인덱스(Index)?
- 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조.
- 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장됨.
- 이렇게 인덱스가 생성하였다면 앞으로 쿼리문에 "인덱스 생성 컬럼을 Where 조건으로 거는 등"의 작업을 하면 옵티마이저에서 판단하여 생성된 인덱스를 탈 수가 있음.
Index 사용 시 장점
테이블을 Full scan 하는 대신 정렬되어 있는 Index에서 scan하기 때문에 조회 속도가 굉장히 빨라짐.
아래의 경우 사용하면 그 장점을 극대화 할 수 있음.⤵️
- 특히, 조건 검색 Where 절에서 많이 쓰이는 column
- 컬럼 = "특정값" 같이 equal 비교에 자주 쓰이는 column
- PK 컬럼처럼 중복값이 없거나 적은 column
- Order by에 자주 걸리는 column
- Join에 자주 걸리는 column
단점
Index로 지정된 값들을 정렬된 상태로 계속 유지시켜줘야 하는 공간적, 시간적 비용 비용이 발생함.
- INSERT, UPDATE, DELETE같은 DML(data manipulation language)행위가 일어났을 때 INDEX 테이블 내에 있는 값들을 다시 정렬을 해야함.
- 한번의 DML 행위로 INDEX 테이블, 원본 테이블 두 군데에 데이터 수정 작업해줘야 함.
Index 구현 자료구조
가장 많이 사용하는 인덱스의 구조는 밸런스드 트리 인덱스 구조.
그리고 B-TREE 인덱스 중에서도 가장 많이 사용하는것은 B*TREE 와 B+TREE 구조.
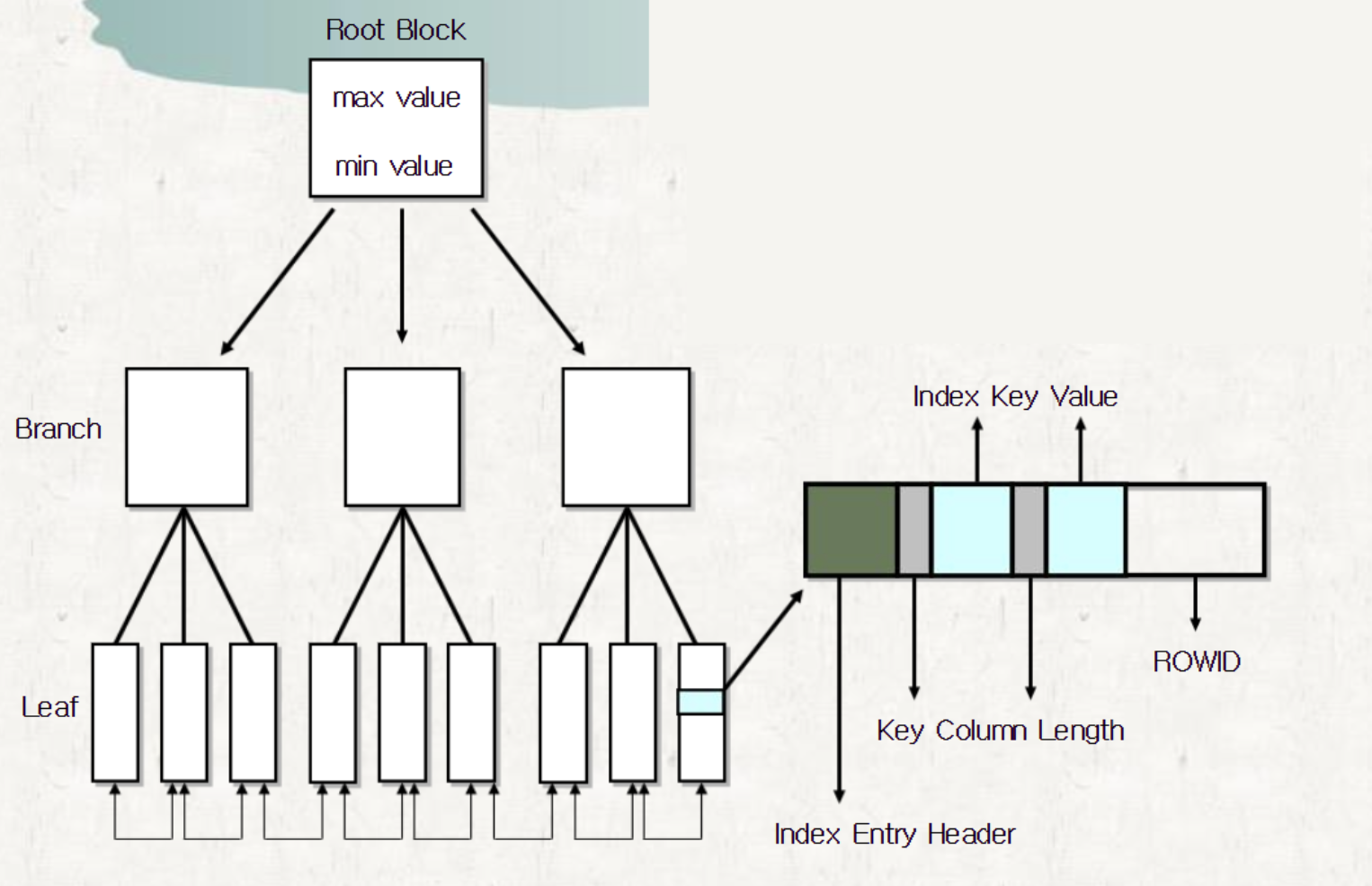
결합 Index?
- 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것.
아래의 경우 사용하면 좋다.⤵️
- where절에서 and 조건으로 자주 결합되어 사용되면서 각각의 분포도 보다 두 개 이상의 컬럼이 결합될 때 분포도가 좋아지는 컬럼들.
- Join의 연결고리가 되는 컬럼들.
- Order by에 자주 묶이는 컬럼들.
결합 인덱스의 컬럼 순서 결정이 중요함.
- 순서를 잘못 배열하면 결합 인덱스의 발동 확률이 매우 낮아질 수 있기 때문.
