한국복지패널 데이터에서 지역별 평균 월급을 추출하고 평균 월급이 높은 순서로 정렬해 그래프를 출력하라.
1. 데이터 준비
https://bit.ly/Koweps_hpwc14_2019_beta2 해당 사이트에 접속하여 파일 다운로드
pip install pyreadstat
위의 패캐지를 아나콘다에 설치
2. 데이터 불러오기
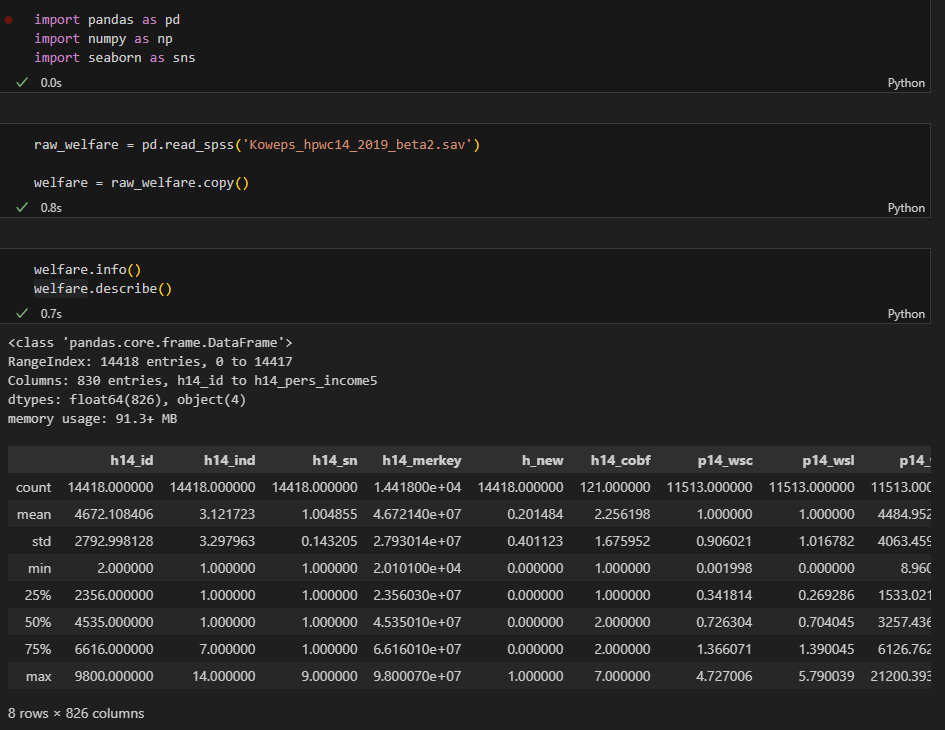
raw_welfare = pd.read_spss('Koweps_hpwc14_2019_beta2.sav') welfare = raw_welfare.copy()
위의 코드를 사용하여 데이터불러오기
welfare.info() welfare.describe()
위의 코드를 사용해서 데이터가 잘 가져와졌는지 확인하기
3. 변수명 변경하기
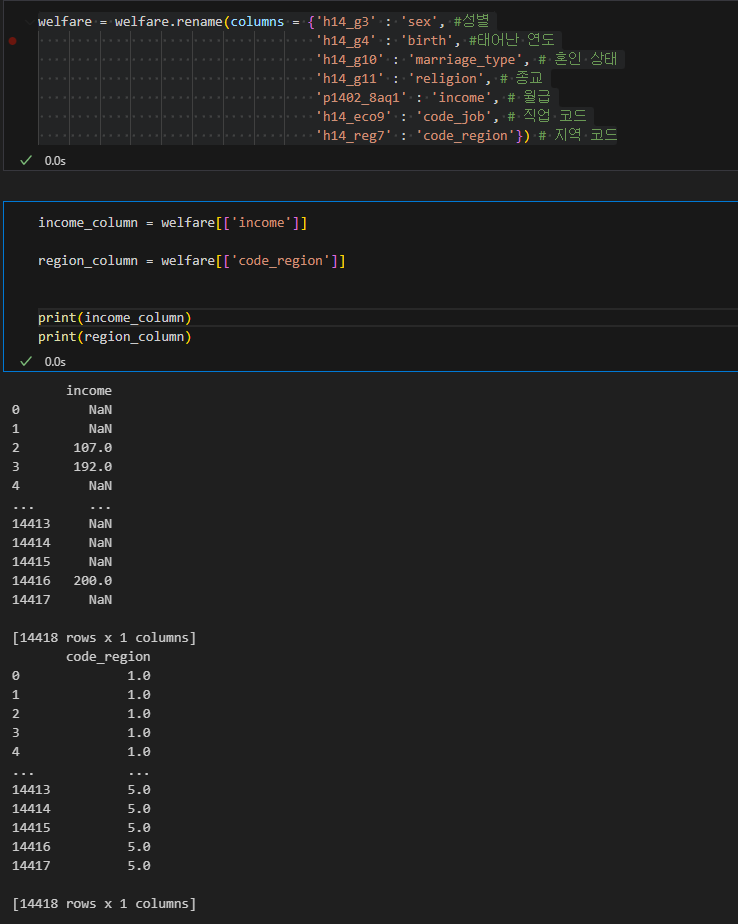
welfare = welfare.rename(columns = {'h14_g3' : 'sex', #성별 'h14_g4' : 'birth', #태어난 연도 'h14_g10' : 'marriage_type', # 혼인 상태 'h14_g11' : 'religion', # 종교 'p1402_8aq1' : 'income', # 월급 'h14_eco9' : 'code_job', # 직업 코드 'h14_reg7' : 'code_region'}) # 지역 코드
위의 코드로 변수명을 변경 후
