8.20 진행한 CS 스터디의 주제는 다음과 같다.
- 남은 운영체제 파트 (#16 ~ #22 : CS 스터디-2에 이어서)
- 네트워크 파트 (#1 ~ #7)
조사하고 공부한 질문들 바로 들어가보자.
16. Thrashing 이란 무엇인가요?
👉 스레싱(Thrashing)이란 페이지 부재율(Page fault)이 증가하여 CPU 이용율이 급격하게 떨어지는 현상을 얘기한다. 스레싱이 발생하는 이유는 프로세스를 처리하는 시간보다 메모리에 적재되지 못한 페이지로 인하여 페이지 교체에 드는 시간이 증가하게되고 그로 인해 CPU이용률이 떨어지게 된다.
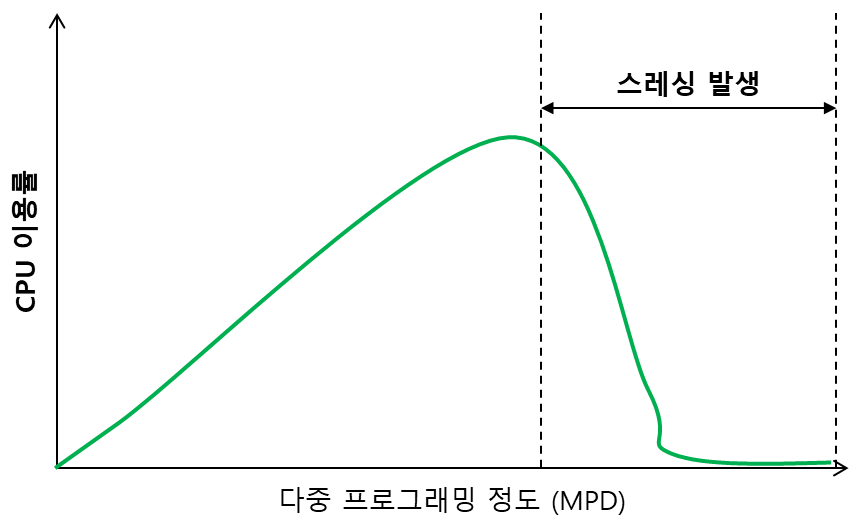
사용하는 프로세스가 많아질 때 어느 한계점 까지는 CPU 이용율이 증가하다가 한계점 이상부터는 CPU 이용율이 떨어지게 되는데 이 때 사용량이 떨어지는 이유 중 하나가 스레싱 때문이다.
스레싱이 발생하는 이유는 프로세스를 처리하는 시간보다 메모리에 적재되지 못한 페이지로 인하여 페이지 교체에 드는 시간이 증가하게 되고 그로 인해 CPU 이용률이 떨어지게 된다.
운영체제는 CPU 이용율이 낮으면 메모리에 동시에 올라가 있는 프로세스의 수인 MPD(다중 프로그래밍의 정도, Multi-Programming Degree)를 높이게 되는데 동시에 실행하는 프로세스가 많아질 수록 각 프로세스에 할당된 메모리 페이지 프레임들은 더욱 작아지게 된다. 너무 적은 페이지 프레임을 할당받은 프로세스들은 페이지 부재가 증가하게되어 Swapping이 증가하게 되고 결국 CPU의 이용율이 더욱 떨어지는 악순환이 생기게 된다.
해결방법
-
Working Set 알고리즘
working set은 한 프로세스가 원할히 수행되기 위한 최소 page 수
프로세스가 일정 시간 동안 집중적으로 특정 주소 영역을 참조하는 경향이 있는데 이를 지역성 집합이라고 함. 워킹셋 알고리즘은 지역성 집합이 메모리에 동시에 올라갈 수 있도록 보장하는 메모리 관리 알고리즘.
- 워킹셋 알고리즘은 프로세스의 워킹셋을 구성하는 페이지들이 한꺼번에 올라갈 수 있을 메모리 공간이 있을 때만 동작.
- 그렇지 않으면 기존 메모리에 존재하는 페이지를 디스크로 스왑 아웃 시켜 공간을 확보.
- 이러한 방법으로 MPD를 조절하고 스레싱을 방지.

- working set window : 워킹셋 알고리즘에서 한꺼번에 메모리에 올라가야 할 페이지들의 집합을 결정.
- 윈도우의 크기를 Δ라고 함
- 워킹셋 알고리즘은 시각 t에서 Δ이전에 참조된 [Δ-t, t] 사이에 참조된 페이지들의 집합으로 결정.
워킹셋 윈도우의 크기를 조절하여 워킹셋의 크기를 조절하는 방법으로 프로세스가 메모리를 필요로 할때는 많이 할당하고 적게 필요로 할 때에는 적게 할당하는 동적인 프레임 할당 기능을 수행.
-
Page Fault Frequency(페이지 부재 빈도)
프로세스의 페이지 부재율을 주기적으로 조사하고 이 값에 근거하여 각 프로세스에 할당할 메모리 양을 동적으로 예측하고 조절하는 알고리즘이다. 현재 페이지 부재와 직전 페이지 부재 사이의 시간을 관찰하여 상한 값(upper bound)을 초과하거나 하한 값(lower bound) 미만이 되면 운영체제가 메모리에 올라가 있는 프로세스의 수를 조절한다.
-
page 교체 알고리즘 : paging 기법의 적절한 사용
- 지역 교환 알고리즘 - 다른 프로세스로 부터 프레임 뺏어오지 못한다.
- 우선순위 교환 알고리즘
17. 가상 메모리란 무엇인가요?
👉 가상 메모리는 메모리가 실제 메모리보다 많아 보이게 하는 기술로, 어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안되었음.가상 메모리의 컨셉은, 실제로 사용되고 있는 프로세스의 일부분 만을 물리 메모리에 로드시켜 놓고, 나머지 부분은 그냥 디스크에 둔다는 Demand Paging 의 원칙에 기반을 두고 있습니다.
따라서 만약 물리 메모리에 현재 로드 되어 있지 않은 메모리 공간에 접근하려고 할 때 Page fault 가 발생하고, OS는 이 때 요청된 페이지를 디스크에서 꺼내 물리 메모리로 가져옵니다.
Demand Paging
- 프로세스의 모든 데이터를 메모리로 적재하지 않고, 실행 중 필요한 시점에서만 메모리로 적재
- 프로세스에서 나눠진 page를 언제 물리메모리에 올려놓을 지에 대한 정책
⚡용어 정리
- 가상 주소(logical address) : 가상적으로 주어진 주소
- 메모리관리장치(MMU)에 의해 실제 주소로 변환되며, 이 덕분에 사용자는 실제 주소를 의식할 필요 없이 프로그램을 구축할 수 있음
- 실제 주소(physical address) : 실제 메모리상에 있는 주소
- 페이지 테이블 : 가상 주소와 실제 주소가 매핑되어 있고 프로세스의 주소 정보가 들어 있음
- 가상 메모리는 페이지 테이블로 관리됨
- 속도 향상을 위해 TLB를 씀
MMU (Memory Management Unit)
가상 메모리 구현을 위해서는 컴퓨터가 특수 메모리 관리 하드웨어를 갖추고 있어야 함
- 가상주소를 물리주소로 변환하고, 메모리를 보호하는 기능 수행
- CPU가 각 메모리에 접근하기 이전에 메모리 주소 번역 작업 수행
- 하지만, 메모리를 일일이 가상 주소에서 물리적 주소로 번역하게 되면 작업 부하가 너무 높아지므로, MMU는 RAM을 여러 부분(페이지, pages)로 나누어 각 페이지를 하나의 독립된 항목으로 처리함.
- 페이지 및 주소 번역 정보를 기억하는 작업이 가상 메모리 구현하는 데 가장 결정적
Page Fault가 발생했을 때, 어떻게 처리되는가?
- 물리 메모리에 올라와 있지 않은 메모리를 접근하는 상황이 일어나면, CPU는 Page Fault가 발생했다는 것을 발견합니다.
- CPU는 현재 진행하고 있는 작업에 인터럽트를 걸고 제어를
Page fault handling routine으로 넘깁니다. - 그러면 page fault를 일으킨 작업이 어떤 페이지에 접근하려고 했는지를 파악하고,
- 가상 주소와 실제 물리 주소의 연관 관계가 매핑되어 있는
page table을 참조하여 연결된 정보를 파악합니다. - 이제 실제로 요청한 페이지를 물리 메모리로 가져와야 하는데, 만약 물리에 빈 공간이 존재하지 않는다면 제거할 페이지(victim page) 를 선택해야 합니다. 일반적으로 페이지 교체 알고리즘인
LRU또는FIFO를 사용하고, 이렇게 선택된 페이지는 제거되고 요청한 페이지가 메모리에 들어오게 됩니다. - 이 과정이 끝나면 이제 새로운 매핑 정보를
page table에 업데이트 해주게 되고, - 중단됐던 작업을 다시 이어서 하게 됩니다.
페이지 크기에 따른 Trade-Off
페이지 크기가 작다면?
페이지가 가지고 있는 정보가 적고, 작업이 한번에 요청하는 데이터보다 적을 가능성이 크기 때문에 page fault가 발생할 가능성이 줄어들게 됩니다.
하지만, 많은 수의 페이지를 관리해야 되는 오버헤드가 이런 장점을 퇴색시킬 수 있습니다.
페이지 크기가 크다면?
작업이 한번에 요청하는 데이터가 작더라도, 포함한 페이지 전체가 로드되기 때문에 page fault가 발생할 가능성이 일반적으로 커지긴 합니다.
하지만 상황에 따라 달라질 수 있는데, 만약 작업이 반복적이고 균일한 데이터 접근 패턴을 가지고 있다면 큰 페이지를 한번에 가져오는 전략이 이득일 수 있습니다. 이렇게 되면 오히려 필요한 정보를 가지고 오기 위해서 페이지를 여러번 교체하고 가져오는 page fault 를 줄일 수 있습니다.
18. 세그멘테이션과 페이징의 차이점은 무엇인가요?
세그멘테이션(Segmentation)
- 가상메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할해서 메모리에 적재한다.
세그먼트 테이블(Segment Table)
- 분할 방식을 제외하면, 페이징과 세그멘테이션이 동일하기 때문에 매핑 테이블의 동작방식 동일
- 논리 주소의 앞 비트들은 페이징 번호가 아니라 세그먼트 번호가 됨
- <segment, offset> 형태로, 세그먼트 번호를 통해 세그먼트의 기준 (세그먼트의 시작 물리 주소)와 한계 (세그먼트의 길이)파악 가능
- 장점
- 내부 단편화 문제를 해소하며 보호와 공유기능을 수행할 수 있다.
- 공유와 보안 측면에서 장점이 있다.
- 단점
- 서로 다른 크기의 세그먼트들이 메모리에 적재되고 제거되는 일이 반복되다 보면, 자유 공간들이 많은 수의 작은 조각들로 나누어져 못 쓰게 될 수도 있다.(외부 단편화)
페이징(Paging)
-
프로세스를 일정한 크기의 페이지로 분할하여 메모리에 적재하는 방식.
- 페이지: 고정 사이즈의 가상 메모리 내 프로세스 조각
- 프레임: 페이지 크기와 같은 주 기억 장치의 메모리 조각
-
장점 ) 홀의 크기가 균일하지 않은 문제가 없어짐
-
단점 ) 주소 변환이 복잡해짐, 내부 단편화 문제의 비중이 늘어나게 된다
- 예를들어 페이지 크기가 1,024B 이고 프로세스 A 가 3,172B 의 메모리를 요구한다면 3 개의 페이지 프레임(1,024 * 3 = 3,072) 하고도 100B 가 남기때문에 총 4 개의 페이지 프레임이 필요한 것이다. 결론적으로 4 번째 페이지 프레임에는 924B(1,024 - 100)의 여유 공간이 남게 되는 내부 단편화 문제가 발생하는 것이다.
페이징 테이블 (Paging Table)
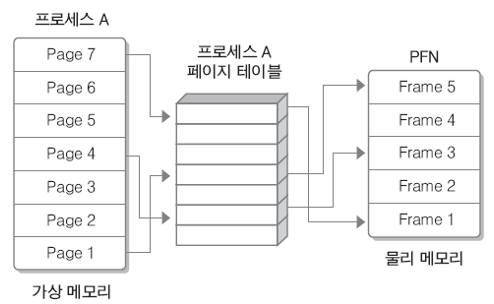
- 위 사진은 페이징 테이블의 매핑
- 물리 메모리는 고정 크기의 프레임으로, 가상 메모리는 고정 크기의 페이지로 분리되어 있음.
- 개별 페이지는 순서에 상관 없이 물리 메모리에 있는 프레임에 매핑되어 저장됨.
- 모든 프로세스는 하나의 페이징 테이블을 가지고 있음
- 메인 메모리에 적재되어 있는 페이지 번호와 해당 페이지가 위치한 메인 메모리의 시작 주소가 있음.
