Store and manipulate text.
문자열은 "hello, world"나 "albatross"와 같이 character의 연속이다. Swift의 문자열은 String 타입으로 표현된다. String은 Character 값의 collection을 포함하여 다양한 방법으로 접근될 수 있다.
Swift의 String과 Character 타입은 빠르고, Unicode와 호환되는 방식을 제공한다. 문자열을 생성하고 조작하는 문법은 C와 비슷한 string literal 문법을 사용하여 가볍고 가독성이 좋다. String concatenation(문자열 연결)은 + operator로 두 개의 string을 결합하는 것처럼 단순하고, string mutability(문자열 변경 가능성)는 Swift의 다른 value와 마찬가지로 상수와 변수 중 하나를 선택하는 것으로 관리된다. 또한 string interpolation(문자열 삽입)으로 상수, 변수, literal, expression을 더 긴 문자열에 삽입할 수 있다. 이는 화면에 표시, 저장, 출력을 위한 커스텀 문자열 값의 생성을 쉽게 만든다.
문법의 단순함에도 불구하고 Swift의 String 타입은 빠르고, 최신의 문자열 구현이다. 모든 문자열은 encoding에 독립적인 Unicode 문자로 이루어져 있고, 다양한 Unicode 문자 표현에 접근할 수 있도록 지원한다.
Swift의 String 타입은 Foundation의 NSString class와 연결되어 있다. Foundation은 String을 NSString에 의해 정의된 method에 노출시키기 위해 확장한다. 즉, Foundation을 import한다면 casting 없이 String에서 NSString의 method에 접근할 수 있다.
String Literals
미리 정의된 String 값을 코드에 string literal로 포함할 수 있다. String literal은 큰따옴표(")로 둘러싸인 character의 연속이다.
String literal을 상수나 변수의 초기 값으로 사용한다.
let someString = "Some string literal value"이 때 상수 someString이 string literal 값으로 초기화되었기 때문에 Swift는 someString을 String 타입으로 추론한다.
Multiline String Literals
만약 여러 줄에 걸쳐 있는 문자열이 필요하다면 세 개의 큰따옴표로 둘러싸인 문자의 연속인 multiline string literal을 사용한다.
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""multiline string literal은 여는 따옴표와 닫는 따옴표 사이의 모든 줄을 포함한다. 문자열은 여는 따옴표의 바로 다음 줄에서 시작해 닫는 따옴표의 이전 줄에서 끝난다. 따라서 다음의 문자열 중 어떤 것도 줄바꿈이 포함되지 않는다.
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""만약 multiline string literal 안에서 줄바꿈을 사용한다면 해당 줄바꿈은 string 값에 포함된다. 만약 줄바꿈을 string 값에 포함시키고 싶지 않지만 코드의 가독성을 위해 줄바꿈을 사용하고 싶다면 다음과 같이 해당 줄의 끝에 backslash()를 추가한다.
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""multiline string literal은 둘러싸인 코드에 맞추어 들여쓰기될 수 있다. 닫는 따옴표 이전의 공백은 Swift에게 다른 줄에서 어떤 공백을 무시해야 하는지를 알려 준다. 하지만 만약 줄에서 닫는 따옴표 이전의 공백보다 더 많은 공백을 작성한다면 해당 공백은 포함된다.

Special Characters in String Literals
String literal은 다음의 특수 문자를 포함할 수 있다.
- The escaped special characters \0 (null character), \ (backslash), \t (horizontal tab), \n (line feed), \r (carriage return), \" (double quotation mark), \' (single quotation mark)
- 임의의 Unicode scalar 값, \u{n}의 형태로 쓰이며 n은 1-8자리의 16진수
다음 코드에서 dollarSign, blackHeart, sparklingHeart는 Unicode scalar 형식의 예시이다.
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" 4 // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496multiline string literal은 3개의 큰따옴표를 사용하기 때문에 큰따옴표를 escape 없이 사용할 수 있다. """를 multiline string literal에 포함하기 위해서는 적어도 하나의 따옴표를 escape 해야 한다.
