
📓 QueryDSL
◎쿼리를 자바 코드로 작성하기 때문에 띄어쓰기, 공백 문제 없고 자바 컴파일러가 오류를 잡아준다.
◎자바 코드기 때문에 코드 자동 완성의 도움을 받을 수 있다.
◎동적 쿼리도 편하게 작성하도록 도와준다.
◎메소드를 따로 뽑을 수 있어 다른 곳에서 재사용이 가능하다.
스프링 데이터 JPA + QueryDSL 로 지금까지 단순하고 반복이라고 생각했던 개발 코드들이 확연하게 줄어들고 핵심 비즈니스 로직을 개발하는데 집중할 수 있다.
그만큼 QueryDSL은 실무 필수 기술이다.
관계형 DB를 사용하는 모든 프로젝트에 스프링 데이터 JPA와 QueryDSL 두 기술을 주로 사용한다.
📓 환경설정
Gradle Project
Spring Web
Spring Data JPA
H2 Database
Lombok
◎실행 설정
preference -> Gradle 에서 intellij 로 설정
◎Lombok 설정
preference -> Plugins -> Lombok 설치
annotation processors -> Enable annotation processing 체크
참고 : 실행되는 JPQL을 보고싶다면 yml에 use_sql_comments: true 설정
JPQL 실행했다는 주석이 나감
📓 QueryDSL 설정
build.gradle 설정
buildscript {
ext {
queryDslVersion = "5.0.0"
}
}
plugins {
id 'org.springframework.boot' version '2.7.3'
id 'io.spring.dependency-management' version '1.0.13.RELEASE'
//querydsl 설정 추가
id "com.ewerk.gradle.plugins.querydsl" version "1.0.10"
id 'java'
}
group = 'study'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.8.0'
implementation 'org.projectlombok:lombok:1.18.24'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
//querydsl 추가
implementation "com.querydsl:querydsl-jpa:${queryDslVersion}"
implementation "com.querydsl:querydsl-apt:${queryDslVersion}"
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
test {
useJUnitPlatform()
}
//querydsl 추가 시작
def querydslDir = "$buildDir/generated/querydsl"
querydsl {
jpa = true
querydslSourcesDir = querydslDir
}
sourceSets {
main.java.srcDir querydslDir
}
compileQuerydsl{
options.annotationProcessorPath = configurations.querydsl
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
querydsl.extendsFrom compileClasspath
}
//querydsl 추가 끝설정하고 나서 오른쪽 Gradle에 Tasks -> other -> compileQuerydsl 더블 클릭해서 실행.
그러면 build 폴더 -> generated -> ... -> QHello 생성됨.
QueryDsl 되는지 테스트 해봄
@SpringBootTest
@Transactional
@Commit //안 해주면 롤백이 되어 H2에 데이터가 보이지 않는다.
class QuerydslApplicationTests {
@Autowired
EntityManager em;
@Test
void contextLoads() {
Hello hello = new Hello();
em.persist(hello);
JPAQueryFactory query = new JPAQueryFactory(em);
//QHello qHello = new QHello("h");
//QHello에 public static final QHello hello = new QHello("hello"); 이게 있음
QHello qHello = QHello.hello; //QHello에 만들어 놓은 것이 있기 때문에 가능.
Hello result = query
.selectFrom(qHello) //query와 관련된 것은 q타입을 넣어야 함.
.fetchOne(); //querydsl 사용함.
assertThat(result).isEqualTo(hello);
//같은 이유?
//
assertThat(result.getId()).isEqualTo(hello.getId());
}
}공부할 때는 H2 DB에서 보도록 하지만 실제로 자동화된 테스트에서는 메모리에서 돌리도록 한다. (테이블이 남으면 안 되기 때문에.)
📓 JPQL, QueryDsl 비교
@SpringBootTest
@Transactional
public class QuerydslBasicTest {
@Autowired
EntityManager em;
JPAQueryFactory queryFactory; //동시성 문제가 없다.
//각 테스트 실행 전에 데이터를 미리 세팅.
@BeforeEach
public void before() {
queryFactory = new JPAQueryFactory(em); //동시성 문제도 걱정 없음.
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
em.persist(teamA);
em.persist(teamB);
Member member1 = new Member("member1", 10, teamA);
Member member2 = new Member("member2", 20, teamA);
Member member3 = new Member("member3", 30, teamB);
Member member4 = new Member("member4", 40, teamB);
em.persist(member1);
em.persist(member2);
em.persist(member3);
em.persist(member4);
}
@Test //JPQL로 member1을 찾음.
public void startJPQL() {
String jpql = "select m from Member m " +
"where m.username = :username";
//member1을 찾아라.
Member findMember = em.createQuery(jpql, Member.class)
.setParameter("username", "member1")
.getSingleResult();
assertThat(findMember.getUsername()).isEqualTo("member1");
}
@Test //QueryDsl로 member1을 찾음.
public void startQueryDsl() {
//QueryDsl은 JPAQueryFactory() 로 시작을 해야 한다.
//필드로 가져가는 것이 더 코드를 줄일 수 있다.
//JPAQueryFactory queryFactory = new JPAQueryFactory(em);
QMember m = new QMember("m");
Member findMember = queryFactory
.select(m)
.from(m)
.where(m.username.eq("member1"))
.fetchOne(); // 단건 조회.
assertThat(findMember.getUsername()).isEqualTo("member1");
}
}@BeforeEach : 각 테스트 실행 전에 데이터를 미리 세팅
eq는 equal로 == 이다
✪ JPQL과 QueryDsl 차이
JPQL은 오류가 발생했다는 것을 실행되는 중에 메소드를 호출할 때 발견한다. 그래서 런타임오류가 발생한다.(최악 오류) 그런데 QueryDSL은 컴파일 타입에 바로 오류가 잡힌다. (QMember처럼 Q타입을 만든 이유이다.)
그리고 파라미터 바인딩을 자동으로 해결해준다.
JPAQueryFactory 필드로 ➪ 스프링이 주입해주는 EntityManager 자체가 멀티쓰레드에 아무 문제 없도록 설계가 되어 있다. 여러 멀티쓰레드가 들어와도 현재 트랜잭션이 어디에 걸려있는지에 따라서 트랜잭션이 바인딩 되도록 분배해준다. 그래서 동시성 문제가 없다.
📓 Q-Type 활용 (권장)
@Test //QueryDsl로 member1을 찾음.
public void startQueryDsl() {
//QueryDsl은 JPAQueryFactory() 로 시작을 해야 한다.
//필드로 가져가는 것이 더 코드를 줄일 수 있다.
//JPAQueryFactory queryFactory = new JPAQueryFactory(em);
//QMember m = QMember.member;
//QMember m1 = new QMember("m1"); 하면 member1에서 m1으로 바뀜.
Member findMember = queryFactory
.select(member) //static import 사용.
.from(member)
.where(member.username.eq("member1"))
.fetchOne(); // 단건 조회.
assertThat(findMember.getUsername()).isEqualTo("member1");
}아까 이 부분에서 static import 사용하여 더 깔끔하게 사용 가능하다.
간혹 같은 테이블을 조인해야 하는 경우 이름이 같으면 안 되기 때문에 member1에서 m1으로 바꾼다.
