIC_PASSWORD:-}
KIBANA_SYSTEM_PASSWORD: ${KIBANA_SYSTEM_PASSWORD:-}
LOGSTASH_USERNAME: ${LOGSTASH_USERNAME:-}
LOGSTASH_PASSWORD: ${LOGSTASH_PASSWORD:-}
networks: [elk]
depends_on: [elasticsearch]먼저, 중심이 되는 Elasticsearch는 Kibana와 통신하기 위해 내부적으로 권한과 함께 kibana_system이라는 내장(build-in) 유저가 생성되지만, Logstash와 통신을 위한 유저는 생성되지 않는다.
따라서 프로젝트 로그로 인해 생성되는 인덱스에 대한 접근 권한을 가지는 유저를 만들어줘야 한다.
entrypoint.sh는 elastic-docs를 참고하여 필요한 권한을 json으로 만들어두고, 유저를 생성하여 해당 유저에게 권한을 부여하도록 했다.
Logstash 설정으로는 filebeats와 통신하기 위한 포트를 설정하고, 전달받은 로그 데이터에 대한 필터링을 설정했다.
Logback을 통해 전달한 로그 데이터는 UTC를 기준으로 timestamp가 생성되기 때문에, 한국 시간으로 변환하기 위해 9hour을 더하였고, 로그 레벨에 따라 인덱스 이름을 다르게 설정하였다.
input {
beats {
port => 5044
}
}
filter {
mutate {
add_field => { "[@metadata][korea_time]" => "%{+YYYY.MM.dd}" }
}
ruby {
code => "
event.set('[@metadata][korea_time]', LogStash::Timestamp.at(event.get('@timestamp').to_i + 9 * 60 * 60).time.strftime('%Y.%m.%d'))
"
}
prune {
blacklist_names => [
"^ecs\\.",
"^host\\.",
"^log\\.file",
"^log\\.offset$",
"^event\\.original",
".*\\.keyword$"
]
}
}
output {
if [level] == "ERROR" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "logstash-error-%{[@metadata][korea_time]}"
user => "${LOGSTASH_USERNAME}"
password => "${LOGSTASH_PASSWORD}"
}
} else if [level] == "WARN" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "logstash-warn-%{[@metadata][korea_time]}"
user => "${LOGSTASH_USERNAME}"
password => "${LOGSTASH_PASSWORD}"
}
} else {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "logstash-info-%{[@metadata][korea_time]}"
user => "${LOGSTASH_USERNAME}"
password => "${LOGSTASH_PASSWORD}"
}
}
}filebeats 설정 옵션은 elastic-filebeat-reference-yml을 참고하였고, log를 수집할 input path와 logstash와 통신하기 위한 host를 설정해준다.
나는 프로젝트 루트의 /logs 하위에 info.log, warn.log, error.log로 관리했다.
filebeat.inputs:
- type: log
enabled: true
paths:
- /logs/*.log
json.keys_under_root: true
json.add_error_key: true
json.overwrite_keys: true
output.logstash:
hosts: ["logstash:5044"]
setup.kibana:
host: "http://kibana:5601"이제 앱에서 로깅을 처리하기 위한 코드를 적용해보겠다.
