MSA에서 대용량 트래픽을 관리하다보면 단일 Database에 부하가 발생할 수 있는데
이 때 필요한 것은 Scale-up, Scale-out 방법이 있다.
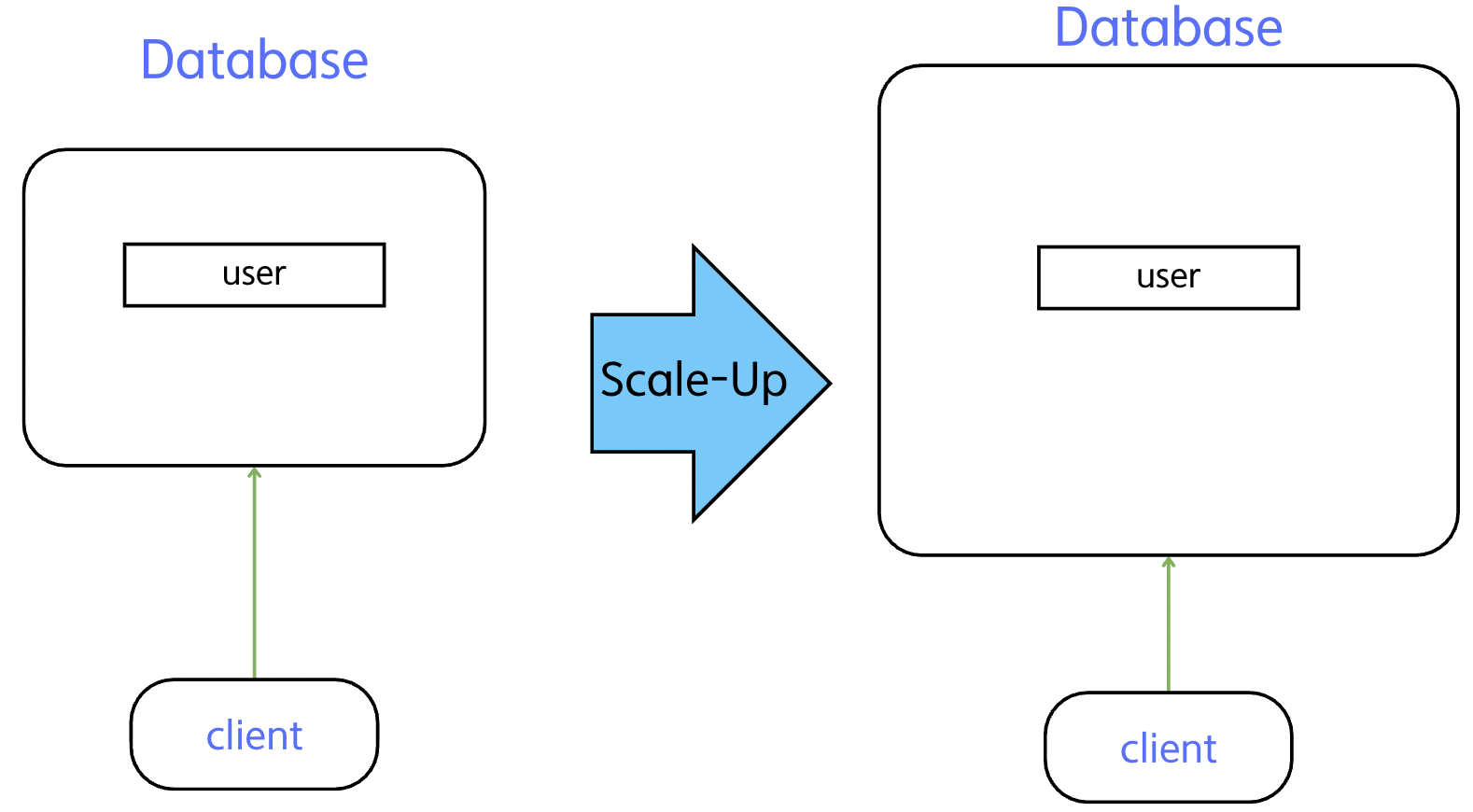
Database의 Scale-up은 DB 장비의 성능을 올리는 방법이 있는데
서비스 규모가 커질수록 장비 성능을 무한정 늘리는 데는 한계가 있다.
이러한 한계 때문에 사용되는 방법이 Scale-out이며,이 때 주로 사용되는 것이 분산 데이터베이스(Distributed Database)이다.