- 따라서, 하나의 프로세스를 나눈 가상 메모리 페이지들이 각각 실제 메인 메모리의 어디 프레임에 적재되어 있는 지 알 수 있음
페이지 vs 프레임
페이지는 논리적 주소공간을 표현하는 가상 메모리 내에서의 메모리 단위라면,
프레임은 메인 메모리의 실제 물리 공간 내에서의 메모리 단위로, 실제 데이터가 메모리에 로드될 때 사용됩니다.
💡Q) 32비트에서, 페이지의 크기가 1kb 이라면 페이지 테이블의 최대 크기는 몇 개일까요?
32비트 시스템에서의 주소 공간은 2^32 (4,294,967,296)개의 가능한 주소로 0부터 2^32 - 1까지의 범위를 가집니다. 페이지 크기가 1KB인 경우 각 페이지는 2^10 (1,024)개의 주소를 커버할 수 있습니다 (2^10 = 1KB).
페이지 테이블의 최대 크기를 계산하려면 전체 주소 공간을 각 페이지가 커버하는 주소 수로 나눕니다:
최대 페이지 테이블 크기 = 전체 주소 공간 / 페이지 크기
= 2^32 / 2^10
= 2^22
= 4,194,304 개의 항목
따라서 32비트 시스템에서 1KB 페이지 크기를 사용하는 경우 페이지 테이블의 최대 크기는 4,194,304개의 항목입니다. 페이지 테이블의 각 항목은 페이지에 해당하며, 페이지 테이블은 주소 공간의 각 페이지에 대한 가상 주소와 물리 주소 간의 매핑을 유지 관리합니다.
19. TLB는 무엇인가요?
👉 TLB(Translation Lookaside Buffer)는 MMU의 일부분으로, 주소 변환 과정을 가속화하기 위해 사용되는 하드웨어 캐시입니다. TLB는 페이지 테이블 엔트리를 저장하여 가상 주소를 실제 물리 주소로 변환하는 속도를 향상시킵니다. TLB는 메모리의 일부이며, 빠른 접근을 위해 CPU 코어에 내장되거나 캐시 메모리에 위치할 수 있습니다.
TLB와 MMU의 위치
-
TLB
TLB는 메모리 관리 유닛(MMU)의 일부이고, 작고 빠른 캐시입니다.
TLB는 MMU 내부에 위치하거나 MMU와 밀접하게 연결된 별도의 캐시 유닛으로 구성될 수 있습니다. -
MMU
MMU는 CPU의 하드웨어 구성 요소로, CPU 내부에 존재합니다.
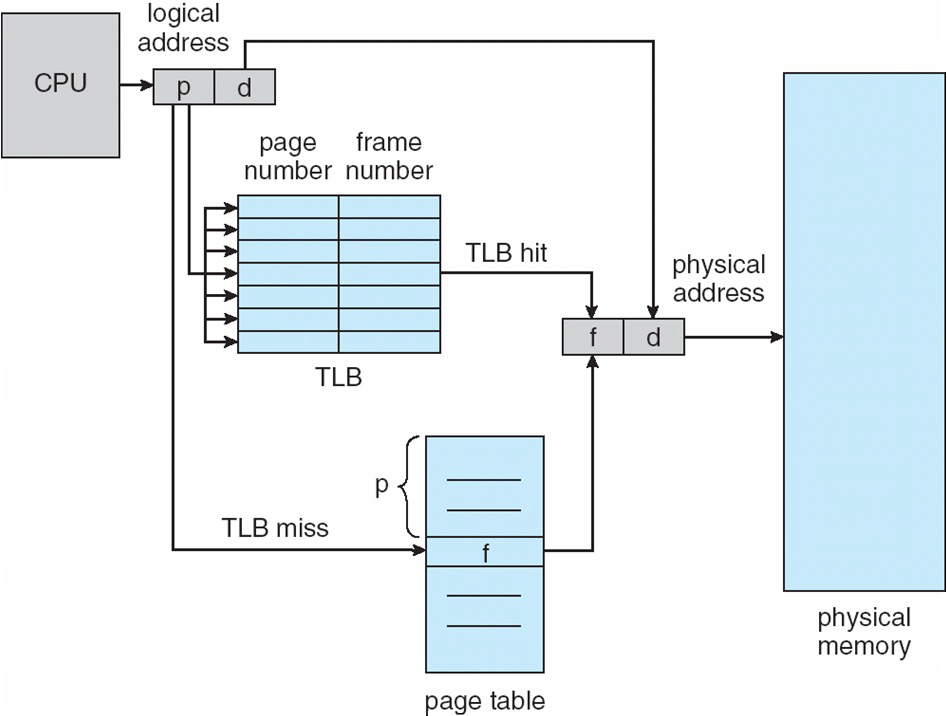
TLB 특징
- CPU가 가상 주소로 메모리에 접근하려고 할 때 우선 TLB에 접근, 없다면 페이지 테이블에서 찾아 접근
- 굉장히 작음 : 64~1024 entry
- MMU에 별도의 칩으로 있음
TLB를 쓰면 왜 빨라질까?
- 페이지 테이블은 메인 메모리에 존재해서 CPU는 메인메모리에 최소 2번은 접근해야 원하는 데이터를 얻을 수 있다.
-
페이지 테이블에 접근
-
해당 정보를 기반으로 실제 메모리에 접근
→ 그러나 TLB는 메모리에 접근하는 것이 아니라 MMU 내부에서 물리주소를 얻을 수 있기 때문에 빨라진다.
-
Q) 코어가 여러 개라면, TLB는 어떻게 동기화 할 수 있을까요?
다중 코어 시스템에서 각 코어는 자체적인 개인 캐시를 가지는데, 일반적으로 코어 간에 공유되지 않습니다. 왜냐하면 공유된 TLB 간의 일관성 유지는 복잡할 수 있으며 동기화 문제를 야기할 수 있기 때문입니다. 그러나, 코어 간 통신이 필요할 때는 다음과 같은 방법을 이용합니다.
-
캐시 일관성 프로토콜
먼저 다중 코어 시스템에서 자주 사용되는 메모리를 액세스할 때 여러 캐시, TLB의 일관성을 유지하기 위해 캐시 일관성 프로토콜이라는 방법을 사용합니다. 이 프로토콜은 한 코어에서 메모리에 대한 변경 사항이 다른 코어에서도 보이도록 관리하여 데이터의 불일치 가능성을 줄입니다.
-
TLB 무효화
TLB 항목을 무효화하거나 업데이트해야 할 경우, "TLB 무효화"라는 메커니즘을 사용합니다. 코어가 메모리 매핑을 수정하는 경우, 해당 코어가 다른 코어에게 특정 TLB 항목을 무효화하도록 통지하여 일관성을 유지합니다.
-
소프트웨어 개입
일부 경우에는 CPU 코어에서 실행되는 소프트웨어가 TLB 동기화에 개입할 수 있습니다. 운영 체제 또는 응용 프로그램 코드는 필요할 때 적절한 TLB 관리 및 동기화 기법을 구현할 수 있습니다.
20. 동기화를 구현하기 위한 하드웨어적인 해결 방법에 대해 설명해 주세요.
Disabling Interrupts
- 인터럽트를 꺼서 lock을 구현하는 방법
- 메모리 값 저장 시 [read-compute-update]의 과정을 거침, 이 과정에서 인터럽트를 꺼서 중간에 다른 쓰레드에게 방해를 받지 않도록 함
- read compute update를 한 덩어리로 만듬
- 문제점
- 인터럽트 끄게 되면 문제 발생 가능
- 멀티 코어 시스템에서는 사용 불가 ( 모든 코어의 인터럽트가 꺼져서 오히려 더 오래 걸림 )
Test - And - Set
- Atomic instruction 이용
- 특정 변수 Test 후, 그 값이 원하는 값이면 새로운 값으로 바꿔준다
- Mutual exclusion 만족시킬 수 있음
// test_and_set 명령어 정의
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return rv;
}
// lock이 가능한지 현재 lock 상태를 반환하고, lock을 true로 설정
// test_and_set 명령어를 이용한 상호 배제 구현
do {
while (test_and_set(&lock))
; /* do nothing */
/* critical section */
lock false;
/* remainder section */
} while(true)
// 두 프로세스 동시에 실행 시
// 처음 실행하는 프로세스는 lock = false이므로 임계구역에 진입
// 임계구역에서 진입하면서 lock = true
// 두 번째 프로세스는 lock = true라서 임계구역 진입 불가
// [따라서 *상호 배제 만족*]Compare - And - Swap
- Atomic instruction 이용
- Test - And - Set 과 비슷하지만, expected 변수 추가
// compare_and_swap 명령어 정의
int compare_and_swap (int *value, int expected, int new_value) {
**int tmp = *value;
if (*value == expected) ***value = new_value;
return tmp;
}
// lock이 가능한지 현재 lock 상태를 반환해주고, value == expected이면 value를 new_value 값으로 설정
// compare_and_swap 명령어를 이용한 상호 배제 구현
while (true) {
while (compare_and_swap(&lock, 0, 1) != 0)
; /* do nothing */
/* critical section */
lock = 0;
/* remainder section */
}
// 여러 프로세스가 동시에 실행될 때
// 프로세스는 lock = 0 이므로 입계구역에 진입 가능
// 임계 구역에 진입하면서 lock=1로 바꿈
// 나머지 프로세스는 lock이 1이라 임계구역에 진입 불가
// [*상호 배제 조건*은 만족]
// 계속 대기하는 프로세스가 생길 수 있으므로 *한정된 대기 조건 만족 X*Load-Linked / Store-Conditional (LL/SC)
- 낙관적 동시성 제어를 제공하기 위해 작동한다.
- Load-Linked : 메모리에서 값을 로드하고 레지스터에 “링크”한다
- Store-Conditional : 로드 이후 다른 스레드에 의해 값이 변경되지 않은 경우에만 값을 메모리로 다시 쓰려고 시도한다.
- 값이 변경된 경우, 저장 작업 실패 ⇒ 메모리 위치가 다른 스레드에 의해 수정 되었음을 의미
세마포어 명령어
- 일부 CPU는 세마포어를 조작하는 특수한 명령어를 제공
- 세마포어는 제한된 수의 리소스에 대한 액세스를 제어하는 동기화 구조로 사용
트랜잭션 메모리
- 고급스러운 하드웨어 기반 동기화 메커니즘
- 일련의 메모리 작업을 단일 트랜잭션으로 처리하여 원자성과 격리성을 보장
- 충돌이 발생하면 트랜잭션을 롤백하고 다시 시도 가능
메모리 바리어/펜스
- 메모리 바리어(또는 메모리 펜스)는 메모리 작업의 순서를 강제하는 하드웨어 명령어
- 특정 메모리 읽기 및 쓰기가 모든 스레드에게 올바른 순서로 보이도록 보장
- 메모리 바리어는 동기화 문제를 일으킬 수 있는 명령어 재배열을 방지하기 위해 사용
- 강한 순서 (strongly ordered)
- 한 프로세서의 메모리 변경 결과가 다른 모든 프로세서에 바로 보인다.
- 약한 순서 (weakly ordered)
- 한 프로세서의 메모리 변경 결과가 다른 프로세서에 즉시 보이지 않는다.
- Load barrier : 메모리에서 데이터를 읽어오는 명령어 다음에 실행되는 명령어들을 지연
- 데이터 읽기가 완료되기 전에 실행된 명령어로부터 발생하는 문제 해결
- Store barrier : 메모리에 데이터를 쓰는 명령어 이전에 실행되는 명령어들을 지연
- 데이터 쓰기가 완료되기 전에 실행된 명령어로부터 발생하는 문제 해결
- 메모리 장벽 없이는 원자적 연산이 제대로 작동안할 수도 있다.
캐시 일관성 프로토콜
- 다중 프로세서 시스템에서 캐시 일관성 프로토콜은 서로 다른 프로세서 캐시가 공유 메모리의 일관된 복사본을 유지하도록 한다
- 동일한 데이터의 다양한 코어의 캐시된 복사본으로 인한 데이터 불일치를 방지하는 데 도움이 됩니다.
🦻 프로그래머가 사용하는 방법은? (소프트웨어)
- Mutex locks
- Semaphores
- monitor
- condition variables
21. 페이지 교체 알고리즘에 대해 설명해 주세요.
Optimal replacement policy (MIN)
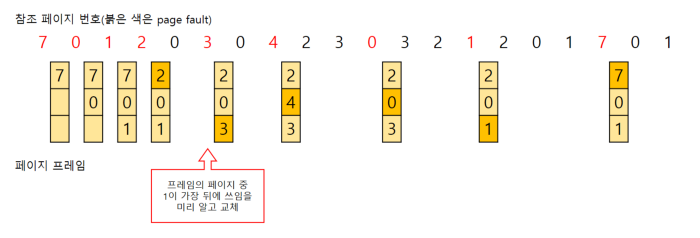
- 가장 미래에 접근할 것 같은 page를 교체하는 방식.
