기계학습 기초(machine Learning) 01
해당포스팅은 coursera의 andrew ng의 강의와 개인적으로 공부한 내용을 정리한 포스팅입니다. 문제가 될 경우 비공개 처리될수 있음
전반적인 내용(꼭 알아야할 내용)들을 정리해 놓았으며, 좀더 심층적인 내용은 개별적으로 포스팅 할 예정
0.기계학습
- data를 이용해 데이터 특성과 패턴을 학습하여, 그 결과를 바탕으로 특정 데이터에 대한 미래 결과(값, 분포)를 예측
- 기본 개념
- 데이터 준비 : 데이터를 입력 데이터(feature)와 출력데이터(target)로 구분
- 모델 선택 및 학습 : 모델 = 데이터의 패턴을 학습하기 위한 알고리즘 -> 현실 세계에서 발생하는 일들을 수학적으로 계산.
학습 = 주어진 데이터를 사용해 모델의 파라미터(수학으로 치면 변수(기울기))를 조정.
모델을 학습하면 모델이 입력데이터와 출력데이터 사이 관계를 출력 - 모델 평가 : 미리 나누어둔 테스트 데이터로 성능 평가
- 예측 : 학습된 모델은 새로운 입력 데이터를 받아 해당하는 출력 데이터를 예측하거나 결정
- 유형
- 지도 학습(Supervised learning)
- 비지도 학습(Unsupervised learning)
- 준지도 학습(Semi-supervised Learning)
- 강화 학습(Reinforcement Learning)
0-1.기본적인 용어 정리
-
옵티마이저 : 비용 함수/손실함수 를 최소화하는 매개변수인 w,b를 찾기 위한 작업에 사용되는 알고리즘
-> 최적화 알고리즘 이라고도 한다. -
가설 : x와y, 즉 입력값과 출력값의 관계를 유추하기 위해 세운 수학적인 식
-
상관 관계 : 두 변수가 선형 관계가 있는 범위를 표현하는 측도(1과 -1 사이 값을 가짐, 0에 가까울수록 선형 관계가 약해진다.)
-
하이퍼 파라미터
- 초매개변수라고 불린다
- 모델의 학습과정을 제어하고 조정하기 위해 사람이 직접 설정해야하는 매개변수 들을 말한다
- 값에 따라서 모델의 성능ㅔ 영향을 주는 매개변수
- 종류 : 학습률, 배치크기, 에포크수 은닉층과 뉴런의 개수
-
매개변수
- 모델이 학습되는 동안 업데이트 되는 값
- 모델은 초기에 랜덤하게 초기와된 매개변수를 데이터에 맞게 조정하면서 학습
- 종류 : 가중치 편향
-
가중치와 편향(weight & bias)
- 가중치
- 입력 데이터의 특성과 연결된 뉴런의 강도
- 입력 데이터가 출력 데이터에 미치는 중요도를 조절하는 매개변수
- 입력으로 들어온 데이터중 어떤 feature를 많이 반영하고 덜 반영할지 결정
- 활성화 함수에 따라 기울기 증가(기울기가 커질수록 모델에 영향을 더준다)
- 편향
- 뉴련의 활성화 조건을 결정하는 매개변수
- 모델이 데이터의 패턴을 더 정확하게 학습할 수 있도록 도와주는 상수 (일종의 보정값)
- 노드의 민감도를 조절해주는 역활
- 가중치와 편향이 헷갈린다면 y =Wx + b라는 단순 선형회귀 수식에서 W가 가중치 b가 편향이다.
- 가중치
-
활성화 함수
- 신경망의 output를 결정하는 식
- 타입 : 이진 함수, 선형 함수, 비선형 함수
- 신경망의 output를 결정하는 식
-
과적합 / 과소적합
- 과적합
- 모델이 훈련데이터에 너무 많이 적합되어 새로운 데이터에 대한 성능이 저하되는 것
- 모델이 훈련데이터의 노이즈나 이상치까지 학습해 실제 데이터에서 예측 능력이 낮아지는 경우
- 과소 적합
- 모델이 훈련 데이터에 적합하지 않아 실제 데이터와도 일반화 되지 못한것
- 과적합
-
선형성 : 독립변수와 종속변수 사이에 선형 관계가 있어야 한다. 위에서 말했듯 직선을 맞춰야 한다는 것을 의미
-
통계학 용어
- 잔차의 독립성 : 잔차는 예측값과 실제값의 차이를 의미. 에러라고도 함
- 정규성 : 통계학에서 가설검증이 정규분포를 따른다는 성질을 전제하는 주요한 가정 중 하나
- 정규분포 : 대칭을 이루는 종모양의 분포
- 연속확률분포 : 확률 밀도 함수를 이용해 분포를 표현 할 수 있는 경우
- 확률 분포 : 확률 변수가 특정한값을 가질 확률
- 확률 밀도 함수 : 연속 확룰 변수를 나타내는 함수
- 정규분포 : 대칭을 이루는 종모양의 분포
- 정규성 검정 : 정규분포를 따르는 모집단에서 관측값들이 취해져 있는지 검정하는 것
- 등분산성 : 모든 확률변수가 같은 유한 분산을 가지는 성질을 가정 -> 모든 분산이 동일하다
- 독립성 : 다중 회귀분석에서 나오는 기본 가정. 독립변수 x 간에 상관관계가 없이 독립한 것을 의미
- 잔차의 자기 상관성, 독립변수와 잔차의 독립성, 예측값과 잔차간의 독립성
- 분산 : 확률 변수가 기대값으로 부터 얼마나 떨어진 곳에 분포하는지 가늠하는 숫자
- 확률변수 : 특정 확률로 발생하는 각각의 결과를 표현하는 변수
1. 손실함수/비용함수(loss function/Cost Function)
- 머신러닝 혹은 딥러닝 모델의 출력값과 사용자가 원하는 출력값의 오차
- 손실함수는 정답과 예측을 입력으로 하여 실수값의 점수를 만든다.
