# RNN
Sequence data
: 음성 인식, 자연어 등이 Sequence data의 예시
: 이전에 데이터들을 기반으로 현재의 데이터를 이해하는 것이 Sequene data이다.
: NN(Neural Network), CNN(Convolutional Neural Network)는 시리즈 데이터들을 처리하기 어려움.
 : 이전의 state가 다음 연산에 영향을 미치는 것이 시리즈 데이터에 가장 적합한 모델이다.
: 이전의 state가 다음 연산에 영향을 미치는 것이 시리즈 데이터에 가장 적합한 모델이다.
Recurrent Neural Network
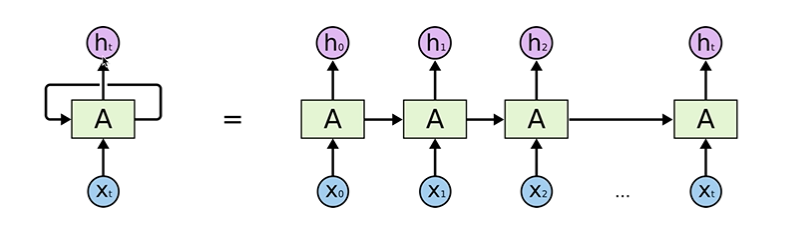
 : state를 계산하고 그 state가 자기 입력이 되는 형태
: state를 계산하고 그 state가 자기 입력이 되는 형태
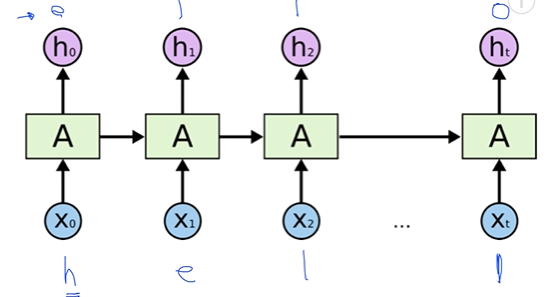
: RNN을 그림 하나로 나타내는 이유는 주어진 이전의 state와 현재 x값을 가지고 계산하는 function이 모든 RNN에 대해서 동일하기 때문이다.
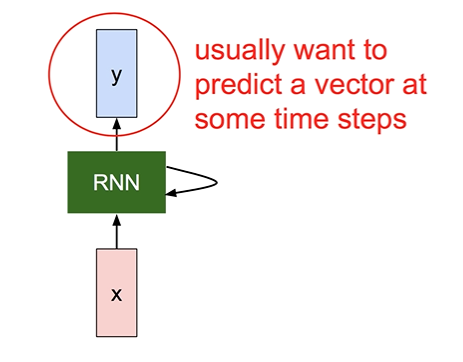
 : RNN의 state를 먼저 계산하고 그 state를 기반으로 y를 계산함
: RNN의 state를 먼저 계산하고 그 state를 기반으로 y를 계산함
(Vanilla) Recurrent Nerual Network
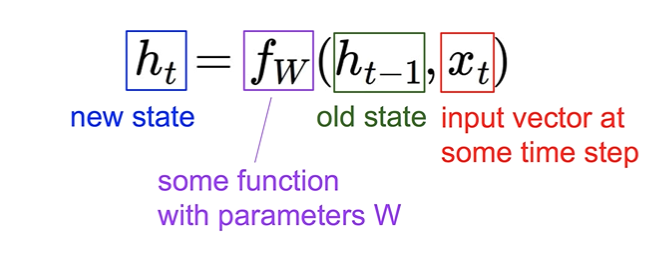
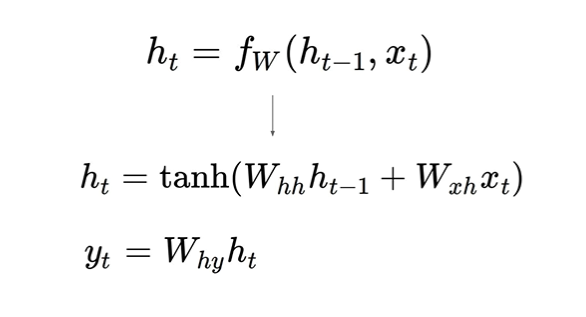 : 구체적인 RNN의 값들을 계산하는 가장 기본적인 연산 방법
: 구체적인 RNN의 값들을 계산하는 가장 기본적인 연산 방법
: h, x 입력에 대해 각각의 weight를 만들어 Wx 형태를 만들어줌.
: tanh(시그모이드와 같은 형태)에 넣어준 후 현재의 state를 계산
: 계산된 h에 다른 형태의 weight을 곱해주어 Wx 형태를 만들어줌.
: W가 어떤 형태의 vector인가에 따라 y가 몇개의 vector로 나올 것인지 결과가 달라짐.
Character-level language model example
Example training sequence: "hello"
 : 현재의 글자가 있을 때 다음 글자를 예측해주는 모델을 language-model이라고 함.
: 현재의 글자가 있을 때 다음 글자를 예측해주는 모델을 language-model이라고 함.
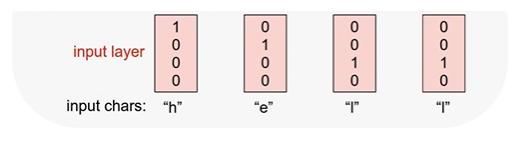 : 각각의 입력을 vector로 표현 -> one-hot encoding 방법
: 각각의 입력을 vector로 표현 -> one-hot encoding 방법
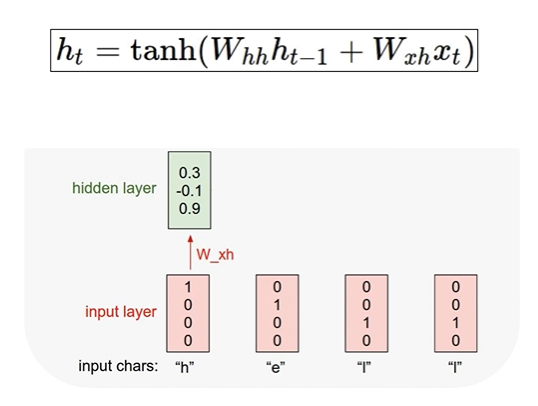 : RNN 셀에 입력 - 첫 번째로 입력할 것은 ht-1 값을 0으로 두고 공식으로 hidden state값을 계산 한 결과
: RNN 셀에 입력 - 첫 번째로 입력할 것은 ht-1 값을 0으로 두고 공식으로 hidden state값을 계산 한 결과
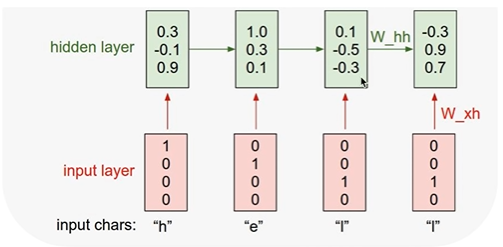
: 이후 위와 같은 연산 반복
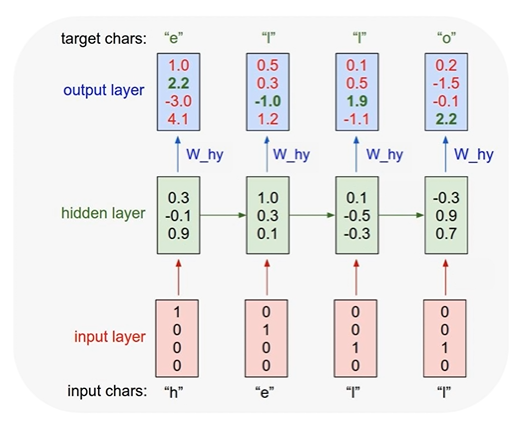 : 마지막으로 y를 뽑아낼 때 state값에 해당 값을 곱한다.
: 마지막으로 y를 뽑아낼 때 state값에 해당 값을 곱한다.
: Softmax를 취하게 되면 가장 큰 값이 해당하는 레이블이 된다. - 원하는 값과 실제 값이 다르면 error
: softmax에 해당되는 cost function 계산하고 평균내면 학습을 시킬 수 있음. - 다음 글자 예측 가능해짐
RNN applications
- Language Modeling
- Speech Recognition
- Machine Traslation
- Conversation Modeling/Question Answering
- Image/Video Captioning
- Image/Music/Dance Generation
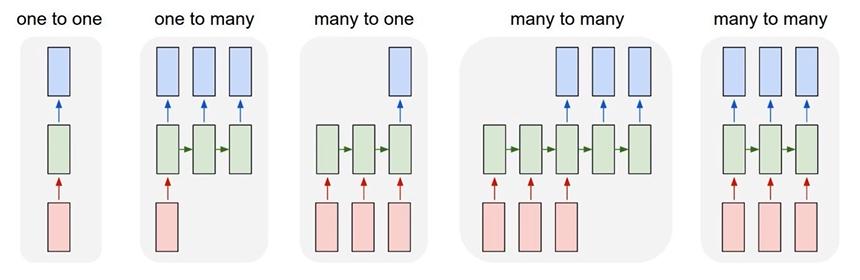
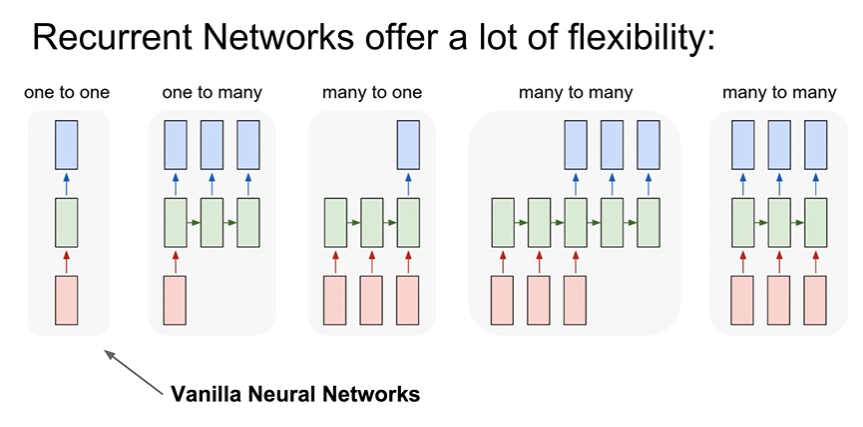 : RNN을 가지고 여러가지 형태로 구성할 수 있음
: RNN을 가지고 여러가지 형태로 구성할 수 있음
one to one - Vanilla Neural Networks
one to many - e.g.Image Captioning : Image-> sequence of words
many to one - e.g.Sentiment Classification : sequence of words -> sentiment
many to many - e.g.Maching Translation : seq of words -> seq of words
many to many - e.g.Video classification on frame level
Multi-Layer RNN
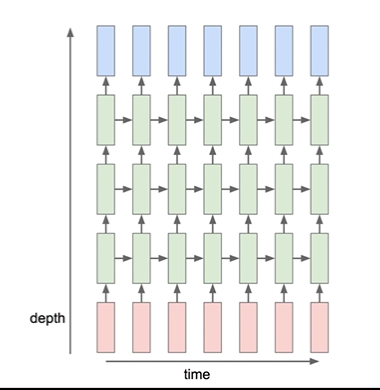 : RNN도 layer를 여러 개 둘 수 있다. - 더 복잡한 학습이 가능
: RNN도 layer를 여러 개 둘 수 있다. - 더 복잡한 학습이 가능
# rnn basics
RNN in Tensorflow 2.0
: tf keras에 포함된 API를 이용하여 아래 두 가지 방식으로 RNN을 구현할 수 있다.
: RNN, LSTM, GRU 등 특정 셀을 선언하고 이를 LOOP하는 코드를 활용
: 위 방법의 상위 코드 두 줄을 결합한 API를 활용

