목표
-
MySQL(8.0) InnoDB의 Lock 모드에 따른 Auto Increment 동작 방식을 이해한다.
-
할당된 Auto Increment 값이 rollback 되었을 때, 다음 값이 어떻게 세팅되는지 알아본다.
🔅 InnoDB AUTO_INCREMENT Lock Modes
InnoDB 는 데이터의 정합성을 지키면서 동시성을 향상하는 방향으로 발전해 왔습니다. AUTO_INCREMENT 잠금 방식에서도 이를 알 수 있는데요. 하나씩 살펴보겠습니다. AUTO_INCREMENT 잠금 모드에는 0, 1, 2 세 가지가 있으며, 8.4 버전 이상에서는 ‘2’가 기본값입니다.
🔹 innodb_autoinc_lock_mode = 0 (전통적인 잠금 모드)
이 모드에서는 트랜잭션의 INSERT 문의 실행이 완료될 때까지 테이블 수준의 lock이 걸립니다. 동시에 두 개의 트랜잭션에서 Insert 요청을 할 경우, 먼저 insert 문이 실행된 트랜잭션에서 insert가 끝날 때까지 다른 트랜잭션은 대기하게 됩니다.
테이블을 생성하고, 각각 트랜잭션을 시작한 후 insert 문을 실행해 보겠습니다. lock을 점유하고 있는 상태를 관찰하기 위해 하나의 트랜잭션에서는 대량의 데이터를 insert 했습니다.
CREATE TABLE study.t1 (
c1 INT(11) NOT NULL AUTO_INCREMENT,
c2 VARCHAR(10) DEFAULT NULL,
PRIMARY KEY (c1)
) ENGINE=InnoDB;- 트랜잭션 T1
begin;
INSERT INTO study.t1 (c2)
SELECT REPEAT('test',2)
FROM information_schema.tables, information_schema.tables t2, information_schema.tables t3;
commit;- 트랜잭션 T2
begin;
INSERT INTO study.t1 (c2)
VALUES ('z');
commit;T1에서 insert 문을 실행한 후, T2 insert 문을 실행했습니다. T2의 데이터는 T1의 insert가 모두 완료된 후에 시작된 것을 알 수 있습니다.
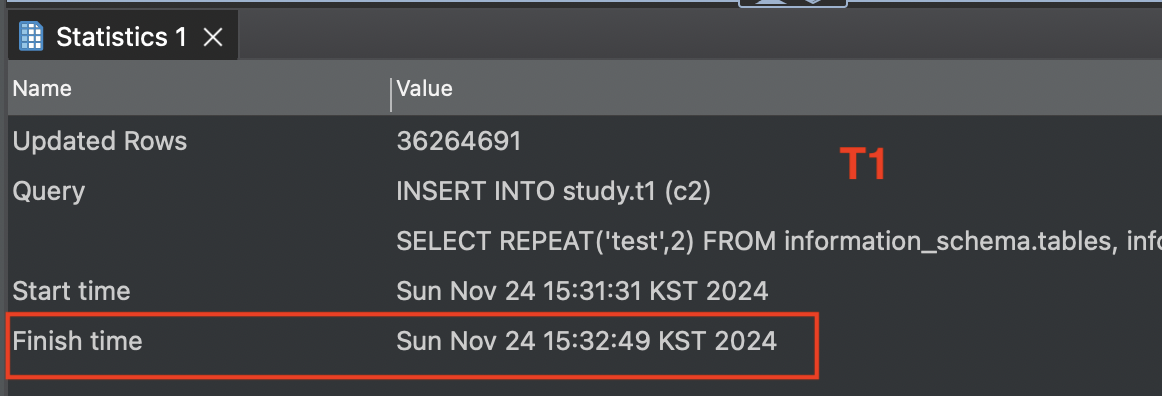
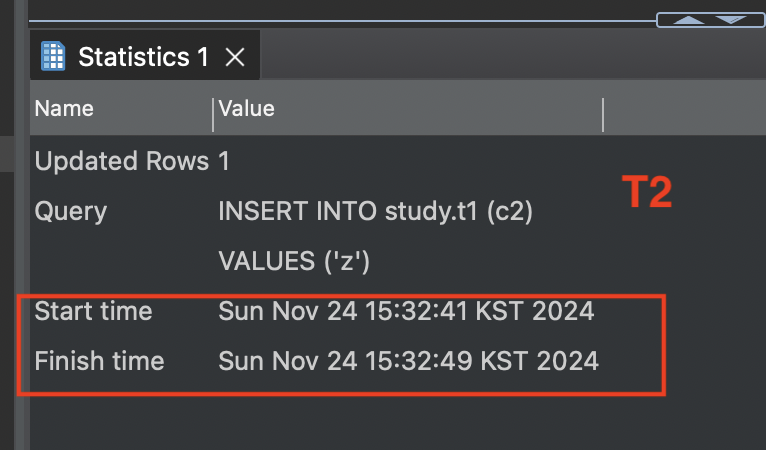