- 이상적이지만 구현하기가 어렵다
FIFO (First In First Out)
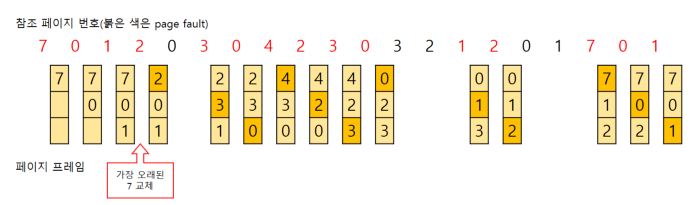
- 도착한지 가장 오래된 page를 교체하는 방식
- 간단하지만 지역성을 고려하지 않아 성능이 좋지 않다. (선점시간)
- Belady’s anomaly가 발생한다
- 변화를 주면 긍정적인 결과가 나와야 하는데, 그렇지 않은 경우를 말한다.
- frame 크기를 증가시키면 성능이 오히려 나빠진다.
- Random
- 무작위로 page를 교체한다
- 지역성 고려 x, 예측 불가
LRU (Least Recently Used)
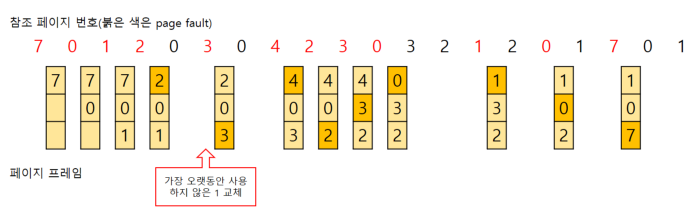
-
가장 과거에 사용되었던 page 내린다. 지역성을 고려하여 히트율이 보장되지만 loop에서는 성능이 좋지 않다.
-
구현 방법
- 계수기와 스택 같은 별도의 하드웨어를 통해 사용된 시점 계산
- 큐 또는 연결 리스트 사용: 메모리의 페이지를 액세스 이력(가장 최근에 액세스한 것부터 가장 최근에 사용하지 않은 것까지)에 따라 정렬된 큐나 연결 리스트를 유지합니다. 큐의 맨 앞에 있는 페이지는 가장 최근에 사용된 페이지를 나타내며, 끝에 있는 페이지는 가장 최근에 사용하지 않은 페이지를 나타냅니다.
- 액세스 순서 업데이트: 페이지가 액세스(읽기 또는 쓰기)될 때마다 해당 페이지를 큐의 맨 앞으로 이동시킵니다. 이 단계는 항상 가장 최근에 사용된 페이지가 맨 앞에 있고, 가장 최근에 사용하지 않은 페이지가 끝에 있도록 보장합니다.
- 제거: 새 페이지를 메모리로 로드해야 하지만 여유 공간이 없을 때, 큐의 끝(가장 최근에 사용하지 않은 페이지)에 있는 페이지를 제거하고 새 페이지를 앞(가장 최근에 사용된 페이지)에 삽입합니다.
-
작동 방식
- 페이지 접근: 페이지가 접근(읽기 또는 쓰기)될 때마다 운영 체제는 해당 페이지의 접근 시간 또는 타임스탬프를 업데이트합니다. 가장 최근에 접근하지 않은 페이지는 가장 오래된 타임스탬프를 가집니다.
- 페이지 교체 결정: 새 페이지를 메모리로 로드해야 하며 여유 공간이 없을 때, 페이지 교체 알고리즘은 가장 오래된 타임스탬프(즉, 가장 최근에 접근하지 않은 페이지)를 가진 페이지를 교체 대상으로 선택합니다.
-
장점: LRU는 실제 페이지 접근 이력을 고려하는 간단하고 직관적인 알고리즘입니다. 프로그램이 강한 시간적 지역성을 보일 때 효과적이며, 자주 접근되는 페이지가 교체되는 경우가 적습니다.
-
단점: 효과적이지만 LRU에도 몇 가지 단점이 있습니다. 각 페이지에 대한 타임스탬프 또는 접근 이력을 유지해야 하므로 메모리를 소비하고 추가적인 오버헤드가 필요할 수 있습니다. 또한 정확한 타임스탬프를 사용하여 LRU 알고리즘을 구현하는 것은 실제로는 어려울 수 있습니다.
-
복잡성: 특정 상황에서는 LRU가 메모리 및 계산 요구 사항 때문에 가장 효율적인 알고리즘이 아닐 수 있습니다. FIFO(First-In-First-Out), Optimal, 또는 다양한 근사 알고리즘(예: Second-Chance, Clock)과 같은 다른 페이지 교체 알고리즘은 LRU의 단점이 문제가 될 때 사용됩니다.
NRU (Not Recently Used)
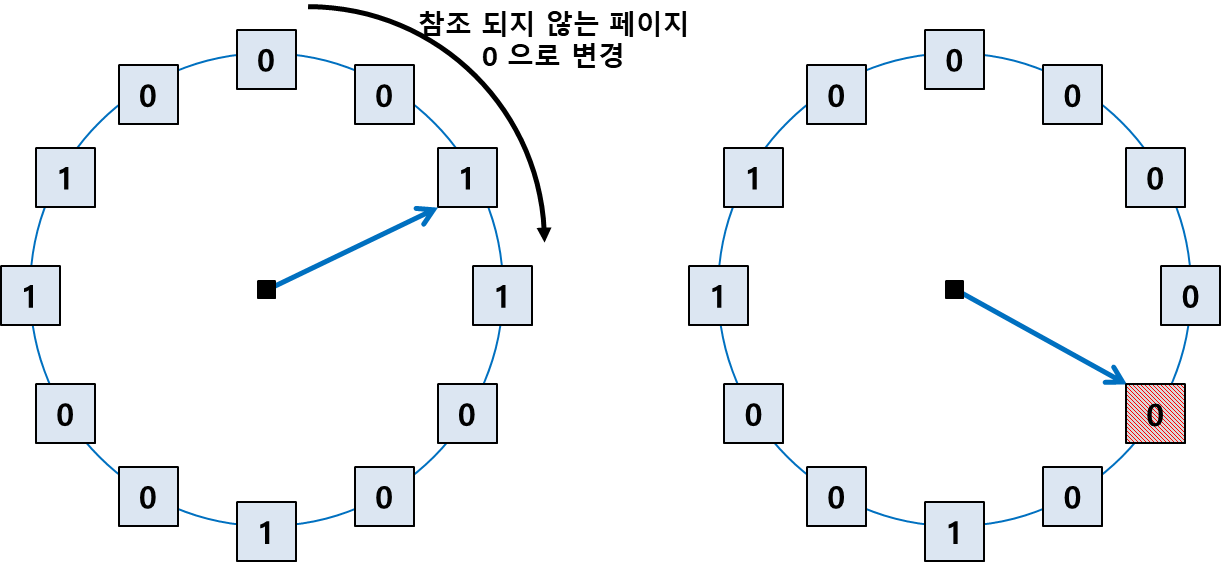
- 가장 최근에 참조되지 않은 페이지 선택, But 참조 시점이 가장 오래되었음을 보장하지는 않음
- Clock 알고리즘
- 최근에 참조되었을을 표시하는 1, 참조 안됐음인 0 Reference Bit를 조사
- 페이지 참조시 자동으로 하드웨어에 의해 1로 세팅
- 한바퀴 돌아도 참조 안되면 0으로 바꾸고 지나감
- 0인 페이지 방문하면 해당 페이지 교체
💡 윈도우 - 클럭 알고리즘(NRU 알고리즘)
💡 리눅스 - Second Chance 알고리즘
- FIFO 알고리즘에 기반을 둔다.
- 클럭과 비슷하지만 갱신 비트 함께 검사한다.
- 원칙
- 현재 포인터가 가리키는 페이지의 참조 비트(r)와 갱신 비트(m) 검사
- 해당 페이지가 리스트에 있고 참조 비트가 0이라면 1로 재설정. 이 떄 포인터 움직이지 않음
- (0,0) 교체, (1,0) (0,1) ⇒ (0,0) 변경, (1,1) ⇒ (0,1) 변
22. 동기와 비동기, 블로킹과 논블로킹의 차이에 대해 설명해 주세요.
Blocking 🆚 Non-blocking
- A함수가 B함수 호출 시 제어권을 어떻게 처리하느냐에 따라 달라진다.
- 블로킹 : A가 B를 호출하면, 제어권을 A가 호출한 B에게 넘겨준다.
- 논블로킹 : A가 B를 호출해도 제어권은 그대로 자신이 가지고 있는다. (B함수 호출해도 자신의 코드를 계속 실행한다.
Synchronous 🆚 Asynchronous
- 호출되는 함수의 작업 완료 여부를 신경 쓰는지 여부
- 동기 : A가 B를 호출한 뒤 B의 리턴값을 확인하며 신경 쓰는 것
- 비동기 : A가 B를 호출할 때 콜백 함수를 같이 전달해, B 작업이 완료되면 함께 보낸 콜백 함수를 실행한다. B 호출 이후에는 B의 작업 완료 여부에는 신경 쓰지 않는다.
Sync-Blocking
- 동기를 블로킹 처럼 실행
- 함수 A는 함수 B의 리턴값을 필요로 한다(동기). 그래서 제어권을 함수 B에게 넘겨주고, 함수 B가 실행을 완료하여 리턴값과 제어권을 돌려줄때까지 기다린다(블로킹).
Sync-Nonblocking
- 동기를 논블로킹 처럼 작동 가능
- A 함수는 B 함수를 호출한다. 이 때 A 함수는 B 함수에게 제어권을 주지 않고, 자신의 코드를 계속 실행한다(논블로킹).
- A 함수는 B 함수의 리턴값이 필요하기 때문에, 중간중간 B 함수에게 함수 실행을 완료했는지 물어본다(동기).
Async-Nonblocking
- 제어권을 B 함수에 주지 않고, 자신이 계속 가지고 있는다(논블로킹). 따라서 B 함수를 호출한 이후에도 멈추지 않고 자신의 코드를 계속 실행한다.
- 그리고 B 함수를 호출할 때 콜백함수를 함께 준다. B 함수는 자신의 작업이 끝나면 A 함수가 준 콜백 함수를 실행한다(비동기).
Async-blocking
- A 함수는 B 함수의 리턴값에 신경쓰지 않고, 콜백함수를 보낸다(비동기).
- 그런데, B 함수의 작업에 관심없음에도 불구하고, A 함수는 B 함수에게 제어권을 넘긴다(블로킹).
Mysql + Node.js ⇒ async/await을 통해서 동기 → 논블로킹으로 바꾼다.
Sync Blocking VS Sync Non-Blocking
성능 차이는 상황에 따라 다르겠지만, 일반적으로 동기 + 논블로킹이 동기 + 블로킹보다 효율적일 수 있다. 왜냐하면 동기 + 논블로킹은 호출하는 함수가 제어권을 가지고 있어서 다른 작업을 병렬적으로 수행할 수 있기 때문이다. 반면에 동기 + 블로킹은 호출하는 함수가 제어권을 잃어서 다른 작업을 수행할 수 없기 때문입니다
- 예시 웹브라우저에서 파일을 다운로드 할 경우 작업은 웹브라우저의 Web APIs 으로 작업을 백그라운드로 넘기고 '제어권'을 바로 반환받아 다른 작업을 수행할 수 있다. 이것이 Non Blocking 이다. 그런데 웹브라우저는 파일 다운로드 작업의 완료 여부에 관심이 있다. 즉, 운로드 작업이 언제 끝나고 얼마나 진행되었는지 파일 다운로드 로드율을 브라우저 하단바에 표시해준다. 그리고 파일이 모두 다운로드 완료되면 사용자가 원하는 최종 작업인 파일 다운로드 작업을 수행하게 된다. 이것이 Synchronous 이다.
멀티플렉싱이라는 단어의 이해
- 하나의 통신 채널을 통해서 둘 이상의 데이터(시그널)를 전송하는데 사용되는 기술
- 물리적 장치의 효율성을 높이기 위해서 최소한의 물리적인 요소만 사용해서 최대한의 데이터를 전달하기 위해 사용되는 기술
위 모델에 멀티플렉싱 기술을 적용하면 다음과 같이 프로세스의 수가 줄어든다.
I/O 다중화가 작동하는 방식은 다음과 같습니다:
- 모니터링: 프로세스는 여러 I/O 소스(소켓, 파일 디스크립터 등)를 적절한 시스템 호출('select', 'poll' 등)을 사용하여 운영 체제에 등록합니다.
- 블로킹: 프로세스는 I/O 다중화 함수를 호출하고, 등록된 I/O 소스 중 어느 하나라도 활성 상태가 될 때까지 블로킹된 상태에 들어갑니다.
- 활동 감지: 등록된 I/O 소스 중 하나 이상이 읽기 준비나 쓰기용 공간을 갖고 있을 때, I/O 다중화 호출이 반환되며 어떤 소스가 준비되었는지 알려줍니다.
- 처리: 프로세스는 준비된 소스에서 I/O 작업을 블로킹 없이 수행할 수 있습니다.
1. 쿠키와 세션의 차이에 대해 설명해 주세요.
웹 브라우저의 캐시
-
소프트웨어적인 대표적인 캐시로 웹 브라우저의 작은 저장소 쿠키, 로컬 스토리지, 세션 스토리지가 있음
-
웹 환경에서는 클라이언트와 서버가 보통 HTTP 프로토콜 이용해 통신
-
하지만 HTTP 프로토콜은 아래와 같은 특징 때문에 쿠기, 세션 사용
- Connectionless (비연결성)
- HTTP는 TCP 연결을 맺고 요청(Request)을 보내면 서버는 응답(Response)을 보내고 연결이 끊어짐.
