스택(Stack) 이란
사전적 의미로는 '쌓다', '더미'라는 뜻이 있습니다. 스택을 흔히 후입선출(선출후입), LIFO 라고 부르는데 쉽게 설명하자면 아래가 막힌 어떤 물체를 생각하시면 됩니다. 쓰레기통, 마트용 음료수 진열대 등 이러한 것이 스택 구조 입니다. 즉 한 쪽 끝에서만 자료(데이터)를 넣고 뺄 수 있는 형식의 자료 구조 입니다. 스택을 실제 개발환경에서 사용 하는 경우는 인터넷 브라우저의 '뒤로가기', '앞으로가기' 버튼을 생각 하시면 됩니다. 따라서 Stack은 데이터를 쌓는 형식으로 저장하는데 따라서 조회, 추가, 삭제 모두 가장 위에 있는 즉 가장 최근의 값에서 이루어 진다. 스택 구조에서 가장 상단에 있는 데이터를 Top이라고 한다.
Java의 스택(Stack) 클래스
자바에서는 Stack 클래스를 따로 지원해주지만 우리는 직접 구현해보는 것을 목표로 할 것이다. 일단은 자바의 Stack 클래스의 함수 부터 살펴 보자.
기본적으로 Stack은
Stack<Element> stack = new Stack<>();과 같이 생성 할 수 있다.
Stack 클래스는 기본적으로
public Element push(Element item); // 데이터 추가
public Element pop(); // 최근에 추가된(Top) 데이터 삭제
public Element peek(); // 최근에 추가된(Top) 데이터 조회
public boolean empty(); // stack의 값이 비었는지 확인, 비었으면 true, 아니면 false
public int seach(Object o); // 인자값으로 받은 데이터의 위치 반환, 그림으로 설명하겠음이 5가지의 함수를 지원해준다. 지금 부터 예제를 통해 하나 하나 살펴 보겠다.
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < 5; i++) {
stack.push(i + 1);
System.out.println(stack.peek());
} // 1, 2, 3, 4, 5 가 현재 들어가 있음
stack.pop(); // 1, 2, 3, 4
System.out.println(stack.peek()); // 4
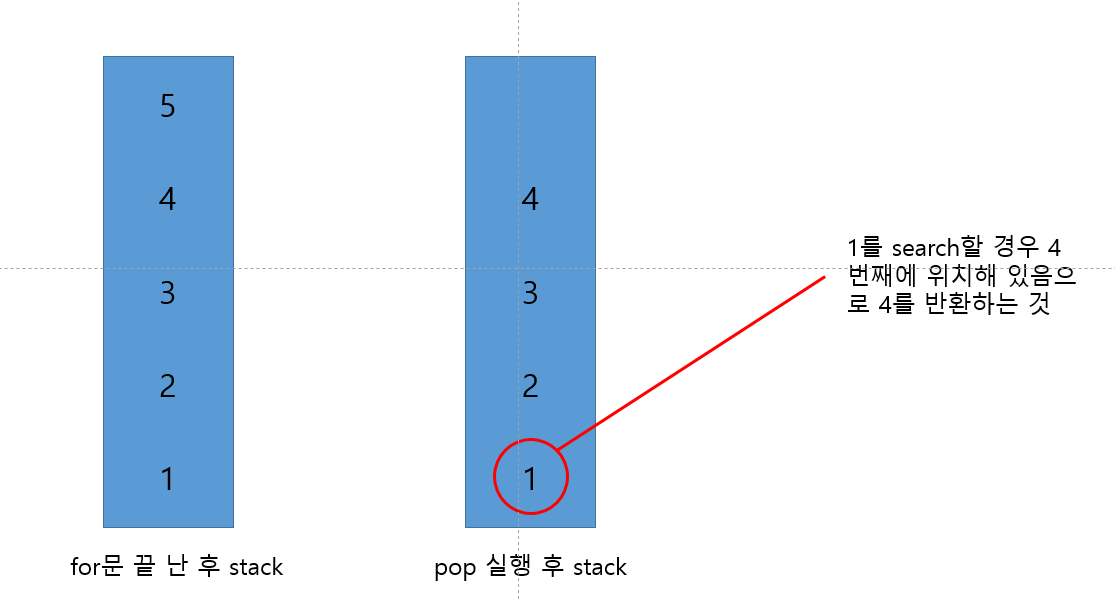
System.out.println(stack.search(1)); // 4
System.out.println(stack.empty()); // false위의 함수 들 중 search의 동작 방식이 궁금할 것이다. search는 인덱스를 반환 하는 것이 아니라 순번을 반환 하는 것이다. 즉 search의 인자 값으로 받은 값이 스택구조에서 몇번째에 있는지를 반환하는 것이다. 다음 그림을 보면 search의 동작이 이해가 갈 것이다.