📓 검색 조건 쿼리
//검색 조건 쿼리
@Test
public void search() {
Member findMember = queryFactory
.selectFrom(member)
.where(member.username.eq("member1")
.and(member.age.eq(10)))
.fetchOne();
assertThat(findMember.getUsername()).isEqualTo("member1");
}and나 or로 검색 조건을 추가 가능. 그리고 and를 그냥 ,로 해도 됨.
결과
select
member0_.member_id as member_i1_1_,
member0_.age as age2_1_,
member0_.team_id as team_id4_1_,
member0_.username as username3_1_
from
member member0_
where
member0_.username=?
and member0_.age=?✪ JPQL이 제공하는 모든 검색 조건
x.eq() : x와 같은지.
x.ne() : x와 다른지. (eq().not() 도 가능.)
x.isNotNull() : x가 is not null.
x.in(10, 20) : x가 10이나 20.
x.notIn(10, 20) : x가 10이나 20이 아님.
x.between(10, 30) : x가 10 ~ 30 사이.
x.goe(30) : x >= 30.
x.gt(30) : x > 30.
x.loe(30) : x <= 30.
x.lt(30) : x < 30.
x.like("member%") : like 검색. (% 필수.)
x.contains("member") : like인데 양쪼겡 %가 들어간 효과.
x.startsWith("member") : like인데 뒤에 %가 들어간 효과. (처음이 member로 시작하는지)
where 조건 넣는 부분에 null 이 들어가면 null을 무시해서 동적 쿼리 만들 때 코드 깔끔하게 작성 가능. (밑에 있음.)
fetch() : 리스트 조회, 데이터 없으면 빈 리스트 반환
fetchOne() : 단건 조회
◎결과가 없으면 null
◎결과가 둘 이상이면 NonUniqueResultException 발생
fetchFirst() : limit(1) 을 걸면서 fetchOne() 실행
fetchResults() : 페이징 쿼리 날림. 따라서 total count 쿼리도 추가 실행
fetchCount() : count 쿼리로 변경해서 count 수만 조회.
📓 결과 조회
@Test
public void resultFetch() {
//Member의 목록을 리스트로 조회
List<Member> fetch = queryFactory
.selectFrom(member)
.fetch();
Member fetchOne = queryFactory
.selectFrom(member)
.fetchOne();
Member first = queryFactory
.selectFrom(member)
.fetchFirst(); //limit(1) 에 fetchOne() 과 같다.
QueryResults<Member> results = queryFactory
.selectFrom(member)
.fetchResults();
results.getTotal();
List<Member> content = results.getResults();
long total = queryFactory
.selectFrom(member)
.fetchCount();
}fetch() : 리스트로 결과를 반환하는 방법, 결과가 없다면 빈 리스트 반환
fetchOne() : 단건을 조회할 때 사용하고 결과가 없다면 null 반환하고 결과가 둘 이상이면 NonUniqueResultException
fetchFirst() : 처음의 한 건을 가져오고 싶을 때 사용
fetchResults() : 페이징을 위해 사용하고 total contents를 가져온다.
fetchCount() : count 쿼리를 날릴 수 있다.
📓 정렬
/**
* 회원 정렬 순서
* 1. 회원 나이 내림차순(desc)
* 2. 회원 이름 올림차순(asc)
* 단 2에서 회원 이름이 없으면 마지막에 출력
*/
@Test
public void sort() {
em.persist(new Member(null, 100));
em.persist(new Member("member5", 100));
em.persist(new Member("member6", 100));
List<Member> result = queryFactory
.selectFrom(member)
.where(member.age.eq(100)) //100살인 사람 찾음.
.orderBy(member.age.desc(), member.username.asc().nullsLast()) //이름이 없을 경우 마지막에 위치하도록 함.
//nullsFirst()도 있다.
.fetch();
Member member5 = result.get(0);
Member member6 = result.get(1);
Member memberNull = result.get(2); //null은 마지막에 위치.
assertThat(member5.getUsername()).isEqualTo("member5");
assertThat(member6.getUsername()).isEqualTo("member6");
assertThat(memberNull.getUsername()).isNull();
}📓 페이징
@Test
public void paging1() {
List<Member> result = queryFactory
.selectFrom(member)
.orderBy(member.username.desc()) //페이징 에서는 orderBy() 넣어야 잘 작동하는지 알 수 있다.
.offset(1) //0부터 시작으로 하나를 스킵한다.
.limit(2)
.fetch()
//그러므로 0,1,2 하고 하나 스킵해서 result의 크기는 2가 된다.
assertThat(result.size()).isEqualTo(2);
}
//페이징을 위해 사용하고 total contents를 가져온다.
@Test
public void paging2() {
QueryResults<Member> queryResults = queryFactory
.selectFrom(member)
.orderBy(member.username.desc()) //페이징 에서는 orderBy() 넣어야 잘 작동하는지 알 수 있다.
.offset(1) //앞에 몇 개를 스킵할 건지 (0부터 시작임.)
.limit(2)
//전체 조회가 필요하다면
.fetchResults();
assertThat(queryResults.getTotal()).isEqualTo(4);
//member1,2,3,4
assertThat(queryResults.getLimit()).isEqualTo(2);
//limit 2
assertThat(queryResults.getOffset()).isEqualTo(1);
//offset 1
assertThat(queryResults.getResults().size()).isEqualTo(2);
//content(조회된 데이터) 2개 -> offset 1 에 limit 2 이므로 2개
}실무에서는 countQuery는 따로 분리해서 작성해야 할 때도 있다. 페이징 쿼리가 단순하면 그냥 사용해도 되지만 contents 쿼리가 복잡하고 count 쿼리가 단순하다면 쿼리를 따로 작성하는 것이 좋다. 만약 where 해서 제약조건이 붙으면 contents 쿼리와 count 쿼리에 조인이 다 붙어서 성능이 좋지 않는 경우가 있다.
paging2() 에서는 쿼리가 2개가 날라간다. -> count 쿼리 나가고 그 다음에 contents 쿼리가 나간다.
/* select
count(member1)
from
Member member1 */ select
count(member0_.member_id) as col_0_0_
from
member member0_
/* select
member1
from
Member member1
order by
member1.username desc */ select
member0_.member_id as member_i1_1_,
member0_.age as age2_1_,
member0_.team_id as team_id4_1_,
member0_.username as username3_1_
from
member member0_
order by
member0_.username desc limit ? offset ?📓 집합
Tuple 을 사용하는 이유는 select에서 데이터 타입이 여러 개 나오기 때문에 사용한 것이다.
// 집합
@Test
public void aggregation() {
List<Tuple> result = queryFactory
.select(
member.count(),
member.age.sum(),
member.age.avg(),
member.age.max(),
member.age.min()
)
.from(member)
.fetch();
//QueryDsl이 제공하는 Tuple이다.