또한 T1에서 insert 문이 실행되고 있을 때, t1 테이블에 배타락과 테이블 수준의 AUTO_INCREMENT 락이 걸린 것도 확인할 수 있었습니다.
SELECT * FROM performance_schema.data_locks WHERE LOCK_TYPE = 'TABLE';
해당 잠금 방식은 AUTO_INCREMNT의 연속성과 일관성을 보장합니다. statement 기반의 binary log로 replication에 데이터를 복제했을 때도 원본과 동일한 값을 가질 수 있습니다. 하지만 테이블에 잠금을 거는 만큼 동시성이 떨어지고, 대량의 데이터를 insert 할 때 병목 현상이 발생합니다.
테스트를 진행할 때도 T2 트랜잭션에서 잠금 대기 타임아웃이 한 번 발생했습니다.
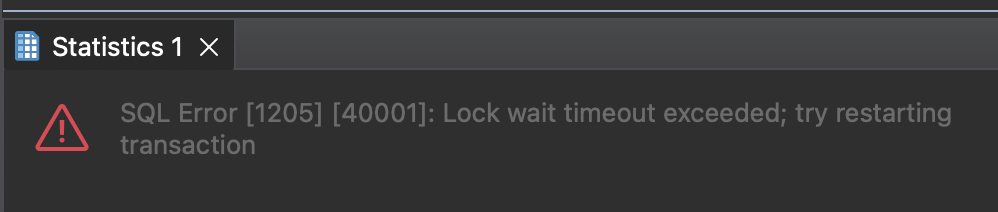
🔹 innodb_autoinc_lock_mode = 1 (“consecutive” lock mode)
해당 모드는 데이터가 연속적으로 삽입되는 것을 보장하면서도 모드 0에 비해 동시 처리 성능을 높였습니다. bulk-insert 동작 시에는 AUTO_INCREMENT 잠금이 걸리지만 삽입될 행의 수를 알고 있는 simple-insert 문에서는 뮤텍스를 사용하여 테이블 수준의 락을 방지합니다.
MySQL에서 뮤텍스는 AUTO_INCREMENT 값을 할당하는 과정에서 글로벌 카운터(Global Counter)를 보호하기 위해 사용됩니다. AUTO_INCREMENT 카운터 업데이트 시에만 이 값에만 잠깐 락을 걸기 때문에 동시 처리 성능을 높일 수 있습니다.
🔅 simple-insert example
INSERT INTO TABLE VALUES (1,'A'), (2,'B'), (3,'C');
🔹 innodb_autoinc_lock_mode = 2 (“interleaved” lock mode)
인터리빙 모드로 AUTO_INCREMENT 테이블 락을 사용하지 않습니다. 각각의 트랜잭션 동작이 병렬로 처리되고, insert 되는 row마다 auto increment 값이 동적으로 할당됩니다. 위와 동일한 방식으로 T1에서 대량의 데이터를 삽입하는 insert 문을 먼저 실행하고 T2에서 1개의 데이터를 삽입하는 쿼리를 실행해 보겠습니다.
