
💫 Backward Fusion 시스템 도입
이번 일지는 Lucid에 최근 도입된 Backward Fusion 시스템을 정리한다. 주제는 단순한 미분 규칙 최적화가 아니라, backward 그래프 구조를 읽고 특정 패턴을 동적으로 결합(fuse) 하는 설계이며, 그 동기가 무엇이었고 실제 구현이 어떤 구조로 결정되었는지를 상세히 기록한다. 새로운 클래스와 함수가 어떻게 추가되었고, backward 호출 시점에 어떤 조건과 경로로 트리거되는지까지 한 흐름으로 정리한다.
🔎 Backward Fusion의 필요성
Lucid의 backward는 기본적으로 그래프를 topological order로 정렬한 뒤 역순으로 순회한다. 이 구조는 명확하지만, 실제 연산 그래프에서는 의미상 취소되거나 단순화 가능한 연산이 반복적으로 나타난다.
예를 들어 neg → neg, exp → log, reshape → reshape, squeeze → unsqueeze 같은 패턴은 forward 단계에서는 자연스럽지만, backward에서는 불필요한 중간 연산과 gradient 전달이 발생한다.
이러한 패턴은 작은 그래프에서는 무시할 수 있지만, 긴 그래프나 반복 루프에서는 누적 비용이 된다. 특히 Lucid는 backward에서 BackwardOperation이 텐서 참조와 grad 함수를 포함하고 있기 때문에, 중간 노드가 살아있는 시간이 길어질수록 메모리와 오버헤드가 증가한다. 따라서 특정 패턴을 감지하고 두 단계의 backward를 하나의 grad 함수로 축약하는 전략이 필요했다.
Backward Fusion의 목표는 다음과 같다.
- 의미상 항등이거나 단순화 가능한 연산 체인을 축약한다.
- backward 호출 경로의 실행 횟수를 줄인다.
- 중간 노드의 참조를 줄여 그래프 수명을 단축한다.
- 구현은 opt-in으로 유지하고, 정확성을 보장하는 패턴만 fusing한다.
🗂️ 시스템의 기본 구조
Backward Fusion은 크게 세 가지 축에서 구현된다.
- Fusion 정의 계층: 어떤 연산 조합을 fuse할지 정의하는 클래스 집합.
- Fusion 매칭 테이블: runtime에서 연산 조합을 lookup하는 registry.
- Fusion 트리거 로직: backward 호출 시 그래프를 순회하며 패턴을 탐지하고, 기존 backward op를 교체하는 로직.
🧠 FusedBackwardOp: Fusion 정의의 기본 단위
Fusion의 핵심 클래스는 FusedBackwardOp다. 이 클래스는 인스턴스화되지 않는 추상 클래스이며,
두 개의 연산(op1, op2) 조합에 대한 fused grad 함수를 정의하기 위해 사용된다.
class FusedBackwardOp(ABC):
op1: ClassVar[type[Operation] | None] = None
op2: ClassVar[type[Operation] | None] = None
heuristic_thresh: ClassVar[int] = 0
@classmethod
def get_fused_grad_func(...): ...
@classmethod
@abstractmethod
def __grad__(cls, *args, **kwargs) -> _GradType: ...여기서 핵심 포인트는 두 가지다.
op1,op2로 fuse 대상 연산의 조합을 선언한다.__grad__는 fused gradient 계산을 담당하며, 이 함수가 backward 단계에서 호출된다.
heuristic_thresh는 Fusion이 적용될 최소 tensor 크기 기준을 의미한다. 이는 작은 텐서에서 fusing 오버헤드가 더 커질 수 있다는 현실적인 판단에서 도입된 값이다.
🧲 자동 등록 방식: __init_subclass__
Fusion 정의가 단순한 선언으로 끝나지 않도록, FusedBackwardOp는 __init_subclass__에서 자동 등록 로직을 수행한다.
def __init_subclass__(cls, **kwargs) -> None:
if cls.op1 is not None and cls.op2 is not None:
key = (cls.op1, cls.op2)
if key in _fusion_table:
... # 중복 등록 방지
_fusion_table[key] = cls이 방식의 장점은 명확하다.
