자료구조의 정의와 중요한 이유
자료 구조란 데이터의 편리한 접근과 조작을 가능하게 하는 데이터를 저장하거나 조직하는 방법입니다. 문맥과 데이터의 종류에 따라 적절한 자료 구조를 사용하는 것은 전체 개발 시스템에 큰 영향을 끼칩니다. 그렇기 때문에 자료구조의 다양한 종류와 각각의 장점과 한계를 잘 이해하고 상황에 맞게 올바른 자료 구조를 선택하고 사용하는 것이 중요합니다.
자료구조는 언어별로(ex: JavaScript, Python, Java, C...) 지원하는 양상이 다릅니다. 언어별로 지원하는 자료구조의 양상이 다르더라도 개념을 올바르게 이해한담녀 해당 언어에 맞추어서 사용하면 됩니다.
자료 구조의 분류
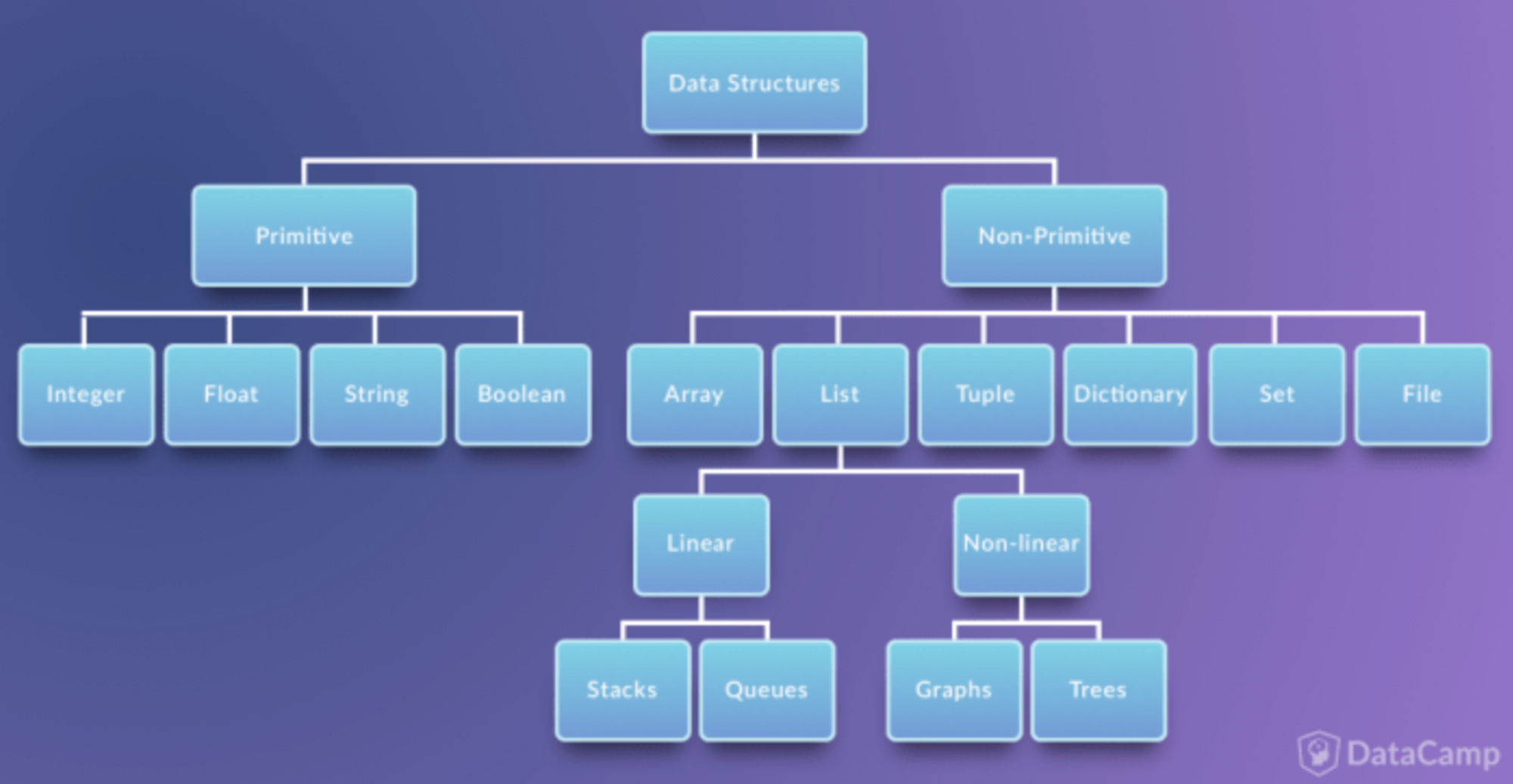
- Primitive Data Structure(단순 구조)
: 프로그래밍에서 사용되는 기본 데이터 타입 - None-Primitive Data Structure(비단순 구조)
: 단순한 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료 구조
- Linear Data Structure(선형 구조)
: 저장되는 자료의 전후 관계가 1:1 (ex. List, Stacks, Queues)
- Non-Linear Data Structure(비선형 구조)
: 데이터 항목 사이의 관계가 1:n 또는 n:m (ex. Graphs, Trees )
일반적으로 가장 자주 사용되는 자료 구조
- Array(List)
- Tuple
- Set
- Dictionary
- Stack & Queue
- Tree
Array(List)
Array(List)는 가장 기초적이고 단순하면서도 가장 자주 사용 되는 자료 구조입니다.