One cell: 4 (input-dim), 2 (hidden_size)
: 예제 데이터 h를 RNN이 처리하는 과정에 대한 그림
: input의 shape가 (Batch_size, Sequence_length, Input_dimension)으로 표현되도록 전처리 되어야 함
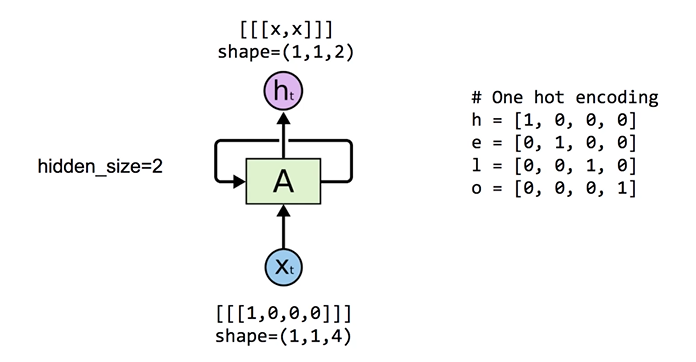
: 그림에 대한 코드 구현
 : outputs 변수 - 전체 sequence에 해당하는 hidden state값들을 가지고 있음
: outputs 변수 - 전체 sequence에 해당하는 hidden state값들을 가지고 있음
: states 변수 - sequence의 마지막 hidden state 값만 가지고 있음
Unfolding to n sequences
: sequence가 1이 아닌 데이터를 RNN으로 처리
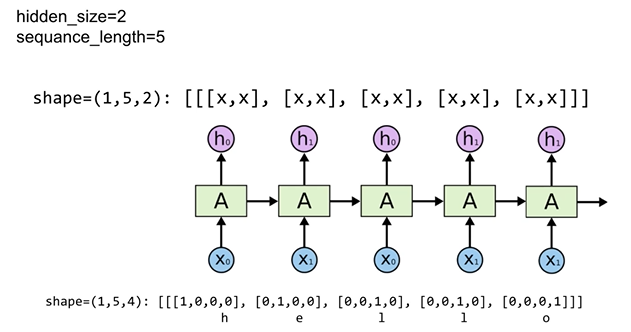
: 그림에 대한 코드 구현
 : outputs 변수 - 전체 sequence에 대한 hidden state값을 가지고 있음
: outputs 변수 - 전체 sequence에 대한 hidden state값을 가지고 있음
: states 변수 - sequence의 마지막 hidden state 값을 가지고 있음
Batching input
: sequence가 5인 데이터, 3개로 구성된 mini batch를 RNN으로 처리
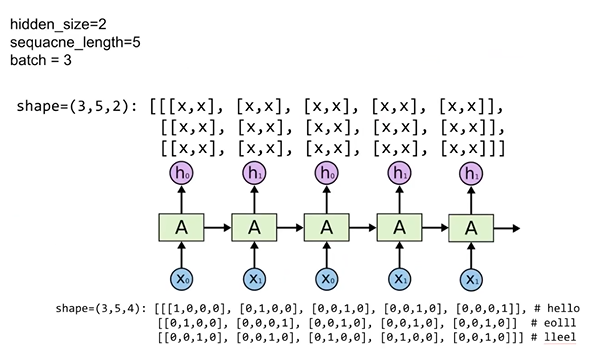
: 그림에 대한 코드 구현
 : outputs 변수 - mini batch를 구성하고 있는 각각의 데이터에 전체 sequence에 해당하는 hidden state값을 가지고 있음
: outputs 변수 - mini batch를 구성하고 있는 각각의 데이터에 전체 sequence에 해당하는 hidden state값을 가지고 있음
: states 변수 - mini batch를 구성하고 있는 각각의 데이터 sequence의 마지막 hidden state 값을 가지고 있음
# many to one
: RNN 다양하게 활용 가능
: one to many - Image Captioning
: many to many - Neural Machine Translation, 형태소 분석
: many to one - Sentiment Classification
What is "many to one"?
: sentence를 word의 sequence라고 생각하고 sentence를 word 단위로 분해할 수 있음
: sentence를 word 단위로 Tokenization 했다고 얘기함
: RNN을 활용하여 각각의 Token을 읽었을 때, polarity를 classification 방식으로 활용하는 것
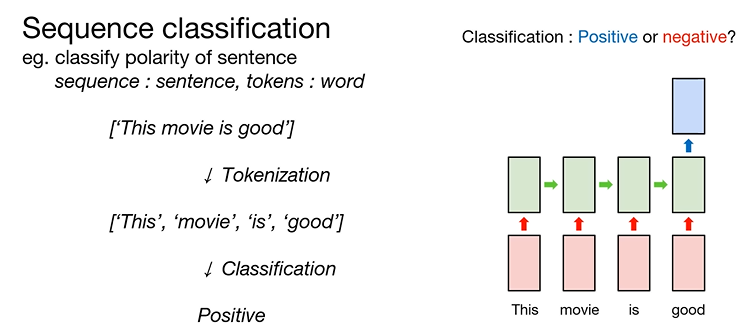
Example : word sentiment classification
: RNN을 many to one 방식으로 사용하여 modeling
: 1은 긍정, 0은 부정
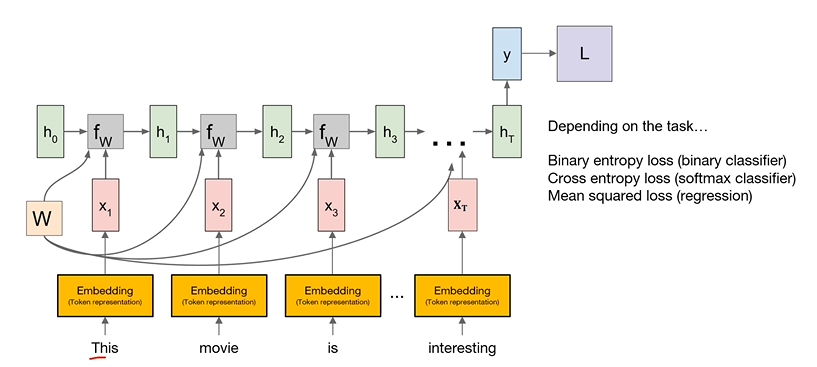
: 예제 데이터로 주어진 각각의 word를 character의 sequence로 간주함
: Token의 dictionary를 만들어야 함
: word를 character의 sequence로 간주했을 때, 각각의 sequence의 길이가 다르기 때문에 pad token 추가
 : pad sequence 함수는 기본적으로 0 값으로 데이터를 padding함
: pad sequence 함수는 기본적으로 0 값으로 데이터를 padding함 : embedding layer에서 simple RNN이 처리할 수 있도록 데이터를 (data dimension, max sequence, input dimension)형태로 처리
: embedding layer에서 simple RNN이 처리할 수 있도록 데이터를 (data dimension, max sequence, input dimension)형태로 처리
: 이를 RNN이 설정한 hidden size만큼의 vector로 처리
: 마지막으로 dense layer가 이를 classification 함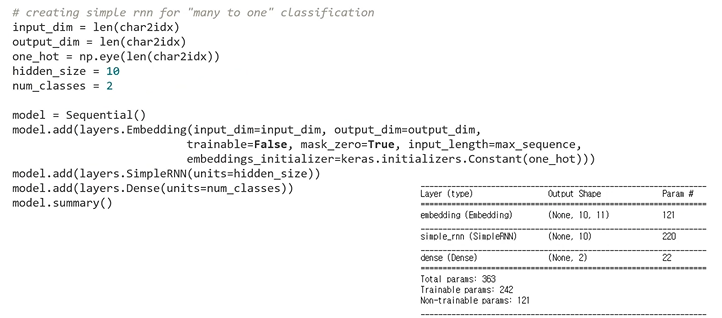 : 생성한 모델을 목적에 맞게 트레이닝 하기 위해서 다음과 같이 모델의 출력과 정답을 비교해주는 loss function 생성
