본 자료는 Elice 플랫폼의 자료를 사용하여 정리하였습니다.
Numpy 사용해보기
Numpy 소개
Numpy란?
- Python에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리
list와 차이점
- list에 비해 빠른 연산을 지원하고 메모리를 효율적으로 사용
배열 만들기
import numpy as np
np.array([1, 2, 3, 4, 5]) # array([1, 2, 3, 4, 5])배열 데이터 타입
np.array([1, 2, 3, 4], dtype = float) # array([1., 2., 3., 4., 5.])
or
numpy배열.astype(int) # array([1, 2, 3, 4])- 타입은 int, float, str, bool 등이 있다.
다양한 배열 만들기
np.zeros(10, dtype = int):0으로1x10배열 만들기np.ones((3,5), dtype = float):1로3x5배열 만들기(실수형태로)np.arange(0, 20, 2):0 <= x < 20으로 2배수씩 채워서 배열 만들기np.linspace(0, 1, 5):0 ~ 1을 5개로 나눠서 배열 만들기
난수로 채워진 배열만들기
np.random.random((2,2)): 난수로2x2배열 만들기np.random.normal(0, 1, (2,2)): 평균이0이고 표준편차가1인 값으로2x2배열 만들기np.random.randint(0, 10, (2,2)):0부터10까지 값으로2x2배열 만들기
배열의 기초
x2.ndim: 몇차원인지x2.shape:?x?배열인지x2.size: 원소가 몇개인지x2.dtype: 데이터타입이 뭔지
Indexing / Slicing
배열[위치]배열[시작:끝]
모양바꾸기
배열.reshape((행, 열)): shape를행x열로 변경np.concatenate([배열1, 배열2], axis = 0): 행을 기준으로 배열을 이어붙인다.(axis를 1로 설정하면 열을 기준으로 삼는다.)a, b = np.split(배열, [인덱스], axis = 0): 행을 기준으로 인덱스 부분에서 나눈다.(axis를 1로 설정하면 열을 기준으로 삼는다.)
Numpy 연산
기본연산
배열 + 5: 배열 모든 값에 +5배열 - 5: 배열 모든 값에 -5배열 * 5: 배열 모든 값에 x5배열 / 5: 배열 모든 값에 /5
행렬끼리도 가능하다.
브로드캐스팅
shape이 다른 array끼리 연산
matrix + 5: matrix의 모든 값에 +5matrix + np.array([1, 2, 3]): matrix행 마다 [1, 2, 3]을 더한다.np.arange(3).reshape((3, 1)) + np.arange(3):3x1과1x3을 더한다.
집계함수 & 마스킹연산
집계함수
np.sum(배열): 합np.min(배열): 최소값np.max(배열): 최대값np.mean(배열): 평균값
배열뒤에 axis로 행 또는 열 별 집계가 가능하다.
마스킹연산
배열 < 3: 값을 다 비교하고 값 위치에 True/False를 채운다.배열[배열 < 3]: True인 값만 출력
Pandas 기본 알아보기
pandas란?
- 구조화된 데이터를 효과적으로 처리하고 저장
- Array 계산에 특화된 numpy를 기반으로 설계
Series
- numpy array가 보강된 형태
- Data와 Index를 가지고 있다.
import pandas as pd
pd.Series([1, 2, 3, 4], index = ['a', 'b', 'c', 'd'], name = 'Title')- 딕셔너리를 Series에 넣을 수 있다.
DataFrame
- 여러 개의 Series가 모여서 행과 열을 이룬 데이터
pd.DataFrame(...)
저장과 불러오기
저장
df.to_csv(파일명)
df.to_excel(파일명)
불러오기
변수명 = pd.read_csv(파일명)
변수명 = pd.read_excel(파일명)
Indexing / Slicing
.loc: 인덱스를 이용해 인덱싱.iloc: 정수를 이용해 인덱싱
새로운 컬럼 추가
df[컬럼명] = np.nan
df.loc[0, 컬럼명] = 값
컬럼 선택하기
df[컬럼명]
df[[컬럼1, 컬럼2]]
누락된 데이터 체크
df.isnull(): 비어있으면 Truedf.notnull(): 값이 있으면 Truedf.dropna(): 비어있는 값이 있는 행 삭제df[컬럼명] = df[컬럼명].fillna(값): 비어있으면 값을 채워준다.
값으로 정렬하기
df.sort_values(컬럼명, ascending = True): 오름차순 정렬df.sort_values([컬럼1, 컬럼2]): 컬럼 2개로 정렬
Pandas 심화 알아보기
조건으로 검색하기
Masking 연산
df["A"] < 0.5
조건 선언
df[(df["A"] < 0.5) & (df["B" > 0.3)]
or
df.query("A < 0.5 and B > 0.3")
문자열로 검색
df["Animal"].str.contains("Cat")
or
df.Animal.str.match("Cat")
함수로 데이터 처리하기
df[컬럼명].apply(함수)
apply 기능에서 데이터 값만 대체하고 싶을 때
df.Sex.replace({"Male":0, "Female":1}, inplace = True)
그룹으로 묶기
df.groupby(컬럼명)
aggregate: 집계를 한번에
df.groupby(컬럼명).aggregate({'data1':'min', 'data2':np.sum})filter: 필터링
df.groupby(컬럼명).filter(함수)apply: 함수 적용
df.groupby(컬럼명).apply(lambda x: x.max() - x.min())get_group: 그룹에서 Key로 데이터 가져오기
df.groupby(컬럼명).get_group(값)
MultiIndex
index = [['A', 'A', 'B', 'B'], [1, 2, 1, 2]]
- Columns도 가능하다.
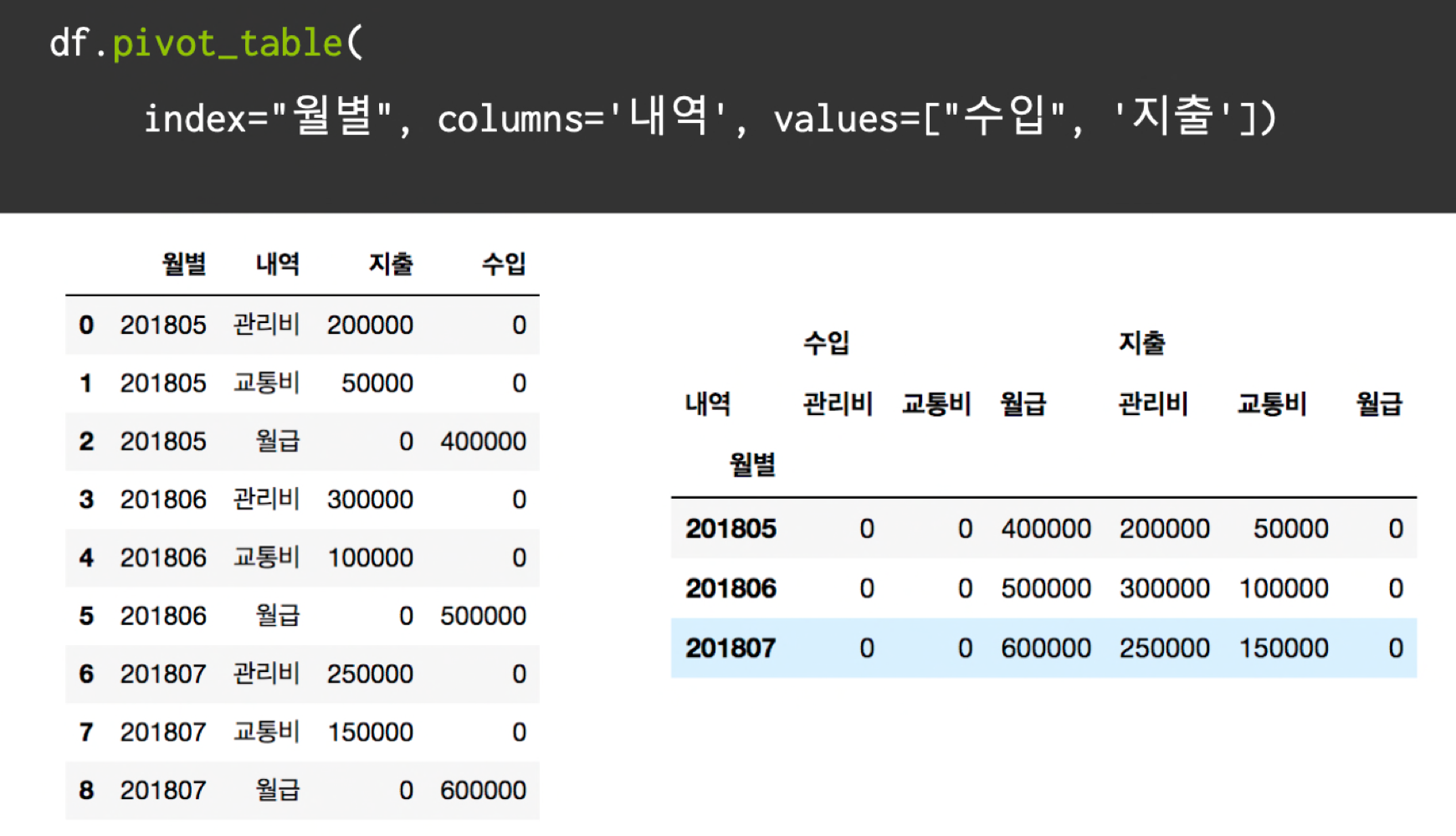
pivot_table
Matplotlib 데이터 시각화
Matplotlib이란?