코드
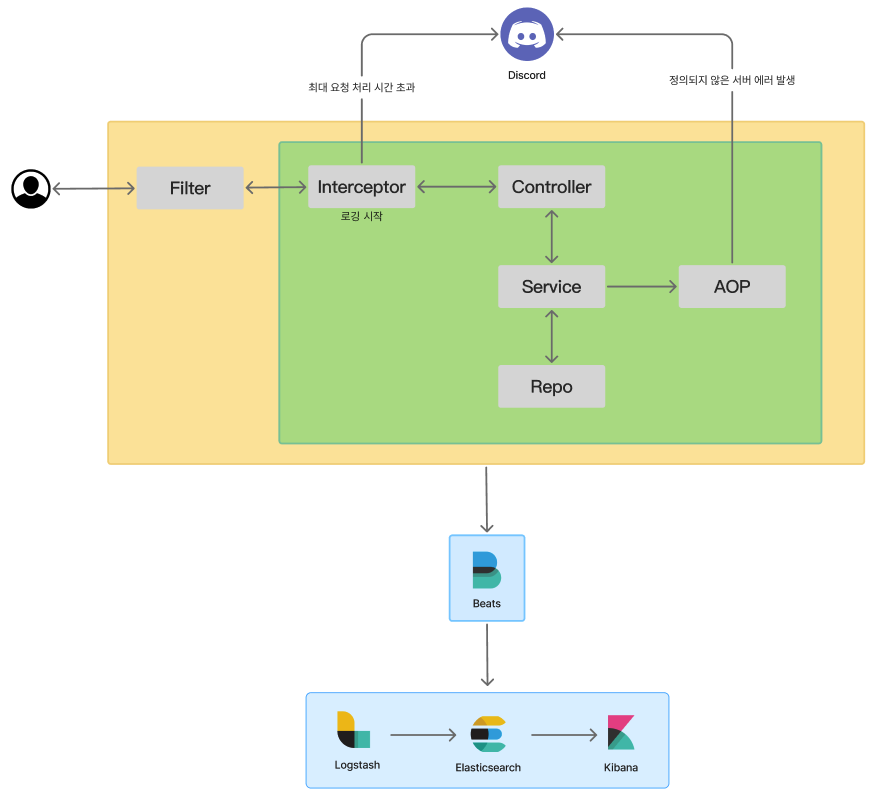
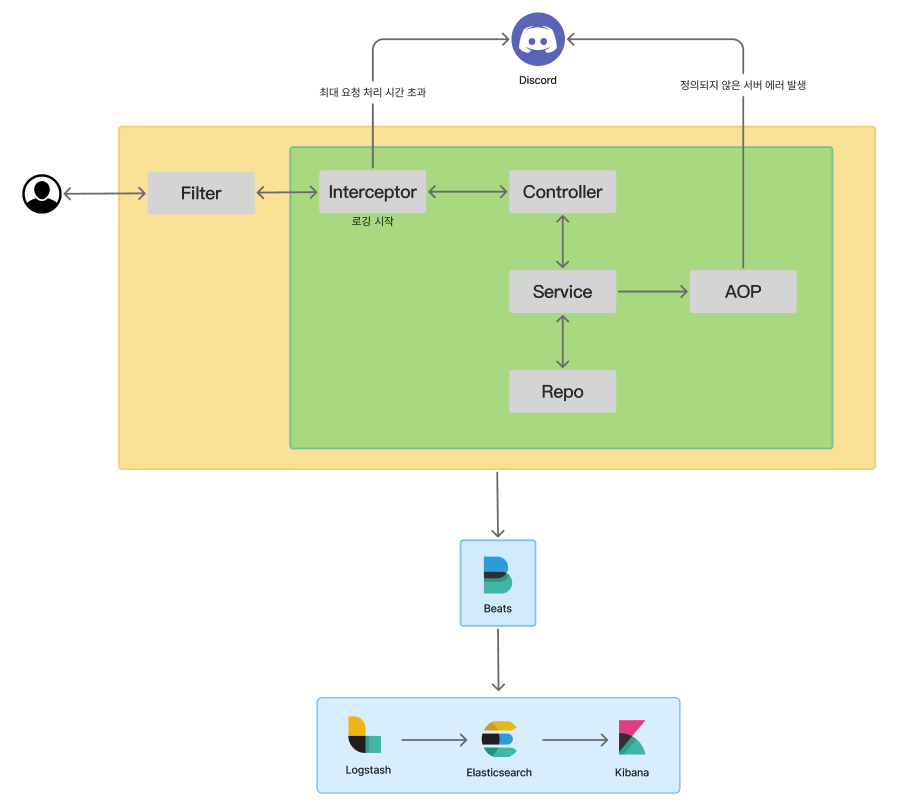
Interceptor를 통한 로깅
'어떤 데이터를 로그로 저장할 것인가?' 를 먼저 고민하게 됐다.