: 생성한 모델을 목적에 맞게 트레이닝 하기 위해서 다음과 같이 모델의 출력과 정답을 비교해주는 loss function 생성
: 예제에서는 classification 문제를 풀고 있기 때문에 cross entropy
loss를 계산하는 함수를 사용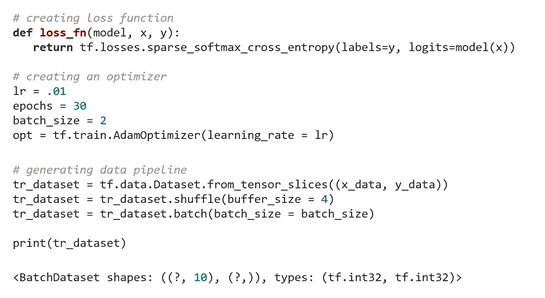 : model training
: model training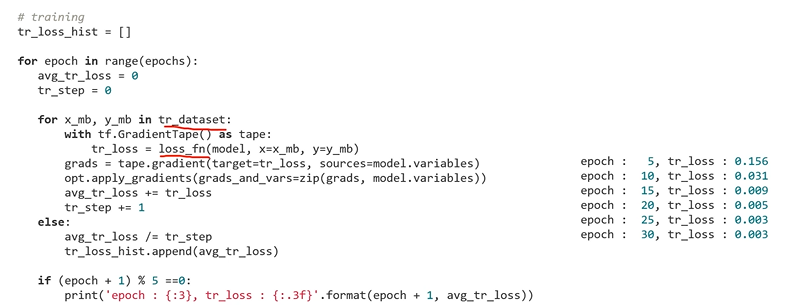 : 다음의 코드로 모델의 성능을 확인할 수 있음
: 다음의 코드로 모델의 성능을 확인할 수 있음
: training의 accuracy가 100%에 도달했음을 알 수 있음
: training의 history를 보았을 때 각 epoch마다 train loss가 계속 떨어지는 것을 확인할 수 있음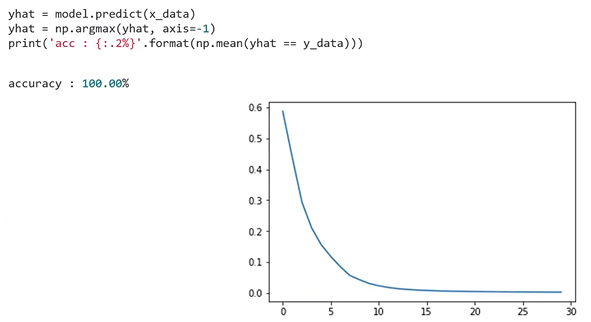
#many to one stacking
What is "stacking"?
: RNN도 recurrent NN를 여러 개 쌓을 수 있음
: multi layered RNN / stacked RNN
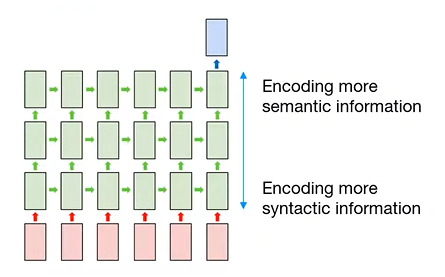
: 자연어 처리에서 stacked RNN 구조는 input에 가까운 RNN의 hidden state가 semantic information보다 syntactic information을 상대적으로 더 잘 encoding 하고 있음
: output에 가까운 RNN의 hidden state는 semantic information을 syntactic information보다 더 잘 encoding 하고 있음
many to one stacking
: RNN을 여러 개 활용하는 stacked RNN을 many to one 구조로 활용
: sequence를 Tokenization한 뒤 embedding layer를 거쳐서 어떤 numeric vector로 표현된 각각의 token을 stacked RNN이 순서대로 읽어들임
: RNN을 몇 개를 stacking 했느냐에 상관없이 동일하게 적용 된다.
: 마지막 token을 읽었을 때 나온 출력과 정답의 loss를 계산하고 이 loss로 stacked RNN을 backpropagation을 통해서 학습함
 : 각각의 token이 integer 인덱스와 mapping이 되어 있음을 확인할 수 있음
: 각각의 token이 integer 인덱스와 mapping이 되어 있음을 확인할 수 있음
 : 생성된 token dictionary를 기반으로 sentence를 integer 인덱스의 sequence로 변환할 수 있음
: 생성된 token dictionary를 기반으로 sentence를 integer 인덱스의 sequence로 변환할 수 있음
: 길이가 긴 sequence를 다룰 때에는 RNN보다 LSTM, GRU를 활용할 수 있음
 : stacked RNN 구조로 batch 단위의 데이터를 처리하기 위해서는 sentence의 sequence가 다른 문제를 해결해주어야 함
: stacked RNN 구조로 batch 단위의 데이터를 처리하기 위해서는 sentence의 sequence가 다른 문제를 해결해주어야 함
: 이를 위해서 pad_sequence funtion을 이용하여 max_sequence 변수가 가리키는 값만큼의 길이로 변환한 데이터를 padding 한다.
: pad_sequence funtion은 기본적으로 0 값으로 padding 함.
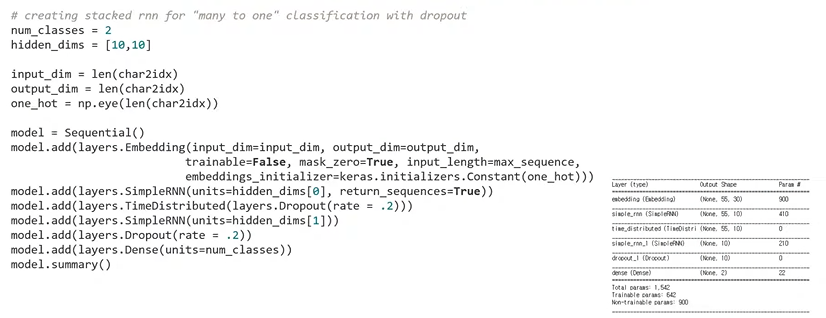 : RNN을 두 개 활용하는 stacked RNN을 many to one 방식으로 활용할 수 있음
: RNN을 두 개 활용하는 stacked RNN을 many to one 방식으로 활용할 수 있음
 : 생성한 model을 목적에 맞게 training하기 위해서 model의 출력과 정답을 비교해주는 loss function을 생성
: 생성한 model을 목적에 맞게 training하기 위해서 model의 출력과 정답을 비교해주는 loss function을 생성
: classification 문제를 풀고 있기 때문에 cross entropy loss를 계산하는 함수를 활용
