Reward Function
기본 제공 함수
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)Training Configuration
- Speed : [0.5 : 1.0] m/s
- Steering Angle : [30 : 30]
- Reinforcement Learing Algorithm : PPO
- Learing time : 1 Hour
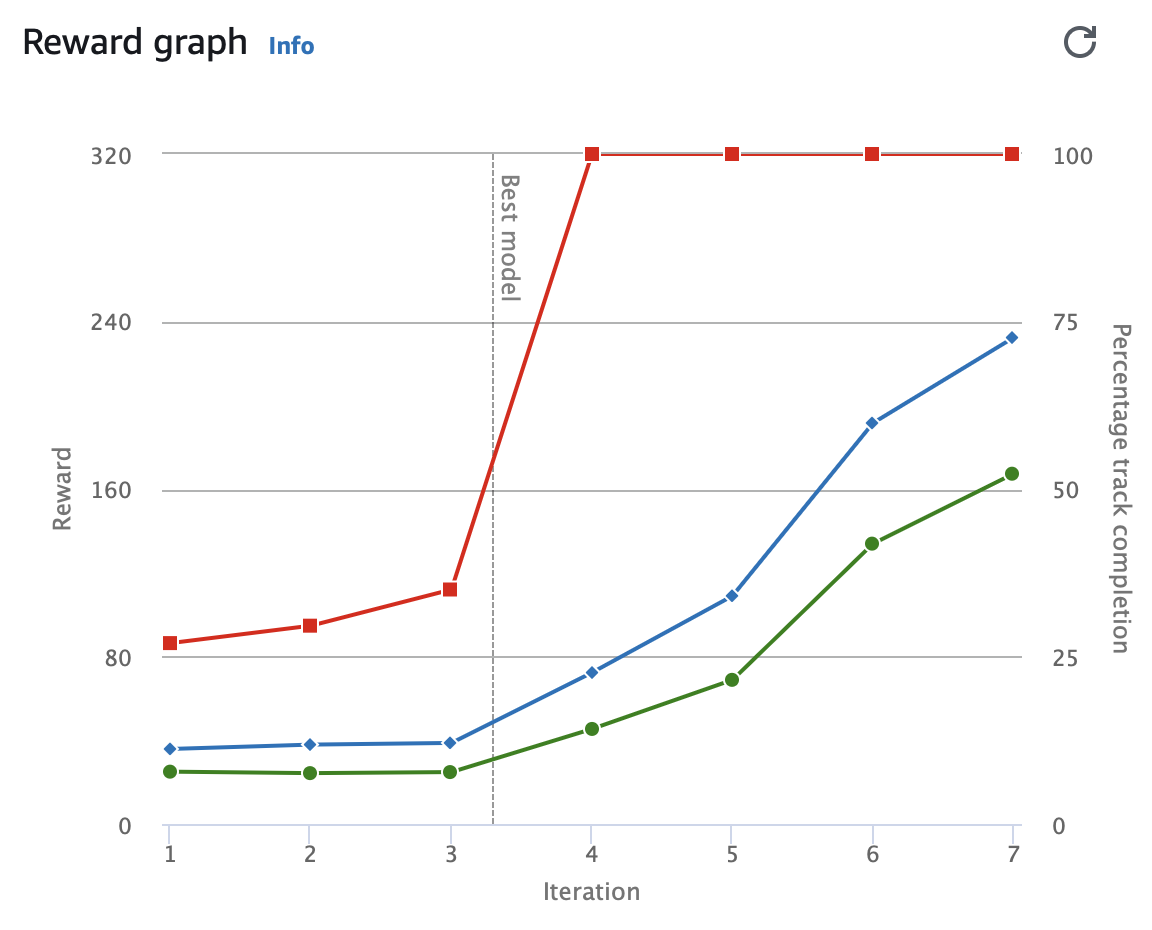
Evaluation Results
- time : 19.263
- off-track : 0
지그재그 방지 코드 - 예시 함수
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
abs_steering = abs(params['steering_angle']) # Only need the absolute steering angle
