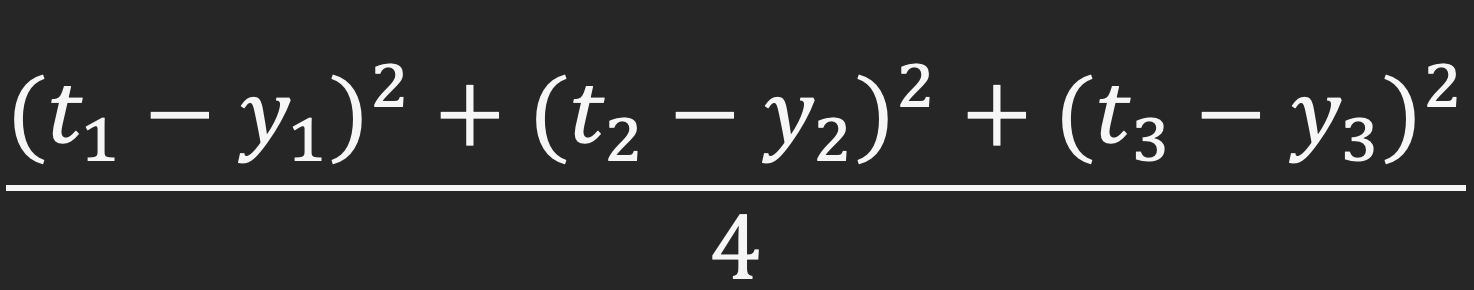numpy&Pandas -> Data처리
Machine Learning
AI(인공지능, Artificial Intelligence) : 사람의 사고능력을 구현한 소프트웨어(시스템)
1. Strong AI : 사람과 구별이 불가능한 AI
2. weak AI : 특정분야에 국한된 AI(바둑, 자율주행, 챗봇...)
cs쪽에서 Data기반 -> 학습(Program) -> 예측(prediction)
: Machine Learning
지금까지 우리가 하고 있는 일반적인 Program은 Rule Based Program(Explict Program)
머신러닝은 규칙을 찾기 힘들다..
우리가 하는 프로그램은
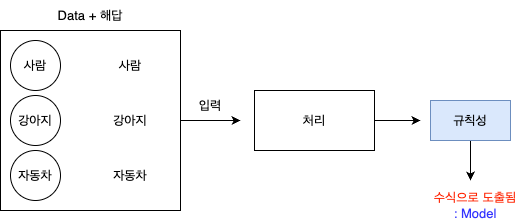
Machine Learning기법
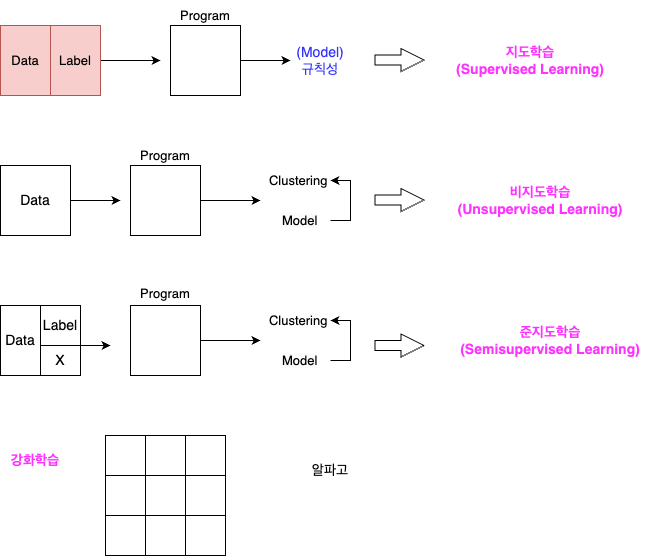
1. 지도학습
- Regression(통계)
- SVM(Support Vector Machine)
- Decision Tree,(-> Ensemble ver) Random Forest
- KNN
Native Bayes
----- 위와 아래의 가장큰 차이점은 Data형태
(Artificial) Neural Network : ANN
-> 발전 Deep Learning
정형 Data : 일반 Machine Learning
비정형 Data : Deep Learning
2. 비지도 학습기법
K-reans, DBSCAN
3. 강화학습 기법
ReinForcement Learning(강화학습)
Machine Learning Type
???
1. Regression(회귀)
: 통계쪽 기법
: 어떤 데이터에 대해 그 데이터에 영향을 주는 조건들의 영향력을 이용해서 데이터에 대한 조건부 평균을 구하는 기법
(= 데이터에 대해 그 데이터를 가장 잘 표현하는 함수)
평균은 우리가 대푯값(: 최소값/최대값/평균/최빈값)으로 가장 많이 이용하는 값
ex) 우리나라의 아파트 가격은 얼마인가요?