- loss나 cost function이라고 하면 그냥 손실함수 또는 비용 함수라고 알아들으면 된다. 똑같은 말
- 점수가 높을수록 모델의 성능이 낮다
- 종류 : RMSE, MSE,Binary Crossentropy, Categroical Crossentropy등
- 보통 j(w,x)라고 한다.
- 이때 질문은 에측값인 가 모든 학습예제인 ,에 대한 실제 목표 에 근접할 것인지를 구하는 것 -> w,b값을
1-1) MSE(Mean Squared Error)
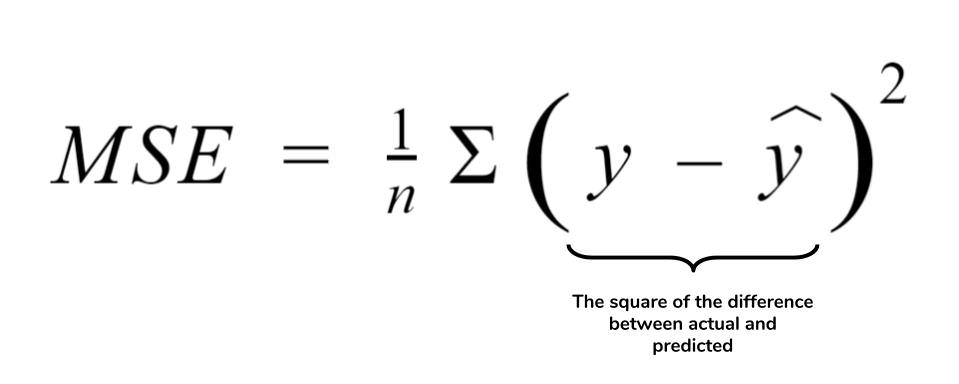
- 예측한값과 실제값 사이의 평균 제곱오차로 정의
- 차가 커질수록 제곱의 연산으로 인해 값이 뚜렷해진다
- 하지만 제곱을 하기에 외곡이 발생할 수도 있다
- 수식
- 모델이 라고 하고, mse라고 한다면
- = (1/n을 1/2n로 해도됨 여기서는 편하게 2n이라고 한다)
- 선형회귀에서는 이것의 목표를 w,b값을 찾는 것을 수식으로
라고한다
import pandas as pd
import numpy as np
import pandas as pd
import numpy as np
# 데이터프레임 생성
data = {'predicted': [2.5, 3.0, 4.2, 5.1, 6.2],
'actual': [2.0, 2.8, 3.8, 4.9, 5.5]}
df = pd.DataFrame(data)
# MSE 계산
mse = np.mean((df['predicted'] - df['actual'])**2)1-2) RMSE(ROOT Mean Squared Error)
- MSE에 제곱근을 한것
- MSE는 오류의 제곱을 구하기에 실제 오류 평균보다 커지기에 제곱근을 하여 외곡을 줄인다
- 차가 커질수록 제곱 연산으로 인해 값이 뚜렷해짐
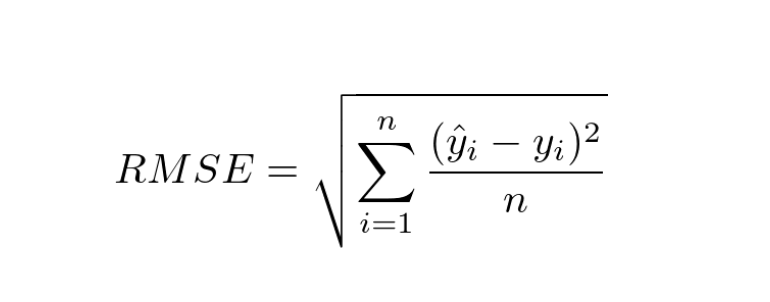
rmse = np.sqrt(np.mean((df['predicted'] - df['actual'])**2))binary crossentropy
- crossentropy
2. 기울기(Gradient)
- 다변수 함수에서 각 변수에 대한 편미분을 모아 벡터로 표현한 것
- 손실함수를 줄이기 위해서는 기울기를 활용한다.
- 기울기를 구하기 위한 방법
- 미분을 통한 기울기 구하기, 경사하강법
2-1) 미분으로 경사 구하기
i) 미분
-
미분은 함수의 변화율을 나타내며, 함수가 어떤 입력값에서 얼마나 빠르게 변화하는가를 나타낸다.