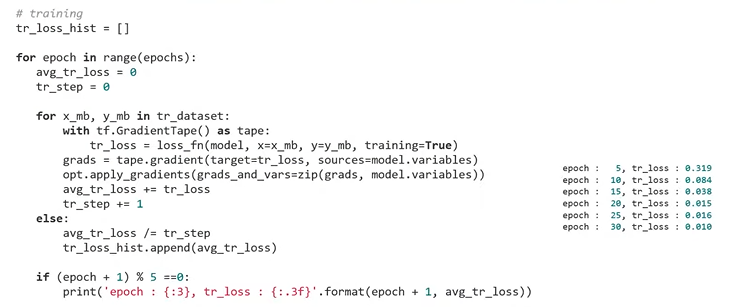 : model training
: model training
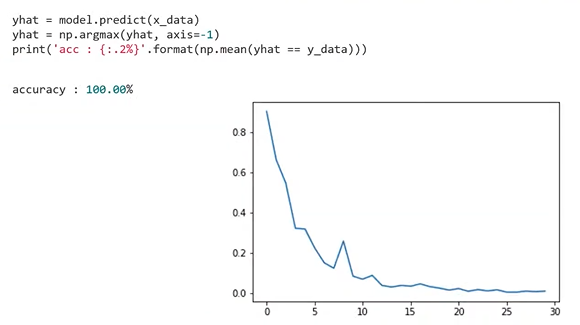 : 모델의 성능 확인 가능
: 모델의 성능 확인 가능
: train accuracy가 100%가 되었음을 확인할 수 있음
: epoch이 진행됨에 따라서 train loss가 감소하는 모습도 확인 가능
# many to many
What is "many to many"?
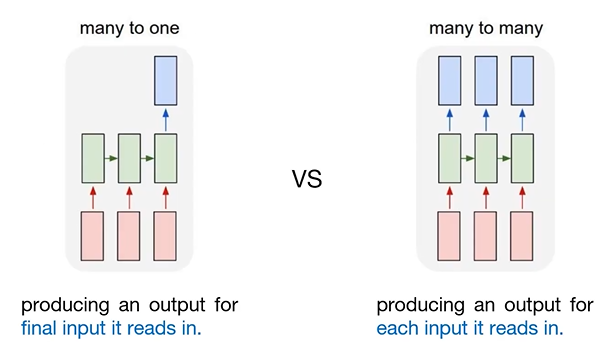
: many to one은 RNN이 sequence를 구성하고 있는 각각의 token을 읽어들이면서 특히 sequence의 마지막에 해당하는 token을 읽었을 때 출력을 내는 구조
: many to many는 RNN이 sequence를 구성하고 있는 각각의 token에 대해서 모두 출력을 내어주는 구조
 : 형태소 분석 예시
: 형태소 분석 예시
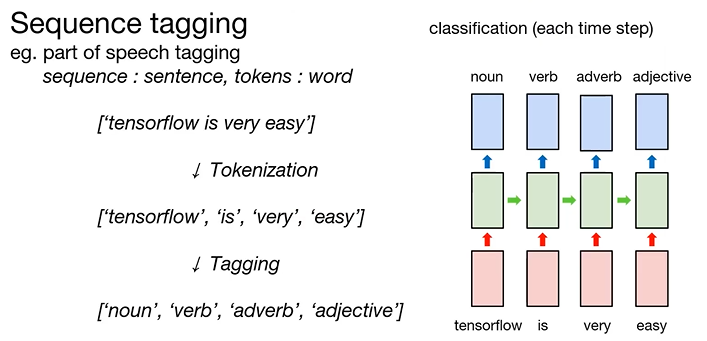 : token인 word는 숫자가 아니기 때문에 embedding layer를 이용하여 RNN이 처리할 수 있도록 numeric vector로 변환해야 함
: token인 word는 숫자가 아니기 때문에 embedding layer를 이용하여 RNN이 처리할 수 있도록 numeric vector로 변환해야 함
: RNN이 각각의 token을 순서대로 읽을때마다 token에 대한 출력을 내고 이를 정답과 비교하여 token마다 loss를 계산 함
: 모든 token에 대하여 계산된 loss를 평균을 냄 - sequence loss
: sequence loss로 RNN을 backpropagation할 수 있음
: masking - 데이터의 sequence를 구성하는 token들 중에서 길이를 맞추기 위해 존재할 뿐인 pad token에 대해서는 loss를 계산하지 않겠다는 것
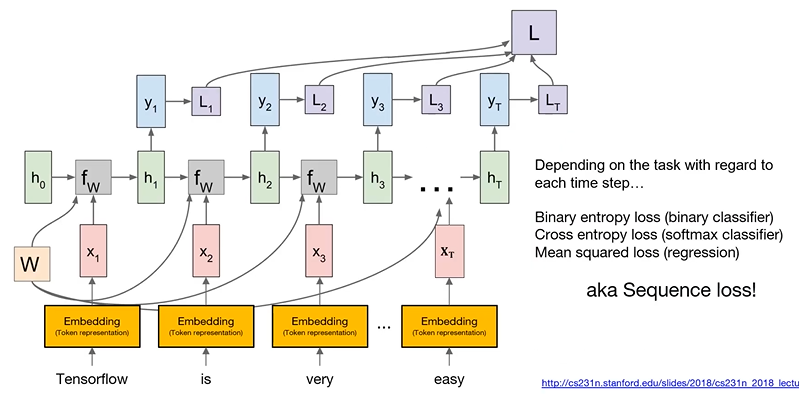
Example : part of speech tagging
: sentence를 word의 sequence로 간주하고 풀 것
: token인 word를 integer 인덱스로 mapping하고 있는 token의 dictionary를 만들어야 함
: 정답이 품사의 sequence 형태로 주어져 있기 때문에 품사를 integer 인덱스로 mapping하고 있는 dictionary 또한 만들어야 함
 : token dictionary 기반으로 word의 sequence를 integer 인덱스의 sequence로 변환
: token dictionary 기반으로 word의 sequence를 integer 인덱스의 sequence로 변환
: 정답인 품사를 integer 인덱스로 mapping하기 위해 만든 dictionary를 기반으로 품사의 sequence도 integer 인덱스의 sequence로 변환
: 각각의 integer 인덱스 sequence를 pad_sequence function을 이용하여 max_sequence가 가리키고 있는 값만큼의 길이로 padding 함
: masking을 위해서 각각의 sentence가 몇 개의 word로 tokenization 되었는지를 계산한 sentence의 유효한 길이 계산
: padding한 부분에 대한 masking 정보를 담고 있는 masking도 계산해줌
 : RNN을 many to many 방식으로 활용하는 구조 완성
: RNN을 many to many 방식으로 활용하는 구조 완성
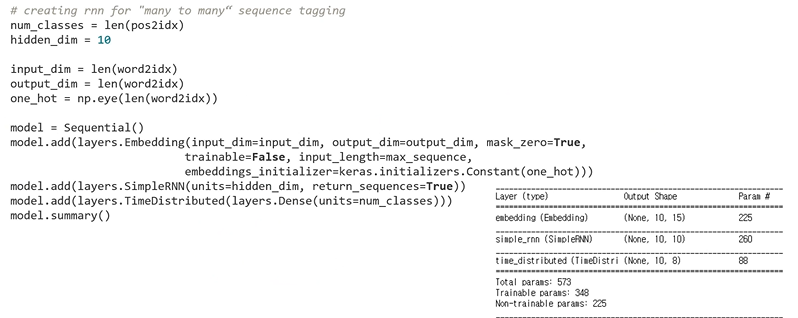 : 생성한 모델을 목적에 맞게 training 하기 위해서 model의 출력과 결과를 비교해주는 loss function 생성
: 생성한 모델을 목적에 맞게 training 하기 위해서 model의 출력과 결과를 비교해주는 loss function 생성
 : model training
: model training
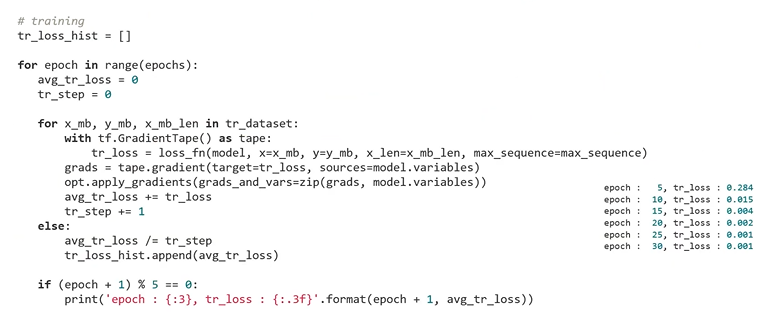 : part of speech tagging을 잘 하고 있는지 확인
: part of speech tagging을 잘 하고 있는지 확인