👉 특징 : 순차적으로 데이터를 저장하는 자료 구조
- 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점입니다.
- 자료구조에 저장하는 데이터는 일반적으로 요소(element)라고 합니다.
- 서로 연결된 데이터들을 순차적으로 저장할 때 사용합니다.
- 순서가 상관 없더라도 서로 연결된 데이터들을 저장할 때 일반적으로 사용합니다.
👉 추가적인 특징
- 삽입(insert) 순서대로 저장됩니다. (새로 삽입되는 요소는 array의 마지막 요소가 됩니다.)
- 이미 생성된 리스트도 수정 가능합니다.
- 동일한 값도 여러번 삽입 가능합니다.
Multi-dimensional Array(다중차원 배열)
- Array의 요소도 array가 될 수 있습니다. 이러한 array를 다중차원(multi-dimensioanl) array 라고 합니다. 일반적으로 2D(2차원) array가 많이 사용됩니다.
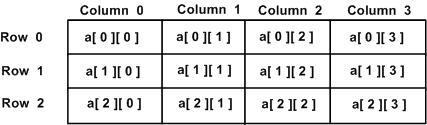
Array 내부 구조
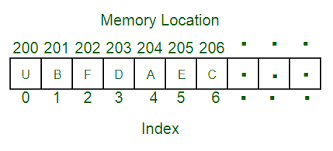
- Array의 가장 큰 특징은 순차적으로 데이터를 저장하는 것이었습니다.
- 순차적을 저장된 데이터는 순차적으로 번호(index)를 지정할 수 있습니다.
- Array의 첫번째 index는 0부터 시작합니다. 마이너스 인덱스는 마지막 요소부터 시작합니다.
(ex: array[-1] : 마지막)
왜 Array는 순차적으로 데이터를 저장할까요?
그건 Array가 실제 메모리 상에서, 즉 물리적으로 데이터가 순차적으로 저장되기 때문입니다.
데이터에 순서가 있기 때문에 index가 존재하며, 특정 요소를 array에서 읽어 들이는 것이 가능하고, 요소의 특정 부분(n~m번째 인덱스)을 분리해 조작하는 것이 가능합니다.
Array 단점
Array는 메모리의 데이터 뿐만 아니라 실제 주소도 순차적으로 되어있습니다. 그렇기 때문에 인덱싱이 가능하는 등 여러 가지 장점이 있지만 반대로 단점도 있습니다.
요소 삭제&추가 (Removing or Adding Elements)
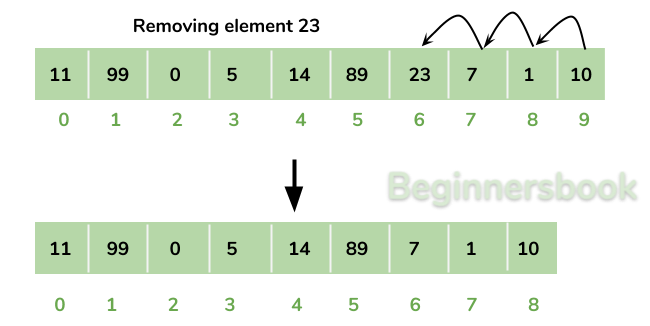
- 순차적으로 담겨있는 데이터 중 특정 위치에 잇는 중간의 요소가 삭제 되는 경우에, 메모리가 항상 순차적으로 이어져있어야 하기 때문에, 삭제된 요소 뒤에 있는 모든 요소들을 앞으로 한 칸씩 이동시켜야 합니다. => 다시 말해서, array에서 요소를 삭제하는 것은 다른 자료 구조에 비해 느릴 수 있습니다.
- 요소를 삭제하느 과정이 코드 상에서는 한 줄 이지만, 실제 메모리 상에서 이루어지는 작업(operation)은 훨씬 커집니다.(expensive operation)
- 중간에 요소가 추가 되는 경우도 삭제와 마찬가지로, 추가 된 요소 뒤에 있는 요소들은 한 칸씩 뒤로 이동해야 합니다.
이런 이유로, Array는 정보가 자주 삭제 되거나 추가되는 데이터를 담기에 적절치 않습니다.