- 공식 : f'(x) ≈ (f(x + h) - f(x)) / h
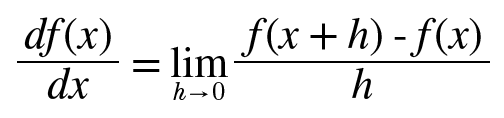
- 공식 : f'(x) ≈ (f(x + h) - f(x)) / h
-
수치 미분 : 함수의 미분 값을 근사적으로 계산하는 방법
- 보통 미분값을 정확히 구하지 못할떄 사용
- 근사치로 하기에 오차가 존재한다
- 종류
- 전방 차분
- f'(x) ≈ (f(x + h) - f(x)) / h로 계산하는것
- 중앙 차분
- (x+h)와 (x-h)일 때의 차분
- f'(x) ≈ (f(x + h) - f(x - h)) / (2 * h)
- 전방 차분
def numerical_diff(f,x):
h = 1e-4
return (f(x+h) - f(x-h)) / (2*h)
여기서 f는 실제 계산식을 넣으면 된다.- 편미분
- 다변수 함수의 미분을 각 변수에 대해 따로 계산하는 것(다변수 함수는 여러 개의 변수에 의존하는 함수)
- 특정 변수를 제외한 나머지 변수는 상수로 간주하고 미분하는것(미분할때 h에 더한다)
- 모든 변수에 대한 편미분을 좌표로 갖는 벡터를 기울기라고한다.
- 변수가 두개인 편미분에 대한 기울기는 ∂f/∂x₀,∂f/∂x₁ (∂ : 편미분, 즉 f(x,y)가있으면 f를 변수 x₀에 대해 편미분 한 값)
종합하자면 기울기는 함수의 가장 낮은 곳(최솟값)을 가르킨다. 따라서 기울기가 가장 낮은 곳은 각 함수의 출력값을 가장 크게 줄이는 곳
참고로 쉽게 구하는 것은 오차역전파법이 있다.
3. optimizer (최적화 함수)
3-1) 경사 하강법
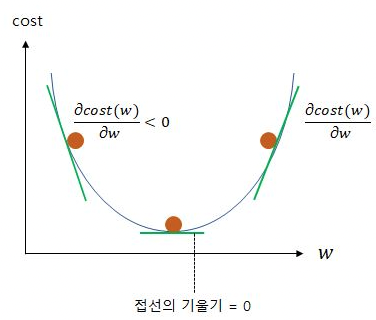
-
함수의 최솟값을 찾기위해 기울기를 활용하여 파라미터를 조금씩 조정하는 최적화 알고리즘
-
수식
- w = =
- -증명 ->
- = = =
- -증명 ->
- b = =
여기서 α는 학습률
- w = =
-
새로운파라미터 = 현재파라미터 - 학습률 *
->w₀-α x 기울기 = 학습률 x 기울기* 학습률은 경사하강법에서 사용되는 파라미터로 파라미터를 업데이트 할떄 얼마나 크게 업데이트 할지 결정한다. -
하지만 local minimum에 빠지기 쉬우며, 안장점을 벗어나지 못한다
-> 의미는 볼록함수 즉,
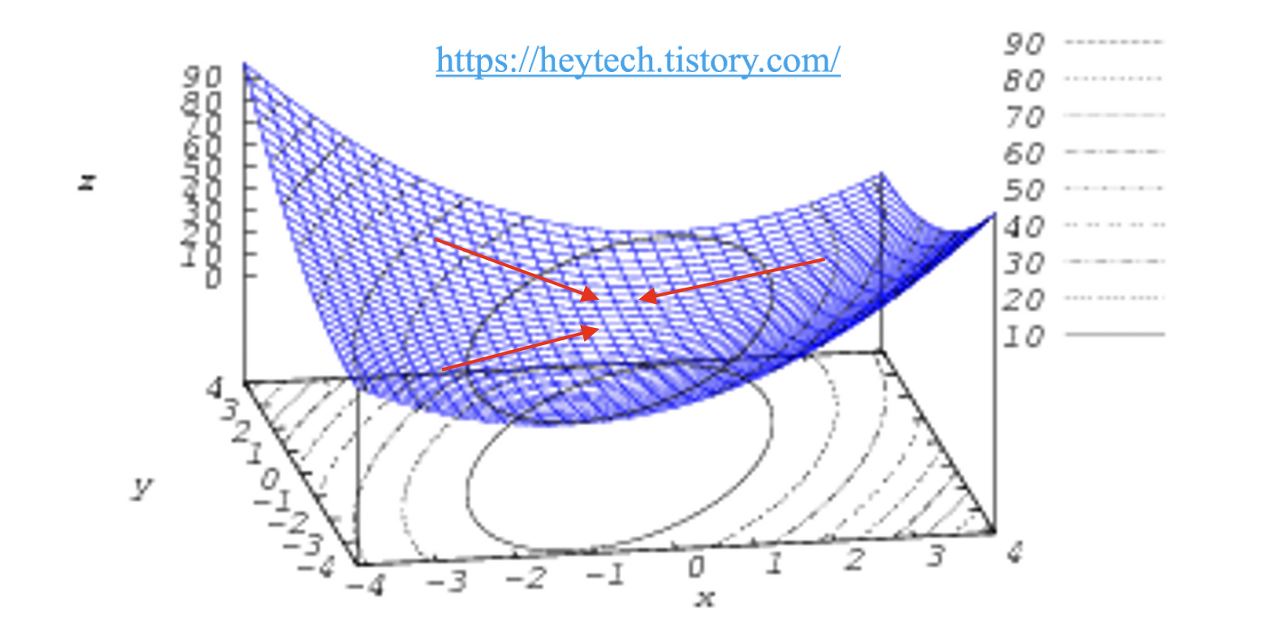 이러한 형태일 경우 최소점이 하나이기에 상관이 없지만 비볼록 형태(울퉁불퉁한 형태) 일 경우 한곳의 최저점에 도달하면 값을 최적화하지 못한다. (여기서 local minimum이란 한 지역의 최저점)
이러한 형태일 경우 최소점이 하나이기에 상관이 없지만 비볼록 형태(울퉁불퉁한 형태) 일 경우 한곳의 최저점에 도달하면 값을 최적화하지 못한다. (여기서 local minimum이란 한 지역의 최저점)
import numpy as np
## 코드 1
# 학습 데이터 생성 (단순한 선형 모델 y = 2x + 3을 생성)
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 3 + 2 * X + np.random.rand(100, 1)
# 경사 하강법 관련 설정
learning_rate = 0.1
n_iterations = 1000
m = len(X)
theta = np.random.randn(2, 1) # 초기 파라미터
# 경사 하강법 수행
for iteration in range(n_iterations):
gradients = 2/m * X.T.dot(X.dot(theta) - y) # 기울기 계산
theta = theta - learning_rate * gradients # 파라미터 업데이트
# 학습된 파라미터 출력
print("학습된 파라미터:", theta)
## 코드 2
## x = 입력 데이터 y = 정답 데이터, w,b는 랜덤
def RMSE(a, b):
mse = ((a - b) ** 2).mean() # 두 값의 차이의 제곱의 평균
rmse = mse ** 0.5 # MSE의 제곱근
return rmse
def loss(x, w, b, y):
