학습하면서 내용을 남겨보며 이 글을 오직 작성자의 주관전 생각입니다..
ElasticSearch 7.x 릴리즈 후 작성하는 글이여서 이전 버전 및 추후 버전 내용과 다를 수 있습니다.
ElasticSearch 란?
Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 분산형 오픈 소스 검색 및 분석 엔진입니다.
Elasticsearch는 Apache Lucene을 기반으로 구축되어 있다.
ElasticSearch는 아래와 같은 상황에서 사용 된다.
애플리케이션 검색
웹사이트 검색
엔터프라이즈 검색
로깅과 로그 분석 (* 앞으로 다룰 내용)
인프라 메트릭과 컨테이너 모니터링
애플리케이션 성능 모니터링
위치 기반 정보 데이터 분석 및 시각화
보안 분석
비즈니스 분석
1.ElasticSearch 구조
논리적 구조
1) 도큐 먼트
ElasticSearch 최소 단위 데이터이다. (MYSQL의 Row에 들어가는 데이터와 비슷하다고 생각함)
2) 타입
도큐먼트가 모여서 하나의 Type이 됨 일종의 RDBMS의 Table, 6.x 까지 지원되는 논리적 구조이며, 7.x 버전 부터는 사라졌다. (20.09.07 elasticsearch 는 7.9.0 버전 까지 배포 됨)
3) 필드
필드는 도큐먼트에 들어가는 데이터 타입으로 RDBMS의 Column명과 비슷하다.
하나의 필드에 여러개 데이터 타입을 가질 수 있다.
4) 매핑
필드와 필드의 속성을 정의하고 색인 방법을 정의 한다.
여러가지 데이터 타입 지정이 가능하지만 필드명 자체는 중복 불가능하다.
5) 인덱스
여러개의 Type이 모여 한개의 Index를 이루지만, ElasticSearch 6.1 부터 하나의 Index에 하나의 Type만 정의 가능하게 변경 되었다.(그래서 .. 7.x 버전부터는 Type이 사라진듯하다..)
RDBMS의 Databases과 비슷하다.
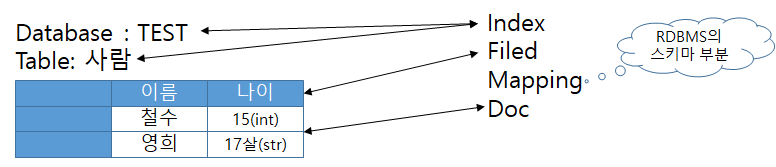
위 논리 적 내용을 그림으로 정리 해보면 아래의 그림 처럼 느껴진다.
** 그림에 문제가 있어 수정중 ..
물리적 구조
1) 노드
각 노드를 속성에 맞게 연동하여 Cluster를 구성 할 수 있으며, 노드이 종류는
Master, Data, MI, Ingest설정을 통해서 할 수 있으며, 설정 방법에 따라서는
Coordinating Node를 설 정 할 수있다.
Master
클러스터를 제어 할 수 있으며, 해당 설정이 ture로 설정 되었을 경우
Elasticsearch가 기동 시 Master Node로 선출 될 수 있다.
node.master = true
node.data = false
node.mi = false
node.ingest = false
Data
데이터가 저장되는 노드이며, user의 요청에 실제 데이터를 응답하는 Node 이다.
node.master = false
node.data = true
node.mi = false
node.ingest = false
Ingest
데이터를 저장 시 전처리 과정(포맷 변경)등이 필요할 경우 해당 전처리 과정을 담당하는 Node이다.
node.master = false
node.data = false
node.mi = false
node.ingest = true
MI (머신 러닝)
머신 러닝을 수행하는 Node이다.
현재 ElasticSearch의 라이센스는 여러 종류가 존재 하며, 기본 xpack 플러그인을 통해 사용 할 수 있는 기능으로 최소 Basic 라이센스 이상을 사용 해야한다.
상업적 배포 목적으로 사용 될 경우 OSS 버전으로 다운로드 해야한다.
node.master = false
node.data = false
node.mi = true
node.ingest = false
xpack.mi.enabled= true #xpack 머신러닝 플러그인 설정
Coordinating
사용자의 요청에 의해 Index가 존재하는 Data Node에 요청을 전송하고, 응답으로 온 데이터를 취합하여 사용자에게 전달하는 Node 이다.
node.master = false
node.data = false
node.mi = false
node.ingest = false
2) 샤드
하나의 Index에 여러개의 샤드가 존재 할 수있으며, 각각의 샤드에는 Replica 샤드가 존재 한다.
Replica 샤드는 서로 다른 Node에 저장된다.
3) 세그먼트
루신 라이브러리에서 사용하는 내부적인 자료 구조이다.