- 파이썬에서 데이터를 그래프나 차트로 시각화할 수 있는 라이브러리
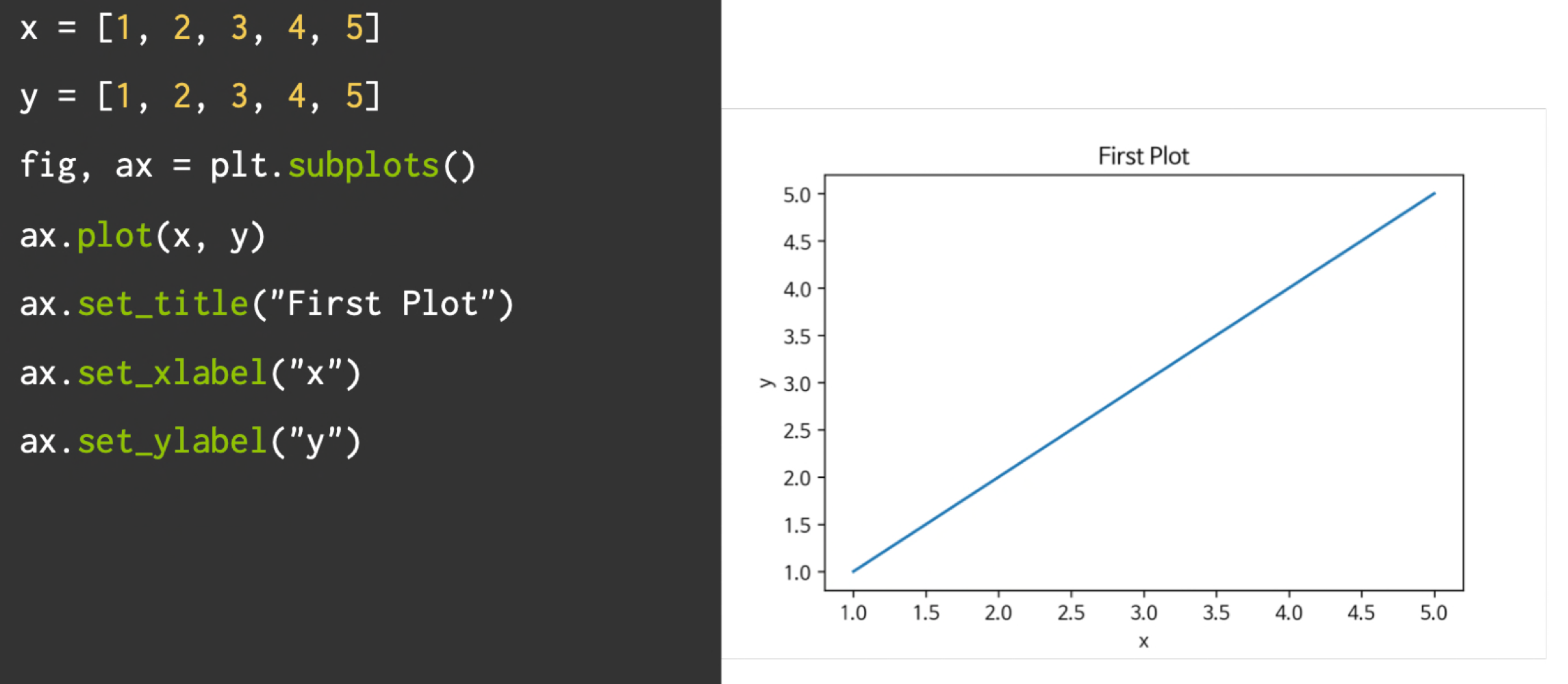
저장하기
- 위의 그림에서 아래 코드 추가