predictions = model(x, w, b)
L = RMSE(predictions, y)
return L
def gradient(x, w, b, y):
dw = (loss(x, w + 0.0001, b, y) - loss(x, w, b, y)) / 0.0001
db = (loss(x, w, b + 0.0001, y) - loss(x, w, b, y)) / 0.0001
return dw, db
LEARNING_RATE = 1 # 상수(학습률)
for i in range(1, 2001):
dw, db = gradient(x, w, b, y) # 3, 4번: 모델이 prediction을 예측하고, 손실함수값을 계산함과 동시에 기울기 계산
w -= LEARNING_RATE * dw # 5번: w = w - η * dw 로 업데이트
b -= LEARNING_RATE * db # 5번: b = b - η * db 로 업데이트
L = loss(x, w, b, y) # 현재의 loss 값 계산
losses.append(L) # loss 값 기록
if i % 100 == 0:
print('Iteration %d : Loss %0.4f' % (i, L)) 요약 하자면
1. 데이터를 준비하고, 가중치와 편향을 랜덤으로 선택
2. 현재 w,b로 prediction(예측 결과)을 예측하고, 그를 통해 손실함수 계산
3. 손실함수 계산 값을 계산-> 기울기 계산 -> 계산된 기울기를 통해 w,b 업데이트 (2,3 반복)
4.지도학습
- 지도학습은 정답이 있는 데이터셋을 통해서 우리가 원하는 값을 찾아내려는 학습 방법
- 즉, 여러 특징(feature)들과 그에 맞는 정답(label)을 알려주고, 알고싶은 feature 조건에 대한 답을 예측하는것
- x에서 y 또는 입력에서 출력 매핑을 학습하는 알고리즘
- 학습할 예제를 제공(올바른 답변을 추가하는 것을 의미 -> input에 대한 label을 제공)
- 보통 의사결정트리, 랜덤 포레스트 및 gradient boosting machine을 사용해 작동
- 지도학습은 regression과 classification으로 나뉜다.
4-1 회귀(Regression)
- 연속적인 값(그래프)을 label(답)로 두고 예측하는 것 -> 예측 결과값의 연속성이 있는 경우로 생각 할 수 있다
- feature를 토대로 값을 예측하는 것
- 종속 변수가 수치형(float)
- 무한히 많은 가능한 숫자 중에서 숫자를 예측하는 방법
i) 선형 회귀(Linear Regression
- 알려진 다른 데이터 값을 사용해 알 수 없는 데이터의 값을 예측하는 데이터 분석 기법
- 종속 변수(알수 없는 변수)와 독립 변수(알려진 변수)를 선형 방정식으로 모델링
- 데이터를 직선에 맞추는 것을 의미
- 조건 : 선형성, 잔차 독립성, 잔차 정규성, 등분산성
- 주어진 입력 변수(또는 특성)와 가중치(weight)의 조합을 사용하여 종속 변수(예측값)를 예측하는 선형 모델을 찾는 것을 목적으로 한다.
- 단순 선형회귀와, 다중선형회귀로 나뉜다.
i-1) 단순 선형 회귀(simple Linear Regression)
- univariate linear regression이라고도 한다.
- 수식 : (여기서 는 종속변수 = 예측값, x는 독립변수, w는 가중치, b는 편향)
i-2) 다중 선형 회귀(Multiple Linear Regression)
-
독립 변수가 여러개인 분석기법 -> 특성들이 여러개 즉, x가 여러개
-
표기할 용어들
- : j번째 특성
- n = 특성의 수
- : i번째 학습 데이터의 모든 특성들(벡터라고 부른다)
- multivariate Linear Regresstion(다변량 선형 회귀)이 아니다
-
수식 :
- 여기서 와 는 행백터이다. 또한 은 선형대수적 내적을 의미한다.
import numpy as np
f = np.dot(w,x) + b4-2 분류(Classification)
- 주어진 데이터를 정해진 categry에 따라 분류하는 것
- 범주를 예측(범주는 반드시 숫자일 필요는 없다.)
