🧊 스레드의 상태
- New (새로운 상태): 스레드가 생성되었으나 아직 시작되지 않은 상태.
- Runnable (실행 가능 상태): 스레드가 실행 중이거나 실행될 준비가 된 상태.
- 일시 중지 상태들 (Suspended States)
- Blocked (차단 상태): 스레드가 동기화 락을 기다리는 상태.
- Waiting (대기 상태): 스레드가 무기한으로 다른 스레드의 작업을 기다리는 상태.
- Timed Waiting (시간 제한 대기 상태): 스레드가 일정 시간 동안 다른 스레드의 작업을 기다리는 상태.
- Terminated (종료 상태): 스레드의 실행이 완료된 상태.
🧊 메모리 가시성
메인 메모리는 CPU 입장에서 보면 거리도 멀고, 속도도 상대적으로 느림. 대신 상대적으로 가격이 저렴해서 큰 용량을 쉽게 구성 가능.
매우 빠른 CPU 연산을 따라가기 위해, CPU 가까이에 매우 빠른 메모리가 필요한데 이것이 캐시 메모리. (가격은 비쌈)
캐시 메모리를 메인 메모리에 반영하거나, 메인 메모리의 변경 내역을 캐시 메모리에 다시 불러오는 것은 언제 발생할지 모름.
멀티스레드 환경에서 한 스레드가 변경한 값이 다른 스레드에서 언제 보이는지에 대한 문제를메모리 가시성이라 함.
volatile 로 캐시 메모리가 아닌 메인 메모리에 항상 직접 접근하여 성능 상대적으로 떨어지지만 이 메모리 가시성 문제를 해결 가능.
🧊 동기화
공유 자원 때문에 여러 스레드가 접근하여 동시성 문제가 발생. 예시로 출금 로직이 있었음.
여러 스레드가 함께 사용하는 공유 자원을 여러 단계로 나누어 사용하기 때문에 동시성 문제가 발생했는데 한 번에 하나의 스레드만 실행하도록 제한 하여 여러 스레드가 동시에 접근해서는 안 되는 공유 자원을 접근하거나 수정하는 부분인 이 영역을 임계 영역 이라 한다.
synchronized는 한 번에 하나의 스레드만 실행하는 안전한 임계 영역 구간을 편리하게 만들게 할 수 있다. 모든 객체는 내부에 자신만의 모니터 락을 가지고 있어 이 락을 통해 한 번에 하나의 스레드만 실행할 수 있다. (꼭 필요한 곳으로 한정해서 설정 필요!!)
volatile 사용하지 않아도 synchronized 안에서 접근하는 변수의 메모리 가시성 문제는 해결됨.
단점
- 무한 대기 : BLOCKED 상태의 스레드는 락이 풀릴 때까지 무한 대기
- 중간에 인터럽트 불가능, 특정 시간까지만 대기하는 타임아웃 불가능
- 공정성 : 락이 돌아왔을 때 BLOCKED 상태의 여러 스레드 중에 어떤 스레드가 락을 흭득할 지 알 수 없음. (최악의 경우 특정 스레드가 오랜 기간 락을 흭득 X)
🧊 LockSupport
무한 대기 문제 해결
스레드를 WAITING 상태로 변경하고 WAITING 상태는 누가 깨워주기 전까지는 계속 대기. CPU 스케줄링에 들어가지도 않음.
park(), parkNanos(nanos), unpark(thread) 함수가 존재
🧊 ReentrantLock
LockSupport는 저수준이므로 Lock 인터페이스와 ReentrantLock 구현체를 사용해서 synchronized 단점 극복
Lock 인터페이스는 안전한 임계 영역을 위한 락을 구현하는 데 사용.
void lock(): 락을 흭득. 이미 락을 흭득했다면, 락이 풀릴 때까지 현재 스레드는 대기. (인터럽트에 응답X)void lockInterruptibly(),boolean tryLock()등이 존재.
공정성 극복 : 스레드가 공정하게 락을 얻을 수 있는 모드를 제공.
private final Lock fairLock = new ReentrantLock(true);
락을 요청한 순서대로 스레드가 락을 흭득할 수 있게 하고 먼저 대기한 스레드가 먼저 락을 흭득하게 되어 스레드 간의 공정성을 보장. (성능 저하)
ReentrantLock에 대기 큐가 있고 락을 관리.