# many to many bidirectional
What is "bidirectional"?
: RNN을 모두 단방향으로만 활용
: RNN을 many to many 방식으로 활용할 때 각각의 token을 RNN이 읽을 때 정보의 불균형이 존재
: sequence를 순서대로 읽는 forward RNN, 역으로 읽는 backward RNN을 두어 문제점 해결
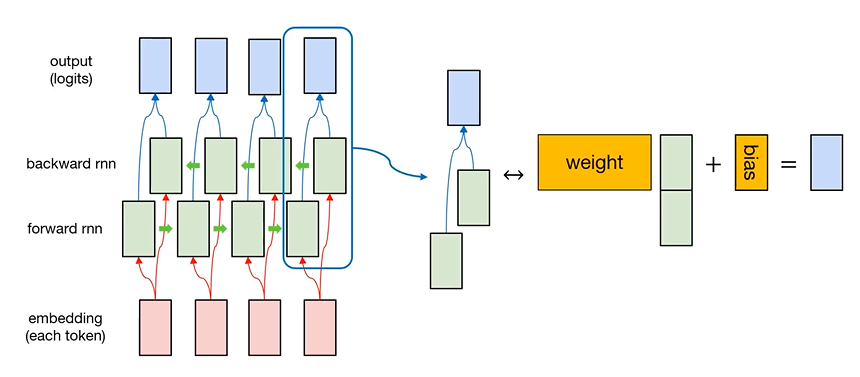 : 어떠한 sequence를 tokenization 한 후 embedding layer를 활용하여 각각의 token을 numeric vector로 변환
: 어떠한 sequence를 tokenization 한 후 embedding layer를 활용하여 각각의 token을 numeric vector로 변환
: 변환된 token을 forward RNN, backward RNN이 읽고, 각각의 RNN의 hidden state를 합칩니다.
: Weight, bias는 모든 token의 hidden state에서 동일하게 적용
many to many bidirectional
: 각 token마다의 bideirectional RNN의 출력과 정답을 비교하여 loss를 계산하고 masking을 활용하여 데이터 간의 길이를 맞추기 위한 pad token을 제외한 실제 데이터의 유효한 token들에 대해서 loss를 계산함
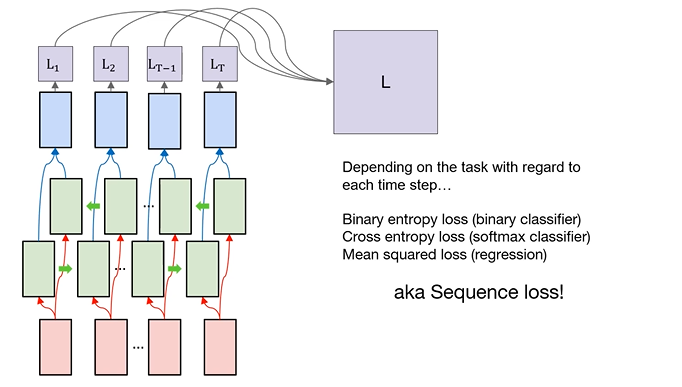
Example : part of speech tagging
: sentence를 word의 sequence로 간주하고 풀 것
: token인 word를 integer 인덱스로 mapping하고 있는 token의 dictionary를 만들어야 함
: 정답이 품사의 sequence 형태로 주어져 있기 때문에 품사를 integer 인덱스로 mapping하고 있는 dictionary 또한 만들어야 함

