NCSN와 DDPM 프레임워크의 성공에는 여러 노이즈 스케일을 활용하는 접근이 핵심적인 역할을 해왔다. 이전 글에서는 NCSN 이후의 전개를 자연스럽게 이해하기 위한 준비 단계로서 상미분방정식(ODE)과 확률미분방정식(SDE)에 대한 간단한 개요를 먼저 살펴보았다.
이제 그 수학적 배경을 바탕으로, 이 글에서는 이러한 다중 노이즈 스케일의 아이디어를 한 단계 끌어올려 이산적인 노이즈 레벨을 넘어서 연속적인 노이즈 수준의 연속체(continuum)를 다루는 프레임워크, 즉 Score SDE(Song et al., 2020c) 의 이론적 기반을 본격적으로 소개할 예정이다.
🛠️ Score SDE로 통합하기
순방향 및 역방향 확산 과정의 연속시간 극한은 이미 Sohl-Dickstein et al. (2015)에서 관찰된 바 있다. 그러나 Song et al. (2020c)는 이 관점을 한층 더 발전시켜 노이즈 수준이 시간에 따라 매끄럽게 증가하는 데이터의 진화를 확률미분방정식(SDE) 또는 상미분방정식(ODE)으로 정식화함으로써 이를 중심적인 이론으로 발전시켰다.
이러한 연속시간 정식화는 기존의 이산시간 확산 모델들을 하나의 틀로 통합할 뿐만 아니라, 생성 과정을 미분방정식을 푸는 문제로 해석할 수 있게 함으로써 생성 모델링에 대한 보다 원리적으로 유연한 기반을 제공한다.
1️⃣ 이산시간에서 연속시간 프로세스로
NCSN과 DDPM에서 사용되는 순방향 노이즈 주입 방식을 다시 살펴보자. NCSN는 증가하는 노이즈 수준의 순열{σi}i=1L을 사용한다. 각 깨끗한 데이터 샘플 x∼pdata에 대해 다음과 같이 섭동(perturbation)을 가한다.
xσ=x+σiϵi,ϵ∼N(0,I)
반면 DDPM은 분산 스케줄{β}i=1L에 따라 점진적으로 노이즈를 주입한다.
xi=1−βi2xi−1+βiϵiϵ∼N(0,I)
이 두 과정을 이산 시간 격자 위에서 함게 바라보면, xt에서 xt+Δt로의 순차적 업데이트는 다음과 같은 형태로 쓸 수 있다.
여기서 약간의 표기상 편의를 위해 xt는 고정된 샘플로, xt+Δt는 확률변수로 취급하겠다.
Δt→0의 극한, 즉 무한히 많은 노이즈 레이어를 가정하는 상황에서, 이산시간 과정은 순방향 시간으로 진화하는 연속시간 확률미분방정식(SDE) 으로 수렴한다.
dx(t)=f(x(t),t)dt+g(t)dw(t)
여기서 w(t)는 표준 Wiener 과정, 즉 브라운 운동(Brownian motion) 을 의미한다.
✏️ Wiener 과정 Recap
Wiener 과정 w(t)는 다음 성질을 갖는 연속시간 확률 프로세스이다. 초기값은 w(0)=0이며, 서로 독립인 증가량(independent increments)를 갖고, 임의의 s<t에 대해 증가량 w(t)−w(s)는 평균이 0이고 분산이 t−s인 Gaussian을 따른다.
이는 시간에 따라 독립적인 Gaussian 섭동이 누적되는 과정을 나타낸다. 또한 Wiener 과정은 거의 확실하게 연속이지만, 어느 지점에서도 미분 가능하지 않다 는 특징을 가진다.
무한소 시간 구간 [t,t+dt]에 대해, Wiener 과정의 증가량은 다음과 같이 정의된다.
dw(t):=w(t+dt)−w(t)
이는 평균이 0이고 분산이 dt인 Gaussian 확률변수로 모델링된다.
dw(t)∼N(0,dtI)
Drift 항 f(x,t)와 확산 계수 g(t)가 주어지면, 순방향 SDE는 terminal 시점의 노이즈 분포를 다시 데이터 분포로 운반하는 역방향 시간 SDE를 자동으로 유도 한다. 이때 역방향 동역학에는 단 하나의 미지(unknown) 항만이 존재하는데, 이는 놀랍게도 각 연속시간 수준에서의 score function이다.