Tuple tuple = result.get(0);
assertThat(tuple.get(member.count())).isEqualTo(4);
assertThat(tuple.get(member.age.sum())).isEqualTo(100);
assertThat(tuple.get(member.age.avg())).isEqualTo(25);
assertThat(tuple.get(member.age.max())).isEqualTo(40);
assertThat(tuple.get(member.age.min())).isEqualTo(10);
}실무에서는 Tuple보다는 DTO로 직접 뽑아오는 방법을 주로 사용
📓 groupBy
/**
* 팀의 이름과 각 팀의 평균 연령을 구하기
*/
//groupBy
@Test
public void group() throws Exception {
List<Tuple> result = queryFactory
.select(team.name, member.age.avg())
.from(member)
.join(member.team, team) //멤버에 있는 team과 team을 조인해줌.
.groupBy(team.name) //team 이름으로 그룹을 넣음.
.fetch();
Tuple teamA = result.get(0);
Tuple teamB = result.get(1);
//teamA (member1,2) -> (10 + 20) / 2
assertThat(teamA.get(team.name)).isEqualTo("teamB");
assertThat(teamA.get(member.age.avg())).isEqualTo(15);
//teamB (member3,4) -> (30 + 40) / 2
assertThat(teamB.get(team.name)).isEqualTo("teamB");
assertThat(teamB.get(member.age.avg())).isEqualTo(35);
}유형별로 갯수를 가져오고 싶은데 COUNT 를 사용하여 데이터를 조회하면 전체 갯수만을 가져오니 컬럼에 데이터를 그룹화할 수 있는 GROUP BY를 사용.
특정 컬럼을 그룹화하고 그룹화한 결과에 HAVING을 사용해서 조건을 걸 수 있다.
📓 기본 조인
기본 문법 : 첫 번째 파라미터에 조인 대상을 지정하고, 두 번째 파라미터에 별칭으로 상ㅇ할 Q 타입을 지정해준다.
◎팀 A에 소속된 모든 회원 조회
@Test
public void join() {
List<Member> result = queryFactory
.selectFrom(member)
.join(member.team, team) //team은 Qmember.team이다.
.where(team.name.eq("teamA"))
.fetch();
assertThat(result)
.extracting("username")
.containsExactly("member1", "member2");
}.extracting("") : 검증하고자 하는 값이 특정 객체에 속해있는지 확인.
.containsExactly("", "") : 순서와 값이 맞는지 확인.
.containsExactly() 사용할 때 import static org.assertj.core.api.Assertions.*; 필요
📓 세타 조인 (내부 조인)
연관관계 없이도 조인이 가능하다.
/**
* 회원의 이름이 팀 이름과 같은 회원을 조회.
*/
@Test
public void theta_join() {
em.persist(new Member("teamA"));
em.persist(new Member("teamB"));
em.persist(new Member("teamC"));
//모든 멤버 가져오고 모든 팀 가져와서 다 조인을 하는 것이다.
//그 다음에 where 에서 조건 제약.
List<Member> result = queryFactory
.select(member)
.from(member, team)
.where(member.username.eq(team.name))
.fetch();
assertThat(result)
.extracting("username")
.containsExactly("teamA", "teamB");
}모든 멤버 가져오고 모든 팀 가져와서 다 조인을 하는 것이다. 그 다음에 where 에서 조건 제약.
☪ from 절에 여러 엔티티를 선택해서 세타 조인한다.
☪ 외부 조인 (left outer, right outer) 이 불가능한다. 조인 on을 사용하면 외부 조인이 가능.
📓 외부 조인 - ON절
- 조인 대상 필터링
- 연관관계 없는 엔티티 외부 조인 -> 연관관계가 없어도 조인을 할 수 있다.
◎회원과 팀을 조인하는데 팀 이름이 teamA인 팀만 조인.
◎회원은 모두 조회.
/**
* 회원과 팀을 조인하면서, 팀 이름이 teamA인 팀만 조인, 회원은 모두 조회.
*/
//on절
@Test
public void join_on_filtering() {
List<Tuple> result = queryFactory
.select(member, team)
.from(member)
.leftJoin(member.team, team)
.on(team.name.eq("teamA"))
.fetch();
for (Tuple tuple : result) {
System.out.println("tuple = " + tuple);
}
}외부 조인이 아닌 내부 조인이면 .on(
~) 과 .where(~) 의 결과는 같다.
외부에서 가져올 데이터가 없기 때문이다. 이 때는 익숙한 where절을 쓰는 것이 편하다.
하지만 외부 조인이면 반드시 on절로.
📓 연관 관계 없는 엔티티 외부 조인
회원의 이름이 팀 이름과 같은 대상 외부 조인.
@Test
public void join_on_no_relation() {
em.persist(new Member("teamA"));
em.persist(new Member("teamB"));
em.persist(new Member("teamC"));
//모든 멤버 가져오고 모든 팀 가져와서 다 조인을 하는 것이다.
//그 다음에 where 에서 조건 제약.
List<Tuple> result = queryFactory
.select(member, team)
.from(member)
.leftJoin(team)
.on(member.username.eq(team.name))
.fetch();
for (Tuple tuple : result) {
System.out.println("tuple = " + tuple);
}
}보통은 .leftJoin(member.team, team)이지만 .leftJoin(team)으로 문법이 다르다.
on절에 id값이 들어가게 되어 join하는 대상이 id로 매칭을 하게 되지 않고 이름으로만 매칭을 하게 된다.
.leftJoin(team) 결과
left outer join
team team1_
on (
member0_.username=team1_.name
//이름으로만 매칭
).leftJoin(member.team, team) 결과
left outer join
team team1_
on member0_.team_id=team1_.id //id로 매칭
and (
member0_.username=team1_.name
)📓 페치 조인
SQL 조인을 활용해서 연관된 엔티티를 SQL 한 번에 조회하는 기능. (성능 최적화에서 자주 사용.)
페치 조인 테스트할 때는 영속성 컨텍스트에 남아있는 데이터를 지워주지 않으면 결과를 제대로 보기 어려워 영속성 컨텍스트에 있는 것을 DB에 반영하고 영속성 날려주고 시작해야 한다.
.fetchJoin() : member를 조회할 때 연관된 team을 한 번에 끌고온다. -> queryFactory에서 .fetchJoin()만 추가해주면 끝.
//페치 조인 적용
@Test
public void fetchJoinUse() {
em.flush();
em.clear();
Member findMember = queryFactory
.selectFrom(member)
.join(member.team, team)
.fetchJoin()
.where(member.username.eq("member1"))
.fetchOne();
//Member 클래스의 team이 LAZY이기 때문에 DB에서 조회할 때는
//member만 조회가 되고 team은 조회가 되지 않는다.
//isLoaded() : 이미 로딩(초기화)된 엔티티인지 아니면 초기화가 안된 엔티티인지 확인해주는 함수.
boolean loaded = emf.getPersistenceUnitUtil().isLoaded(findMember.getTeam());
assertThat(loaded).as("페치 조인 미적용").isTrue();
}📓 서브 쿼리
나이가 가장 많은 회원을 조회
//엔티티 이름이 중복될 경우 별칭을 따로 줘야 한다.