로그를 적용하는 이유는 장애가 발생했을 때 신속하게 파악하고 어디서 장애가 발생했는지 추적하기 위함이다.
따라서 다음과 같은 데이터를 관리한다
- 요청 시간
- 로그 레벨
- 로그 이름 (클래스명)
- 로그 메시지
- MDC
- requestId
- userId
- clientIP
- requestURI
- requestMethod
- httpStatus
- turnaroundTime(sec)
위 로그 데이터를 위해 요청 전/후에 로깅 작업을 해야 한다.
Filter와 Interceptor 모두 가능하지만, JWTFilter를 통한 인증이 성공한 요청에 대해서만 로깅하기 위해 Interceptor를 적용하였다.
요청 처리 전/후에 적절한 로깅을 처리하고, 최대 요청 시간이 증가했다면 webhook을 통해 알림을 전송했다.
@Profile("prod")
public class RequestInterceptor implements HandlerInterceptor {
private final static Long MAX_TURNAROUND_TIME_SEC = 60L; // 1min
...
@Override
public boolean preHandle(HttpServletRequest request, @NotNull HttpServletResponse response, @NotNull Object handler) {
String requestId = UUID.randomUUID().toString();
request.setAttribute(SessionType.REQUEST_ID, requestId);
request.setAttribute(SessionType.START_TIME, System.currentTimeMillis());
LoggingUtil.logPreRequest(requestId, request.getRequestURI(), request.getMethod());
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
long startTime = (Long) request.getAttribute(SessionType.START_TIME);
long turnaroundTimeSec = (System.currentTimeMillis() - startTime) / 1000;
if (turnaroundTimeSec > MAX_TURNAROUND_TIME_SEC) {
sendLongTimeRequestWebhook(turnaroundTimeSec);
}
LoggingUtil.logCompleteRequest(response.getStatus(), turnaroundTimeSec, ex);
}
...
}
public class LoggingUtil {
public static void logPreRequest(String requestId, String requestURI, String requestMethod) {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
String userId = (authentication == null || Objects.equals(authentication.getName(), "anonymousUser")) ? "anonymous" : authentication.getName();
String clientIp = RequestInfoExtractor.getClientIpAddressIfServletRequestExist();
MDC.put("requestId", requestId);
MDC.put("userId", userId);
MDC.put("clientIp", clientIp);
MDC.put("requestURI", requestURI);
MDC.put("requestMethod", requestMethod);
log.info("HTTP request started");
}
public static void logCompleteRequest(int status, long turnaroundTime, Exception ex) {
MDC.put("httpStatus", String.valueOf(status));
MDC.put("turnaroundTime(sec)", String.valueOf(turnaroundTime));
if (ex == null) {
log.info("HTTP request completed");
} else {
log.error("HTTP request failed", ex);
}
MDC.clear();
}
}AOP(Aspect) 로깅
Interceptor는 요청에 대한 시작과 끝을 추적하기 위함이라면, Aspect는 특정 예외 혹은 의도치 않은 에러 발생 시 로깅하기 위함이다.
따라서, RuntimeException을 상속받은 프로젝트의 전역 예외 GeneralException에 대한 로깅과 정의되지 않은 Server Error에 대한 로깅을 구현했다.
Server Error는 발생 시 디스코드 웹훅 메시지를 전송하도록 했다.
예외 발생 시 에러는 Controller까지 전파되고, Controller에서 이를 처리하여 에러 응답을 반환하는 구조이기 때문에, 이 흐름에 영향을 주지 않도록 Service 계층에서는 GeneralException과 ServerError를 캐치해 로깅만 수행한 뒤, 다시 예외를 던져 정상적인 예외 처리 플로우가 유지되도록 했다.