이러한 관찰은 score matching을 학습 목표로 삼아야 함을 명확히 보여준다. 일단 score function이 학습되면, 샘플링은 학습된 score를 사용하여 역방향 시간 SDE를 수치적으로 적분하는 과정 으로 귀결된다.
2️⃣ 순방향 시간 SDE: 데이터에서 노이즈로
이러한 정식화 하에서, NCSN과 DDPM 같이 이산시간에 기반한 기존 방법들은, 구간 [0,T]위에서 정의된 순방향 SDE에 의해 지배되는 확률 과정 x(t)를 통해 연속시간 프레임워크로 통합될 수 있다.
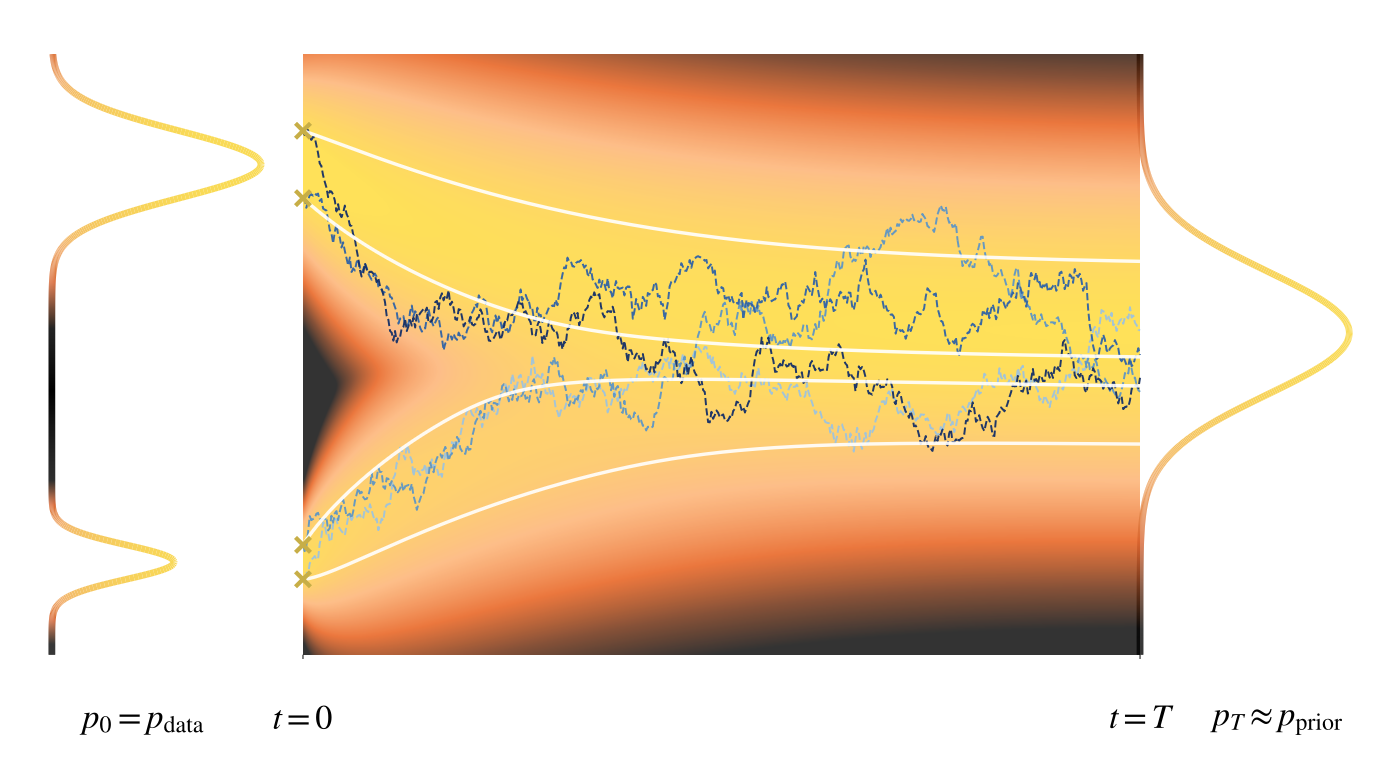
dx(t)=f(x(t),t)dt+g(t)dw(t),x(t)∼pdata
앞서 소개했듯이, 여기서 f(⋅,t):RD→RD는 drift 항, g(t)∈RD는 스칼라 확산 계수, 그리고 w(t)는 표준 Wiener 과정을 의미한다. 이를 순방향 SDE라고 부르며, 이는 깨끗한 데이터가 시간에 따라 점진적으로 노이즈로 섭동되는 과정을 수학적으로 기술한다.
