#ABC부트캠프 #유클리드소프트 #2022청년ESG지원사업 #코딩 #대전부트캠프 #대전청년 #ESG경영 #파이썬 #빅데이터 #대전IT교육 #프로그래밍 #개발자 #진로탐색 #데이터교육 #ESG교육pythonProject > examples 디렉토리는 닫아주고 config 디렉토리 만들어주기.
config
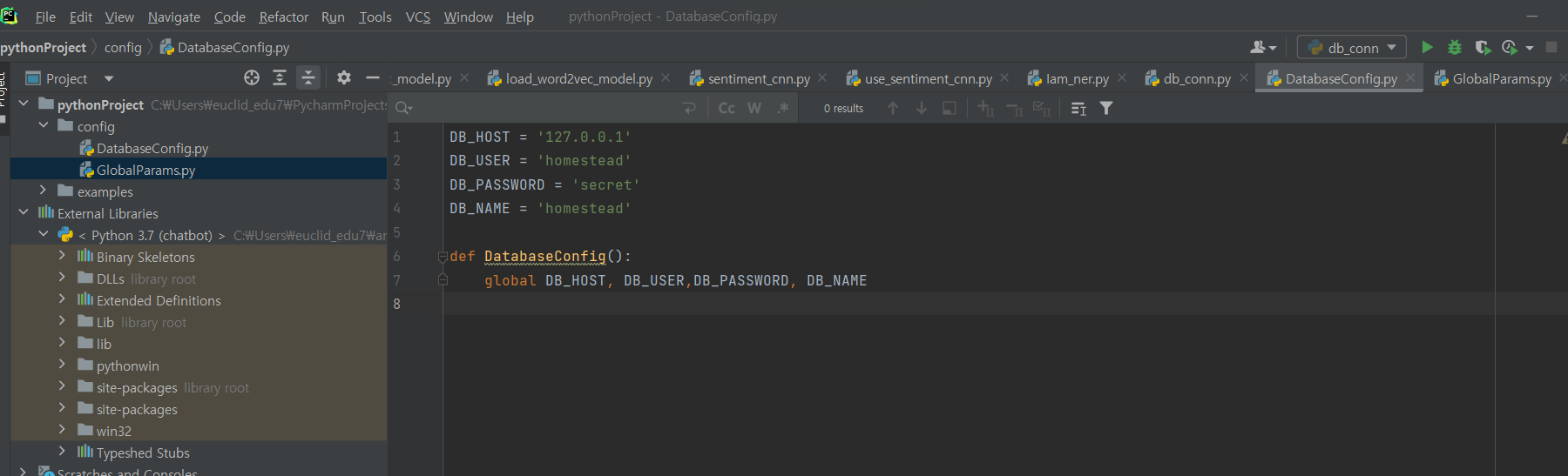
^ 파일 생성 후 코드 입력

^ 파일 생성 후 코드 입력
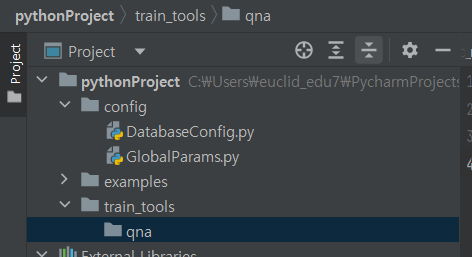
^ train_tools > qna 폴더 생성
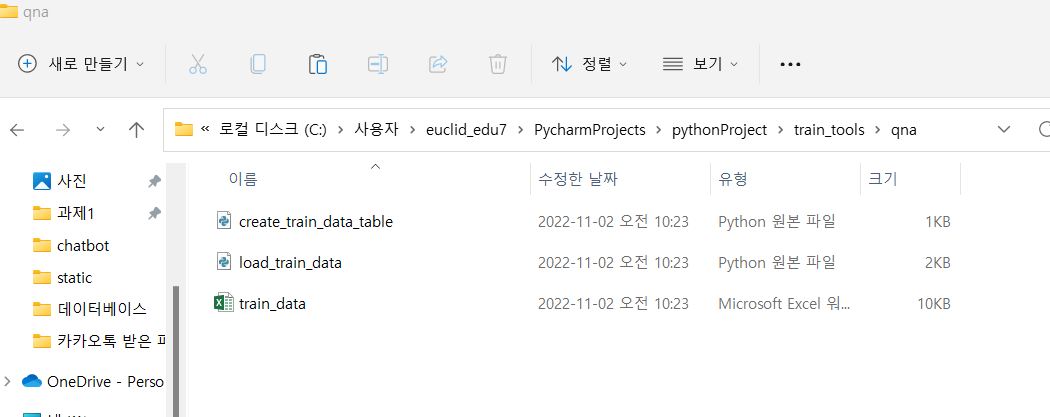
^ 데이터 다음과 같은 위치에 올려주기
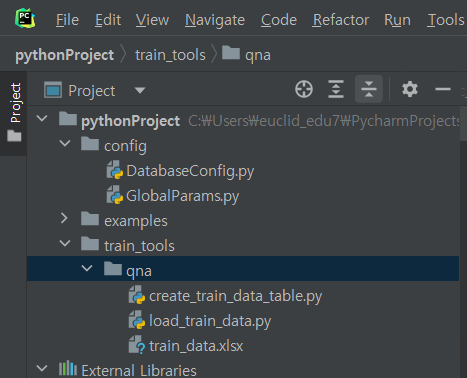
^ 그러면 qna 아래에 데이터 3개 뜨는 것 확인 가능
create_train_data_table.py
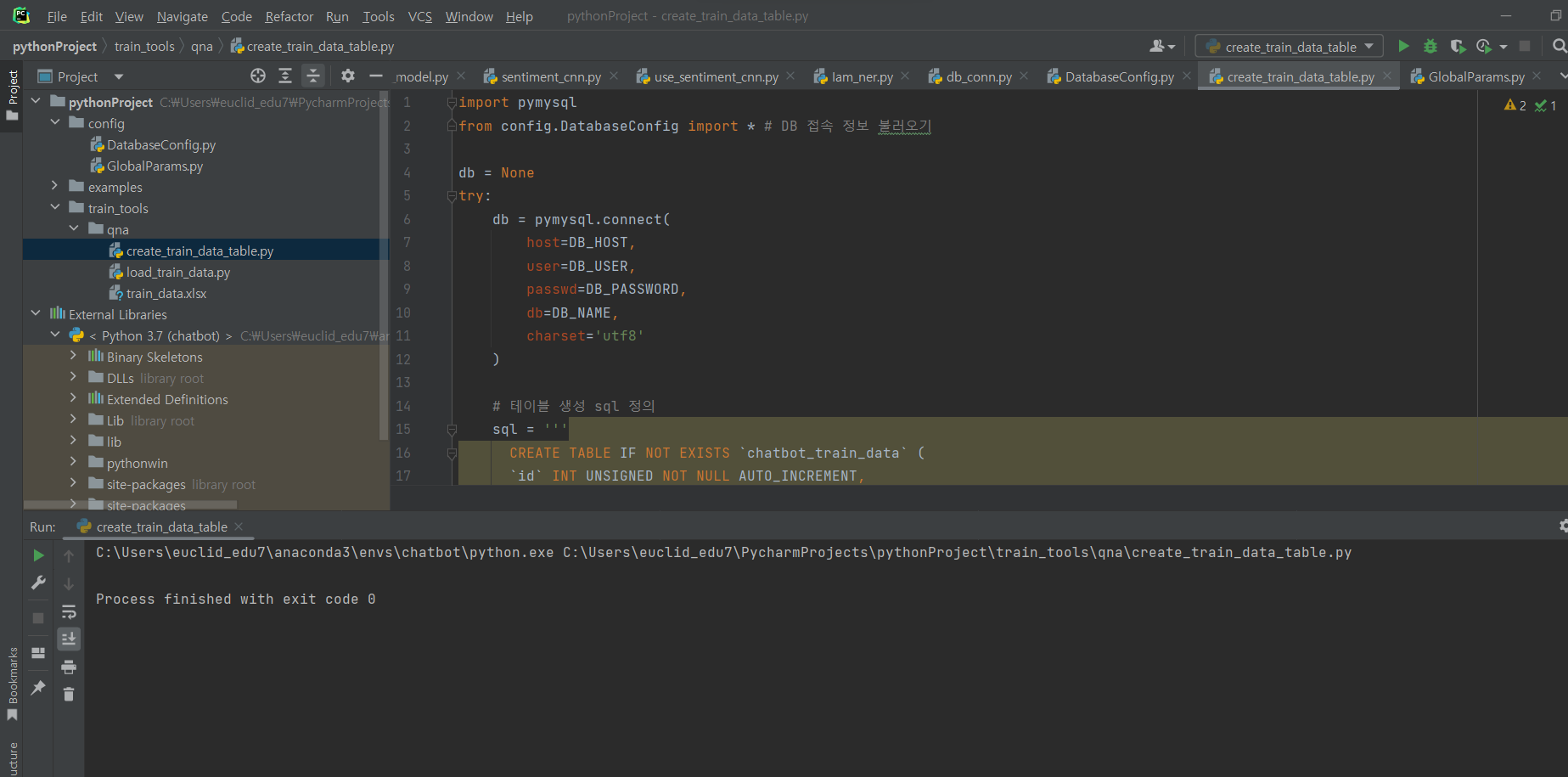
import pymysql
from config.DatabaseConfig import * # DB 접속 정보 불러오기
db = None
try:
db = pymysql.connect(
host=DB_HOST,
user=DB_USER,
passwd=DB_PASSWORD,
db=DB_NAME,
charset='utf8'
)
# 테이블 생성 sql 정의
sql = '''
CREATE TABLE IF NOT EXISTS `chatbot_train_data` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`intent` VARCHAR(45) NULL,
`ner` VARCHAR(1024) NULL,
`query` TEXT NULL,
`answer` TEXT NOT NULL,
`answer_image` VARCHAR(2048) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB DEFAULT CHARSET=utf8
'''
# 테이블 생성
with db.cursor() as cursor:
cursor.execute(sql)
except Exception as e:
print(e)
finally:
if db is not None:
db.close()^ create_train_data_table.py 실행해주기
MySQL Workbench
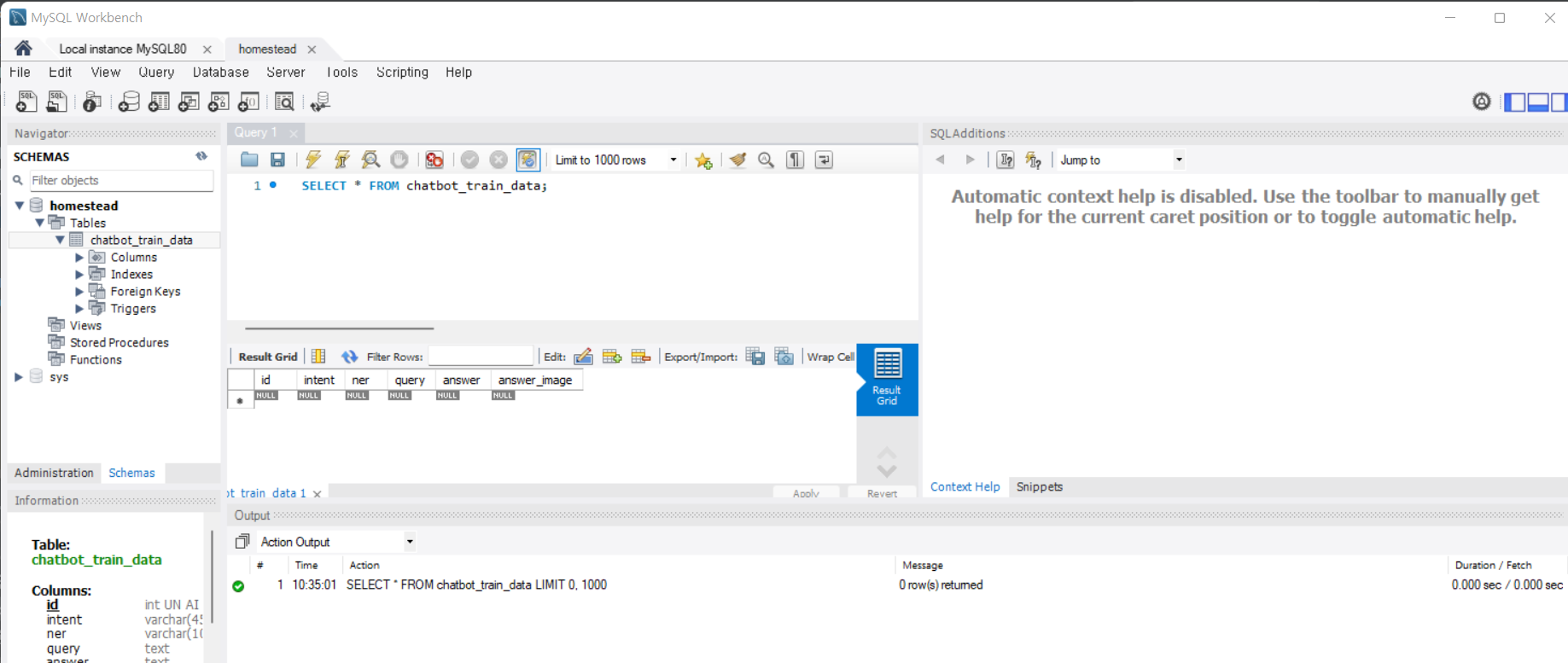
^ MySQL Workbench 앱 homestead에서 chatbot_train_data 생성된 것 확인 가능. 클릭 후 코드 입력 후 실행해주기.