- 물론 HTTP 1.1 버전은 커넥션을 계속 유지하는 keep-alive 옵션이 디폴트이긴 함.
- 하지만 HTTP 1.0 버전은 기본적으로 connectionless.
- Stateless (무상태)
- HTTP는 상태를 따로 저장하지 않음. 즉, 연결이 끊어지는 순간 모든 상태 정보가 사라짐
- 서버는 클라이언트가 첫 번째 통신 때 보낸 정보를 두 번째 통신 때 알 수 없음
- Connectionless (비연결성)
쿠키
- 클라이언트(로컬)에 저장되는 키와 값이 들어있는 작은 데이터 파일
- 클라이언트에 저장되어 필요시 정보를 참조하거나 재사용 가능
- 사용자 인증이 유효한 시간을 명시할 수 있으며, 유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지된다는 특징.
- 클라이언트에 총 300개의 쿠키 저장 가능, 하나의 도메인 당 20개의 쿠키 가질 수 있음, 하나의 쿠키는 4KB(=4096byte)까지 저장 가능
구성
-
이름 : 쿠키를 구별하는 이름
-
값 : 쿠키에 저장되는 값
-
유효시간 : 쿠키 유지시간
-
도메인 : 쿠키를 전송할 도메인
-
경로 : 쿠키를 전송할 요청 경로
-
동작 방식
-
클라이언트(웹 브라우저)가 서버에 로그인 요청
서버는 클라이언트 요청 받아 클라이언트의 정보를 담은 쿠키 생성
이후 HTTP 헤더에 set-cookie 옵션을 통해 쿠키를 포함해 응답 보냄
클라이언트는 해당 쿠키를 쿠키 저장소에 저장해 놓음
-
로그인 완료 후, 첫 페이지에 접근
클라이언트는 쿠키 저장소에서 쿠키를 꺼내 HTTP 요청에 쿠키를 담아 전송
서버는 HTTP 요청의 쿠키를 읽어 클라이언트를 식별 가능
-
-
사용 예시
- 방문 사이트에서 로그인 시, "아이디와 비밀번호를 저장하시겠습니까?"
- 팝업창을 통해 "오늘 이 창을 다시 보지 않기" 체크
세션
-
일정 기간동안 사용자(클라이언트)로부터 들어오는 일련의 요구를 하나의 상태로 보고 그 상태를 유지시키는 기술
- 일정 시간 : 방문자가 웹 브라우저를 통해 웹 서버에 접속한 시점부터 웹 브라우저를 종료하여 연결을 끝내는 시점 → 방문자가 웹 서버에 접속해 있는 상태를 하나의 단위
-
쿠키를 기반으로 하지만 서버측에서 저장되고 관리
- 사용자가 많아질수록 서버 메모리를 많이 차지.
- 즉, 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 됩니다.
-
세션 ID를 이용해 클라이언트를 구분하며 브라우저를 종료할 때 까지 세션을 유지
- 각 클라이언트에 고유 Session ID 부여
-
저장 데이터에 제한 X
-
동작 방식
-
클라이언트(웹 브라우저)가 서버에 로그인 요청
서버는 클라이언트 요청 받아 클라이언트의 정보를 담은 세션 생성
이후 세션 ID를 담은 쿠키 생성하고, HTTP 헤더에 set-cookie 옵션을 통해 쿠키를 포함해 응답 보냄
클라이언트는 해당 쿠키를 쿠키 저장소에 저장해 놓음
-
로그인 완료 후, 첫 페이지에 접근
클라이언트는 쿠키 저장소에서 쿠키를 꺼내 HTTP 요청에 쿠키를 담아 전송
서버는 HTTP 요청의 쿠키를 읽어 쿠키 안의 세션 ID를 이용해 클라이언트를 식별 가능
-
-
사용 예시
- 화면을 이동해도 로그인이 풀리지 않고 로그아웃하기 전까지 유지
쿠키 VS 세션
-
쿠키는 클라이언트에 저장되지만, 세션은 서버에 저장된다.
-
세션은 서버에 저장되므로 서버의 자원 사용 / 쿠키는 클라이어언트에 저장되므로 서버 자원 사용 X
- 서버에 요청을 보내는 사용자가 많으면 세션은 부하가 심해짐
-
쿠키는 정보를 직접 저장하기 때문에 보안면에서는 세션이 우수하다.
- 중간에 정보를 스니핑 당할 수 있음
-
쿠키는 만료시간 동안 파일로 저장되므로 브라우저를 종료해도 정보가 남아있지만, 세션은 브라우저가 종료되면 만료시간과 상관없이 삭제된다.
-
로컬 스토리지
- 만료기한이 없는 키-값 저장소
- 10MB까지 저장 가능
- 웹 브라우저를 닫아도 유지되고 도메인 단위로 저장, 생성됨
- HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없으며 클라이언트에서만 수정 가능함
-
세션 스토리지
- 만료기한이 없는 키-값 저장소
- 5MB까지 저장 가능
- 탭 단위로 세션 스토리지를 생성하며, 탭을 닫을 때 해당 데이터가 삭제됨
- HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없으며 클라이언트에서만 수정 가능함
세션 방식의 로그인 과정에 대해 설명해 주세요.
- 사용자 인증:
사용자가 웹 사이트나 애플리케이션의 안전한 영역에 액세스하려면 일반적으로 사용자 이름과 비밀번호와 같은 로그인 자격 증명을 입력하도록 요청됩니다. - 유효성 검사:
서버는 제공된 자격 증명을 검증하여 등록된 사용자 데이터베이스와 비교합니다. 자격 증명이 올바르면 서버는 사용자를 위한 세션을 생성합니다. - 세션 생성:
인증이 성공적으로 이루어지면 서버는 사용자를 위한 세션을 생성합니다. 세션은 일반적으로 고유한 세션 ID를 생성하고 이를 사용자의 계정과 연결합니다. - 세션 ID 할당:
세션 ID는 사용자의 브라우저에 쿠키로 저장되는 경우가 많습니다. 또는 URL 매개변수로 전달될 수도 있지만 세션 ID가 노출될 가능성 때문에 이 방식은 보안이 취약합니다. - 사용자 상호작용:
사용자가 응용 프로그램을 탐색하는 동안 각 요청과 함께 세션 ID가 전송됩니다. 서버는 이 세션 ID를 사용하여 사용자를 식별하고 사용자의 세션 데이터를 검색합니다. 이 데이터에는 사용자 역할, 권한 및 기타 관련 데이터가 포함될 수 있습니다. - 세션 관리:
서버는 세션의 수명주기를 관리합니다. 이에는 만료 시간을 설정하는 것도 포함됩니다. 사용자가 일정 기간 동안 비활성 상태인 경우 세션이 만료될 수 있으며 이 경우 사용자는 다시 로그인해야 합니다. 세션은 사용자가 로그아웃하거나 보안상의 이유로 서버에서 명시적으로 무효화될 수도 있습니다. - 액세스 제어:
사용자가 응용 프로그램과 상호작용하는 동안 서버는 사용자의 세션 데이터를 확인하여 액세스 권한을 결정합니다. 이를 통해 응용 프로그램은 개인화된 콘텐츠를 제공하고 보안 조치를 시행할 수 있습니다. - 로그아웃:
사용자가 로그아웃하려는 경우 일반적으로 세션이 파기됩니다. 이에는 서버에서 세션 데이터를 삭제하고 사용자의 브라우저에서 세션 ID 쿠키를 제거하는 것이 포함됩니다.
HTTP의 특성인 Stateless에 대해 설명해 주세요.
Connectionless
- TCP연결을 맺고 요청을 보내면 서버는 응답을 보내고 연결이 끊어진다.
- HTTP 1.1은 커넥션을 계속 유지한다.
Stateless
- HTTP는 상태를 따로 저장하지 않고 연결이 끊어지는 순간 모든 상태 정보가 사라지게 된다.
Stateless의 의미를 살펴보면, 세션은 적절하지 않은 인증 방법 아닌가요?
세션 방식은 이에 반하긴 하나, 세션 기반 로그인의 개념은 상태없는 프로토콜인 HTTP에 일부 상태성을 도입함. HTTP 프로토콜 자체는 상태없게 설계되었지만, 웹 애플리케이션에서는 사용자 식별과 문맥 관리와 같은 일부 형태의 필요성이 있어 세션과 같은 상태성 메커니즘을 사용하게 됨.
세션 기반 로그인은 사용자 문맥과 인증 상태를 유지하기 위해 서버에서 세션을 생성하는 것을 포함함. 이 세션 상태는 서버에 저장되며 클라이언트 측에 세션 ID로 참조되며, 이는 대개 쿠키로 저장됨. 이는 어느 정도의 상태성을 도입하지만, 웹 애플리케이션에서 사용자 세션을 관리하는 실용적인 접근 방식.
2. HTTP 응답코드에 대해 설명해 주세요.
서버가 브라우저의 요청에 대한 응답으로 클라이언트 브라우저로 보내는 세 자리 숫자.
요청된 작업의 결과를 나타내며 요청의 성공, 실패 또는 상태에 대한 정보를 제공함.
HTTP 응답 코드는 HTTP 프로토콜의 핵심 구성요소이며, 클라이언트(예: 웹 브라우저)와 서버 간의 통신에서 중요한 역할.
1XX(정보 전달)
요청을 받았고, 작업을 진행 중. HTTP 1.1 버전부터 추가됨
- 100 Continue: 진행중, 현재까지 진행 상태에 문제가 없음
- 101 Switching Protocol: 클라이언트가 보낸 Upgrade 요청 헤더에 대한 응답이 들어가며 서버에서 프로토콜을 변경할 것임을 알려줌Websocket 프로토콜 전환 시 사용
- 102 Processing(WebDAV): 서버가 요청을 수신해 처리하고 있지만, 아직 제대로된 응답을 알려줄 수 없음
2XX(성공)
요청이 받았고 이해되고 성공적으로 처리되었음을 나타냄.
- 200 OK: 요청이 성공적으로 되었다.
- 201 Created: 요청이 성공적이였으며 새로운 리소스가 생성됨
- 202 Accepted: 요청을 수신했지만 처리되지 않았음
- 203 Non-Authoritative Information: 응답받은 메타정보가 서버에 저장된 원본과는 동일하지 않지만 로컬이나 다른 복사본에서 수집되었음을 알리는 응답코드
- 204 Non Content: 성공적으로 처리했지만 컨텐츠를 제공하지 않음
- 205 Reset Content: 서버가 요청을 성공적으로 처리했지만 콘텐츠를 표시하지 않음204와 달리 요청자가 문서보기를 재설정할 것을 요구
- 206 Partial Content: 컨텐츠의 일부분만 제공
- 207 Multi-Status: 여러 소스에서 여러 응답인 상태에서 적절한 정보를 사용자한테 제공할 수 있도록 하는 응답코드
- 208 Aleardy Reported(WebDAV): DAV 바인딩 멤버는 이미 응답의 앞 부분에 열거. 다시 포함되지 않음
- 226 IM Used(HTTP Delta Encoding): 서버가 사용자의 GET 요청에 대한 리소스의 의무는 다했고, 현재 인스턴스에 적용된 하나 이상의 인스턴스 조작 결과를 보낼 때 사용
3XX(리다이렉션)
클라이언트가 요청을 충족하기 위해 추가 작업을 수행해야 함. 요청한 리소스는 다른 위치에서 사용 가능.
- 300 Multiple Choices: 서버에서 여러 개의 응답이 있음을 알릴 때 사용할 의도로 만들었으나, 정작 응답을 선택하는 방법은 표준화되지 않아 사용되지 않음
- 301 Move Permanently: 영구적으로 컨텐츠가 이동했을 때 사용
- 302 Found: 일시적으로 컨텐츠가 이동함
- 303 See Other: 서버가 사용자의 GET 요청을 처리해 다른 URL에서 요청된 정보를 가져올 수 있도록 응답하는 코드
- 304 Not Modified: 캐시 목적으로 사용. 클라이언트에게 응답이 수정되지 않았음을 알려줌.
- 305 Use Proxy: 프록시를 사용하지 않으면 접근할 수 없는 컨텐츠에 사용할 목적.보안상 이유로 현재 사용 중지된 비권장 응답코드
- 307 Temporary Redirect: 302와 동일하기 일시적 컨텐츠 이동을 나타내나, HTTP 메서드의 변경을 허용하지 않음
- 308 Permanently Redirect: 301와 동일하기 영구적 컨텐츠 이동을 나타내나, HTTP 메서드의 변경을 허용하지 않음
4XX (클라이언트 오류)
클라이언트 측에서 오류가 발생했음을 나타냄. 잘못된 요청이나 무단 액세스와 같은 것.
