웹 크롤링 실습




웹 크롤링 이해하기
[복습] 데이터 사이언스 프로세스
필요한 정보를 추출하는 5가지 단계
-
문제 정의 : 해결하고자 하는 문제 정의
-
데이터 수집 : 문제 해결에 필요한 데이터 수집
-
데이터 전처리 (정제) : 실질적인 분석을 수행하기 위해 데이터를 가공하는 단계
- 수집한 데이터의 오류 제거(결측치, 이상치), 데이터 형식 변환 등
-
데이터 분석 : 전처리가 완료된 데이터에서 필요한 정보를 추출하는 단계
-
결과 해석 및 공유 : 의사 결정에 활용하기 위해 결과를 해석하고 시각화 후 공유하는 단계
[복습] 데이터 수집
데이터 수집은 다양한 기술과 방법을 활용할 수 있습니다.
-
웹 스크래핑(Web Scraping) : 웹 페이지에서 데이터를 추출하는 기술
-
웹 크롤링 (Web Crawling) : 웹 페이지를 자동으로 검색하고 데이터를 수집하는 기술
-
Open API 활용 : 공개된 API를 통해 데이터를 수집
-
데이터 공유 플랫폼 활용 : 다양한 사용자가 데이터를 공유하고 활용할 수 있는 온라인 플랫폼
종류 : 캐글 (Kaggle), Data world, 데이콘, 공공 데이터 포털 등
웹 크롤링이란?
여러 웹 페이지를 돌아다니며 원하는 정보를 모으는 기술
원하는 정보를 추출하는 스크래핑(Scraping)과 여러 웹 페이지를 자동으로 탐색하는 크롤링(Crawling)의 개념을 합쳐 웹 크롤링이라고 부름
즉, 웹 사이트들을 돌아다니며 필요한 데이터를 추출하여 활용할 수 있도록 자동화된 프로세스
웹 크롤링 프로세스
웹 페이지 다운로드
- 해당 웹 페이지의 HTML, CSS, JavaScript 등의 코드를 가져오는 단계
페이지 파싱
- 다운로드 받은 코드를 분석하고 필요한 데이터를 추출하는 단계
링크 추출 및 다른 페이지 탐색
- 다른 링크를 추출하고, 다음 단계로 이동하여 원하는 데이터를 추출하는 단계
데이터 추출 및 저장
- 분석 및 시각화에 사용하기 위해 데이터를 처리하고 저장하는 단계
웹 크롤링 실습
준비 단계
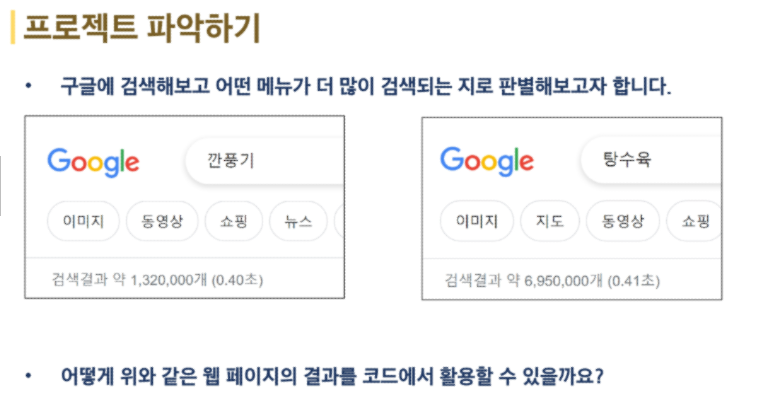
실습 및 도전 과제에는 구글 검색 결과 페이지를 크롤링합니다.
아래 필수 라이브러리 설치 후 진행합니다.
request : HTTP 요청을 보내고 응답을 받을 수 있는 모듈
beautifulSoup : HTML 문서에서 원하는 데이터를 추출하는데 사용하는 파이썬 라이브러리
Selenium : 웹 어플리케이션을 테스트하고 자동화하기 위한 파이썬 라이브러리
- 웹 페이지의 동적인 컨텐츠를 가져오기 위해 사용함 (검색 결과 등)
