웹 - 부족한 부분 채우기 (1)
CORS
1. CORS가 무엇인지 간단하게 설명해주세요.
일반적으로 웹 브라우저는 자바스크립트로 접근할 수 있는 웹 자원은 같은 출처에 속한 것만 접근이 가능하며, 이를 "Same-Origin Policy"라고 합니다.
이는 웹 애플리케이션의 안정성과 잠재적 위험을 줄이기 위한 조치입니다.
하지만, 일부 상황에서는 이러한 제약을 우회해야할 필요가 있을 수 있는데, 이 때 CORS가 사용됩니다.
교차 출처 리소스 공유(Cross-Origin Resource Sharing)는 추가 HTTP 헤더를 사용하여, 한 출처에서 실행 중인 웹 애플리케이션이 다른 출처의 선택한 자원에 접근할 수 있는 권한을 부여하도록 브라우저에 알려주는 체제입니다.
웹 애플리케이션은 리소스가 자신의 출처(도메인, 프로토콜, 포트)와 다를 때 교차 출처 HTTP 요청을 실행합니다.
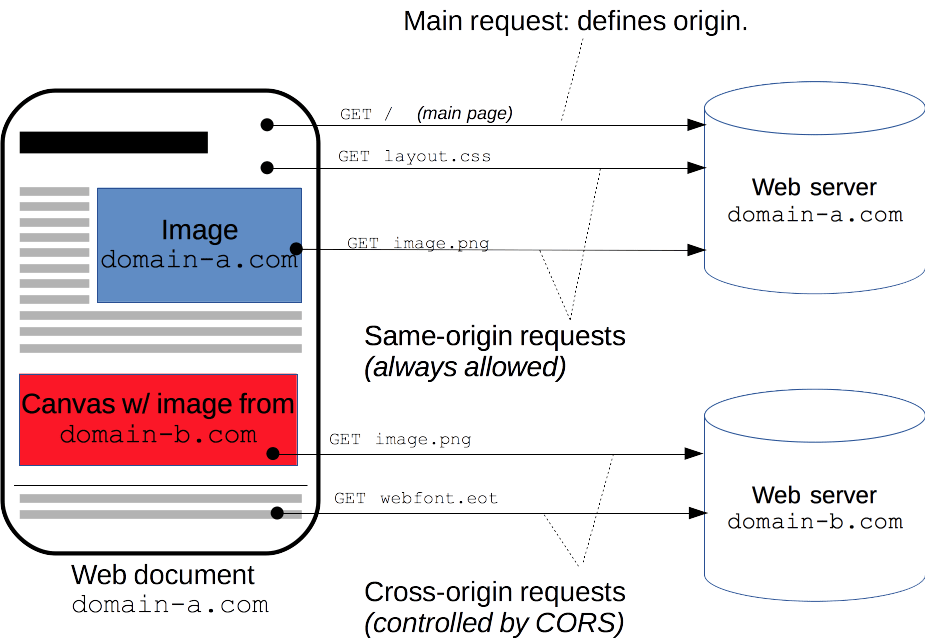
1-A. 브라우저에서 AJAX를 통해 다른 도메인의 API에 요청을 하게될 경우 어떠한 일련의 과정들이 이루어지게 되고, 어떤 과정을 통해서 브라우저가 Block을 하게되는지 설명해주세요.
브라우저가 교차 출처에 대해 AJAX 요청을 진행하게 될 경우, Preflight Request (이하 사전 요청)를 진행하게 됩니다. 사전 요청은 OPTIONS 메서드를 통해 다른 도메인의 리소스로 HTTP 요청을 보내고 실제 요청이 전송하기에 안전한지 확인하는 절차입니다.
해당 사전 요청을 통해 현재 브라우저에서 사용하고 있는 헤더의 스니펫, 본 요청의 메서드와 오리진 등이 전달되며, 사전 요청을 통해 응답 헤더의 Access-Control-Allow-Origin을 확인해 CORS 가능 여부를 판단합니다.
만일 요청하는 오리진과 응답 헤더의 Access-Control-Allow-Origin이 다르다면 브라우저에서 이후 요청을 Block하게 됩니다.