- 새로운 fused op를 추가할 때 별도의 등록 함수가 필요 없다.
- 등록 누락이나 순서 문제를 피할 수 있다.
- 런타임에서는 단순한 table lookup으로 매칭이 가능하다.
이 구조는 match_fusion_table(op1, op2)로 이어진다.
def match_fusion_table(op1: Operation, op2: Operation) -> type[FusedBackwardOp] | None:
return _fusion_table.get((type(op1), type(op2)), None)즉, op 타입 조합이 key가 되고, 해당 key에 등록된 FusedBackwardOp가 있으면 반환된다.
🧫 get_fused_grad_func: 실행 가능한 grad 함수 생성
Fusion이 적용되려면 BackwardOperation에 실제 실행 가능한 grad 함수가 필요하다. 이를 위해 FusedBackwardOp는 get_fused_grad_func를 제공한다. 이 메서드는 __grad__를 직접 호출하는 것이 아니라, 입력/결과 텐서와 라이브러리 핸들을 바인딩한 closure를 만든다.
@classmethod
def get_fused_grad_func(cls, inputs, results, device="cpu") -> Callable[[], _GradType]:
...
bound = {}
if "ins" in params: bound["ins"] = ins
if "rets" in params: bound["rets"] = rets
if "lib_" in params: bound["lib_"] = _lib_mapping[device]
return partial(cls.__grad__, **bound)이 설계는 세 가지를 해결한다.
- fused grad 함수는
BackwardOperation이 요구하는 "인자 없는 callable" 형태를 만족한다. - fusing 대상 텐서와 결과 텐서를 직접 캡처하지 않고, 필요 시점에 접근할 수 있게 한다.
- CPU/Metal 백엔드 모두에 대해 동일한 구현을 사용할 수 있다.
또한 inspect.signature 기반으로 필요한 인자를 자동으로 바인딩하기 때문에, fused op의 __grad__ 시그니처가 유연해진다.
⚡️ 실제 Fusion 정의들
현재 등록된 fusion 패턴은 주로 항등 혹은 view 변환의 역전파가 단순해지는 조합에 집중한다. 주요 예시는 다음과 같다.
neg → neg→DoubleNegreciprocal → reciprocal→DoubleReciprocalexp → log→LogExpreshape → reshape→DoubleReshapesqueeze → unsqueeze,unsqueeze → squeeze→SqueezeUnsqueeze,UnsqueezeSqueeze
구현 패턴은 크게 두 종류다.
1️⃣ IdentityFusion
단순히 output gradient를 그대로 전달하면 되는 조합에 사용된다.
class _IdentityFusion(FusedBackwardOp):
@classmethod
def __grad__(cls, rets: tuple[Tensor]) -> _GradType:
return rets[0].grad2️⃣ IdentityViewFusion
view 연산처럼 reshape가 필요한 조합에 사용된다.
class _IdentityViewFusion(FusedBackwardOp):
@classmethod
def __grad__(cls, ins: tuple[Tensor], rets: tuple[Tensor]) -> _GradType:
v = rets[0]
x = ins[0]
return v.grad.reshape(x.shape) if v.grad is not None else None이 구조를 통해 DoubleReshape, SqueezeUnsqueeze 같은 패턴은 단일 reshape로 정리된다.
LogExp는 size가 충분히 큰 경우에만 적용되도록 heuristic_thresh = 10_000을 설정해 두었다. 이는 작은 텐서에서 fusion의 이득이 크지 않거나 오히려 손해일 수 있기 때문이다.