데이터 : 아파트
조건 : 평수, 서울/지방...y(가격) = 평수x8000 + 역세권 1or0 x 3000 + 학군 1or0 x 5000
Regression Model
- 독립변수(feature특성)
종속변수(target) - lable
연수기간/공부기간 : 독립변수(feature특성)
성적 : 종속변수(target) - lable
| 독립변수 | 독립변수 | 종속변수 |
|---|---|---|
| 연수기간 | 공부기간 | 성적 |
| 1 | 2 | 10 |
| 3 | 1 | 70 |
| 5 | 10 | 100 |
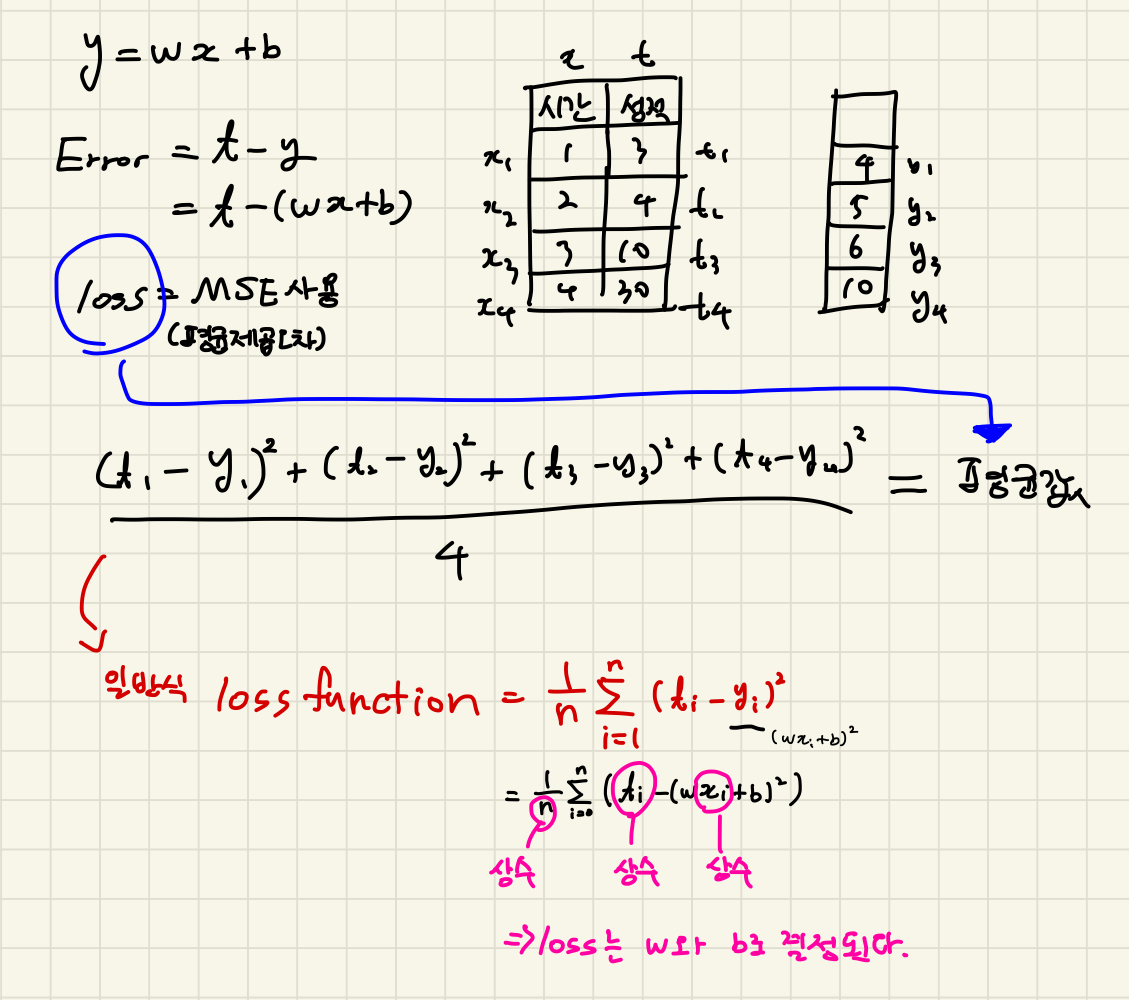
y=베타x + 베타1
종속변수 = 가중치독립 + 상수
=>
y= ax + b
-
종속변수가 추가되면 차원이 추가됨 ex) 2차원에서 3차원
-
독립변수가 1개일 때
:y=ax+b형태로 만들어짐 : claasical Lineur Regression Model -
독립변수가 2개일 때