예시) emp_pay 테이블에서 급여년월, 급여코드, 사원번호 컬럼으로 emp_pay_idx라는 결합 인덱스를 생성한 상황.
create index emp_pay_idx on emp_pay(급여년월, 급여코드, 사원번호);--
올바른 사용법은 다음과 같음.
select * from emp_pay where 급여년월 = '202107';
select * from emp_pay where 급여년월 = '202107' and 급여코드 ='정기급여';--
아래는 결합 Index 조건이 발동되지 않아 사실상 full scan 하는 경우.
select * from emp_pay where 급여코드 = '정기급여';
select * from emp_pay where 사원번호 = '20210401';
select * from emp_pay where 사원번호 = '20210401' and 급여코드 = '정기급여';즉, where 조건문을 나열할 때 결합 인덱스의 첫 번째 컬럼인 급여년월의 조건식이 없으면 B*Tree 구조인 결합 인덱스를 검색할 수 없기 때문에 결합 인덱스가 무용지물이 되니 주의해야 함.
--
다음은 결합 Index 조건의 효율성이 크게 떨어지는 경우.
select * from emp_pay where 급여년월 LIKE '2021%' and 급여코드 = '정기급여';이 경우, Equal(=)이 아닌 범위 연산자 LIKE '2021%' 조건을 사용했으므로 두번째 칼럼인 급여코드에 대한 조건을 B*Tree에서 쉽게 찾을수가 없게 됨.
따라서, 급여코드에 대한 조건은 인덱스를 찾아가는 검색조건이 아니라 인덱스 값이 조건에 맞는지 여부를 검증하는 체크 조건이 되는 것.
--
select * from emp_pay where 급여년월 = '202107' and 사원번호 = '20210401';마지막 경우는, 첫번째 칼럼인 급여년월의 조건이 equal(=)이더라도 두번째 컬럼인 급여코드에 대한 조건이 없으므로 세번째 칼럼인 사원번호 조건을 검색 조건이 아닌 체크 조건으로 밖에 사용할 수 없게 됨. 사실상 full scan이 일어나고 있는 것.
Reference
https://coding-factory.tistory.com/746
https://coding-factory.tistory.com/755
