데이터 모델과 성능 (1) 정규화와 반정규화
1. 성능 데이터 모델링의 개요
1) 성능 데이터 모델링의 정의
- 데이터 용량이 커질수록, 기업의 의사결정 속도가 빨라질수록 데이터를 처리하는 속도는 빠르게 처리되어야 할 필요성을 반증해준다.
- 데이터 모델 구조에 의한 성능 저하가 불가피함
- 데이터 대용량화로 인한 불가피한 성능 저하
- 인덱스 특성을 고려하지 않은 생성으로 인한 성능 저하
- 따라서 데이터 모델링을 할 때, 어떤 작업 유형에 다라 성능 향상을 도모해야 하는지 목표를 분명하게 해야 정확한 성능 향상 모델링을 할 수 있음
- 설계단계의 모델링 떄부터 정규화, 반정규화, 테이블 통합, 테이블 분할, 조인구조, PK, FK 등 여러가지 성능과 관련된 사항이 반영 될 수 있도록 해야한다
2) 성능 모델링 수행 시점
- 데이터 증가가 빠를수록 성능 저하에 따른 성능 개선 비용이 기하급수적으로 증가하게 된다
3) 성능 데이터 모델링 고려사항
- 정규화 수행
- 엔터티에 집중되는 부분 찾기
- 트랜젝션 분석하기
- 반정규화 수행
- 이력 모델의 조장, pk/fk 슈퍼/서브 type 조정
- 성능 관점에서 검증
2. 정규화와 성능
0) 정규화란?
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다. (ref. 위키백과)
- 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연셩을 위한 방법이며 데이터를 분해하는 과정
- 불필요한 데이터(data redundancy)를 제거
- 그에 따라 데이터 저장을 "논리적으로" !!!
- 데이터 베이스 재설계를 최소화 (개발도중에)
- 다양한 Query 가 가능하도록 최적 설계 (Join 을 통한)
- 무결성 제약조건을 충족하기 위해서
1) 정규화를 통한 성능 향상 전략
- 조회 vs 입력/수정/삭제 성능은 Trade off 일 가능성이 크다
- 정규화를 수행한다는 것은 결정자를 기준으로 의존자로하여금 입력/수정/삭제 이상을 제거하는 것임
- 데이터 처리속도가 빨라질 수도 있지만, 느려질 수도 있음
2) 함수적 종속성에 근거한 정규화 필요
- 반복데이터를 분리하고, 각 데이터가 종속된 테이블에 정합성에 따라 배치하여 속도향상 기여
3) [번외] 정규화가 필요한 Anomaly(이상) 에 대한 정리
-
삭제이상 (Delete Anomaly)
튜플 삭제시 연쇄 삭제가 발생하는 현상
예를 들어 2101 학번의 홍길동 학생이 ST01 과목을 수강 취소할 경우,
취소 사유를 물을 수 있는 유일한 정보인 연락처마저 잃게 되는것을 의미 -
삽입이상 (Insert Anomaly)
튜플 삽입시 지정하지 않은 속성값이 NULL을 갖거나, 원하지 않는 자료가 삽입되는 현상
예를 들어 2101 학번 홍길동 학생의 연락처만 추가하고 싶을 때,
과목코드가 비게되므로 NULL값을 가져 문제가 발생 -
갱신이상 (Update Anomaly)
데이터 갱신시 일관성 유지가 안되는 현상입니다!
예를 들어 홍길동 학생이 연락처를 바꿨을 경우,
ST01, ST02 모두 갱신해야하는데 ST01만 갱신할 경우 발생하게 됩니다!