- 숫자를 예측할 경우 회귀와 다르게 만드는 것은 분류는 작은 유한한 집합을 예측(중간의 값들은 예측 불가)
- 출력 클래스와 출력 범주라는 용어가 종종 서로 교환되어 사용되는데 동일한 의미
- 이진 분류와 다중 분류로 나뉜다
- 이진 분류 - 입력값에 따라 모델이 분류한 카테고리가 두가지인 분류 알고리즘.
- 양성 클래스 : 학습하고자 하는대상
- 음성 클래스 : 양성클래스를 제외한 나머지
- 다중 분류 - 입력값에 따라 모델이 분류한 카테고리가 세가지 이상인 분류 알고리즘
- 이진 분류 - 입력값에 따라 모델이 분류한 카테고리가 두가지인 분류 알고리즘.
- 알고리즘
- logistic regresstion
- Naive Bayes
- decision tree
- support vector machine(svm)
- k-nearest neighbor
i)로스지틱 회귀
- 이진 분류일 경우 시모이드 함수 사용
- 다중 분류일 경우 소프트맥스 사용
- 용어
- 이진 분류
- 시모이드는 =
- 오즈(odds) - 성공이확률이 실패 확률에 비해 몇배 더 높은가를 나타낸다 즉, 비율
- 수식 : = (여기서 는 x라는 변수가 주어졌을떄 y라벨이 1일 확률)
- 로짓 변환(logit)
- 오즈에 로그를 취한 함수 형태
- 입력값 p의 범위가 0~1 일때 []를 출력
- logit(p) = log(odds) =
- 로지스틱함수
- 로짓 변환의 역함수로 해석
- f(p)=logit(p) = log(odds) = = = (행렬적으로 표현한것)을 역함수로 해석하였을떄 p = = = -> p에 대해서 정리를 하면 p= 이것을 묶고 p에 대해서 정리를 하면 p =
- = =
- 따라서 선형회귀랑 sigmoid결합
- 시그모이드 함수는 =인데 -x 부분에 WTX가 대입된 형태이기 때문
그래프
x에 대해서 y가 라벨이 1일 확률이 0~1 까지 숫자로 연결이 되는 것
-
로지스틱 회귀 모델은 로지스틱 함수 형태의 회귀 모델
-
위에 그래프에서 x축이 로 바뀌어진것
-
=
- wX값에 따라 예측값이 달라진다
-
손실함수 정의
-
경사하강법을 사용하지만 그안에 L(즉, 로스 함수)에 대한 내용
-
베이즈 정리
- -> 조건부 확률은 w가 x인 조건이 들어왔을때는 w,x가 둘다 존재할 확률/x일 확률이다 이따 = 또한 w가 조건으로 들어왔을경우에는 형태가 된다
- P(X|w)P(w) 여기서 p(x)를 삭제 시킨이유는 x는 데이터로 주어지는 값이기 계산 할수 있는 값이어서 알던지 모르던지 중요하지 않다는 의미
- 사후확률 () : 데이터가 주어졌을때 가설에 대한 확률 분포 즉, 신뢰도
- 우도확룰 () : 가설을 잘 모르지만 안다고 가정했을 경우 주어진 데이터의 분포
- 모델의 파라미터 값을 모르지만 w로 표현했을 경우 주어진 데이터의 분포 -> 우도 확류은 w에 대한 함수로 데이터의 분포를 표현
- i.i.d(독립적이면서 같은 분포를가진다)라고 가정하고, pdf의 곱으로 표현
- w : (평균), (분산)
- PDF :
- 즉 우도 확률(likehood) =
- 사전 확률() : 데이터를 보기전, 일반적으로 알고 있는 가설의 확률
- 이 확률 둘을 통해서 가설(파라미터)를 추정하는 방법으로 mle와 map 두가지가 있다
-
maximum likelihood estimation
- 현재의 데이터분포가 나올 확률이 가장 높은 파라미터는 우도 확률을 최대로 만드는 파라미터이기에 이것을 찾는것 방법론
- 가장 간단한 파라미터 추정법이지만 데이터에 따라 값이 민감 (데이터가 많을수록 좋다)
-
maximum a posterior
- 데이터에 의존적인 MLE의 단점을 해결하기 위해 사용되는 방법론
- 주어진 데이터에 대해 최대 확률을 가지는 파라미터를 찾는 방법
-
- 바론 계산은 불가능(우리가 해결해야할 과제가 x를 주고 최적의 파라미터 w를 구하는 것인데 x를 주고 w가 나올 확률을 구하는 것) 그래서 위에 우도확률과 사전확률의 곱으로 근사할 수 있다고한것
- 따라서 사전확률의 정확도에 따라 추정의 정확도가 달라진다
-
베르누이 분포
- 두가지 결과값만을 가지는 실험(베르누이 시행)에 따라 0또는 1의 값을 대응시키는 확률 변수를 베르누이 확률 변슈라칭하고 이것의 분포를 베르누이 분포라한다.
