🍀 스레드 관리하는 공간 없이 직접 사용
스레드 생성 시간으로 인한 성능 문제가 있습니다.
스레드를 사용하려면 먼저 스레드를 생성해야 하는데 메모리 할당하고 운영체제 자원 사용하고 운영체제 스케줄러 설정까지해서 스레드를 관리하고 실행 순서를 조정하면 CPU와 메모리 리소스를 소모하고 운영체제의 스케줄링 알고리즘에 따라 추가적인 오버헤드가 발생할 수 있습니다.
스레드 생성은 자바 객체 하나 생성과 비교할 수 없을 정도로 큰 작업입니다.
스레드 관리 문제
서버의 CPU, 메모리 자원은 한정되어 있어 무한의 스레드를 생성할 수 없습니다.
사용자의 주문을 처리하는 서비스가 주문이 들어올 때마다 스레드를 생성하여 요청을 한다면 평소 동시에 100개 정도의 스레드면 충분했는데 이벤트로 갑자기 10,000 개의 스레드가 필요해버려지면 CPU, 메모리 자원이 버티지 못합니다.
애플리케이션을 종료할 때도 안전한 종료를 위해 실행 중인 스레드가 남은 작업은 모두 수행한 다음에 프로그램을 종료하거나 급하게 종료할 때 인터럽트 등의 신호를 주고 종료한다고 한다면 스레드가 어딘가에 관리가 되어 있어야 안전하게 종료할 수 있습니다.
Runnable 인터페이스 단점
run() 메서드는 반환 값을 가지지 않아서 실행 결과를 얻기 위해선 별도의 메커니즘이 필요합니다. join() 등을 사용해서 스레드가 종료되기를 기다려야 합니다.
예외도 던질 수가 없어 메서드 내부에서 처리해야 합니다.
🦉 스레드 풀 (단점을 해결하기 위한 스레드 생성, 관리 풀)
스레드를 관리하는 풀에 미리 스레드를 만들어놓고 작업 요청이 뜨면 그때 스레드를 하나 조회해서 작업을 처리합니다. 작업 완료하고 나면 다시 풀에 반납합니다.
작업을 완료해도 스레드가 종료하는 것이 아닌 반납을 통해 이후 다시 재사용할 수 있게 해줍니다. -> 스레드 생성하는 시간이 0
컬렉션에 스레드를 보관하고 재사용할 수 있게 하고 처리할 작업이 없다면 WAITING 상태로 관리하다가 요청이 오면 그때 RUNNABLE로 변경이 필요합니다. 생산자 소비자 문제도 발생합니다.
하지만 자바가 제공하는 Executor 프레임워크로 스레드풀, 관리, Runnable, 생산자 소비자 문제까지 해결해줍니다.
🍀 Executor
스레드 풀에 작업을 요청하는 메서드가 execute() 입니다.
public interface Executor{
void execute(Runnable command);
}ExecutorService 인터페이스는 실행 뿐만 아니라 추가적인 여러 기능을 제공합니다. 주요 메서드로는 submit(), close()로 작업 제출과 제어 기능을 제공합니다.
대부분 이 인터페이스르 사용합니다.
public interface ExecutorService extends Executor, AutoCloseable{
<T> Futere<T> submit(Callable<T> task);
@Override
default void close(){}
}실행 결과
13:35:32.817 [ main] -- 초기 상태 --
13:35:32.827 [ main] [pool = 0, active = 0, queueTasks = 0, completedTaskCount = 0]
13:35:32.827 [ main] -- 작업 수행 중 --
13:35:32.828 [ main] [pool = 2, active = 2, queueTasks = 2, completedTaskCount = 0]
13:35:32.828 [pool-1-thread-1] taskA 시작
13:35:32.828 [pool-1-thread-2] taskB 시작
13:35:33.834 [pool-1-thread-2] taskB 시작
13:35:33.835 [pool-1-thread-2] taskC 시작
13:35:33.834 [pool-1-thread-1] taskA 시작
13:35:33.838 [pool-1-thread-1] taskD 시작
13:35:34.837 [pool-1-thread-2] taskC 시작
13:35:34.842 [pool-1-thread-1] taskD 시작
13:35:35.831 [ main] -- 작업 수행 완료 --
13:35:35.832 [ main] [pool = 2, active = 0, queueTasks = 0, completedTaskCount = 4]
13:35:35.837 [ main] -- shutdonw 완료 --
13:35:35.838 [ main] [pool = 0, active = 0, queueTasks = 0, completedTaskCount = 4]스레드 풀에 2개의 작업이 있고 활동은 없음. 두 스레드 모두 쉬는 중이다. 그리고 이중에서 완료된 작업은 4개다.
close()로 셧다운 하고 나면 풀에 있는 스레드가 전부 제거됩니다. 풀에 작동 중으로 WATING 상태로 있던 스레드 2개가 안전하게 종료됩니다.