income_column = welfare[['income']] region_column = welfare[['code_region']] print(income_column) print(region_column)
위의 코드로 잘 변경됬는지 확인(시험마다 다를 수 있으니 바뀌면 변수명을 바꾸자)
4. 지역(code_region) 전처리
<데이터병합 과정>
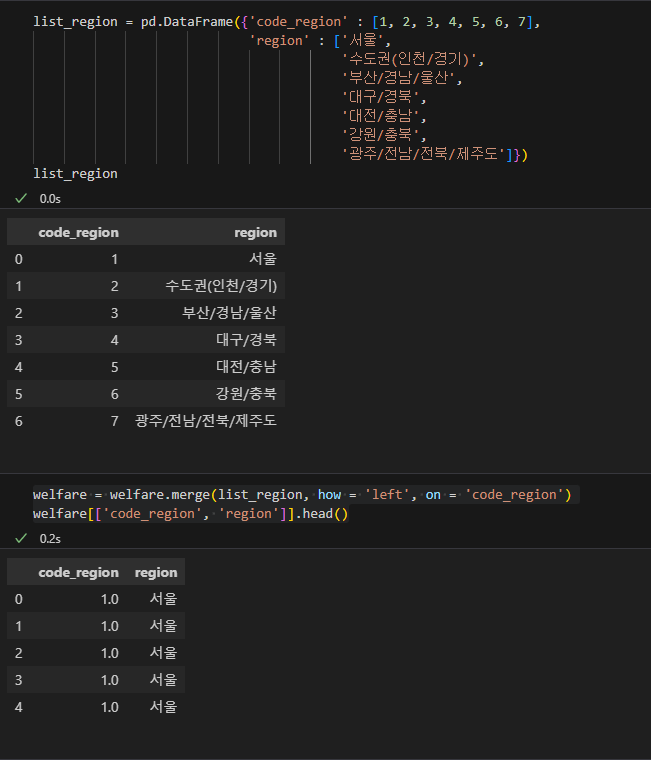
list_region = pd.DataFrame({'code_region' : [1, 2, 3, 4, 5, 6, 7], 'region' : ['서울', '수도권(인천/경기)', '부산/경남/울산', '대구/경북', '대전/충남', '강원/충북', '광주/전남/전북/제주도']}) list_region
위의 코드를 활용해서 list_region을 제작
welfare = welfare.merge(list_region, how = 'left', on = 'code_region') welfare[['code_region', 'region']].head()
위의 코드를 사용해서 welfare에 list_region을 합친다
<지역별 월급평균구하기>
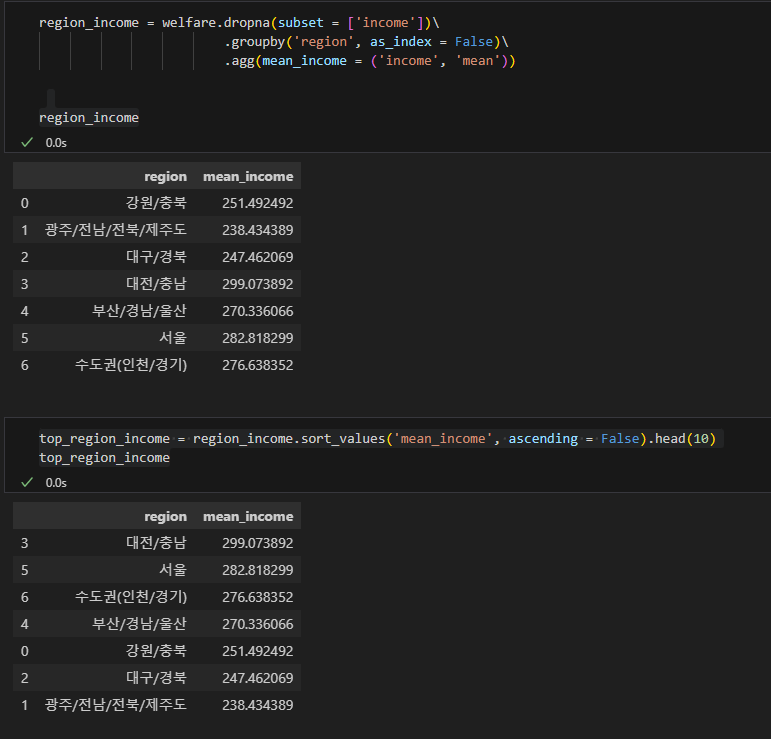
