개요
한국 시간으로 2024년 3월 20일 오전 3시, Stardew Valley 1.6이 업데이트되었다. 이에 따라 Stardew Valley의 유틸리티 웹 앱인 xnb.js와 stardew dressup의 업데이트가 불가피해졌다. Stardew Valley 1.6 업데이트가 xnb.js와 stardew dressup에 미치는 영향은 다음과 같다.
- xnb.js
- 대규모의 xnb 데이터 포맷 변경
- stardew valley가 사용하는 Data를 담은 xnb 파일이 더 이상 {string: string} 형의 딕셔너리 자료형이 아닌, c# 객체를 담은 커스텀 자료구조 포맷으로 변경되었다.
- 대규모의 xnb 데이터 포맷 변경
- stardew dressup
- 신규 모자, 상의, 악세서리 추가
- 체형 스프라이트 변경
따라서, 거의 2년 만에 xnb.js와 stardew dressup을 업데이트하기로 결정했다.
문제 상황
에릭 바론, 이게 맞아요?
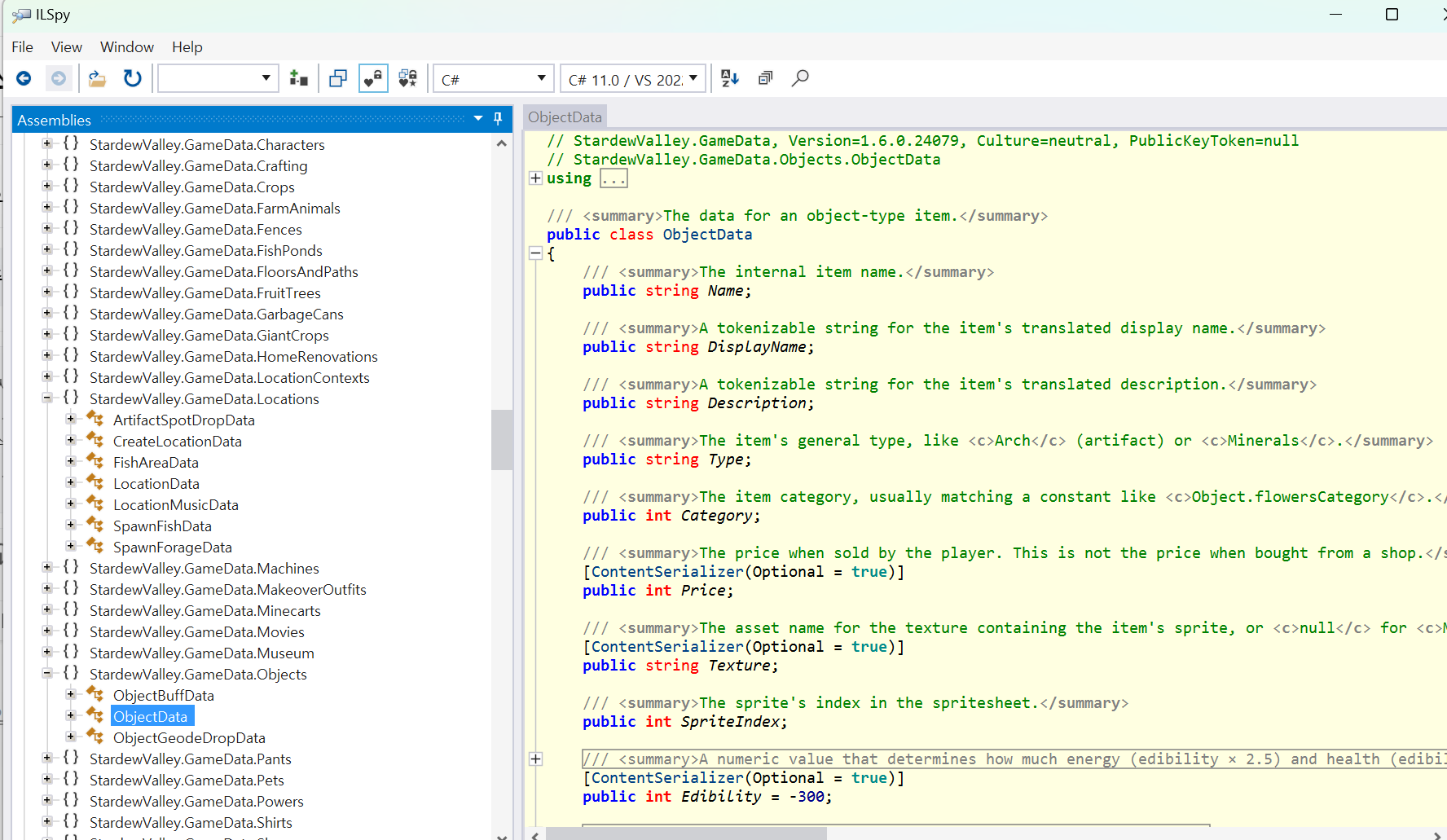
Stardew Valley 1.6에서는 수많은 양의 데이터를 저장하는 새로운 클래스들이 생겼다. 1.5까지는 클래스의 양이 적었기 때문에, 다음의 방식으로 코드를 추가했었다.