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""Extended String Delimiters
확장된 구분 기호를 사용해 특수 문자의 영향 없이 문자열에 특수 문자를 포함할 수 있다. 문자열을 큰따옴표로 둘러싸고 이를 숫자 기호(#)로 둘러싼다. 예를 들어 string literal #"Line 1\nLine 2"# 는 줄바꿈 없이 \n을 그대로 출력한다.
만약 특수 문자의 효과가 필요하다면 숫자 기호의 개수와 escape character() 다음의 개수를 같게 한다. 예를 들어 #"Line 1\nLine 2"# 에서 추가로 줄도 바꾸고 싶다면 #"Line 1#nLine 2"# 를 사용하면 된다. ###"Line1###nLine2"### 도 동일하다.
확장된 구분 기호는 multiline string literal에서도 사용 가능하다. multiline string literal에서 확장된 구분 기호를 사용해 """를 포함할 수 있다.
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
"""#Initializing am Empty String
빈 String 값을 생성하기 위해 빈 string literal을 할당하거나 새로운 String instance를 initializer 문법으로 초기화 할 수 있다.
var emptyString = "" // 빈 string literal
var anotherEmptyString = String() // initializer 문법
// 위의 두 문자열은 empty이고 동일하다.String 값이 empty인지 확인하기 위해 해당 String의 Boolean isEmpty property를 사용할 수 있다.
if emptyString.isEmpty {
print("Nothing to see here")
}String Mutability
특정 String이 변경 가능함을 표현하기 위해 변수에, 변경 불가능함을 표현하기 위해 상수에 할당할 수 있다.
var variableString = "Horse"
variableString += " and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// 상수는 변경 불가능하기 때문에 compile-time error가 발생한다.위의 접근은 문자열 변경 가능성을 NSString과 NSMutableString으로 나타내는 Object-C와 Cocoa와 다르다.
Strings Are Value Types
Swift의 String 타입은 value 타입(reference 타입과 반대되는 개념)이다. 새로운 String 값을 만든다면 그 String 값은 함수나 메서드로 전달되거나 상수나 변수에 할당될 때 복사된다.
Swift의 copy-by-default String behavior는 함수나 메서드가 String 값을 전달할 때 그 값이 어디에서 왔는지와 상관없이 정확히 String 값이라는 것을 보장한다. 전달된 문자열은 직접 수정하지 않는 한 수정되지 않는다.
Swift의 컴파일러는 복사가 정말로 필요할 때만 수행될 수 있도록 문자열 사용성을 최적화한다. 이는 문자열을 value 타입으로 사용할 때 항상 좋은 성능을 보인다는 것을 의미한다.
Working with Characters
String에 대한 각각의 Character 값을 for-in loop에서 iterate해 접근할 수 있다.
for character in "Dog!🐶" {
print(character)
}또는 Character 타입을 명시하여 단일 문자 string literal로 Character 상수나 변수를 생성할 수 있다.
let exclamationMark: Character = "!"String 값은 initializer의 인자로 Character 값의 array를 전달 받아 생성될 수도 있다.
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)Concatenating Strings and Characters
새로운 String 값을 만들기 위해 String 값들이 addition operator(+)로 연결될 수 있다.
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2또한 이미 존재하는 String 변수에 addition assignment operator(+=)을 사용하여 String 값을 붙일 수 있다.
var instruction = "look over"
instruction += string2String 타입의 apppend() 메서드를 사용하여 String 변수에 Character 값을 붙일 수 있다.
let exclamationMark: Character = "!"
welcome.append(exclamationMark)Character 값은 반드시 단일 문자만 포함할 수 있기 때문에 이미 존재하는 Character 값에 String이나 Character를 붙일 수는 없다.
여러 개의 multiline string literal을 사용해 더 긴 문자열을 구성하는 경우 line break에 유의해야 한다.
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// 두 줄 출력
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// 세 줄 출력
// one
// two
// threeString Interpolation
String interpolation(문자열 삽입)은 string literal 안에 여러 개의 상수, 변수, literal, expression을 포함함으로써 새 String 값을 생성하는 방법이다. string literal 안에 삽입되는 각각의 값은 소괄호로 감싸지고 backslash()가 prefix된다.
