# 정적 웹 페이지 크롤링 준비
* 파싱 : HTML 구조를 분석하는 작업 -> BeautifulSoup 라이브러리 사용
1. BeautifulSoup 연습하기1
- 라이브러리 설치
pip install beautifulsoup4- BeauitfulSoup을 임포트하여 사용
from bs4 import BeautifulSoup- 연습용 html을 작성한다.
html = '<h1 id="title">한빛출판네트워크</h1><div class="top"><ul class="menu"><li><a href="http://www.hanbit.co.kr/member/login.html" class="login">로그인</a></li></ul><ul class="brand"><li><a href="http://www.hanbit.co.kr/media/">한빛미디어</a></li><li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li></ul></div>'- BeautifulSoup 객체를 생성한다.
soup = BeautifulSoup(html, 'html.parser')- 객체에 저장된 html 내용을 확인한다.
print(soup.prettify()): 3에서는 분석할 HTML의 실제 웹페이지를 사용하지 않고 html 구조를 작성한 문자열을 사용한다.
: BeautifulSoup을 사용하기 위해 4에서 객체를 생성한다.
: BeautifulSoup() 생성자 함수의 첫 번째 매개변수로는 분석할 HTML을 저장한 문자열 객체인 html을 지정하고 두 번째 매개변수로는 사용할 분석기를 지정한다.
: 5에서 prettify() 함수를 사용하여 객체 soup에 저장된 내용을 HTML 문서 형태로 출력하여 확인한다.
2. BeautifulSoup 연습하기2
- 태그 파싱하기
: 지정된 한 개의 태그만 파싱한다.
>>> soup.h1
>>> tag_h1 = soup.h1
>>> tag_h1
>>> tag_div = soup.div
>>> tag_div
>>> tag_ul = soup.ul
>>> tag_ul
>>> tag_li = soup.li
>>> tag_li
>>> tag_a = soup.a
>>> tag_a- 지정된 태그를 모두 파싱하여 리스트를 구성
>>> tag_ul_all = soup.find_all("ul")
>>> tag_ul_all
>>> tag_li_all = soup.find_all("li")
>>> tag_li_all
>>> tag_a_all = soup.find_all("a")
>>> tag_a_all- 다음과 같은 속성을 이용하여 파싱할 수도 있다.
1) attrs : 속성 이름과 속성값으로 딕셔너리 구성
2) find() : 속성을 이용하여 특정 태그 파싱
3) select() : 지정한 태그를 모두 파싱하여 리스트 구성
- 태그#id 속성값
- 태그.class 속성값
>>> tag_a.attrs
>>> tag_a['href']
>>> tag_a['class']
>>> tag_ul_2 = soup.find('ul', attrs={'class':'brand'})
>>> tag_ul2
>>> title = soup.find(id="title")
>>> title
>>> title.string
>>> li_list = soup.select("div>ul.brand>li")
>>> li_list
>>> for li in li_list:
print(li.string)# 정적 웹 페이지 크롤링 실습
1. 크롤링 허용 여부 확인하기
: 웹 페이지를 크롤링하기 전에 크롤링 허용 여뷰를 확인하기 위해 주소 창에 '크롤링한 주소/robots.txt'를 입력해본다.
: robots.txt는 검색 엔진이나 웹 크롤러 등의 웹 로봇이 사이트를 방문했을 때 사이트의 수집 정책을 알려주기 위해 사용한다.
: robots.txt 파일이 없다면 수집 크롤링 가능
| 표시 | 허용 여부 |
|---|---|
| User-agent: Allow: / 또는 User-agent: Disallow: | 모든 접근 허용 |
| User-agent:* Disallow: / | 모든 접근 금지 |
| User-agent:* Disallow: /user/ | 특정 디렉토리만 접근 금지 |
2. 웹 페이지 분석하기
: 할리스커피의 전국 매장 정보를 크롤링
- 매장 정보 찾기
: 할리스커피 홈페이지 -> Store 클릭 - HTML 코드 확인하기
: Ctrl + U를 누르면 웹 페이지에 대한 HTML 소스 보기 창이 열림
: HTML 코드 522번 줄의 < tbody > 태그가 매장 정보 테이블이다.
 : 각 매장에 대한 정보는 < tr > ~에 있다.
: 각 매장에 대한 정보는 < tr > ~에 있다.