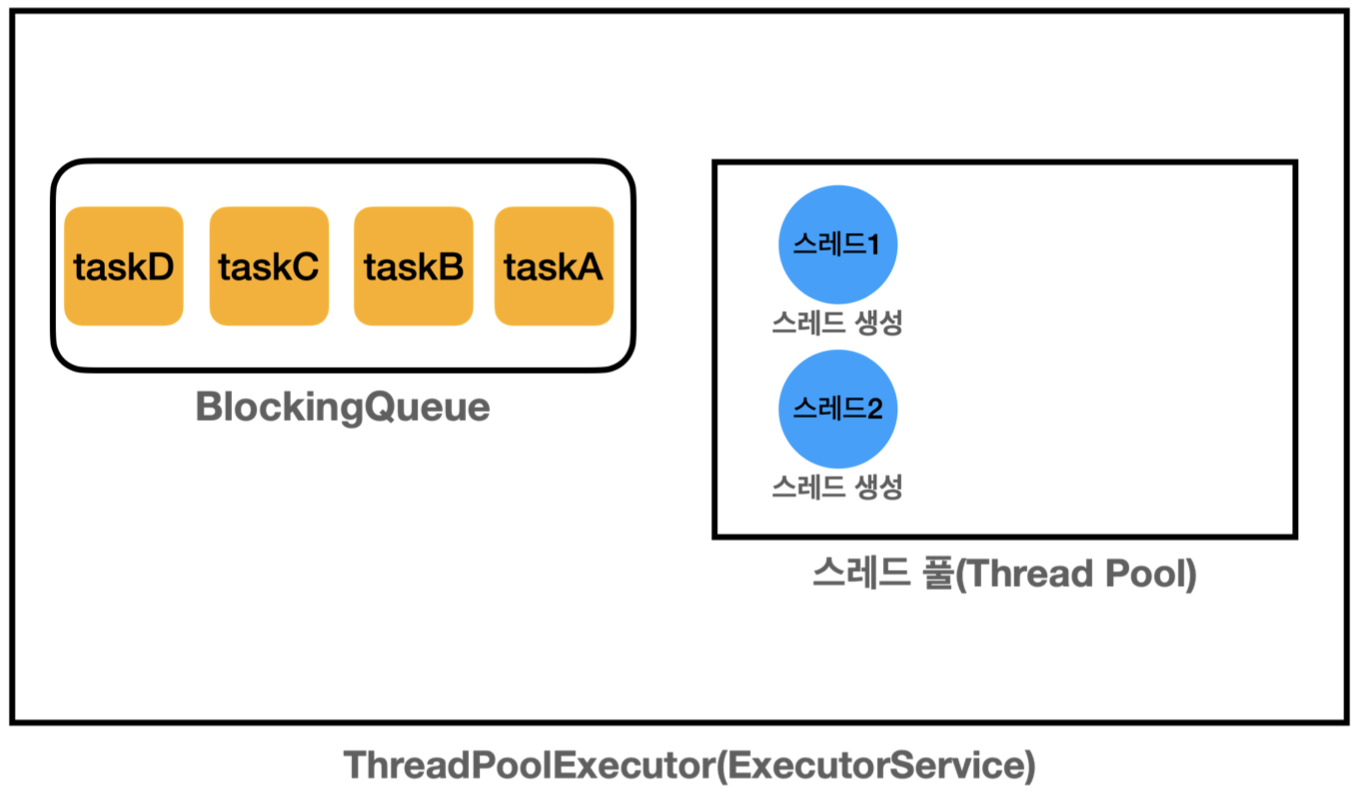
ExecutorService 의 가장 대표적인 구현체는 ThreadPoolExecutor.