@Aspect
public class GeneralExceptionLoggingAspect {
@Pointcut("execution(public * com.pitchain..*.application..*.*(..))")
private void logPointcut() {}
@AfterThrowing(value = "logPointcut()", throwing = "exception")
public void logAfterThrowing(JoinPoint joinPoint, GeneralException exception) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
String className = signature.getDeclaringType().getSimpleName();
List<String> arguments = LoggingUtil.getArguments(joinPoint);
String parameterMessage = LoggingUtil.getParameterMessage(arguments);
ErrorStatus errorStatus = exception.getErrorStatus();
MDC.put("httpStatus", String.valueOf(errorStatus.getHttpStatus()));
log.error("[ERROR] POINT : {} || EXCEPTION : {} || ARGUMENTS : {}",
className, errorStatus.getCode(), parameterMessage
);
log.error("[ERROR] FINAL POINT : {}", exception.getStackTrace()[0]);
log.error("[ERROR] MESSAGE : {}", exception.getMessage());
MDC.remove("httpStatus");
}
}
@Aspect
public class UnintendedExceptionLoggingAspect {
private final DiscordWebhookSender discordWebhookSender;
@Pointcut("execution(public * com.pitchain..*.application..*.*(..))")
private void logPointcut() {}
@AfterThrowing(value = "logPointcut()", throwing = "exception")
public void logAfterThrowing(JoinPoint joinPoint, Exception exception) {
if (exception instanceof GeneralException) return;
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
String className = signature.getDeclaringType().getSimpleName();
String parameterMessage = getParameterMessage(joinPoint);
MDC.put("httpStatus", "500");
Throwable cause = exception.getCause();
String stackTrace = getStackTrace(exception);
log.error("[SERVER ERROR] POINT : {} || ARGUMENTS : {}", className, parameterMessage);
log.error("[SERVER ERROR] MESSAGE : {}", exception.getMessage());
log.error("[SERVER ERROR] CAUSE : {}", cause != null ? cause.toString() : "No cause available"
);
log.error("[SERVER ERROR] FINAL POINT : {}",
(stackTrace != null && stackTrace.length() > 0) ? getFirstLine(stackTrace) : "No stack trace available"
);
MDC.remove("httpStatus");
sendErrorWebhook(parameterMessage, stackTrace);
}
}Logback
이제 앱에서 호출하는 로그를 Filebeat가 수집하고, 롤링을 적용하기 위해 Logback 프레임워크를 활용하여 logback.xml을 설정했다.
일(d) 단위로 롤링을 실시하고 30일 동안 보관한다.
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true">
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<property name="LOG_PATH" value="./logs" />
<property name="LOG_FILE_INFO" value="${LOG_PATH}/info.log" />
<property name="LOG_FILE_ERROR" value="${LOG_PATH}/error.log" />
<property name="LOG_FILE_WARN" value="${LOG_PATH}/warn.log" />
<!-- INFO -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE_INFO}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/info.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp fieldName="@timestamp"/>
<logLevel />
<loggerName />
<message />
<mdc />
</providers>
</encoder>
</appender>
<!-- ERROR -->
...
<!-- WARN -->
...
<!-- 콘솔 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp fieldName="@timestamp"/>
<logLevel />
<loggerName />
<message />
</providers>
</encoder>
</appender>
</configuration>
전체 흐름
큰 틀로 전체적인 흐름을 살펴보면 다음과 같이 처리된다.