fig.set_dip(300) fig.savefig(파일명)
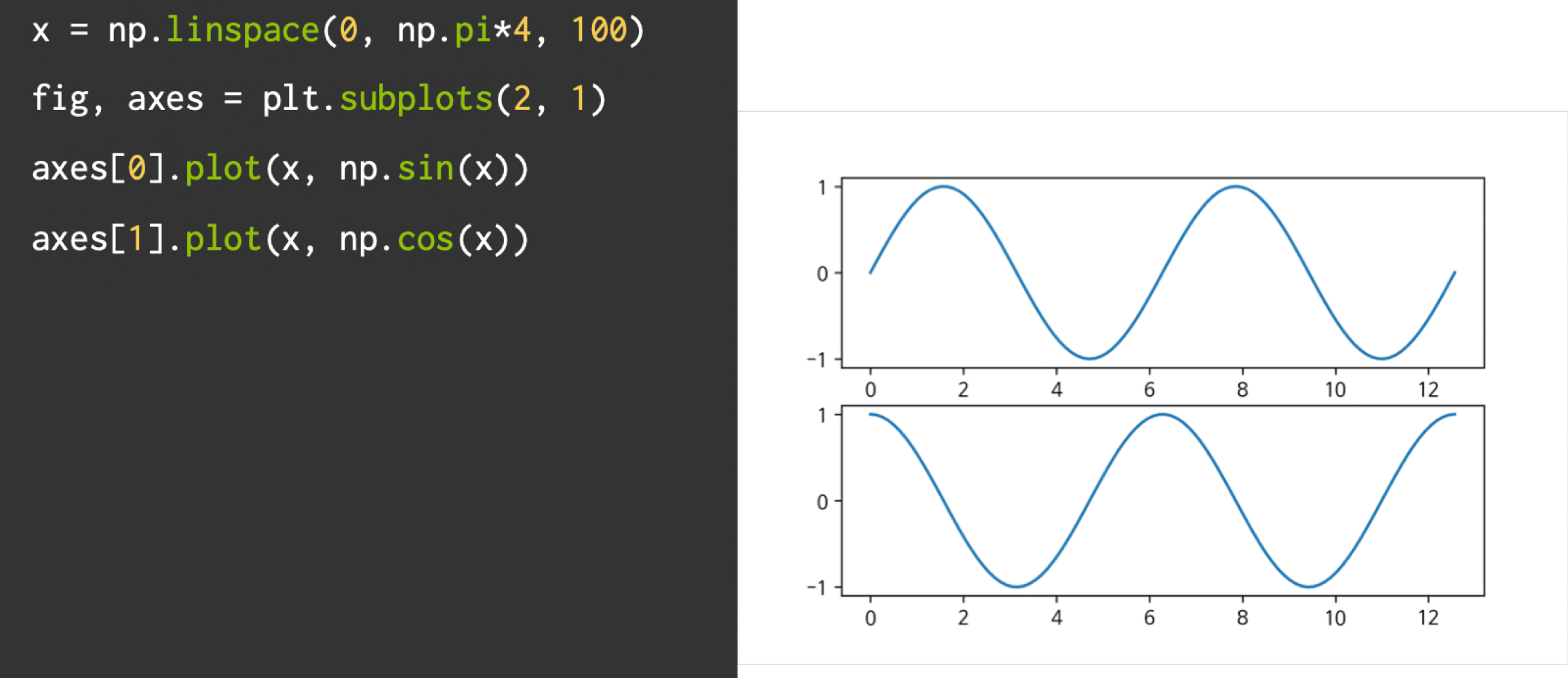
그래프 여러개 그리기
그래프 스타일
라인강조
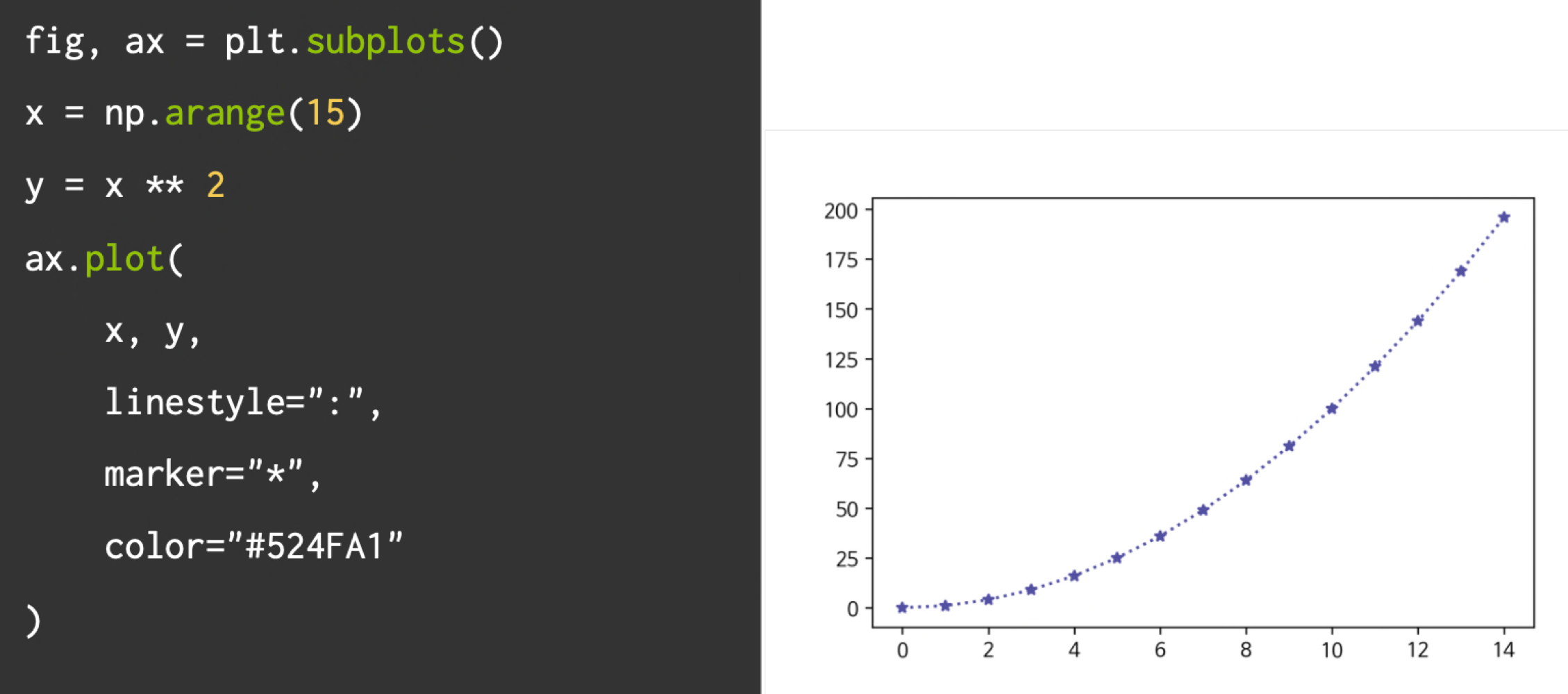