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"extended string delimiter를 사용해 string interpolation으로 취급될 수 있는 문자들을 포함하는 문자열을 생성할 수 있다. 이 때 해당 영향은 무시된다.
print(#"Write an interpolated string in Swift using \(multiplier)."#)
// "Write an interpolated string in Swift using \(multiplier)." 출력.extended delimiter를 사용하는 문자열 안에서 string interpolation을 사용하고 싶다면 문자열의 시작과 끝의 숫자 기호(#) 개수만큼 역슬래시 다음에 숫자 기호(#)를 넣는다.
print(#"6 times 7 is \#(6 * 7)."#)
// "6 times 7 is 42." 출력삽입된 문자열에서 소괄호 안에 작성한 expression은 unescaped backslash(\), carriage return(커서가 줄의 가장 앞으로 이동), line feed를 포함할 수 없다. 하지만 다른 string literal은 포함할 수 있다.
Unicode
Unicode는 다른 쓰기 시스템에서 encoding, 표기, 텍스트 처리를 위한 국제적인 표준이다. 이를 통해 규격화된 형태로 모든 언어의 거의 모든 문자를 표기할 수 있으며, 텍스트 파일이나 웹 페이지 같은 외부 소스에서 해당 문자들을 읽고 쓸 수 있다. Swift의 String과 Character 파입은 Unicode를 완벽하게 지원한다.
Unicode Scalar Values
Swift의 native String 타입은 Unicode scalar 값에 기반한다. Unicode scalar 값은 U+0061 의 경우 LATIN SMALL LETTER A ("a"), U+1F425의 경우 FRONT-FACING BABY CHICK ("🐥")와 같이 문자나 modifier에 대한 고유한 21 비트 숫자이다.
모든 21 비트 Unicode scalar 값이 문자에 할당된 것은 아니다. 몇몇 scalar는 나중에 할당될 예정이거나 UTF-16 encoding에서의 사용을 위해 지정되어 있다. 문자에 할당된 scalar 값은 LATIN SMALL LETTER A 나 FRONT-FACING BABY CHICK처럼 보통 이름을 가진다.
Extended Grapheme Clusters
Swift Character 타입의 모든 instance는 하나의 extended grapheme cluster로 표기된다. Extended grapheme cluster는 하나 이상의 Unicode scalar의 연속이며 (결합되었을 때) 하나의 사람이 읽을 수 있는 문자를 생성한다.
문자 é는 하나의 Unicode scalar é (LATIN SMALL LETTER E WITH ACUTE, or U+00E9)로 표기될 수 있다. 하지만 동일한 문자가 한 쌍의 scalar들로 표기될 수도 있다 — 표준 문자 e (LATIN SMALL LETTER E, or U+0065) 다음의 COMBINING ACUTE ACCENT scalar (U+0301). COMBINING ACUTE ACCENT scalar는 그래픽으로 해당 scalar의 앞에 오는 scalar에 적용된다. 따라서 유니코드 인식 텍스트 렌더링 시스템에서 렌더링될 때 e는 é로 변환된다.
두 경우 모두 문자 é는 extended grapheme cluster를 나타내는 하나의 Swift Character 값으로 표기된다. 첫 번째 경우, cluster는 단일 scalar를 포함한다. 두 번째 경우 cluster는 두 개의 scalar를 포함한다.
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
// eAcute is é, combinedEAcute is éExtended grapheme cluster는 많은 복잡한 script 문자들을 하나의 Character 값으로 표기하는 유연한 방식이다. 다음 예시처럼 한글은 precomposed 혹은 decomposed sequence로 표시될 수 있다. 두 경우 모두 Swift에서 단일 Character 값으로 표시된다.
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed is 한, decomposed is 한Extended grapheme cluster는 enclosing mark를 사용하여 다른 Unicode scalar를 사용하여 단일 Character 값의 일부로 묶을 수 있다.
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute is é⃝국가 표시 기호에 대한 Unicode scalar는 REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA)와 REGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8)처럼 하나의 Character 값을 만들기 위해 결합될 수 있다.
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUS is 🇺🇸
Counting Characters
문자열에서 Character 값의 개수를 구하기 위해 문자열의 count property를 사용한다.
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")Swift가 Character에 extended grapheme clusters를 사용하기 때문에 문자열 삽입(string concatemation)과 문자열 수정(modification)이 문자열의 문자 개수에 영향을 항상 미치는 것은 아니다.