테스트
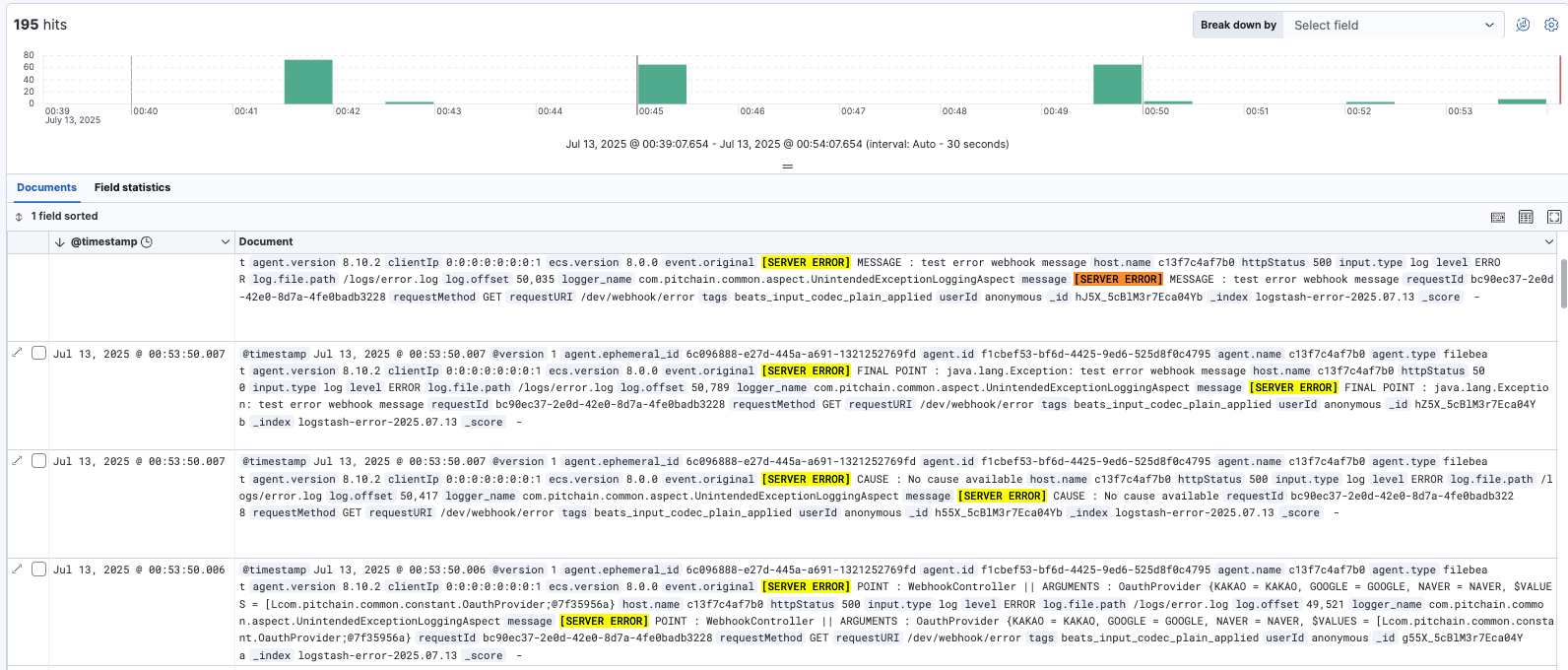
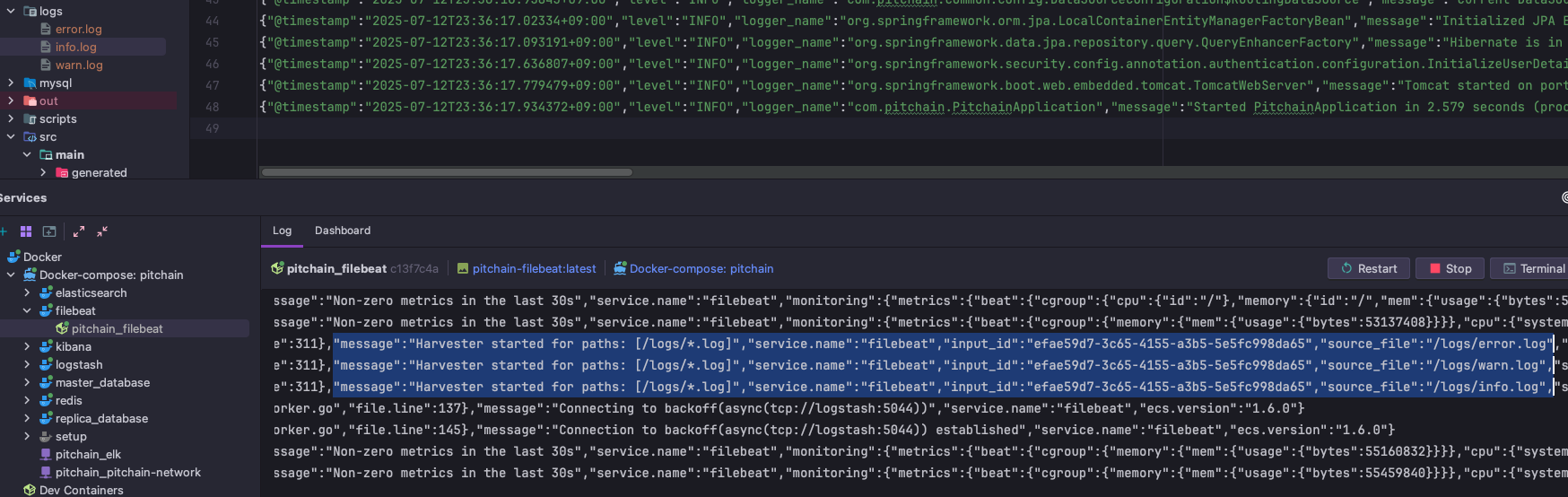
앞서 작성한 docker-compose를 통해 로깅 파이프라인 서비스들과 애플리케이션을 실행해보면 다음과 같이 /logs/*.log에 로그들이 작성되고, Filebeat에는 각 파일에 대한 Harvester가 생성됨을 확인할 수 있다.
이제 Kibana를 통해 로그를 확인해보기 위해 localhost:5601로 접근하면 로그인 창이 뜬다.
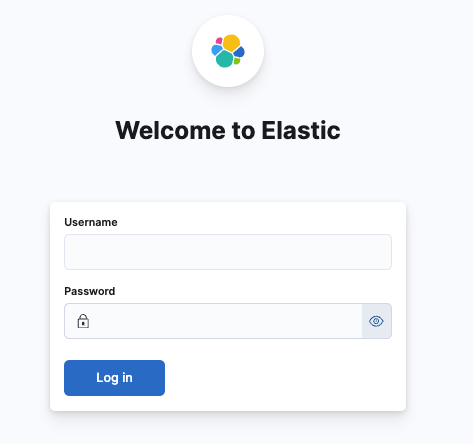
여기에는 kibana_system 유저가 아닌 elastic에 접근할 수 있는 유저로 로그인 해야 한다. kibana_system은 ES-Kibana가 통신하기 위해 권한이 부여된 유저이지 kibana의 접근 권한, es의 인덱스 접근 권한이 설정된 유저가 아니다.
나는 대시보드 확인 목적의 유저를 따로 만들지 않았기 때문에, elastic 루트 계정으로 로그인하여 확인하였다.
로그인 후 인덱스를 시각화하기 위해 Discover 항목에 들어가면 다음과 같이 현재 저장된 인덱스들과, pattern을 통해 조회하고 싶은 인덱스들을 지정해줄 수 있다.