- 400 Bad Request: 요청 자체가 잘못됨
- 401 Unauthorized: 인증이 필요한 리소스에 인증없이 접근한 경우이 응답코드를 사용할 때 반드시 브라우저에 어느 인증 방식을 사용할 것인지 보내야 함
- 단순히 권한이 없는 경우 이 응답 코드 대신 403을 사용
- 403 Forbidden: 서버가 요청을 거부
- 404 Not Found: 찾는 리소스가 없음
- 408 Reqeust Timeout: 요청 중 시간 초과
5XX (서버 오류)
서버가 응답할 수 없다는 의미, 요청이 올바른지 여부는 알 수 없음. 서버의 부하, DB 처리 과정 오류, 서버에서 익셉션이 발생하는 경우를 의미.
-
500 Internal Server Error: 서버에 오류가 발생해 작업을 수행할 수 없음
-
501 Not Implemented: 서버가 요청을 수행하는데 필요한 기능을 지원하지 않는 경우
-
502 Bad Gateway: 게이트웨이가 연결된 서버로부터 잘못된 응답을 받았을 때 사용
-
503 Service Temporaliy Unavailable: 서비스를 일시적으로 사용할 수 없음
-
504 Gateway Timeout: 게이트웨이가 연결된 서버로부터 응답을 받을 수 없었을 때 사용됨
-
401 (Unauthorized) 와 403 (Forbidden)은 의미적으로 어떤 차이가 있나요?
-
401 : 클라이언트가 인증되지 않았거나, 유효한 인증정보가 부족해 요청이 거부되었음. 주로 로그인 되지 않은 상태에서 요청을 하는 경우
-
403 : 클라이언트가 권한이 없다는 것을 의미, 로그인하여 인증되었지만 접근 권한이 없는 무언가를 요청할 때 사용되는 값, 인가 부족으로 액세스가 거부됨.
이러한 상태 코드를 올바르게 사용하여 클라이언트에게 왜 요청이 거부되었는지와 문제가 인증인지 권한이 있는지를 의미 있는 정보로 제공하는 것이 중요함
-
200 (ok) 와 201 (created) 의 차이에 대해 설명해 주세요.
-
200 : 요청이 성공하였으며, 서버가 요청된 내용을 제공함.
-
201 : 요청이 성공하였으며, 새로운 리소스가 요청 결과로 성공적으로 생성되었음.
이러한 코드 간 구별은 요청의 결과에 대한 클라이언트에게 추가 정보를 제공하기 때문에 중요함. 둘 다 성공을 나타내지만, 201(Created)의 사용은 특히 새로운 리소스가 요청에 대한 응답으로 서버에 추가되었음을 클라이언트에게 알리는 역할.
3. HTTP Method 에 대해 설명해 주세요.
HTTP 메서드(HTTP methods 또는 HTTP verbs)
웹 서버에 요청을 보낼 때 어떤 유형의 작업이 수행되어야 하는지를 나타내는 표준화된 동작. 이러한 메소드는 요청의 목적을 정의하며 서버가 들어오는 요청을 어떻게 처리해야 하는지를 결정함. 각 HTTP 메소드는 리소스에 수행할 수 있는 특정 작업에 대응.
GET
- 서버에서 데이터 요청. 리소스 조회
- Body값과 Content-Type이 비워져있음
- 전송 방식
-
query (쿼리 파라미터, 쿼리 스트링)
→ 메시지 바디를 통해 전달 할 수 있지만, 지원하지 않는 곳이 많아 권장 XGET /search?q=hello&hl=ko HTTP/1.1 Host: www.google.com // 리소스 경로 뒤에 '?' 문자를 붙여 시작 // key-value 형태로 데이터 전송, &로 추가 데이터 이어줌 // 보안에 취약하므로 보안에 민감하지 않은 내용 포함시킴
-
POST
- 서버에 데이터 전송. 새로운 리소스를 생성(등록)할 때 주로 사용
- Body 값과 Content-Type 값을 작성
- URL 로 데이터를 받지 않음
- 전송 방식
-
메시지 바디
POST /members HTTP/1.1 Content-Type: application/json { "username": "hello", "age": 20 } // 공백 아래에 오는 데이터가 Message Body
-
PUT
- 요청 데이터를 사용해 새로운 리소스를 생성하거나, 대상 리소스를 나타내는 데이터 대체
- 고유값의 리소스가 존재하면 리소스를 대체, 없다면 생성
- 클라이언트가 요청시 리소스를 알고 있음
- 전송 방식
- 메시지 바디
PUT /members/100 HTTP/1.1 Content-Type: application/json { "username": "hello", "age": 20 }
- 메시지 바디
DELETE
-
리소스 삭제
-
Body와 Content-Type 값 없음
DELETE /members/100 HTTP/1.1 Host: localhost:8080
HEAD
- GET 메서드와 동일하지만, 상태 줄과 헤더만 반환받음.
- 리소스의 가용성을 확인하거나 전체 내용을 가져오지 않고도 메타데이터를 검색하는 데 자주 사용됨.
OPTIONS
- 목표 리소스와의 통신 옵션을 설명하기 위해 사용됨. (주로 CORS에서 사용)
- 서버에서 지원하는 HTTP 메소드와 헤더를 확인하는 데 사용할 수 있음.
PATCH
-
리소스의 일부분 수정
PATCH /members/100 HTTP/1.1 Content-Type: application/json { "age": 50 }
CONNETCT
- 요청한 리소스에 대해 양방향 연결을 시작하는 메소드. 터널을 열기 위해 사용
TRACE
- 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
- 요청했던 패킷 내용과 응답 받은 요청 패킷 내용을 비교하여 변조 유무를 확인할 수 있음.
HTTP 메서드 속성
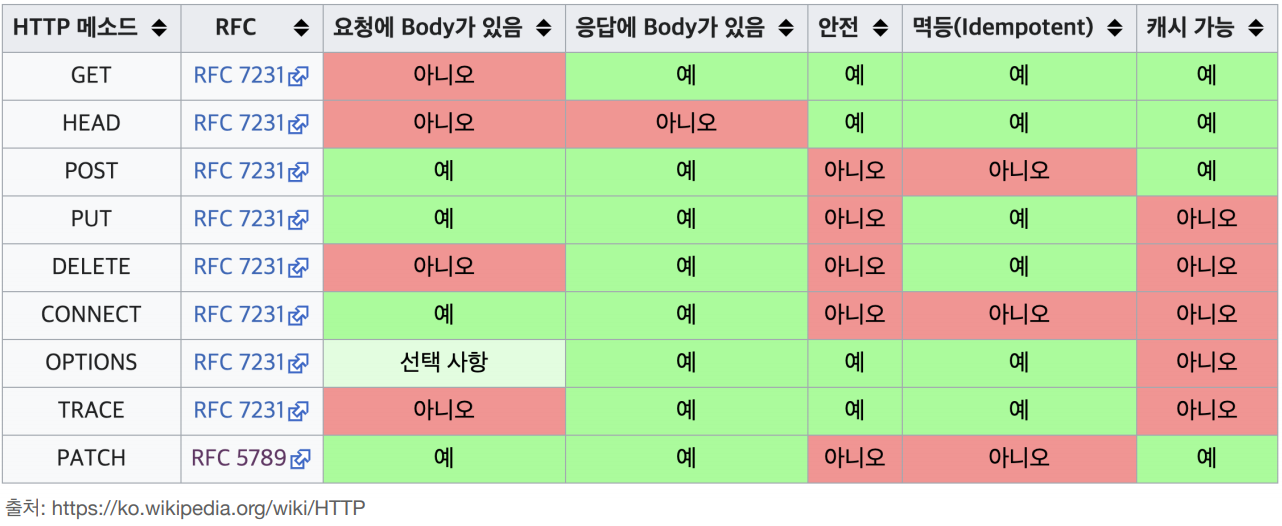
안전 (Safe)
호출해도 리소스를 변경하지 않음. 즉, 데이터의 변경이 일어나지 않는다는 뜻.
GET 메서드는 단순히 데이터를 가져올때 사용하는데, 이러한 GET 같은 메서드를 안전(safe).
멱등 (Idempotent)
몇 번을 호출하든 최종적인 결과는 똑같음.
- 데이터를 가져오거나(GET), 삭제하거나(DELETE), 완전히 대체하는(PUT) 작업은 몇 번이 수행되건 상관없이 결과는 같음.
- 하지만, POST의 경우는 다름.
- POST 메서드로 결제를 수행했다고 가정.
- 해당 POST 메소드가 두 번 호출된다면 결제가 중복해서 발생 가능.
- 사용자의 돈이나 제품의 수량같은 데이터가 계속해서 달라지겠죠.
- 따라서, 이러한 메소드는 멱등하지 않은 것.
- POST 메서드로 결제를 수행했다고 가정.
- 이러한 속성은 서버의 문제로 클라이언트가 같은 요청을 다시해도 되는가? 에 대한 판단 근거가 될 수 있음.
캐시 가능 (Cacheable)
응답 결과 리소스를 캐시해서 사용해도 되는지. GET과 HEAD, POST, PATCH 메소드가 이 속성을 가짐. 일반적으로 GET, HEAD 정도만 캐시로 사용.
요청 / 응답에 Body 존재
요청이나 응답시 데이터를 Message Body에 담아 보내는지, 아닌지에 대한 것.
HTTP Method의 멱등성에 대해 설명해 주세요.
- 여러번 수행해도 결과가 같음, 호출로 인해 데이터가 변형되지 않음을 의미한다.
POST와 PUT, PATCH의 차이는 무엇인가요?
POST- 새 리소스를 생성하거나 데이터를 제출하거나 멱등하지 않은 작업을 수행하려는 경우에 사용.
PUT- 전체 리소스 내용을 업데이트하거나 교체하려는 경우에 사용.
PATCH- 리소스에 부분적인 수정을 적용하려는 경우에 사용.
HTTP 1.1 이후로, GET에도 Body에 데이터를 실을 수 있게 되었습니다. 그럼에도 불구하고 왜 아직도 이런 방식을 지양하는 것일까요?
GET 메소드가 서버에서 데이터를 검색하도록 설계되었으며 이상적으로는 서버의 상태에 부작용을 주지 않아야 한다는 것. GET 요청에 요청 본문을 포함하는 것은 이러한 설계 원칙에 모순되며 여러 문제가 발생할 수 있음
- 캐싱 및 가시성:
GET요청은 브라우저 및 프록시 서버와 같은 중개 서버에서 자주 캐시됨. 요청 본문이 포함되면 캐싱 메커니즘에 간섭하여 잘못된 또는 오래된 응답이 캐시되어 후속 사용자에게 제공될 수 있음. - 서버 및 프록시 동작: 일부 서버 및 프록시 서버는 요청 본문이 포함된
GET요청을 올바르게 처리하지 않을 수 있음. 이들은 본문을 무시하거나 잘못 해석하거나 요청을 거부할 수 있음 이는 예측할 수 없는 동작과 호환성 문제를 초래할 수 있음. - 보안 문제:
GET요청의 요청 본문에 민감한 데이터를 포함시키는 것은 보안 위험. 데이터가 다양한 로그, 브라우저 기록 및 URL이 기록되는 기타 장소에서 노출될 수 있음. - 메세지 바디를 이용해 데이터를 전달할 수는 있으나, 서버에서 따로 구성해야 하는 단점이 있기 때문에 지원하지 않는 곳이 많아 사용하지 않음.
추가 질문
PUT과DELETE사용은 위험할까?- https://okky.kr/questions/395308
- 사실
PUT과DELETE는 나쁜 것도 아니고 보안에 문제가 있는 것도 아님. - 서버 관리자가
PUT과DELETE의 존재를 몰라 보안 취약점이 발생할 수 있음. - 하지만, HTTP 의 모든 METHOD 가 활성화되면 WebDAV extention이 활성화 되니 조심해야 함.
- HTTP 1.1 표준
- OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, CONNECT
- 이를 모두 활성화하게 되면 WebDAV extention에서 아래와 같은 메소드가 추가됨.
- PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK, UNLOCK
- 이 메소드들을 사용하면 웹 서버의 파일을 변경할 수 있어 보안에 심각한 문제
- 따라서, 서버 관리자 입장에서는 GET, POST만 사용하는 것이 편리
- HTTP 1.1 표준
4. HTTP에 대해 설명해 주세요.
*HTTP (하이퍼텍스트 전송 프로토콜)**는 월드 와이드 웹에서 데이터 통신의 기반입니다. 이는 응용 계층 프로토콜로, 클라이언트(일반적으로 웹 브라우저)와 서버(웹 콘텐츠가 호스팅되는 곳) 간의 데이터 교환 방식을 규정합니다. HTTP는 웹 서버에서 HTML 파일, 이미지, 비디오 및 기타 멀티미디어 콘텐츠와 같은 리소스를 검색하는 것을 가능하게 합니다.
HTTP의 주요 특징
- 요청-응답 모델: HTTP는 요청-응답 모델에서 작동합니다. 클라이언트가 HTTP 요청을 서버에 보내면 서버는 요청을 처리하고 요청한 데이터를 포함한 HTTP 응답을 반환합니다.
- Stateless: HTTP는 상태 없는 프로토콜로, 각 요청-응답 주기가 이전 주기와 독립적입니다. 서버는 이전 요청에 대한 기억을 유지하지 않으며 각 요청은 고립적으로 처리됩니다. 이러한 설계는 서버 관리를 간단하게 하며 확장성을 향상시킵니다.