라인스타일
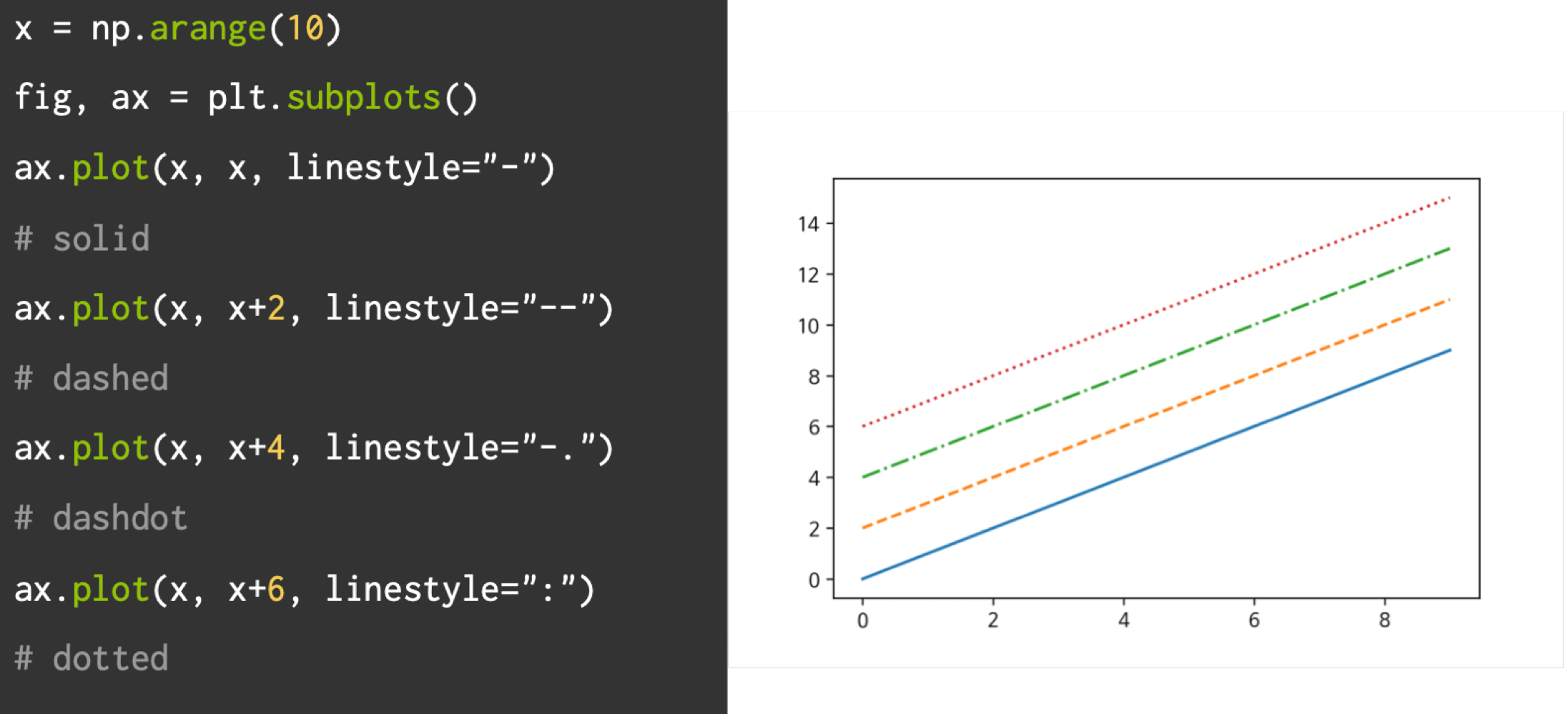
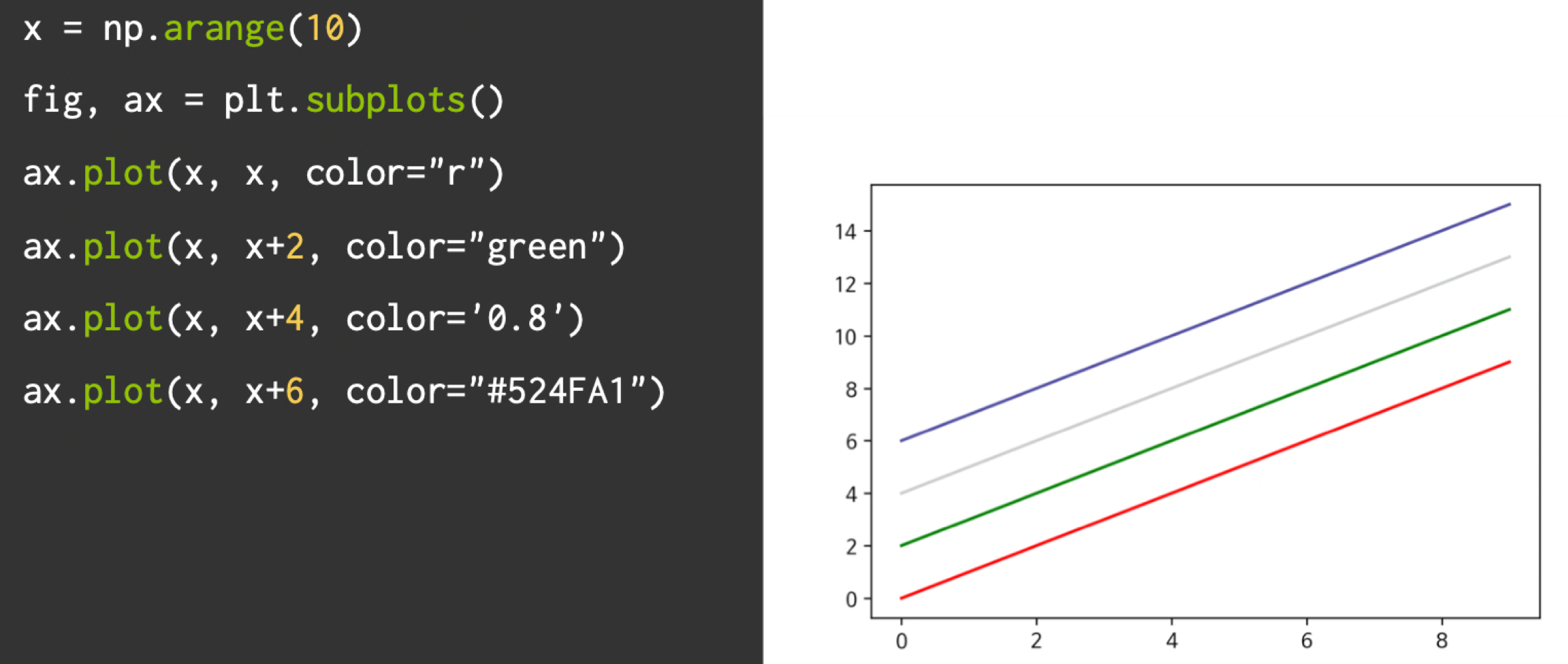
라인색상