위와 같은 Anomaly 발생시 정규화를 검토해야 한다고 생각하면 좋다
4) [번외] 정규화 순서
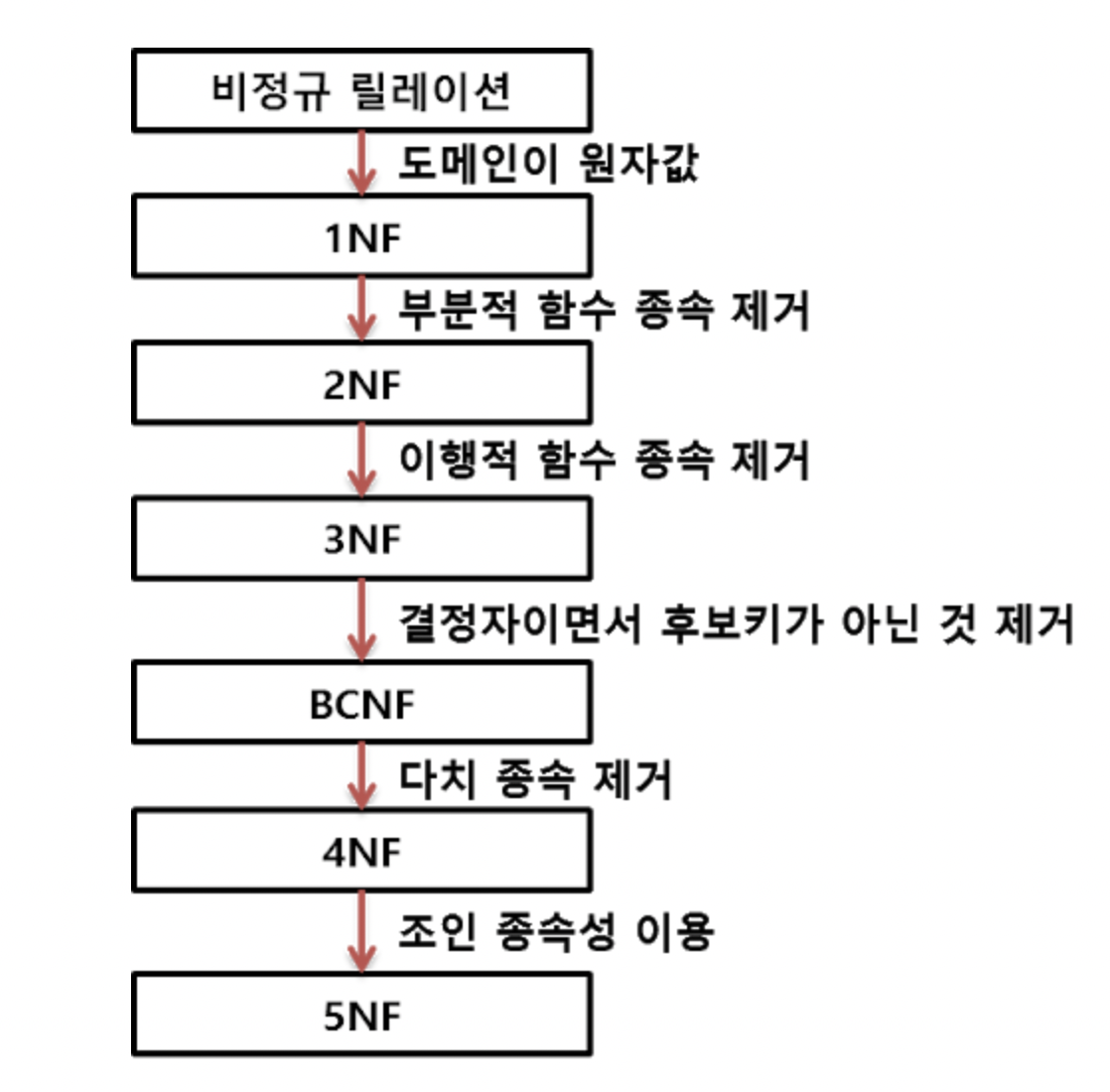
5) 정규화 종류
1. 1NF (부분적 함수 종속 제거)
테이블(Relation)이 1NF를 만족했다는 것은 아래 세 가지 조건를 만족했다는 것을 의미
- 어떤 Relation에 속한 모든 Domain이 원자값(atomic value)만으로 되어 있다.
- 모든 attribute에 반복되는 그룹(repeating group)이 나타나지 않는다.
- 기본 키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.