사용자 정의 stack 구현
우리가 구현해야하는 것은 Top과 push, pop, peek 이다. search와 empty는 자바에서 지원해주는 것이고(다른 언어는 안해봐서 모르겠습니다.ㅠㅠ) 기본적으로는 저 3가지 요소는 필수이기에 search와 empty는 구현하지 않아도 되지만 그래도 직접 구현해 보겠습니다. 그리고 Stack을 구현할 때 배열로 만드는 방법과 LinkedList로 만드는 방법이 있습니다. 이 두가지의 장단점은 각각 분명하니 만드면서 생각해 보시길 바랍니다. (궁금하신분은 제일 아래로 ㅎㅎ)
배열로 Stack 구현
public class UserArrayStack {
int top;
int [] stack;
int size;
public UserArrayStack(int size) {
this.size = size; //
stack = new int[size];
top = -1; // top 의 값 초기화
}
private void push(int item) {
stack[++top] = item;
System.out.println(stack[top] + " push!");
}
private void peek() {
System.out.println(stack[top] + " peek!");
}
private void pop() {
System.out.println(stack[top] + " pop!");
stack[top--] = 0;
}
private int search(int item) {
for (int i = 0; i <= top; i++) { // for 문은 top 만큼
if (stack[i] == item)
return (top - i) + 1; // top - 탐색한 배열의 인덱스, 배열 이므로 +1 추가
}
return -1;
}
private boolean empty() {
return size == 0;
}
}아마 배열로 구현하는 것은 쉽게 따라 할 수 있고 또 여러분도 굳이 제 코드나 다른 분들의 코드를 보지 않더라도 따라 할 수 있을 것입니다. 저는 결과 값을 쉽게 보기 위해 pop과 peek을 void로 만들었습니다.
LinkedList로 Stack 구현
링크드리스트로 Stack을 구현하는 것은 배열 보다 복잡하나 링크드리스트의 특성과 Stack의 특성을 잘 결합한다면 쉽게 할 수 있을 것입니다. 링크드리스트로 스택을 구현하기 위해서는 우선 Node를 먼저 만들어줘야합니다. LinkedList(연결 리스트)를 간략하게 설명하자면 연결 리스트는 Node(노드)로 구성되어 있으며 노드는 데이터와 다음 노드를 가르키는 주소로 구성되어 있습니다.
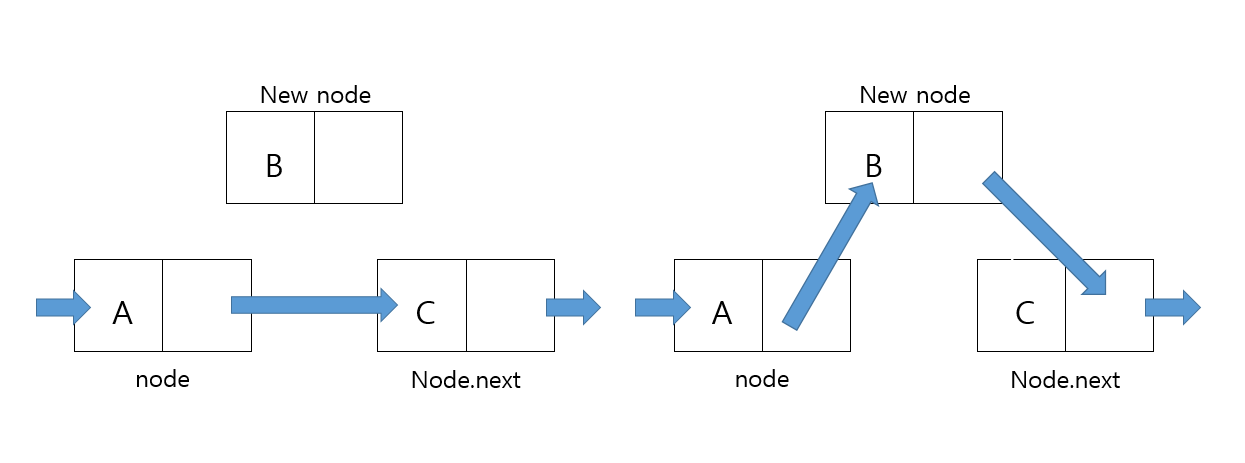
자세한 설명은 제가 따로 포스팅 하겠습니다.