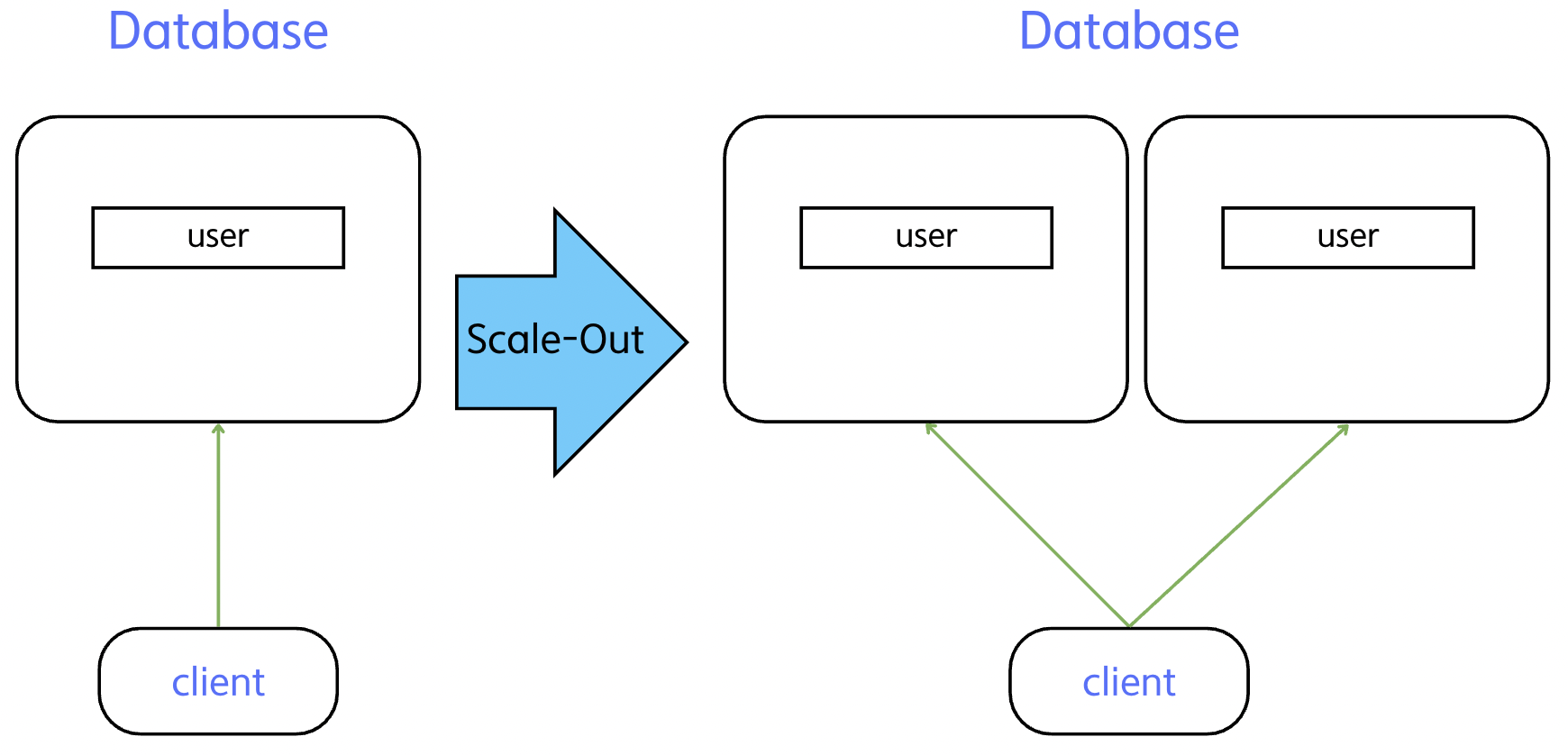
1. 분산 데이터베이스가 뭔데?
여러개의 노드(서버)에 데이터를 저장하고 이를 하나의 데이터베이스처럼 사용하는 시스템을 말한다.
즉, 하나의 논리적인 데이터베이스가 물리적으로 여러 장소에 분산된 구조를 갖는다.
- 장점
- 확장성(Scalability) : 단일 DB로 감당할 수 없는 데이터 또는 트래픽 증가에 대응 가능
- 고가용성 및 장애 복구(Fault Tolerance) : 하나의 서버가 다운되더라도 다른 노드가 서비스를 제공
- 성능 향상 : 읽기/쓰기 등의 작업을 여러 노드에 분산시켜 병렬 처리 가능
- 단점
- 복잡한 트랜잭션 : 여러 노드에 걸친 ACID 보장이 어려움
- 데이터 일관성 문제 : 네트워크 지연으로 동기화 실패 가능
- 어려운 운영 관리 : 배포, 모니터링, 보안 등 유지보수가 복잡
2. 데이터 분산을 어떻게 하는데?