- 메소드: HTTP는 리소스에 대해 수행할 작업을 나타내는 다양한 메소드(또는 동사)를 정의합니다. 일반적인 메소드로는
GET(데이터 검색),POST(데이터 제출),PUT(리소스 업데이트 또는 생성),DELETE(리소스 제거) 등이 있습니다. - 상태 코드: HTTP 응답은 요청의 결과를 나타내는 상태 코드와 함께 제공됩니다. 예를 들어
200 OK는 성공을 나타내며,404 Not Found는 요청한 리소스가 없음을 나타내며,500 Internal Server Error는 서버 측의 문제를 나타냅니다.
HTTP 통신의 허점
우리가 기본적인 HTTP 프로토콜을 사용하는 웹서버(웹앱서버)를 띄워 로그인 API를 호출할 때, 아이디와 비밀번호를 서버로 보내면 입력한 텍스트는 누구든 알아볼 수 있는 평문으로 보내진다. 만약 누군가가 중간에서 이 정보를 탈취한다면 유저의 아이디와 비밀번호를 고스란히 알게 된다.
이러한 치명적인 보안적 허점을 해결하기 위해 인증서를 발급받고, 그 인증서를 기반으로 데이터를 인코딩해서 주고받는다. 이는 다른 누군가가 탈취하더라도 알아볼 수 없게 된다. 이 방법이 HTTPS이다.
기존의 HTTP는 TCP/IP 위의 애플리케이션 계층에서 사용되는 프로토콜이다. HTTPS는 TCP/IP 계층 위에 SSL(TLS)를 얹어 보안을 강화한 프로토콜 방식이다. 이를 통해 모든 HTTP 요청과 응답은 암호화된다.
만일 HTTPS에서 대칭키를 사용할 경우 최초 한 번은 서버에서 클라이언트로 암호화에 사용할 키를 전달해야 하는데, 그 과정에서 암호화 키를 누군가 탈취한다면 누군가 암호화/복호화 가능한 키를 가지고 있기 때문에 암호화 통신을 하더라도 무용지물이 된다. (누군가 데이터를 복호화해서 정보를 다 해석할 수 있다.)
비대칭키를 사용할 경우 서버는 개인키/공개키를 둘 다 가지고 있고, 클라이언트에서 요청할 때 공개키만 준다. 이 공개키로 암호화한 데이터는 서버만 가지고 있는 '개인키'로만 복호화 가능하다. 그리하여 누군가 공개키를 탈취하고 데이터를 탈취하더라도 데이터를 복호화할 수 없게 된다. 하지만 처리 속도가 느려 성능에 문제가 생길 수 있다.
HTTPS는 각각의 단점을 보완하기 위해 대칭키/비대칭키 방식을 혼합하여 사용한다. 최초 한 번 서버가 공개키/개인키를 가지고 있다가 클라이언트가 요청 시 공개키를 전달해준다. 클라이언트는 실제 데이터 전달에 사용할 대칭키를 공개키로 암호화하여 서버에 전달한다. 서버는 개인키를 사용해 대칭키를 복호화하고 그 후 대칭키로 실제 통신이 이루어진다. (이러한 방식을 사용하면 최초 핸드셰이킹 시에만 비대칭키 알고리즘을 사용하니 속도 저하의 문제도 해결되고, 대칭키 전달 시 대칭키를 비대칭키로 암호화하니 중간에 대칭키가 탈취되어도 누군가가 복호화할 수 없는(사용할 수 없는) 키가 되기에 보안적으로도 안전하다.)
이러한 대칭키는 HTTPS 통신 과정에서 세션키로 불린다.
왜 HTTPS Handshake 과정에서는 인증서를 사용하는 것 일까요?
HTTPS 핸드셰이크 과정에서 인증서는 관련된 당사자의 신뢰성과 신뢰성을 확립하는 데 중요한 역할을 합니다.
- 보안 및 신원 확인: 인증서의 주요 목적은 통신에 참여하는 서버의 (그리고 때로는 클라이언트의) 신원을 확인하는 것입니다. 인증서는 본질적으로 서버의 공개 키, 서버에 대한 정보(도메인 이름과 같은), 그리고 신뢰할 수 있는 인증 기관(CA)에서의 디지털 서명을 포함하는 디지털 문서입니다. 이로써 클라이언트는 악의적으로 서버를 가장하는 해커가 아닌 실제 서버와 통신하고 있는지를 확인할 수 있습니다.
- 암호화 키 교환: 핸드셰이크 중에 클라이언트와 서버는 후속 데이터 교환을 보호하기 위해 사용할 암호화 키를 협상합니다. 인증서에 포함된 서버의 공개 키는 "사전 마스터 비밀"을 암호화하는 데 사용되며, 이후 서버의 개인 키로 안전하게 교환 및 복호화됩니다. 이 프로세스를 통해 정품 서버만이 암호화 키를 설정할 수 있으며 데이터 교환의 보안을 강화합니다.
- 믿을 수 있는 제3자: 인증 기관(CAs)은 인증서를 발급하는 신뢰할 수 있는 제3자 기관입니다. 이러한 CA는 고유한 공개 키와 개인 키를 가지며, 인증서에 대한 그들의 디지털 서명은 그들이 발급한 인증서의 신뢰성을 검증합니다. 브라우저와 시스템은 잘 알려진 CA의 신뢰할 수 있는 루트 인증서 목록으로 미리 구성되어 있습니다. 이는 신뢰 체인의 기초를 형성하며, 루트 인증서가 중간 인증서를 확인하고 중간 인증서가 서버 인증서를 확인합니다.
- 중간자 공격 방지: 적절한 인증서 없이는 악의적인 행위자가 서버로 가장하여 클라이언트와 서버 간의 통신을 가로챌 수 있습니다. 이를 중간자 공격이라고 합니다. 인증서의 사용은 클라이언트가 정품 서버와 직접 통신하고 있는지를 보장하여 이러한 공격을 방지하는 데 도움이 됩니다.
SSL 과 TLS
SSL(Secure Sockets Layer)과 TLS(Transport Layer Security)는 모두 네트워크 통신에서 보안을 제공하는 프로토콜로, 데이터의 안전한 전송을 보장하기 위해 사용됩니다. SSL은 초기에 개발되었고, TLS는 이후에 SSL의 개선 버전으로 나왔습니다.
암호화 방식:
- SSL: 주로 RC4와 같은 보안에 취약한 암호화 방식이 사용되었습니다.
- TLS: 더욱 강력하고 안전한 AES(Advanced Encryption Standard)와 같은 암호화 방식이 사용됩니다.
초기 핸드셰이크 단계:
- SSL: SSL에서 초기 핸드셰이크 단계에서는 인증서 교환 시 클라이언트가 서버 인증서를 검증하지 않는 경우도 있었습니다.
- TLS: TLS에서는 초기 핸드셰이크 단계에서 서버 인증서의 검증이 강제되며, 보안 강화를 위해 많은 변경이 이루어졌습니다.
프로토콜 호환성:
- SSL과 TLS는 서로 다른 암호화 방법과 구조로 인해 호환되지 않습니다. 서버와 클라이언트는 안전한 연결을 수립하기 위해 동일한 프로토콜 버전을 명시적으로 지원해야 합니다.
지원 및 사용:
-
SSL의 보안 취약점으로 인해 현대의 응용 프로그램과 시스템은 대부분 SSL 지원을 폐기하고 TLS로 전환하였습니다. 현재 널리 사용되는 버전은 TLS 1.2 및 TLS 1.3입니다.
-
HTTP 1.1과 1.0의 차이 (https://code-lab1.tistory.com/196)
5. 웹소켓과 소켓 통신의 차이에 대해 설명해 주세요.
웹소켓(WebSocket)과 소켓(Socket) 통신은 모두 네트워크 통신 기술로, 클라이언트와 서버 간에 데이터를 실시간으로 주고받는 데 사용됩니다.
그렇지만 차이점의 결론부터 말하자면, WebSocket은 HTTP 프로토콜과의 통합성과 간편성으로 웹 애플리케이션에 더 적합하며, 소켓 통신은 저수준 연결 제어가 필요한 특수한 경우에 주로 사용됩니다.
소켓 통신(Socket Communication):
- 프로토콜: 소켓 통신은 일반적으로 원시 TCP 또는 UDP 소켓을 의미합니다. 이는 클라이언트와 서버 간의 직접적이고 영구적인 연결을 확립하는 것을 포함합니다.
- 연결: 소켓 연결은 풀 더플렉스(Full-Duplex)로, 클라이언트와 서버 모두가 동시에 데이터를 송수신할 수 있도록 합니다.
- 저수준: 소켓 통신은 네트워킹 스택의 하위 수준에서 작동하며, 데이터 전송을 위한 기본적인 메커니즘을 제공합니다. 데이터 직렬화, 단편화 및 프로토콜 세부 사항을 개발자가 수동으로 처리해야 합니다.
- 사용: 소켓 통신은 연결과 데이터에 대한 저수준 제어가 필요한 시나리오에서 일반적으로 사용되며, 온라인 게임, 실시간 스트리밍 또는 최소한의 지연이 중요한 응용 프로그램과 같은 곳에서 사용됩니다.
WebSocket:
- 프로토콜: WebSocket은 HTTP 프로토콜 위에 구축된 프로토콜입니다. 초기 연결을 설정하기 위해 HTTP 핸드셰이크를 시작하고, 연결을 WebSocket으로 업그레이드하여 풀 더플렉스 통신을 가능하게 합니다.
- 연결: WebSocket 연결도 풀 더플렉스이며, 반복적으로 연결을 열고 닫는 오버헤드 없이 양방향 데이터 흐름을 지속적으로 가능하게 합니다.
- 고수준: WebSocket은 상당 부분의 저수준 네트워크 관리를 추상화하며, 실시간 통신을 위한 사용자 친화적인 API를 제공합니다. 개발자가 저수준 소켓 세부 사항을 관리할 필요가 없도록 합니다.
- 사용: WebSocket은 실시간 업데이트나 상호 작용이 필요한 웹 애플리케이션에서 일반적으로 사용되며, 채팅 애플리케이션, 협업 도구 및 실시간 데이터 대시보드와 같은 곳에서 사용됩니다.
주요 차이점:
- 프로토콜: WebSocket은 HTTP 상에서 작동하며, 소켓 통신은 일반적으로 원시 TCP 또는 UDP 소켓을 사용합니다.
- 연결 설정: WebSocket은 초기 연결을 HTTP 핸드셰이크로 시작한 다음 WebSocket으로 연결을 업그레이드합니다. 소켓 통신은 직접적이고 영구적인 연결을 활용합니다.
- 데이터 관리: WebSocket은 데이터 전송 관리를 위한 더 고수준 API를 제공하며, 데이터 직렬화와 단편화를 수동으로 처리하지 않아도 됩니다.
- 사용: WebSocket은 주로 웹 기반 애플리케이션에 적합하며, HTTP 프로토콜과의 통합성과 간편성으로 인해 선택됩니다. 반면, 소켓 통신은 저수준 제어가 필요한 특수한 사용 사례에서 사용됩니다.
- 데이터 형식 : TCP에 기반한 소켓 통신은 단순히 바이트 스트림을 통한 데이터 전송이므로, 바이트로 이루어진 데이터를 다뤄야 하지만, 웹 소켓 통신은 어플리케이션 계층인 7계층에 기반해 메세지 형식의 데이터를 다룬다.
사실 이 둘은 서로 상반되는 개념이 아니기 때문에 완전하게 차이점을 비교할 수는 없음.
- 웹에서도 TCP 소켓 통신으로 실시간 통신을 할 수는 있지만 전송 계층의 원시 바이트 대신 애플리케이션 계층을 통해 메시지를 보내는 것이 개발측면에서 더 적합하기 때문에 TCP 소켓통신에 기반하여 웹 소켓을 발전시킨 것이기 때문.
한 마디로 웹 소켓은 TCP 소켓과 구분되는 것이 아니라 TCP 소켓의 추상화된 형태.
“웹 소켓과 소켓은 전혀 다르다” 보다는 “소켓 통신에 기반하여 웹 소켓은 웹 어플리케이션에 맞게 발전한 형태로 소켓 통신을 한다” .
소켓과 포트의 차이가 무엇인가요?
소켓은 데이터 전송을 위한 통신 종단점으로, 포트는 특정 서비스나 프로세스를 위한 숫자식 식별자입니다.
- 표현: 소켓은 IP 주소와 포트 번호를 모두 포함하며, 포트는 숫자식 식별자만을 나타냅니다.
- 역할: 소켓은 장치나 애플리케이션 간의 통신을 가능하게 하며, 포트는 들어오는 데이터를 적절한 응용 프로그램이나 서비스로 라우팅하는 역할을 합니다.
- 고유성: 소켓은 로컬 및 원격 IP 주소 및 포트 번호의 조합으로 고유하게 식별됩니다. 또한 포트와 연관되어 있는 여러개의 소켓이 있을 수 있습니다. 포트 번호 자체는 IP 주소의 문맥 내에서 고유합니다.
