Spring Data JPA
1. 영속성 컨텍스트란
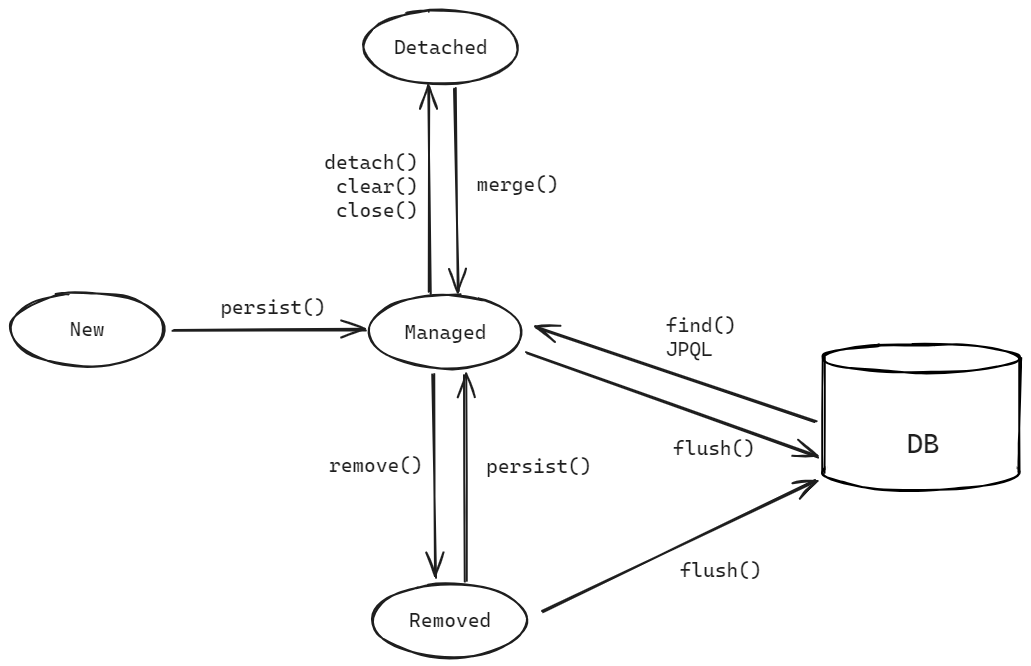
객체와 관계형 데이터베이스 매핑하기영속성 컨테이너영속성 컨테이너를 제대로 이해하면 JPA가 내부적으로 어떻게 동작하는지 알 수 있다. 즉, JPA를 더 정확하고 효율적으로 사용이 가능하다.DB에 데이터를 저장하는 것이 아니라 JPA의 영속성 컨텍스트에 데이터를 저장논리
2.영속성 컨텍스트의 특징
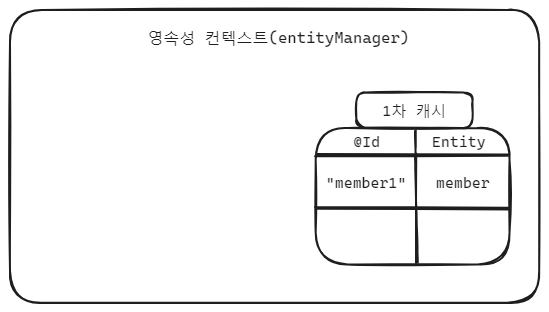
JPA를 사용한다는 것은 영속성 컨텍스트를 사용한다는 것이고 그럼 영속성 컨텍스트의 이점을 누릴 수 있다는 말과 같다고 생각합니다.1차 캐시동일성 보장트랜잭션을 지원하는 쓰기 지연변경 감지지연 로딩1차 캐시에 들어있는 entity의 경우 DB를 거치지 않고 조회가 가능
3.JPA(Java Persistence API) - 플러시

영속성 컨텍스트의 변경내용을 데이터베이스에 반영영속성 컨텍스트의 쓰기 지연 SQL 저장소에 있던 SQL을 데이터베이스에 반영데이터 베이스 트랜잭션이 commit되면 자동적으로 flush()가 발동한다.그렇다면 flush()가 발동하면 어떤 일이 일어날까?변경감지수정된
4.객체와 테이블 매핑