데이터를 분산 저장하는 방식은 크게 파티셔닝(Partitioning)과 샤딩(Sharding)으로 구분되며 사용하는 목적과 환경에 따라 차이가 있다.
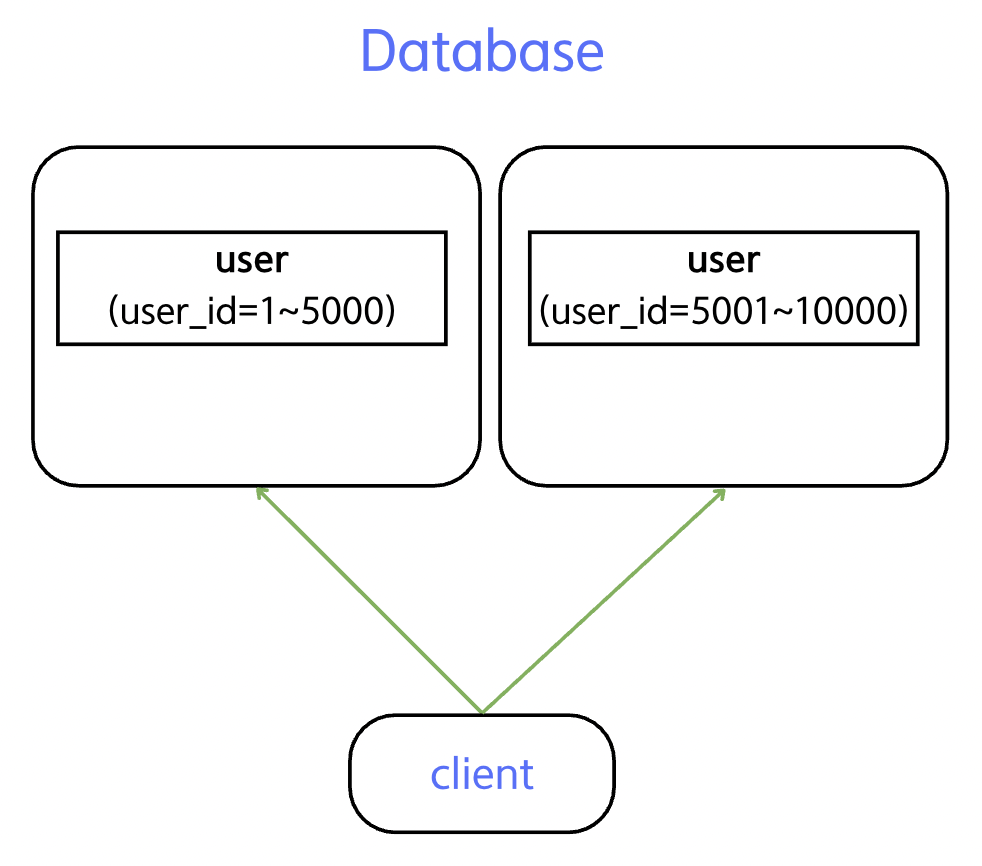
- 수평 분할 : 테이블의 행(row)을 기준으로 나누는 방식으로, 보통 샤딩의 기본 형태로 많이 사용된다.
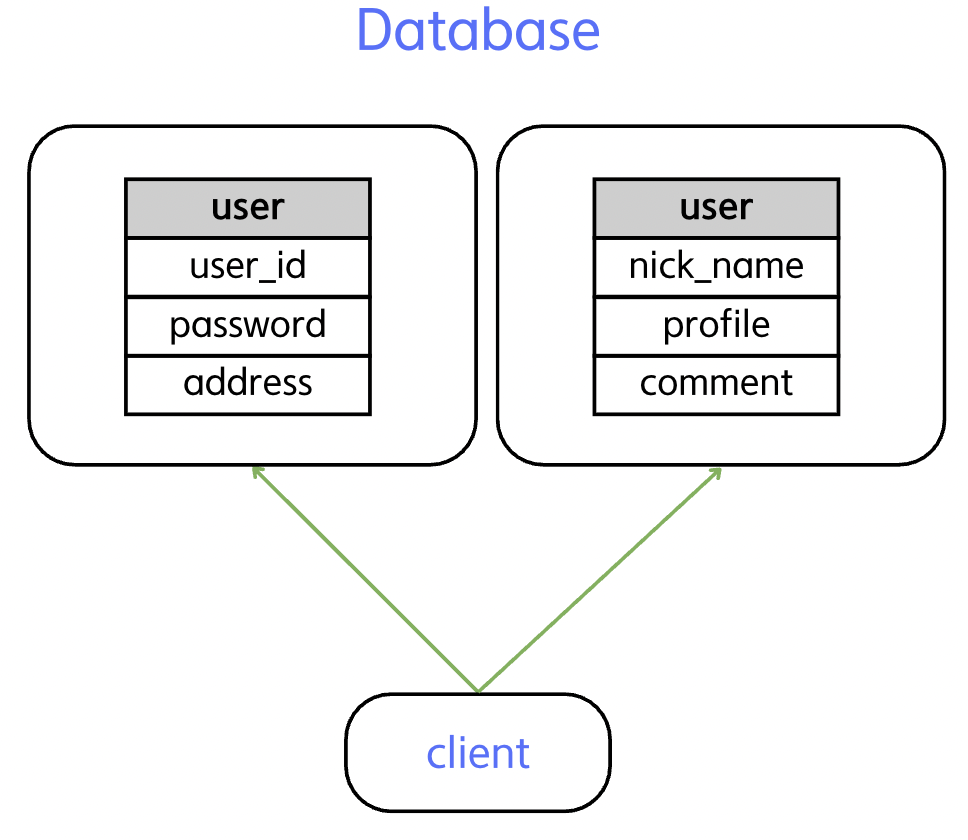
- 수직 분할 : 테이블의 열(column)을 기준으로 나누는 방식으로, 주로 데이터 정규화나 I/O 성능 최적화 목적으로 사용된다.
