
Encoding
머신러닝 or 딥러닝의 경우 컴퓨터를 이용하여 데이터를 분석하게 될 것이다.
데이터 분석도중에 문자열에 관한 변수도 분명히 있을 것이다. 이러한 문자열에 관한 속성은 아무 전처리없이는 알고리즘이 읽어들이기도 힘들 뿐더러 사용자가 분석에 사용하기에는 적합하지 않다.
그래서 이러한 분석하기 어려운 변수들을 숫자형으로 변환시켜주는 것이 Encoding이라고 할 수 있다. 머신러닝 모델에 학습을 시킬 때에는 이러한 전처리 기법을 사용하여 Feature Engineering을 거쳐야 한다.
Encoding에는 두가지 종류가 있다.
Label EncodingOnehot Encoding
Label Encoding
인간의 혈액형에는 4가지 종류가 있다. 'A', 'B', 'O', 'AB'가 있는것은 누구나 알 것이다. 이러한 범주형 속성을 그대로 머신러닝 모델에 넣기에는 적합하지 않다. 문자열이기 때문이다. 이를 숫자로 치환할 수 있다면??
'A' = 1, 'B' = 2, 'O' = 3, 'AB' = 4
처럼 말이다. 이와같은 인코딩 방법을 Label Encoding이라고 한다.
from sklearn.preprocessing import LabelEncoder
blood = ['A','A','O','AB','O','B','O']Label Encoding을 하기 위해 sklearn.preprocessing에서 LabelEncoder을 import 실행한다.
인코더 실습을 실행하기 위해 임의로 blood라는 리스트를 생성했다.
blood['A', 'A', 'O', 'AB', 'O', 'B', 'O']
Label = LabelEncoder()
Label.fit(blood)
labels = Label.transform(blood)
print("인코딩 후 : ", labels)인코딩 후 : [0 0 3 1 3 2 3]
라벨 인코딩한 결과를 보면 'A'는 0으로, 'B'는 1, 'O'는 3, 마지막으로 'AB'는 2로 인코딩된것을 알 수 있다. 딱 보면 알 수 있듯이 알파벳순서대로 인코딩이 됬다.
fit() / transform()
fit(): 데이터로 사이킷런 ML 모델을 학습시키는 메서드transform(): 입력된 데이터의 형태에 맞추어 데이터를 직접 변환시키는 메서드
즉, 위 코딩의 단계를 설명하자면
1. Label 변수에 LabelEncoder() 함수를 적용
2. Label 변수 (LaberEncoder())의 fit()메서드를 이용하여 blood 데이터를 적용. 즉, blood 데이터로 LaberEncoder이라는 모델을 학습
3. transform()메서드를 이용하여 학습된 LabelEncoder이라는 모델을 blood에 적용
장점
- 많은 Feature를 만들지 않고, 오직 하나의 Labeled Feature만 만든다.
- Onehot Encoding보다 속도가 빠르다.
- 위의 코딩을 보라. 짧은 코딩만으로도 쉽게 구현 했다.
문제점
- 문자열형이 숫자형으로 변환됨으로써 숫자의 특성이 적용이 된다. 예를 들어서 크기라는 특성이 적용될 수 있다. 크고 작음 같은 경우말이다. 이로인해 예측성능이 떨어질 수도 있다. 그 이유는 원래 범주형 변수란 순서라는 개념이 없는데 숫자는 크기라는 순서 개념이 있기 때문이다. 그래서 ML 모델들은 순서개념 전제하에 학습을 한다.
- 위의 단점으로 인하여 선형회귀 모델에는 적합하지 않다. 하지만 의사 결정 트리 또는 랜덤 포레스트와 같은 범주형 변수를 사용할 수 있는 메서드는 괜찮다.
Onehot Encoding
Label Encoding은 객체 하나하나당 숫자를 부여한 인코더이다. 매우 간단한 방법!!
이번에 배울 Onehot Encoding은 숫자가 아닌 벡터를 부여한다.
위에서 예제로 봤던 혈액형을 가지고 예를 들어보자
| 혈액형 | Onehot Encoding |
|---|---|
| A | {1, 0, 0, 0} |
| AB | {0, 1, 0, 0} |
| B | {0, 0, 1, 0} |
| O | {0, 0, 0, 1} |
즉, Feature 유형에 따라 새로운 Feature를 추가하여 고유 값에 해당하는 칼럼만 1, 나머지는 0으로 표시한다.
from sklearn.preprocessing import OneHotEncoderOnehot Encoding을 하기 위해 OneHotEncoder을 import한다.