QMember memberSub = new QMember("memberSub");
List<Member> result = queryFactory
.selectFrom(member)
.where(member.age.eq(
JPAExpressions
.select(memberSub.age.max())
.from(memberSub)
))
.fetch();
assertThat(result).extracting("age")
.containsExactly(40);나이가 평균 이상인 회원
""
.where(member.age.goe(
JPAExpressions
.select(memberSub.age.avg())
.from(memberSub)
))where 절 말고 select 절에도 in 사용 가능
~~~
.select(member.username,
JPAExpressions
.select(memberSub.age.avg())
.from(memberSub))in 연산자는 where(memberSub.age.in(JPAExpressions.select~~)) 이런식으로
JPAExpressions는 static import 가능!!!!
JPA 서브쿼리는 from 절에서 서브쿼리를 만들지 못한다. select 절이나 where 절에서는 가능하지만 from은 불가능하다. 당연히 QueryDSL 도 지원하지 않는다.
하이버네이트 구현체를 사용하면 사용하면 select절의 서브 쿼리는 지원한다.
Querydsl도 하이버네이트 구현체를 사용하면 select절의 서브쿼리를 지원한다.
☪ from 절의 서브쿼리 해결 방안
◎ 서브쿼리를 join으로 변경한다. (가능할 때도 있고 불가능할 때도 있다.)
◎ 애플리케이션에서 쿼리를 2번 분리해서 실행한다. (상황에 따라 다름)
◎ nativeSQL 사용 (JPA 한계로 어쩔 수 없이 사용.) -> 위 2개 먼저 시도
📓 CASE 문
select 절에 when 으로 case 를 줄 수 있다.
마지막에는 자바 default 처럼 otherwise()를 쓴다.
데이터를 줄이는 일로만 사용하고 실제로 예제처럼 전환하고 바꾸고 보여주는 식은 DB에서 사용하지 않는다.
// Case 단순한 조건
@Test
public void basicCase() {
List<String> result = queryFactory
.select(member.age
.when(10).then("열살")
.when(20).then("스무살")
.otherwise("기타"))
.from(member)
.fetch();
//10살이면 열살 출력, 스무살이면 20살 출력.
for (String s : result) {
System.out.println("s = " + s);
}
}
// Case 복잡한 조건 -> CaseBuilder 사용
@Test
public void complexCase() {
List<String> result = queryFactory
.select(new CaseBuilder()
.when(member.age.between(0, 20)).then("청소년")
.when(member.age.between(21, 40)).then("성인")
.otherwise("기타"))
.from(member)
.fetch();
for (String s : result) {
System.out.println("s = " + s);
}
}from 절을 쓰지 않는 경우 No sources given 이라는 에러가 발생한다.
📓 상수, 문자 더하기
그냥 문자만 가져올려면 Expressions.constant("") 사용
List<Tuple> result = queryFactory
.select(member.username, Expressions.constant("A1234"))
.from(member)
.fetch();결과
tuple = [member1, A1234]
tuple = [member2, A1234]
tuple = [member3, A1234]
tuple = [member4, A1234]
문자를 더하고 싶다면
List<String> fetch = queryFactory
.select(member.username.concat("_").concat(member.age.stringValue()))
.from(member)
.where(member.username.eq("member1"))
.fetch();결과
s = member1_10
member.age.stringValue() 부분이 중요!!! 문자가 아닌 다른 타입들은 stringValue()로 문자로 변환할 수 있다. ENUM을 처리할 때도 자주 사용하니 기억!!!
📓 프로젝션과 결과 반환
프로젝션 : select 절에 대상으로 뭘 가져올지 지정하는 것
프로젝션 하나.
List<String> result = queryFactory
.select(member.username)
.from(member)
.fetch();프로젝션 대상이 하나면 그 대상의 타입에 맞춰서 하면 되지만 대상이 2개 이상일 경우 Tuple을 사용한다.
//프로젝션 대상이 여러 개
@Test
public void tupleProjection() {
List<Tuple> result = queryFactory
.select(member.username, member.age)
.from(member)
.fetch();
for (Tuple tuple : result) {
String username = tuple.get(member.username);
Integer age = tuple.get(member.age);
System.out.println("username = " + username);
System.out.println("age = " + age);
}
}참고: 튜플은 패키지가 com.querydsl.core 이다. 튜플을 리포지토리 계층 안에서 사용하는 것은 괜찮은데 넘어서서 서비스 계층이나 컨트롤러까지 가는 것은 좋은 설계가 아니다. (하부 구현 기술인 JPA나 QueryDSL을 쓴다는 것을 핵심 비즈니스 로직이나 서비스 쪽이 알면 좋지 않듯이)
그래서 바깥 계층으로 던지는 것은 DTO로 바꿔서 반환하는 것을 권장. 튜플도 querydsl의 종속적인 타입이기 때문에 튜플은 리포지토리 안에서만 사용.
📓 프로젝션과 결과 반환을 DTO로 조회한다. (중요)
DTO는 따로 클래스를 생성해야 한다는 점 기억!!!!
엔티티를 조회하면 id, username, age 다 불러와야 하기 때문에 쿼리할 때 딱 정한 것만 가져오고 싶은 것.
JPQL은 DTO로 반환할 때 타입을 맞춰야 하기 때문에 new study.querydsl.dto.MemberDto(m.username, m.age) 를 써야한다.
List<MemberDto> resultList = em.createQuery("select new study.querydsl.dto.MemberDto(m.username, m.age)
from Member m", MemberDto.class)
.getResultList();그래서 순수 JPA에서 DTO를 조회할 때는 new 명령어 사용하고 DTO의 package 이름을 다 적어줘야 하기 때문에 지저분한다.
또한 생성자 방식만 지원한다. (생성자가 반드시 필요함.)
- setter 이용하거나 필드에 바로 값을 주입해주는 것이 불가능하다.
☪ Querydsl은 위 문제를 다 극복하여 Dto로 조회한다.
- 프로퍼티(Setter) 접근 (기본 생성자 필수.)
- 필드 직접 접근 (기본 생성자 필수.)
- 생성자 사용
☪ 프로퍼티(Setter) 접근 (Projections.bean 사용)
bean은 getter, setter할 때 빈으로 setter로 injection 해줌.
기본 생성자 필수.
List<MemberDto> result = queryFactory
.select(Projections.bean(MemberDto.class,
member.username,
member.age))
.from(member)
.fetch();
NoSuchMethodException : ~~~ MemberDto라는 에러가 발생
바로 밑에at java.lang.Class.getConstructor0라고 써 있음.
기본 생성자가 없어서 발생한 문제다.
Querydsl이 MemberDto를 만든 다음에 값을 set 하고 기본 생성자를 호출해야 하는데 기본 생성자가 없어서 에러가 발생한 것.
☪ 필드 직접 접근
(Projections.fields) 로만 바꾸면 된다.
getter, setter 무시하고 바로 필드에 꽂아버림.
기본 생성자 필수.
☪ 생성자 접근
Projections.constructor
public void findDtoByConstructor(){
List<MemberDto> result = queryFactory
.select(Projections.constructor(MemberDto.class,
member.username,
member.age))
.from(member)
.fetch();
for(MemberDto memberDto : result){
System.out.println("memberDto = " + memberDto);
}
}◎UserDto 사용.
필드 직접 접근 - 임의로 MemberDto가 아닌 UserDto로 접근
List<UserDto> result = queryFactory
.select(Projections.fields(UserDto.class,
member.username,
//member.username.as("name")
member.age))
.from(member)
.fetch();필드를 하기 때문에 필드 명이 맞아야 들어가기 때문에 매칭이 되지 않아서 테스트 실행에는 문제가 없지만 UserDto 출력 시 name에 null이 들어간다.