ThreadPoolExecutor(ExecutorService) 는 크게 2가지 요소로 구성
- 스레드 풀 -> 스레드 관리
- BlockingQueue -> 작업을 보관 (생산자 소비자 문제)
생산자가 execute() 를 호출하면 RunnableTask("taskA") 인스턴스가 BlockingQueue에 보관됩니다. 스레드 풀에 있는 스레드가 소비자가 됩니다. 그러면 소비자 중에 하나가 BlockingQueue에 들어있는 작업을 받아서 처리합니다.
ThreadPoolExecutor(ExecutorService) 는 크게 2가지 요소로 구성되어 있습니다.
- 스레드 풀: 스레드를 관리한다.
- BlockingQueue : 작업을 보관한다. 생산자 소비자 문제를 해결하기 위해.
생산자가 es.execute(new RunnableTask("taskA")) 를 호출하면, RunnableTask("taskA") 인스턴스 가 BlockingQueue 에 보관됩니다.
ThreadPoolExecutor 의 생성자는 다음 속성을 사용
ExecutorService es = new ThreadPoolExecutor(2, 2, 0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());corePoolSize: 스레드 풀에서 관리되는 기본 스레드의 수maximumPoolSize: 스레드 풀에서 관리되는 최대 스레드 수keepAliveTime,TimeUnit unit: 기본 스레드 수를 초과해서 만들어진 스레드가 생존할 수 있는 대기 시간. 이 시간 동안 처리할 작업이 없다면 초과 스레드는 제거된다.BlockingQueue workQueue: 작업을 보관할 블로킹 큐.LinkedBlockingQueue를 사용하여 메모리가 허용하는 한 끝까지 담을 수 있음
스레드 풀에서 스레드를 꺼내서 작업을 실행하는 것처럼 보이지만 실제로는 상태가 변경된다.
작업이 완료되면 스레드 풀에 스레드를 반납하고 반납하면 스레드는 다시 WAITING 상태로 스레드 풀에 대기합니다. (반납 -> 스레드의 상태가 변경된다고 이해)