예제를 통해 살펴보면 아래 테이블(Relation)은 위의 1,2,3번 조건 중 1번 조건를 만족하지 못한 사례
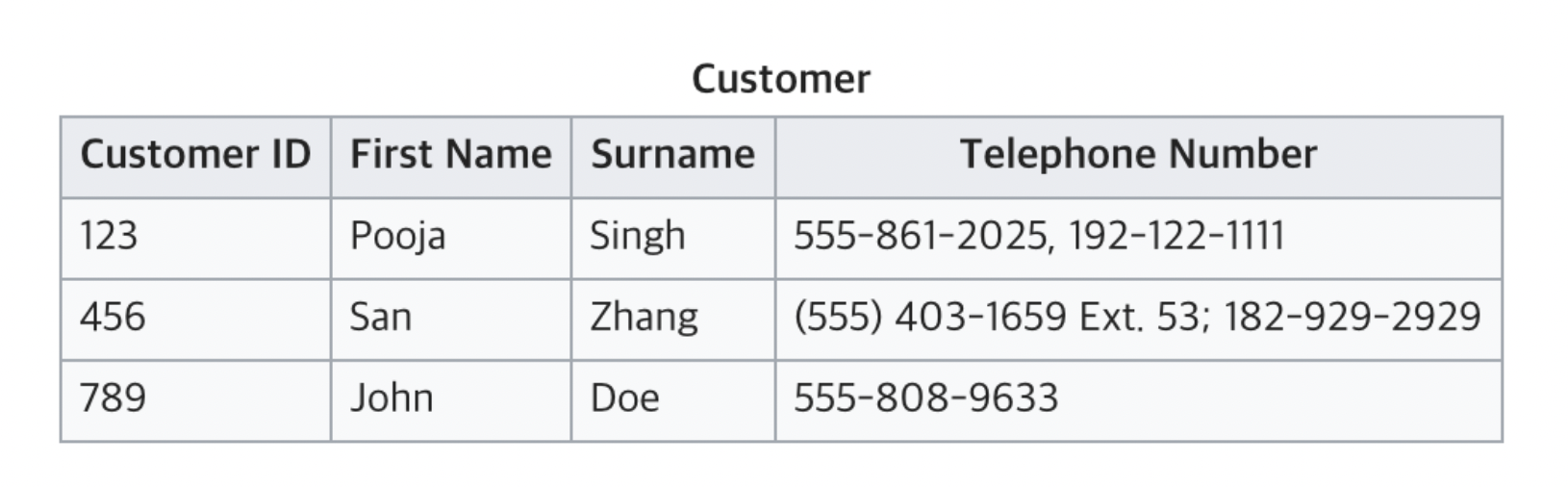
실제로 현업에 투입되면 위와 같은 테이블이 생각보다 자주 만날 수 있어서 종종 놀란다.(IT 기업이 아니라서 그런가..)
2.2NF (부분적함수종속)
2NF를 수행 했을 경우 테이블의 모든 컬럼이 완전 함수적 종속을 만족하게 된다.
(부분 함수적 종속을 모두 제거되었으므로!)
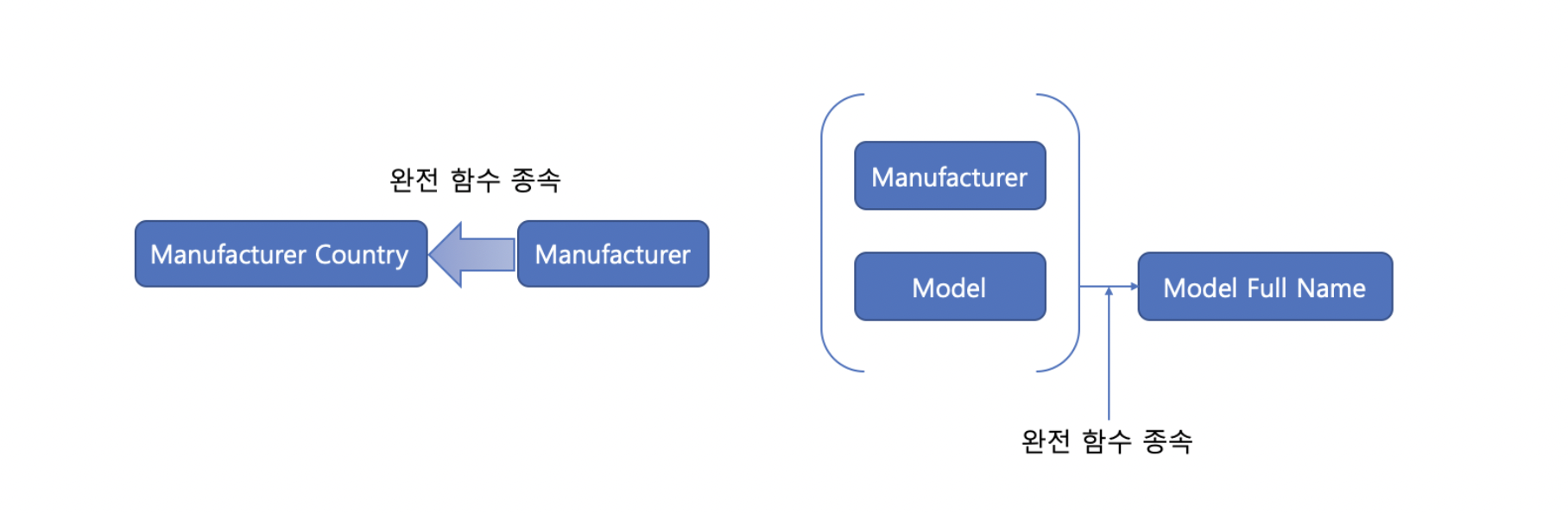
이를 이해하기 위해서는 부분 함수적 종속과 완전 함수적 종속이라는 용어를 알아야 한다.