@Entity, @Table: 객체와 테이블 매핑@Column: 필드와 컬럼 매핑@Id: 기본 키 매핑@ManyToOne, @JoinColumn, ...: 연관관계 매핑JPA가 관리하는 클래스, 엔티티라 합니다. Table과 직접적으로 매핑되는 클래스주의기본 생성자 필
5.JPA의 DB스키마 자동 생성

JPA가 매핑 정보를 보고 애플리케이션 로딩 시점에 자동으로 DB스키마를 생성하고 테이블에 데이터를 알아서 넣는다.persistence.xmlapplication.propertiesapplication.ymlyml 설정에서는 계층 표현이 중요합니다. 띄어쓰기를 잘못하면
6.JPA 매핑 - 필드와 컬럼
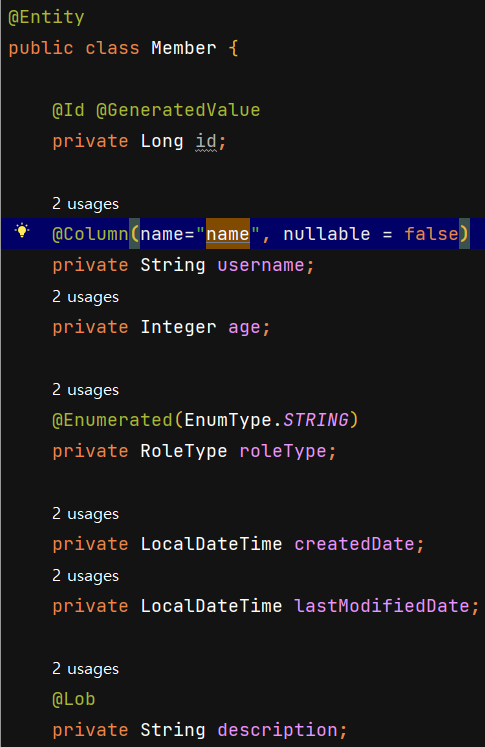
자바와 DB의 데이터 타입이 다른 것들이 있기 때문에 이 데이터를 어노테이션을 사용해서 맞춰줘야 합니다.객체 필드와 테이블 컬럼 매핑에 사용자바 enum 타입을 매핑할 때 사용무조건 EnumType.STRING으로 사용해야 한다.주의사항EnumType.ORDINAL 사
7.JPA 매핑 - 기본 키

@Id@GeneratedValue기본 키 생성을 데이터베이스에 위임주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행AUTO_INCREMENT는 데이터베이스에 INSERT SQL을 실행