- (파라미터는 p하나이다)
- L = (여기서 L은 우도확률)
-
로지스틱회귀는 mle로 푼다
- = = (여기서 는 시그모이드) -> 여기서 p값이 을 베르누이 분포로 해석 가능 (즉,가 0.7이면 y가 1일 확률이 0.7이기에 1이라고 판단한것 )
- 로지스틱 함수에서의 우도함수
- (로지스틱 회귀는 이진분류이기에 베르누이분포와 연결해서 해석하고 표현한것 -> 어떤 값이 주어졌을때 는 y가 1일 확률 (1-\sigma(W^TX_i))^{1-y_i}$는 y가 0이었을때 값) 이것을 maximize하는 것이 목표
- 따라서 로그함수를 취하는데 log는 단조 증가이기에 ln L을 최대로 만드는 w는 동일 -> 편하게 하기위해서 ln값을 취해 지수함수를 내려서 계산
- ->
- 하지만 우리가 하는것은 로스 값을 최소로 해야하기 때문에 max를 min으로 바꾸기 위해 -를 만들어서 사행 즉, $-ln L $이 손실함수
- 경사하강법
- 미분을 하기위해 정리를 하면 =
- =
- 즉
-
-
다중 분류 모델
- 분류해야되는 클래스가 여러개인 모델
- 이진 분류모델에서 확장이 필요하다
- softmax함수 사용
- 다중 분류 문제를 위한 비선형 함수
- (k는 클래스의 갯수) , 유도과정은 추후에 정의
- softmax함수는 시그모이드 함수를 일반화한 함수 -> 시그모어 함수처럼 결과값을 0~1 사이의 숫자들로 정규화
- 하나의 클래스에만 대응 되게 하는데 데이터 전처리에서 올렸던 원-핫 인코딩 기법이다.
- 손실 정의
- cross entropy loss로 오차를 정의한다
- 위에 우도함수에서 정의했던 것처럼 정의를 하면 1일 경우와 아닐경우로 나누고 아닌경우에는 모든항이 0이 된다
0) 이진 분류 알고리즘
i) logistic regreesion
- 일반적이고 효과적인 분류 알고리즘
- 선형 회귀와 동일하게 선형 방적식을 학습
- 어떤 범주에 속할 확률을 0~1 사이의 값으로 예측하고 확률에 따라 분류 -> 즉 확률값(연속적)을 출력하고 이를 이용해 분류
- 즉 독립변수의 선형 결합을 이용해 사건의 발생가능성을 예측하는데 사용 되는 통계 기법
- 용어
- 로지스틱 함수(시그모이드 함수) : k개의 설명 변수에서 사건(A)이 발생할 확률 가 발생 할 확률 =
이 내용에 대한 자세한 설명은 이링크에서 설명 - odds : 사건이 발생할 확률을 발생하지 않은 확률로 나눈것
- 수식 =
- 해당값에 log를 취한 것을 log-odds라고 한다.
- 로지스틱 함수(시그모이드 함수) : k개의 설명 변수에서 사건(A)이 발생할 확률 가 발생 할 확률 =
5 model
i) arima
시계열 데이터 회귀(time series data regression)
시계열
- 시간의 흐름에 따라 관측되어 시간의 영향을 받게 되는 데이터
- 구성 요소 : 추세변동(trend), 순환변동(cycle), 계절변동(seasonal variations), 우연변동(random flucation)
- trend : 시간이 경과함에 따라 관측값이 지속적으로 증가하거나 감소하는 추세를 갖는 경우의 변동
- cycle : 주기적인 변화를 가지는 주기가 긴 경우의 변동
- seasonal vaiations : 계절이나 주별 과 같은 주기적인 요인에 의한 변동
- random flucation : 규칙적인 움직임과는 무관하게 랜덤한 요인에 의해 나타나는 변동
- 백색 잡음 : 평균이 0이고 분산이 일정한 시계열 데이터
arima모델
- 정상 프로세스 : 시간에 관계없이 평균과 분산이 일정한 시계열 데이터
- acf(자기상관(해당 시계열이 자기자신과 어떤 상관관계를 가지는지)함수)는 함수이다. 그것을 그래프로 표현한것. 자기자신과 자기자신 바로 이전의 오토코렐레이션이 lag1 두시점 시프트한건 lag2
- 이것에대한 플랏을 그리고 스테이블한지 아닌지는 플랏을 보고 판단가능. 특정한 패턴이 없이 랜덤하게 나타나면 스테이셔널이라고 한다
- 비정상 프로세스 : 스테이셔널하지 않은것
- acf를 찍으면 일정한 패턴이 있다.
- 떨어졌다올라가는 것도 nonstational이라고 한다.
ar,ma,arma는 데이터가 스테이셔너리해야한다. non-stationary면 바꾸어야한다 -> differencing하는것
-
ar models
-
y(t) = ϕ(0) + ϕ(1)+y(t-1) + ...+ ϕ(p)y(t-p) + ϵ(t)
- 여기서 y는 t시점에 관심있는값
- 수식 뜻은 y1시점 2시점 p시점 전값을 x삼아 회귀모델을 만든다
- 다중 회귀모델과 달리 y의 자기 자신가지고 모델링하기에 독립적이지 않는다 계수(ϵ)을 타일로해 최소제곱법 불가능
*ϕ는 가중치라고 생각하면 될듯 - p는 indenvalueable의 갯수 (파라미터의 갯수)
-
ma model
- t시점의 데이터를 t시점의 예측오차(백색잡음)들로 표현
- 연속적인 예측오차텀으로 y의 관계를 모델링
- 수식
- θ (0) + ϵ(t)+θ(1)ϵ(t-1) ...+θ(q)ϵ(t-q)
- θ 계수로 백색잡음의 이전 시점 값들과 관계.