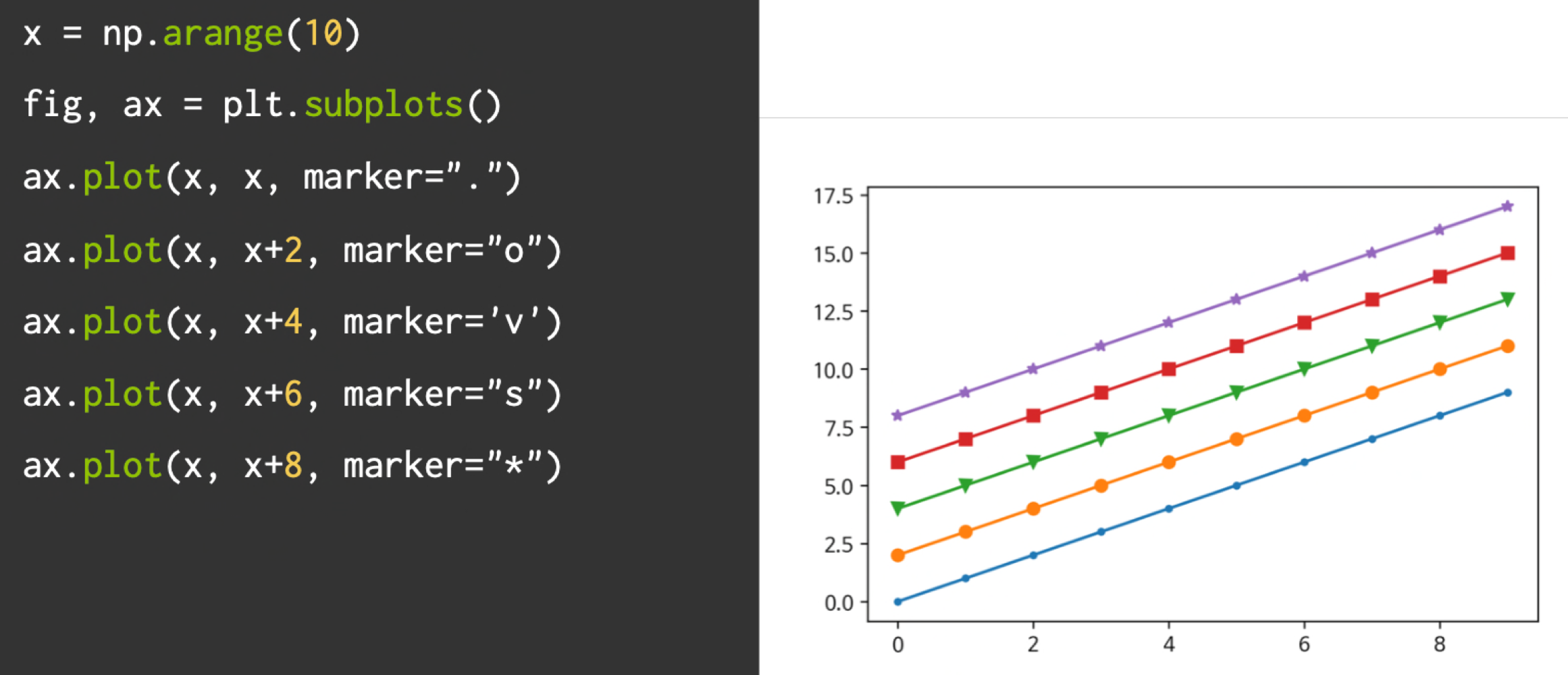
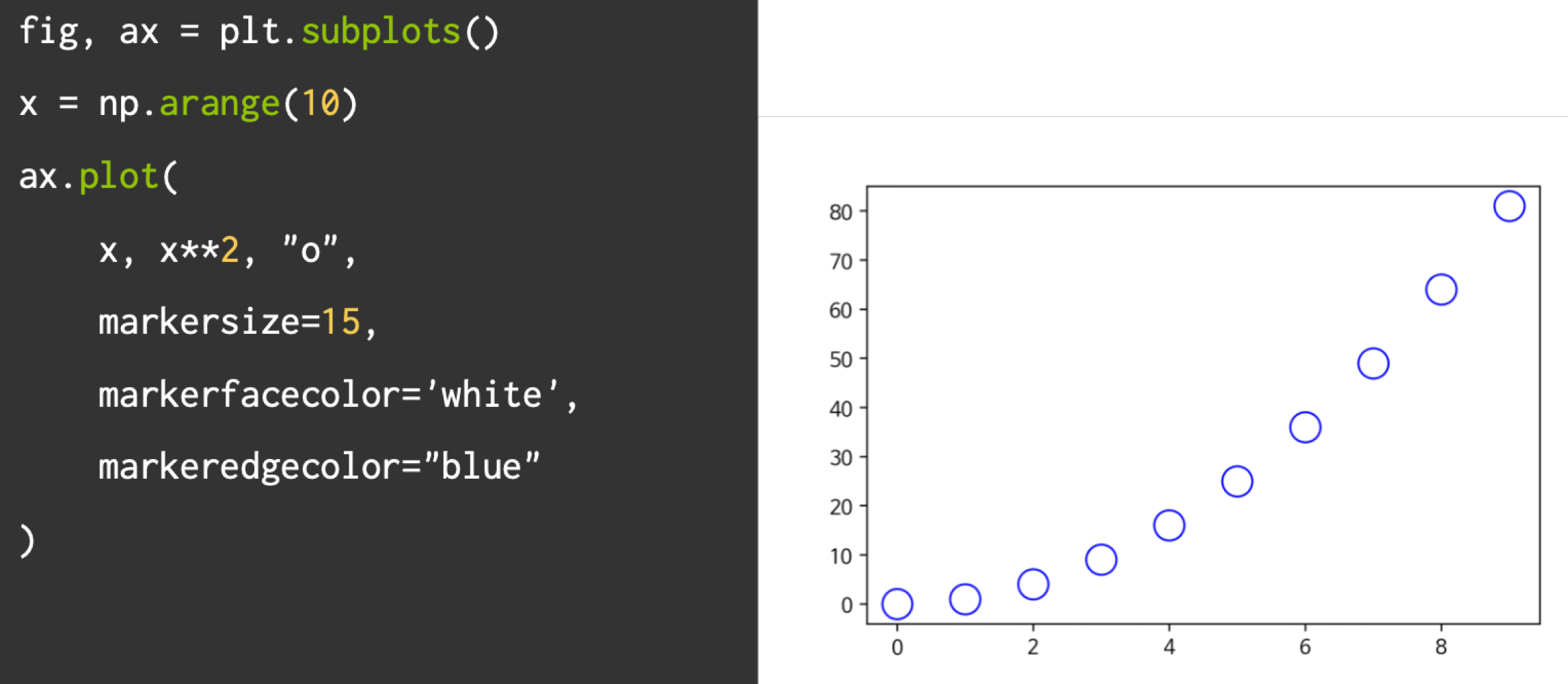
라인마커
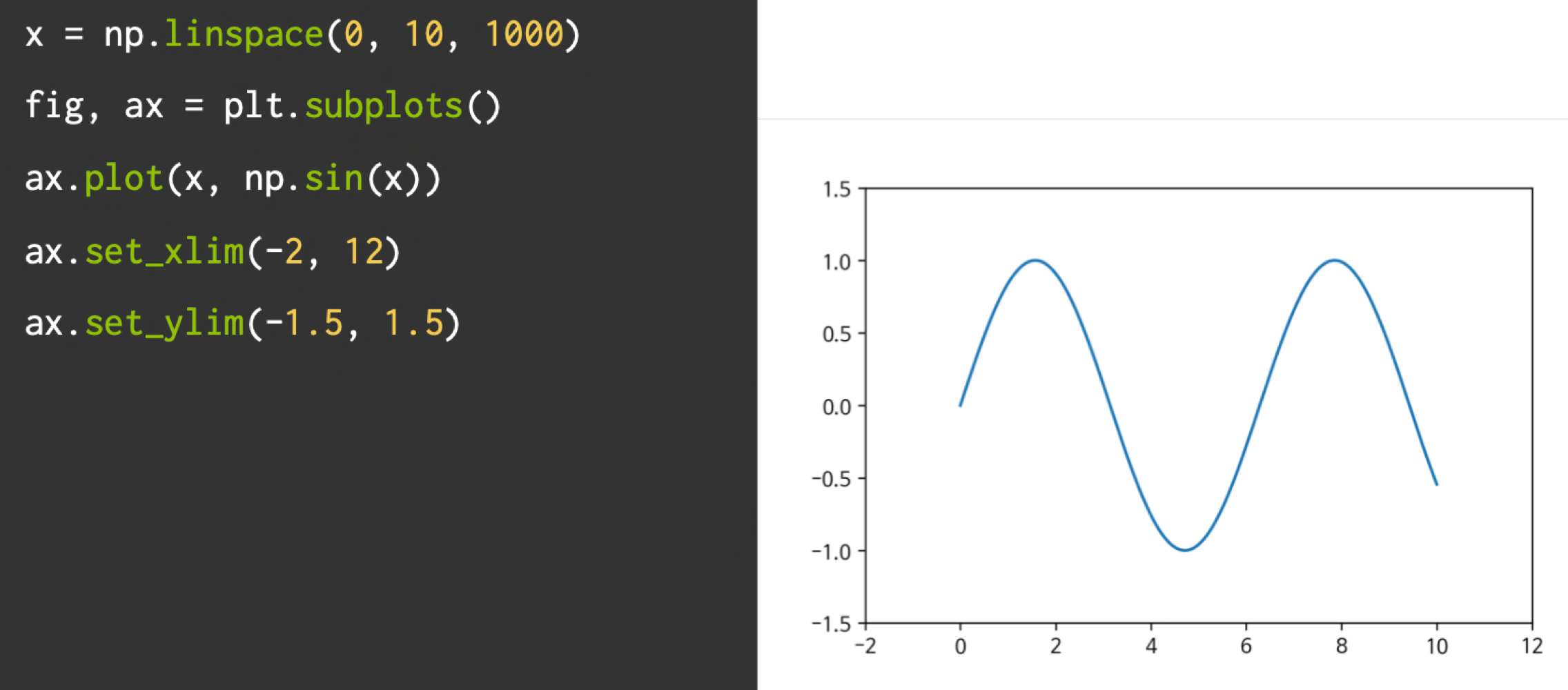
축경계 조정