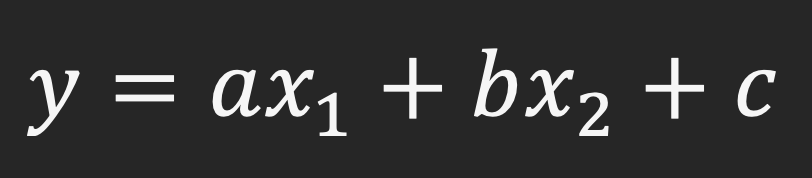
(만약 데이터가 평균을 사용하기 힘든 편향된 데이터라면 회귀모델 사용을 고려해야 함)
Regression(회귀)
1800년대 찰스다윈 '종의 기원'
우성인자를 이용해 더 나은 인류...=> 우생학
코드로 알아보기
0330-LinearRegression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df= pd.DataFrame({
'공부시간(x)' : [1,2,3,4,5,7,8,10,12,13,14,15,18,20,25,28,30],
'시험점수(t)' : [5,7,20,31,40,44,46,49,60,62,70,80,85,91,92,97,98]
})
display(df.head())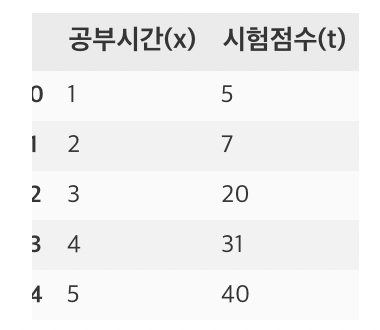
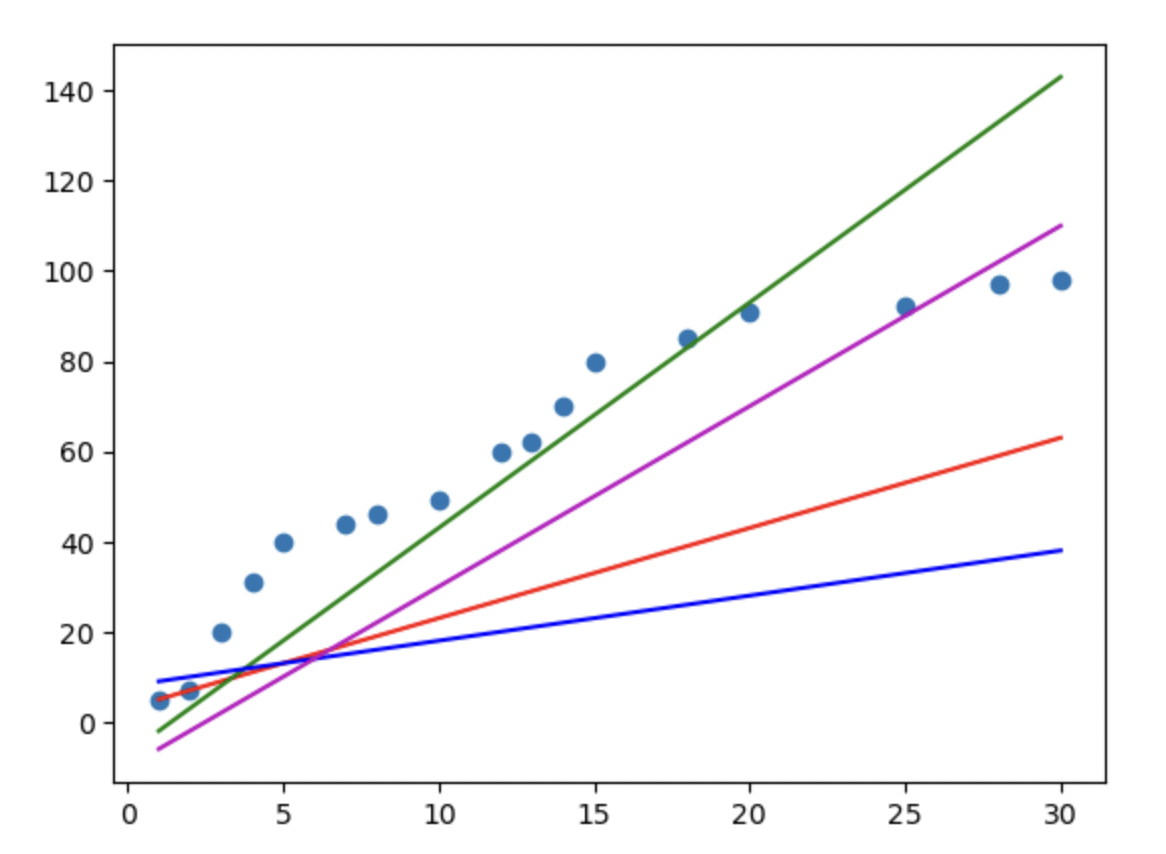
데이터의 분포를 그래프로 알아보자