- 함수적 종속: X의 값에 따라 Y값이 결정될 때 X -> Y로 표현하는데, 이를 Y는 X에 대해 함수적 종속 이라고 합니다. 예를 들어 학번을 알면 이름을 알 수 있는데, 이 경우엔 학번이 X가 되고 이름이 Y가 됩니다. X를 결정자라고 하고, Y는 종속자라고 합니다 다른 말로 X가 바뀌었을 경우 Y가 바뀌어야만 한다는 것을 의미한다.
- 함수적 종속에서 X의 값이 여러 요소일 경우, 즉, {X1, X2} -> Y일 경우, X1와 X2가 Y의 값을 결정할 때 이를 완전 함수적 종속 이라고 하고, X1, X2 중 하나만 Y의 값을 결정할 때 이를 부분 함수적 종속 이라고 합니다.
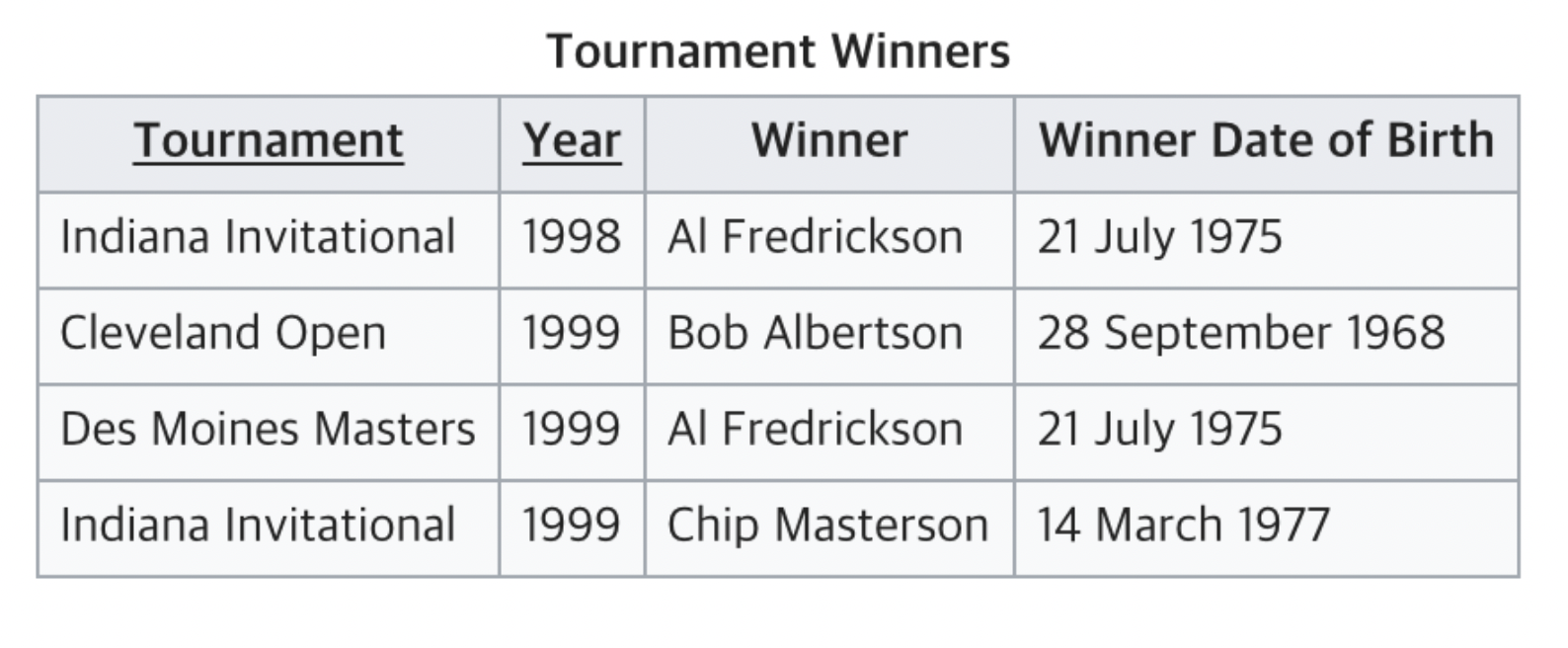
그렇다면 예시를 통해 살펴보도록 하자