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD = 15
# Penalize reward if the car is steering too much
if abs_steering > ABS_STEERING_THRESHOLD:
reward *= 0.8
return float(reward)Training Configuration 1
- Speed : [0.5 : 1.0] m/s
- Steering Angle : [30 : 30]
- Reinforcement Learing Algorithm : PPO
- Learing time : 1 Hour
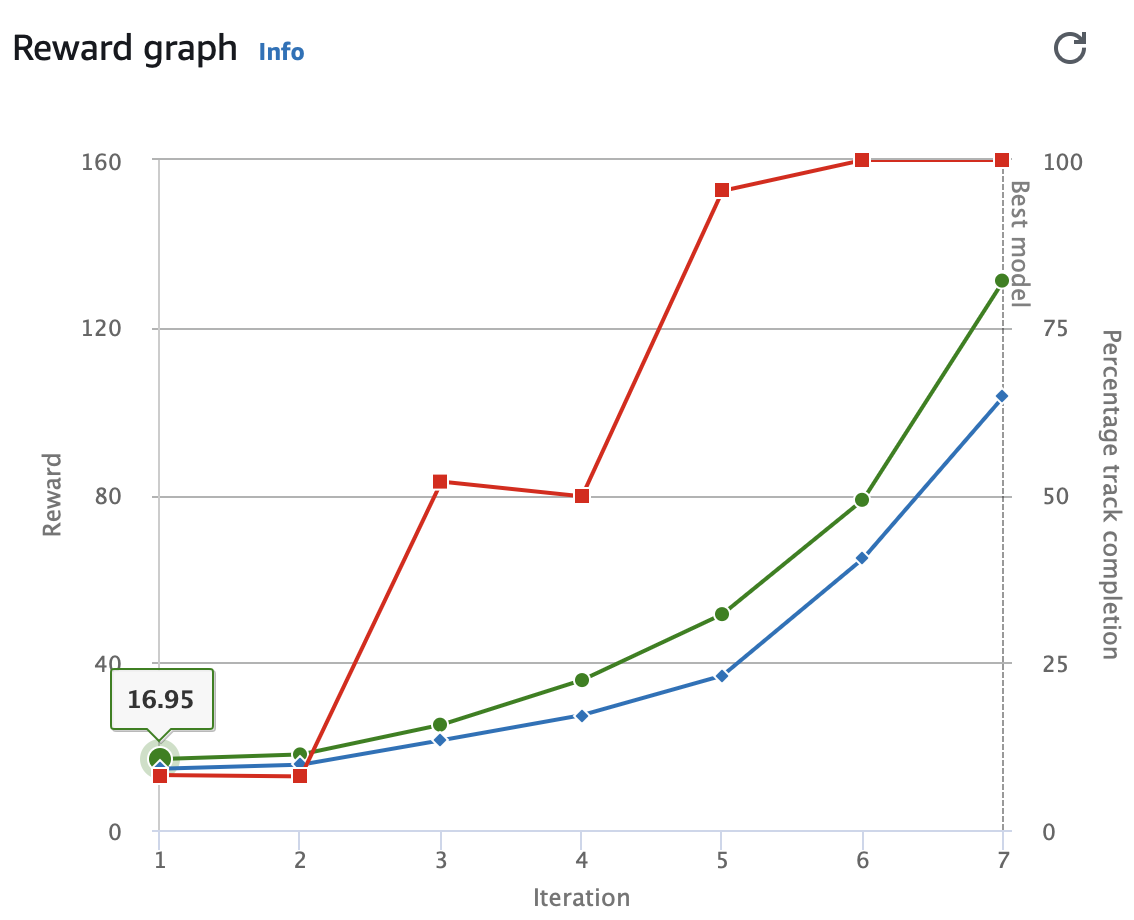
Training Configuration 2
- Speed : [0.5 : 2.0] m/s
- Steering Angle : [30 : 30]