: scatter()를 이용
plt.scatter(df['공부시간(x)'], df['시험점수(t)'])
plt.show()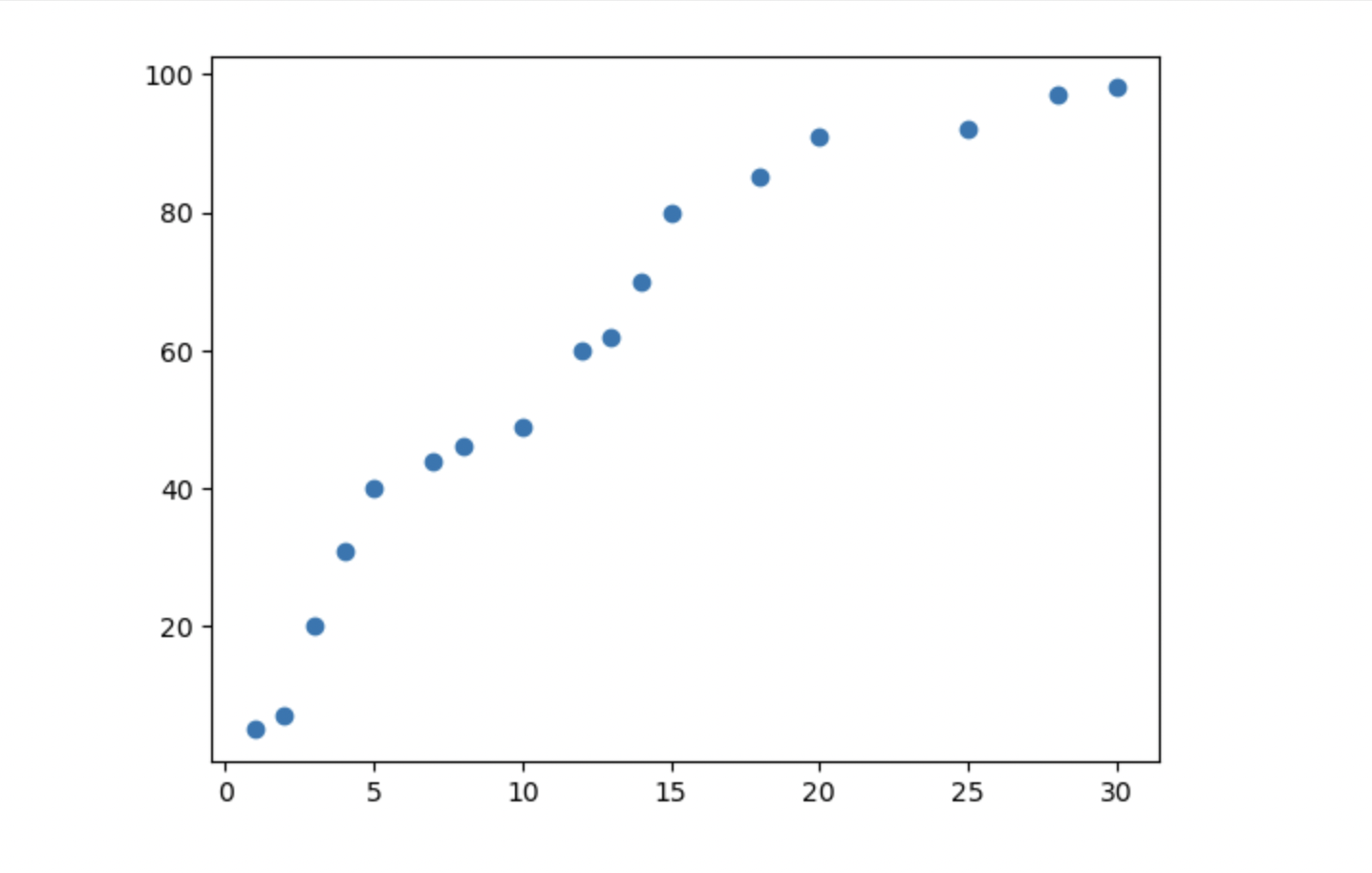
우리가 찾고 싶은 건 classical Linear regeression model
현재 데이터에 대해서는 1차 직선으로 표현
y = ax +b
직선을 그릴때는plot()을 이용하면 그릴 수 있음
plt.scatter(df['공부시간(x)'], df['시험점수(t)'])
plt.plot(df['공부시간(x)'],2*df['공부시간(x)'] + 3, color='r')
plt.plot(df['공부시간(x)'],5*df['공부시간(x)']-7, color='g')
plt.plot(df['공부시간(x)'],1*df['공부시간(x)']+8, color='b')
plt.plot(df['공부시간(x)'],4*df['공부시간(x)']-10, color='m')
plt.show()