UserDto는 username이 아닌 name으로 필드를 만들었다. (MemberDto에는 필드로 username이라는 이름이 있음.)
필드명이 MemberDto에는 username이지만 UserDto는 그냥 name 이기 때문에 매칭이 되지 않기 때문이다. 그럴 때는 as로 별칭을 따로 준다.
따라서 member.username.as("name") 으로 해준다.
서브쿼리에서도 매칭이 되도록 설정 가능
//서브쿼리에서도 UserDto 매칭이 되도록 설정 가능
@Test
public void findUserDtoSubQuery() {
QMember memberSub = new QMember("memberSub");
queryFactory
.select(Projections.fields(UserDto.class,
member.username.as("name"),
//서브쿼리.
ExpressionUtils.as(JPAExpressions
.select(memberSub.age.max())
.from(memberSub), "age") // age가 alias다
))
.from(member)
.fetch();
}ExpressionUtils로 감싸면 두 번째 파라미터로 alias를 줄 수 있다. (매칭)
- 서브쿼리는 어쩔 수 없이
ExpressionUtils로 감싸서 쿼리를 날리는 수밖에 없다. projections.constructor의 경우에는 이름이 아닌 타입을 보고 가기 때문에 문제없다.- DTO에 생성자만 잘 만들어주면 됨.
📓 프로젝션과 결과 반환 - @QueryProjection
Dto 클래스의 생성자에 @QueryProjection 하고 compileQuerydsl 해주면 generated 에 QMemberDto가 생성이 된다.
List<MemberDto> result = queryFactory
.select(new QMemberDto(member.username, member.age))
.from(member)
.fetch();장점은 다른 값이 추가로 들어오게 되면 컴파일 전에 에러가 발생(컴파일 오류)해서 빠르게 확인 가능하다.
단점으로는 @QueryProjection 을 넣어줘서 new QMemberDto를 생성해야한다는 점과 Dto 자체가 querydsl의 의존성을 가지게 된다는 점이다.
📓 동적 쿼리를 해결하는 2가지 방식
- BooleanBuilder 사용
- Where 다중 파라미터 사용
동적 쿼리 : 상황에 따라 다른 문법의 SQL을 적용하는 것. (쿼리문이 변하면 동적, 변하지 않으면 정적.)
ex) 어떤 조건에 대하여 조회하는 대상이 고정되어 있지 않고 파라미터를 통해 그 대상들을 상황에 맞게 조회.
☪ BooleanBuilder 사용
//동적 쿼리 - BooleanBuilder 사용
@Test
public void dynamicQuery_BooleanBuilder() {
String usernameParam = "member1";
Integer ageParam = 10;
List<Member> result = searchMember1(usernameParam, ageParam);
assertThat(result.size()).isEqualTo(1);
}
private List<Member> searchMember1(String usernameParam, Integer ageParam) {
//파라미터 값이 null인지 아닌지에 따라서 쿼리가 동적으로 바뀌어야 한다.
// ex) ageParam이 null이면 이름이 "member1"인 멤버만 조회.
BooleanBuilder builder = new BooleanBuilder();
if (usernameParam != null) {
builder.and(member.username.eq(usernameParam));
}//builder에는 and나 or 조건을 넣어줄 수 있다.
if (ageParam != null) {
builder.and(member.age.eq(ageParam));
}
return queryFactory
.selectFrom(member)
.where(builder)
.fetch();
}☪ Where 다중 파라미터 사용 (실무에서 자주 사용, 깔끔하게 작성 가능, BooleanBuilder보다 좋음.)
where 문에서 바로 해결
//동적 쿼리 - where 사용
@Test
public void dynamicQuery_WhereParam() {
String usernameParam = "member1";
Integer ageParam = 10;
List<Member> result = searchMember2(usernameParam, ageParam);
assertThat(result.size()).isEqualTo(1);
}
private List<Member> searchMember2(String usernameParam, Integer ageParam) {
return queryFactory
.selectFrom(member)
.where(usernameEq(usernameParam), ageEq(ageParam))
.fetch();
}
// null 처리 꼭 해줘야 함.
private BooleanExpression usernameEq(String usernameParam) {
// usernameParam이 null이라면 where절에 usernameEq(usernameParam) 이게 null이 된다.
// 하지만 where(null, ageEq()) 가 되면서 null로 무시가 된다. (and 조건으로 되지 않음.) 이렇게 동적 쿼리가 만들어진다.
return usernameParam == null ? null : member.username.eq(usernameParam);
}
private BooleanExpression ageEq(Integer ageParam) {
return ageParam == null ? null : member.age.eq(ageParam);
}결과
select
member1
from
Member member1
where
member1.username = ?1age를 null로 설정했으면 username만 파라미터 바인딩하고 age는 null.
장점 : 조합이 되어 재사용할 수 있다는 장점도 있다.
예제에서 usernameEq(), ageEq(), allEq() 메서드처럼 만든 메서드를 .where에 조립하여 사용할 수 있다.
📓 수정, 삭제 벌크 연산(배치 쿼리)
쿼리 한 번으로 대량 데이터 수정할 때 사용
long count = queryFactory
.update(member)
.set(member.username, "비회원")
.where(member.age.lt(28)) //회원이 28살 미만이면
.execute();update 할 때는 .fetch() 가 아닌 .execute()로 실행.
주의할 점은 count 쿼리를 실행하면 영속성 컨텍스트 무시하고 DB에 바로 쿼리를 날린다. 그래서 DB와 영속성 컨텍스트의 상태가 달라져버린다.
영속성 컨텍스트 상태
member1
member2
member3
member4
DB상태
비회원
비회원
member3
member4
JPA는 기본적으로 DB에서 가져온 결과를 영속성 컨텍스트에 다시 넣어줘야 한다.
JPA는 DB에서 select 해왔어도 영속성 컨텍스트에 있으면 DB에서 가져온 것을 버린다. (영속성 컨텍스트가 우선권을 가짐.)
그래서 member1,2 로 유지가 된다.
해결 방법은 em.flush(); em.clear(); (영속성 컨텍스트 초기화해서 날려버림)
◎벌크 수정 사칙연산
더하기를 하고 싶다면 .set(member.age, member.age.add(1))
빼고 싶다면 그냥 -1 처럼 음수로
곱하기는 multiply
나누기는 divide
◎벌크 삭제는 delete 사용
long count = queryFactory
.delete(member)
.where(member.age.gt(10))
.execute();📓 SQL function 호출
JPA와 같이 Dialect에 등록된 내용만 호출
◎replace
List<String> result = queryFactory
.select(Expressions.stringTemplate(
"function('replace', {0},{1},{2})",
member.username, "member", "M"))
//username에서 member 라는 단어를 M으로 바꿔서 조회.
.from(member)
.fetch();결과 (JPQL 임)
select
replace(member0_.username,
?,
?) as col_0_0_
from
member member0_s = M1
s = M2
s = M3
s = M4 로 replace 됨.
◎lower - 소문자로 바꿈.