- T1
begin;
INSERT INTO study.t1 (c2)
SELECT REPEAT('test',2)
FROM information_schema.tables, information_schema.tables t2, information_schema.tables t3;
commit;- T2
begin;
INSERT INTO study.t1 (c2)
VALUES ('z');
commit;우선 T1 트랜잭션에서 대량 삽입 중에 LOCK 현황을 살펴보면 AUTO_INCREMENT 락이 걸리지 않은 것을 확인할 수 있습니다.

T1의 삽입이 이뤄지는 중에 T2에서 삽입할 경우, 잠금 대기 없이 바로 처리되는 것과 트랜잭션 T2에서 insert 한 데이터가 트랜잭션 T1에서 삽입한 테이터들 중간에 끼어있는 것을 알 수 있습니다.
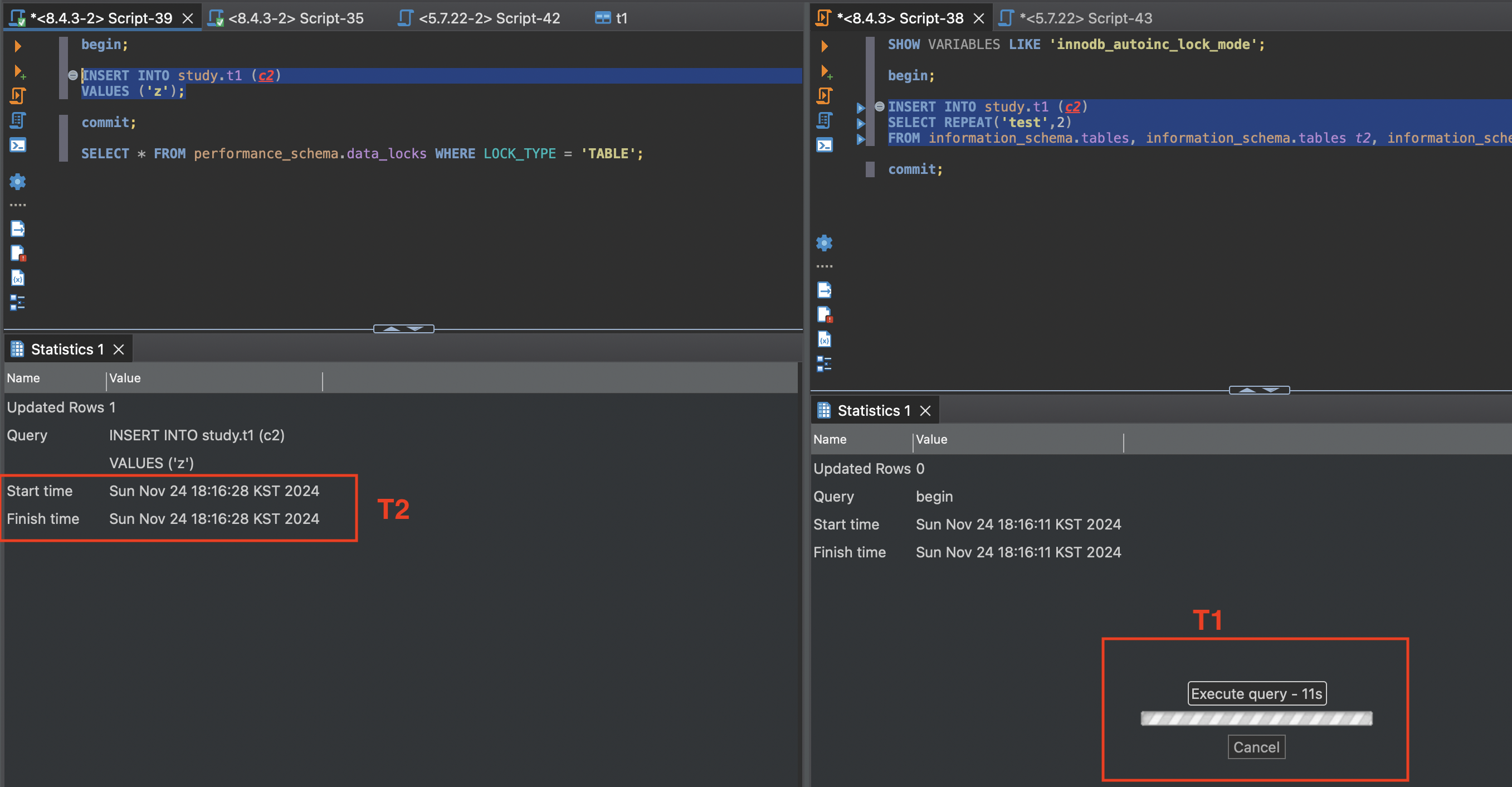
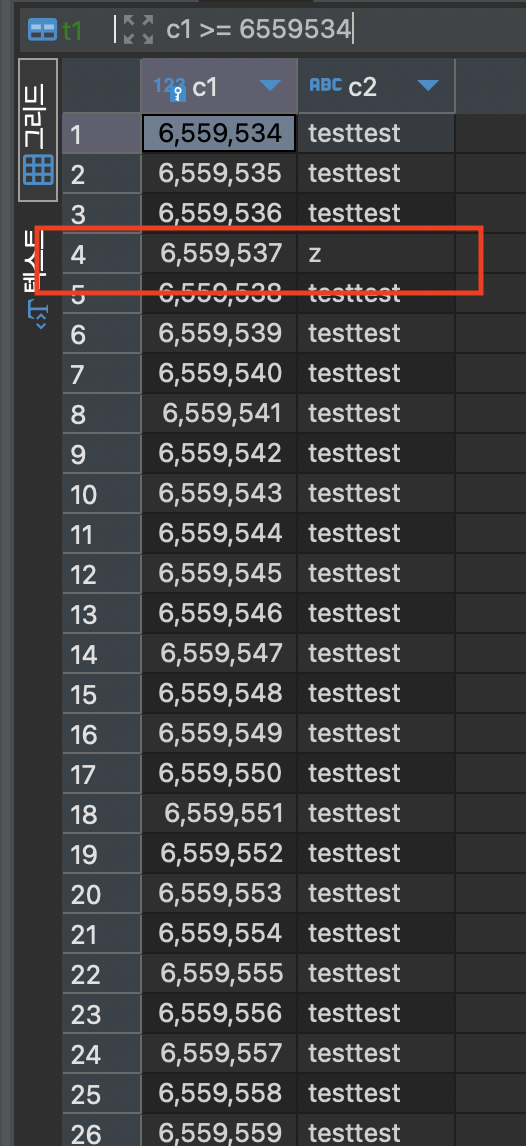
모드 2는 높은 동시 처리 성능을 보이지만 데이터 복제 시에는 유의해야 합니다. 데이터가 불연속적일 수 있기 때문에 “문장 기반 복제(Statement-based replication)” 방식으로 복제가 이뤄질 경우 원본과 복제본의 auto_increment 컬럼값이 다를 수 있습니다. MySQL 5.7버전부터는 “행 기반 복제(row-based replication)” 방식을 기본값으로 합니다.
🔅 한 번 증가한 AUTO_INCREMENT 값은 줄어들지 않는다.
한 트랜잭션에서 insert 문이 실행된 후 rollback 되면 이미 사용했던 auto_increment 값은 재사용 되지 않고, 이후 번호부터 사용됩니다. 이는 AUTO_INCREMENT 테이블 락을 최소화하기 위함인데요. innodb_autoinc_lock_mode = 0에서도 트랜잭션이 종료될 때까지가 아닌 insert 문의 실행이 완료될 때까지만 auto_increment 락이 유지됩니다. 만약 rollback 시에 auto_increment 값을 되돌려야 한다면, auto_increment 락은 트랜잭션이 종료될 때까지 유지돼야 할 것입니다.