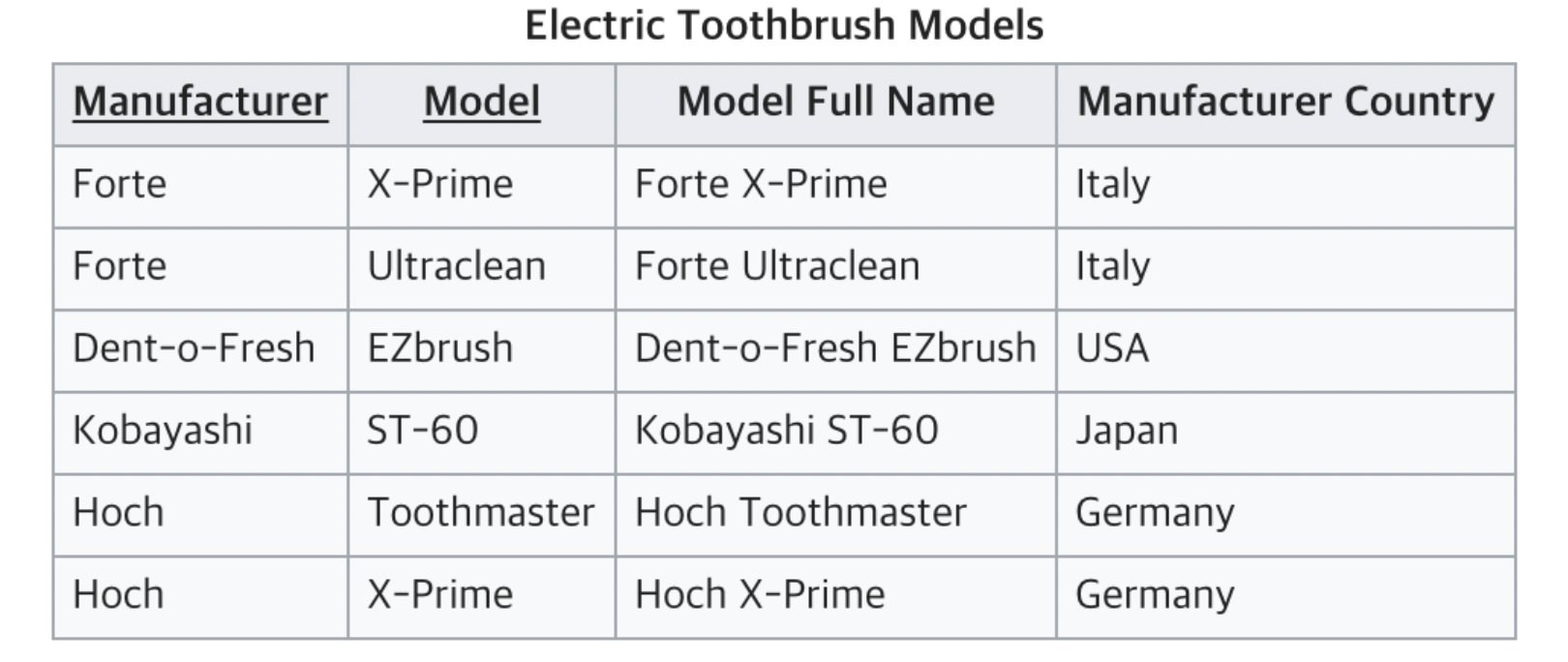
위 테이블의 문제는 아래와 같다.
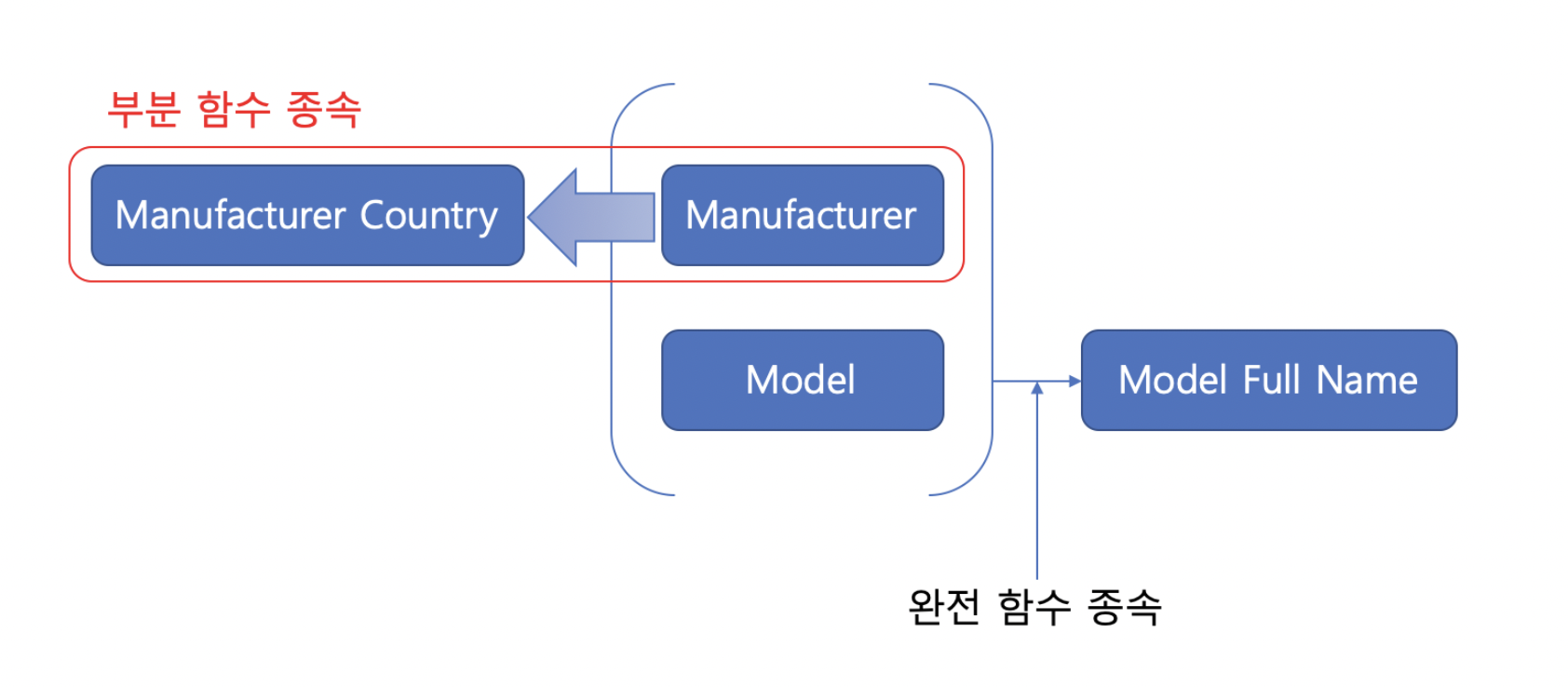
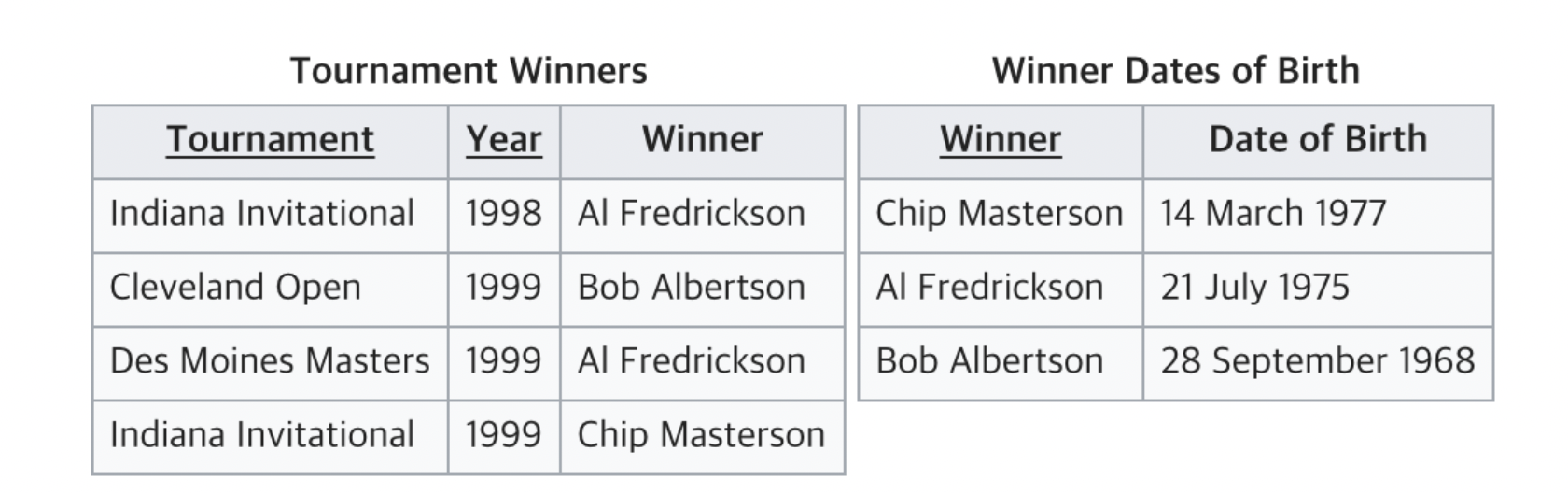
즉 위에서 언급한 함수적 종속이 2개 존재하고, 결국 PK(유일값) 이 2개 이상이 발생할 수 있다고 생각하면 된다. 해결책은 아래와 같다.