🧊 생산자 소비자 문제
버퍼가 비었을 때 소비, 버퍼가 가득 찼을 때 생산하는 문제를 해결하기 위해 스레드가 잠깐 작업을 기다릴 수 있지만 결국 임계 영역 안에서 락을 가지고 대기하는 것이 문제.
아무 일도 하지 않고 대기하는 동안은 잠시 다른 스레드에게 락을 양보해서 락을 가진 스레드도 버퍼에서 값을 흭득하거나 값을 채우고 락을 반납하기.
Object.wait() : 현재 스레드가 가진 락을 반납하고 대기. 현재 스레드를 대기 상태로 전환. notify() 호출할 때까지 대기.
Object.notify() : 대기 중인 스레드 중 하나를 깨움. synchronized 블록이나 메서드에서 호출 가능.
Object.notifyAll() : 대기 중인 모든 스레드를 깨움.
그러면 생산자는 큐에 데이터가 가득 차 있어도, 저장할 공간이 생길 때까지 대기하고 소비자도 큐에 데이터가 없어도 큐에 데이터가 들어올 때까지 대기 가능.
이렇게 해도 생산자와 소비자가 같은 대기 큐에서 대기하며 notify() 호출 시 어떤 스레드가 깨어날지 제어가 불가능.
🧊 생산자, 소비자 대기 집합 나누기
생산자 스레드는 데이터를 생산하고 대기 중인 스레드에게 알려줘야 함. 반대로 소비자 스레드는 데이터를 소비하고 대기 중인 생산자 스레드에게 알려줘야 함. 그래서 대기 집합을 둘로 나눔.
Lock, ReentrantLock을 사용해서 분리가 가능.