1-B. preflight를 Target Url에 날리게된다면, CORS가 Allow인지 어디를 통해서 브라우저가 전달받게 되나요? (Payload)
사전 요청의 응답 헤더 중 Access-Control-Allow-Origin을 통해 해당 오리진이 허용되었는지 확인할 수 있습니다. 또한 Access-Control-Allow-Headers와 Access-Control-Allow-Methods를 통해 헤더와 메소드에 대한 허용 여부를 브라우저에게 전달해줄 수 있습니다.
1-C. 모든 Request에 preflight가 날라가나요? (크로스 오리진 한정)
일부 요청은 CORS Preflight를 트리거하지 않습니다.
이 경우를 "Simple Requests"라고 일컫으며, 다음 조건을 충족하는 경우 "Simple Requests"로 동작합니다.
자세한 내용은 MDN을 참고해야합니다.
-
다음 중 하나의 메서드
GET
HEAD
POST -
Content-Type 헤더가 아래의 값들인 경우
application/x-www-form-urlencoded
multipart/form-data
text/plain -
요청에 사용된 XMLHttpRequest.upload 객체에 이벤트 리스너가 등록되어 있지 않을 때
-
ReadableStream 객체가 요청에서 사용되지 않을 때
1-D. 어떤 메소드에 대해 preflight가 날라가나요? (simple request 참고)
Simple Requests가 동작하는 GET, HEAD, POST를 제외한 모든 메소드의 경우 preflight가 트리거됩니다.
COOKIE
1. 쿠키가 무엇이고 어떻게 생성이 되나요?
HTTP 쿠키는 서버가 사용자의 웹 브라우저에 전송하는 작은 데이터 조각입니다.
브라우저는 그 데이터 조각들을 저장해 놓았다가, 동일한 서버에 재 요청 시 저장된 데이터를 함께 전송합니다.
즉 모든 요청마다 쿠키가 함께 전송되기 때문에, 성능이 떨어지는 원인이 될 수 있으므로, 클라이언트 데이터를 보관할 목적이라면 활용 목적에 따라 웹 스토리지와 함께 구분해 사용되어야 합니다.
쿠키는 서버 요청에 대한 반환 헤더를 통해, 혹은 브라우저의 document.cookie를 통해 생성할 수 있습니다.
1-A. 모든 서버에서 전송되는 모든 데이터가 쿠키에 담기게 되나요? 쿠키가 담기게 되는 directive가 있는데 이 것이 무엇인지 아시나요?
HTTP 요청을 수신할 때, 서버는 응답과 함께 Set-Cookie 헤더를 전송할 수 있습니다.
쿠키는 보통 브라우저에 의해 저장되며, 그 후 쿠키는 같은 서버에 의해 만들어진 요청들의 Cookie HTTP헤더 안에 포함되어 전송됩니다.
1-B. 브라우저 사이드에서는 쿠키를 생성할 수 있나요?
브라우저에서도 Document.cookie를 사용해 만들어질 수 있습니다.
HttpOnly 플래그가 설정되어 있지 않다면, 쿠키들은 자바스크립트로부터 잘 접근될 수도 있습니다.
Hydration
1. Hydration이 무엇인지 간단하게 설명 부탁드립니다.
Hydrate는 Server Side 단에서 렌더링 된 정적 페이지와 번들링된 JS파일을 클라이언트에게 보낸 뒤, 클라이언트 단에서 HTML 코드와 React인 JS 코드를 서로 매칭 시키는 과정을 의미합니다.
서버에서 생성한 HTML 코드에서 React 요소들을 찾아 상태를 적용하고, 이벤트 리스너를 설정하고, 컴포넌트를 새로 만들지 않고 존재하는 컴포넌트에 상태를 적용하는 작업을 수행합니다.
Script
1. 브라우저가 HTML을 파싱할 때, Script 태그를 만나게되면 어떠한 동작을 할까요?
브라우저가 HTML을 파싱하는 도중 Script 태그를 마주치게 된다면, Script가 다운로드 되고 완전히 실행되기 전까지는 HTML 파싱이 중단되게 됩니다.