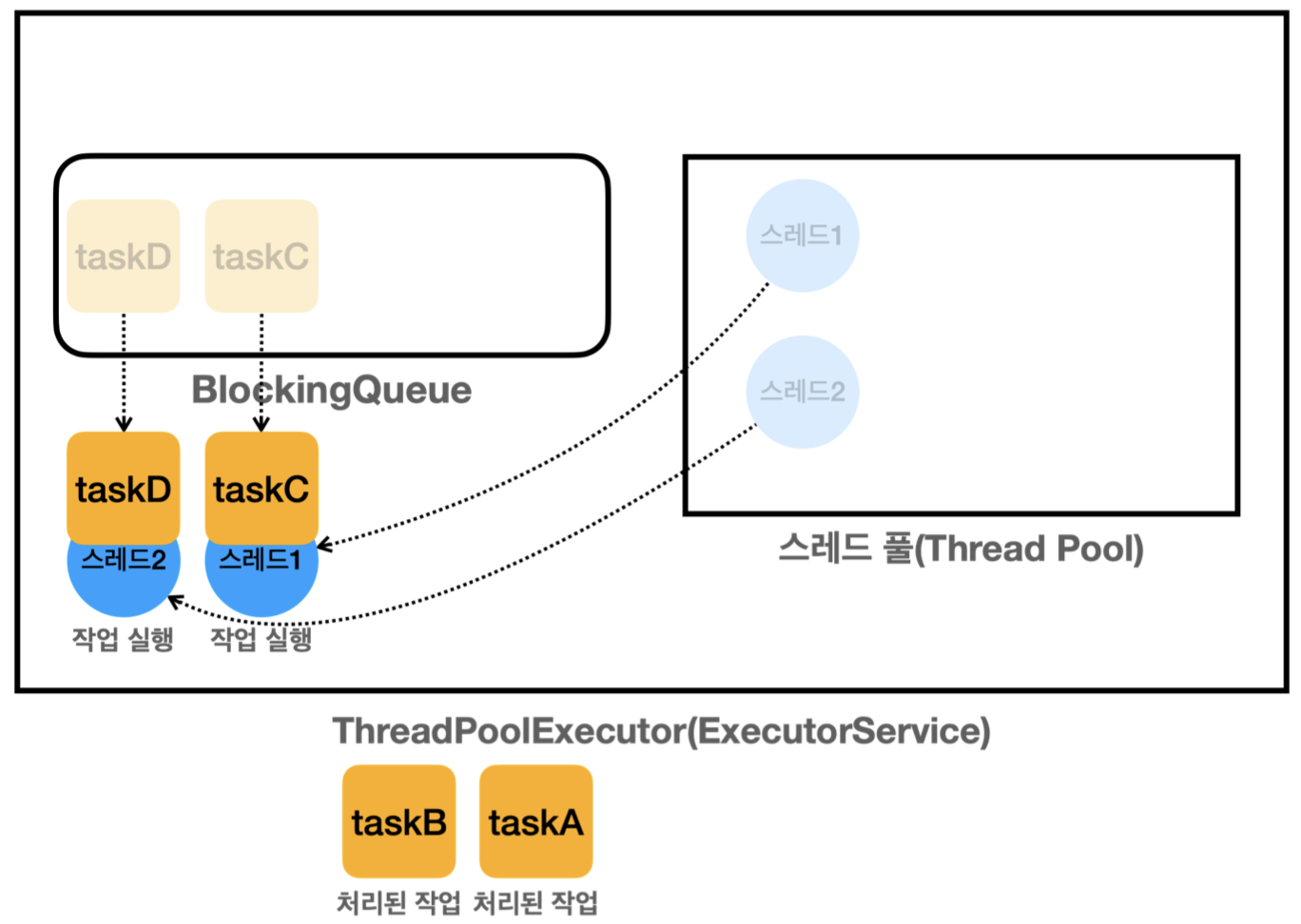
반납했던 스레드가 다시 taskC, taskD의 작업을 처리하기 위해 스레드 풀에서 스레드를 꺼내 재사용. 작업 완료 후 close() 호출하면 ThreadPoolExecutor 가 종료되고 스레드 풀에 대기하는 스레드도 함께 제거.
ThreadPoolExecutor를 생성한 시점에 스레드 풀에 스레드를 미리 만들지 않는다.
ThreadPoolExecutor를 생성할 때 초기 스레드 수를 설정할 수 있는데 이 초기 스레드는 스레드 풀에서 바로 사용할 수 있는 스레드의 수를 말합니다.
만약 작업 요청이 들어오고 현재 가능한 스레드가 없다면,ThreadPoolExecutor는 새로운 스레드를 생성하여 작업을 처리합니다.
미리 만들어 두지 않는다는 의미는 최초의 작업이 들어올 때 작업을 처리하기 위한 스레드를 만드는 것이고 스레드 풀에 미리 만들어두지는 않는다는 의미!!!!
🍀 Future - Runnable 불편함 해결
run() 메서드에는 반환값이 없어 별도의 메커니즘이 필요. 스레드의 실행 결과를 직접 받을 수 없어 스레드가 실행한 결과를 멤버 변수에 넣고 join() 등을 사용해서 스레드가 종료되기를 기다린 후에 멤버 변수를 통해 값을 받았습니다.
또한 체크 예외를 던질 수 없어 메서드 내부에서 처리해야 했습니다.
java.util.concurrent에서 제공되는 기능인 Callable의 call()메서드를 사용하면 됩니다.
11:41:09.915 [pool-1-thread-1] Callable 시작
11:41:11.927 [pool-1-thread-1] result value = 8
11:41:11.928 [pool-1-thread-1] Callable 완료
11:41:11.929 [ main] result value = 8숫자를 반환하려고 하므로 제네릭을 Integer로 선언하고 구현은 Runnable과 비슷하지만 결과를 필드에 담아두는 것이 아닌 결과를 반환하도록 했습니다. 그래서 결과를 보관할 별도의 멤버 변수가 필요하지 않습니다.