: word의 sequence와 정답인 품사의 sequence를 integer 인덱스의 sequence로 변환
: max_sequence 변수가 가리키는 값만큼의 길이로 각각의 데이터를 padding

: bidirectional RNN을 Many to Many 방식으로 활용
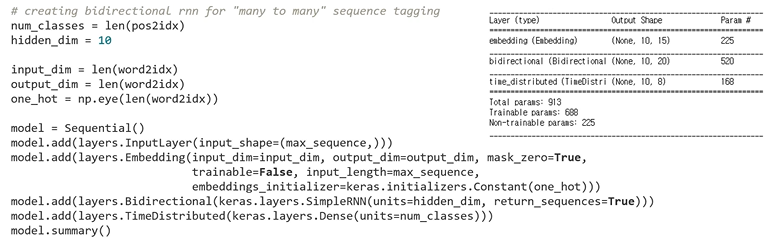
: 생성한 모델을 목적에 맞게 training 하기 위해서 model의 출력과 결과를 비교해주는 loss function 생성

: Model training
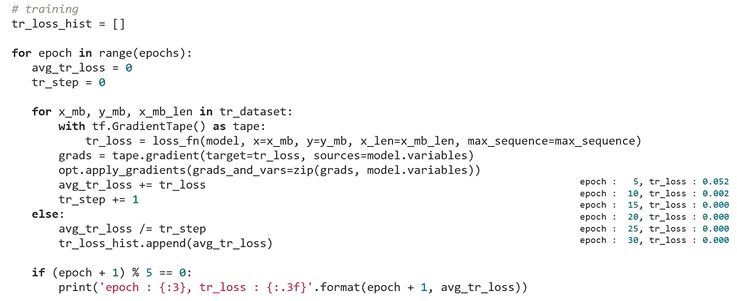
: part of speech tagging을 잘 하고 있는지 확인

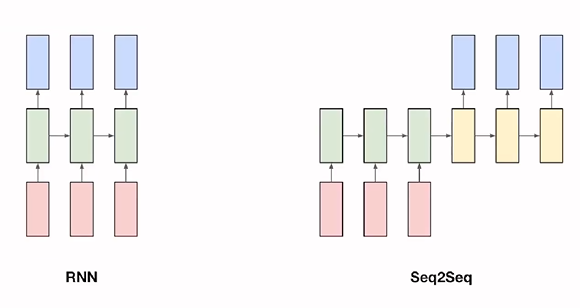
# Seq2Seq
Seq2Seq Overview
: Sequence의 입력을 받고 Sequence의 출력을 하는 model
Example : Chatbot
: Seq2Seq가 잘 작동하는 task
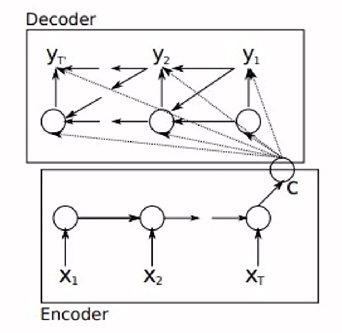
Encoder-Decoder
: Seq2Seq 모델의 대표적인 특징
: RNN 모델을 기반으로 함
: Encoder - 입력 값을 받아, 입력 정보를 담은 vector 만듬
: Decoder - vector를 활용하여 출력값을 만들어냄
: Encoder 부분은 step마다 입력 값이 들어가고 있음
: 입력 값은 하나의 단어가 되고 Encoder 부분의 전체 RNN 신경망의 마지막 부분에 c로 표현된 하나의 vector 값이 나옴
: Decoder 부분으로 들어가 c vector를 이용해 RNN 학습을 시작
: 신경망의 각 step마다 하나씩 출력 값이 나옴 -> 단어가 된다.
: 각 step의 출력 값이 다음 step의 입력 값으로 사용됨
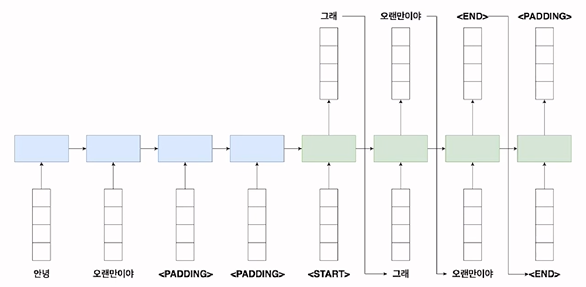
: 파란색 부분 - Encoder
: 각 신경망의 step마다 단어가 하나씩 들어감
: 각 단어는 embedding된 후 vector로 바뀐 후 입력 값으로 활용됨
: 초록색 부분 - Decoder
: start라는 특정 token을 활용 - 문장의 시작을 나타냄
: 각 step마다 출력이 나옴 -> 다음 step의 입력 값으로 사용된다.
: end라는 특정 token -> 문장의 마지막을 나타냄
Data Pipeline: Dataset
: source의 문장을 target으로 번역하는 Dataset

Data Pipeline: Vocab Dict
: source에는 각각의 dictionary의 pad token을 추가
: target token에서는 pad, bos - beggining of sentence, eos - end of sentence를 추가

