문제
나의 요약
N개의 소문자로 된 단어가 주어진다. 이들 중 접두사의 길이가 가장 긴 두 단어를 찾아 출력하자. 여러개일 경우에는 먼저 위치한 접두사의 단어들부터 출력하자.
접근방법
보자마자 Trie 자료구조가 생각났다. Trie 자료구조의 형태는 다음 사진을 보면 쉽게 알 수 있다
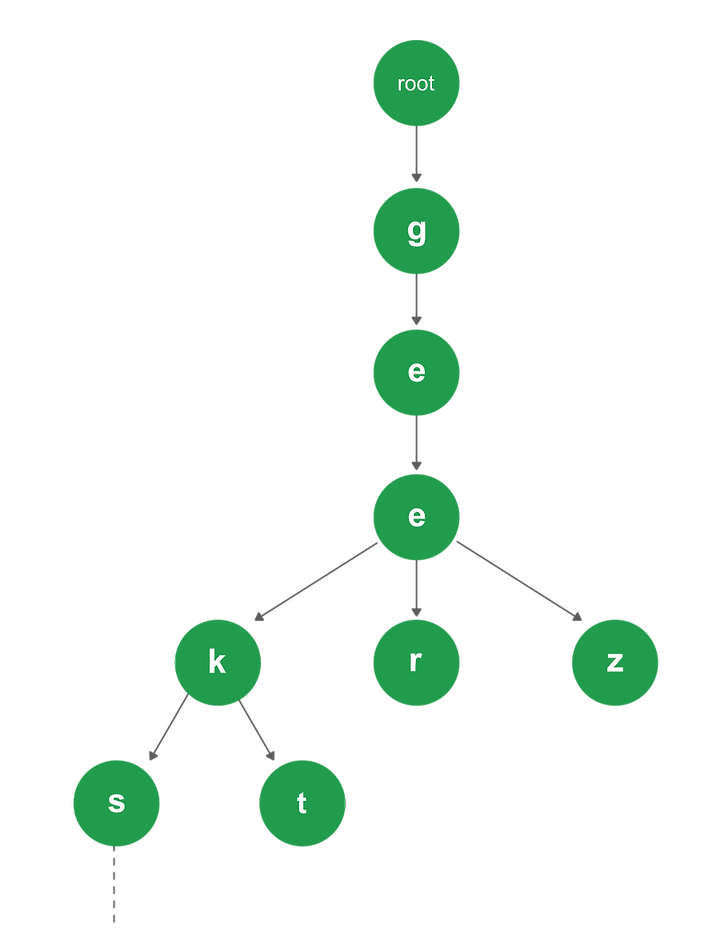
만약 'geeks', 'geekt', 'geer', 'gez'의 단어가 있다면, 위와 같이 표현된다.
마치 문자열들을 문자로 쪼개 트리를 구성하는 것과 같다.
우리는 가장 긴 접두사를 찾아야했기 때문에, Trie 자료구조를 활용해 각 노드의 '자식 수'를 이용할 것이다. 자식 수가 2 이상이라면, 이 접두사를 지닌 단어가 2개 이상이라는 뜻이다.
우리는 단어들을 Trie 자료구조에 집어넣고, 트리를 탐색하며 자식 수가 2 이상인 가장 깊이가 깊은 노드를 찾으면 된다. 루트부터 그 노드까지가 이루는 단어가 곧 접두사이다. 접두사를 찾으면, 그 이후에 그 접두사를 가진 단어들을 순서대로 탐색해 출력해주면 된다.
풀이
#include <bits/stdc++.h>
using namespace std;
typedef struct Node{
char value;
int count;
unordered_map<char, Node*> children;
}Node;
unordered_map<char, Node*> trie;
int N;
vector<string> strs;
void Input()
{
for(int i = 0; i < 26; i++)
{
Node* node = new Node();
node->value = 'a' + i;
node->count = 0;
trie['a' + i] = node;
}
cin >> N;
set<string> strsSet;
for(int i = 0; i < N; i++)
{
string s;
cin >> s;
strs.push_back(s);
strsSet.insert(s);
}
for(const string& s : strsSet)
{
Node* parentNode = trie[s[0]];
parentNode->count++;
for(int j = 1; j < s.length(); j++)
{
if(parentNode->children.count(s[j]) == 0)
{
Node* newNode = new Node();
newNode->value = s[j];
newNode->count = 1;
parentNode->children[s[j]] = newNode;
}
else
{
parentNode->children[s[j]]->count++;
}
parentNode = parentNode->children[s[j]];
}
}
}
void Solve()
{
int prefixLength = 0;
string prefix;
for(int i = 0; i < strs.size(); i++)
{
char firstChar = strs[i][0];
stack<pair<Node*, string>> st;
string pre(1, firstChar);
st.push({trie[firstChar], pre});
while(!st.empty())
{
Node* nowNode = st.top().first;
string nowPrefix = st.top().second;
st.pop();
if(nowPrefix.length() > prefixLength && nowNode->count >= 2)
{
prefix = nowPrefix;
prefixLength = nowPrefix.length();
}
for(const pair<char, Node*>& child : nowNode->children)
{
if(child.second->count >= 2)
{
st.push({child.second, nowPrefix + child.first});
}
}
}
}
if(prefixLength == 0)
{
cout << strs[0] << '\n' << strs[1] << '\n';
return;
}
int count = 0;
for(const string& s : strs)
{
if(prefixLength > s.length()) continue;
bool isPrefix = true;
for(int j = 0; j < prefixLength; j++)
{
if(prefix[j] != s[j])
{
isPrefix = false;
break;
}
}
if(isPrefix)
{
cout << s << '\n';
count++;
}
if(count == 2) break;
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
Input();
Solve();
}상당히 코드가 길다.. 짧게 풀이를 요약하자면,
1. 단어들을 입력받아 중복되는 단어는 제외하고 trie에 알맞게 저장한다.
2. trie를 순회하며 '자식의 수'가 2 이상인 가장 깊은 노드를 찾아 접두사를 만든다. (이때 순회하는 순서는 입력받은 순서대로 진행한다.)
3. 만약 접두사가 없다면, 그냥 첫번째 두번째 단어를 출력한다.
4. 접두사가 있다면 단어들을 순서대로 비교해 접두사를 가진 단어들을 출력한다. 2개를 출력했다면 종료한다.
회고
생각보다 처음 생각했던 대로 풀이가 잘 진행되었다. Trie 자료구조 자체를 알고나서는 처음 구현해보는 것이라, 좀 간소화된 측면도 있고 내멋대로 바꾼 점도 있었다.
풀이 자체는 맞았지만 작동시간이 1초 가까이 걸려서 다른 사람의 풀이를 보니, 그냥 사전순으로 정렬시켜서 인접한 두 단어를 비교해 접두사를 구하는 경우도 있었다. 이게 훨씬 편해보이긴 한다... 쓸데없이 어렵게 푼 느낌이 있지만 그래도 Trie 자료구조를 대략 구현해봤다는 것에 의의를 두자.
