No-Offest(Cursor) 방식의 무한스크롤 구현
개요
진행하고 있던 프로젝트에서 채팅을 도입하게 되었고, 채팅 메시지는 상당히 데이터 양이 많기 때문에 한 번에 가져오기에는 시간이 오래 걸릴 것으로 예상되었다.
따라서 무한 스크롤 방식을 적용하기로 했고, no-offset(cursor) 방식을 도입하기로 하였다
No-Offset + Cursor 방식은 왜 빠른가?
먼저 offset + limit 방식을 살펴보자
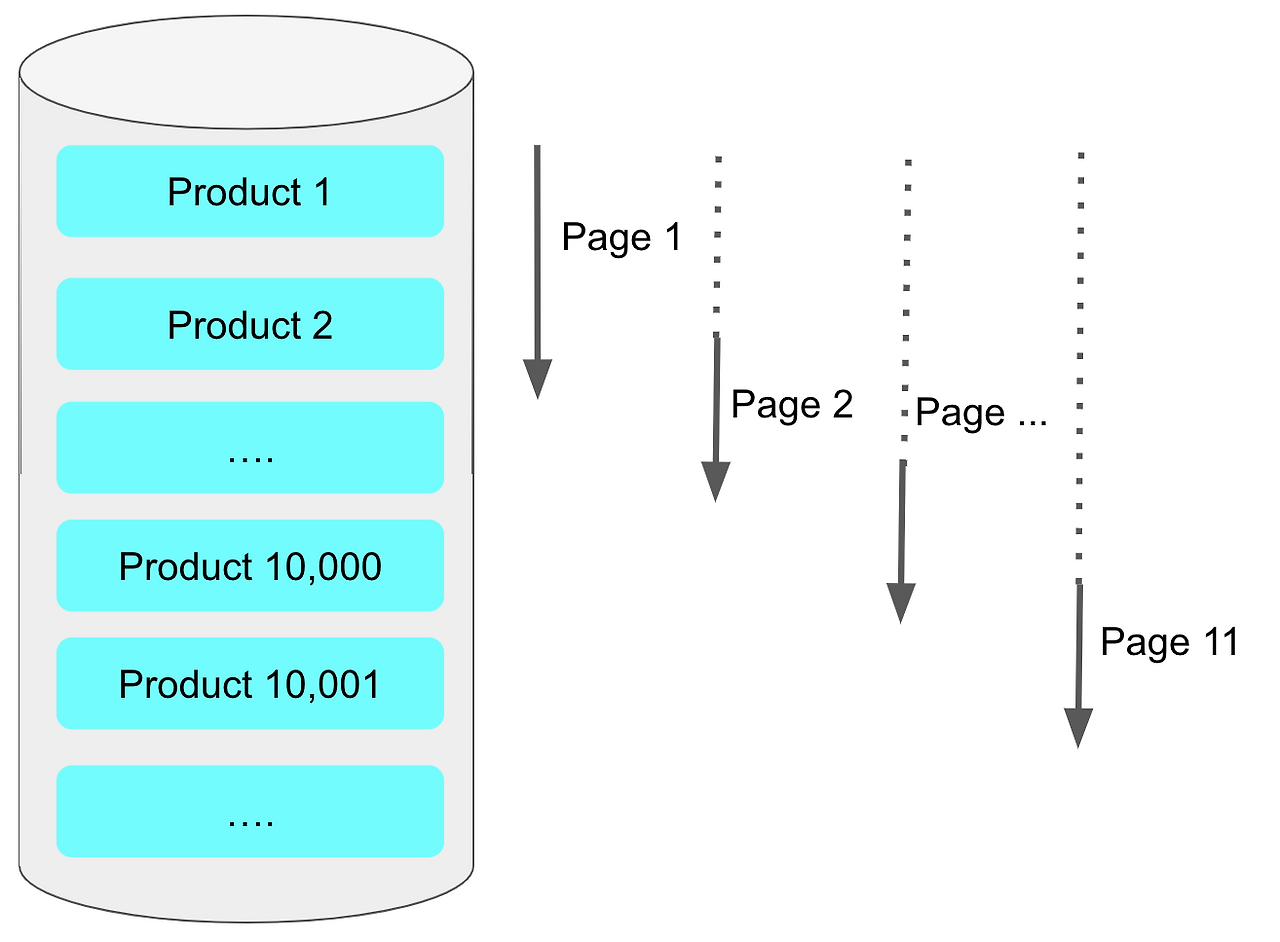
만약 offset = 10,000 이고 limit = 20으로 조회를 한다면 원하는 데이터 Product = 10,001 ~10,020을 조회하기 위해 불필요한 Product = 1 ~ 10,000을 모두 읽어야 한다. 즉, 20개의 데이터를 조회하기 위해 10,020개의 데이터를 조회해야 하는 비효율적인 상황이다.