🛠️ BackwardOperation에 대한 확장점
Fusion이 실제로 적용되려면, 기존 backward op의 실행 함수를 바꿀 수 있어야 한다. 이 역할을 맡는 것이 BackwardOperation이며, 여기에는 두 개의 override 메서드가 존재한다.
class BackwardOperation:
def override_grad_func(self, new_grad_func: _GradFuncType) -> None: ...
def override_tensor_refs(self, new_tensor_refs: tuple[weakref.ref[_TensorLike]]) -> None: ...이 메서드들은 Fusion 적용 시점에 호출되며,
- 기존 grad 함수를 fused grad 함수로 교체
- 기존 tensor_refs를 새로운 텐서 참조 집합으로 교체
하는 역할을 한다. 즉, BackwardOperation 자체를 교체하지 않고 내부의 실행 경로만 재정의하는 방식이다.
이 설계는 안전성 측면에서도 유리하다. 이미 만들어진 BackwardOperation 객체의 수명과 연결 구조는 유지하되, 실행 함수만 교체하기 때문에 기존 그래프 관리 로직과 충돌하지 않는다.
🚦 Fusion 트리거
Fusion은 backward 호출 시점에만 적용되며, 트리거 로직은 Tensor.backward 내부에서 호출된다.
if lucid.ENABLE_FUSION and self.is_cpu():
self._try_backward_fusion(topo_order)즉, 전역 플래그 ENABLE_FUSION이 켜져 있고, CPU 경로일 때만 적용된다. GPU path는 아직 fuse 대상에서 제외된다.
Tensor._try_backward_fusion의 핵심 흐름은 다음과 같다.
topo_order를 순회하며 각 텐서가 단일 소비자만 가지는지 분석한다.- 소비자가 하나뿐인 경우에만 fusion 후보로 등록한다.
- 소비자
v와 그 parentp의 연산 조합을 lookup한다. - 매칭이 되는 경우, 조건(heuristic, 그래프 구조)을 체크한다.
- 조건을 만족하면 backward op를 교체하고 그래프 연결을 재구성한다.
이 과정에서 단일 소비자만 허용하는 이유는 명확하다.
- 하나의 텐서가 여러 소비자를 가질 경우, grad는 다중 경로에서 합산되어야 한다.
- 현재 fusion 구조는 단일 경로만 가정하므로, multi-consumer를 fuse하면 gradient가 누락될 위험이 있다.
따라서 Tensor._try_backward_fusion은 아래 방식으로 소비자 매핑을 만든다.
consumer_of = {}
multi_consumer = set()
for consumer in topo_order:
for parent in consumer._prev:
pid = id(parent)
if pid in multi_consumer:
continue
prev_consumer = consumer_of.get(pid)
if prev_consumer is None:
consumer_of[pid] = consumer
else:
multi_consumer.add(pid)
consumer_of.pop(pid, None)이렇게 하면 단일 소비자만 가진 텐서만 consumer_of에 남는다.
🔬 매칭 조건과 제한 사항
Fusion이 실제로 적용되기 위해서는 다음 조건을 통과해야 한다.
p._op와v._op가 모두 존재해야 한다.(type(p._op), type(v._op))조합이 fusion table에 존재해야 한다.v.size >= fused_backward_op.heuristic_thresh조건을 만족해야 한다.v가 단일 parent만 가지는 simple unary chain이어야 한다.
코드 상의 제한은 다음과 같이 명시되어 있다.
if len(v._prev) != 1 or v._prev[0] is not p:
continue즉, 현재 구현은 단항 연산 체인만 지원하며, binary ops나 복합 연산의 fusion은 의도적으로 제외된다.
⚙️ 실제 적용: 그래프 재구성과 backward op 교체
조건이 맞으면 다음 로직이 수행된다.
p의 부모들을p_parents로 저장한다.v._prev에서p를 제거하고p_parents를 추가한다.p.clear_node(clear_op=False)를 호출해 중간 노드를 정리한다.v._backward_op의 tensor_refs와 grad_func를 fused 함수로 교체한다.
핵심 코드는 다음과 같다.
p_parents = tuple(p._prev)
v._prev.remove(p)
v._prev.extend(p_parents)
p.clear_node(clear_op=False)
v._backward_op.override_tensor_refs(tuple(weakref.ref(t) for t in v._prev))
v._backward_op.override_grad_func(
fused_backward_op.get_fused_grad_func(
inputs=p_parents, results=v, device=v.device
)
)즉, 그래프 연결은 p를 건너뛰도록 재배치되고, backward 실행은 fused grad 함수 하나로 교체된다. 결과적으로 backward 루프에서 p._backward_op를 실행할 필요가 없으며, p는 사실상 그래프에서 제거된 것처럼 동작한다.