8.단방향 연관관계
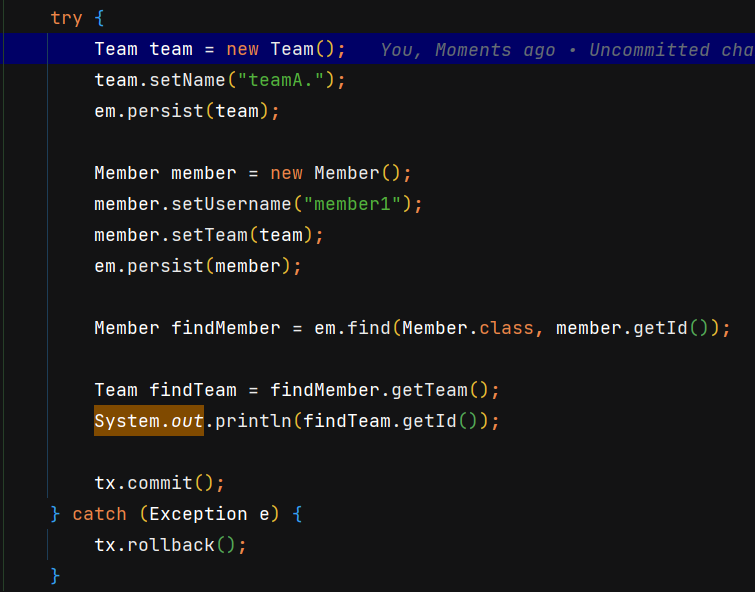
모든 코드는 Github에 올라와 있습니다. A엔티티가 B엔티티를 참조하지만 B엔티티는 A엔티티를 참조하지 않는 경우엔티티의 참조가 한쪽 방향으로만 있는 경우회원과 팀이 있다.회원은 팀을 참조지만, 팀은 회원을 참조하지 않는다.회원과 팀은 다대일 관계다.객체지향에서는
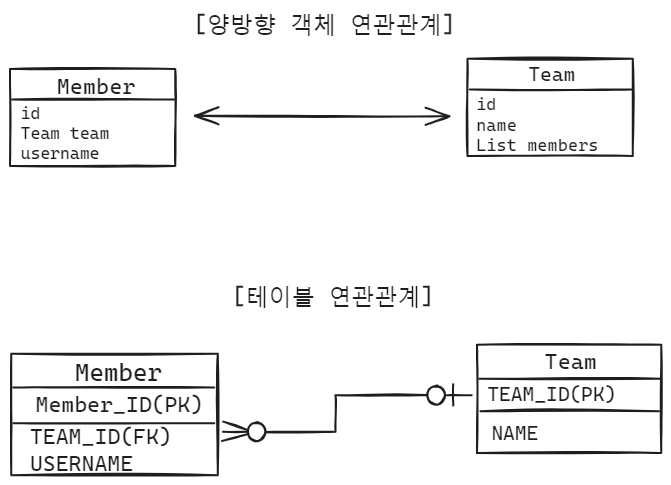
9.양방향 연관관계와 연관관계의 주인 - 1
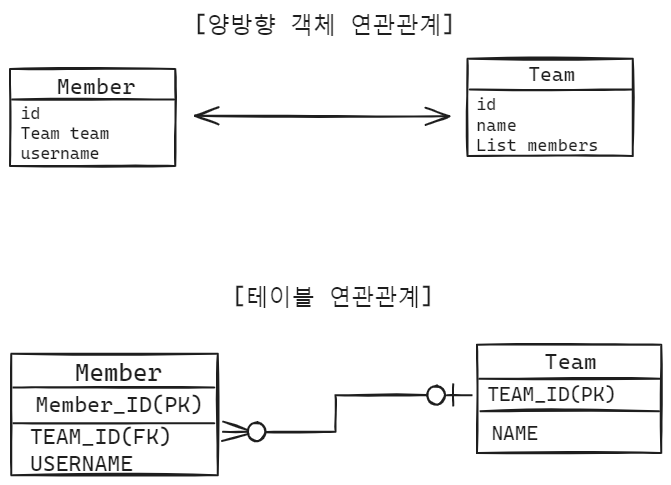
이전 포스팅의 단방향 연관관계에서 더 발전시켜서 양방향으로 만들어보겠습니다.모든 코드는 Github에 올라와 있습니다.두 엔티티가 서로를 참조하는 관계회원과 팀이 있다.회원은 하나의 팀에 소속된다.하나의 팀은 여러 회원을 가지고 있다.Member와 Team을 양방향 연
10.양방향 연관관계와 연관관계의 주인 - 2
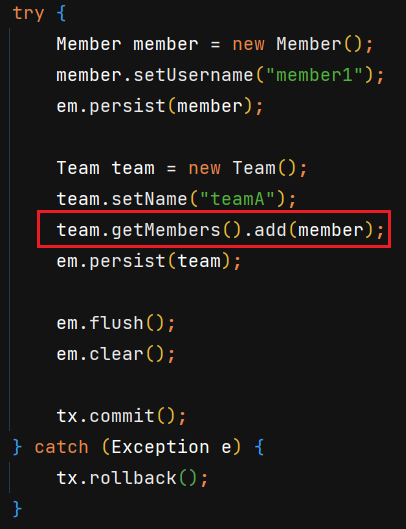
저번 포스팅에서는 양방향 연관관계의 기본적인 부분에 대해서 알아보았습니다.이번에는 양방향 연관관계를 맺을 때 주의해야 할 점에 대해서 알아보겠습니다.모든 코드는 Github 에 올라와있습니다.mappedBy 된 변수에 값을 입력하려고 한다.분명히 team.getMemb