만약 조회 시작 지점인 10,000 부터 조회하게 된다면, 필요한 데이터 20개만 빠르게 가져올 수 있을 것이다.
이 방식이 no-offset(cursor) 방식이다
조회 시작 지점을 바로 찾기 위해선 조건절에서 pk를 비교하면 된다. 다음 쿼리 pk인 id를 조건절에서 비교하여 '인덱스 레인지 스캔'을 통해 p.id가 10,000 지점을 바로 찾게된다. 즉, 불필요한 이전 데이터들을 건너뛰고 내가 원하는 20개의 데이터만 조회할 수 있게 된다.
SELECT *
FROM Product p
Where p.id > 10,000
ORDER BY p.id
LIMIT 20테스트 환경 세팅
테스트를 진행하기 위해 100,000 개의 채팅 메시지를 저장해두었다
private void saveChatMessages(StudyChatRoom studyChatRoom, Long userId, int dataSize) {
String sql = "INSERT INTO study_chat_messages (message, study_chat_room_id, user_id) VALUES (?, ?, ?)";
List<Object[]> batchArgs = new ArrayList<>();
for (int i = 0; i < dataSize; i++) {
String message = "message " + i;
Long studyChatRoomId = studyChatRoom.getId();
batchArgs.add(new Object[]{message, studyChatRoomId, userId});
}
jdbcTemplate.batchUpdate(sql, batchArgs);
}성능 테스트
Offset+Limit 성능 측정
위 사진 설명과는 다르게 이 프로젝트에서는 채팅을 최신순(id기준 내림차순)으로 조회하고 있다.
먼저 offset + limit 방식의 비효율적인 조회를 테스트 해보기 위해 offset = 0, size=100인 조회와 offset=99000, size=100 조회를 테스트해보았다
// Repository
@Query("SELECT m FROM StudyChatMessage m " +
"WHERE m.studyChatRoom.id = :chatRoomId " +
"ORDER BY m.id DESC " +
"LIMIT :size OFFSET :offset")
List<StudyChatMessage> findByChatRoomIdOrderByCreatedAtDesc(@Param("chatRoomId") Long chatRoomId, @Param("offset") int offset, @Param("size") int size);
// Test
@Test
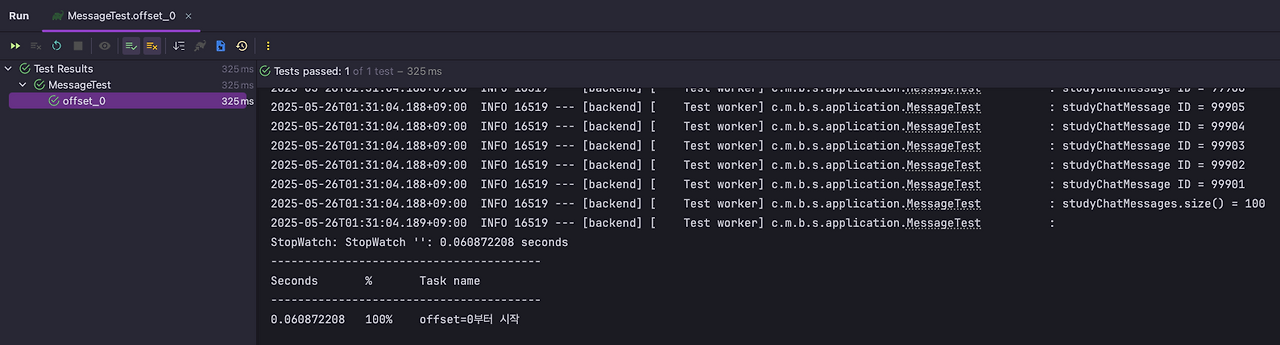
void offset_0() {
stopWatch.start("offset=0부터 시작");
List<StudyChatMessage> studyChatMessages = studyChatMessageRepository.findByChatRoomIdOrderByCreatedAtDesc(
studyChatRoomId, 0, 100);
stopWatch.stop();
for (StudyChatMessage studyChatMessage : studyChatMessages) {
log.info("studyChatMessage ID = {}", studyChatMessage.getId());
}
log.info("studyChatMessages.size() = {}", studyChatMessages.size());