Data Pipeline: Preprocess
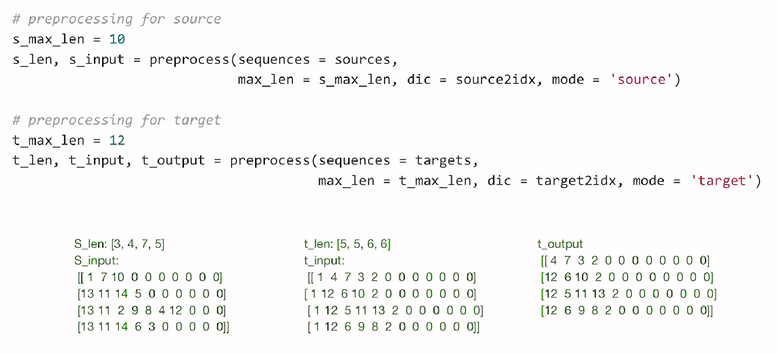
: input을 전처리 하는 과정
: source와 target을 옵션으로 준 이후 max의 길이 인자만큼의 데이터와 sequence와 dictionary를 받아 처리
: 각각의 사전을 입력된 vocab 사전을 바탕으로 치환해줌
: 문장의 index 길이를 맞추기 위해 padding을 추가로 입력
 : target을 전처리 하는 과정
: target을 전처리 하는 과정
: 사전을 사용하며 padding을 하는 과정
: target에서의 입력으로 사용될 입력 값을 만드는 과정과 결과 학습을 위해 필요한 label인 target 값을 만들어야 함
: target의 입력 값에는 문장의 시작과 끝에 시작과 종료 token을 넣어줌
: target의 label 값에는 문장 끝에 종료 token을 붙여 data를 전처리
 : source에서의 최대 길이 target에서의 최대 길이 정의
: source에서의 최대 길이 target에서의 최대 길이 정의
: preprocess 함수를 통해 source와 target, 각각의 최대 길이, 사전, 어떤 모드로 할 것인지 정하는 과정을 나타냄
: source와 target 모두 원래 길이와 최대 길이에 맞게 생성된 것을 확인 할 수 있다.
Data Pipeline: tf.data
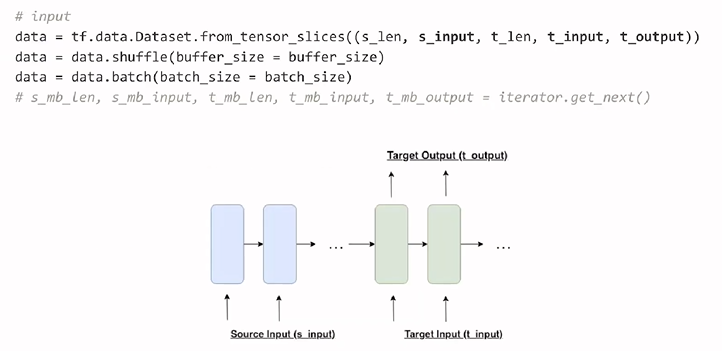
: from_tensor_slices에 맞게 numpy형태로 각 데이터를 변환해줌
: shuffle과 batch를 통해서 data를 준비
: 각 데이터는 Seq2Seq에 맞게 준비된다.
Encoder-Decoder
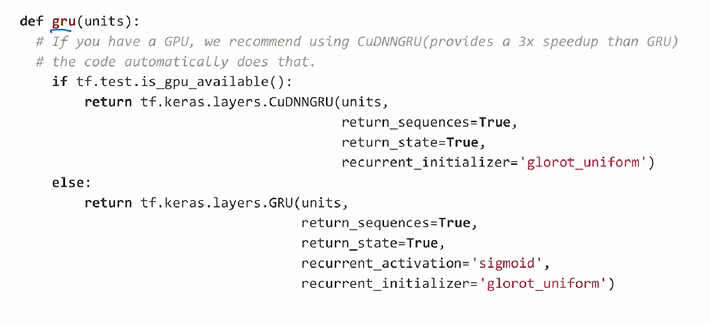
: GRU 알고리즘을 활용하여 함수 구성
: 학습 시에 gpu를 보유하고 있다는 CuDNN계열의 모듈로 학습
: 일반적으로 속도가 2~3배 정도 더 빨라짐
: 입력 값의 초기화 진행시에 glorot_uniform 사용 - random 값이 너무 작거나 크게 초기화 되는 것을 방지해줌
Encoder-Decoder: Encoder
: 단어의 크기, embedding의 차원 수, encoding의 hidden size, batch size를 인자로 받음
: 내부 call method에서 source input x 입력 값을 받으면 각각의 입력을 embedding layer에 통과를 시켜줌
: 그 후에 GRU layer를 활용하여 output과 state를 출력하는 구조
: hidden_state init은 처음에 GRU layer의 입력 값으로 들어가기 위한 더미 입력 값

Encoder-Decoder: Decoder
: 마지막에 출력를 해야되는 fully connected layer 추가

: GRU layer에서 학습을 진행한 후에 마지막에 fully connected layer에 입력을 하여 최종 결과 값을 출력함
: 입력 값을 embedding 및 GRU layer에 통과시키고 초기 hidden state를 설정하는 방법은 Encoder에서 선언하는 방법과 동일
: Encoder와 Decoder의 class를 활용하기 위해 각각의 입력 값을 추가하여 객체 생성

Loss & Optimizer
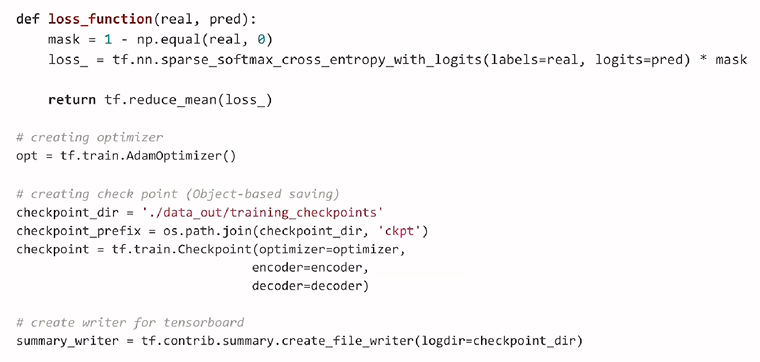
: loss function에서는 real, pred를 통해 입력을 받고 mask 값을 구성하여 0으로 설정된 padding된 값을 cross entropy logit을 구할 때 영향을 받지 않게 직접 곱해줌
: loss의 총합의 평균을 구하여 관련 값을 return
: 모델을 저장할 directory와 checkpoint 설정
Train
: 각 source의 input과 target의 input, label 값들을 로드하여 학습을 함
: Encoder의 최종 출력을 Decoder의 첫 hidden vector로 대입해주고 Decoder를 학습시킴
: Decoder의 첫 입력에서 문장의 시작을 의미하는 bos-beggin of sentence를 넣어줌
: 그 이후의 예측값과 Decoder의 hidden 값을 통해 학습
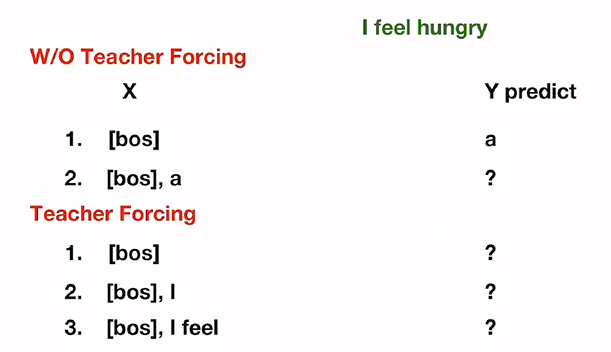
: Decoder 학습 시에 이전 step의 정답 단어들을 다음 step의 입력 값으로 넣어주는 teacher forcing

: Teacher Forcing 예제
: Y predict에 I가 나와야 하지만 a가 나온 후 다음 입력 값으로 들어가게 되면 예측값이 틀리게 된다.
: Y가 어떤 것을 예측하던지 I와 I feel이 들어감
: total loss를 구함
: 학습하면서 업데이터 되어야 할 parameter는 variable에 저장
: loss를 최소화하는 방법으로 적용
: 출력된 값은 10번의 epoch마다 print로 확인하면서 checkpoint에 저장

