CNN
: 이미지 학습, 예측
: Feature Extraction과 학습(DNN)으로 나뉨
: 학습(DNN) (convolution, pooling)
: convolution - 특징을 뽑아내기와 Image개수 증가
: pooling - Image 개개의 size를 축소
실사 Image에 대해서도 학습이 잘 되나요?
① Data량이 많아야 함 (정제가 잘 된 Data는 수가 적더라도 학습이 가능함)
② Feature의 수가 작아야 함 (Feature의 갯수가 많을 수록 과적합이 일어남)
하지만 충분한 데이터가 있음에도 생각보다 학습이 안 됨
데이터가 더 적어지면 model은 더 안 좋아지는게 현실..
이 문제를 해결하려면,
① Augmentation(증식) -> ImageDataGenerator
②
Pretrainde Network
: Inception/ResNet/EffientNet/VGG/MobileNet 등등
: 다운로드 해야하지만, keras에서 쉽게 사용할 수 있음
- Google -> Inception(45개-convolution, 20개-pooling) -> 모델을 만든다. Data는
Imagenet이라는 곳에서 - MS -> ResNet(Inception의 3배)(EffientNet/VGG/MobileNet 도 있음)
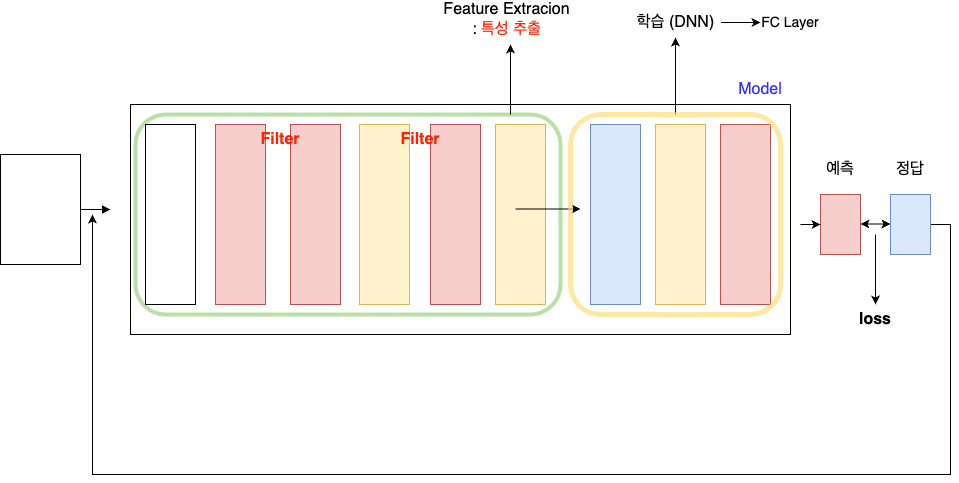
: 필터를 만들어냄
: 이걸 학습하는게 전이학습(Transfer)
전이학습의 시발점??
코드로 알아보기
(colab에서)
# 우리는 전이학습 모델로 VGG16을 이용할 거에요
# 누군가 이미 만들어놓은 VGG16이라는 이름의 CNN모델을 이용해보자
from tensorflow.keras.applications import VGG16
model_base = VGG16(weights ='imagenet',
include_top=False,
input_shape=(150,150,3))
print(model_base.summary())
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = '/content/drive/MyDrive/(KOSA)Python 실습/cat_dog_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1/255)
batch_size=20
def extract_feature(directory, sample_count):
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count,))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i = 0
for x_data_batch, t_data_batch in generator:
feature_batch = model_base.predict(x_data_batch)
features[i*batch_size:(i+1)*batch_size] = feature_batch
labels[i*batch_size:(i+1)*batch_size] = t_data_batch
i += 1
if i * batch_size >= sample_count:
break;
return features, labels
train_features, train_labels = extract_feature(train_dir,2000)
validation_features, validation_labels = extract_feature(validation_dir,1000)
test_features, test_labels = extract_feature(test_dir,1000)
train_features = np.reshape(train_features, (2000,4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000,4 * 4 * 512))
test_features = np.reshape(test_features, (1000,4 * 4 * 512))
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import RMSprop
model = Sequential()
model.add(Dense(256,
activation='relu',
input_shape=(4 * 4 * 512,)))
model.add(Dropout(0.5))
model.add(Dense(1,
activation='sigmoid'))
model.compile(optimizer=RMSprop(learning_rate=2e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_features,
train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels)) 
Machine Learning(지도)
- Regression
- Deep Learning(비정형)
- vision -> 전이학습 (이미지 처리를 위해 전이학습까지 했음)
- NLP(자연어)
- Deep Learning(비정형)

하이 반가워요😆💻