위와같이 테이블을 분리시키면 된다.
3. 3NF (이행적 함수종속)
테이블(Relation)이 제 3정규형을 만족한다는 것은 아래 두 가지 조건을 만족하는 것을 의미한다.
- Relation이 제 2정규화 되었다.
- 기본 키(primary key)가 아닌 속성(Attribute)들은 기본 키에만 의존해야 한다.
아래는 두 번째 조건이 위반된 사례이다.
즉, 후보키가 여러개임과 동시에 종속성이 A <- B <- C 와 같이 연달아서 발생시 테이블을 쪼개야 된다는 것이다. 위 예제의 해결책은 아래와 같다.
4. BCNF (Boyce-Codd Normal Form)
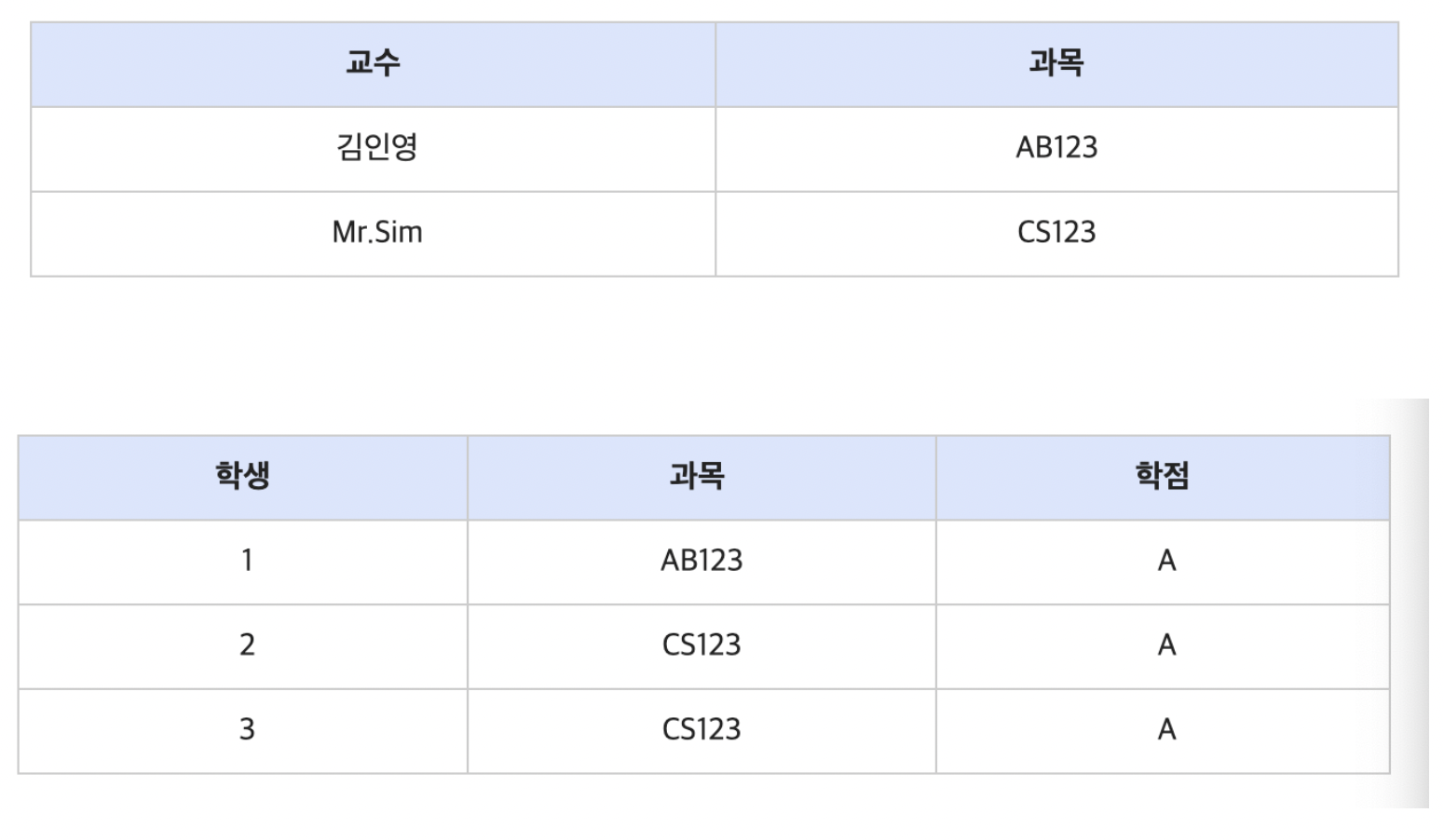
BCNF는 (Boyce and Codd Normal Form) 3차 정규형을 조금 더 강화한 버전으로 볼 수 있다. 이는 3차 정규형으로 해결할 수 없는 이상현상을 해결할 수 있다. BCNF란 3차정규형을 만족하면서 모든 결정자가 후보키 집합에 속한 정규형이다. 아래와 같은 경우를 생각해보면, 후보키는 수퍼키중에서 최소성을 만족하는 건데, 이 경우 (학생, 과목) 이다. (학생, 과목)은 그 로우를 유일하게 구분할 수 있다. 근데 이 테이블의 경우 교수가 결정자 이다. (교수가 한 과목만 강의할 수 있다고 가정) 즉, 교수가 정해지면 과목이 결정된다. 근데 교수는 후보키가 아닙니다. 따라서 이 경우에 BCNF를 만족하지 못한다고 한다.