load_train_data.py
import pymysql
import openpyxl
from config.DatabaseConfig import * # DB 접속 정보 불러오기
# 학습 데이터 초기화
def all_clear_train_data(db):
# 기존 학습 데이터 삭제
sql = '''
delete from chatbot_train_data
'''
with db.cursor() as cursor:
cursor.execute(sql)
# auto increment 초기화
sql = '''
ALTER TABLE chatbot_train_data AUTO_INCREMENT=1
'''
with db.cursor() as cursor:
cursor.execute(sql)
# db에 데이터 저장
def insert_data(db, xls_row):
intent, ner, query, answer, answer_img_url = xls_row
sql = '''
INSERT chatbot_train_data(intent, ner, query, answer, answer_image)
values(
'%s', '%s', '%s', '%s', '%s'
)
''' % (intent.value, ner.value, query.value, answer.value, answer_img_url.value)
# 엑셀에서 불러온 cell에 데이터가 없는 경우, null 로 치환
sql = sql.replace("'None'", "null")
with db.cursor() as cursor:
cursor.execute(sql)
print('{} 저장'.format(query.value))
db.commit()
train_file = 'train_data.xlsx'
db = None
try:
db = pymysql.connect(
host=DB_HOST,
user=DB_USER,
passwd=DB_PASSWORD,
db=DB_NAME,
charset='utf8'
)
# 기존 학습 데이터 초기화
all_clear_train_data(db)
# 학습 엑셀 파일 불러오기
wb = openpyxl.load_workbook(train_file)
sheet = wb['Sheet1']
for row in sheet.iter_rows(min_row=2): # 해더는 불러오지 않음
# 데이터 저장
insert_data(db, row)
wb.close()
except Exception as e:
print(e)
finally:
if db is not None:
db.close()train_data.xlsx
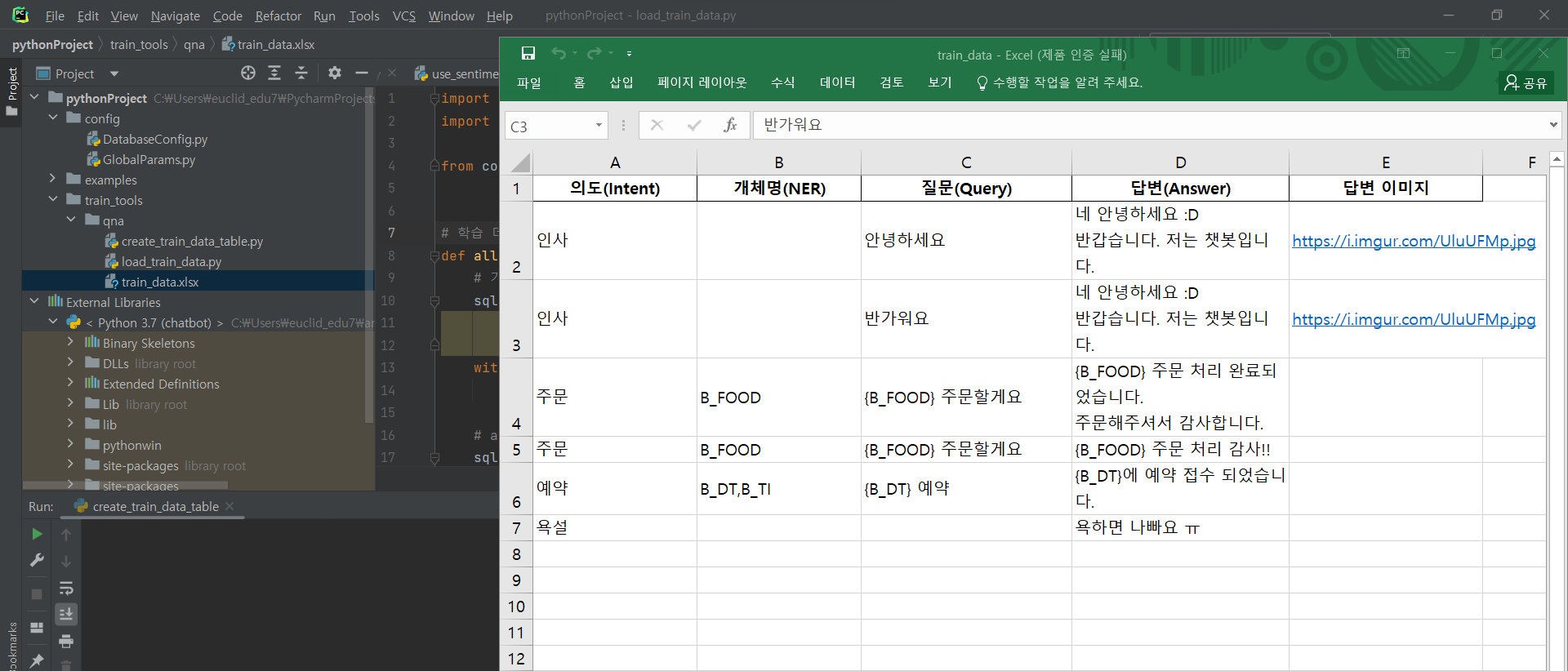
^ train_data 엑셀파일 어떠하게 구성되어 있는지 확인
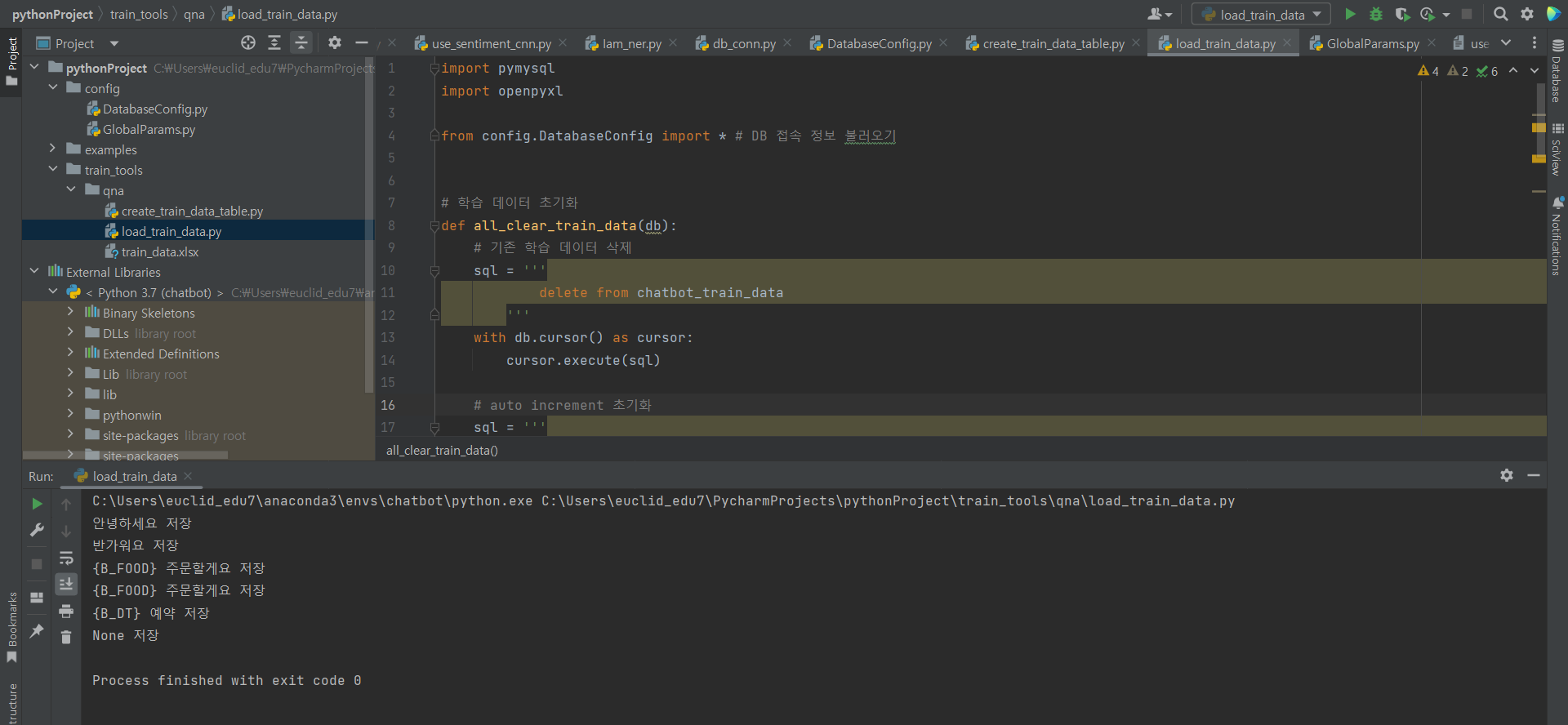
^ load_train_data.py 파일 실행해주기
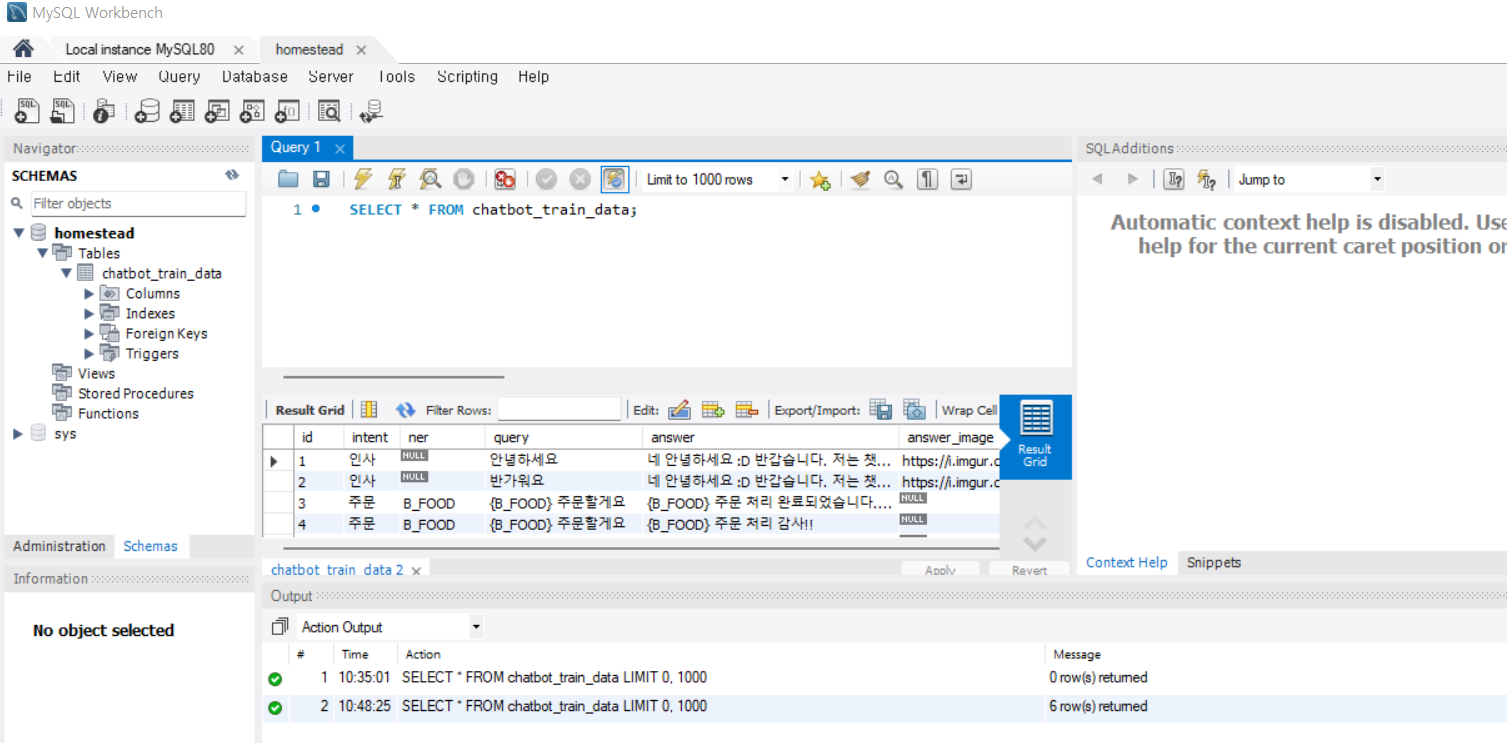