예를 들어 새 문자열을 4개의 문자를 가지는 단어 cafe로 초기화하고 해당 문자열의 마지막에 COMBINING ACUTE ACCENT (U+0301)를 추가한다면 네 번째 문자는 é가 되고 문자 개수는 여전히 4개이다.
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// "the number of characters in cafe is 4" 출력
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// "the number of characters in café is 4" 출력Extended grapheme cluster는 여러 개의 Unicode scalar로 구성될 수 있다. 따라서 다른 문자들 - 그리고 같은 문자의 다른 표기들 - 이 저장하기 위해 다른 크기의 메모리를 요구할 수 있다. 그렇기 때문에 Swift에서 문자들은 문자열에서 각각 같은 크기의 메모리를 차지하지 않는다. 결과적으로 문자열에서의 문자 개수는 extended grapheme의 범위를 결정하기 위해 문자열을 iterate하지 않고서는 계산될 수 없다.특별히 긴 문자열 값을 다룬다면 count property가 반드시 전체 문자열의 Unicode scalar를 iterate 해야 한다는 것을 염두에 두자.
같은 문자들에 대해 count property로 반환되는 문자의 개수는 항상 NSString의 length property와 같은 것은 아니다. NSString의 길이는 문자열에서의 Unicode extended grapheme의 개수가 아닌 UTF-16 표기 문자열에서의 16 비트 코드의 개수에 기반한다.
Accessing and Modifying a String
문자열의 메서드나 property 혹은 subscript 문법을 사용해 문자열에 접근하고 변경할 수 있다.
String indices
String 값은 관련된 index 타입인 String.Index를 가진다. 이는 문자열에서 각각의 Character의 위치와 일치한다.
위에서 언급한 것처럼 다른 문자들은 다른 크기의 저장 공간을 차지하기 때문에 어떤 Character가 특정 위치에 있는지 결정하기 위해서는 String의 처음부터 끝까지의 Unicode scalar를 iterate 해야 한다. 따라서 Swift의 문자열은 정수 값으로 indexing 될 수 없다.
String에서 첫 번째 Character의 위치에 접근하기 위해 startIndex property를 사용한다. endIndex property는 String에서 마지막 문자의 다음 위치이다. 결과적으로 endIndex property는 문자열의 subscript로는 유효하지 않다. 만약 String이 empty라면 startIndex와 endIndex는 동일하다.
특정 index의 직전 혹은 직후 index에 접근하기 위해서는 String의 메서드인 index(before:)과 index(after:)를 사용한다. 특정 index에서 조금 더 떨어진 index에 접근하기 위해서는 이 중 하나의 메서드를 여러 번 호출하는 대신 index(_:offsetBy:) 메서드를 사용한다.
특정 String index의 Character에 접근하기 위해 subscript 문법을 사용할 수 있다.
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a문자열 범위 밖의 index나 문자열 범위 밖의 index에 해당하는 Character에 접근한다면 runtime error가 발생한다.
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Error문자열에서 문자들의 모든 index에 접근하기 위해 indices property를 사용한다.
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// "G u t e n T a g ! " 출력Collection protocol을 따르는 모든 타입에서 startIndex와 endIndex property, index(before:), index(after:), and index(_:offsetBy:) 메서드를 사용할 수 있다.
String을 포함하여 Array, Dictionary, Set 등이 있다.
Inserting and Removing
문자열의 특정 index에 하나의 문자를 삽입하기 위해서 insert(_:at:) 메서드를 사용하고, 또 다른 문자열을 삽입하기 위해서는 insert(contentsOf:at:) 메서드를 사용한다.
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome은 "hello!"와 동일.
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcome은 이제 "hello there!"과 동일.문자열의 특정 index에서 하나의 문자를 제거하기 위해서 remove(at:) 메서드를 사용하고, 특정 범위의 substring을 제거하기 위해서는 removeSubrange(_:) 메서드를 사용한다.
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome은 "hello there"과 동일.
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome은 이제 "hello"와 동일.RangeReplaceableCollection을 따르는 모든 타입에서 insert(:at:), insert(contentsOf:at:), remove(at:), removeSubrange(:) 메서드를 사용할 수 있다. String을 포함하여 Array, Dictionary, Set 등이 있다.