log.info("StopWatch: {}", stopWatch.prettyPrint());
}
@Test
void offset_99_900() {
stopWatch.start("offset=99,000부터 시작");
List<StudyChatMessage> studyChatMessages = studyChatMessageRepository.findByChatRoomIdOrderByCreatedAtDesc(
studyChatRoomId, 99_900, 100);
stopWatch.stop();
for (StudyChatMessage studyChatMessage : studyChatMessages) {
log.info("studyChatMessage ID = {}", studyChatMessage.getId());
}
log.info("studyChatMessages.size() = {}", studyChatMessages.size());
log.info("StopWatch: {}", stopWatch.prettyPrint());
}
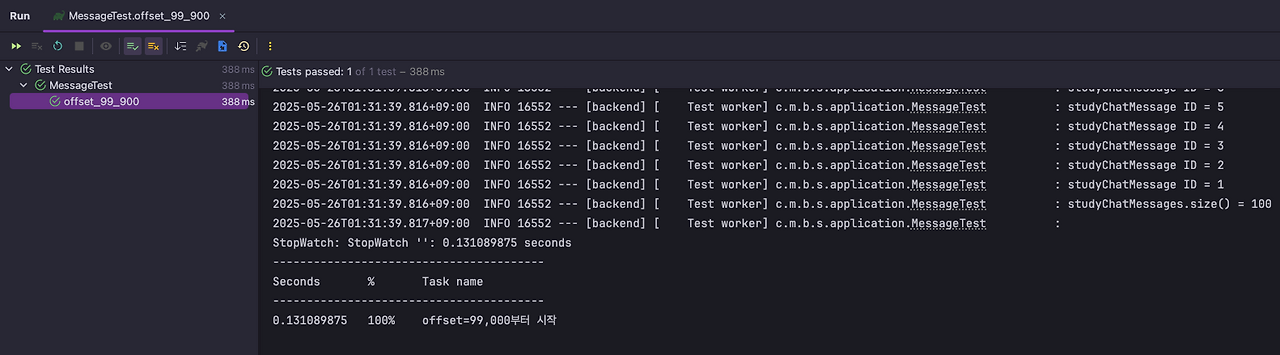
offset이 커지면서 조회 속도가 대략 2배나 차이나는 것을 확인해볼 수 있다. 채팅 메시지가 늘어날수록 성능은 계속 저하될 거라는 것을 짐작해볼 수 있다.
No-Offset + Cursor 도입
// Repository
public List<StudyChatMessage> findAllByChatRoomIdForInfiniteScroll(Long studyChatRoomId, Long lastStudyChatMessageId, Integer size) {
return queryFactory
.selectFrom(studyChatMessage)
.where(
eqStudyChatRoomId(studyChatRoomId),
ltStudyChatMessageId(lastStudyChatMessageId)
)
.orderBy(studyChatMessage.id.desc())
.limit(size + 1)
.fetch();
}
// Test
@Test
void noOffset() {
stopWatch.start("no offset + cursor");
List<StudyChatMessage> studyChatMessages = studyChatMessageRepository.findAllByChatRoomIdForInfiniteScroll(
studyChatRoomId, 101L, 100);
stopWatch.stop();
for (StudyChatMessage studyChatMessage : studyChatMessages) {
log.info("studyChatMessage ID = {}", studyChatMessage.getId());
}
log.info("studyChatMessages.size() = {}", studyChatMessages.size());
log.info("StopWatch: {}", stopWatch.prettyPrint());
}offset을 활용하지 않기 때문에 studyChatMessage = 1~100까지 조회하기 위해 WHERE studyChatMessage < 101을 지정하여 offset = 99,000과 같은 데이터를 조회하도록 만들었다
결과는 offset = 99,000인 조회임에도 불구하고 offset + limit 방식에서 offset=0인 조회와 거의 유사한 시간임을 확인해볼 수 있다.
결과
테스트 데이터 100,000 건에 대해, no-offset(cursor) 방식의 무한스크롤을 적용 결과 99,900개의 데이터 조회를 생략하여 성능 향상을 얻을 수 있었다