^ 그러면 데이터 올라간 것 확인 가능
^ dict 파일 생성
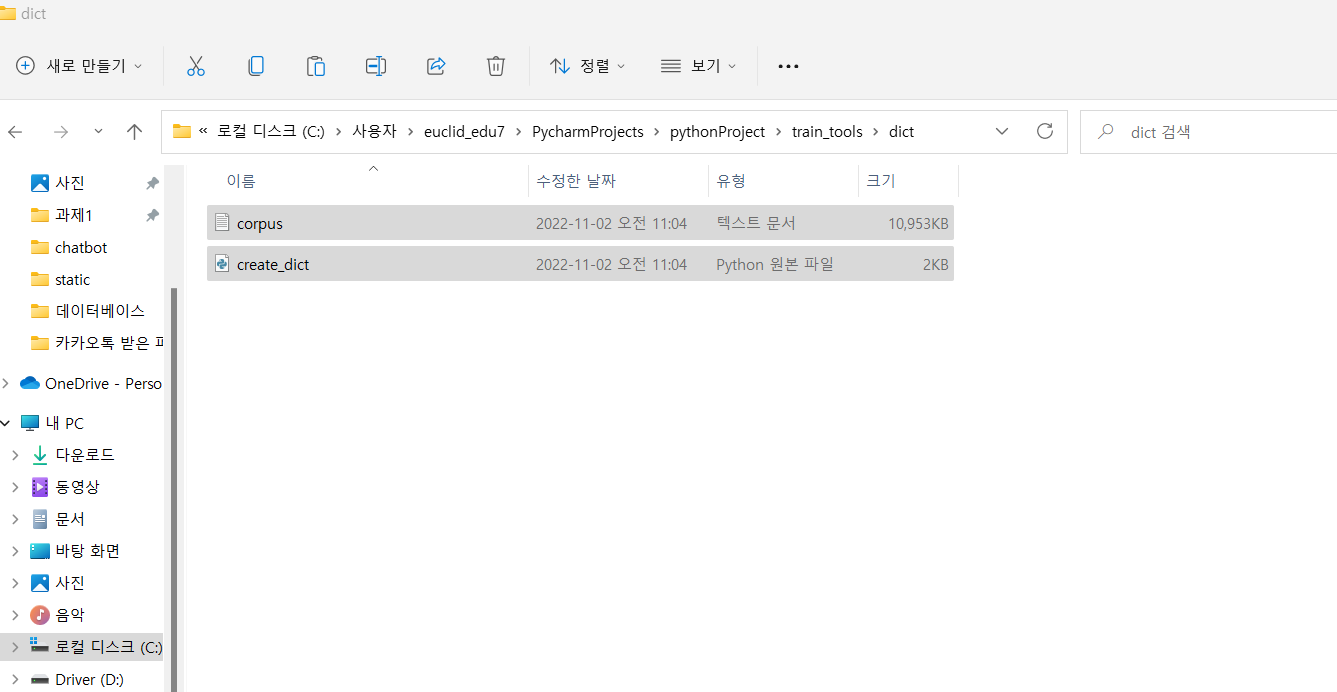
^ 다음 위치(dict)에 데이터 놓기
create_dict.py
#
# 챗봇에서 사용하는 사전 파일 생성
#
from utils.Preprocess import Preprocess
from tensorflow.keras import preprocessing
import pickle
import time
# 말뭉치 데이터 읽어오기
def read_corpus_data(filename):
with open(filename, 'r', encoding='UTF-8') as f:
data = [line.split('\t') for line in f.read().splitlines()]
return data
# 0) 측정 시작
start = time.time()
# 1) 말뭉치 데이터 가져오기
corpus_data = read_corpus_data('corpus.txt')
print('1) 말뭉치 데이터 읽기 완료: ', time.time() - start)
# 2) 말뭉치 데이터에서 키워드만 추출해서 사전 리스트 생성
p = Preprocess(userdic = '../../utils/user_dic.tsv')
dict = []
# 리스트에서 문장 하나씩 가져와서 POS 품사 태깅
for c in corpus_data:
pos = p.pos(c[1])
for k in pos:
dict.append(k[0])
print('2) 말뭉치 키워드 추출 사전 리스트 생성 완료: ', time.time() - start)
# 3) 사전에 사용될 word2index 생성
# 사전의 첫번 째 인덱스에는 OOV 사용
tokenizer = preprocessing.text.Tokenizer(oov_token='OOV')
tokenizer.fit_on_texts(dict)
word_index = tokenizer.word_index
print('3) 사전에 사용될 word2index 생성 완료: ', time.time() - start)
# 4) 사전 파일 생성
f = open("chatbot_dict.bin", "wb")
try:
pickle.dump(word_index, f)
except Exception as e:
print(e)
finally:
f.close()
print('4) 사사전 파일 생성 완료: ', time.time() - start)단어사전
^ 파일 생성 후 데이터 담기
^ utils 파일 이름 오류나서 이름 변경 후 실행해주기

^ 실행된 결과
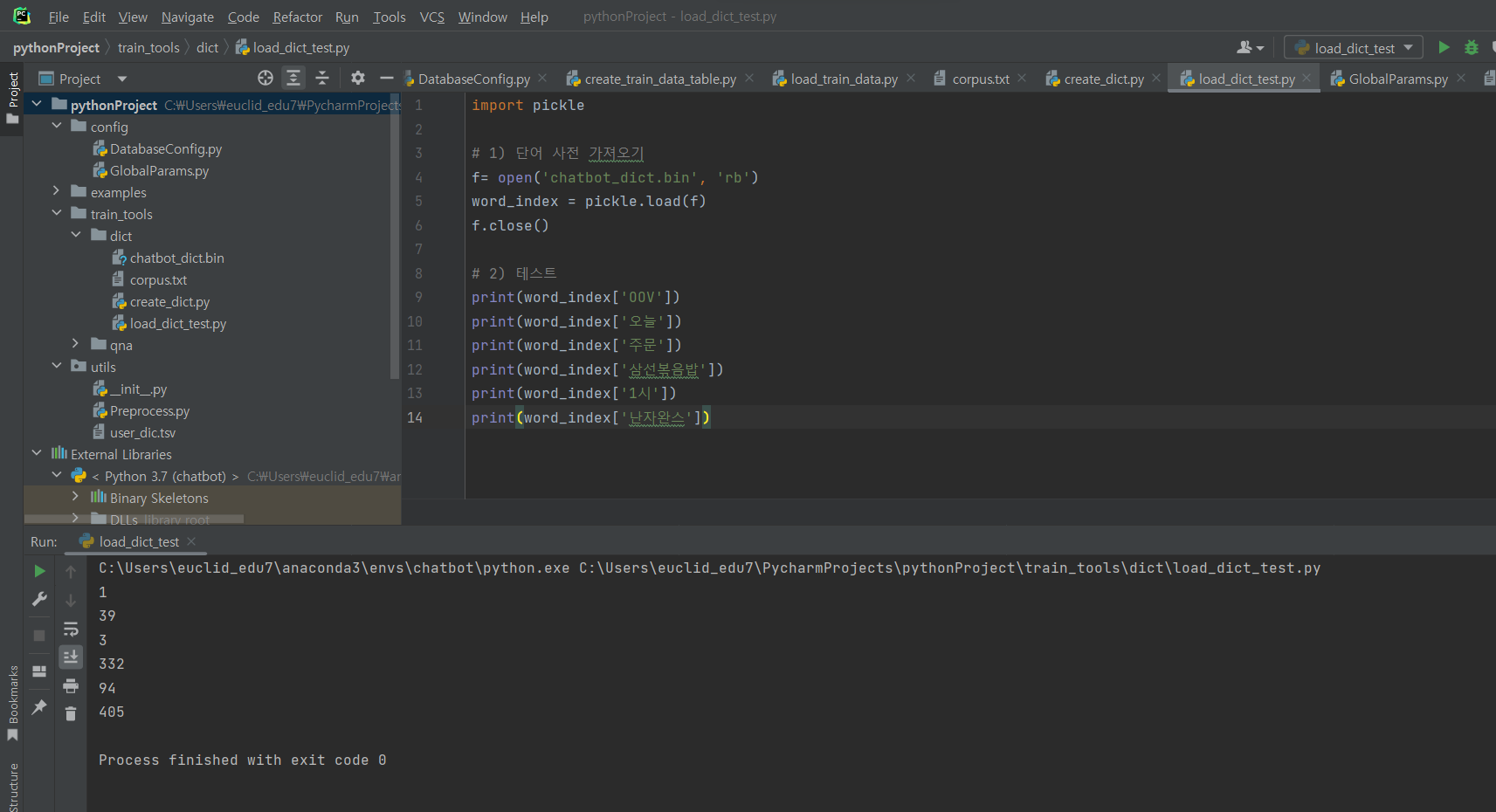
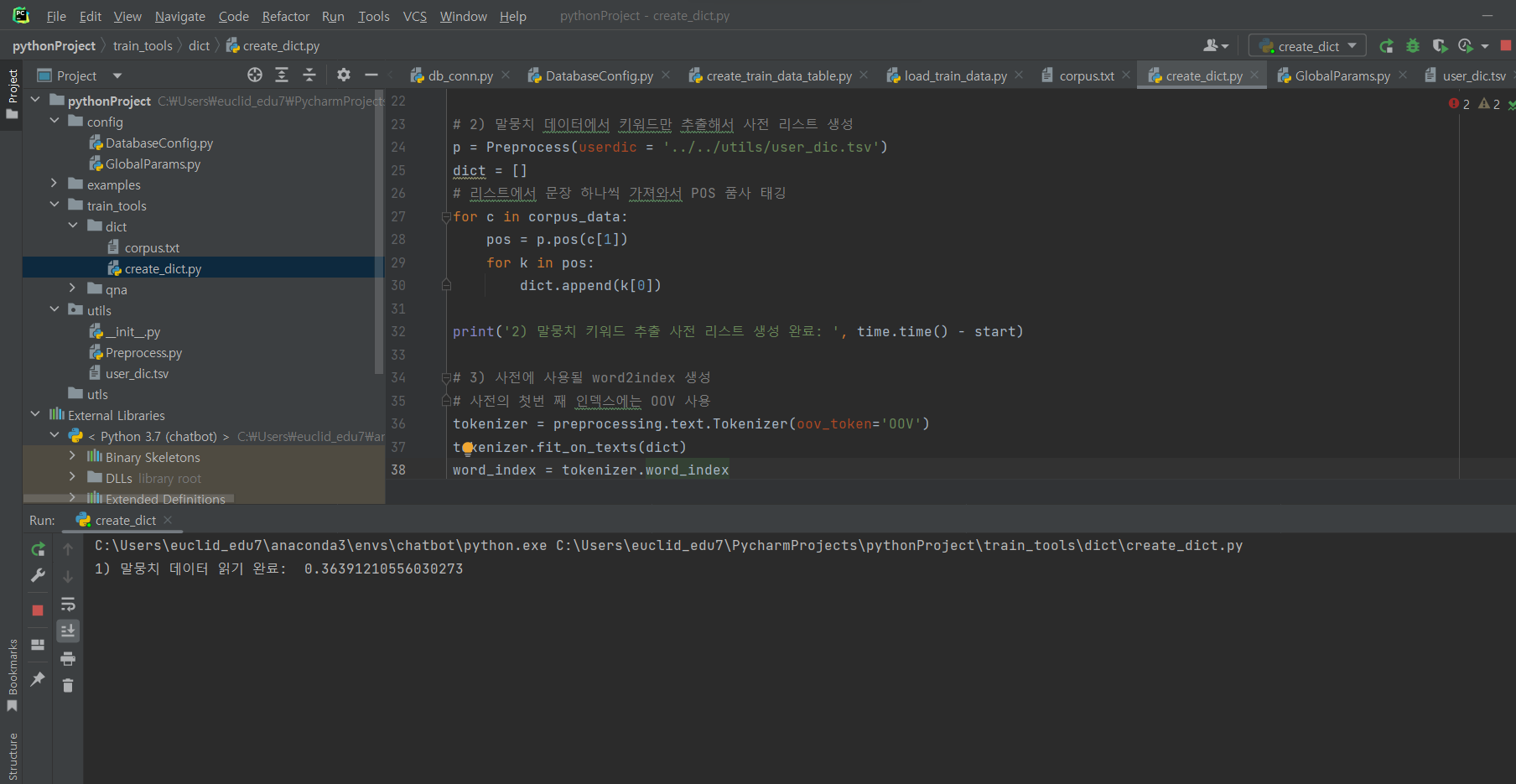
^ 파일 생성 후 코드 입력 실행 (단어 사전 만들기)
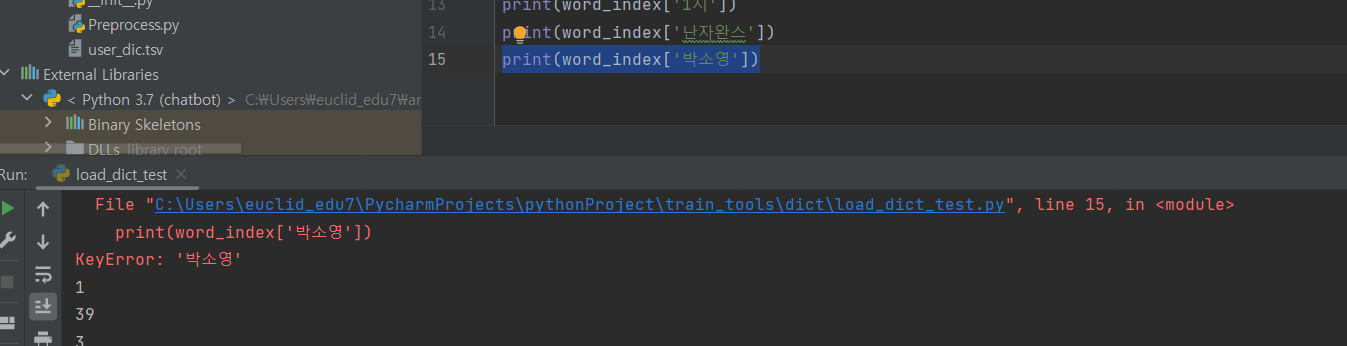
^ 단어 사전에 없는 단어를 입력하면 읽지를 못해 오류날 것임.