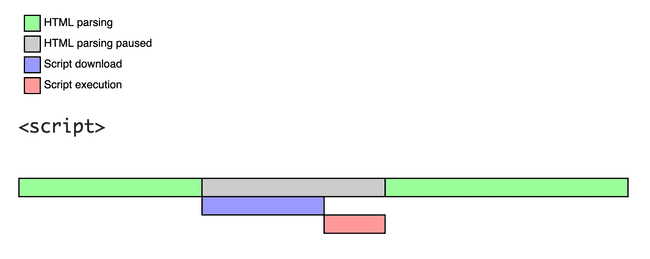
네, 사용자에게 치명적입니다.
따라서 Bootstrap과 같은 프레임워크에서는 스크립트의 선언부를 HTML Body 태그의 끝 부분에서 작성할 것을 권장하고 있습니다.
1-A. async와 defer Attribute는 Script의 동작 방식을 어떻게 바꿀까요?
async 스크립트는 DOM 렌더 과정을 방해하지 않도록 병렬로 로드합니다.
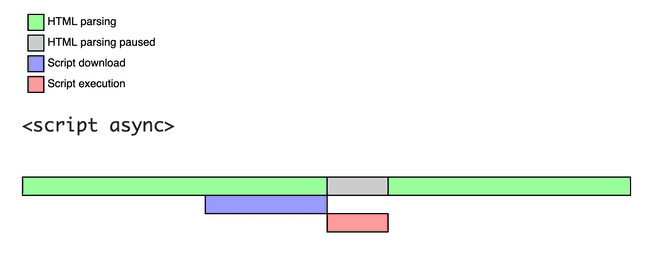
이는 브라우저가 DOM을 구성하는 동시에 백그라운드에서 스크립트를 불러올 수 있음을 의미합니다. 즉, async 속성을 적용하면 스크립트를 불러오는 과정에서 DOM 렌더를 차단하지 않도록 보장합니다.
하지만, async 스크립트는 오직 파일을 불러오는 것만 병렬로 실행한다는 것이 중요합니다.
파일의 로딩을 마치게 된다면, 그 즉시 DOM 렌더를 멈추고 async 방식으로 불러온 스크립트 파일의 해석을 시작합니다. 때문에 async 속성으로 파일을 불러온다고 해도, 스크립트의 해석이 얼마나 오래 걸리는지는 스크립트의 파일의 오버헤드에 달려있습니다. 따라서 DOM에 접근하는 스크립트를 async 방식으로 불러오는 것은 권장되지 않습니다.
이러한 특성 때문에 async 스크립트는 실행 순서가 보장되지 않습니다.
오버헤드가 다른 각각의 스크립트가 로드된다면, 먼저 로드되는 스크립트가 먼저 실행되기 때문입니다. 이 때문에 서로 의존성이 있는 스크립트일 경우 제대로 동작하지 않을 수 있습니다. 또한 DOM과 별개로 완전한 비동기로 동작하기 때문에 DOMContentLoaded 이벤트 콜백으로 로드를 보장받을 수 없게 됩니다.
따라서 async 스크립트는 DOM에 직접 접근하지 않거나, 다른 스크립트에 의존적이지 않은 스크립트들을 독립적으로 실행해야할 때 효과적입니다. (ga 등)
defer 스크립트 역시 async와 비슷하게 동작합니다. 다만 차이점이 존재한다면, 로드가 완료되고 즉시 그 내용이 실행되는 async 스크립트와는 다르게, defer 스크립트는 모든 DOM이 로드된 후에야 실행됩니다.
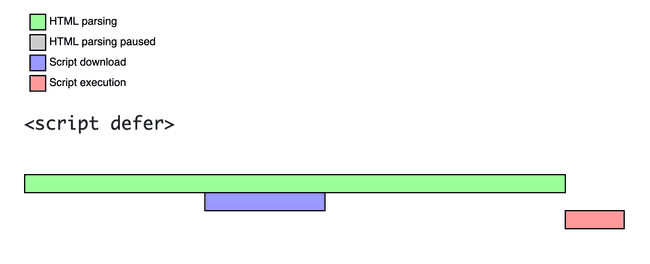
또한 두 가지 특성이 더 있는데, 첫 번째는 선언한대로 실행 순서가 보장된다는 것입니다.
실제로 더 빨리 로드되는 스크립트가 있다고 하더라도, 실행은 항상 선언한 순서대로 실행됩니다. 물론 스크립트 파일을 제외한 DOM 구성이 끝난 이후에도요.