Substrings
문자열에서 subscript나 prefix(_:) 같은 메서드를 사용하여 부분 문자열을 얻을 때 결과는 또 다른 String이 아닌 Substring의 instance이다. Swift에서 부분 문자열은 대부분 문자열과 동일한 메서드를 포함하고, 이는 문자열을 다루는 방식과 같은 방식으로 부분 문자열을 다룰 수 있다는 것을 의미한다. 그러나 문자열과 다르게 문자열에서 작업을 수행하는 짧은 시간 동안만 부분 문자열을 사용해야 한다. 만약 더 오랫동안 결과를 저장할 준비가 되었다면 부분 문자열을 String의 instance로 변환한다.
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning은 "Hello".
// 장기 저장을 위해 결과를 String으로 변환한다.
let newString = String(beginning)문자열과 마찬가지로 각각의 부분 문자열은 부분 문자열을 구성하는 문자가 저장된 메모리 영역을 가진다. 문자열과 부분 문자열의 차이는 성능 최적화 관점에서 부분 문자열이 원본 문자열을 저장하기 위해 사용된 메모리를 재사용한다는 것이다. (문자열도 비슷한 최적화를 사용하지만 만약 두 문자열이 메모리를 공유한다면 이들은 동일하다.) 이 성능 최적화는 문자열이나 부분 문자열을 변경할 때까지 메모리를 복사하는 성능 비용을 고려할 필요가 없다는 것을 의미한다. 위에서 언급했듯이 적어도 하나의 부분 문자열이 사용되는 한 원본 문자열이 메모리에 계속 남아 있어야 하기 때문에 부분 문자열은 장기 저장에 적합하지 않다.
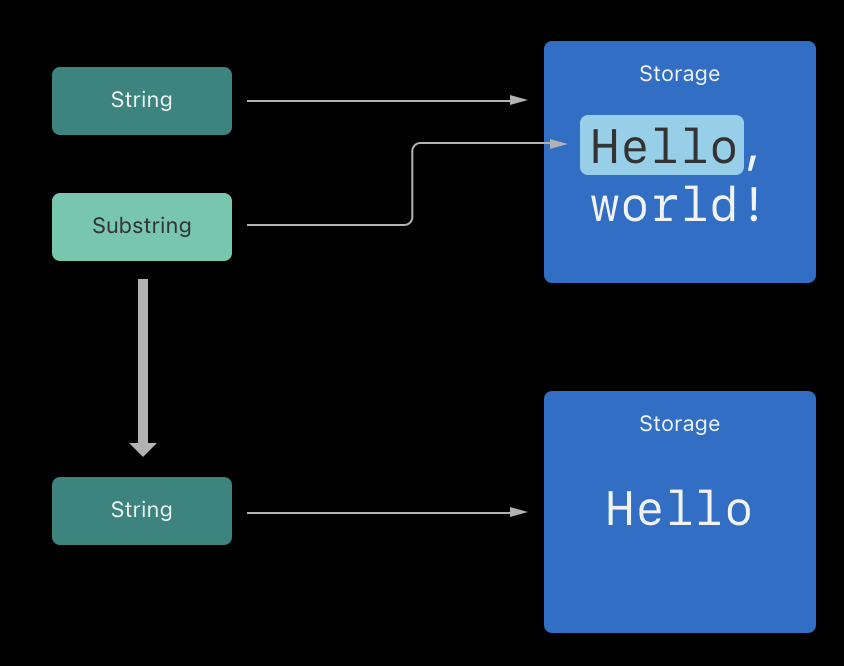
String과 Substring은 모두 StringProtocol protocol을 따른다. 이는 문자열 조작 함수가 StringProtocol 값을 받아들이기 편리하다는 것을 의미하며 String과 Substring 값으로 이러한 함수를 호출할 수 있다.
Comparing Strings
Swift는 텍스트 값을 비교하기 위한 3가지 방법을 제공한다: 문자열과 문자 equality, prefix equality, suffix equality.
String and Character Equality
문자열과 문자 equality는 "equal to" operator(==)과 "not equal to" operator(!=)로 확인된다.