models
^ 파일 생성 후 데이터 불러오기 후 train_model.py 실행하기
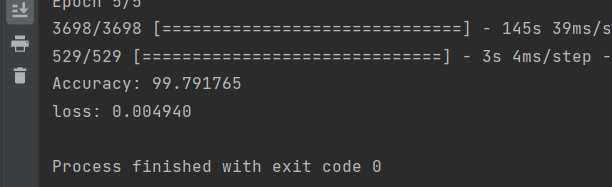
^ 실행 결과
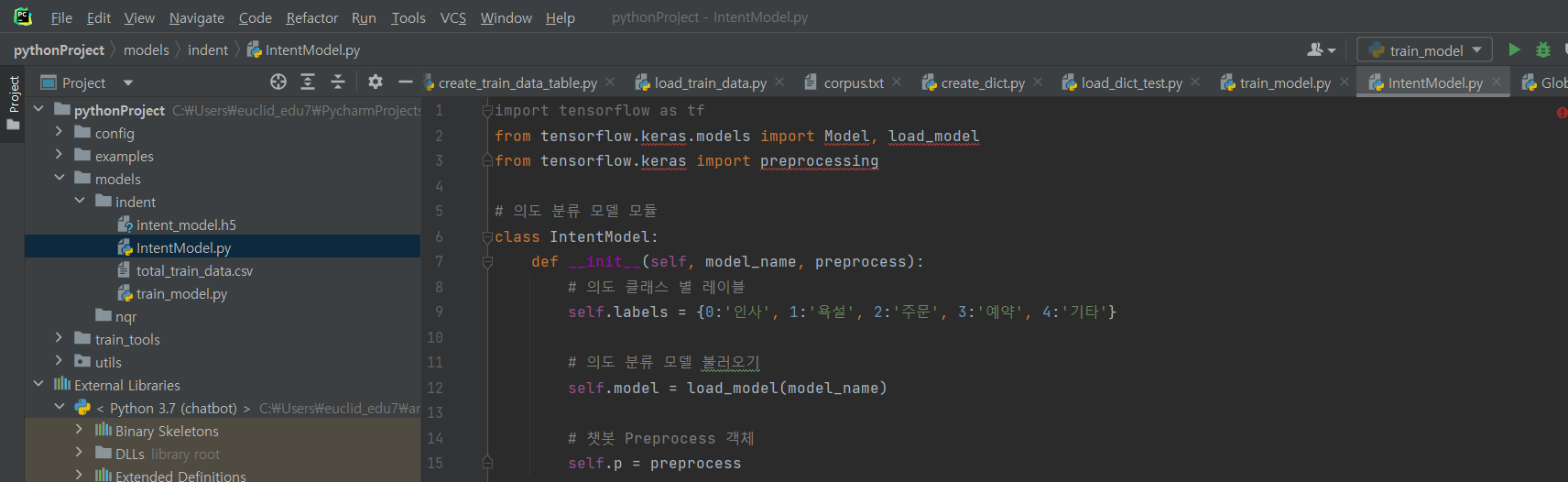
^ (1) IntentModel.py 파일 생성 후 코드 입력
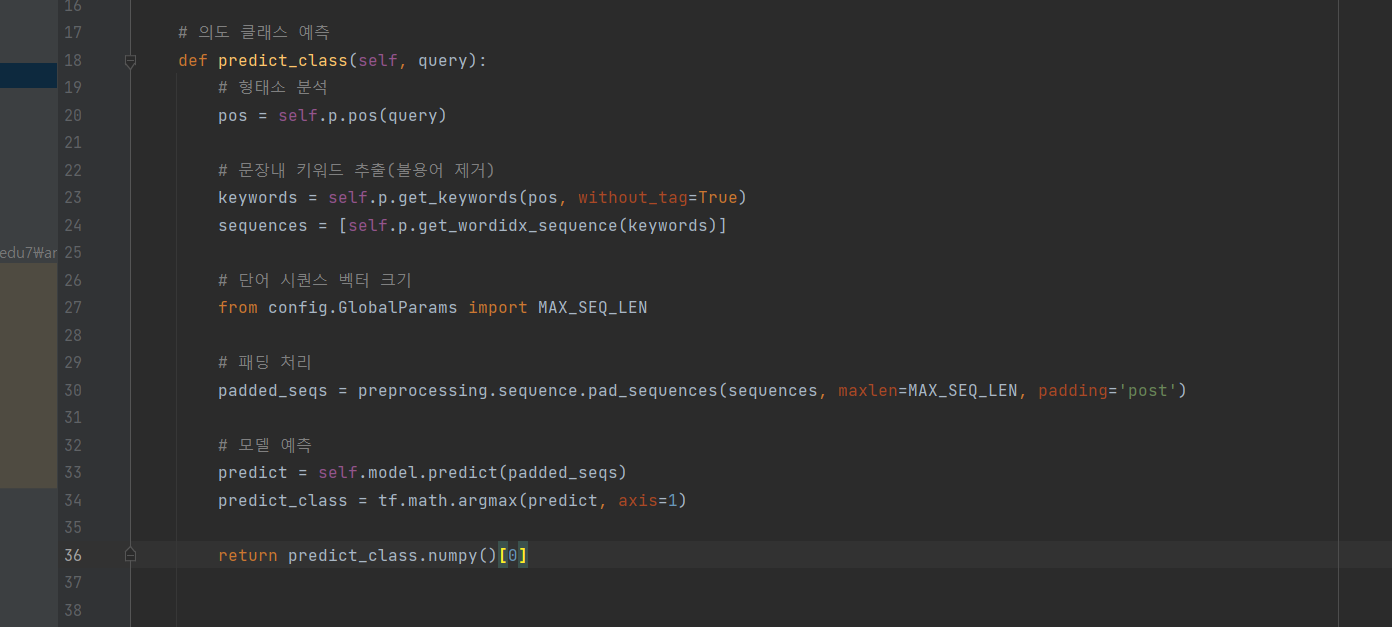
^ (2) 이어서 코드 입력
테스트 (챗봇 의도 파악)
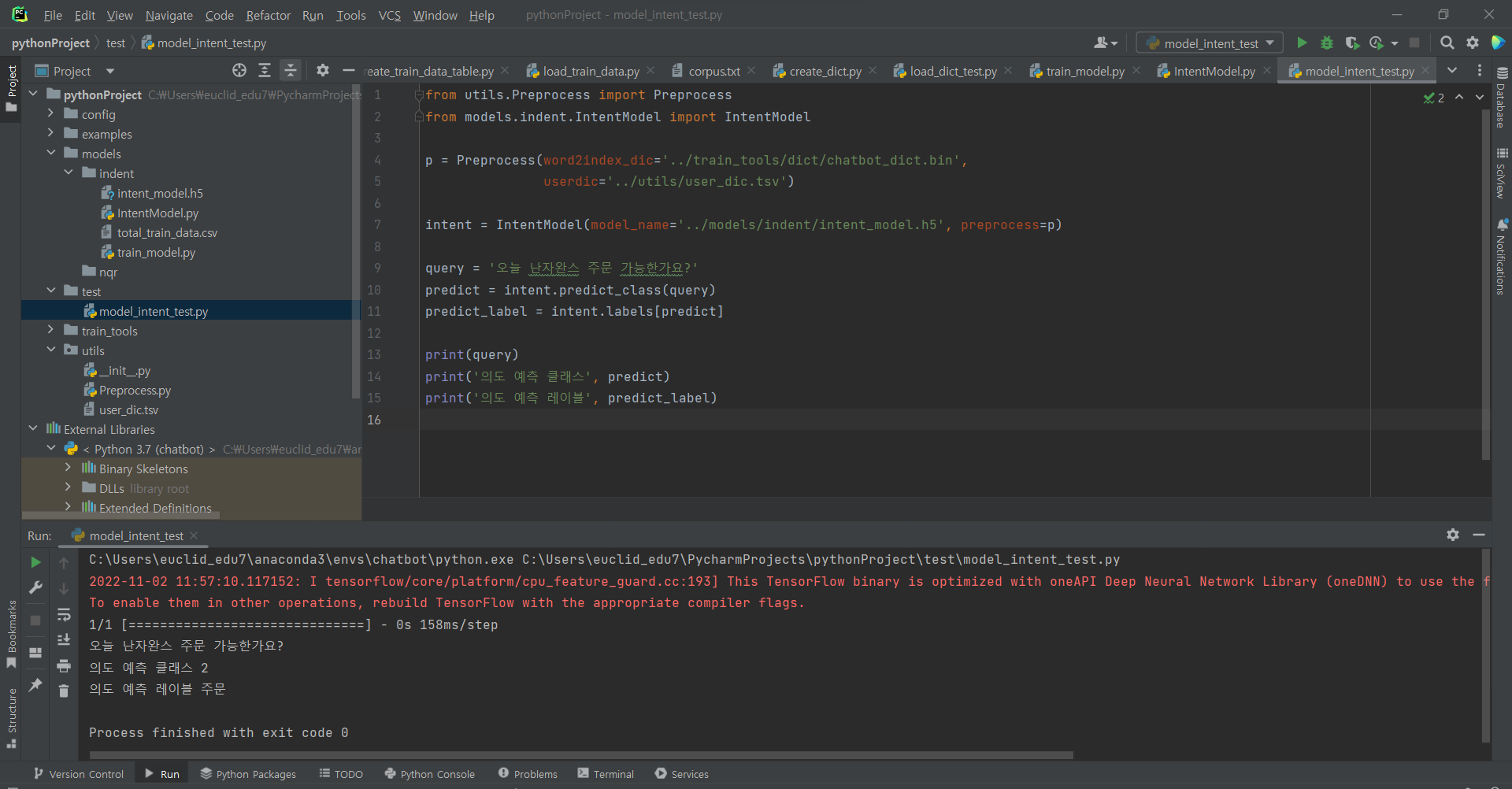
^ 파일 생성 후 코드 입력 후 실행 : 문장에 있어 주문으로 파악함.
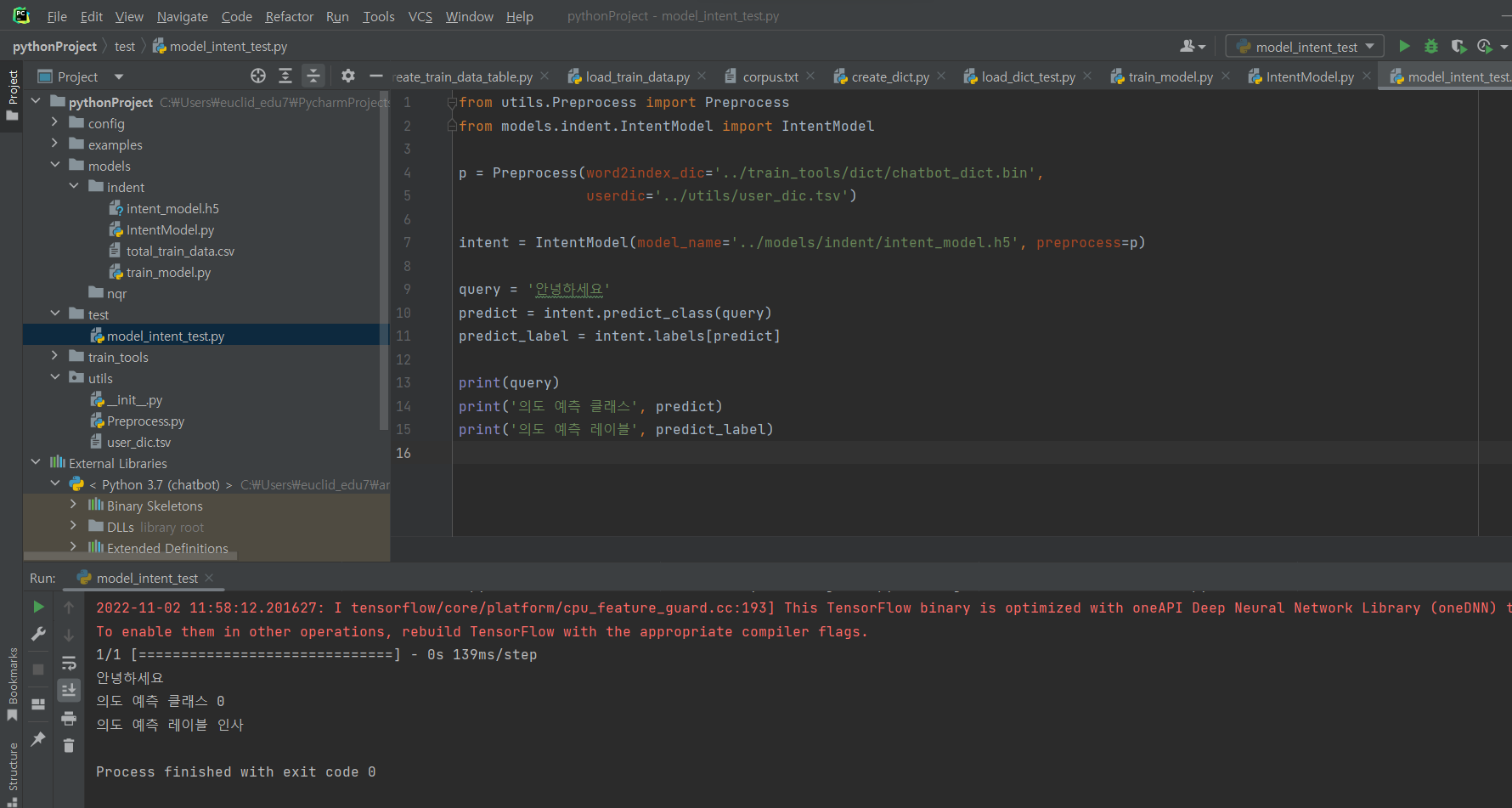
^ 안녕하세요를 인사로 파악함.