import {BaseReader,
ListReader,
Int32Reader,
StringReader,
DictionaryReader,
NullableReader
} from "../../readers/readers.js"; //@xnb/readers
import FishPondRewardReader from "./FishPondRewardReader.js";
/**
* FishPondData Reader
* @class
* @extends BaseReader
*/
export default class FishPondDataReader extends BaseReader {
static isTypeOf(type) {
switch (type) {
case 'StardewValley.GameData.FishPond.FishPondData':
return true;
default: return false;
}
}
static parseTypeList() {
return ["FishPondData",
"List<String>", "String", // requiredTags
null, // spawnTime
"List<FishPondReward>", ...FishPondRewardReader.parseTypeList(), //producedItems
"Nullable<Dictionary<Int32,List<String>>>:4",
"Dictionary<Int32,List<String>>", "Int32", "List<String>", "String" //populationGates
];
}
static type()
{
return "Reflective<FishPondData>";
}
/**
* Reads FishPondData from buffer.
* @param {BufferReader} buffer
* @param {ReaderResolver} resolver
* @returns {object}
*/
read(buffer, resolver) {
const int32Reader = new Int32Reader();
const stringListDictReader = new NullableReader( new DictionaryReader(
new Int32Reader(),
new ListReader( new StringReader() )
) );
const RequiredTags = resolver.read(buffer);
const SpawnTime = int32Reader.read(buffer);
const ProducedItems = resolver.read(buffer);
const PopulationGates = stringListDictReader.read(buffer, resolver);
return {
RequiredTags,
SpawnTime,
ProducedItems,
PopulationGates
};
}
write(buffer, content, resolver) {
const stringListReader = new ListReader( new StringReader() );
const int32Reader = new Int32Reader();
const fishPondRewardListReader = new ListReader( new FishPondRewardReader() );
const stringListDictReader = new NullableReader( new DictionaryReader(
new Int32Reader(),
new ListReader( new StringReader() )
) );
this.writeIndex(buffer, resolver);
stringListReader.write(buffer, content.RequiredTags, resolver);
int32Reader.write(buffer, content.SpawnTime, null);
fishPondRewardListReader.write(buffer, content.ProducedItems, resolver);
stringListDictReader.write(buffer, content.PopulationGates, resolver);
}
isValueType() {
return false;
}
}c# 클래스를 기반으로, 읽기 함수, 쓰기 함수, parseTypeList(언팩한 json을 yaml 포맷으로 바꾸는 데 annotation을 붙이는 데 필요하다)를 일일이 작성하고, 이를 클래스로 만들어야 했다. 1.5까지는 커스텀 자료구조를 저장하는 xnb 파일이 별로 없어서 전통적인 방식을 유지해도 상관이 없었으나, 1.6에서 대규모의 커스텀 자료구조 xnb 파일이 추가되면서, 전통적인 방식을 고수하면 유지보수하기 매우 어려울 것이라는 생각이 들었다.
따라서, 타입 구조 객체를 받아서 위와 같은 코드로 동작하는 xnb 리더를 만들기로 결정했다.
공통점 파악
using Microsoft.Xna.Framework.Content;
using System.Collections.Generic;
namespace StardewValley.GameData.FishPond
{
public class FishPondData
{
public List<string> RequiredTags;
[ContentSerializer(Optional = true)]
public int SpawnTime = -1;
public List<FishPondReward> ProducedItems;
[ContentSerializer(Optional = true)]
public Dictionary<int, List<string>> PopulationGates;
}
}read(buffer, resolver) {
const int32Reader = new Int32Reader();
const stringListDictReader = new NullableReader( new DictionaryReader(
new Int32Reader(),
new ListReader( new StringReader() )
) );
const RequiredTags = resolver.read(buffer);
const SpawnTime = int32Reader.read(buffer);
const ProducedItems = resolver.read(buffer);
const PopulationGates = stringListDictReader.read(buffer, resolver);
return {
RequiredTags,
SpawnTime,
ProducedItems,
PopulationGates
};
}위는 원본 c# 클래스이며, 아래는 해당 c# 클래스의 인스턴스를 저장하는 xnb 파일을 불러오는 read 함수다. 클래스의 필드명이 언팩 객체의 필드명이 되며, [ContentSerializer(Optional = true)]가 붙은 필드는 nullable로 감싸주고 있다.
resolver(xnb 파일의 헤더를 읽어와 필요한 reader를 선언한다)에 정의되지 않은, 원시 자료형 reader나, nullable reader는 따로 리더 인스턴스를 선언한 뒤 이를 기반으로 읽기 과정을 수행하며, 그렇지 않은 경우 resolver에 읽기 과정을 맡긴다.