region_income = welfare.dropna(subset = ['income'])\ .groupby('region', as_index = False)\ .agg(mean_income = ('income', 'mean')) region_income
위의 코드를 사용해 월급의 평균을 구한다
<높은 지역 먼처 출력>
top_region_income = region_income.sort_values('mean_income', ascending = False).head(10) top_region_income
위의 코드를 사용해 월급 평균이 높은 순부터 정렬되고 잘 정렬되는지 확인한다
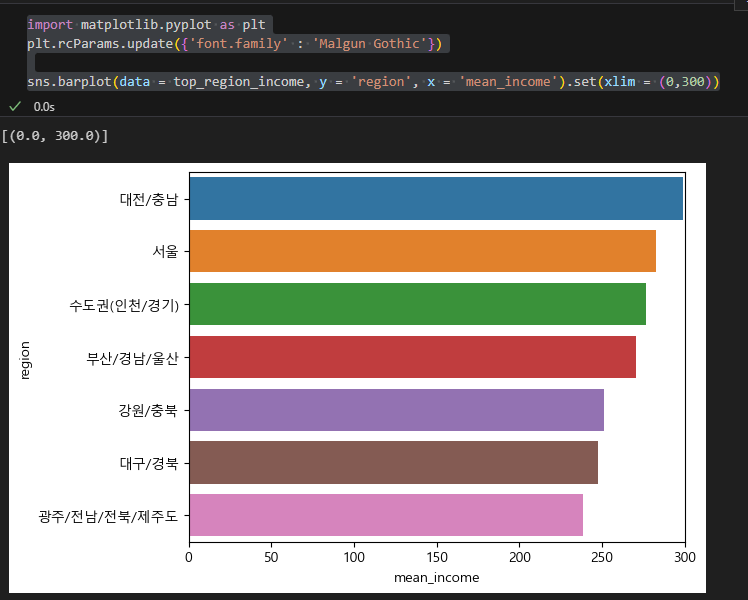
5. 그래프 출력
import matplotlib.pyplot as plt plt.rcParams.update({'font.family' : 'Malgun Gothic'}) sns.barplot(data = top_region_income, y = 'region', x = 'mean_income').set(xlim = (0,300))
import matplotlib.pyplot as plt plt.rcParams.update({'font.family' : 'Malgun Gothic'}) sns.barplot(data = top_region_income, x = 'region', y = 'mean_income')
위의 두 코드중 하나를 사용해 월급이 높은순으로 그래프를 만든다
####6. 사진

^.^