🍀 Future
메인 메서드가 future.get()를 호출했을 때 작업을 처리하는 스레드 풀의 스레드가 작업을 아직 완료하지 못해서 작업을 처리 중인 상태라면? (완료하면 반환값 받음)
결과를 바로 반환하지 않고, Future라는 객체를 대신 반환이 필수인가? -> Future라는 객체로 받아서future.get()으로
스레드가 처리할 작업이 즉시 실행되어서 즉시 반환하는 것이 불가능합니다. 작업은 즉시 실행되는 것이 아니라 프레드 풀의 스레드가 미래의 어떤 시점에 이 코드를 대신 실행해야 합니다. submit()으로 던졌을 때 작업이 즉시 실행되는 게 아니고 스레드 풀에 있는 한 스레드가 큐에서 작업을 꺼내서 실행합니다. 그리고 바쁘면 대기해야하는 상황도 있습니다.
call()메서드는 메인 스레드가 실행하는 것도 아니고, 스레드 풀의 다른 스레드가 실행하기 때문에 언제 실행이 되어서 결과를 반환할 지 알 수 없습니다. 그래서 submit()은 작업의 결과를 반환하는 대신에 결과를 나중에 받을 수 있는 Future라는 객체를 대신 제공합니다.
단순하게 Future 객체는 전달한 작업의 미래 결과를 담고 있다고 생각하면 됩니다.
작업이 끝나지 않으면 결과가 없기 때문에 future.get() 에서 결과가 나올 때까지 기다립니다.
실행 결과
12:02:45.907 [ main] submit() 호출
12:02:45.910 [pool-1-thread-1] Callable 시작
12:02:45.910 [ main] future 즉시 반환, future = java.util.concurrent.FutureTask@4501b7af[Not completed, task = thread.executor.future.CallableMainV2$MyCallable@28d25987]
12:02:45.911 [ main] future.get() [블로킹] 메서드 호출 시작 -> main 스레드 WAITING
12:02:47.928 [pool-1-thread-1] result value = 2
12:02:47.928 [pool-1-thread-1] Callable 완료
12:02:47.929 [ main] future.get() [블로킹] 메서드 호출 시작 -> main 스레드 WAITING
12:02:47.930 [ main] result value = 2
12:02:47.930 [ main] future 완료, future = java.util.concurrent.FutureTask@4501b7af[Completed normally]future.get()에서 메인 스레드가 작업 실행이 완료돼서 반환할 때까지 WAITING으로 기다립니다. 작업이 끝나면 RUNNABLE이 되면서 결과를 받고 로그를 찍습니다.
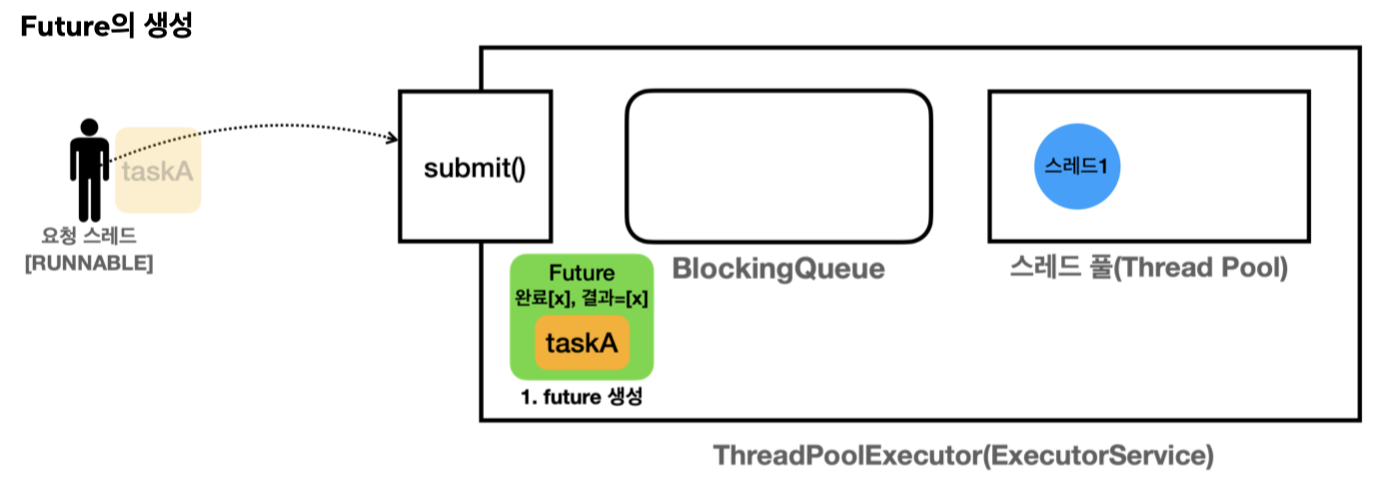
ExecutorService는 전달한 taskA의 미래 결과를 알 수 있는 Future 객체를 생성하고 Future 인터페이스의 객체 안에 taskA의 인스턴스가 보관됩니다.