8.0 이전 버전에서는 서버를 종료했다가 재시작할 경우, 이전에 rolback 되어 버려진 auto_increment 가 다시 사용될 수도 있습니다. 이는 auto_increment counter 값을 저장하는 위치가 다르기 때문입니다. 8.0 이전 버전에서는 auto_increment counter 값을 메모리에 저장하기 때문에, 서버가 종료될 경우 이 값이 유실됩니다. 서버 재시작 시에 테이블의 데이터 상태를 기반으로 auto_increment counter 값을 다시 계산합니다.
🔹 5.7.22 버전
하나씩 테스트해 보겠습니다. 먼저 5.7.22 버전입니다. 4개의 데이터를 삽입한 후 commit하고, 다시 4개의 데이터를 삽입한 후 rollback 하였습니다. auto_increment 값이 9인 것을 확인할 수 있습니다.
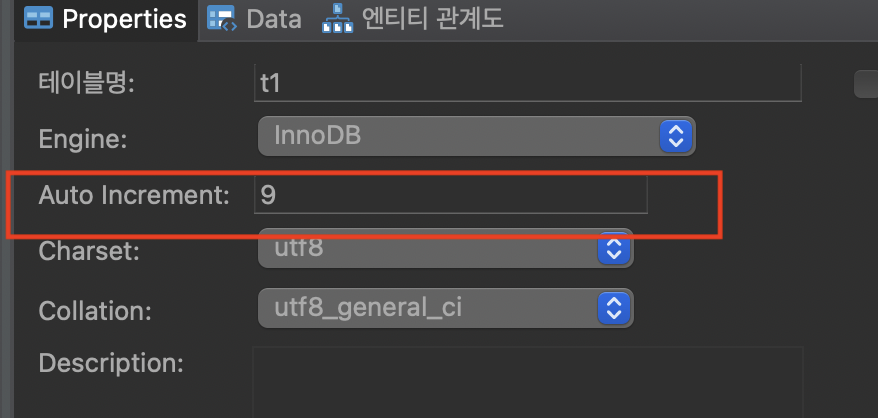
서버 종료 후 재시작 후에 t1 테이블을 확인해 보면 auto_increment가 5인 것을 알 수 있습니다. 해당 테이블에 저장된 데이터의 c1 max 값이 4이기 때문입니다.
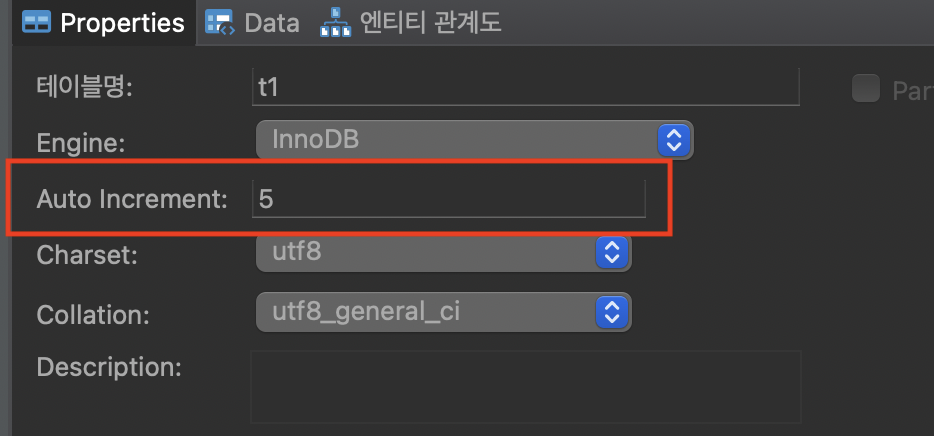
만약 c1의 max 값이 6이라면 어떨까요? 서버 종료 및 재시작해 보면 예상대로 7인 것을 알 수 있습니다.