List<String> result = queryFactory
.select(member.username)
.from(member)
// .where(member.username.eq(
// Expressions.stringTemplate(
// "function('lower', {0})",
// member.username)))
.where(member.username.eq(member.username.lower()))
.fetch();결과
select
member1.username
from
Member member1
where
member1.username = lower(member1.username)일반적인 DB에서 사용하는 것들(lower, gt같은 거)은 Query DSL이 어느 정도 내장하고 있다.
📓 queryFactory 생성자 만드는 2가지 방법
☪ 1. em만 파라미터 받고 queryFactory해서 new 해줘도 됨.
public MemberJpaRepository(EntityManager em) {
this.em = em;
this.queryFactory = new JPAQueryFactory(em);
//querydsl 쓰려면 JPAQueryFactory 필요
}하나만 주입받아도 돼서 테스트 코드 작성 시 괜찮음
- 스프링 빈으로 등록
Application 클래스 가서
@Bean
JPAQueryFactory jpaQueryFactory(EntityManager em){
return new JPAQueryFactory(em);
}그리고 평소처럼 생성자 생성.
@RequiredArgsConstructor 써서 생성자 생략 가능
JPAFactoryFactory를 외부에서 주입받아야 해서 테스트 코드 작성 시 좀 귀찮음.
동시성 문제
ex) this.queryFactory = new JPAQueryFactory(em);
싱글톤인데 같은 객체를 모두 멀티쓰레드에서 다 써도 문제가 없다.
JPAQueryFactory 에 대한 동시성 문제는 EntityManager에 다 의존한다.
EntityManager를 스프링에서 쓰면 동시성 문제와 전혀 관계없이 트랜잭션 단위로 다 따로따로 분리해서 동작하게 된다.
스프링에서는 진짜 영속성 컨텍스트 EntityManager가 아니라 Proxy를 주입해서 트랜잭션 단위로 분리해서 바운딩되도록 해준다.
📓 동적 쿼리 해결 + DTO로 성능 최적화해서 한 번에 조회 - Builder 사용
리포지토리에서 동적 쿼리를 어떻게 해결하는지, 한 번에 DTO로 조회하는 성능 최적화 조회를 해보자.
멤버의 정보와 팀의 정보를 한 번에 섞어서 닥 원하는 데이터만 찍어서 가져오기 위해 DTO를 생성.
MemberTeamDto 생성.
public class memberTeamDto{
private Long memberId;
private String username;
private int age;
private Long teamId;
private String teamName;
@QueryProjection
public MemberTeamDto(){
~~
}
}public class MemberSearchCondition{
private String username;
private String teamName;
private Integer ageGoe;
private Integer ageLoe;
}public List<MemberTeamDto> searchByBuilder(MemberSearchCondition condition) {
//빌더 만듦.
BooleanBuilder builder = new BooleanBuilder();
//username이 null이거나 "" 이 들어올 수 있다.
//null은 상관없지만 ""가 문제되므로 StringUtils.hasText를 사용한다.
if (hasText(condition.getUsername())) {
builder.and(member.username.eq(condition.getUsername()));
}
if (hasText(condition.getTeamName())) {
builder.and(team.name.eq(condition.getTeamName()));
}
if (condition.getAgeGoe() != null) {
builder.and(member.age.goe(condition.getAgeGoe()));
}
if (condition.getAgeLoe() != null) {
builder.and(member.age.loe(condition.getAgeLoe()));
}
return queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.from(member)
.leftJoin(member.team, team)
.where(builder)
.fetch();
}주의 : 조건이 없으면 쿼리로 데이터를 다 끌고와서 운영할 때 난감한 일이 벌어진다. 따라서 test할 때 조건을 주거나 limit로 페이지 쿼리를 해주는 것이 좋다.
📓 동적, 성능 최적, where절 파라미터 사용
//동적, 성능 최적, where절 파라미터 사용
public List<MemberTeamDto> search(MemberSearchCondition condition) {
return queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.fetch();
}
private BooleanExpression usernameEq(String username) {
return hasText(username) ? member.username.eq(username) : null;
//반대로는
//return isEmpty(username) ? null : member.username.eq(username);
}
private BooleanExpression teamNameEq(String teamName) {
return hasText(teamName) ? team.name.eq(teamName) : null;
}
private BooleanExpression ageGoe(Integer ageGoe) {
return ageGoe != null ? member.age.goe(ageGoe) : null;
}
private BooleanExpression ageLoe(Integer ageLoe) {
return ageLoe != null ? member.age.loe(ageLoe) : null;
}만들어 놓은 메서드들을 재사용할 수 있다는 점이 매우 큰 장점이다. 또한 한 번에 where 파라미터에서 어떤 조건을 사용했는지 볼 수 있어 편리하다.
📓 조회 API 컨트롤러 개발
🔦 편리한 데이터 확인을 위해 샘플 데이터 추가
🔦 샘플 데이터 추가가 테스트 케이스 실행에 영향을 주지 않도록 프로파일 설정
스프링이 올라올 때 자동으로 샘플 데이터를 넣고 API를 호출해서 데이터만 보기
프로파일을 나눠서 테스트에 영향이 없도록 한다. 그러면 테스트를 실행할 때랑 로컬에서 스프링 부트를 가지고 톰캣을 띄울 때랑 2가지를 다른 상황으로 프로파일을 돌린다.
톰캣으로 돌리면 샘플 데이터 추가하는 로직이 동작하게 되고 테스트 케이스를 돌릴 땐 샘플 데이터를 넣는 로직이 동작하지 않게 한다.
왜냐면 테스트는 DB에 맞춰서 세트를 맞춰놨는데 테스트 케이스에서도 샘플 데이터가 실행되버리면 테스트가 깨져버리게 된다.
그래서 로컬에서 톰캣으로 돌릴 때와 테스트 케이스 돌릴 때의 프로파일을 분리하는 작업을 한다.
application.yml에서
spring:
profiles:
active: local
datasource:
~~테스트 케이스는 test 폴더에다가 resources 생성하고 yml 파일을 복사해서 넣기.
spring:
profiles:
active: test
datasource:로 수정하면 main 소스코드와 테스트 소스 코드 실행 시 프로파일을 분리할 수 있다.
예제)
@Profile("local")
@Component
@RequiredArgsConstructor
public class InitMember {
private final InitMemberService initMemberService;
@PostConstruct
public void init() {
initMemberService.init();
}
@Component
static class InitMemberService {
@PersistenceContext
private EntityManager em;
@Transactional //데이터 초기화하는 로직.
public void init() {
//스프링 띄울 때 데이터 다 넣어놓고 조회용 API만 호출하기 위해 샘플 데이터를 넣음.
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
em.persist(teamA);
em.persist(teamB);
for (int i = 0; i < 100; i++) {
//절반은 팀A, 절반은 팀B에 소속되도록 설정.
Team selectedTeam = (i & 2) == 0 ? teamA : teamB;
em.persist(new Member("member" + i, i, selectedTeam));
}
}
}
}@Profile("") : 스프링 환경 설정(프로파일)을 할 수 있다. 프로파일은 개발, 테스트, 운영 등 다양한 환경에서 애플리케이션을 실행할 때 설정을 다르게 적용할 수 있도록 도와준다.