Future 에는 taskA에 대한 완료 여부와 결과 값을 가지고 있습니다. -> 작업을 완료하고 반환하면.
taskA를 감싸고 있는 Future가 대신 BlockingQueue에 담깁니다.
Future<Integer> future = es.submit(new MyCallable())여기서 future 객체가 만들어지고 future 참조를 반환하는 것입니다. 그래서 로그에서 future를 즉시 반환합니다. FutureTask는 Future의 구현체이고 로그에서는 상태를 볼 수 있습니다. ([Not completed, task = thread.executor.future.CallableMainV2$MyCallable@28d25987])
핵심은 작업을 전달할 때 생성된 Future는 즉시 반환된다는 점입니다.
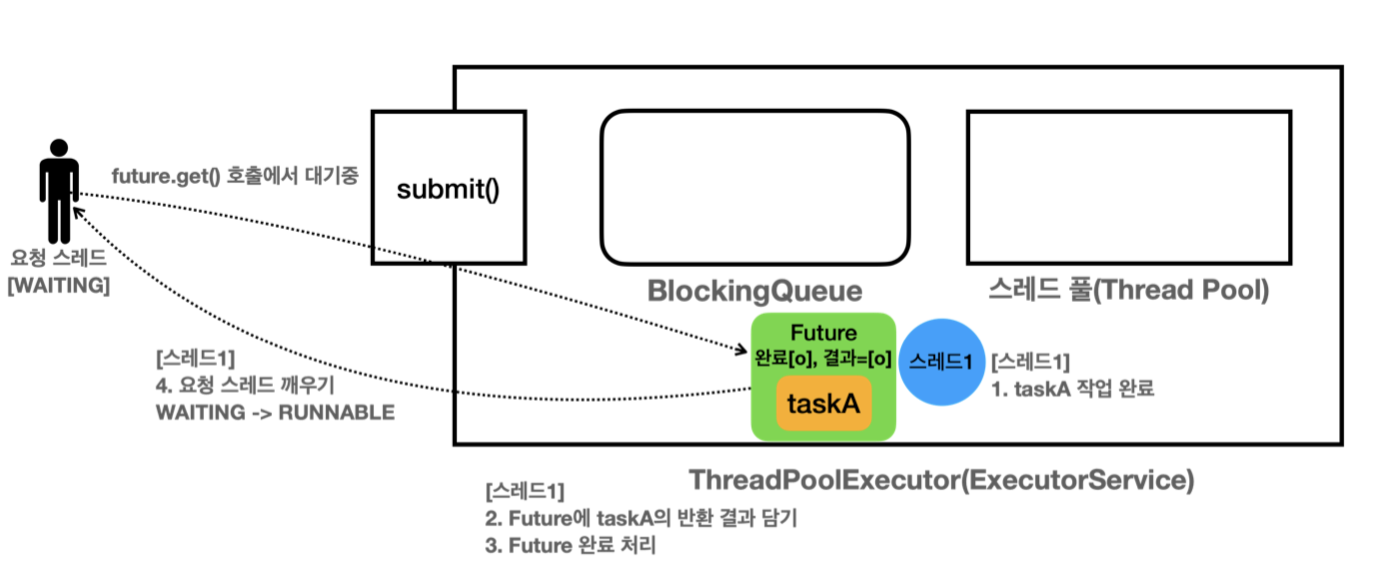
구현체인 FutureTask는 Runnable 인터페이스도 함께 구현하고 있어 스레드는 FutureTask의 run() 메서드를 수행합니다. run()메서드가 taskA의 call() 메서드를 호출하고 그 결과를 받아서 처리합니다.
메인 스레드(요청 스레드)는 작업의 결과가 필요해서 future.get()을 호출하는 taskA의 작업이 아직 완료되지 않으면 Future도 완료 상태가 아니기 때문에 완료될 때까지 대기합니다. (RUNNABLE -> WAITING)
작업이 완료되면 Future는 taskA에 대한 결과를 담고 완료 상태가 됩니다. 그 후에 대기하고 있던 메인 스레드가 깨어나서(어떤 스레드가 대기하고 있는데 Future는 알고 있음) 값 다 담고 결과를 출력하게 됩니다.