Condition condition = lock.newCondition()Condition은 `ReentrantLock`을 사용하느 스레드가 대기하는 스레드 대기 공간. `condition.await()` : 지정한 condition에 혀냊 스레드를 대기 상태로 보관. `condition.signal()` : 대기 중인 스레드를 하나 깨움.
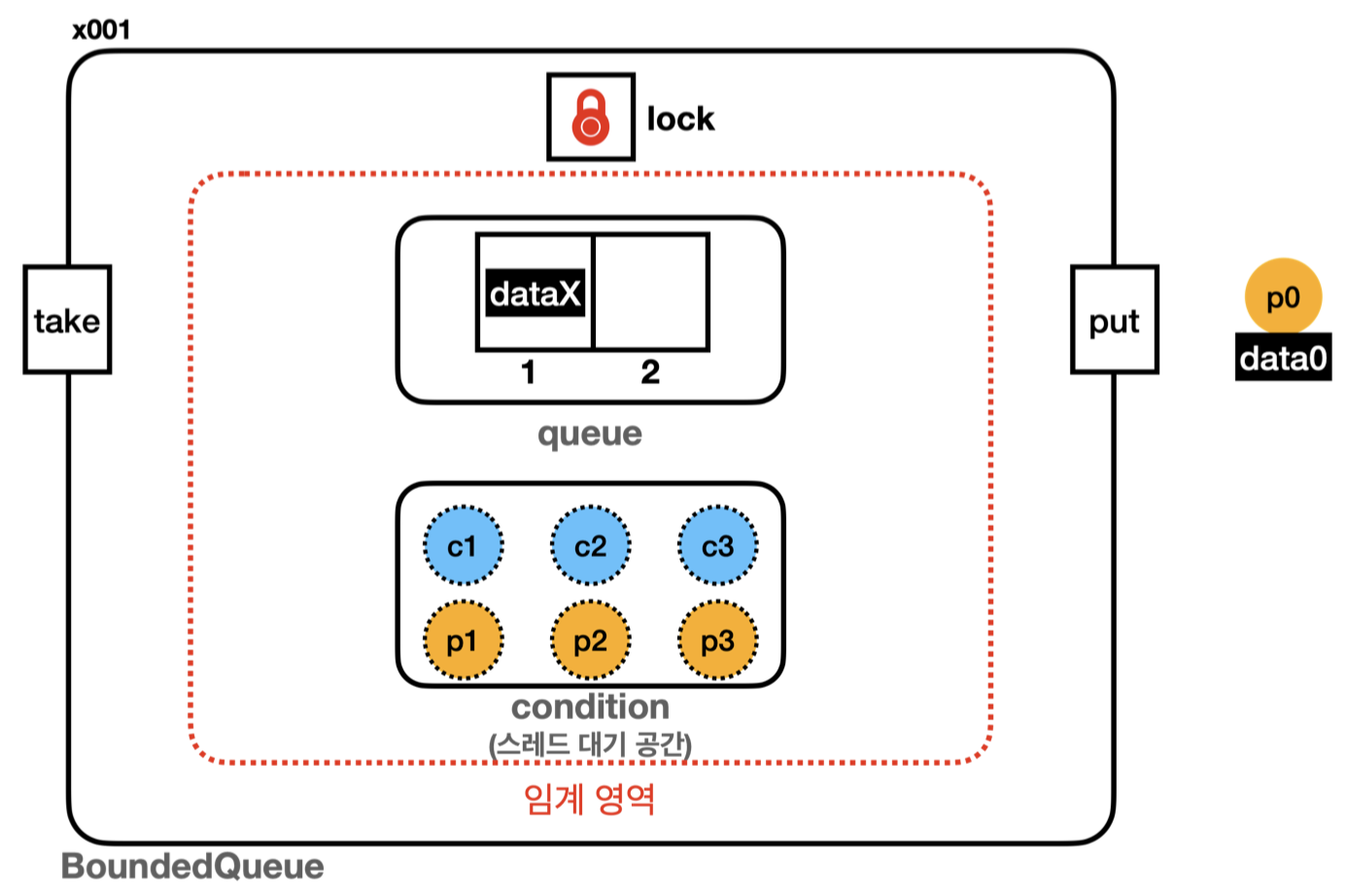
이렇게 스레드가 대기하는 집합이 하나면 원하는 스레드를 선택해서 깨울 수가 없다. 생산자는 데이터를 생산한 다음 대기하는 소비자를 깨워야 하는데 대기하는 생산자를 깨울 가능성이 있다. 따라서 비효율이 발생한다.
따라서 다음과 같이 따로 분리가 필요!!
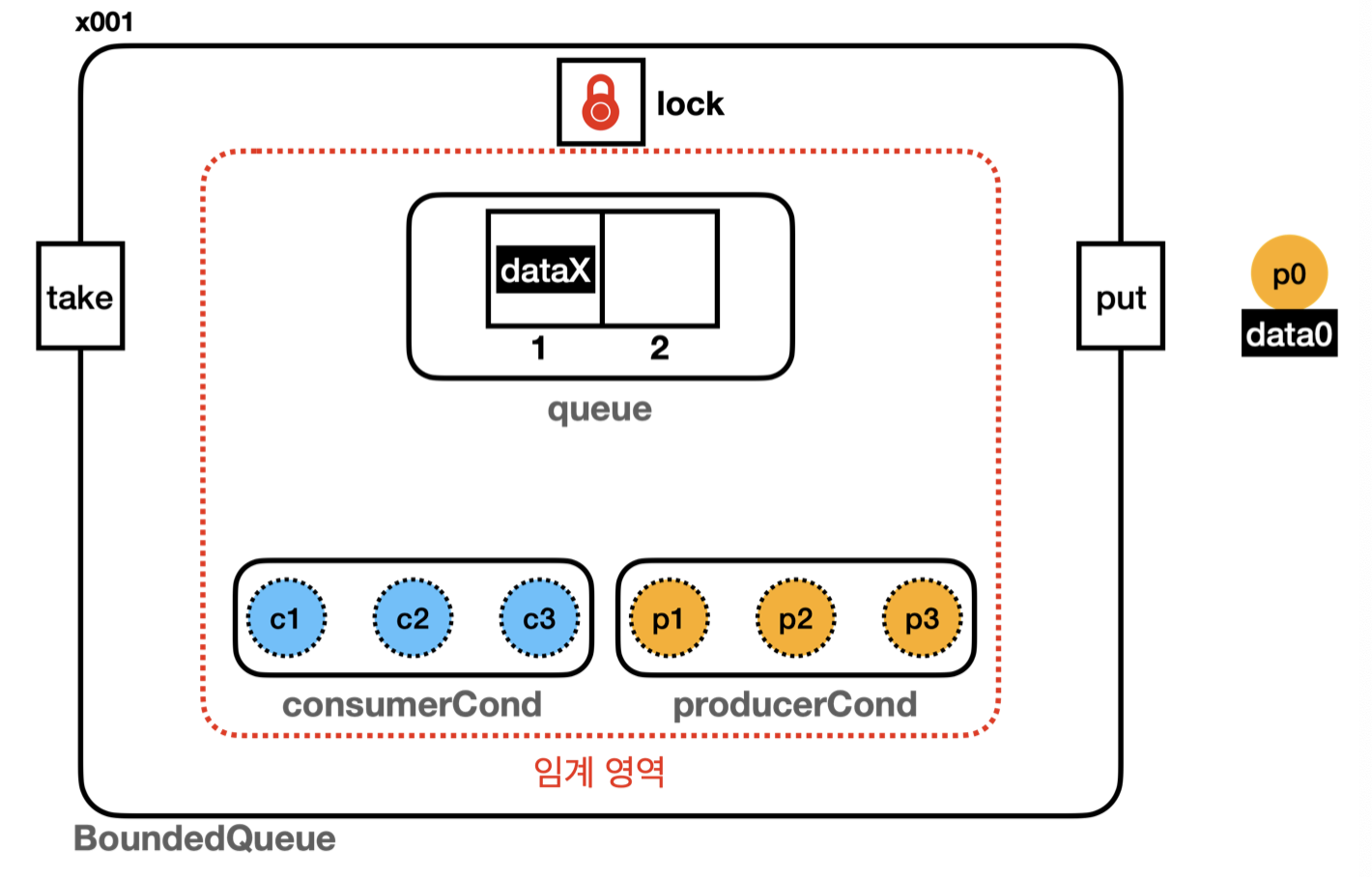
생산자 스레드, 소비자 스레드를 정확하게 나누어 관리하고 깨우기 가능.
생산자는 소비자를 깨우고 소비자는 생산자를 깨움.
사용한 Queue 종류
BoundedQueue : 버퍼 역할을 하는 큐의 인터페이스
ConcurrentLinkedQueue : 여러 스레드가 동시에 접근할 수 있도록 설계된 큐
ArrayDeque
BlockingQueue(인터페이스) : 멀티스레드 자료구조로 스레드를 차단할 수 있는 큐
- ArrayBlockingQueue(구현체) : 배열 기반으로 구현되어 있고, 버퍼의 크기가 고정
- LinkedBlockingQueue(구현체) : 링크 기반으로 구현되어 있고, 버퍼의 크기를 고정할 수도, 무한하게 사용할 수도 있다.