인자로 들어가는 값은 프로파일이 현재 인자값과 일치할 시 아래 코드에서 명시한 스프링 빈을 등록하라는 뜻.
@PostConstruct : 의존성 주입이 이루어진 후 초기화를 수행하는 메서드. 의존성 주입이 끝나고 실행됨이 보장되므로 빈의 초기화에 대해 걱정할 필요가 없어진다.
이 2가지를 같이 넣어서 할 수 없다.
@PostConstruct 하는 부분과 @Transactional 하는 부분을 분리해줘야 한다.
프로파일이 test이기 때문에 @Porfile("local")인 init 멤버는 활성화하지 않는다.
test할 때는 test용 데이터로만 하고 로컬을 띄워서 할 때는 local로 해서 푼다
다음은 API 생성
@RestController
@RequiredArgsConstructor
public class MemberController {
private final MemberJpaRepository memberJpaRepository;
@GetMapping("v1/members")
public List<MemberTeamDto> searchMemberV1(MemberSearchCondition condition) {
return memberJpaRepository.search(condition);
}
}📓 사용자 정의 리포지토리 (스프링 데이터 JPA)
(위에서는 순수 JPA로 했음)
1. 인터페이스 작성 (MemberRepositoryCustom)
2. 사용자 정의 인터페이스 구현 (MemberRepositoryImpl)
3. 스프링 데이터 리포지토리에 사용자 정의 인터페이스 상속
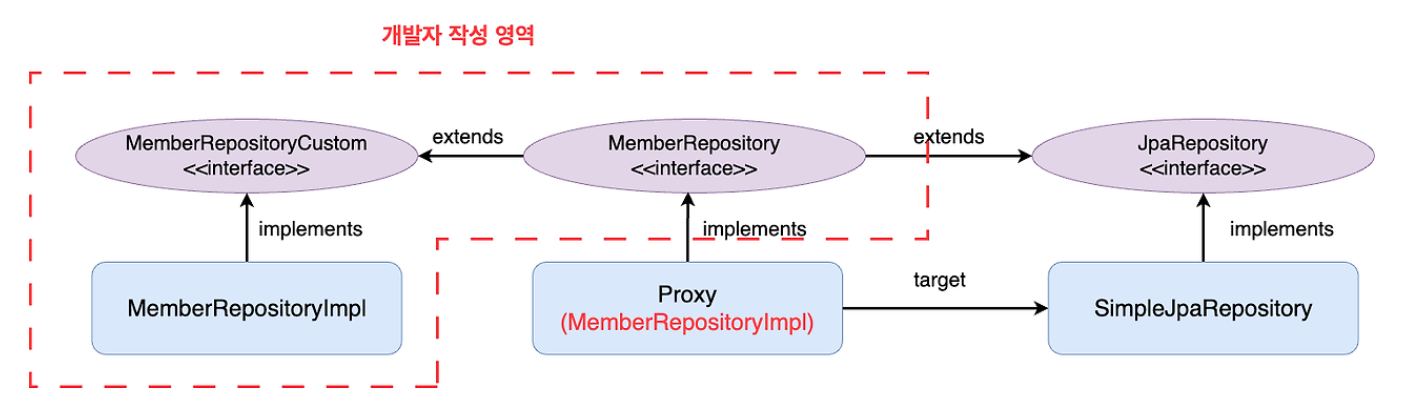
내가 원하는 구현 코드를 넣을려면 사용자 정의 리포지토리를 사용해야 한다.
스프링 데이터를 사용하면서 search 기능을 내가 직접 구현한 것으로 사용하고 싶다.
그러면 인터페이스 하나 생성하고 메서드 생성
public interface MemberRepositoryCustom {
List<MemberTeamDto> search(MemberSearchCondition condition);
}규칙 -> search에 대한 구현을 할 때는 클래스명에서 꼭 뒤에 스프링 데이터 인터페이스 + Impl 을 꼭 써야한다. ex) MemberRepositoryImpl
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final JPAQueryFactory queryFactory; //QueryDsl 사용하기 위해 필요.
public MemberRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
public List<MemberTeamDto> search(MemberSearchCondition condition) {
//search 기능 구현
return queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.fetch();
}
}memberRepository가 MemberRepositoryCustom을 받고 있기 때문에 가능하다.
Querydsl은 어쩔 수 없이 custom을 써야한다. (인터페이스에 메소드를 구현할 수 없기 때문에)
무조건 custom에 다 넣는 것은 좋은 설계가 아니니 핵심 비즈니스 로직으로 재사용 가능성이 있는 것들은 MemberRepository에 넣고, 공용성이 없고 특정 API에 종속되거나 수정 라이프 사이클 자체가 API나 화면에 맞춰서 기능이 변경이 되면 별도로 조회용 리포지토리를 만드는 것도 나쁘지 않음.
(여기서는 search 메서드를 따로 MemberQueryRepository 에 구현했음.)
(기본은 custom을 쓰는게 맞음. 근데 구조적으로 유연하게 또는 프로젝트가 너무 크면 분리해 내는 것도 괜찮은 방법.)
📓 스프링 데이터 페이징 활용
◎ QueryDsl에서 스프링 데이터의 Page, Pageable을 활용
◎ 전체 카운트를 한 번에 조회하는 단순한 방법
◎ 데이터 내용과 전체 카운트를 별도로 조회하는 방법.
☪ searchPageSimple()
custom 인터페이스에 작성
Page<MemberTeamDto> searchPageSimple(MemberSearchCondition condition, Pageable pageable);
Page<MemberTeamDto> searchPageComplex(MemberSearchCondition condition, Pageable pageable);MemberRepositoryImpl 에서
@Override
public Page<MemberTeamDto> searchPageSimple(MemberSearchCondition condition, Pageable pageable) {
QueryResults<MemberTeamDto> results = queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
//pageable
.offset(pageable.getOffset()) //몇 번째를 스킵하여 몇 번째부터 시작할건지.
.limit(pageable.getPageSize()) //한 번 조회할 때 몇 개까지 조회.
.fetchResults(); // contents 쿼리와 count 쿼리 2개를 날림.
List<MemberTeamDto> content = results.getResults(); //contents
long total = results.getTotal(); //total count
return new PageImpl<>(content, pageable, total);
}.fetchResults(); : QueryDSL이 contents용 쿼리와 count쿼리를 2번 날림.
◎데이터 내용과 전체 카운트를 별도로 조회하는 방법
위에 searchPageSimple()은 fetchResults() 로 해서 querydsl이 알아서 total count를 날렸지만
searchPageComplex()는 내가 직접 total count 쿼리를 날려줌.
상황에 따라 join이 필요 없을 때가 있고 쿼리 작성하다 보면 content 쿼리는 복잡한데 count 쿼리는 간단할 때가 있다. .fetchResults()를 쓰면 join, where 다 붙어야 하기 때문에 최적화가 불가능하다. 그래서 count 쿼리를 최적화하고 싶으면 별도로 분리해서 작성해야 한다. (성능을 위해 count 쿼리를 분리하는 것이 좋음. 데이터가 별로 없으면 그냥 fetchResult().)