- Reinforcement Learing Algorithm : PPO
- Learing time : 1 Hour
Evaluation Results 1
- time : 18.670
- off-track : 0
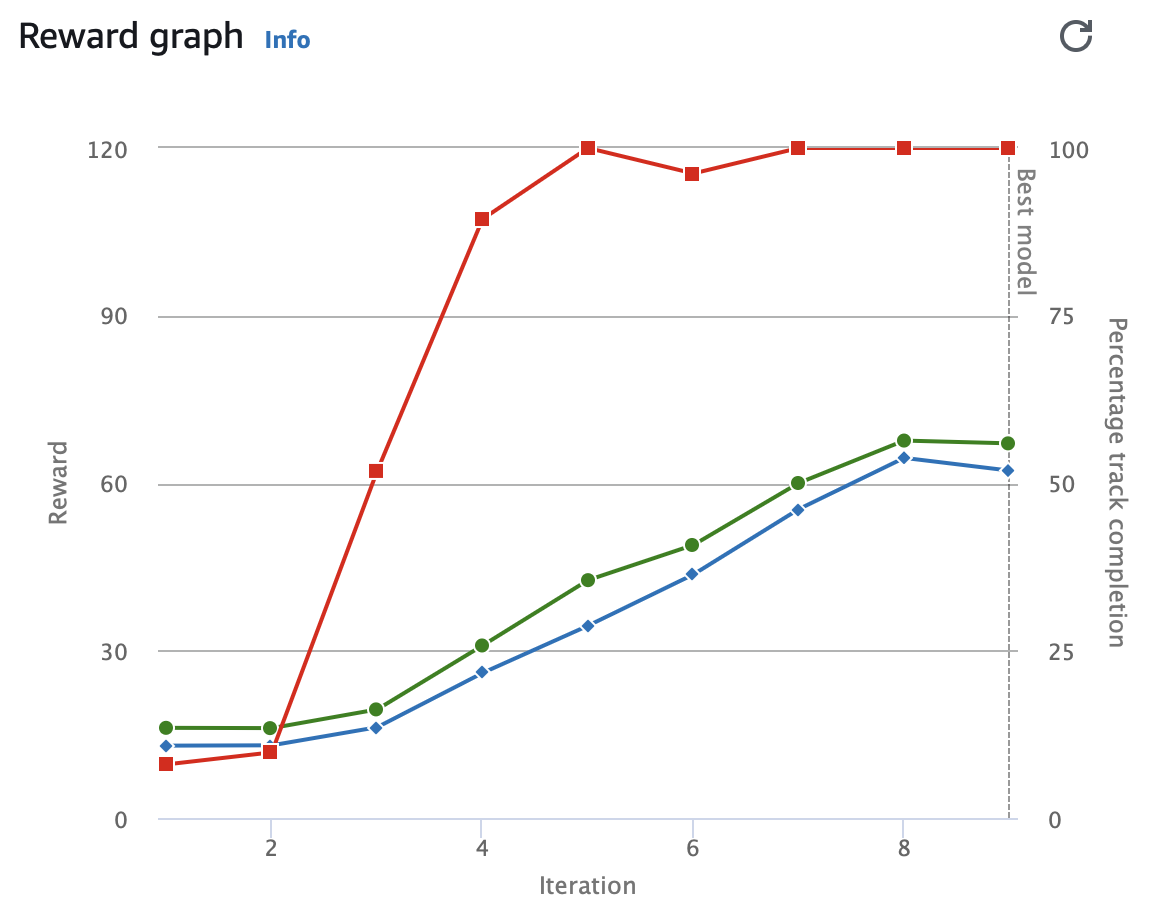
Evaluation Results 2
- time : 12.011
- off-track : 0
비교 및 결과
시간 단축
| 기본코드 | Test 1 | Test 2 | |
|---|---|---|---|
| Time(s) | 19.263 | 18.670 | 12.011 |
| 단축시간(s) | 0.593 | 7.152 |
차이점
- 속도
[0.5:1.0] >> [0.5:2.0] - 보상함수
차량 주행간에 트랙을 지그재그로 다니는 것을 방지하는 예시 코드 입력.
앞으로의 비교를 위해 기본 제공 코드, 참조 코드로 테스트
beginner's Record