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// "These two strings are considered equal" 출력두 String 값(혹은 Character)은 extended grapheme cluster가 정규적으로 동일한 경우 동일하다고 간주된다. Extended grapheme cluster는 다른 Unicode scalar로 이루어져 있더라도 언어적 의미와 표기가 같다면 정규적으로 동일하다.
예를 들어 LATIN SMALL LETTER E WITH ACUTE (U+00E9)는 LATIN SMALL LETTER E (U+0065) 다음의 COMBINING ACUTE ACCENT (U+0301)와 정규적으로 동일하다.
반대로 영어에서 사용되는 LATIN CAPITAL LETTER A (U+0041, or "A")는 러시아에서 사용되는 CYRILLIC CAPITAL LETTER A (U+0410, or "А")와 동일하지 않다. 시각적으로는 비슷해 보여도 같은 언어적 의미를 가지고 있지 않기 때문이다.
Swift에서 문자열과 문자 비교는 local-sensitive하지 않다.
Prefix and Suffix Equality
문자열이 특정 문자열 prefix나 suffix를 가지고 있는지 확인하기 위해서 하나의 String 타입 argument를 받아 Boolean 값을 반환하는 문자열의 hasPrefix(:)나 hasSuffix(:) 메서드를 사용한다.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]Act 1의 Scene 개수를 세기 위해 hasPrefix(_:) 메서드를 사용할 수 있다.
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// "There are 5 scenes in Act 1" 출력.비슷하게 hasSuffix(_:) 메서드를 사용하여 Capulet's mansion Friar과 Lawrence's cell에서 진행되는 scene의 개수를 셀 수 있다.
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// "6 mansion scenes; 2 cell scenes" 출력.hasPrefix(:)와 hasSuffix(:) 메서드는 각 문자열의 extended grapheme cluster에서 문자별 정규적 equality 비교를 수행한다.
Unicode Representations of Strings
Unicode 문자열이 텍스트 파일이나 다른 외부 저장 공간에 쓰여질 때, 해당 문자열의 Unicode scalar는 정의된 Unicode encoding 형식 중 하나로 encode 된다. 각각의 형식은 문자열을 code unit이라고 알려진 작은 단위로 encode 한다. 여기에는 UTF-8 encoding 형식(문자열을 8-비트 code unit로 encode), UTF-16 encoding 형식(문자열을 16-비트 code unit로 encode), UTF-32 encoding 형식(문자열을 32-비트 code unit로 encode) 이 포함된다.
Swift는 문자열의 Unicode 표현에 접근하기 위해 여러 개의 방식을 제공한다. Unicode extended grapheme cluster인 Character 값에 접근하기 위해 for-in 문에서 문자열을 iterate 할 수 있다.
또한 다음의 3개의 Unicode 호환 표현 중 하나로 String 값에 접근할 수 있다.
- UTF-8 code units (문자열의 utf8 property로 접근)
- UTF-16 code units (문자열의 utf16 property로 접근)
- 21-bit Unicode scalar 값, 문자열의 UTF-32 encoding 형식과 동일 (문자열의 unicodeScalars property로 접근)
아래 각각의 예시는 D, o, g, ‼ (DOUBLE EXCLAMATION MARK 또는 Unicode scalar U+203C), 그리고 🐶 문자 (DOG FACE, or Unicode scalar U+1F436)로 이루어진 문자열의 다른 표현을 보여준다.