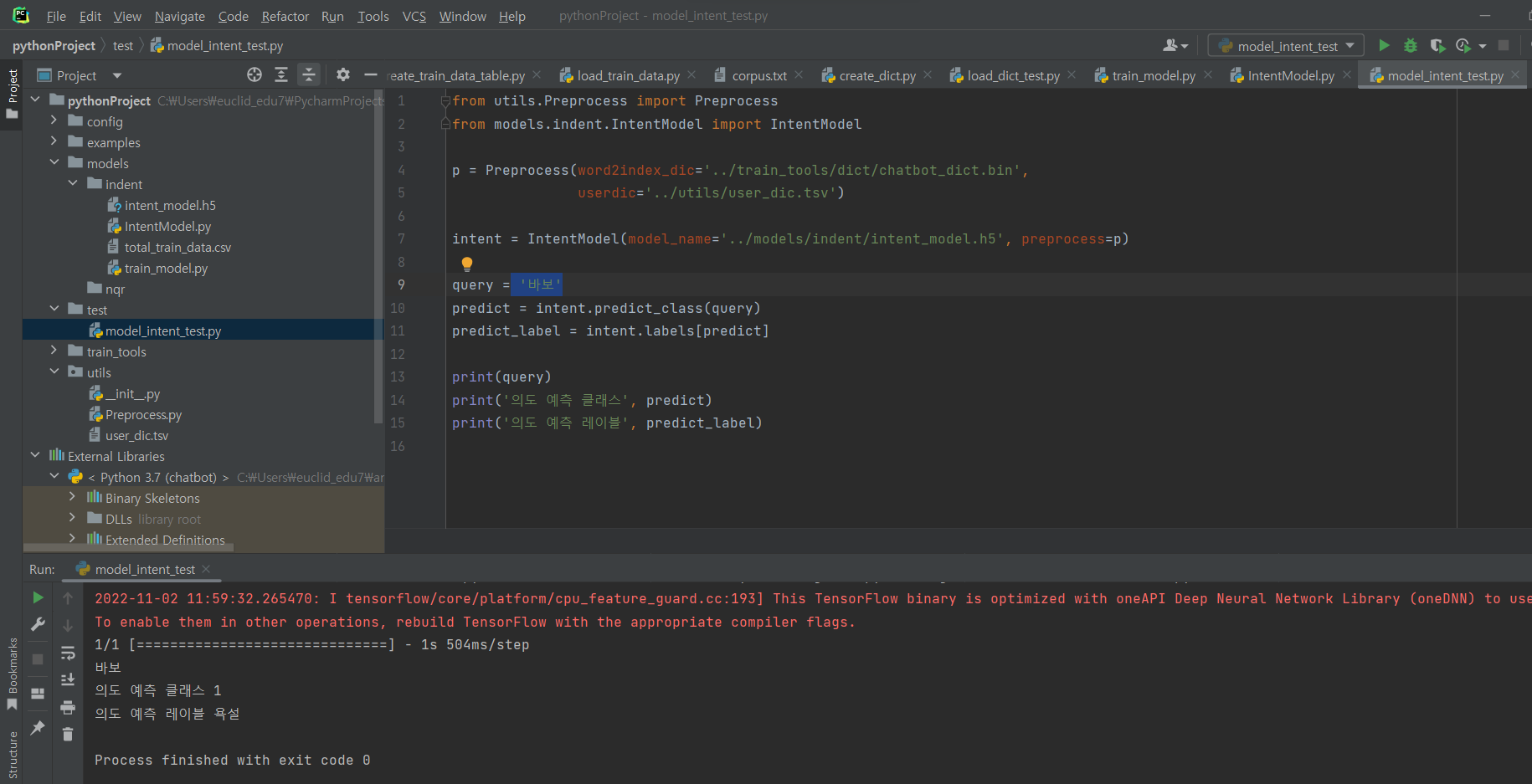
^ 바보를 입력하니 욕설이라고 파악함.
ner
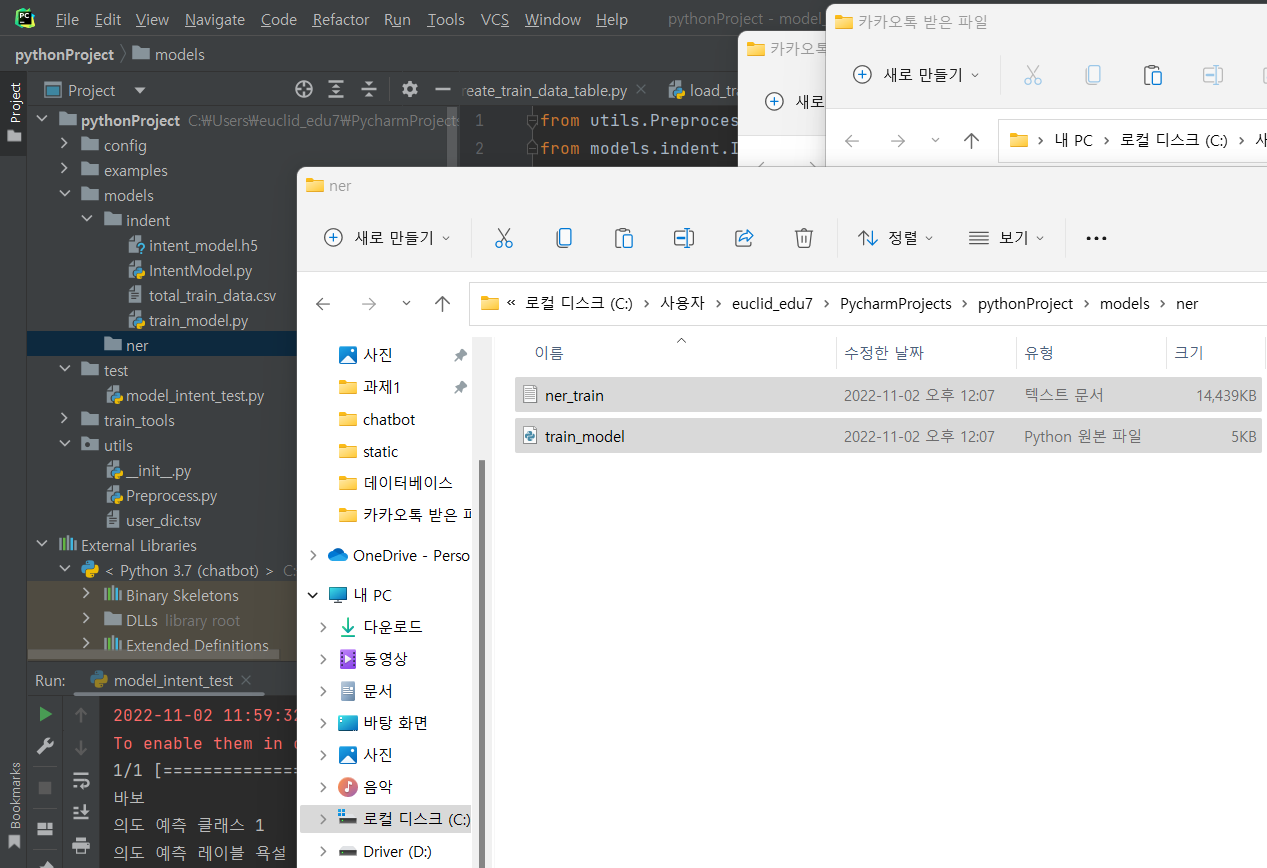
^ ner 폴더 생성 후 데이터 넣고 train_model.py 실행하기 ( 30분 정도 걸림...)
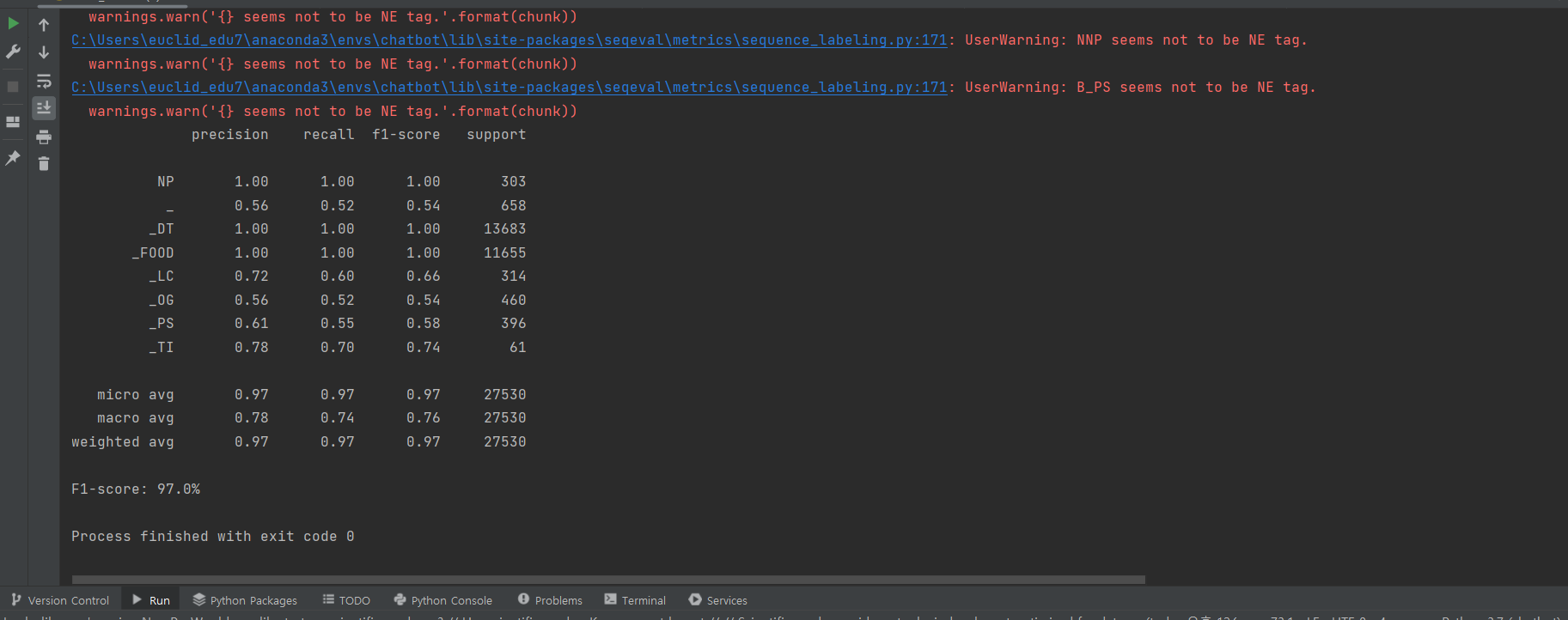
^ 결과
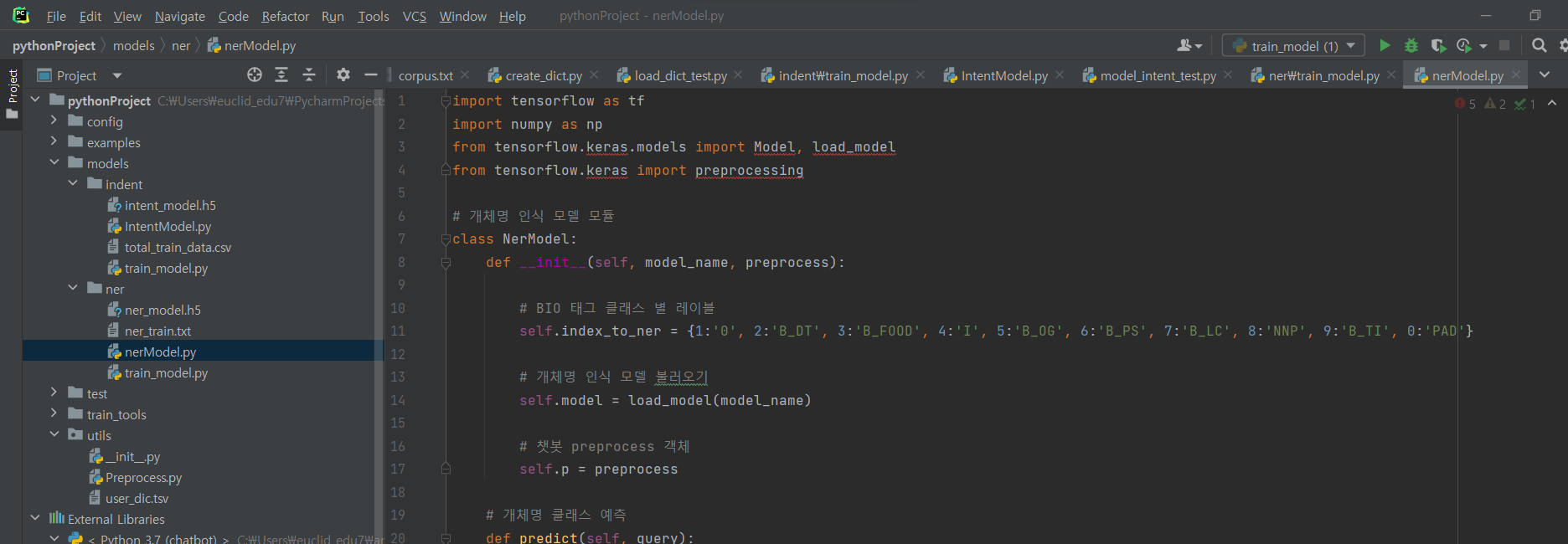
^ nerModel.py 파일 생성 후 아래 코드 입력하기
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Model, load_model
from tensorflow.keras import preprocessing
# 개체명 인식 모델 모듈
class NerModel:
def __init__(self, model_name, preprocess):
# BIO 태그 클래스 별 레이블
self.index_to_ner = {1:'0', 2:'B_DT', 3:'B_FOOD', 4:'I', 5:'B_OG', 6:'B_PS', 7:'B_LC', 8:'NNP', 9:'B_TI', 0:'PAD'}
# 개체명 인식 모델 불러오기
self.model = load_model(model_name)
# 챗봇 preprocess 객체
self.p = preprocess
# 개체명 클래스 예측
def predict(self, query):
# 형태소 분석
pos = self.p.pos(query)
# 문장내 키워드 추출(불용어 제거)
keywords = self.p.get_keywords(pos, without_tag=True)
sequences = [self.p.get_wordidx_sequence(keywords)]
# 패딩 처리
max_len = 40
padded_seqs = preprocessing.sequence.pad_sequences(sequences, maxlen=max_len, padding='post')
predict = self.model.predict(np.array([padded_seqs[0]]))
predict_class = tf.math.argmax(predict, axis=-1)
tags = [self.index_to_ner[i] for i in predict_class.numpy()[0]]