- q는 세타의 갯수
- θ (0) + ϵ(t)+θ(1)ϵ(t-1) ...+θ(q)ϵ(t-q)
-
arma model
- 자기자신의 시차의 값들과 t시점의 예측오차값을 가지고 표현 ma와 ar을 합친것
-
arima
- differencing을 하는 것을 integration이라고한것이고 arima의 i는 몇번했는지 적는것
- ar은 p i는 d ma는 q라고한다.
- d는 몇번 differencing 했는지
-
differencing(차분)
- 현시점 데이터에서 d시점의 데이터를 뺸것
- ex) 예를 들어 x[2,7,10,5,8]이 있으면 x[ ,2,7,10,5]를 뺸것이다 y=[5,3,-5,3]가 결과 첫번째 데이터와 마지막는 포기가 되는것이다
- 수식 : y(t) = x(t)-x(t-d)이것이다(하나씩 시프트한거라고 생각하면 될듯)
arima모델 프로세스
- 데이터 전처리(핵심은 데이터가 stational해야하는 non이면 바꿔줘야됨) -> 시범적인 모델을 찾아야된다. -> 파라미터를 추정후에 -> 괜찮은지 체크한다. 괜찮지 않으면 다시돌아가 모델을 찾는다 -> 괜찮으면 최종모델적용
arima모델 선택 하기
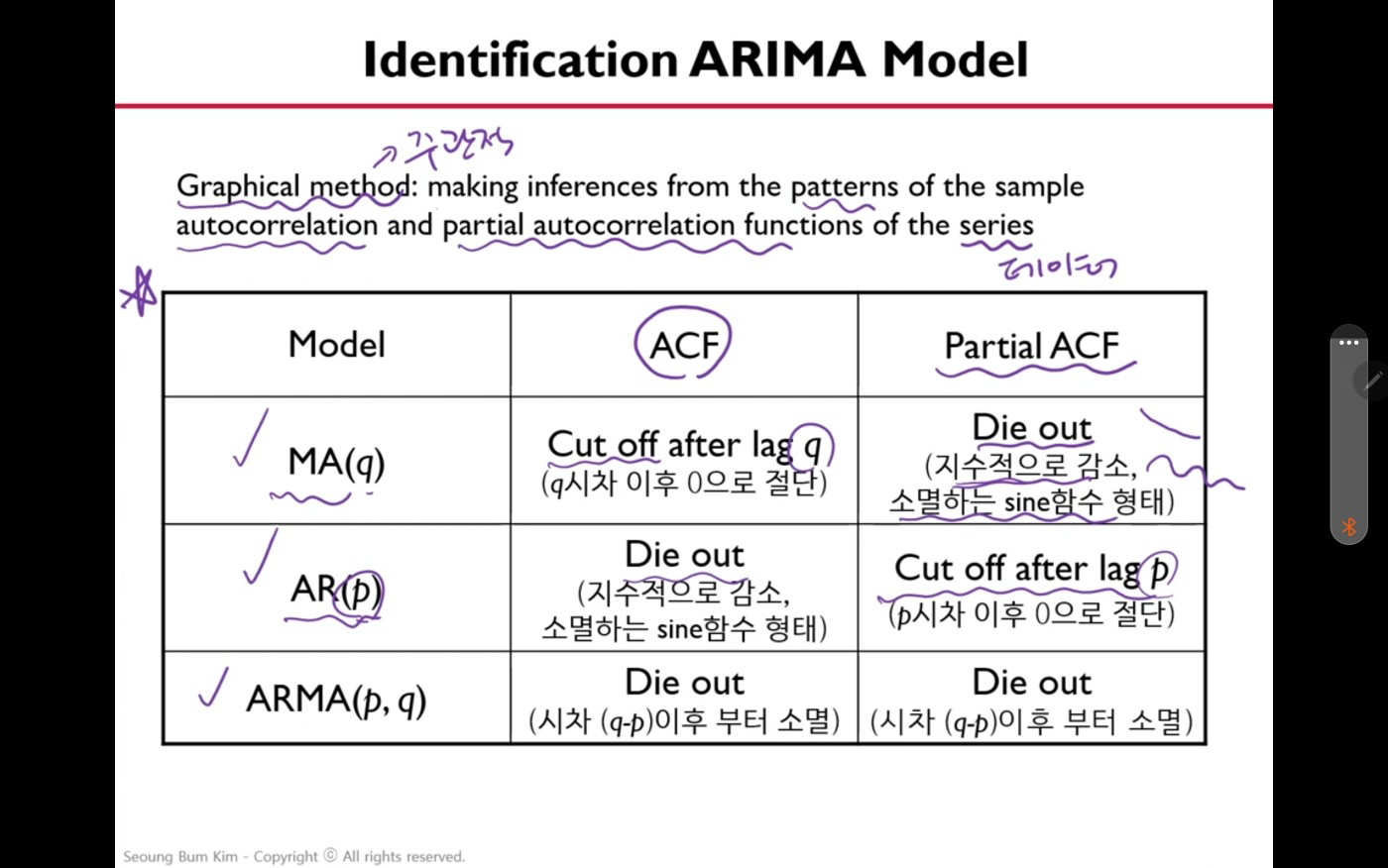
ii) 의사결정 나무
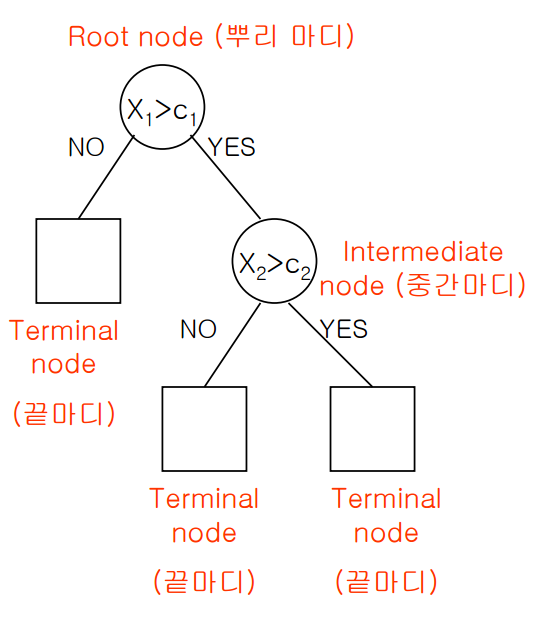
- 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측가능한 규칙들의 조합으로 나타내는 분석기법 -> 기준에 따라 데이터를 분류 -> 데이터에 내재되어 있는 패턴을 변수 조합으로 나타내는 예측/분류 모델을 트리의 형태로 만드는 것
- 데이터를 2개 혹은 그이상의 부분집합으로 분할(균일하게 분할해야한다.)