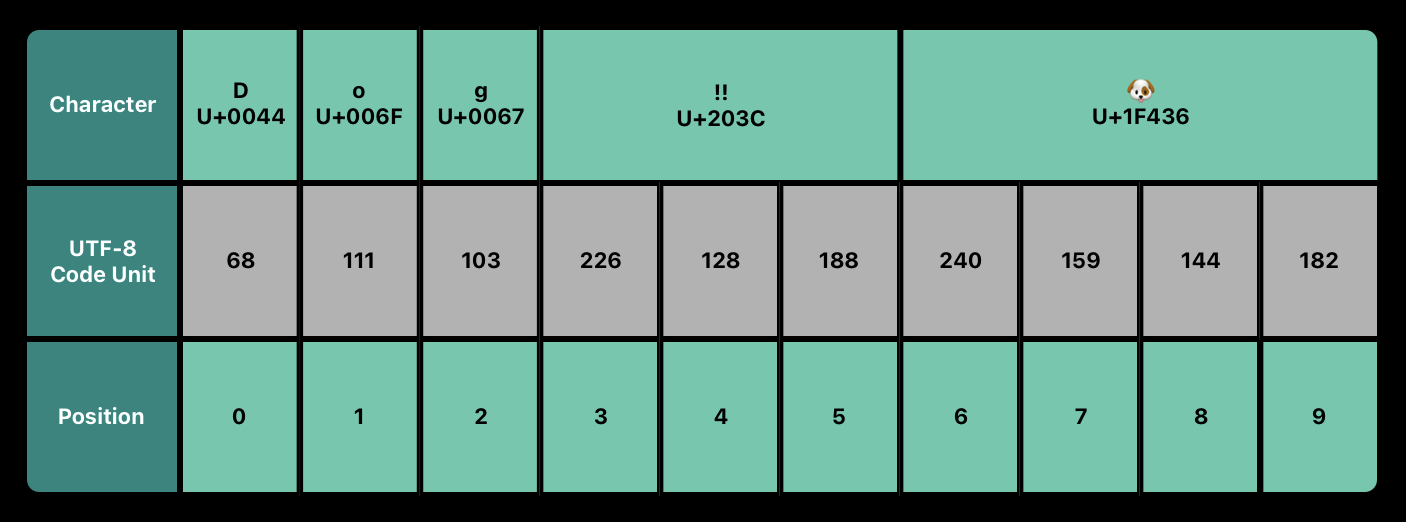
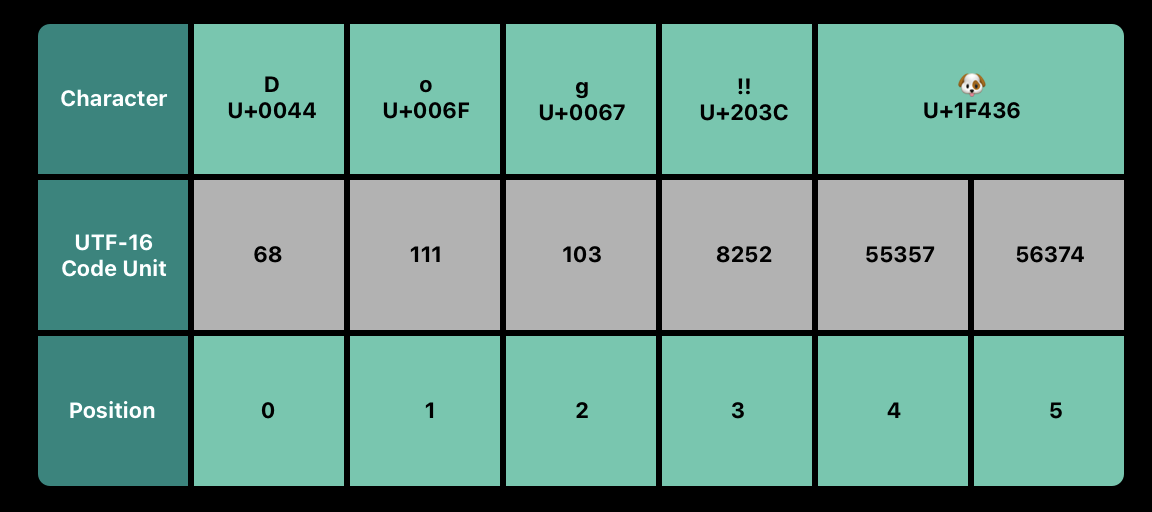
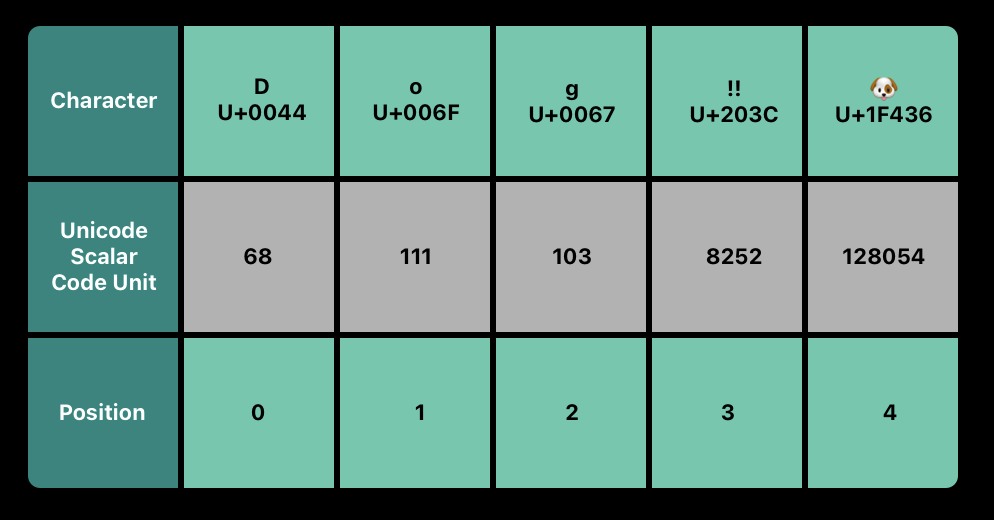
let dogString = "Dog‼🐶"UTF-8 Representation
문자열의 UTF-8 표현에 접근하기 위해 해당 문자열의 utf8 property에서 iterate 할 수 있다. 이 property는 문자열의 UTF-8 표현에서 각각 unsigned 8-비트(UInt8) 값인 String.UTF8View 타입이다.
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// "68 111 103 8252 128054 " 출력.위의 예시에서 앞 세 개의 10진수 codeUnit 값(68, 111, 103)은 ASCII와 같은 UTF-8 표현인 문자 D, o, g를 표현한다.
다음 세 개의 10진수 codeUnit 값(226, 128, 188)은 DOUBLE EXCLAMATION MARK 문자에 대한 3 바이트 UTF-8 표현이다.
마지막 네 개의 codeUnit 값(240, 159, 144, 182)는 DOG FACE 문자에 대한 4 바이트 UTF-8 표현이다.
UTF-16 Representation
문자열의 UTF-16 표현에 접근하기 위해 해당 문자열의 utf16 property에서 iterate 할 수 있다. 이 property는 문자열의 UTF-8 표현에서 각각 unsigned 16-비트(UInt8) 값인 String.UTF16View 타입이다.
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// "68 111 103 8252 55357 56374 " 출력.동일하게, 앞 세 개의 10진수 codeUnit 값(68, 111, 103)은 UTF-8과 같은 UTF-16 표현인 문자 D, o, g를 표현한다.