return list(zip(keywords, tags))
def predict_tags(self, query):
# 형태소 분석
pos = self.p.pos(query)
# 문장내 키워드 추출(불용어 제거)
keywords = self.p.get_keywords(pos, without_tag=True)
sequences = [self.p.get_wordidx_sequence(keywords)]
# 패딩 처리
max_len = 40
padded_seqs = preprocessing.sequence.pad_sequences(sequences, maxlen=max_len, padding='post')
predict = self.model.predict(np.array([padded_seqs[0]]))
predict_class = tf.math.argmax(predict, axis=-1)
tags = []
for tag_idx in predict_class.numpy()[0]:
if tag_idx == 1: continue
tags.append(self.index_to_ner[tag_idx])
if len(tags) == 0: return None
return tags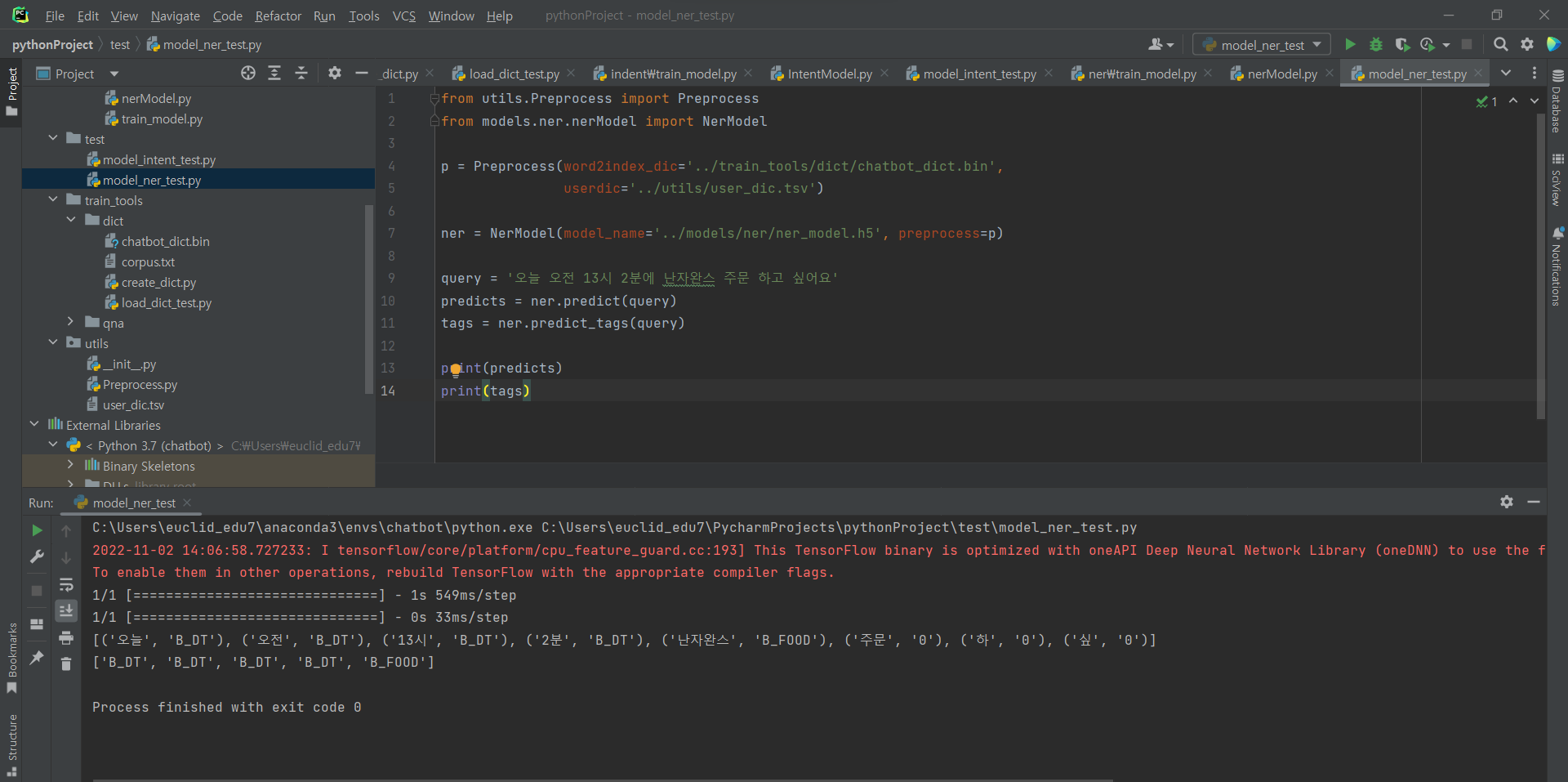
^ model_ner_test.py 파일 생성 후 코드 입력해주고 실행해주기.
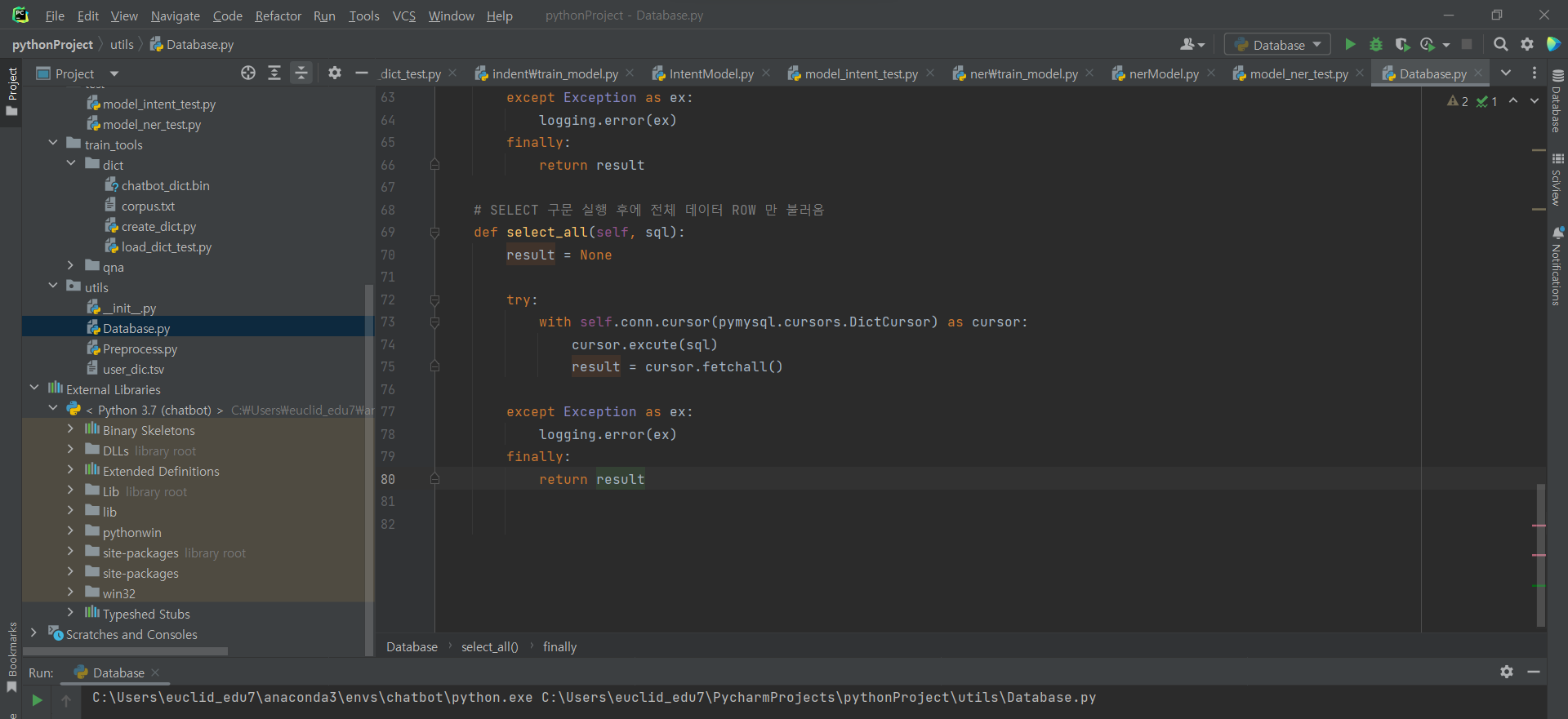
^ 파일 생성 후 아래 코드 입력
import pymysql
import pymysql.cursors
import logging
# 데이터베이스 제어 모듈
class Database:
def __init__(self, host, user, password, db_name, charset='utf8'):
self.host = host
self.user = user
self.password = password
self.db_name = db_name
self.charset = 'utf8'
self.conn = None
# DB 접속
def connect(self):
if self.conn != None:
return
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
db=self.db_name,
charset= self.charset
)
# DB 연결 종료
def close(self):