Array Resizing
- 배열은 메모리가 순차적으로 채워지기 때문에 배열이 처음 생성될 대 어느 정도 메모리를 미리 할당합니다. (
pre-allocation) - 메모리를 pre-allocation함으로써 새로 추가되는 요소들도 순차적으로 메모리에 저장할 수 있습니다.
- 요소들이 pre-allocation했던 메모리 이상으로 많아지면 메모리를 더 할당해줘야 합니다.(
resizing) - 새로 추가 할당된 메모리도 순차적이어야 하기 때문에, 배열의 resizing은 상대적으로 오래 걸립니다.
- 예를 들어, 100개의 메모리 공간이 다 차서 100개를 추가해야 되는 경우 200개 크기의 메모리를 생성 하고 기존 100개를 복사하고, 101번 부터 데이터가 순차적으로 추가됩니다.
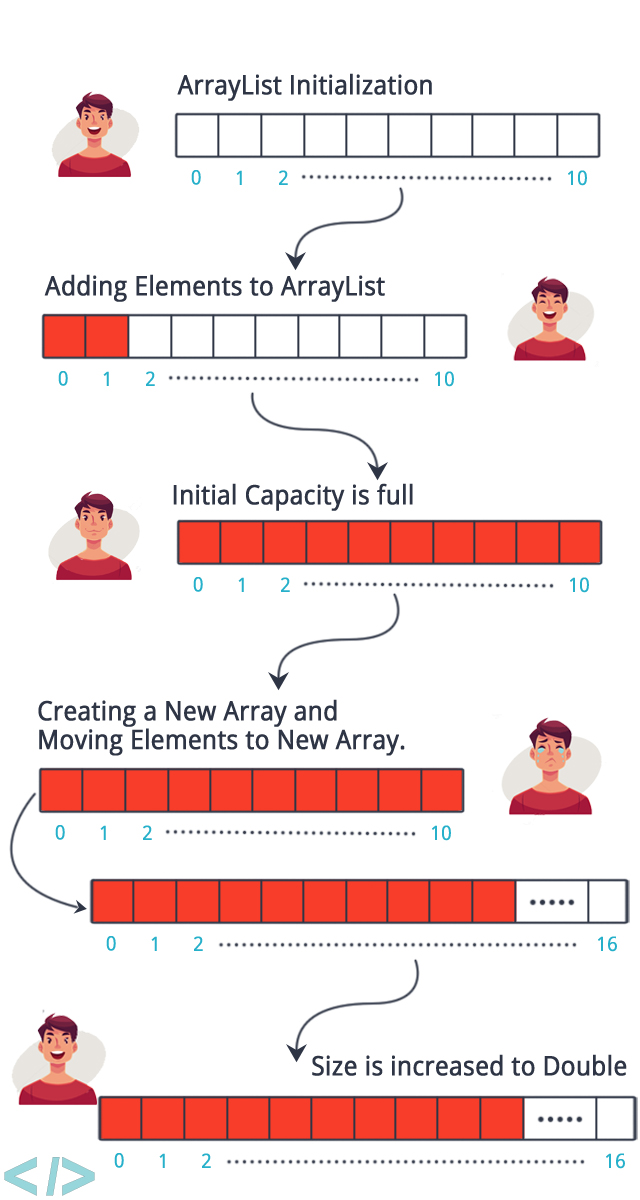
그렇기 때문에 Array는 사이즈 예측이 잘 안 되는 데이터를 다루기에는 적절치 않습니다. 일반적으로 대부분의 언어에서는 배열의 pre-allocation과 resizing을 자동으로 실행하지만, 이러한 점을 알고 있어야 사이즈가 급격하게 자주 늘어날 확률이 있는 데이터는 array보다 더 적합한 자료구조를 선택해야 한다는 것을 알 수 있습니다.
Array를 사용하면 좋은 경우
주식 차트에 대한 데이터는 요소가 중간에 새롭게 추가되거나 삭제되는 정보가 아니며, 날짜별로 주식 가격이 차례대로 저장되어야 하는 데이터입니다. 즉, 순서가 굉장히 중요한 데이터 이므로 Array 같이
순서를 보존 해주는 자료구조를 사용하는 것이 좋습니다. 이와 같은 데이터에 Array를 사용하지 않는 경우, 즉 순서가 없는 자료 구조를 사용하는 경우에는 날짜별 주식 가격을 확인하기 어려우며 매번 전체 자료를 읽어 들이고 비교해야 하는 번거로움이 발생합니다.
- 순차열적인 데이터를 저장할 때
- 다차원 데이터를 다룰 때 => Multi-dimensional Array
- 어떠한 특정 요소를 빠르게 읽어야 할 때 => index로 쉽게 접근 가능
- 데이터의 사이즈가 급변하게 자주 변하지 않을 때
- 요소가 자주 삭제 되거나 추가되지 않을 때