🧾 Backward 호출에서의 작동 흐름 요약
Backward Fusion의 전체 흐름을 한 번에 요약하면 다음과 같다.
Tensor.backward가 호출된다.- topological sort를 통해
topo_order가 구성된다. ENABLE_FUSION플래그가 켜져 있고 CPU라면Tensor._try_backward_fusion이 실행된다.- 단일 소비자 텐서만 대상으로 fusion 매칭이 수행된다.
- 매칭된 조합은
FusedBackwardOp의 grad 함수로 교체된다. - backward 루프에서 실제 grad 전파가 실행된다.
이 흐름은 기존의 backward 구조를 크게 바꾸지 않으면서, 특정 패턴에서만 미세 최적화가 적용되는 방식이다.
📌 도입 효과와 현재 한계
Backward Fusion의 즉각적인 효과는 다음과 같이 요약할 수 있다.
- 중간 노드의 backward 실행이 줄어듦
- 작은 연산 체인의 불필요한 grad 전파를 제거
- 그래프 수명을 줄여 메모리 사용량을 완화
하지만 현재 구현에는 명확한 한계가 있다.
- 단항 연산 체인만 지원한다.
- GPU 경로는 제외되어 있다.
- fusion 대상이 제한적이며, 복합 연산은 지원되지 않는다.
이 한계는 의도된 것이며, 정확성을 최우선으로 두고 최소 패턴부터 도입하는 전략의 결과다.
📊 실험: LogExp 체인에서의 실제 속도 개선
이론만으로는 fusing의 효과를 직관적으로 전달하기 어렵기 때문에, LogExp 패턴에 대해 간단한 실험을 수행했다. CPU 환경에서 를 20회 연속으로 적용한 뒤 backward 시간을 측정했고, fusion ON/OFF를 비교했다. x축은 입력 텐서의 element 수이며, 좌측 그래프는 평균 backward 시간, 우측 그래프는 OFF/ON speedup 비율을 나타낸다.