두 번째로 defer 스크립트는 단순히 먼저 로드한 스크립트라 할지라도, 실행하는 시점을 지연시키는 것이기 때문에, DOMContentLoaded 이벤트가 발생하기 전에 이미 실행된 상태입니다.
이 때문에 기본적으로 DOM의 모든 엘리먼트에 접근할 수 있고, 실행 순서도 보장하기 때문에 가장 범용적으로 사용할 수 있는 속성입니다. 또한 실행 순서도 보장하기 때문에 스크립트 파일 끼리의 의존성이 있는 경우에도 정답이 될 수 있습니다.
캐싱
1. 웹에서 브라우저가 캐싱을 하는 정책이 어떻게 되는가요? 어떻게 브라우저가 리소스에 대한 캐시를 판단하는지 알려주세요.
브라우저는 일반적으로 HTTP 캐시를 구현하고 있습니다.
해야할 일은 서비스를 제공하는 서버로 부터 알맞는 HTTP 헤더를 내려받아 브라우저에게 응답 캐시를 언제 얼마만큼 보유할지 가이드하면 됩니다.
1) ETags
서버는 ETag를 HTTP 헤더에 담아 유효 토큰으로 통신할 수 있습니다.
유효 토큰은 효율적인 자원 업데이트 체크를 가능하게 하는데, 리소스가 바뀌지 않는다면 아무 데이터도 전달되지 않는다는 의미입니다.
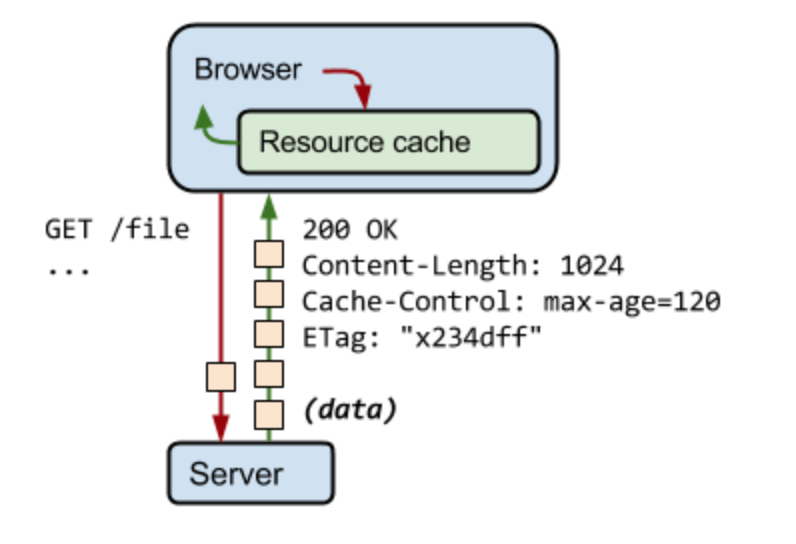
위의 응답에서 초기 요청 이후 120초가 지났다고 가정을 하고, 브라우저가 동일한 자원에 대해 새로운 요청을 보냈다고 가정해보겠습니다.
첫째로 브라우저는 로컬 캐시를 확인하고 이전의 응답을 찾아볼 것입니다.
불행히도 브라우저는 응답 시간이 만료되었으므로 이전의 응답을 찾을 수 없게 됩니다.
이 시점에서 브라우저는 새로운 요청을 보내고 새로운 전체적인 응답을 기대하게 되는데, 이 과정은 매우 비효율적입니다. 서버측 자원이 바뀌지 않았는데에도 불구하고 이미 캐시되어 있는 자원을 다시 다운로드하기 때문입니다. (max-age로 인해 만료기간이 지났기 때문입니다.)
따라서 브라우저는 ETag 헤더를 정의해 문제를 해결하도록 가이드라인을 제공하고 있습니다.
서버는 자원에 대한 요청 시 해당 자원에 대한 중재 토큰을 생성합니다.
해당 토큰은 해시값 또는 파일 내용에 대한 지문이될 수 있습니다.