public class Node {
private int data;
private Node nextNode;
public Node(int data) {
this.data = data;
this.nextNode = null;
}
protected void linkNode(Node node) {
this.nextNode = node;
}
protected int getData() {
return this.data;
}
protected Node getNextNode() {
return this.nextNode;
}
}
public class UserLinkedListStack {
Node top;
public UserLinkedListStack() {
this.top = null;
}
private void push(int data) {
Node node = new Node(data);
node.linkNode(top);
top = node;
}
public int peek() {
return top.getData();
}
private void pop() {
if (empty())
throw new ArrayIndexOutOfBoundsException();
else {
top = top.getNextNode();
}
}
private int search(int item) {
Node searchNode = top;
int index = 1;
while(true) {
if (searchNode.getData() == item) {
return index;
} else {
searchNode = searchNode.getNextNode();
index ++;
if (searchNode == null)
break;
}
}
return -1;
}
private boolean empty() {
return top == null;
}
}직접 하면서 느낀거지만 이 둘의 구현의 난이도는 별차이가 없다. 구현 요소?가 배열이냐 연결리스트냐의 차이지 세부적인 내용들은 비슷하기 때문이다. 아무튼 설명을 하자면 제일 처음 push를 할 때 새 노드를 만들어 주고 그후 이전에 있던 노드(top)과 연결을 한다. 그후 새로운 노드가 가장 앞에 있어야 하니 새로운 노드를 Top으로 명시를 한다. pop의 'ArrayIndexOutOfBoundsException()'은 노드가 아무 것도 없을 때의 에러를 막아주는 아이라고 생각하면 된다. pop은 top은 push를 했을 때 새 노드로 재선언 했지만 pop은 지우는 것이므로 top 과 연결된 노드 즉 top 아래의 있는 노드로 top을 재선언 하는 것이다.
배열 구현의 장단점
배열의 장점은 우선 구현이 쉽고 데이터의 접근 속도 즉 조회가 빠르다는 점입니다. 하지만 단점은 항상 최대 개수를 정해놔야지 사용이 가능하다는 점입니다.
즉 구현과 접근은 좋지만 다른 프로젝트에서 활용할 때는 여러모로 불편합니다.
링크드 리스트 구현의 장단점
반대로 연결리스트로 구현했을 때의 장점은 데이터의 최대 개수가 한정되어 있지 않고 삽입 삭제가 용이 하다는 것입니다. 하지만 반대로 배열과 달리 데이터의 조회가 힘든다는 점입니다. 배열과 달리 노드를 따라따라 가서 조회를 해야지 데이터를 찾을 수 있기 때문입니다.

6개의 댓글


Stack의 특성상 마지막 데이터를 쉽게 빼낼 수 있어 마지막 기록, 최근 기록등등을 저장할 경우만 사용합니다.
또한 조회에 강점을 가지는 자료구조들이 많기 때문에 데이터 조회가 일어날경우 stack사용을 회피합니다.
이러한 특성때문에 stack구현시 데이터조회가 느린 연결리스트의 단점은 실질적으로 단점이 아니게됩니다.
결국 링크드스택의 단점은 사실상 없게되며 위에서 말씀하신대로 유동적인 공간할당 + 메모리할당시 불리한 배열(메모리 사용률이 높을수록 배열의 메모리 할당이 힘들어집니다 -> 배열은 연속된 주소값을 가지는 메모리를 할당함)이므로 링크드스택으로 구현하는 것을 선호합니다! 참고하시면 좋을 것 같아요~
잘봤습니다! 혹시 소스코드 저런식으로 어떻게 이쁘게 넣으셨나요?