Drift 항 f와 확산 계수 g가 주어지면, 순방향 과정은 완전히 결정론적이게 되며, 이는 Gaussian 노이즈 주입을 통해 데이터 변수가 시간에 따라 점진적으로 훼손되는 방식을 기술한다. 특히 이로부터 다음과 같은 두 종류의 시간 의존적 분포족(time-dependent distribution family)이 유도된다.
😶🌫️ Perturbation Kernels
조건부 분포 pt(xt∣x0)는 깨끗한 데이터 샘플 x0∼pdata가 시간 t에서의 노이즈가 섞인 상태 xt로 어떻게 진화하는지를 나타낸다.
일반적으로 위 식의 drift 항 f(x,t)는 x에 대한 임의의 함수가 될 수 있으나, 해석적으로 편리하고 널리 사용되는 관점은 이를 affine 형태로 가정하는 것이다.
f(x,t)=f(t)x
여기서 f(t)는 시간 t의 스칼라 함수이며, 보통 음이 아닌 값이 되지 않도록 선택된다(∀t∈[0,T]:f(t)≥0). 이러한 구조 하에서는 프로세스가 모든 시간에서 Gaussian으로 유지 되며, 조건부 분포는 이에 대한 평균-분산 ODE(mean-variance ODE) 를 풀어 closed-form 형태의 해로 얻을 수 있다.
이와 같은 명시적 형태를 통해 SDE를 수치적으로 적분하지 않고도 x0가 주어졌을 때 xt를 직접 샘플링할 수 있으며, 이로 인해 이를 simulation-free 라고 부른다. NCSN과 DDPM은 모두 이러한 affine drift 설정에 속한다.
🌈 Marginal Densities
시간 t에서의 marginal density pt(xt)는 섭동 커널(perturbation kernel)에 대해 적분함으로써 얻어진다.
pt(xt):=∫pt(xt∣x0)pdata(x0)dx0,p0=pdata
계수 f(t)와 g(t)를 적절히 선택하면 순방향 과정은 시간에 따라 점진적으로 노이즈를 추가하여 초기 상태의 영향이 사실상 소거되도록 만든다. T가 충분히 커지면 조건부 분포 pT(xT∣x0)는 더 이상 x0에 의존하지 않게 되는데, 이는 평균이
T→∞lim[m(T)=exp(∫0Tf(u)du)x0]=0
으로 수렴하기 때문이다. 여기서 f(u)가 음이 아닌 값을 갖지 않도록 선택되면, 지수 항이 감쇠한다. 동시에 분산은 증가하여 미리 선택한 사전 분포에 맞게 안정화된다.
그 결과, 초기에는 데이터 샘플들에 대한 복잡한 혼합을 나타내던 marginal density
pT(xT)=∫pT(xT∣x0)pdata(x0)dx0
는 점차 단순한 사전 분포 pdata(보통 Gaussian)으로 수렴한다. 이 극한에서
pT(xT)≈pprior(xT),pT(xT∣x0)≈pprior(xT)
가 성립하며, 순방향 과정은 임의의 데이터 분포를 취급이 용이한 사전 분포로 사상(project) 하게 된다. 이는 이후의 역과정과 생성 과정을 위한 편리한 출발점을 제공한다.
