
유사도 계산 알고리즘
유사도 계산 하면 가장 유명한 알고리즘은 DTW 알고리즘입니다.
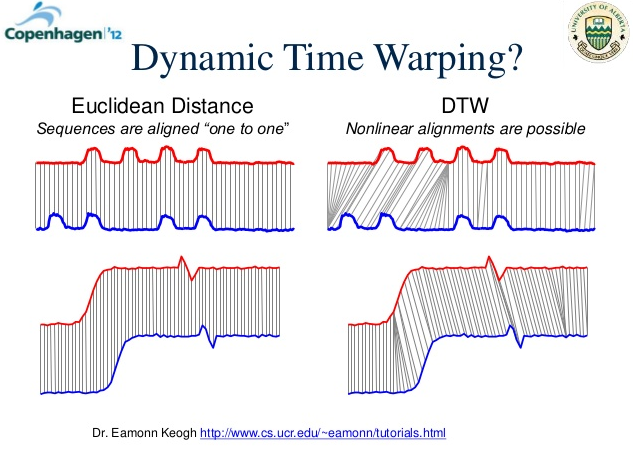
위의 그림은 두 시계열 데이터의 유사도를 계산하는 방법인데요, 왼쪽과 같이 그저 두 데이터의 차에 대한 root mean square을 계산한다면 둘은 옆으로 살짝 밀려 있는 형태임에도 아주 상이한 시계열 데이터라는 판정을 받게 될 것입니다. DTW 알고리즘은 오른쪽과 같이 데이터의 각 부분이 타겟 데이터의 어떤 부분에 대응되는지 (alignment) 판별하여, 이를 고려하는 알고리즘입니다. 자세한 내용은 Wiki를 참조해 주시면 감사하겠습니다.
MidiFind의 유사도 계산 알고리즘
MidiFind라는 논문은 두 가지 지표를 이용하여 유사도를 계산했습니다.

하나는 Bag-of-words Euclidean Distance이고, 나머지 하나는 Levenshtein Time Warping Distance입니다.

두 가지 지표는 구체적으로 어떻게 구하는 것일까요? Bag-of-words는 자연어 처리 분야에서 사용되는 용어로, 단어(이 연구에서는 음표)들을 가방 안에 넣고 나면 그 가방 속에서 단어들이 들어온 순서는 고려하지 않는다는 의미로 보시면 되겠습니다.
Bag-of-words Euclidean Distance는 연주된 음의 순서를 전혀 고려하지 않고 두 소스의 데이터에서 각 음이 연주된 빈도만을 측정합니다. 이때 옥타브는 신경쓰지 않고, C1, C2, C3, ...와 같은 음들을 모두 같은 C로 생각하여 모두 12개의 반음에 대한 히스토그램을 만들고, 이를 음표 전체의 개수로 나누어 Normalization을 수행합니다. 이렇게 각각 구한 두 개의 히스토그램의 Euclidean Distance를 재서 첫 번째 지표로 활용합니다.
Levenshtein Time Warping Distance는 두 시계열 데이터에 대해서 DTW 알고리즘 중 하나인 Levenshtein Distance를 수행한 결과를 지표로 활용합니다.
Feature Extraction
그런데, DTW 알고리즘은 1차원 시계열 데이터를 사용하는데, ...