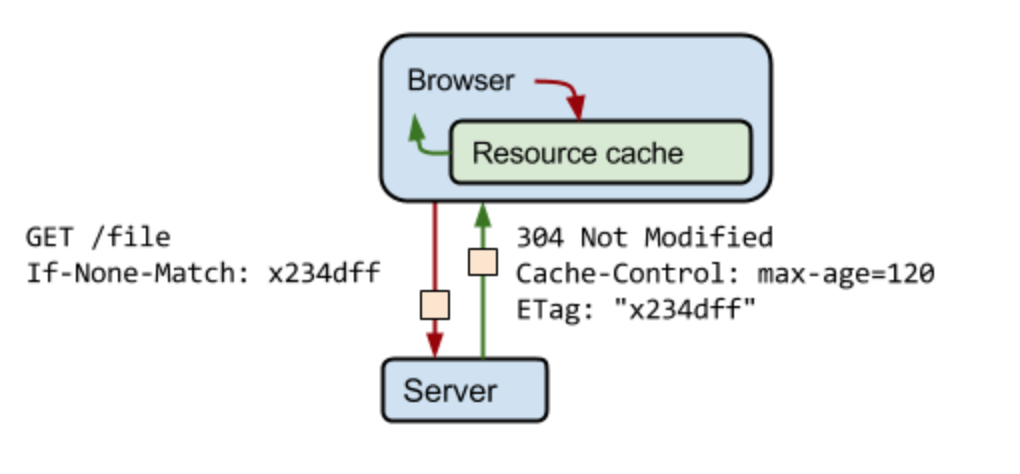
클라이언트는 ETag 토큰을 HTTP Request 헤더의 "If-None-Match"에 담아서 보내면, 서버는 토큰을 현재 자원과 비교합니다.
토큰이 바뀌지 않았다면 서버는 "304 Not Modified"를 리턴하는데, 이 것은 브라우저에게 너가 이미 가지고 있는 캐시에서 (만료는 되었지만) 바뀐것이 없으니 다시 120초의 시간을 재할당하라고 알려줍니다. 다운로드를 다시 할 필요가 없으니, 시간과 대역폭을 절약할 수 있다는 의미가 되는 것입니다.
2) Cache-Control
각 자원을 HTTP 헤더의 Cache-Control을 통해 정의할 수 있습니다.
해당 속성은 누가 응답을 어떤 조건에서 얼마나 캐시할 수 있는지를 정의합니다.
성능 최적화의 관점에서 가장 좋은 요청은 서버와 통신하지 않는 요청입니다.
로컬에 복사되어 있는 응답(=캐시)은 네트워크 레이턴시를 줄여주고 데이터 통신에 드는 비용을 없애줍니다.
대표 적인 Cache-Control의 지시어는 다음과 같습니다.
-
max-age
max-age는 지정된 초 만큼 응답값을 캐싱합니다.
만일max-age=86400이라면, 응답을 하루동안 캐싱하여 서버와 통신하지 않고 복사된 캐시 데이터를 사용하게 됩니다. -
no-cache, no-store
no-cache는 매 요청마다 ETag를 검사합니다. 이 뜻은max-age가 0이라는 의미와 동일한데, 결과적으로 적절한 유효 토큰(ETag)이 존재한다면,no-cache는 캐시 응답을 체크하기 위해 왕복 통신이 발생하게 된다. 하지만 자원이 바뀌지 않았을 때 다운로드는 피할 수 있다. 정확하게 하기 위해 부연 설명하자면, 캐시가 있다면 요청자체를 하지 않지만no-cache로 한다면 매번 요청을 진행하여 ETag를 검사합니다.
반대로 no-store은 반환된 응답의 어떤 버전이라도, 브라우저에게 캐시를 하지 말라는 설정입니다. 결과적으로는 매번 유저가 자원을 요청할 때, 요청은 서버로 보내지게되고, Stale 하지 않은 전체 응답이 다운로드 됩니다.
- public, private
응답이 public으로 되어있다면, 응답 코드가 정상적으로 캐시할 수 있는 코드가 아니더라도, HTTP 검증과 연관되어 있더라도 어찌됐건 캐시할 수 있다는 의미입니다.
대부분의 경우에는 필요가 없는데, 왜냐하면 max-age와 같은 설정을 통해 명시적으로 캐싱할 수 있기 때문이다.
private의 경우 응답을 캐시할 수는 있지만, 응답은 전형적으로 말단 유저를 타겟으로 하고 중간 매개체들은 캐시할수 없다는 의미입니다. 예를 들어, 유저의 브라우저는 개인 정보가 있는 HTML 페이지를 캐시할 수 있지만, CDN은 페이지를 캐시할 수 없다는 말이 됩니다.