if self.conn is None:
return
if not self.conn.open:
self.conn = None
return
self.conn.close()
self.conn = None
# SQL 구문 실행
def execute(self, sql):
last_row_id = -1
try:
with self.conn.cursor() as cursor:
cursor.excute(sql)
self.conn.commit()
last_row_id = cursor.lastrowid
except Exception as ex:
logging.error(ex)
finally:
return last_row_id
# SELECT 구문 실행 후에 단 1개의 데이터 ROW 만 불러옴
def select_one(self, sql):
result = None
try:
with self.conn.cursor(pymysql.cursors.DictCursor) as cursor:
cursor.excute(sql)
result = cursor.fetchone()
except Exception as ex:
logging.error(ex)
finally:
return result
# SELECT 구문 실행 후에 전체 데이터 ROW 만 불러옴
def select_all(self, sql):
result = None
try:
with self.conn.cursor(pymysql.cursors.DictCursor) as cursor:
cursor.excute(sql)
result = cursor.fetchall()
except Exception as ex:
logging.error(ex)
finally:
return resultFindAnswer.py
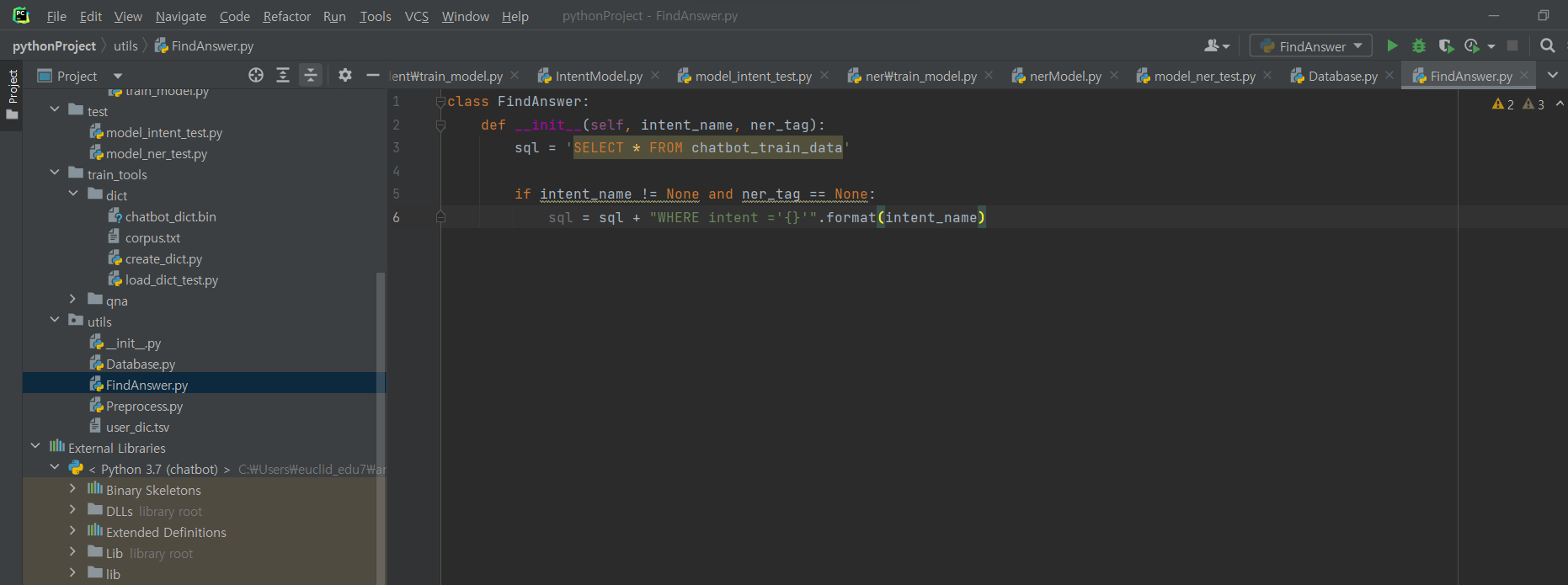
^ FindAnswer.py 파일 생성 후 코드 입력
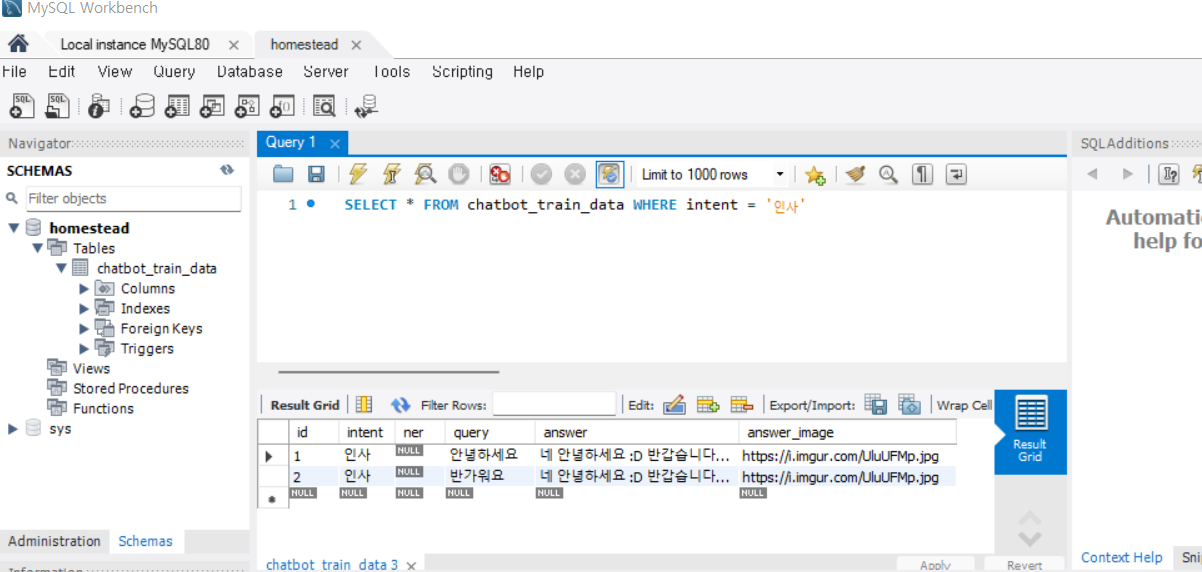
^ 이렇게 확인 가능
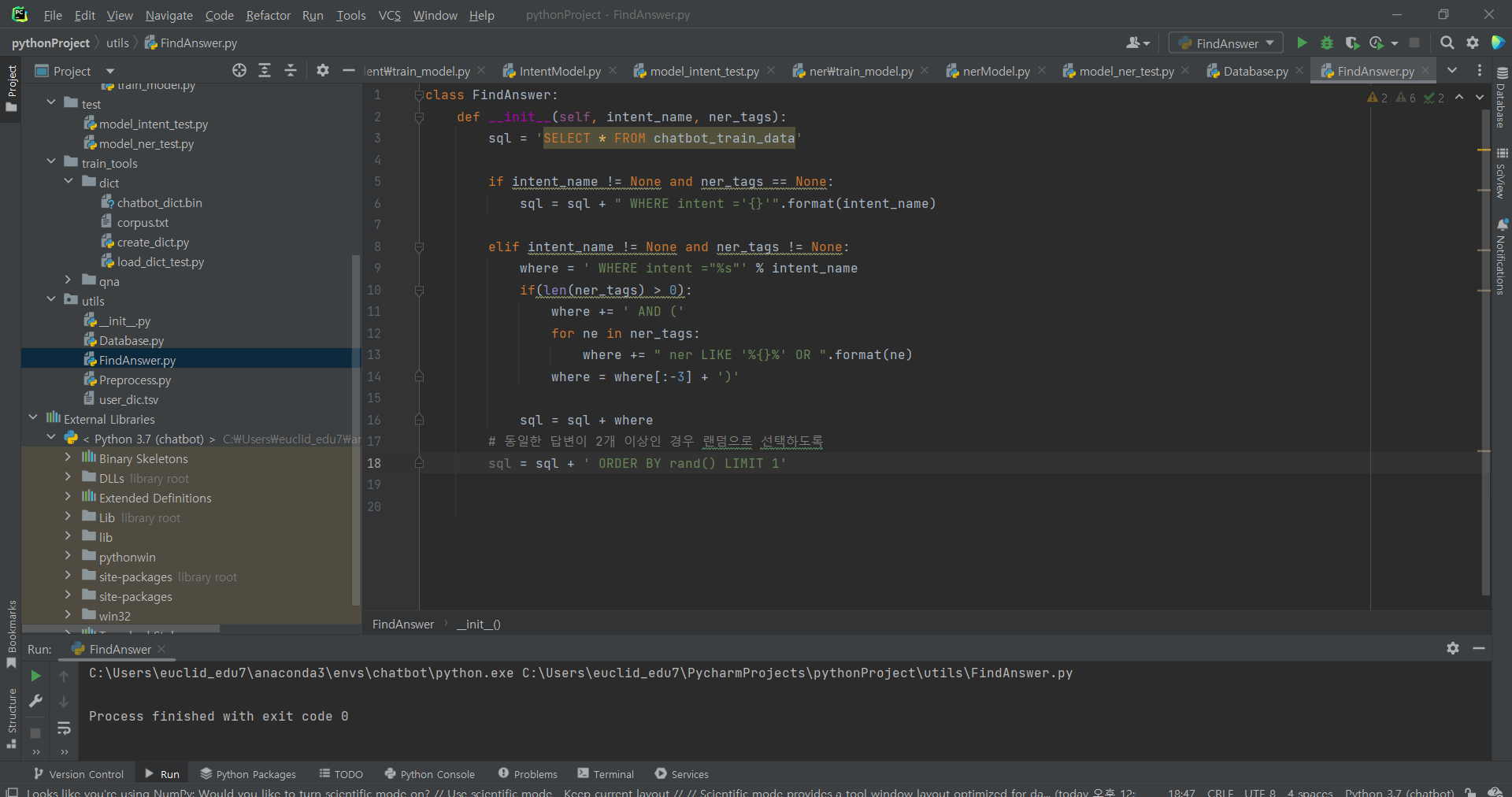
^ 추가 입력
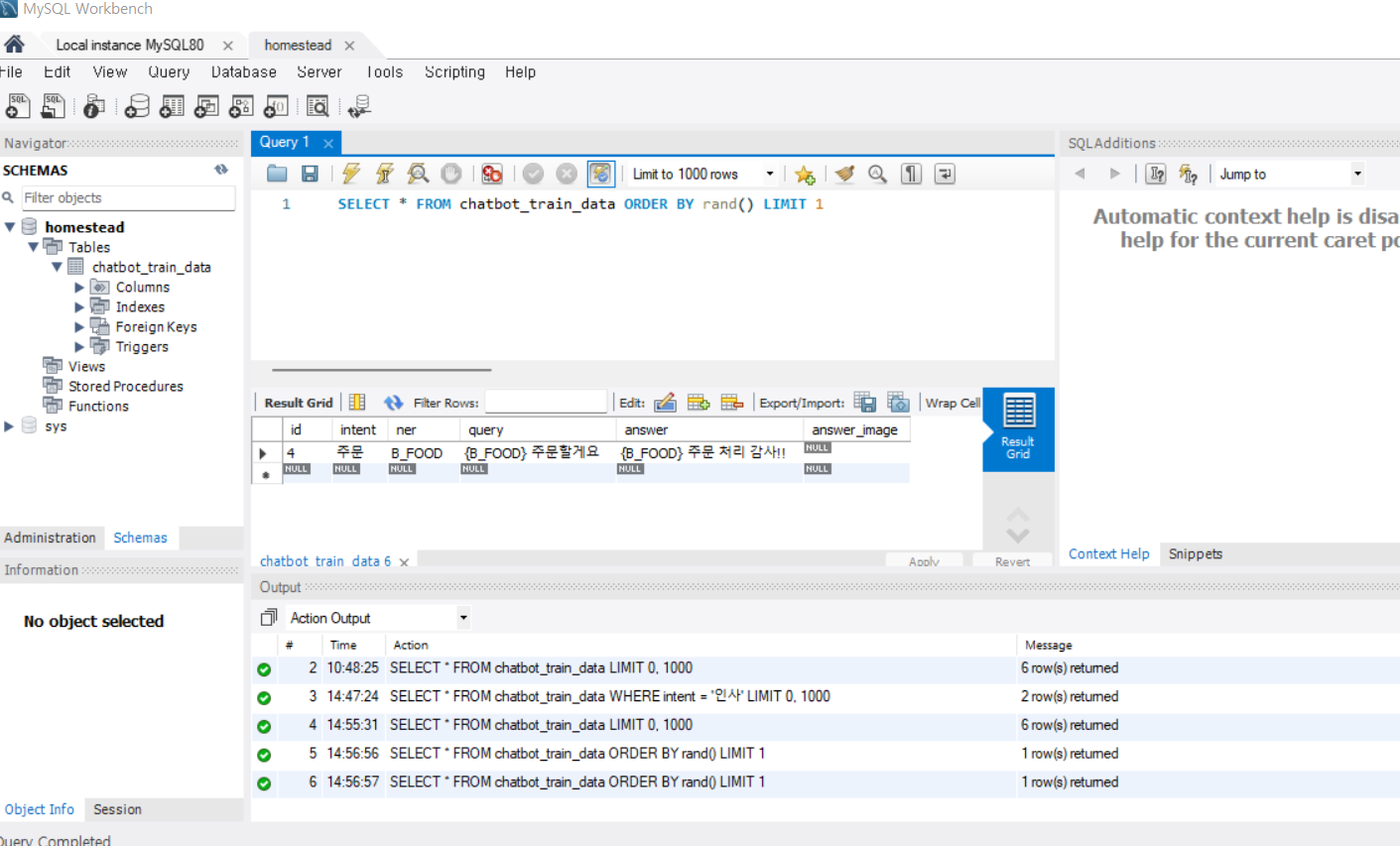
^ 실행할 때마다 다른 값이 나옴
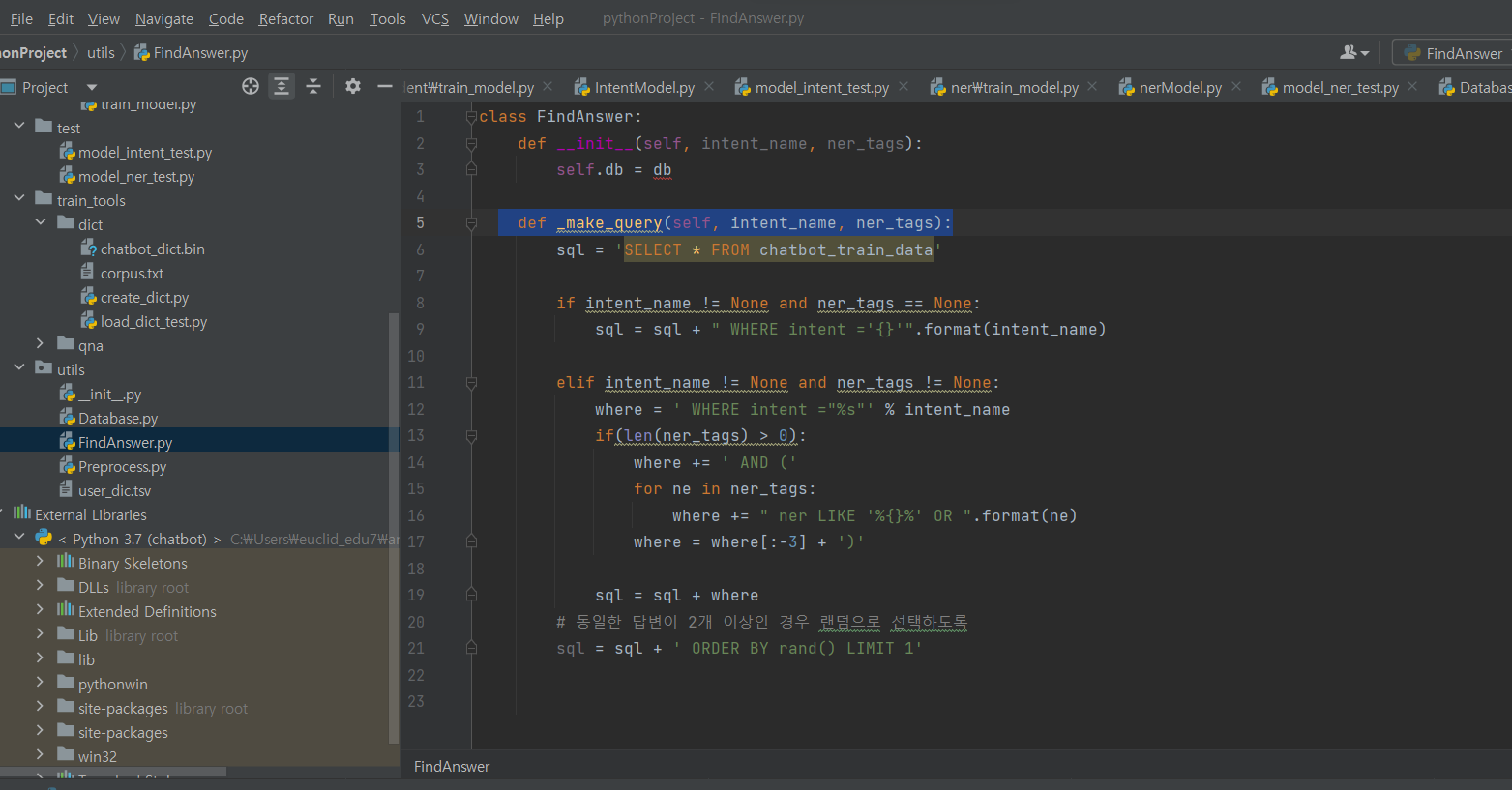
^ 위에 한 줄 추가 입력해주는 거 까먹음
아래는 FindAnswer.py 에 입력해줘야 하는 전체 코드이다.