위에 content 에서 .fetch() 로 바꾸고 count 쿼리를 위한 total 을 하나 더 생성해 주면 된다.
☪ searchPageComplex()
count 쿼리인 것이랑 아닌 거랑 완전히 분리해서 별도의 쿼리로 나간다.
@Override
public Page<MemberTeamDto> searchPageComplex(MemberSearchCondition condition, Pageable pageable) {
List<MemberTeamDto> content = queryFactory
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
//pageable
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
//content만 가져옴
//total count용 쿼리용을 하나 더
//내가 직접 total count 쿼리를 날려줌
long total = queryFactory
.select(member)
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.fetchCount();
return new PageImpl<>(content, pageable, total);
}content 쿼리와 total 쿼리를 리팩토링 할 수도 있다.
Ctrl + Alt + M (메서드 생성해서)으로 간단하게도 가능.
📓 CountQuery 최적화
바로 위에서 content 쿼리와 count 쿼리 둘 다 가져왔는데 때에 따라서 count 쿼리 생략 가능하다.
count 쿼리 생략 가능한 경우
◎ content와 pageable의 total size를 보고 페이지 시작이면서 컨텐츠 사이즈가 페이지 사이즈보다 작을 때.
◎ 마지막 페이지일 때 (offset + 컨텐츠 사이즈를 더해서 전체 사이즈 구함.)
//Count Query 최적화.
JPAQuery<Member> countQuery = queryFactory
.select(member)
.from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
);
//count 쿼리 조건 만족하면 호출 안 함.
return PageableExecutionUtils.getPage(content, pageable, () -> countQuery.fetchCount());count 쿼리는 countQuery.fetchCount(); 를 호출해줘야 쿼리가 날라간다. 함수기 때문에 구문이 실행이 되지 않고 content와 pageable의 total사이즈를 보고 조건에 맞으면 count 쿼리의 함수를 호출하지 않는다.
즉 전체 데이터 100개만 들어있다고 할 경우 페이징에서 200개로 가져온다면 (size = 200) totalCount를 날릴 필요가 없다. 이미 처음에 데이터를 다 불러와 버렸기 때문에.
이것이 select에서 가져온 결과가 count 쿼리보다 더 작기 때문에 두 번째로 넘어갈 데이터가 없는 것이다.
🕸️ PageableExecutionUtils.getPage
PageImpl()과 같은 역할을 하지만 마지막 인자로 함수를 전달하는데 내부 작도에 의해서 totalCount가 페이지 사이즈보다 작거나, 마지막 페이지일 경우 해당 함수를 실행하지 않는다.
즉 count 쿼리 호출을 하지 않기 때문에 쿼리를 조금 더 줄일 수 있다.
📓 QuerydslPredicateExecutor
public interface MemberRepository extends JpaRepository<Member, Long>, MemberRepositoryCustom, QuerydslPredicateExecutor<Member> {QuerydslPredicateExecutor 상속 해주면 스프링 데이터 JPA가 제공하는 Querydsl 기능을 사용할 수 있다.
그런데 제약이 커서 복잡한 실무에서는 사용하기 많이 부족하다. (단순한 조건만 가능)
◎조인이 불가능하다. (묵시적 조인은 가능하지만 left join 불가능)
◎클라이언트가 Querydsl에 의존해야 한다. -> Controller나 Service 계층에서 Repository 를 호출할 텐데 findAll()에서 넘겨야 하는게 Querydsl의 Predicate이다.
Repository를 만들어서 하부에 Querydsl 같은 구체화된 기술을 숨겨야 다음에 그 기술들을 리팩토링 가능한데 Predicate 이면 Querydsl을 바꾸거나 할 때 서비스, 컨트롤러 로직이 다 여기에 같이 의존관계가 생겨서 문제가 된다.
서비스 클래스가 Querydsl이라는 구현 기술에 의존해야 한다.
📓 리포지토리 지원
QuerydslRepositorySupport 추상클래스가 있다.
Querydsl 라이브러리를 쓰기위해서 리포지토리 구현체를 받으면 편리하다.
~~RespositoryImpl 에서 extends 로 받으면 된다.
public class MemberRepositoryImpl extends QuerydslRepositorySupport implements MemberRepositoryCustom {
public MemberRepositoryImpl() {
super(Member.class);
}이걸 쓰게 되면 추상 클래스이기 때문에 super에서 호출하게 되면 부모가 많은 기능을 제공해준다.
EntityManager를 쓸 수 있고 Querydsl 쓸 수 있다.
편리한 점은 EntityManager를 주입을 받아 준다.
EntityManager entityManager = getEntityManager();그리고 페이징을 편리하게 해준다. -> offset, limit를 지워줄 수 있다.
applyPagination 가 query.offset/limit를 지원해준다.
JPQLQuery<MemberTeamDto> jpaQuery = from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")));
JPQLQuery<MemberTeamDto> query = getQuerydsl().applyPagination(pageable, jpaQuery);
query.fetch();from 에서 시작한다.
from(member)
.leftJoin(member.team, team)
.where(
usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())
)
.select(new QMemberTeamDto(
member.id.as("memberId"),
member.username,
member.age,
team.id.as("teamId"),
team.name.as("teamName")))
.fetch();getQuerydsl().applyPagination()
장점 -> 스프링 데이터가 제공하는 페이징을 Querydsl로 편리하게 변환 가능하다.
(단 Sort는 오류 발생.)
EntityManager 제공.
단점 -> Querydsl 3.X 버전을 대상으로 만듬.
4.X에 나온 JPAQueryFactory로 시작할 수 없다.
QueryFactory를 제공하지 않음.
Sort 기능 불가.
✠ Querydsl 한계 극복하는 지원 클래스 직접 만들기
스프링 데이터가 제공하는 페이징을 편리하게 변환하고 페이징과 카운트 쿼리도 분리
스프링 데이터 Sort 지원.
from 시작이 아닌 select(), selectFrom() 으로 시작 가능.
EntityManager, QueryFactory 제공.
public Page<Member> searchPageByApplyPage(MemberSearchCondition condition, Pageable pageable){
JPAQuery<Member> query = selectFrom(member)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()));
//offset, limit 넣으면 sort가 동적으로 안됨.
List<Member> content = getQuerydsl().applyPagination(pageable, query)
.fetch(); //그래서 sort 하기 위해 getQuerydsl() 해서 동적으로 해줌.
return PageableExecutionUtils.getPage(content, pageable, query::fetchCount);
//기존의 페이징은 querydsl support 가 제공하는 것으로 함.
//그나마 최적화한 버전.
}Querydsl4RepositorySupport 을 통해 지원한 코드.
//다음 버전. -> 직접 만든 applyPage 기능으로 함
public Page<Object> applyPagination(MemberSearchCondition condition, Pageable pageable) {
//Querydsl4RepositorySupport 에서 만든 applyPagination.
Page<Object> result = applyPagination(pageable, query -> //람다
query.selectFrom(member)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe())));
return result;
//바로 위 (searchPageByApplyPage) 메서드와 완전히 같은 코드.
//Ctrl + Alt + N 으로 합치기 가능.
}그리고 자바8의 람다를 사용할 수 있게 되면서 코드를 깔끔하게 작성이 가능하다.
(람다 다시 봐야지.)