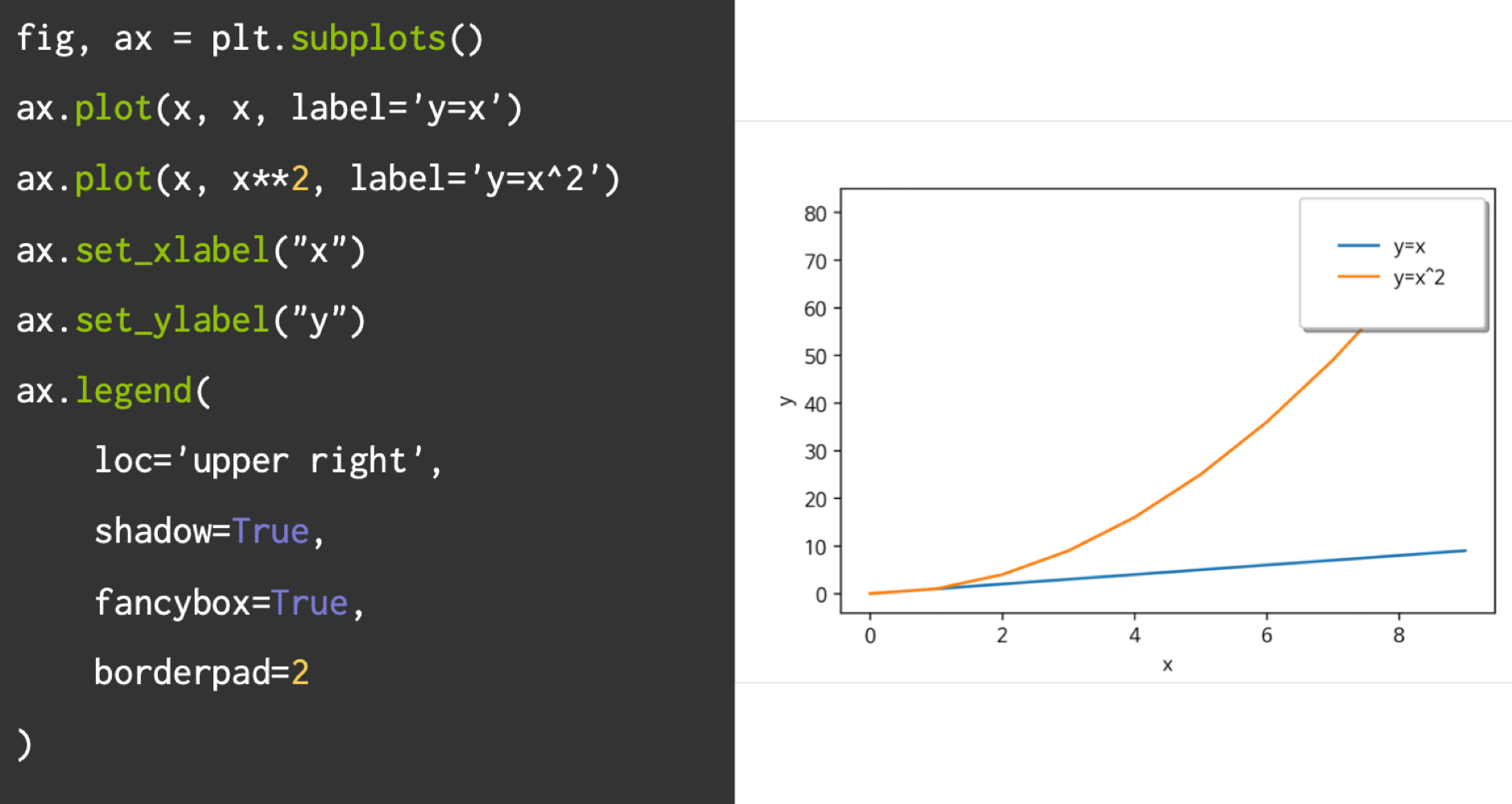
범례
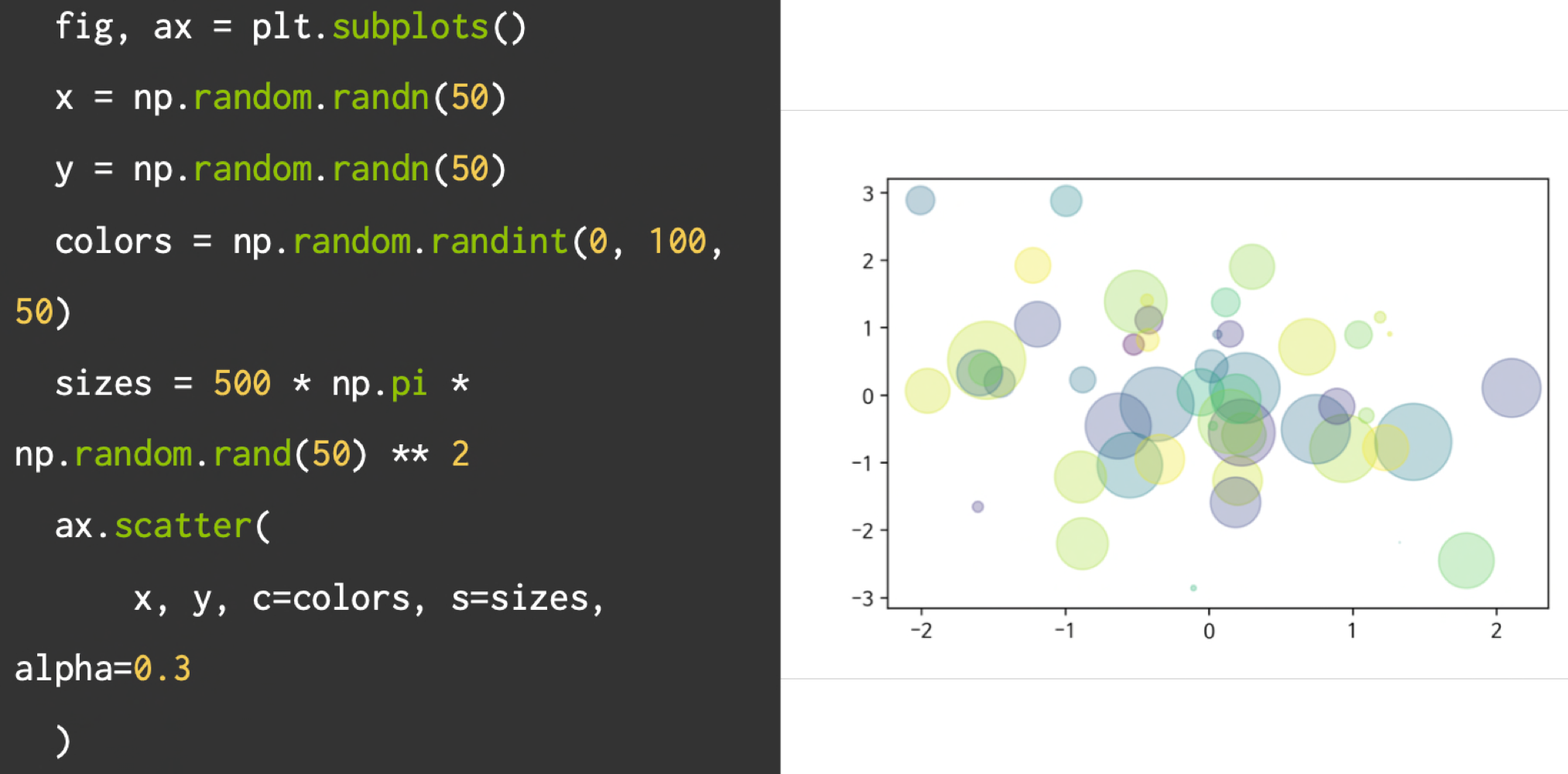
선점도 그래프(Scatter)