잘 생각해 보면, 미리 객체의 key와 reader를 대응시킨 map을 만든 뒤 이를 순회하면 해결할 수 있을 것 같다.
read(buffer, resolver) {
const result = {};
for(let [key, reader] of this.readers.entries())
{
if(reader.isValueType()) result[key] = reader.read(buffer);
else if(reader.constructor.type() === "Nullable") result[key] = reader.read(buffer, resolver);
else result[key] = resolver.read(buffer);
}
return result;
}이렇게 변환할 수 있다. write 역시 비슷한 방식으로 바꿀 수 있다.
문제는 타입 데이터를 기반으로 커스텀 reader를 생성하는 것에 있었는데...
접근 과정
분석 결과, 커스텀 클래스형 자료구조 플러그인은 ReflectiveReader를 사용하고 있었으며, ReflectiveReader의 하위 데이터로 C# 클래스를 갖는 것을 확인할 수 있다. 이를 기반으로, 타입을 정리한 scheme 객체를 이용해 해당 타입 구조를 언팩하고 패킹할 수 있는 ReflectiveReader를 반환하기로 결정한다.
xnb.js가 xnb 파일을 언팩하는 과정은 다음과 같다.
- lz4 혹은 lzx로 압축된 파일의 압축을 해제한다.
- 헤더 부분의 유효성을 확인하고, 헤더 데이터를 추출한다.
- 리더 데이터를 읽어온다.
- 문자열로 된 리더 데이터를 기반으로,
TypeReaderstatic 클래스에서 문자열로 된 리더를 실제 객체 리더로 변환한다. - 실제 리더 객체 리스트를 기반으로, 데이터를 언팩한다.
xnb.js가 문자열로 된 리더를 실제 객체로 변환하는 과정은 다음과 같다.
- 생 문자열로 된 리더를 간략화한다. 이 과정은 디버깅에도 쓰이지만, 리더 객체를 빠르게 찾거나, yaml로 변환할 때 타입을 첨부하는 데에도 쓰인다.
- 간략화된 문자열을 기반으로 실제 리더 객체를 반환한다.
예시로, Microsoft.Xna.Framework.Content.DictionaryReader`2[[System.String, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089],[StardewValley.GameData.Fences.FenceData, StardewValley.GameData, Version=1.6.1.24080, Culture=neutral, PublicKeyToken=null]] 문자열은 Dictionary<String, StardewValley.GameData.Fences.FenceData> 로 간략화되고, 다시 이것이 new DictionaryReader(new StringReader(), new FenceDataReader()) 로 바뀌는 형태다.
처음에는 ReflectiveReader를 상속하는 별도의 클래스를 만들거나, ReflectiveReader를 반환하는 함수를 reader 라이브러리에서 만들까 생각했지만, 전자의 경우는 유연성이 떨어질 것으로 예상되며, 후자의 경우는 reader 라이브러리에서 현재 임포트된 reader를 알기 위해 core 라이브러리를 참조하게 되는 경우가 있어서, core 라이브러리의 TypeReader 클래스, 즉 문자열 리더를 기반으로 실제 리더를 반환시키는 것을 담당하는 클래스를 수정하기로 결심했다.
TypeReader 클래스는 다음과 같은 수정과정을 거쳤다.
simplifyType,getReader메소드는 ReflectiveReader / ReflectiveScheme 문자열이 감지되면, 하위 타입을 기반으로ReflectiveScheme<${simple}>/ReflectReader객체를 반환한다. 이 때, 하위호환성을 위해 이미 ReflectedReader를 커스텀 리더 클래스로 구현한 경우 그것을 우선시한다.simplifyType,getReader메소드는 알 수 없는 문자열이 감지되면 해당 클래스를 지원하는 schemes가 있는지 감지하고, 있으면ReflectiveScheme<${simple}>/ReflectReader객체를 반환한다.- 커스텀 타입 구조를 임포트할 수 있는
setSchemes,addSchemesAPI를 추가했다. 이 때, 임포트를 진행할 때 미리 임포트한 객체를 실제 Reader 객체로 변환시킨다. - scheme을 reader로 변환시키는 코드는 다음과 같다.