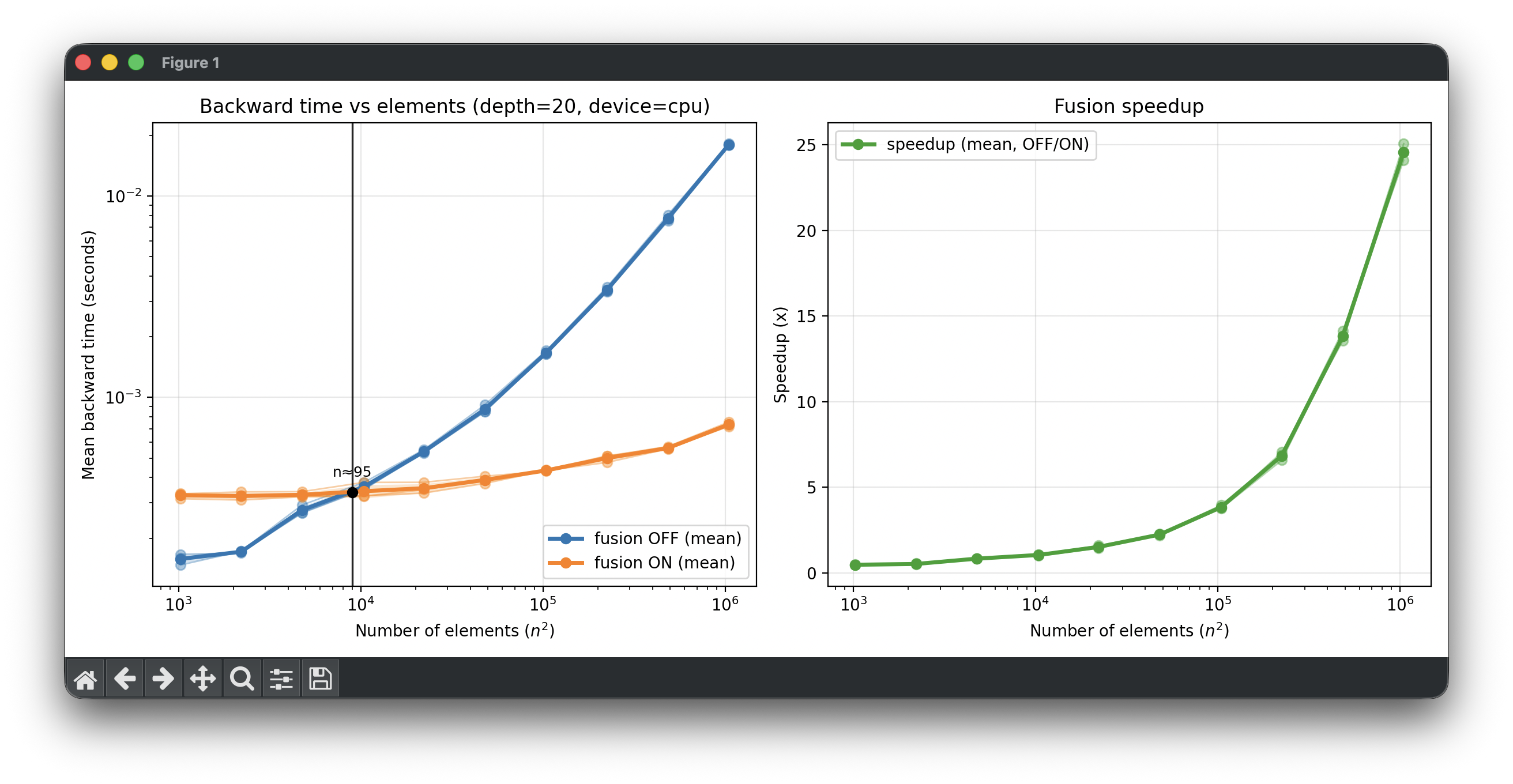
결과는 명확했다. 작은 텐서에서는 차이가 크지 않지만, element 수가 증가할수록 fusion OFF의 cost는 급격히 증가했고, fusion ON은 상대적으로 완만하게 증가했다. 특히 큰 입력 구간에서는 speedup이 두 자릿수로 올라가며, LogExp처럼 항등에 가까운 체인을 fusing하는 것이 실제로 의미 있는 효과를 만든다는 점을 확인할 수 있었다.
🌱 앞으로의 확장 가능성
Backward Fusion의 확장은 크게 두 방향이 가능하다.
- 패턴 확장: binary op 조합이나 activation-chain 등으로 대상 확대.
- 디바이스 확장: GPU path에서도 fusing 가능한 연산에 대해 동일한 로직 적용.
이를 위해서는 fused grad 함수가 multi-input을 안전하게 처리할 수 있어야 하며, 현재의 FusedBackwardOp 인터페이스도 이를 위해 확장될 필요가 있다. 또한 fusion에 의해 그래프가 재구성될 때, 디버깅이나 hook 동작과 충돌하지 않도록 정교한 조건 설계가 필요하다.
🏁 마무리
Backward Fusion은 Lucid의 backward 엔진에 작고 명확한 최적화 층을 추가한 기능이다. 구조 자체는 단순하지만, 실제로는 그래프 구조의 안정성, gradient 정확성, 그리고 메모리 수명이라는 세 가지 축을 동시에 고려해야 했기 때문에 설계 난이도가 꽤 높았다.
이번 도입으로 Lucid는 단순한 autodiff 엔진을 넘어, 그래프 구조 자체를 읽고 최적화하는 프레임워크로 한 단계 더 진화했다. 앞으로 더 많은 패턴과 디바이스 경로가 이 구조 안으로 들어오게 될 것이며, 그 과정에서 fusion 시스템은 Lucid의 성능 최적화에서 핵심 축이 될 것이다.