요약하면, 소켓은 IP 주소와 포트 번호의 조합으로 통신 종단점을 나타내며, 포트는 장치 내에서 특정 서비스나 프로세스로 데이터를 라우팅하는 숫자식 식별자입니다. 소켓은 통신을 가능하게 하며 포트는 장치 내에서 들어오는 데이터의 조직화를 돕습니다.
여러 소켓이 있다고 할 때, 그 소켓의 포트 번호는 모두 다른가요?
네, 여러 개의 소켓이 있는 경우 각 소켓과 관련된 포트 번호는 모두 달라야 합니다. 포트 번호는 네트워크 내에서 장치에서 실행 중인 다른 서비스나 프로세스를 고유하게 식별하는 데 사용됩니다. 이 구별은 들어오는 데이터가 올바른 응용 프로그램이나 서비스로 올바르게 라우팅되도록 보장합니다.
만약 두 소켓이 동일한 장치에서 동일한 로컬 포트 번호를 사용한다면 충돌과 데이터 충돌이 발생하여 네트워크가 들어오는 데이터를 의도한 응용 프로그램이나 프로세스로 정확하게 라우팅할 수 없게 될 것입니다. 따라서 각 소켓에 대해 고유한 포트 번호를 보장하는 것은 올바른 통신을 유지하고 데이터 간섭을 방지하는 데 필수적입니다.
일부 예외적인 상황이나 특수한 구성에서는 같은 포트 번호를 공유하는 소켓도 있을 수 있습니다. 예를 들어, 로드 밸런싱을 위해 여러 웹 서버가 같은 포트 번호를 사용하는 경우가 있을 수 있습니다. 하지만 이러한 상황은 특수한 설정과 처리 방식이 필요하며, 일반적인 네트워크 통신에서는 각 소켓이 다른 포트 번호를 사용하는 것이 일반적입니다.
서로 다른 프로세스에서 같은 포트 번호를 열 수 없는가?
TCP/IP 프로토콜을 기반으로 하는 네트워크 통신에서, 포트 번호는 특정 프로세스나 서비스가 특정 컴퓨터에서 통신을 할 때 식별하기 위한 번호입니다. 포트 번호는 0부터 65535까지의 범위에서 할당될 수 있으며, 특정 포트 번호는 하나의 프로세스만 사용할 수 있습니다.
서로 다른 프로세스에서 같은 포트 번호를 동시에 사용할 수 없는 이유는 네트워크 스택의 동작 원리와 겹치는 포트 번호로 인한 혼선을 피하기 위해서입니다. 컴퓨터에서 들어오는 네트워크 패킷은 목적지 포트 번호를 확인하여 어떤 프로세스로 전달해야 할지 결정합니다. 만약 서로 다른 프로세스가 같은 포트 번호를 사용한다면, 네트워크 스택은 어떤 프로세스에게 패킷을 전달해야 할지 혼란스러울 수 있습니다.
6. HTTP/1.1과 HTTP/2의 차이점은 무엇인가요?
HTTP/1.1과 HTTP/2는 모두 웹 브라우저와 웹 서버 간의 통신에 사용되는 하이퍼텍스트 전송 프로토콜의 버전입니다. 인터넷 상에서 데이터를 전송하는 기본 목적은 동일하지만, 두 버전 간에는 여러 가지 주요한 차이점이 있는데,
결론부터 말하자면, HTTP/2는 멀티플렉싱, 바이너리 프로토콜, 헤더 압축, 서버 푸시 등의 기능을 도입하여 HTTP/1.1에 비해 큰 개선을 가져왔습니다. 이러한 개선은 웹 통신의 성능, 효율성 및 보안을 향상시켜 더 빠르고 원활한 웹 경험을 제공합니다.
HTTP/1.1:
- 연결 처리: HTTP/1.1에서 각 HTTP 요청/응답 주기는 별도의 연결을 필요로 합니다. 이를 "요청-응답" 모델이라고 합니다. 클라이언트로부터의 여러 요청은 하나의 느린 요청이 다른 요청의 처리를 차단하는 "헤드 오브 라인 블로킹" 현상을 초래할 수 있습니다.
- 자원 로딩: HTTP/1.1에서는 이미지, 스크립트, 스타일시트와 같은 자원들이 하나의 연결을 통해 순차적으로 로딩됩니다. 이는 네트워크 리소스의 비효율적 사용과 페이지 로딩 시간의 증가를 가져올 수 있습니다.
- 헤더 압축: HTTP/1.1은 헤더 압축을 기본적으로 지원하지 않아 각 요청/응답마다 헤더의 중복이 발생하며 통신의 오버헤드를 증가시킵니다.
HTTP/2:
- 멀티플렉싱: HTTP/2의 가장 중요한 개선점 중 하나는 멀티플렉싱입니다. 하나의 연결을 통해 여러 요청과 응답을 동시에 송수신할 수 있도록 합니다. 이는 HTTP/1.1의 헤드 오브 라인 블로킹 문제를 해결하며 데이터 전송의 효율성을 향상시킵니다.
- 바이너리 프로토콜: HTTP/2는 HTTP/1.1의 텍스트 기반 프로토콜과는 다르게 바이너리 프로토콜을 사용합니다. 이로써 오버헤드를 줄이고 더 효율적인 파싱이 가능해집니다.
- 헤더 압축: HTTP/2는 헤더 압축 메커니즘을 포함하며, HPACK이라는 기법을 사용하여 헤더와 관련된 오버헤드를 크게 줄입니다.
- 서버 푸시: HTTP/2는 서버 푸시를 도입하여 클라이언트가 명시적으로 요청하지 않은 자원(예: 이미지 또는 스크립트)을 클라이언트에게 보낼 수 있게 합니다. 이로써 추가적인 왕복 요청이 줄어듭니다.
- 우선순위 설정: HTTP/2는 요청 우선순위를 설정할 수 있게 하여 클라이언트가 어떤 리소스가 더 중요하고 먼저 전달되어야 하는지 지정할 수 있습니다.
- 보안: 직접적인 기능은 아니지만, HTTP/2는 현대 브라우저에서 프로토콜을 지원하기 때문에 보안 연결(HTTPS)을 사용할 것을 권장합니다.
HOL Blocking 에 대해 설명해 주세요.
헤드 오브 라인 (HOL) 블로킹은 특히 HTTP/1.1과 같은 프로토콜에서 여러 요청과 응답이 단일 연결을 통해 전송되는 네트워크 통신에서 발생할 수 있는 현상입니다. HOL 블로킹은 하나의 요청에 대한 느린 또는 지연된 응답이 후속 응답의 처리를 막아, 사실상 전체 통신 라인을 차단하는 상황을 나타냅니다.
더 자세하게는,
- 단일 연결: HTTP/1.1에서는 여러 요청과 응답을 단일 연결을 통해 보내서 각 요청마다 연결을 반복적으로 설정하고 닫는 오버헤드를 줄일 수 있습니다.
- 요청 대기열: 클라이언트가 서버로 여러 요청을 보내면 서버는 이를 순차적으로 처리하고 응답을 받은 순서대로 클라이언트에 보냅니다.
- 느린 응답: 요청 중 하나가 처리에 더 많은 시간이 필요하거나 응답 생성에 지연이 있는 경우, 이는 서버의 대기열 내 후속 응답의 처리를 지연시킵니다.
- 차단 효과: 서버가 느린 응답을 완료하기를 기다리는 동안, 보낼 준비가 된 다른 응답들은 느린 응답 뒤에 대기열에 있습니다. 이로 인해 나중의 응답은 차단되어 느린 응답이 처리될 때까지 클라이언트에게 보내지지 않게 됩니다.
- 부정적 영향: HOL 블로킹은 느린 응답을 기준으로 전체 처리량이 제한되므로 통신의 효율성과 성능에 큰 영향을 미칠 수 있습니다. 이로 인해 페이지 로딩 시간이 더 오래 걸리고 사용자 경험이 저하될 수 있습니다.
HTTP/2는 HOL 블로킹 문제를 해결하기 위해 멀티플렉싱을 도입했습니다. 멀티플렉싱을 사용하면 단일 연결을 통해 여러 요청과 응답을 동시에 송수신할 수 있어 느린 응답으로 인한 병목 현상 없이 더 빠르고 효율적인 통신이 가능해집니다.
요약하면, HOL 블로킹은 HTTP/1.1과 같은 프로토콜에서 하나의 요청에 대한 느린 또는 지연된 응답으로 후속 응답이 차단되어 통신 과정의 전체 효율성이 감소하는 상황을 나타냅니다.
HTTP/3.0의 주요 특징에 대해 설명해 주세요.
HTTP/3.0, 또는 "HTTP over QUIC"으로도 알려져 있는 것은 하이퍼텍스트 전송 프로토콜의 최신 버전입니다. 이 버전은 이전 버전에 비해 특히 성능과 보안 면에서 여러 가지 중요한 특징과 개선 사항을 도입하는데,
가장 중요한 것은 HTTP/3.0은 QUIC 프로토콜과 통합하여 상당한 성능 개선, 지연 감소 및 강화된 보안을 제공한다는 점입니다.
- QUIC 프로토콜: HTTP/3.0은 QUIC(Quick UDP Internet Connections) 전송 프로토콜을 기반으로 구축되었습니다. QUIC은 TCP와 UDP의 특징을 결합하며 내장된 암호화로 더 빠르고 신뢰성 있는 연결을 제공하기 위해 설계되었습니다.
- 지연 감소: QUIC의 설계는 연결 설정 지연을 최소화하기 위해 연결 설정에 필요한 왕복 수를 최소화합니다. 이로써 초기 데이터 전송의 성능을 향상시킵니다.
- 개선된 보안: QUIC은 기본적으로 암호화를 포함하여 데이터 전송에 더 나은 보안과 개인 정보 보호를 제공합니다. 이로써 데이터의 가로채기와 데이터 전송 중의 잠재적인 공격으로부터 보호됩니다.
- 혼잡 제어: QUIC은 네트워크 상황에 적응하는 혼잡 제어 메커니즘을 포함하여 과도한 데이터 전송을 방지하고 네트워크 리소스를 공정하게 공유합니다.
7. TCP와 UDP의 차이에 대해 설명해 주세요.
*TCP (Transmission Control Protocol)과 UDP (User Datagram Protocol)**는 컴퓨터 네트워크에서 사용되는 전송 계층 프로토콜입니다.
TCP는 확인 응답과 플로우 컨트롤과 같은 메커니즘을 통해 신뢰성 있고 순서가 지정된 데이터 전송을 제공합니다. UDP는 낮은 지연과 높은 속도의 데이터 전송을 제공하며, 신뢰성보다는 속도가 더 중요한 응용 프로그램에 적합합니다. TCP와 UDP의 선택은 응용 프로그램의 특정 요구 사항과 신뢰성과 속도 사이의 균형을 고려하여 결정됩니다.
TCP (Transmission Control Protocol):
- 신뢰성 있는 통신: TCP는 연결 지향적인 프로토콜로, 신뢰성 있고 순서가 지정된 데이터 전송을 보장합니다. 데이터가 오류 없이 올바른 순서로 수신되도록 합니다.
- 확인 응답: TCP는 데이터 수신 확인 응답을 사용하여 데이터의 수신을 확인합니다. 발신자가 데이터에 대한 확인 응답을 받지 못하면 데이터를 다시 전송하여 수신자에게 도달하도록 보장합니다.
- 플로우 컨트롤: TCP는 수신자가 데이터를 처리할 수 있는 능력에 기초하여 데이터 전송 속도를 조절하는 플로우 컨트롤 메커니즘을 사용합니다.
- 연결 설정 및 종료: TCP는 연결을 설정하기 위해 세 단계의 핸드쉐이크를 요구하며, 연결을 종료하기 위해 네 단계의 핸드쉐이크를 수행합니다. 이는 발신자와 수신자 간의 적절한 동기화를 보장합니다.
- 오류 감지 및 수정: TCP에는 데이터 전송 중에 오류를 감지하고 수정하는 오류 확인 메커니즘이 포함되어 있습니다. 오류가 감지되면 수신자가 재전송을 요청합니다.
- 사용 용도: TCP는 데이터의 정확성과 신뢰성이 중요한 응용 프로그램에 사용되며, 웹 브라우징, 이메일, 파일 전송 및 온라인 거래와 같은 분야에서 사용됩니다.
UDP (User Datagram Protocol):
- 비연결성 통신: UDP는 형식적인 발신자와 수신자 간 연결을 설정하지 않는 비연결성 프로토콜입니다. 간단히 수신 확인 응답을 기다리지 않고 데이터를 전송합니다.
- 확인 응답 없음: UDP는 데이터 수신 확인 응답을 제공하지 않기 때문에 데이터가 수신자에게 도달하거나 올바른 순서로 도달할 보장이 없습니다.
- 플로우 컨트롤 없음: UDP에는 데이터 전송 속도를 제어하기 위한 내장된 메커니즘이 없습니다. 이로 인해 수신자가 과다한 데이터로 인해 데이터 손실이 발생할 수 있습니다.
- 연결 설정 및 종료 없음: UDP는 연결 설정 또는 종료 과정을 필요로 하지 않습니다. 단순히 데이터 패킷을 대상 IP 주소와 포트로 전송합니다.