🍀 Future 존재 이유
Future 가 있는 상태와 없는 상태의 과정을 확인해봅니다.
Future가 없다면 요청 스레드가 결과를 받을 때까지 2초가 대기하고 2초 후에 결과를 받고 다음 라인을 수행하기 때문에 task1의 결과를 기다린 다음에 task2를 요청하여 각각 2초씩 총 4초가 걸립니다. (마치 단일스레드 작업처럼)
Future가 있다면 요청 스레드는 즉시 Future르 반환하고 작업 스레드는 task1을 수행합니다. (task2도 마찬가지로)
그러면 요청 스레드는 task1, task2를 동시에 수행합니다.
즉 내가 원하는 대로 작업을 다 던지면 알아서 여러 군데에서 실행되고 결과를 기다리면서 블로킹됩니다. task1은 future.get()에서 요청 스레드가 결과를 받기 위해서 2처 정도 기다리고 task2는 이 2초를 기다리는 동안 작업을 수행하기 때문에 즉시 결과를 반환하게 됩니다. (task2도 이미 2초간 작업을 완료했기 때문에)
그래서 총 2초만에 작업이 끝나게 되는 것입니다.
ExecutorService es = Executors.newFixedThreadPool(2);
Future<Integer> future1 = es.submit(task1);
Future<Integer> future2 = es.submit(task2);
Integer sum1 = future1.get();
Integer sum2 = future2.get();순서는 반드시 이렇게 지켜야 작성해야 합니다.
Future가 없다면 결과를 받을 때까지 요청 스레드는 아무 일도 하지 못하고 대기해야 합니다. (다른 작업을 동시에 수행 불가능)
Future 덕분에 결과적으로 task1, task2를 동시에 요청했고 두 작업을 바로 요청해씩 때문에 작업을 동시에 제대로 수행할 수 있습니다. (요청 스레드 대기 X)
Future는 요청 스레드를 블로킹 상태로 만들지 않고 필요한 요청을 모두 수행할 수 있게 해줍니다. 필요한 모든 요청을 한 다음에 Future.get() 을 호출해서 최종 결과를 받을 수 있습니다.
🍀 Future의 메서드
🫥 future.cancel()
작업이 되고 있는 스레드를 cancel로 취소할 수 있습니다.
log("future.cancel(" + mayInterruptIfRunning + ") 호출");
boolean cancelResult = future.cancel(mayInterruptIfRunning);
log("cancel(" + mayInterruptIfRunning + "_ result: " + cancelResult + ")");cancel(true)라면 취소 상태로 변경하고, 작업이 실행 중이라면 interrupt()를 호출해서 작업을 중단합니다.
cancel(false)를 호출하면 실행 중인 작업은 그냥 둡니다. 즉 Future를 취소 상태로 변경하지만, 단 이미 실행 중인 작업을 중단하지는 않습니다.
인터럽트를 걸지 않고 cancel()을 호출했기 때문에 Future는 CANCEL 상태가 됩니다.
실행 결과
true일 경우
14:55:55.453 [pool-1-thread-1] 작업 중 0
14:55:55.453 [ main] Future의 상태 보기: RUNNING
14:55:56.460 [pool-1-thread-1] 작업 중 1
14:55:57.462 [pool-1-thread-1] 작업 중 2
14:55:58.463 [ main] future.cancel(true) 호출
14:55:58.464 [pool-1-thread-1] 인터럽트 발생
14:55:58.469 [ main] cancel(true_ result: true)
14:55:58.472 [ main] Future는 이미 취소 되었습니다false일 경우
14:56:35.341 [pool-1-thread-1] 작업 중 0
14:56:35.341 [ main] Future의 상태 보기: RUNNING
14:56:36.348 [pool-1-thread-1] 작업 중 1
14:56:37.354 [pool-1-thread-1] 작업 중 2
14:56:38.350 [ main] future.cancel(false) 호출
14:56:38.357 [ main] cancel(false_ result: true)
14:56:38.357 [pool-1-thread-1] 작업 중 3
14:56:38.360 [ main] Future는 이미 취소 되었습니다
14:56:39.358 [pool-1-thread-1] 작업 중 4
14:56:40.364 [pool-1-thread-1] 작업 중 5
14:56:41.367 [pool-1-thread-1] 작업 중 6
14:56:42.372 [pool-1-thread-1] 작업 중 7
14:56:43.374 [pool-1-thread-1] 작업 중 8
14:56:44.381 [pool-1-thread-1] 작업 중 9🫥 e.getCause()
Future.get()을 호출하면 작업의 결과값 뿐만 아니라 작업 중에 발생한 예외도 받을 수 있습니다.