쉽게 정리하면, 삽입과정에서 중복의 여지가 발생한다는 것이다(3차 정규화를 만족함에도 불구하고)
아래 예제를 보자
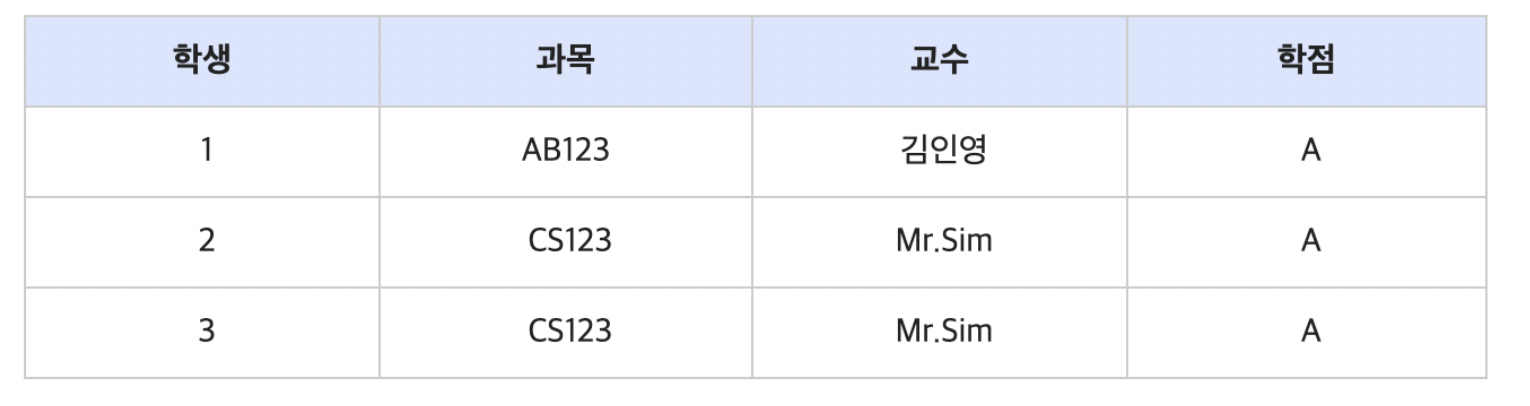
후보키는 수퍼키중에서 최소성을 만족하는 건데, 이 경우 { 학생, 과목 }이 후보키가 된다.
근데 해당 테이블의 경우 교수가 결정자이다.
그 이유는, 교수가 한 과목만 강의할 수 있다고 가정할 때, 교수가 정해지면 과목이 결정되기 때문입니다.
따라서 교수는 수퍼키가 되게 되고, 이 경우에 BCNF를 만족하지 못한다.
이를 해결하기 위해서는 테이블을 분리해야한다.
3. 반정규화 성능
1) 정의
- 정규화된 엔터티, 속성, 관계에 대해 시스템 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법을 말함
- 디스크 I/O 량이 많아서 성능이 저하되거나, 경로가 너무 멀어서 조인으로 인한 성능 저하가 나타는 경우 수행한다
- 업무적으로 조회 성능이 중요할때 주로 사용함
2) 적용 방법
- 반정규화 대상 조사
--- 범위 처리 빈도수 조사
--- 대량의 범위 처리 조사
--- 통계성 프로세스 조사
--- 테이블 조인 개수 조사- 다른 방법검토
--- 뷰 테이블 활용
--- 클러스터링 활용
--- 인덱스 조절
--- 응용 앱개발- 반정규화 적용
--- 테이블 반정규화
--- 속성 반정규화
--- 관계 반정규화
3) 반정규화의 기법
- 테이블의 반정규화
- 속성 반정규화
- 관계 반정규화