- BlockingDeque(구현체) : 이중 연결 리스트 기반으로 양쪽 끝에서 요소를 추가하거나 제거할 수 있는 큐. 고정 크기 또는 무한 크기로 설정 가능.
🧊 BlockingQueue
버퍼 큐가 가득 차서 1. 예외 던지고 받아서 처리, 2. 대기하지 않고 즉시 false를 반환, 3. 대기, 4. 특정 시간 만큼만 대기 가 있다.
실무에서 응답성을 위한 것이다. 대기 상태에 있어도 고객이 중지 요청을 하거나, 너무 오래 대기한 경우 포기하고 빠져나가기 위한 것.
🧊 CAS
CAS 장점
1. 낙관적 동기화 : 락을 걸지 않고도 값을 안전하게 업데이트 가능. (원자적 연산만 가능) 충돌이 적은 환경에서 높은 성능을 보임.
2. 락 사용X 이기 때문에 락을 흭득하기 위해 대기하는 시간이 없음. 병렬처리 효율적.
CAS 단점
1. 충돌이 빈번하다면 여러 스레드가 동시에 동일한 변수에 접근하여 업데이터를 시도할 때 충돌 발생.
- CAS는 루프를 돌며 재시도해야 하며, 이에 따라 CPU 자원을 계속 소모. (반복적인 재시도로 오버헤드 발생)
- CAS는 충돌 시 반복적인 재시도를 하므로 이 과정이 반복되면 스핀락과 유사한 성능 저하가 발생 (충돌 빈도가 높을수록 이런 현상이 많이 발생)
동기화 락 장점
1. 충돌 관리 : 락을 사용하면 하나의 스레드만 리소스에 접근할 수 있으므로 충돌이 발생 X. (여러 스레드가 경쟁할 경우에도 안정적으로 동작)
2. 복잡한 상황에서도 락은 일관성 있는 동작을 보장.