function convertSchemeEntryToReader(scheme)
{
if(typeof scheme === "string") return TypeReader.getReader(scheme);
if(Array.isArray(scheme)) {
const ListReader = TypeReader.getReaderClass("ListReader");
return new ListReader(convertSchemeEntryToReader(scheme[0]));
}
if(typeof scheme === "object") {
const keyCount = Object.keys(scheme).length;
if(keyCount === 1) {
const DictionaryReader = TypeReader.getReaderClass("DictionaryReader");
const [key, value] = Object.entries(scheme)[0];
return new DictionaryReader(
convertSchemeEntryToReader(key),
convertSchemeEntryToReader(value)
);
}
else if(keyCount > 1) {
return convertSchemeToReader(scheme);
}
}
throw new XnbError(`Invalid Scheme to convert! : ${scheme}`);
}
function convertSchemeToReader(scheme)
{
const result = new Map();
for(let [key, type] of Object.entries(scheme))
{
let reader = convertSchemeEntryToReader(type);
if(key.startsWith("@")) {
key = key.slice(1);
if(!reader.isValueType()) {
try {
reader = new TypeReader.readers.NullableReader(reader);
}
catch {
throw new XnbError("There is no NullableReader from reader list!");
}
}
}
result.set(key, reader);
}
return result;
}- scheme 오브젝트의 key, value를 순회한다.
- value를 기반으로 리더를 반환하는데,
- value가 문자열이면 해당 타입과 일치하는 reader 객체를 반환한다.
- value가
["Type"]형태면 reader 객체를 ListReader로 감싼다. - value가
{"KeyType" : "ValueType"}형태면 reader 객체를 DictionaryReader로 감싼다. - 그 밖의 경우, 재귀적으로 실행한다.
- 만약 key가
@key타입인 경우, 해당 key는 optional 필드이다.- NullableReader로 reader 객체를 감싼다.
- 만약 reader 객체가 primitive 자료형을 다루는 객체인 경우, 해당 객체는 nullable로 감싼 형태로 패킹되지 않으므로, reader 객체를 감싸지 않는다.
- value를 기반으로 리더를 반환하는데,
- 변환된 key와 value를 map 객체에 저장한다. map 객체에 저장하는 까닭은 map 객체는 추가한 순서를 보장하므로, 필드의 순서가 중요한 xnb 언팩에 적합하기 때문이다.
이를 기반으로, reflectiveReader는 이름과 readers를 기반으로 다음의 언팩/패킹 과정을 거치게 된다.
/**
* Reflective Reader
* @class
* @extends BaseReader
*/
export default class ReflectiveSchemeReader {
static isTypeOf(type) {
return false;
}
static hasSubType() {
return false;
}
static type()
{
return "ReflectiveScheme";
}
/**
* @constructor
* @param {Object} object scheme
*/
constructor(name, readers) {
this.name = name;
this.readers = readers;
}
/**
* Reads Reflection data from buffer.
* @param {BufferReader} buffer
* @returns {Mixed}
*/
read(buffer, resolver) {
const result = {};
for(let [key, reader] of this.readers.entries())
{
if(reader.isValueType()) result[key] = reader.read(buffer);
else if(reader.constructor.type() === "Nullable") result[key] = reader.read(buffer, resolver);
else result[key] = resolver.read(buffer);
}
return result;
}
/**
* Writes Reflection data and returns buffer
* @param {BufferWriter} buffer
* @param {Number} content
* @param {ReaderResolver} resolver
*/
write(buffer, content, resolver) {
this.writeIndex(buffer, resolver);
for(let [key, reader] of this.readers.entries())
{
reader.write(buffer, content[key], (reader.isValueType() ? null : resolver));
}- read 함수는 readers의 entries를 순회해, reader가 value 타입이거나 nullable 타입이면 reader 객체를 이용해 데이터를 가져오고, 그렇지 않으면 미리 정의된 resolver를 이용해 데이터를 가져온다. 불러온 데이터를 기반으로 result 객체에 저장한다.
- write 함수는 index를 먼저 저장한 뒤, readers의 entries를 순회해, reader가 원시 타입이면 resolver 매개변수에 null을, 그렇지 않으면 resolver 객체를 인자로 넣어 reader를 이용해 값을 쓴다.
- resolver 매개변수에 원시 타입 여부를 구분하는 까닭은, xnb 포맷이 원시 타입 데이터를 저장하기 전에 사용하는 리더의 인덱스를 저장하지 않기 때문이다.
향후 개발사항
- 잠재적으로 특정 c# 클래스의 프로퍼티 타입이 다른 c# 클래스를 참조할 수 있다. 해당 부분은 고려가 필요할 것.
- 아직 yaml을 대응하기 위한
parseTypeList함수를 안 만들었다. 곧 만들 예정.