: td[0]는 매장이 있는 지역, td[1]는 매장 이름, td[3]는 매장 주소, td[5]는 매장 전화번호이다. - 나머지 매장 정보 확인하기
: 현재 페이지는 10개 매장의 정보만 나타나 있음
: 다음 페이지 버튼을 클릭하여 다시 HTML 코드 확인 - 'pageNo=' 다음에 페이지 번호를 붙여서 페이지 주소를 생성하는 원리를 이용하여 웹 페이지 크롤링
3. 파이썬 셸 창에서 크롤링하기
- BeautifulSoup과 urllib.request를 임포트한다.
from bs4 import BeautifulSoup
import urllib.request- 작업 결과를 저장할 리스트를 준비한다.
result = []- BeautifulSoup 객체를 생성하여 파싱한다.
for page in range(1,59):
Hollys_url = 'https://www.hollys.co.kr/store/korea/korStore.do?pageNo=%d&sido=&gugun=&store=' %page
print(Hollys_url)
html = urllib.request.urlopen(Hollys_url)
soupHollys = BeautifulSoup(html, 'html.parser')
tag_tbody = soupHollys.find('tbody')
for store in tag_tbody.find_all('tr'):
if len(store) <= 3:
break
store_td = store.find_all('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
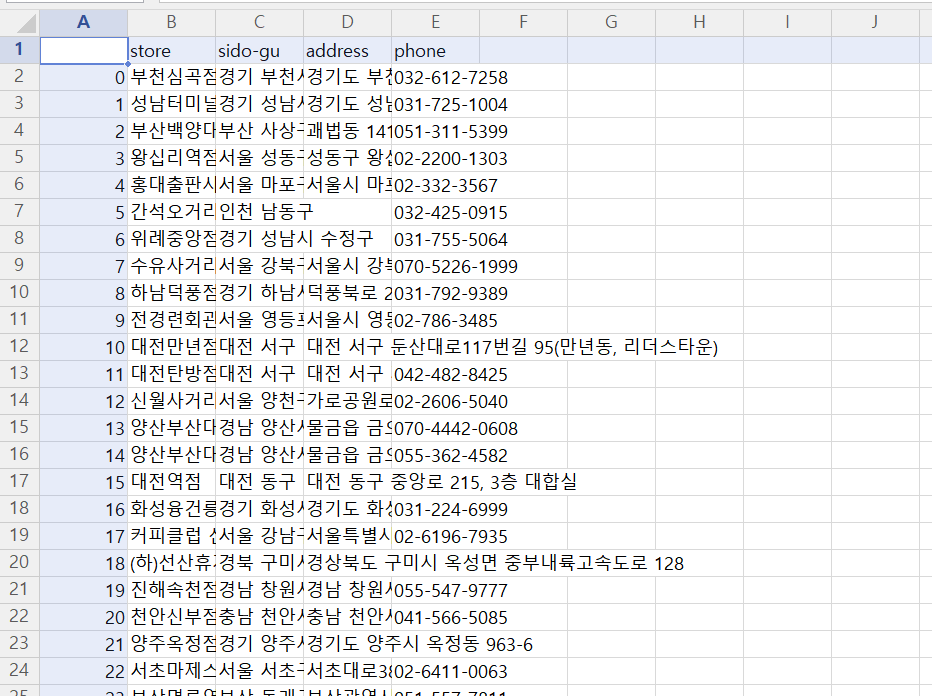
result.append([store_name]+[store_sido]+[store_address]+[store_phone])- 크롤링된 내용을 확인한다.
1) 결과가 저장된 result의 원소 개수 확인하기
2) 첫 번째 원소 확인하기
3) 마지막 원소 확인하기
4) 마지막 매장 정보가 저장되어 있는 store_td의 내용 확인하기
>>> len(result)
>>> result[0]
>>> result[565]
>>> store_td
>>> store_td[1].string
>>> store_td[0].string
>>> store_td[3].string
>>> store_td[5].string- 크롤링한 데이터 저장하기
pip install pandas- pandas를 임포트한다.
import pandas as pd- pandas를 사용하여 테이블 형태의 데이터프레임을 생성한다.
hollys_tbl = pd.DataFrame(result, columns=('store', 'sido-gu', 'address', 'phone'))- 테이블을 CSV 파일로 저장한다.
hollys_tbl.to_csv('./6장_data/hollys1.csv', encoding='cp949', mode='w', index=True)4. 파이썬 파일 작성하여 크롤링하기
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime
#[CODE 1]
def hollys_store(result):
for page in range(1,59):
Hollys_url = 'https://www.hollys.co.kr/store/korea/korStore.do?pageNo=%d&sido=&gugun=&store=' %page
print(Hollys_url)
html = urllib.request.urlopen(Hollys_url)
soupHollys = BeautifulSoup(html, 'html.parser')
tag_tbody = soupHollys.find('tbody')
for store in tag_tbody.find_all('tr'):
if len(store) <= 3:
break
store_td = store.find_all('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
result.append([store_name]+[store_sido]+[store_address]+[store_phone])
return
#[CODE 0]
def main():
result = []
print('Hollys store crawling >>>>>>>>>>>>>>>>>>')
hollys_store(result) #[CODE 1] 호출
hollys_tbl = pd.DataFrame(result, colums=('store', 'sido-gu', 'address', 'phone'))
hollys_tbl.to_csv('./6장_data/hollys1.csv', encoding='cp949', mode='w', index=True)
del result[:]
if __name__ = '__main__':
main()