3️⃣ 생성을 위한 역방향 시간 확률 프로세스
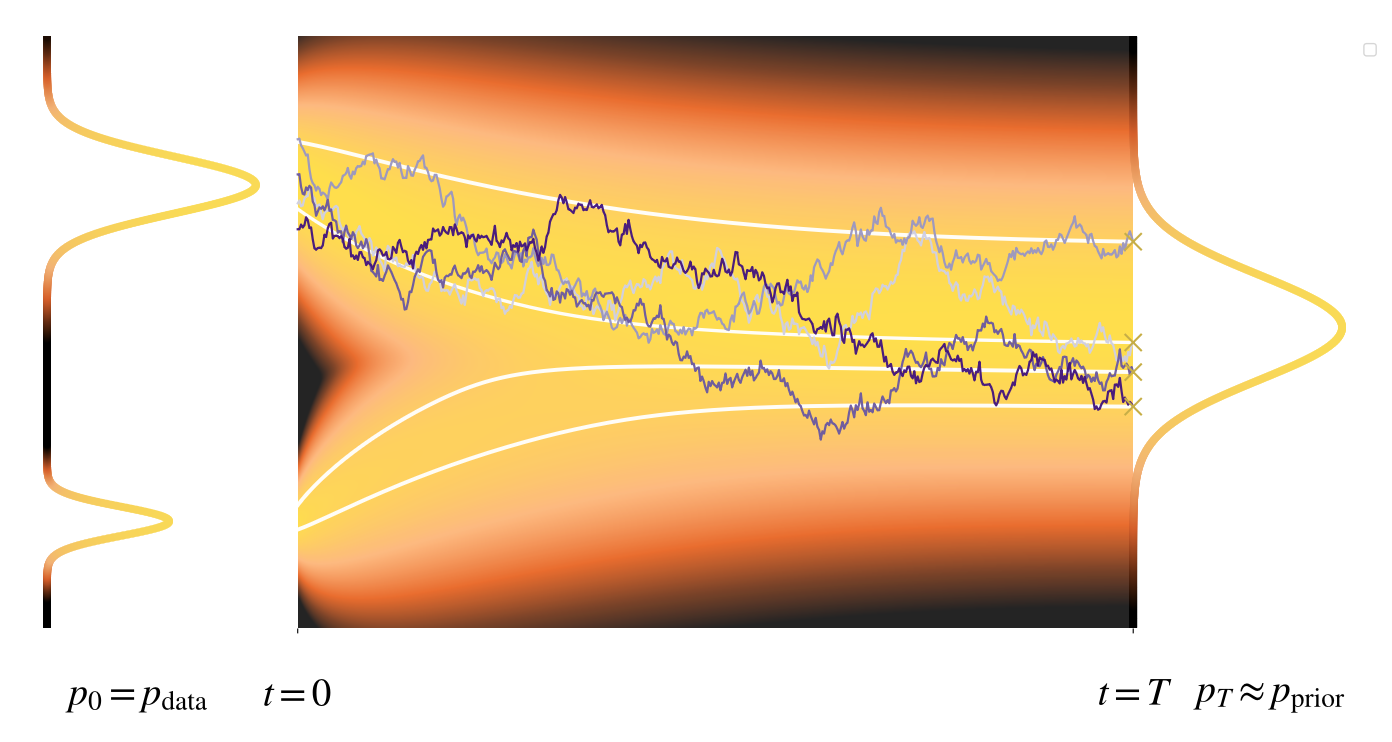
직관적으로 보면, 노이즈로부터의 데이터 생성은 순방향 과정을 역전함으로서 달성할 수 있다. 즉, 사전 분포에서 샘플링한 임의의 점에서 출발하여, 이를 시간의 역방향으로 진화시켜 생성된 샘플을 얻는 것이다.
결정론적 시스템, 즉 상미분방정식(ODE)의 경우 이 아이디어는 자연스럽게 성립된다. 무작위성이 개입되지 않으므로, 시간 역전은 단순히 순방향 과정에서의 궤적을 동일한 경로를 따라 반대 방향으로 추적하는 것을 의미한다.