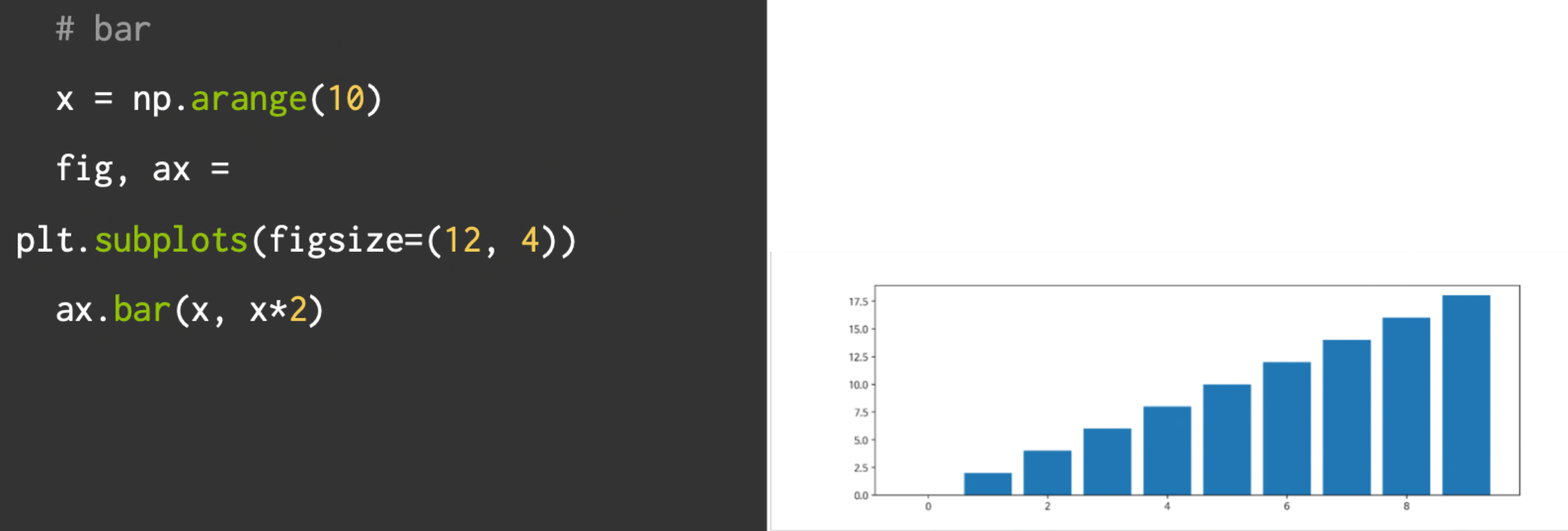
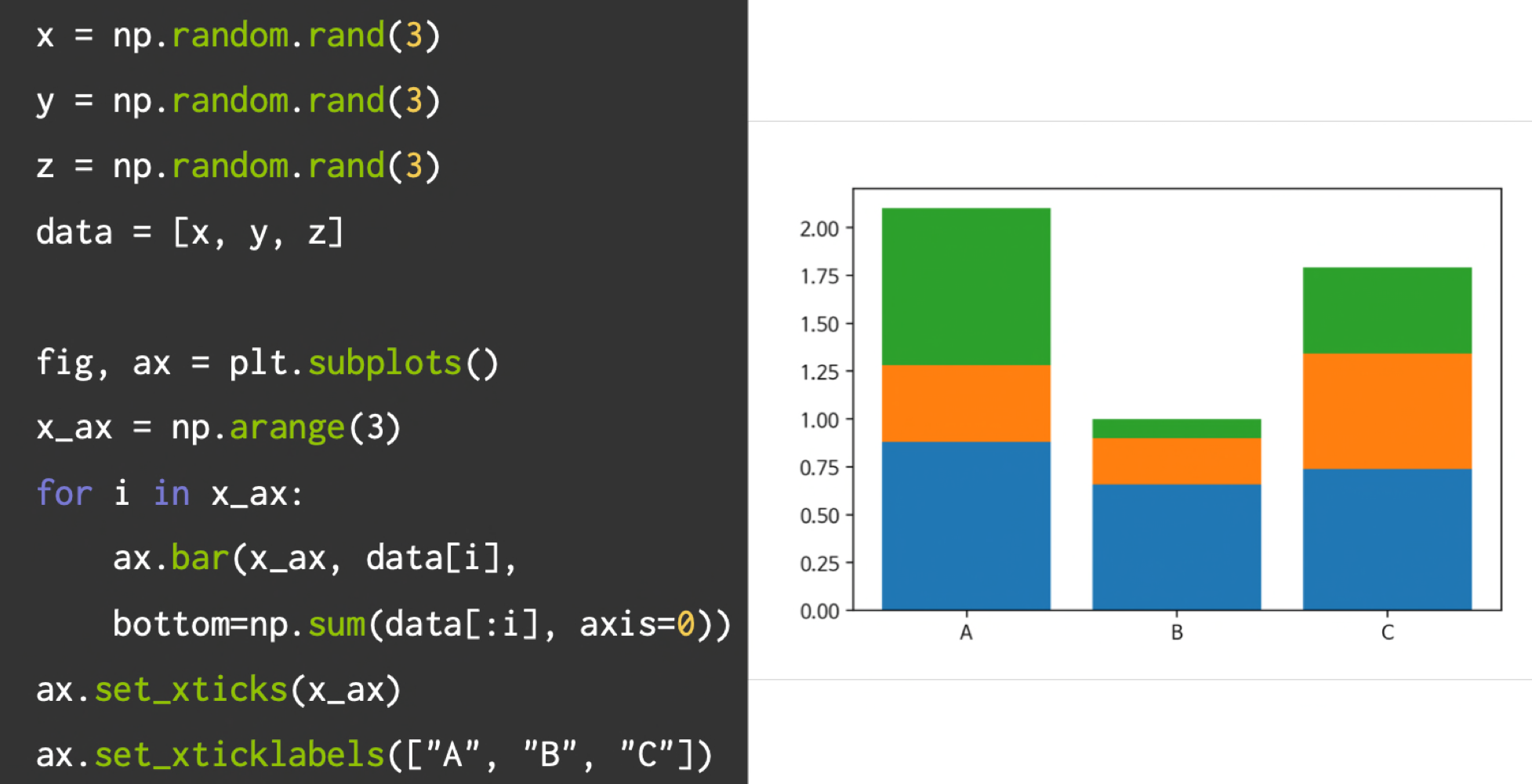
막대 그래프(Bar)
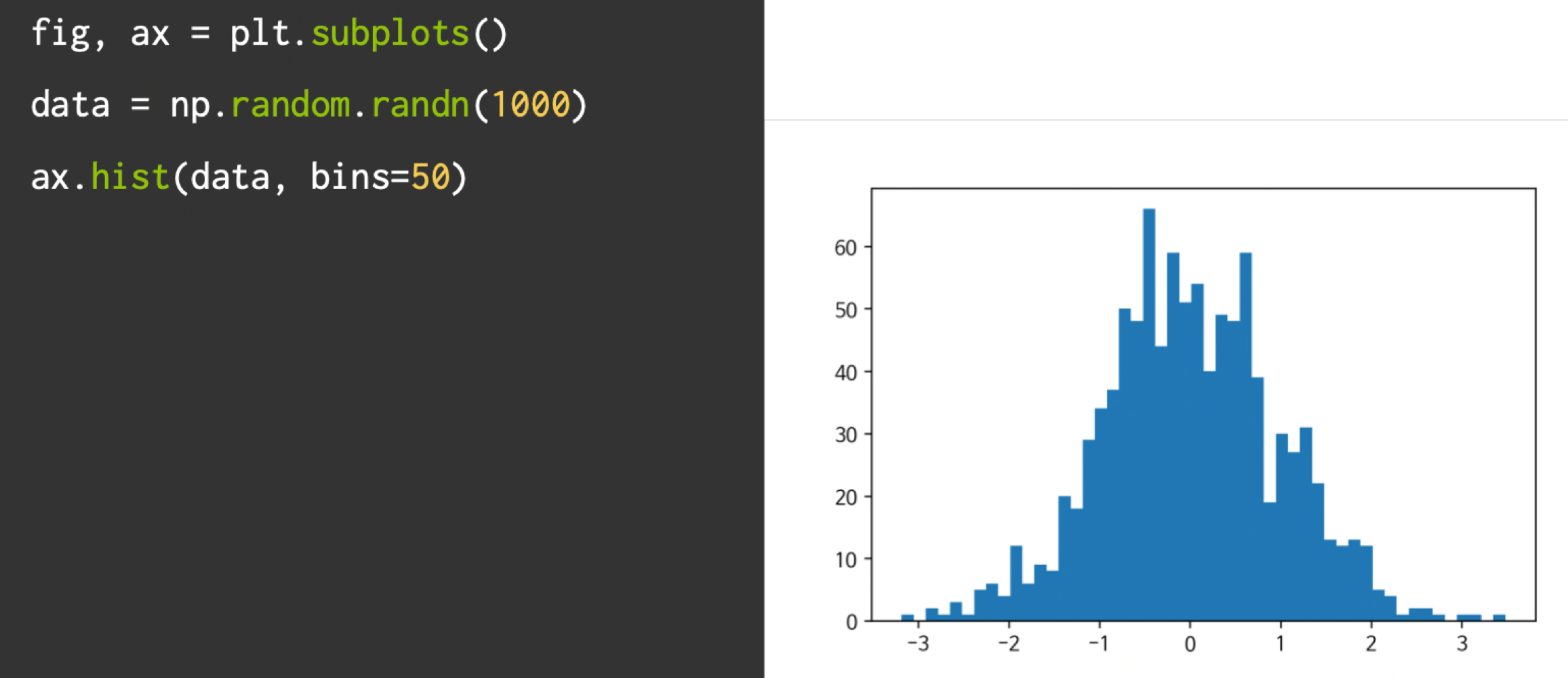