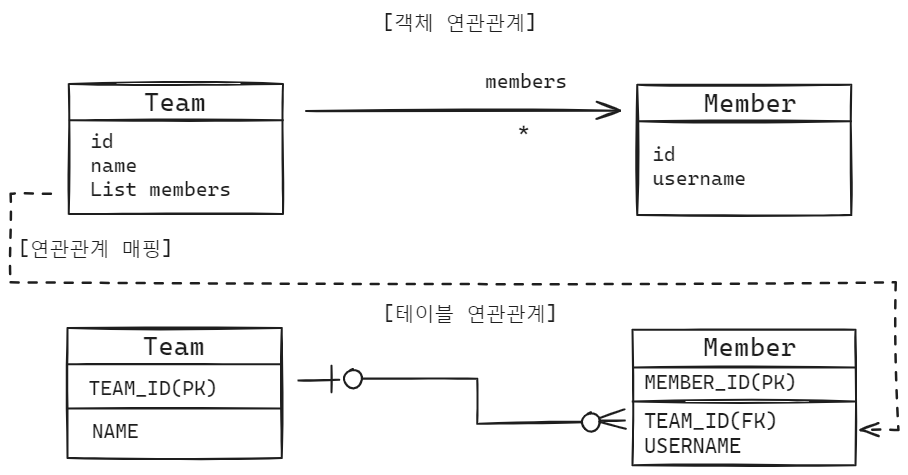
11.연관관계_다대일(N:1)
연관관계 매핑에는 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M)가 있습니다. 이번 포스팅에서는 다대일(N:1)에 대해서 알아보겠습니다.가장 많이 사용되는 연관관계 매핑 중 하나한 엔티티의 여러 인스턴스가 다른 엔티티의 단일 인스턴스와 연관되는 관
12.연관관계_일대다(1:N)
한 엔티티의 인스턴스가 다른 엔티티의 여러 인스턴스와 연관되는 관계예) 한 명의 작가가 여러 권의 책을 쓸 수 있는 경우'일' 쪽에서 외래키를 관리객체입장에서 TEAM에서 외래키를 관리, 데이터베이스는 '다' 쪽에서 외래키를 관리한다.Team위 코드를 보면 일대다 관계
13.연관관계_일대일(1:1)
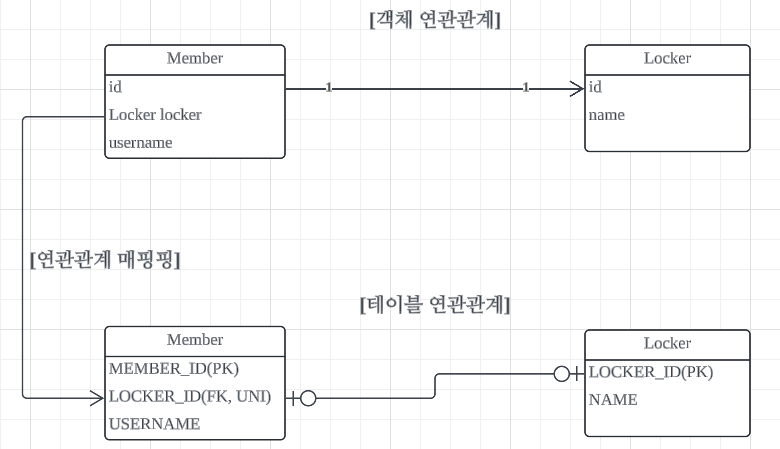
각 엔티티는 상대 엔티티와 하나의 관계만을 가집니다.데이터베이스에서는 외래키에 UNIQUE 제약조건이 추가된 상황MemberMember에서 Locker를 관리하기 때문에 @JoinColumn을 추가합니다.Member에서 Locker에 데이터를 생성, 수정을 합니다.반대