- 오류 수정 없음: UDP는 오류 감지를 위해 체크섬을 포함하지만, 오류 수정을 위한 메커니즘을 제공하지 않습니다. 오류가 감지되면 수신자는 오류가 있는 데이터를 폐기할 수 있습니다.
- 사용 용도: UDP는 정확성보다 속도가 중요한 응용 프로그램에 사용되며, 온라인 게임, 스트리밍 미디어, 음성 통화, DNS 등과 같은 분야에서 사용됩니다.
왜 HTTP는 TCP를 사용하나요?
HTTP가 주로 TCP (전송 제어 프로토콜)를 사용하는 이유는 TCP가 신뢰성 있고 연결 지향적인 통신 채널을 제공하기 때문입니다. 이 선택은 HTTP의 요구 사항과 잘 맞으며 웹 콘텐츠를 정확하고 손실 없이 전달하는 것을 목표로 합니다.
- TCP는 신뢰성 있는 데이터 전송을 보장합니다. 서버에서 보낸 데이터가 오류 없이 정확한 순서로 클라이언트에 도달하는 것을 보장합니다. 이는 이미지, 스크립트, HTML 파일과 같은 웹 리소스에서 정확성이 중요한 경우 중요합니다.
- TCP에는 체크섬을 사용하여 오류 감지 메커니즘이 포함되어 있습니다. 데이터 전송 중에 오류가 감지되면 TCP는 정확성을 보장하기 위해 잘못된 데이터의 재전송을 요청합니다.
- TCP는 데이터 패킷의 순서를 유지합니다. 이는 HTML, CSS, 이미지 등의 리소스 순서가 올바르게 보존되어야 하는 웹 페이지에서 중요합니다.
- 웹은 기존의 TCP/IP 네트워킹 인프라 위에서 구축되었으며, 따라서 HTTP가 통신에 TCP를 사용하는 것은 자연스러운 선택입니다.
그렇다면, 왜 HTTP/3 에서는 UDP(QUIC) 를 사용하나요? 위에서 언급한 UDP의 문제가 해결되었나요?
HTTP/3에서 UDP(사용자 데이터그램 프로토콜) 위에 구축된 QUIC의 사용은 UDP와 관련된 문제점을 최대한 해결하고 그 장점을 활용하기 위해 가져왔습니다. 예를 들어, QUIC는 기존 UDP에는 없는 기능인 신뢰성, 오류 수정 및 혼잡 제어를 위한 자체 메커니즘을 통합해 사용하였습니다.
즉, HTTP/3는 UDP 위에서 구축된 QUIC 프로토콜을 사용하여 지연 감소, 빠른 연결 설정 및 향상된 멀티플렉싱과 같은 장점을 활용하면서 QUIC 프로토콜 자체에 내장된 메커니즘을 통해 UDP와 관련된 도전 과제를 해결합니다. 이로써 HTTP/3는 이전 버전의 HTTP에 비해 더 효율적이고 빠른 웹 브라우징 경험을 제공합니다.
TCP, UDP를 사용 시 고려점은?
데이터 신뢰성, 순서가 있는 데이터 전달 및 오류 수정이 응용 프로그램에 필수적인 경우 TCP를 선택할 것이고,
낮은 지연, 실시간 통신 및 최소한의 오버헤드가 더 중요하며 응용 프로그램이 자체적인 오류 처리를 처리할 수 있는 경우 UDP를 선택할 것 같습니다.
Checksum이 무엇인가요?
체크섬(checksum)은 데이터 집합에서 송신이나 저장 중에 발생한 오류를 감지하기 위해 존재하는 값입니다. 이는 데이터에 대한 간단한 오류 감지 형태로, 데이터에 대한 계산을 수행하고 일반적으로 짧은 이진 순서로 된 값을 생성하는 과정을 포함합니다. 이 값은 전송이나 저장 전에 데이터에 첨부됩니다.
데이터를 수신하거나 검색할 때 동일한 체크섬 계산을 다시 수행합니다. 계산된 체크섬은 전송되거나 저장된 데이터와 함께 전송된 체크섬 값과 비교됩니다. 체크섬이 일치하는 경우, 데이터가 오류 없이 정확하게 수신되거나 검색된 것을 나타냅니다. 체크섬이 일치하지 않으면 데이터가 전송이나 저장 중에 손상되거나 변경되었을 수 있다는 것을 나타냅니다.
하지만 체크섬은 기본적인 오류 감지 수준을 제공하지만 오류 수정 기능은 제공하지 않습니다. 체크섬이 오류를 나타내는 경우, 추가 조치(재전송 또는 올바른 데이터 요청 등)가 필요할 수 있습니다. 보다 강력한 오류 처리를 위해 순환 중복 검사(CRC)와 같은 더 고급 오류 감지 및 수정 방법이 사용됩니다.
TCP와 UDP 중 어느 프로토콜이 Checksum을 수행할까요?
TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol) 모두 체크섬을 사용이 가능하기는 합니다.
TCP: TCP는 헤더에 체크섬을 포함합니다. TCP 연결을 통해 데이터가 전송될 때, 전송되는 데이터를 기반으로 체크섬 값을 계산합니다. 이 체크섬은 패킷의 TCP 헤더에 추가됩니다. 수신자가 데이터를 받을 때, 수신된 데이터를 기반으로 체크섬을 다시 계산하고 TCP 헤더의 체크섬 값과 비교합니다. 체크섬이 일치하면 데이터가 오류 없이 수신된 것으로 나타납니다. 일치하지 않으면 데이터가 전송 중에 손상되었을 수 있다는 것을 시사합니다.
UDP: UDP도 헤더에 체크섬을 포함합니다. 그러나 UDP에서 체크섬의 사용은 선택 사항입니다. UDP 응용 프로그램이 체크섬을 사용하려면 전송하는 데이터를 기반으로 체크섬 값을 계산하고 UDP 헤더에 추가합니다. 데이터가 수신될 때, 수신자는 수신된 데이터를 기반으로 체크섬을 계산하고 UDP 헤더의 체크섬 값과 비교할 수 있습니다. 응용 프로그램에서 체크섬 불일치를 감지하면 필요한대로 오류 처리를 수행할 수 있습니다.
요약하면, TCP와 UDP 모두 오류 감지를 위해 체크섬을 활용할 수 있지만, TCP는 헤더에 모든 전송 데이터에 대해 체크섬을 사용하도록 요구하며, UDP는 응용 프로그램이 선택적으로 사용하거나 사용하지 않을 수 있는 기능으로 남겨둡니다.
그러면, Checksum을 통해 오류를 정정할 수 있나요?
아니요, 체크섬은 오류 수정을 위해 설계된 것이 아니며, 오류 감지에 사용됩니다.
체크섬은 데이터 전송 또는 저장 중에 발생한 오류의 존재 여부를 식별할 수 있지만, 이러한 오류를 수정할 수는 없습니다.
오류 수정을 위해 더 고급 기술인 전방 오류 수정(FEC)이나 자동 반복 요청(ARQ) 프로토콜 등이 사용됩니다. 이러한 방법은 전송된 데이터에 여분의 정보를 도입하여 수신자가 전체 데이터 재전송 없이 오류를 수정할 수 있게 합니다. 그러나 이러한 기술은 단순한 체크섬보다 복잡하며 추가 오버헤드가 포함됩니다.
TCP가 신뢰성을 보장하는 방법에 대해 설명해 주세요.
TCP (Transmission Control Protocol)은 오류 감지, 확인 메커니즘, 순서 번호, 그리고 손실된 또는 손상된 데이터의 재전송과 같은 다양한 기술을 조합하여 신뢰성을 보장합니다.
- 체크섬: TCP는 데이터의 오류를 감지하기 위해 헤더에 체크섬을 포함합니다. 수신자가 수신된 데이터로부터 다른 체크섬을 계산하는 경우, 데이터가 손상되었다는 것을 나타내며, 수신자는 재전송을 요청합니다.
- 확인 및 재전송: 송신자가 데이터 패킷을 전송할 때, 수신자는 각 패킷의 수신을 확인합니다. 송신자는 지정된 시간 내에 확인을 받지 못하면 해당 패킷이 전송 중에 손실되거나 손상되었다고 가정하고 패킷을 다시 전송합니다. 이를 통해 누락된 또는 오류가 있는 데이터 패킷이 다시 전송됩니다.
- 순서 번호: TCP는 보낸 각 데이터 패킷에 순서 번호를 할당합니다. 수신자는 이러한 순서 번호를 사용하여 순서가 바뀐 패킷을 재정렬하고 누락된 패킷을 감지합니다. 패킷이 누락되거나 순서가 바뀐 경우 수신자는 누락된 패킷의 재전송을 요청할 수 있습니다.
- 슬라이딩 윈도우: TCP는 송신자와 수신자 간의 데이터 흐름을 제어하기 위해 슬라이딩 윈도우 메커니즘을 사용합니다. 이를 통해 송신자는 각 패킷마다 개별 확인을 기다리지 않고 일정한 수의 패킷을 계속 전송할 수 있습니다. 윈도우의 크기는 네트워크 조건에 따라 동적으로 조정될 수 있습니다.
- 선택적 반복: TCP는 수신자가 순서가 바뀐 패킷을 확인하고 재정렬할 수 있는 선택적 반복 메커니즘을 사용합니다. 송신자는 누락된 패킷만 재전송하면 되므로 누락된 패킷 다음의 모든 패킷을 재전송할 필요가 없습니다.
- 플로우 제어: TCP는 수신자가 처리할 수 있는 데이터 양을 초과하지 않도록 플로우 제어 메커니즘을 사용합니다. 이를 통해 혼잡을 방지하고 데이터가 관리 가능한 속도로 전달됩니다.
- 연결 설정 및 종료: TCP는 연결 설정에 세 단계의 핸드셰이크를 사용하며, 연결 종료에는 네 단계의 핸드셰이크를 사용합니다. 이러한 메커니즘은 송신자와 수신자가 데이터 전송을 준비하고 연결이 닫히기 전에 모든 데이터가 전송되고 수신되도록 보장합니다.
TCP의 혼잡 제어 처리 방법에 대해 설명해 주세요.
- 느린 시작(Slow Start): 연결이 설정되거나 일정 기간 동안 비활동한 후 데이터 전송이 다시 시작될 때, TCP는 보수적인 송신 속도로 시작합니다. 이를 위해 확인된 각 패킷마다 혼잡 윈도우 크기를 두 배로 증가시킵니다. 이 접근 방식은 혼잡으로 인한 트래픽 급증을 방지하는 데 도움이 됩니다.
- 혼잡 회피(Congestion Avoidance): 느린 시작 단계 이후, TCP는 혼잡 회피 단계로 진입합니다. 패킷 왕복 시간마다 한 세그먼트만 추가하면서 혼잡 윈도우 크기를 보다 점진적으로 증가시킵니다. 이 방법을 통해 송신자는 혼잡을 유발하지 않고 네트워크가 처리할 수 있는 최적의 송신 속도를 찾을 수 있습니다.
- 빠른 재전송과 빠른 복구(Fast Retransmit and Fast Recovery): 송신자가 세그먼트의 손실(ACK가 누락된 경우)을 감지하면 혼잡이 발생했다고 가정하고 빠른 재전송을 트리거합니다. 타임아웃을 기다리지 않고 누락된 세그먼트를 재전송합니다. 또한 TCP는 빠른 복구 모드로 전환하여 혼잡 윈도우 크기를 줄이고 혼잡 회피 임계값으로 점진적으로 증가시킵니다.
- 타임아웃과 재전송(Timeout and Retransmission): 송신자가 일정한 세그먼트에 대한 ACK를 타임아웃 기간 내에 받지 못하는 경우, 세그먼트가 혼잡으로 인해 손실된 것으로 가정합니다. 송신자는 누락된 세그먼트를 재전송하고 네트워크 혼잡 상태에 따라 혼잡 윈도우 크기를 조정합니다.
- 명시적 혼잡 통보(ECN): ECN은 네트워크 라우터가 IP 헤더의 특별한 비트를 사용하여 엔드포인트에게 혼잡 상태를 신호로 보낼 수 있는 메커니즘입니다. TCP 활성화된 장치는 이러한 신호를 기반으로 동작을 조정하며, 혼잡을 피하기 위해 송신 속도를 줄입니다.
- 동적 조정(Dynamic Adjustments): TCP는 지속적으로 네트워크 조건을 모니터링하며 왕복 시간, 패킷 손실률, 사용 가능 대역폭 등을 포함합니다. 이러한 요소를 기반으로 송신 속도와 혼잡 윈도우 크기를 동적으로 조정하여 최적의 성능을 유지합니다.
- 임의 조기 감지(Random Early Detection, RED): TCP 프로토콜 자체에는 포함되지 않았지만, 네트워크 라우터는 혼잡을 관리하기 위해 RED를 구현할 수 있습니다. RED는 네트워크가 심각하게 혼잡해지기 전에 패킷을 삭제하거나 표시하여 TCP가 심각한 혼잡이 발생하기 전에 반응할 수 있도록 합니다.