Histogram
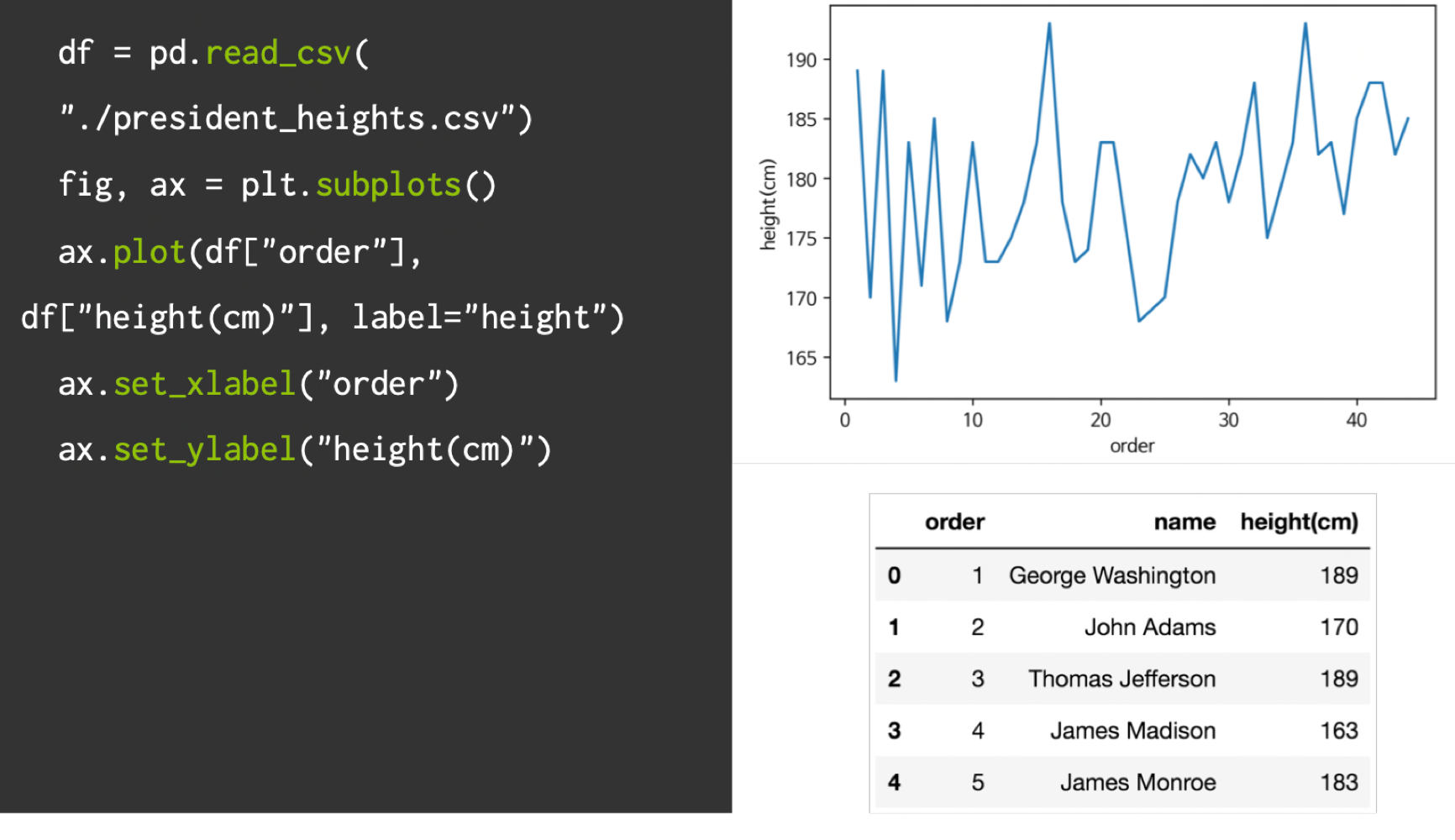
Matplotlib with Pandas
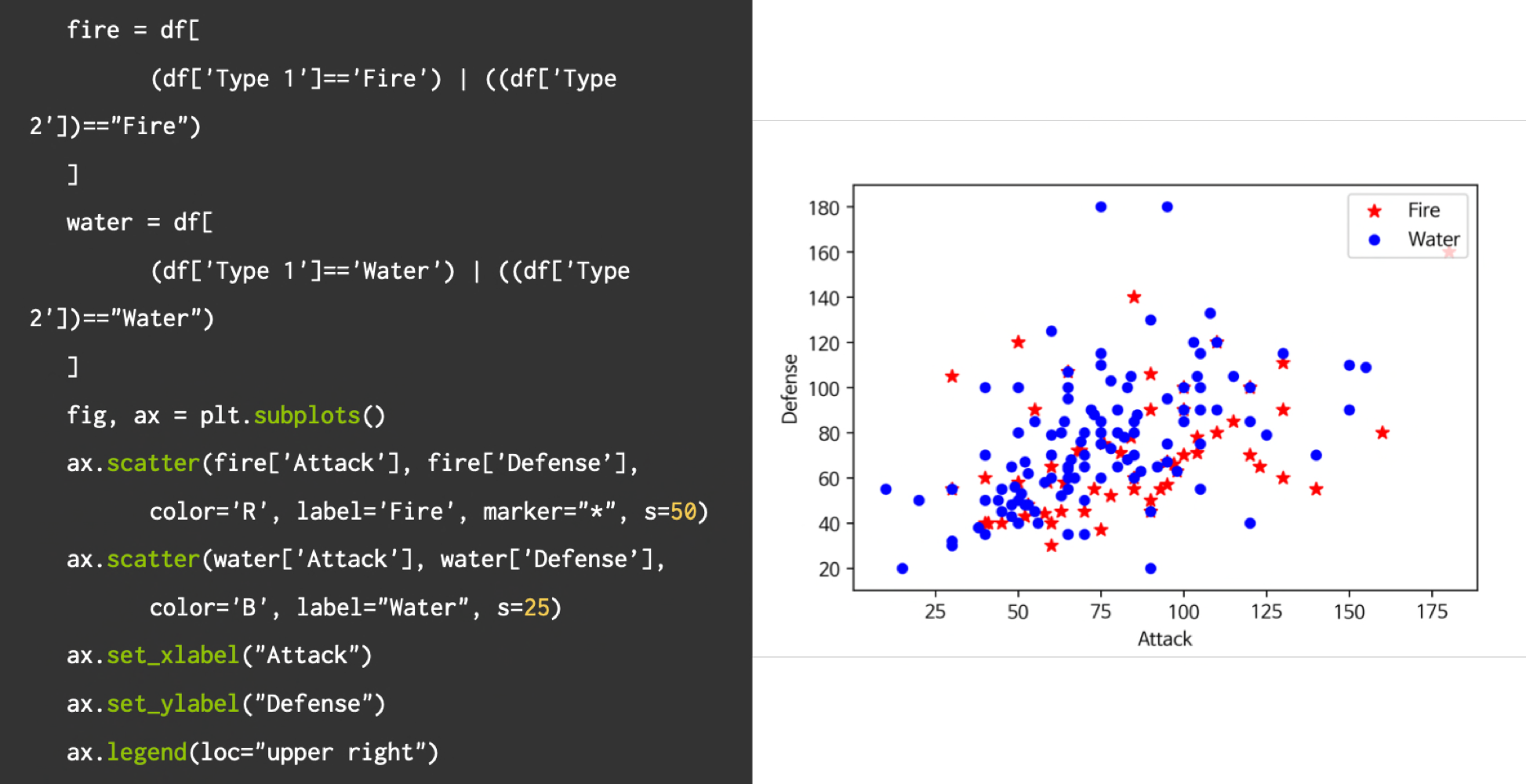

열심히