: 매 epoch마다 loss값이 정상적으로 떨어지는 것을 볼 수 있음

Prediction
: 문장, 학습에서 학습된 encoder와 decoder, 각각의 입력과 target사전, 각각의 최대 길이를 나타내는 입력과 target을 인자로 받음
: input에서는 주어진 문장을 띄어쓰기로 쪼갠 이후에 input length의 사전을 기반으로 indexing화 해줌
: 전처리에서 진행했던 것처럼 padding으로 길이를 맞춰줌
: 이후 학습에서 진행되었던 것처럼 encoder의 hidden 값을 decoder의 첫 hidden 값으로 입력을 받음
: 문장을 시작하는 token을 decoder의 입력으로 하여 예측을 시작

: 각 값들을 target의 최대 길이만큼 반복하면서 id값을 예측
: id가 eos token으로 예측을 하면 예측을 중지하고 결과 값을 돌려줌

: prediction 함수를 사용하여 각 값들의 예측 결과 확인
: 두 문장 모두 정상적으로 번역

# Seq2Seq with Attention
Seq2Seq Attention Overview
: RNN Decoder, Encoder를 활용하여 간단한 번역을 할 수 있는 구조로 모델을 생성
: 이는 중간에 한 개의 vector값을 활용하는 방식으로는 모든 정보를 담기 어려움
: 입력 언어와 타켓 언어가 길면 길어질수록 모델이 성능이 떨어지는 현상이 발생
What is Attention
: 위의 문제를 해결하기 위한 접근 방법 중 하나
: 중요한 정보에 집중
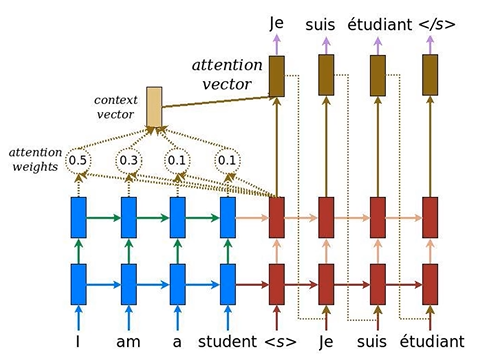 : 이전 Seq2Seq에서는 마지막 encoder에 hidden을 활용하여 context vector를 생성하고 이를 기반으로 Decoder 부분 학습
: 이전 Seq2Seq에서는 마지막 encoder에 hidden을 활용하여 context vector를 생성하고 이를 기반으로 Decoder 부분 학습
: Attention에서는 encoder 부분을 전부 활용하여 context vector에 적용
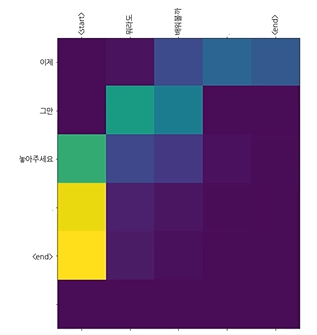
: 그 전에 attention weight 개념을 활용하여 현재 step에서 가장 중요하게 영향을 미친 encoder에 가중치를 주는 접근 방법
Data Pipeline: Dataset
: source의 문장을 target으로 번역하는 Dataset
Encoder
: 내부 call method에서 source input x 입력 값을 받으면 각각의 입력을 embedding layer에 통과를 시켜줌
: 그 후에 GRU layer를 활용하여 output과 state를 출력하는 구조

Decoder (W/ Attention)
: Attention은 Decoder쪽에 구현되어 있음
: 현재 step에서 어떤 Encoder가 중요하게 반영이 되는지를 구하기 위해 score를 구함.
: score를 구하는 방법으로 Bahdanau's additive style 사용
: Attention weights를 구하기 위해 score 값을 기반으로 softmax를 취해줌
: context vector는 각 hidden 값에 기존에 구했던 weight 값을 곱하여 구함
: 현재 step에 있는 Decoder의 출력 값과 context vector를 합쳐서 Attention vector를 생성하여 반영해줌
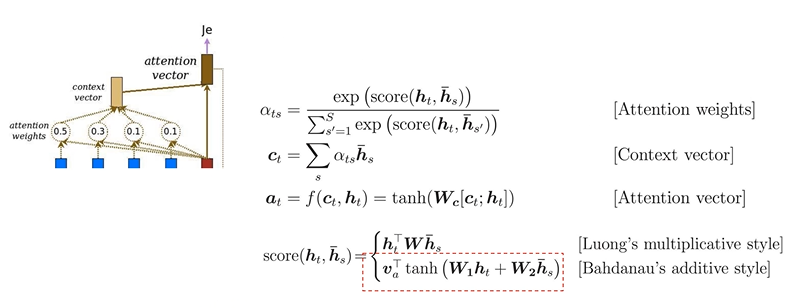
: Attention을 위해서 마지막에 dense vector와 같은 W1, W2, V값을 구해줌
: 구현했던 수식을 활용하기 위해 미리 선언해준 것
 : Bahdanau's additive style을 코드에서 구현하기 위해서는 W1, W2, V 모두 사용
: Bahdanau's additive style을 코드에서 구현하기 위해서는 W1, W2, V 모두 사용
: W1, hidden값을 넣은 W2를 구현한 후 tan를 곱한 다음 V layer를 구하여 score를 구함
: Attention weight를 구하기 위해 softmax를 활용해줌
: 현재 Encoder 출력값과 Attention weight 가중치를 곱하여 context vector 값을 구해줌
 : 기존에 구했던 context vector와 embedding을 통과한 Decoder의 input을 활용하여 GRU값을 구헤서 출력 값을 만들어냄.
: 기존에 구했던 context vector와 embedding을 통과한 Decoder의 input을 활용하여 GRU값을 구헤서 출력 값을 만들어냄.
: 최종 출력 값을 Fully Connected에 연결하여 값을 생성

Train
: 각 source의 input과 target의 input, label 값들을 로드하여 학습을 함
: Encoder의 최종 출력을 Decoder의 첫 hidden vector로 대입해주고 Decoder를 학습시킴
: Decoder의 첫 입력에서 문장의 시작을 의미하는 bos-beggin of sentence를 넣어줌
: 그 이후의 예측값과 Decoder의 hidden 값을 통해 학습
: Decoder 학습 시에 이전 step의 정답 단어들을 다음 step의 입력 값으로 넣어주는 teacher forcing

: 학습하면서 업데이터 되어야 할 parameter는 variable에 저장
: loss를 최소화하는 방법으로 적용
: 출력된 값은 10번의 epoch마다 print로 확인하면서 checkpoint에 저장

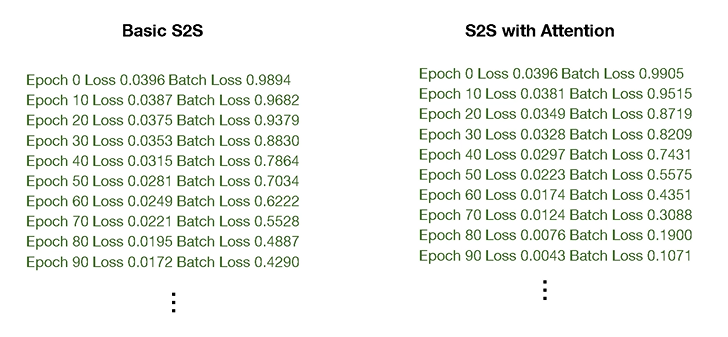
: Seq2Seq와 Attention을 적용한 학습을 비교
: 같은 epoch으로도 조금 더 빨리 loss가 떨어지는 것을 확인 가능
Prediction
: Seq2Seq와 동일
: 모델에 예측을 하면 정상적인 결과가 나옴

Bonus: Chatbot
: 입력에 질문을 넣고 답변에 응답을 넣는 방식으로 Chatbot 구현 가능