- 해시 기반 샤딩 : 데이터를 저장할 때 특정 키(user_id, order_id 등)에 해시 함수를 적용해서 결과값에 따라 데이터를 특정 샤드에 할당하는 방식으로, 수평 분할의 한 방식이다.
shard_number = hash(key) % N
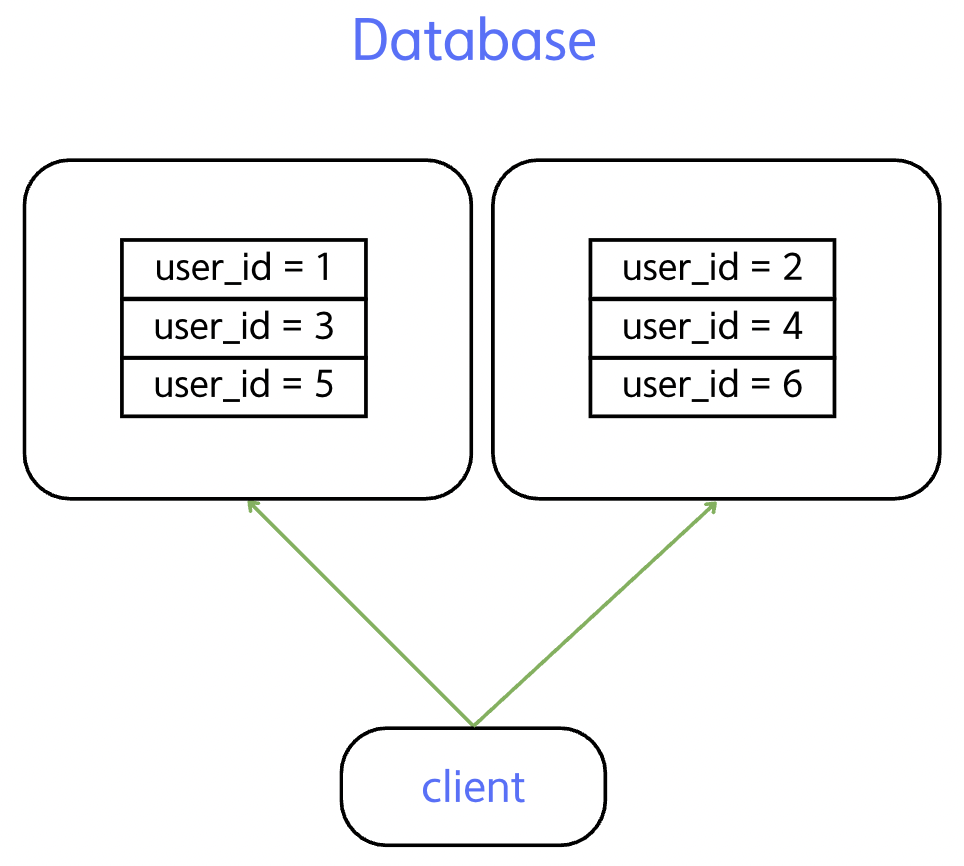
해시 함수가 균일하다면 데이터가 고르게 분산될 수 있고, 어떤 샤드에 데이터가 있는지 계산만으로 알 수 있지만
샤드의 수(N)가 바뀌면 대부분의 데이터를 재배치해야하고, 샤딩된 데이터는 서로 다른 노드에 저장되기 때문에 조인이나 범위 검색 시 성능 저하가 발생할 수 있다.

난 멋져!