네 번째의 10진수 codeUnit 값(8252)는 16진수 203C와 동일하며, DOUBLE EXCLAMATION MARK 문자에 대한 Unicode scalar U+203C 표현이다.
다섯 번째와 여섯 번째의 codeUnit 값(55357, 56374)는 DOG FACE 문자에 대한 UTF-16 surrogate pair 표현이다. 이 값은 U+D83D(10진수 55357)의 high-surrogate 값, U+DC36(10진수 56374)의 low-surrogate 값이다.
Unicode Scalar Representation
문자열의 Unicode scalar 표현에 접근하기 위해 해당 문자열의 unicodeScalars property에서 iterate 할 수 있다. 이 property는 UnicodeScalar 타입의 모음인 UnicodeScalarView 타입이다.
각각의 UnicodeScalar는 Uint32 값 안에서 표현되고 scalar의 21-비트 값을 반환하는 value property를 가진다.
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// "68 111 103 8252 128054 " 출력한 번 더, 앞 세 개의 10진수 codeUnit 값(68, 111, 103)은 UTF-8과 같은 UTF-16 표현인 문자 D, o, g를 표현한다.
네 번째의 10진수 codeUnit 값(8252) 역시 16진수 203C와 동일하며, DOUBLE EXCLAMATION MARK 문자에 대한 Unicode scalar U+203C 표현이다.
다섯 번째와 마지막 UnicodeScalar의 value property인 128054는 16진수 1F436와 동일한 10진수이며, DOG FACE 문자에 대한 Unicode scalar U+1F436를 표현한다.
value property를 query 하는 대안으로, 각각의 UnicodeScalar 값은 string interpolation과 같이 새로운 String 값을 구성하는 데 사용될 수 있다.
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