반면, 확률미분방정식(SDE)은 매 시간 단계마다 확률적 요인을 포함하므로, 하나의 점이 여러 가능한 무작위 궤적을 따라 진화할 수 있다. 그 결과, 이러한 과정의 시간 역전을 정의하고 다루는 일은 훨씬 더 복잡한 문제이다.
다만, 개별적인 확률적 궤적 자체는 가역적이지 않지만 이들 궤적에 대한 분포는 역전될 수 있다는 점이 핵심적인 통찰이다. 이는 Anderson(1982)의 기초적인 결과를 통해 정식화되는데, 해당 결과에 따르면 순방향 과정의 시간 역전 과정 {xˉ(t)}t∈[0,T] 역시 잘 정의된 확률미분방정식(SDE)에 의해 지배된다.
여기서 wˉ(t)는 역시간에서의 표준 Wiener 과정으로, wˉ(t):=w(T−t)−w(t)로 정의된다.
확산 항이 존재하는 경우, 즉 g=0일 때에는 추가적인 보정 항 −g2(t)∇xlogpt(xˉ(t))이 역방향 동역학에 나타난다는 점에 주목하자. 이 항은 확산의 효과를 보정하며, 순방향 SDE에 의해 유도된 marginal density들의 진화를 역시간 동역학이 정확히 재현하도록 보장한다.
🧐 개념적으로 역과정이 작동하는 이유
언뜻 보기에, 역시간 과정에 브라운 운동에 의한 노이즈 포함된다는 점은 역설적으로 보일 수 있다. 순방향 확산이 데이터를 점점 더 무작위적인 상태로 퍼뜨린다면, 특히 wˉ(t)를 통해 추가적인 확률성을 도입하는 과정을 거꾸로 적용했을 때 어떻게 데이터 manifold 근처에 집중된 깨끗하고 구조적인 샘플이 생성될 수 있는지는 명확하지 않다.
핵심은 역시간 SDE가 임의의 무작위성을 주입하지 않는다는 점이다. 확산 항 g(t)dwˉ(t)는 항상 score에 의해 구동되는 drift 항 −g2(t)∇xlogpt(xˉ(t))과 함께 작용한다. 이 두 항은 서로 균형을 이룬다.
Score 항은 궤적을 확률 밀도가 높은 영역으로 유도하는 반면, 노이즈 항은 동역학을 압도하지 않는 범위 내에서 제어된 확률성을 도입하여 탐색을 가능하게 한다.
이를 보다 명확히 보기 위해 이전 NCSN에 대한 글에서 제시된 Langevin 직관으로 되돌아가 보자. f(t)≡0인 경우, 위의 dxˉ(t)식은 다음과 같이 쓸 수 있다.
dxˉ(t)=−g2(t)∇xlogpt(xˉ(t))dt+g(t)dwˉ(t)
이제 시간 변수를 s:=T−t,dt=−ds로 순방향으로 재매개변수화하자. 또한 브라운 운동을 다시 정의하여 dwˉ(t)=−dws가 되도록 가정해보자.
이는 시간에 따라 변하는 온도(temperature) τ(s)를 갖는 Langevin 형태의 방정식으로, 시간에 따라 변화하는 밀도 πs를 타깃으로 한다. Tweedie 공식에 따르면, score 방향 ∇logπs는 각 시간 단면에서의 조건부 깨끗한 신호(conditional clean data)를 향하므로, drift 항은 지속적으로 denoised된 구조를 다시 끌어당기는 역할을 한다.
결정적으로, g(t)는 역방향 궤적을 따라 annealing된다. 초반부(s≈0, 즉 t≈T)에는 g(T−s)가 상대적으로 크기 때문에 주입되는 노이즈가 강하고, 프로세스는 넓은 영역을 탐색한다. 반대로 s가 증가함에 따라 g(T−s)는 감소하고, 확률적 항은 약화되며 score 항이 지배적으로 작용하여 샘플들을 πs의 고밀도 영역으로 끌어당긴다.