- 분류에서는 분할 시 데이터가 비슷한 범주를 가지고 있는 관측치끼리 분할
- 예측에서는 비슷한 수치를 가지고 있는 관측치 끼리 분할
- 의사결정 트리는 분류나 회귀 둘다 가능
- 회귀일 경우 terminal node의 종속 변수의 평균을 예측값으로 반환 이때 예측값 종류는 terminal node의 개수와 일치
- 분류일 경우 trminal node는 종속변수의 최빈 값을 예측값으로 반환
- 용어
- 불순도 : 복잡성을 의미하며, 범주안에 서로 다른 데이터가 얼마나 있는가를 뜻함. -> 복잡할수록 불순도는 높아진다.
- 엔트로피 : 불순도를 측정하는 지표 (0과 1사이값을 가진다)
- 수식 : (여기서는 A 영역에서 k 범주에 들어가는 비율을 의미한다 )
- 만약 2개의 영역이 있다고 가정하면
가된다.
- 만약 2개의 영역이 있다고 가정하면
- 수식 : (여기서는 A 영역에서 k 범주에 들어가는 비율을 의미한다 )
- 지니지수 : 불순도를 측정하는 지표 중 하나
- 수식 :
- 정보이득 : 분기 이전의 불순도와 분기 이후의 불순도 차이.
- 분류나무는 구분을 한 다음 각 영역의 순도가 증가, 불순도 혹은 불확실성이 최대한 감소하도록 하는 방향으로 학습을 진행
6. Evaluation Metric
6-1. Accuracy
- 실제 데이터가 얼마나 같은지를 판단하는 지표
6-2. 혼동행렬/오차행렬(confusion metrix)
- 정확도 = 맞춘 문제수 /전체 문제수로 라고 하는데 정확도는 맞춘 결과와 틀린 결과를 세부적으로 알려주지 않는다.
- 모델의 예측결과와 실제 정답 간 관계를 나타낸다
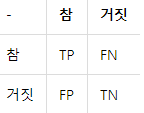
- True/False는 정답을 맞췄는지 여부, Negative/Postive는 제시 한 정답이다. TP는 양성으로 제시하고 정답. FN은 부정이라고 헀는데 틀린것이다.
- 정밀도
- 양성이라고 대답한 전체 데이터에 대한 비율
- 수식 : TP/TP+FP
- 재현율(민감도)(recall)
- 실제 값이 양성인 데이터의 전체 개수에 대한 TP비율 -> 양성인 데이터중 얼마나 양성인지 예측헀는지 비율
- 수식 : TP/TP+FN
- 특이도 (Specificity,TNR)
- 현실이 실제로 부정일 떄 예측 결과도 부정일 확률 -> 특이도가 높다는 것은 현실이 부정일때 그 예측도 제대로 이루어지고 있다는 것을 의미
- 수식 :
- FPR = 1 - TNR
6-3. f1-score
- 정밀도와 재현율의 조화평균으로 주로 분류 클래스간 데이터가 분균형이 심각할 때 사용
- 0과 1 사이의 값을 가진다
- 수식
- f1 - score를 개선하는 방법
- 샘플링 (balancing sampling)
- 예측 임계값 조정(thershold adjustment)
- 단점
- 오차 분포에 대한 정보를 제공하지 않는다, 다중 클래스 분류에 최적화되어있지 않다.
6-4. ROC 곡선과 AUC
- ROC curves
- 이진 분류 모델에서 임계값을 변화시켰을 때, 모델의 precision과 1에서 모델의 특이도를 각각 x,y 축으로 그린 곡선 -> 즉 1 세로축에는 민감도, y축에는 거짓 긍정이 그려져 있는것

- AUC
- roc곡선의 하단 넓이를 구한 값
7.비지도 학습
- 정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화해 새로운 데이터에 대한 결과를 예측하는 것
- 데이터 내에서 어떤 특정한 구조나 패턴을 찾는 것
- 입력값은 있지만 결과값(label)이 없는것
비지도 학습에 대해서는 나중에 추가

유익해요