3. 락을 대기하는 스레드는 CPU를 거의 사용 X.
동기화 락 단점
1. 락 흭득 시간 : 스레드가 락을 흭득하기 위해 대기해야 하므로 대기 시간이 길어짐.
2. 컨텍스트 스위칭 오버헤드 : 락 사용하면 락 흭득을 대기하는 시점과 락을 흭득하는 시점에 스레드의 상태가 변경됨. 컨텍스트 스위칭이 발생할 수 있으며, 이로 인해 오버헤드 증가.
일반적으로는 동기화 락을 사용하고 특별한 경우에만 CAS를 사용해야 하는데 CAS를 사용한 최적화가 더 나은 경우라면 스레드를 RUNNABLE로 살려둔 상태에서 계속 락 흭득을 반복 체크하는 것이 더 효율적인 경우에 사용해야 한다.
이 경우 대기하는 스레드가 CPU 자원을 계속 소모하기 때문에 대기 시간이 매우매우 짧아야 한다. (임계 영역이 필요는 하지만 연산이 매우매우 짧을 때 사용.)
DB를 기다리거나 다른 서버의 요청을 기다리는 것처럼 기다리는 작업에는 동기화 락을 사용.
실무에서는 충돌할 가능성보다 충돌하지 않을 가능성이 훨씬 높기도 하고 주문 수 증가와 같은 단순한 연산이라면 CAS처럼 낙과적인 방식이 더 낫다. 그래서 단순한 연산이라면 AtomicInteger 같은 CAS 연산을 사용하는 방식이 효과적이다.
우리가 직접 CAS 연산을 사용하는 경우는 드물기 때문에 이해만 하자!! AtomicInteger 같은 연산을 사용하는 라이브러리들을 잘 사용만 하자!!!
🧊 동시성 컬렉션
컬렉션 프레임워크는 원자적인 연산을 제공하는지. 예를 들면 하나의 List인스턴스에 여러 스레드가 동시에 접근해도 되는지.
-> 기본적으로 원자적인 연산을 제공하지 않는다. 스레드 세이프 하지 않다.
-> 스레드 세이프 : 여러 스레드가 동시에 접근해도 괜찮은 경우
여러 스레드가 접근해야 한다면 synchronized, Lock 등을 통해 안전한 임계 영역을 만들어야 한다.
프록시가 대신 동기화 기능을 처리할 수도 있다.
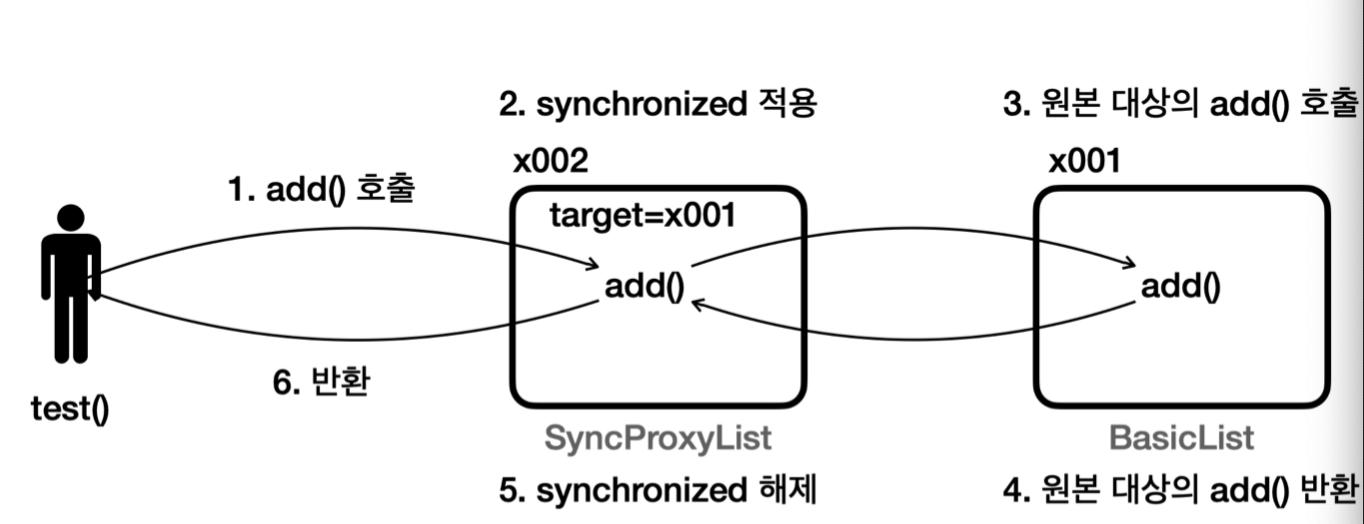
test() 메서드에서 스레드를 만들고 스레드에 있는 run()에서 add()를 호출하면SyncProxyList(x002)에 있는 add가 호출되고 SyncProxyList는 동기화를 적용하여 target에 있는 add()가 호출된다.
