Multinomial classification
ex) 성적(A,B,C)을 5명에게 부여할 때 표현은 아래와 같다.
1) A or not
2) B or not
3) C or not
: class file을 표현할 때 행렬로 구현
: 3가지 경우에 대해 독립적으로 구현하면 복잡
: 3가지 경우를 하나로 합침
Softmax Classifier의 Cost함수
: 0~1사이의 값을 가짐
: 전체 값의 합이 1 -> 확률로 볼 수 있음
: ONE-HOT ENCODING = 제일 큰 값을 1로 만들고 나머지는 0
: CROSS-ENTROPY - 예측값과 실제값의 차이를 구함.
Softmax Classifier
Sample dataset
x_data = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_data = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0],
[0, 1, 0],
[0, 1, 0],
[1, 0, 0],
[1, 0, 0]]
#convert into numpy and float format
x_data = np.asarray(x_data, dtype=np.float32)
y_data = np.asarray(y_data, dtype=np.float32)
nb_classes = 3 #num classesSoftmax function
: Softmax 함수는 여러 개의 클래스를 예측할 때 유용
: 확률 값의 총합은 반드시 1이 되어야 함
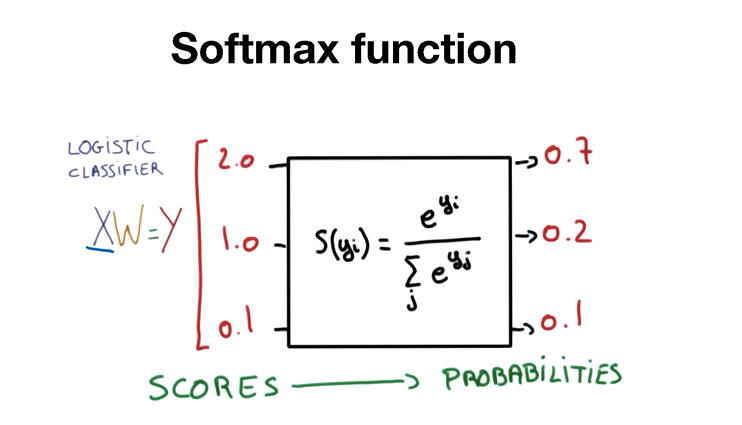
: 텐서플로우 코드 구현 방법
hypothesis = tf.nn.softmax(tf.matmul(X,W)+b)
# LOGISTIC CLASSFIER에 나와있는 부분에 대해서 텐서플로우의 matrix곱을 활용Softmax Function
#Weight and bias setting
W = tfe.Variable(tf.random_normal([4, nb_classes]), name='weight')
b = tfe.Variable(tf.random_normal([nb_classes]), name='bias')
variables = [W, b]
hypothesis = tf.nn.softmax(tf.matmul(x_data, W) + b)
# Softmax onehot test
sample_db = [[8,2,1,4]]
sample_db = np.asarray(sample_db, dtype=np.float32)
# Output
tf.Tensor([[0.9302204 0.06200533 0.00777428]], shape=(1, 3), dtype=float32)
Cost Function: cross entropy
# Cross entropy cost/Loss
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)Cost Function
def cost_fn(X,Y):
logits = hypothesis(X)
cost = -tf.reduce_sum(Y * tf.log(logits), axis=1)
cost_mean = tf.reduce_mean(cost)
return cost_mean
print(cost_fn(x_data, y_data))Gradient Function
def grad_fn(X, Y):
with tf.GradientTape() as tape:
cost = cost fn(X, Y)
grads = tape.gradient(cost, variables) # variables = [W, b]
return grads
print(grad_fn(x_data, y_data))Train
def fit(X, Y, epachs=2000, verbose=100):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
for i in range(epochs):
optimizer.apply_gradients(zip(grads, variables))
if (i==0) | ((i+1)%verbose==0):
print('Loss at epoch %d: %f' %(i+1, cost_fn(X,Y).numpy()))Prediction
a = hypothesis(x_data)
print(a)
print(tf.argmax(a, 1))
print(tf.argmax(y_data, 1)) # matches with y_dataSoftmax Classifier Animal Classification
Softmax function
hypothesis = tf.nn.softmax(tf.matmul(X,W)+b)
tf.matmul(X,W)+bSoftmax_cross_entropy_with_logits
# Cross entropy cost/Loss
cost_i = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels = Y_one_hot)
cost = tf.reduce_mean(cost_i)Sample Dataset
: Animal classification with softmax_cross_entropy_with_logits
# Predicting animal type based on various features
xy = np.loadtxt('data-04-zoo.csv', delimter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]tf.one_hot and reshape
nb_classes = 7 # 0 ~ 6
Y_one_hot = tf.one_hot(list(y_data), nb_classes) # one hot shape=(?, 1, 7)
Y_one_hot = tf.reshape(Y_one_hot, [-1, nb_classes]) # shape=(?, 7): one_hot의 rank가 N이면 그 아웃풋은 N+1이 된다.
Implementation - Load Dataset
# Predicting animal type based on various Features
xy = np.loadtxt('data-04-zoo.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
print(x_data.shape, y_data.shape)
nb_classes = 7 # 0 ~ 6
# Make Y data as onehot shape
Y_one_hot = tf.one_hot(list(y_data), nb_classes)
Y_one_hot = tf.reshape(Y_one_hot, [-1, nb_classes])Implementation - Softmax Classifier
#Weight and bias setting
W = tfe.Variable(tf.random_normal([16, nb_classes]), name='weight')
b = tfe.Variable(tf.random_normal([nb_classes]), name='bias')
variables = [W, b]
# tf.nn.softmax computes softmax activations
def logit_fn(X):
return tf.matmul(X,W) + b
def hypothesis(X):
return tf.nn.softmax(logit_fn(x))
def cost_fn(X, Y):
logits = logit_fn(X)
cost_i = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=Y)
cost = tf.reduce_mean(cost_i)
return cost
def grad_fn(X, Y):
with tf.GradientTape() as tape:
loss = cost_fn(X, Y)
grads = tape.gradient(loss, variables)
return grads
def prediction(X, Y):
pred = tf.argmax(hypothesis(X), 1)
correct_prediction = tf.equal(pred, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracyImplementation - Training
def fit(X, Y, epochs=500, verbose=50):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
for i in range(epochs):
grads = grad_fn(X, Y)
optimizer.apply_gradients(zip(grads, variables))
if (i==0) | ((i+1)%verbose==0):
acc = prediction(X, Y).numpy()
loss = tf.reduce_sum(cost_fn(X, Y)).numpy()
print('Loss & Acc at {} epoch {}, {}'.format(i+1, loss, acc))
fit(x_data, Y_one_hot)모두를 위한 딥러닝 시즌2 - Tensorflow
모두를 위한 딥러닝 시즌2 - Tensorflow
모두를 위한 딥러닝 시즌2 - Tensorflow
모두를 위한 딥러닝 시즌2 - Tensorflow