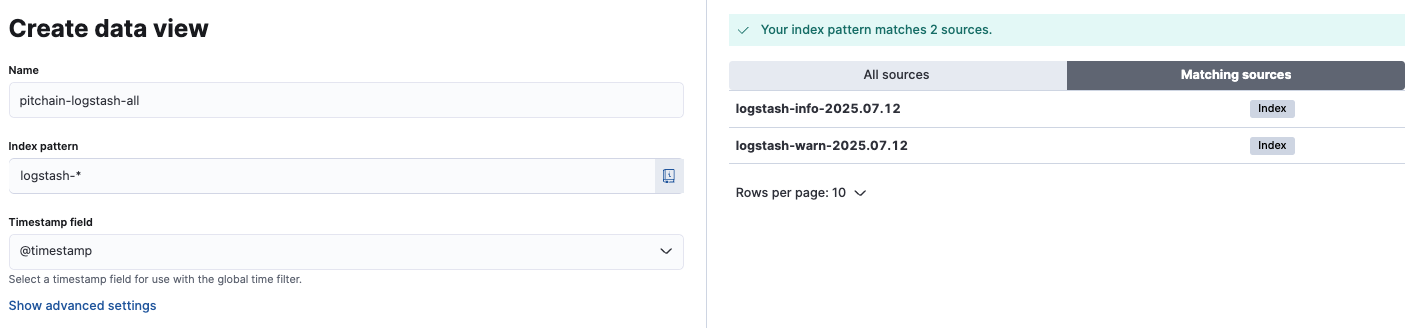
우측에는 logstash.conf에 설정한 filter와 ouput 형식으로 인덱스가 생성된 것이다.
해당 인덱스 패턴으로 데이터를 조회하면 프로젝트 로드 시점의 로그들과 테스트용 info.log를 확인해볼 수 있다.
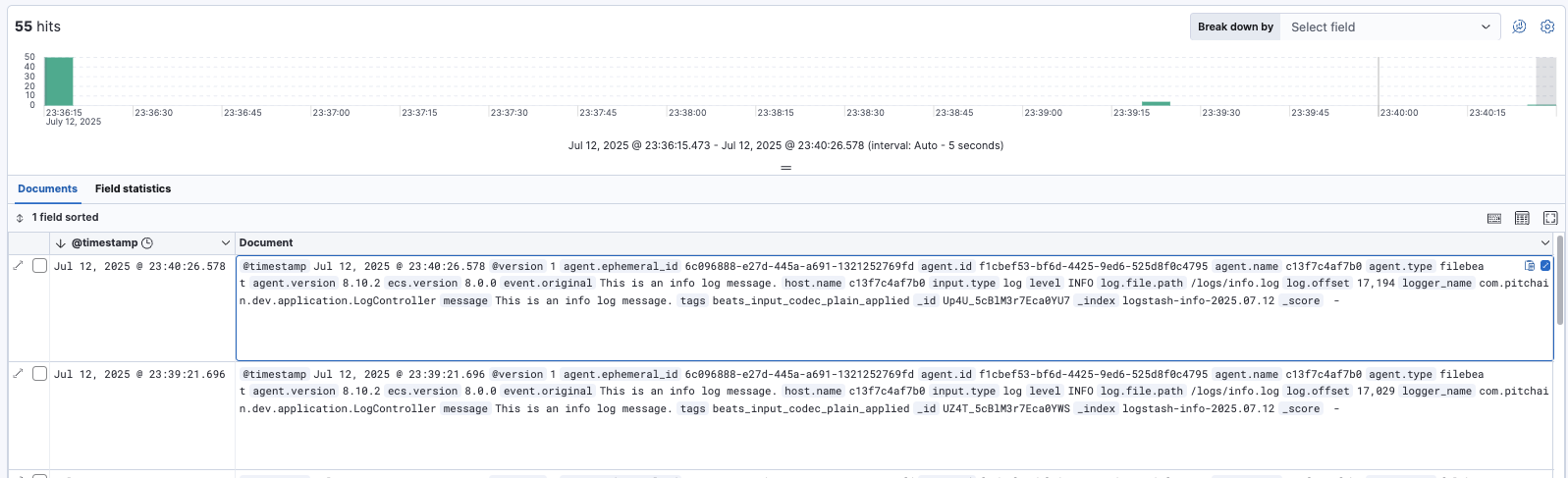
추가로 테스트용으로 서비스 계층에서 에러를 반환하는 API와 요청 처리와 1분이 초과하는 API를 구현하여 실행해보았다.