Label Encoding은 리스트 그 자체로 인코딩이 가능했다. 그런데
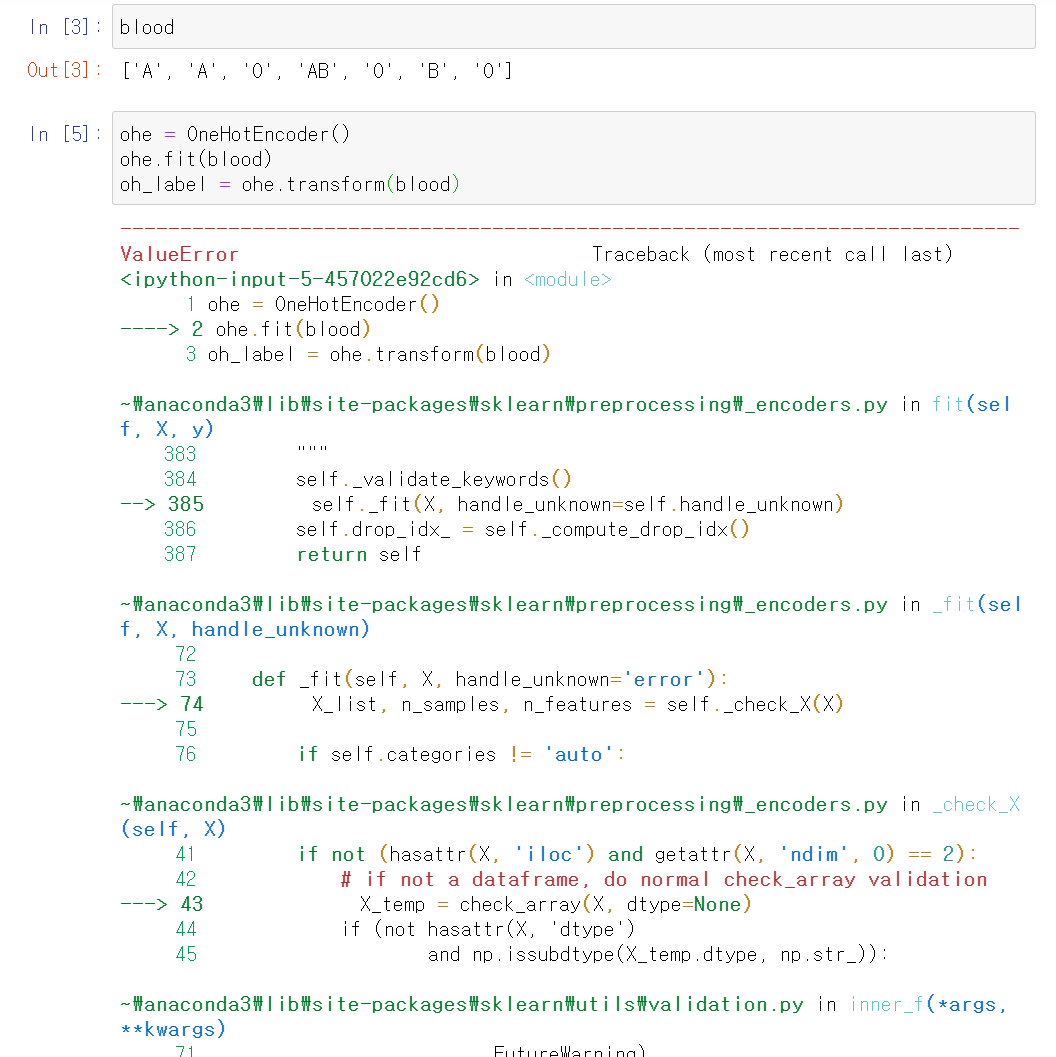
리스트인채로 Onehot은 불가능했다. Onehot은 Numpy에서 배열로 변환해줘야 한다. 배열도 1열 배열(?)로 변환시켜줘야 한다.
blood = ['A','A','O','AB','O','B','O']
blood = np.array(blood)
blood = blood.reshape(-1, 1)blood 자체는 리스트라서 np.array로 배열변환을 했다. 그 후에 reshape(-1, 1)을 이용하여 1열 배열로 변환. reshape(-1, 1)은 나중에 다시 봐보자.
ohe = OneHotEncoder()
ohe.fit(blood)
oh_label = ohe.transform(blood)
print("OneHotEncoder")
print(oh_label.toarray())
print("OnehotEncoder dim()")
print(oh_label.shape)
그러면 정상적으로 출력이 된다.
장점
- Feature끼리 벡터로 서로 독립적인 관계이기 때문에(서로 내적하면 0이 된다) Label Encoding과 다르게 서로 영향을 주지 않는다.
- 이것 또한 보듯이 구현이 쉽다.
라벨보다는 조금 복잡하지만(배열화)
문제점
- Feature 내에 종류가 많을 경우 (혈액형은 4가지밖에 없지만 막 10개 넘어가는 종류라면??) 각 Feature마다 벡터들을 만들어내기 때문에 매누 많은 Feature를 만들어낸다. 그로 인해 모델 훈련의 속도가 늦어지고 훈련에 더 많은 정보를 필요하게 된다.
(차원의 저주 문제) - 트리 모델같은 경우 단순히 0과 1로 결과를 만들어내기 때문에 Tree의 depth가 깊어진다. 그리고 가지 경우로만 트리를 만들어나간다.
Random Forest같은 경우 일부 Feature만 샘플링하여 트리를 만들어나간다.
그러면 Feature가 방대한 양이므로 이 Feature가 다른 Feature보다 더 많이 쓰이게 된다.
차원의 저주
- ML 모델을 통해 데이터 학습시, 차원이 증가하면 학습데이터 수가 차원의 수보다 적어져서 성능이 저하되는 현상
- 차원이 증가할수록 개별 차원 내 학습할 데이터가 적어지는 현상
- 차원의 증가함은 변수의 수가 증가함을 뜻한다.
- 관측치 수보다 변수의 수가 많아지면 발생 (관측치는 100개, 변수는 3000개??같은)