클라이언트 입장에서 프록시는 원본과 똑같이 생겼고, 호출할 메서드도 똑같다. 단지 SimpleList의 구현체일 뿐이다.
프록시가 동기화를 적용하고 원본을 호출하기 때문에 원본 코드도 이미 동기화가 적용된 상태로 호출된다.
원본 코드는 손대지 않고 SyncProxyList를 통해 동기화 기능을 적용.
서로 같은 인터페이스를 사용하기 때문에 SyncProxyList를 그대로 활용 가능. 즉 SyncProxyList 프록시 하나로 SimpleList 인터페이스의 모든 구현체를 동기화 가능.
기존 코드와의 호환성 유지를 위해 기존의 컬렉션 클래스를 수정하지 않고 동기화 기능을 추가하고 싶을 때 유용합니다. 또한 특정 메서드에만 동기화를 적용하거나, 전체 클래스에 적용하는 등의 유연한 설정이 가능합니다.
synchronized 프록시 방식 단점
1. 각 메서드 호출 시마다 동기화 비용이 추가됨. -> 성능 저하
2. 전체 컬렉션에 대해 동기화가 이루어지기 때문에 잠금 범위가 넓어질 수 있다. -> 모든 메서드에 대해 동기화를 적용하다 보면, 특정 스레드가 컬렉션을 사용하고 있을 때 다른 스레드들이 대기해야 하는 상황이 빈번하게 발생.
3. 선택적 동기화 적용(동기화의 필요성을 잘못 판단)이 어려워 과도한 동기화로 이어질 수 있다. -> 모든 메서드에 synchronized를 걸어버림.
🔫🔫 다양한 동시성 컬렉션 클래스
고성능 멀티스레드 환경을 지원하는 동시성 컬렉션 클래스들을 제공하는 concurrent 패키지.
ConcurrentHashMap, CopyOnWriteArrayList, BlockingQueue 등이 존재.
CopyOnWriteArraySet : HashSet 대안
ConcurrentSkipListSet : TreeSet의 대안 (정렬된 순서 유지, Comparator 사용 가능)
ConcurrentSkipListMap : TreeMap의 대안
ConcurrentLinkedQueue, ConcurrentLinkedDeque
스레드 차단하는 블로킹 큐
BlockingQueueArrayBlockingQueue: 크기 고정, 공정 모드 사용 가능 -> 성능 좀 저하LinkedBlockingQueue: 크기가 무한하거나 고정됨.PriorityBlockingQueue: 우선 순위가 높은 요소를 먼저 처리SynchronousQueue: 데이터를 저장하지 않는 큐. 소비자가 데이터를 받을 때까지 대기.- 중간에 큐 없이 생산자 소비자가 직접 거래.
DelayQueue: 지연된 요소를 처리하는 블로킹 큐, 각 요소는 지정된 지연 시간이 지난 후에야 소비될 수 있다. -> 일정 시간이 지난 후 작업을 처리해야 하는 스케줄링 작업에 사용됨.
비/차단 큐
차단 큐는 큐가 비어 있을 때 소비자가 데이터를 가져가려고 할 경우, 소비자가 대기하게 되는 큐입니다. 큐가 가득 찼을 경우라면 생산자가 데이터를 추가할 때 생산자도 대기합니다.
생산자와 소비자 간의 동기화를 자연스럽게 처리할 수 있고, 데이터 흐름을 원활하게 유지 가능.
비차단 큐는 큐가 비어있거나 가득 차 있어도 스레드가 대기하지 않고 즉시 결과를 반환하는 큐입니다. 데이터가 없으면 Null를 반환하거나, 생산자가 가득 찬 큐에 데이터를 추가하려고 하면 예외를 발생합니다.
🧊 Executor