요청 스레드가 submit()을 호출해서 작업을 전달하면 작업 스레드는 작업을 실행하는데 IllegalStateException이 발생합니다. 예외가 발생하면 Future는 FAILED 상태가 됩니다.
요청 스레드는 결과를 얻기 위해 Future.get()을 호출합니다. Future의 상태가 FAILED면 ExecutionException예외를 던지고 이 예외는 내부에 Future에 저장해둔 IllegalStateException을 포함하고 있습니다.
e.getCause()를 호출하면 작업에서 발생한 원본 예외를 받을 수 있습니다.
try {
// 예외 발생 후 상태를 확인하기 위함
log("Future.get() 호출 시도, future.state() = " + future.state());
result = future.get();
log("result value = " + result);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} // 그래서 RuntimException이 발생한 원인으로 InterruptedException이 있을 수 있는 것입니다.
catch (ExecutionException e) {
log("e = " + e);
Throwable cause = e.getCause(); // 원본 예외
log("cause = " + cause);
}e.getCause()는 ExecutionException이 왜 발생했는지 원인을 가져올 수 있습니다. 그러면 Future에서는 한번 ExecutionException을 내부에서 감싸서 그 안에 받은 IllegalException을 객체로 넣습니다.
**실행 결과** ```java 15:09:07.677 [ main] 작업 전달 15:09:07.679 [pool-1-thread-1] Callable 실행, 예외 발생 15:09:09.688 [ main] Future.get() 호출 시도, future.state() = FAILED 15:09:09.689 [ main] e = java.util.concurrent.ExecutionException: java.lang.IllegalStateException: ex 15:09:09.689 [ main] cause = java.lang.IllegalStateException: ex ``` Callable을 실행하는데 `IllegalException`이 발생하고 future는 FAILED 상태가 됩니다. `future.get()`을 받는데 예외 터질 때 `ExecutionException`이 터져서 나옵니다. (ExecutionException 예외는 내부에 앞서 Future에 저장해둔 IllegalStateException을 포함하고 있다)
참고 예외
작업 스레드는 Future에 발생한 객체를 담아줍니다. 예외도 객체이므로 잡아서 필드에 보관할 수 있습니다.
🫥 invokeAll(), invokeAny()
invokeAll()은 모든 Callable 작업을 제출하고, 모든 작업이 완료될 때까지 기다립니다. 한 번에 모든 작업을 던지고 기다려서 받겠다 하면 invokeAll.
실행 결과
15:41:17.935 [pool-1-thread-2] task2 실행
15:41:17.935 [pool-1-thread-1] task1 실행
15:41:17.935 [pool-1-thread-3] task3 실행
15:41:18.945 [pool-1-thread-1] task1 완료
15:41:19.943 [pool-1-thread-2] task2 완료
15:41:20.943 [pool-1-thread-3] task3 완료
15:41:20.945 [ main] value = 1000
15:41:20.946 [ main] value = 2000
15:41:20.946 [ main] value = 3000invokeAny()은 하나의 Callable 작업이 완료될 때까지 기다리고, 가장 먼저 완료된 작업의 결과를 반환합니다. 한 번에 작업 던지고 그 중에 먼저 끝나는 얘를 받은 후에 나머지는 포기하고 버리고 싶다면 invokeAny.
실행 결과
15:43:11.773 [pool-1-thread-2] task2 실행
15:43:11.773 [pool-1-thread-3] task3 실행
15:43:11.773 [pool-1-thread-1] task1 실행
15:43:12.781 [pool-1-thread-1] task1 완료
15:43:12.782 [pool-1-thread-2] 인터럽트 발생, sleep interrupted
15:43:12.782 [ main] value = 1000
15:43:12.782 [pool-1-thread-3] 인터럽트 발생, sleep interrupted