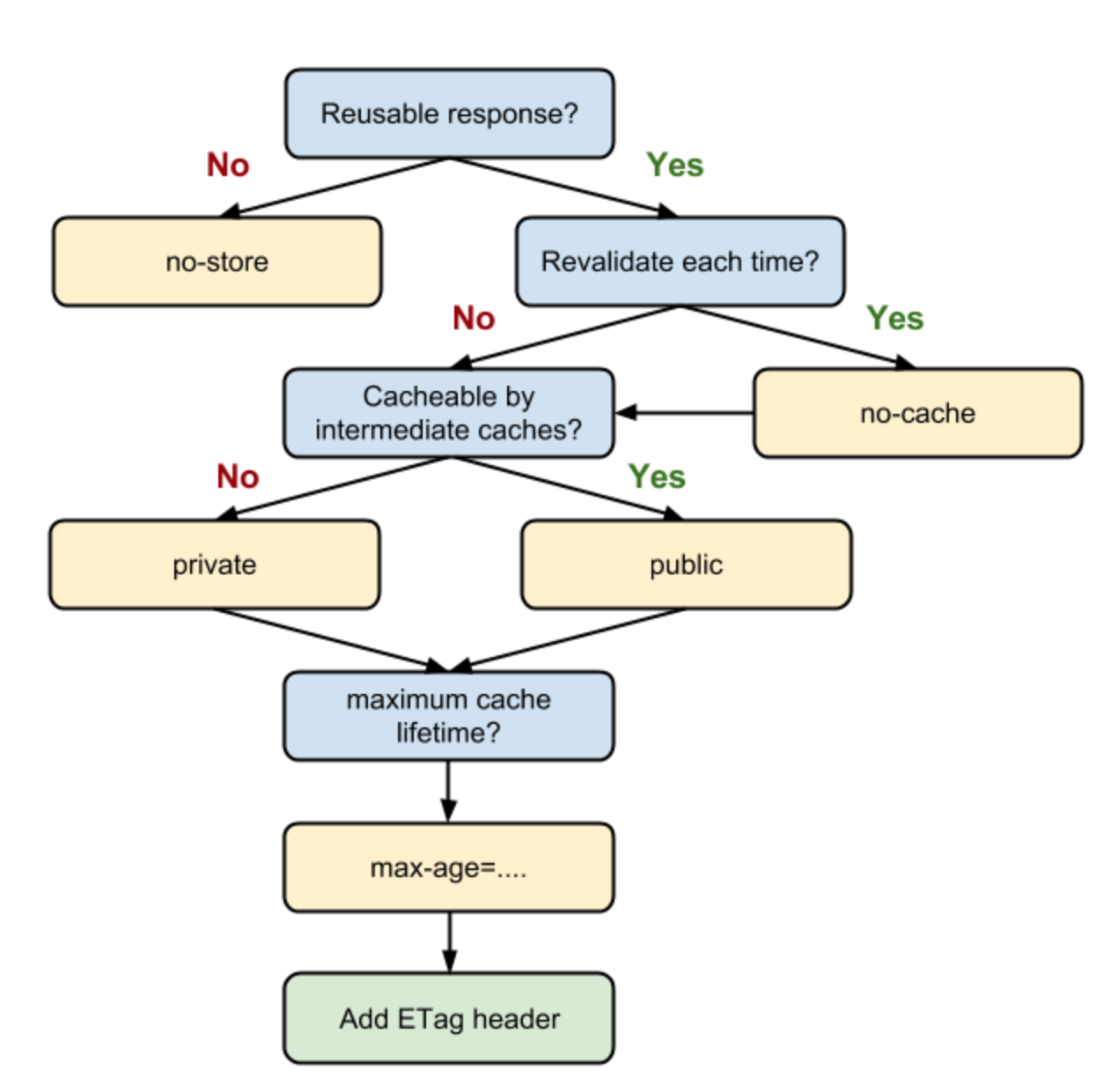
1-A. 그러면 브라우저가 동일 리소스에 대해 요청할때 해당 데이터가 캐싱이 만료되었는지 어떻게 알 수 있나요?