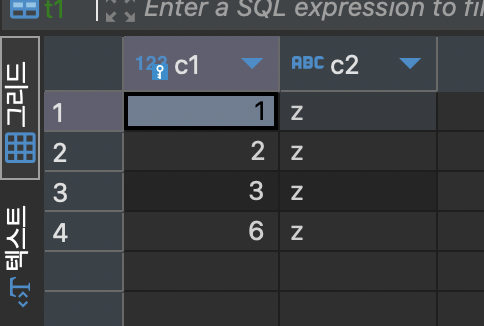
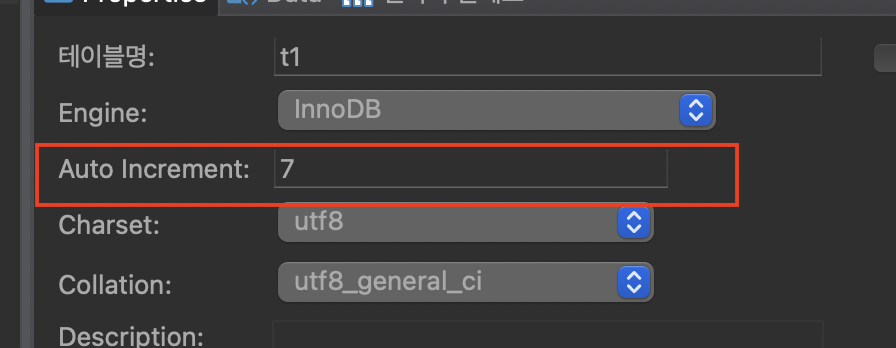
🔹 8.4.3 버전
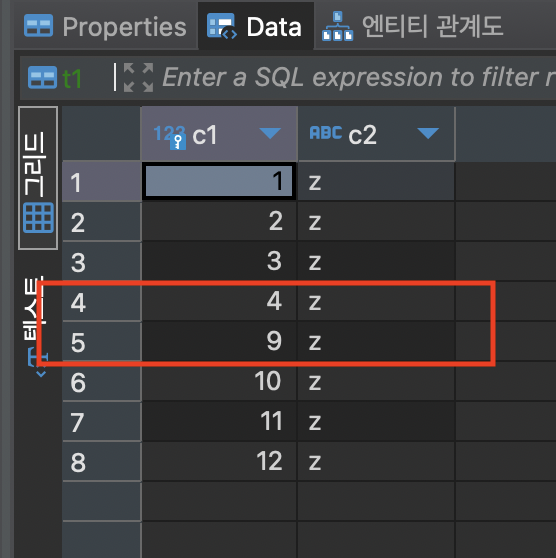
5.7.22 버전과 동일하게 4개 삽입 → commit → 4개 삽입 → rollback 순서로 실행하였습니다. 8.0 이상의 버전에서는 서버 종료 후 재시작했을 때에도 auto_increment 값이 유지되었습니다. 8.0 이상에서는 auto_increment counter 값을 메모리가 아닌 리두 로그(Redo log)에 저장하여 관리하기 때문에 서버가 재시작되어도 유지되는 것입니다. auto_increment counter가 관리되는 방식이 개선되어 counter 값의 유실로 인한 데이터의 무결성이 깨지는 상황을 방지할 수 있게 되었습니다.
🔅 REDO LOG
리두 로그(redo log)는 오라클 RDBMS 환경에서 데이터베이스에 생긴 변경 이력을 기록해놓은 파일들이다. 만약 데이터베이스가 깨어질 경우, 리두 로그에 남겨진 기록을 이용하여 원래 상태로 복구할 수 있다. (위키백과)
참고
📎 https://dev.mysql.com/doc/refman/8.4/en/innodb-auto-increment-handling.html