class FindAnswer:
def __init__(self, intent_name, ner_tags):
self.db = db
def _make_query(self, intent_name, ner_tags):
sql = 'SELECT * FROM chatbot_train_data'
if intent_name != None and ner_tags == None:
sql = sql + " WHERE intent ='{}'".format(intent_name)
elif intent_name != None and ner_tags != None:
where = ' WHERE intent ="%s"' % intent_name
if(len(ner_tags) > 0):
where += ' AND ('
for ne in ner_tags:
where += " ner LIKE '%{}%' OR ".format(ne)
where = where[:-3] + ')'
sql = sql + where
# 동일한 답변이 2개 이상인 경우 랜덤으로 선택하도록
sql = sql + ' ORDER BY rand() LIMIT 1'
return sql
def search(self, intent_name, ner_tags):
sql = self._make_query(intent_name, ner_tags)
answer = self.db.select_one(sql)
# 검색되는 답변이 없으면 의도명만 검색
if answer is None:
sql = self._make_query(intent_name, None)
answer = self.db.select_one(sql)
return (answer['answer'], answer['answer_image'])
# NER 태그를 실제 입력된 단어로 변환
def tag_to_word(self, ner_predicts, answer):
for word, tag in ner_predicts:
if tag == 'B_FOOD' or tag == 'B_DT' or tag == 'B_TI':
answer = answer.replace(tag, word)
answer = answer.replace('{', '')
answer = answer.replace('}', '')
return answer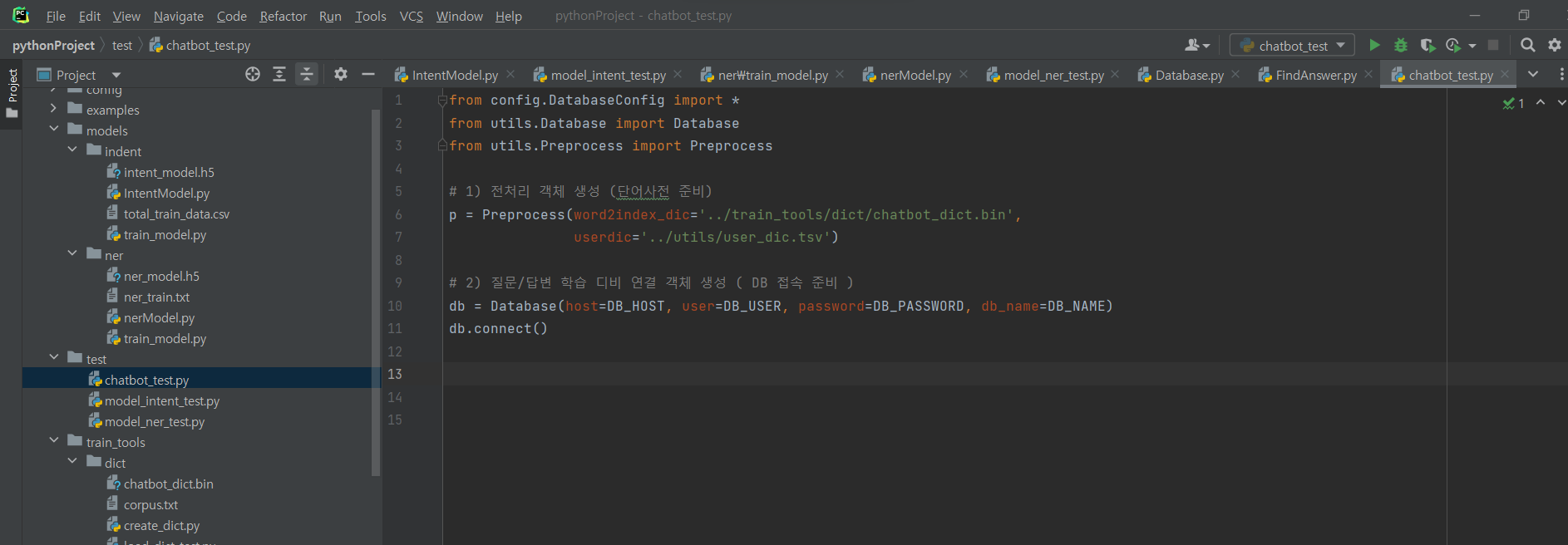
^ chatbot_test.py 파일 생성 후 아래 코드 입력
from config.DatabaseConfig import *
from utils.Database import Database
from utils.Preprocess import Preprocess
# 1) 전처리 객체 생성 (단어사전 준비)
p = Preprocess(word2index_dic='../train_tools/dict/chatbot_dict.bin',
userdic='../utils/user_dic.tsv')
# 2) 질문/답변 학습 디비 연결 객체 생성 ( DB 접속 준비 )
db = Database(host=DB_HOST, user=DB_USER, password=DB_PASSWORD, db_name=DB_NAME)
db.connect()
# 3) 원문 준비
query = '오전에 난자완스 10개 주문합니다.'
# 4) 의도 파악
from models.indent.IntentModel import IntentModel
intent = IntentModel(model_name='../models/indent/intent_model.h5', preprocess=p)
predict = intent.predict_class(query)
intent_name = intent.labels[predict]
# 5) 개체명 인식
from models.ner.nerModel import NerModel
ner = NerModel(model_name='../models/ner/ner_model.h5', preprocess=p)
predicts = ner.predict(query)
ner_tags = ner.predict_tags(query)
print('질문:', query)
print('=' * 100)
print('의도파악:', intent_name)
print('개체명 임식:', predicts)
print('답변 검색에 필요한 NER', ner_tags)
print('=' * 100)
# 6) 답변 검색
from utils.FindAnswer import FindAnswer
try:
f = FindAnswer(db)
answer_text, answer_image = f.search(intent_name, ner_tags)
answer = f.tag_to_word(predicts, answer_text)
except:
answer = '죄송해요 무슨 말인지 모르겠어요'
print('답변:', answer)
db.close()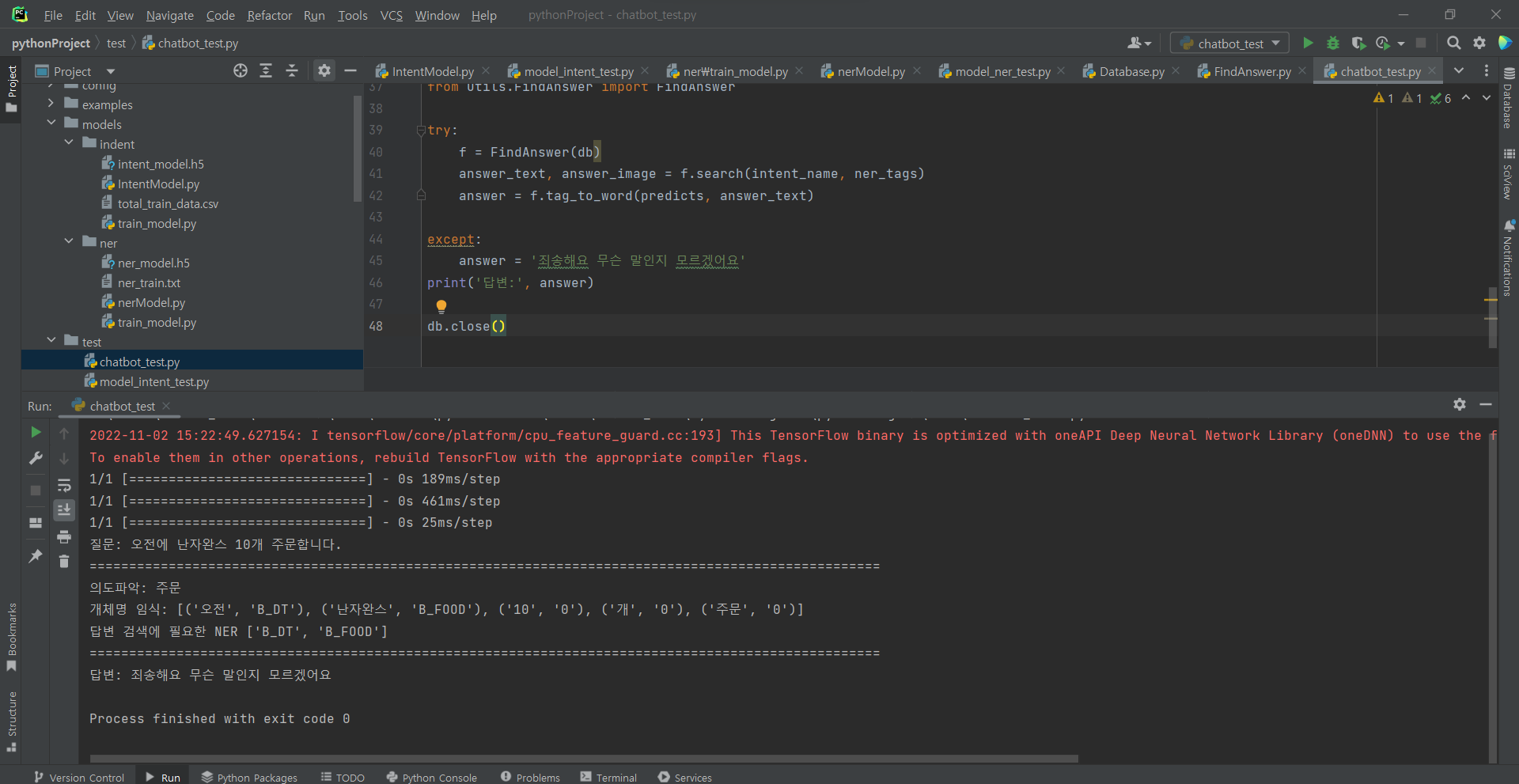
^ 실행해보기.
BotServer.py
^ 다음 위치에 BotServer 데이터 넣어줌.
import socket
class BotServer:
def __init__(self, srv_port, listen_num):
self.port = srv_port
self.listen = listen_num
self.mySock = None
# sock 생성
def create_sock(self):
self.mySock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.mySock.bind(("0.0.0.0", int(self.port)))
self.mySock.listen(int(self.listen))
return self.mySock
# client 대기
def ready_for_client(self):
return self.mySock.accept()
# sock 반환
def get_sock(self):
return self.mySock
^ bot.py 파일 넣어주기
import threading
import json
from config.DatabaseConfig import *
from utils.Database import Database
from utils.BotServer import BotServer
from utils.Preprocess import Preprocess
from models.intent.IntentModel import IntentModel
from models.ner.NerModel import NerModel
from utils.FindAnswer import FindAnswer
# 전처리 객체 생성
p = Preprocess(word2index_dic='train_tools/dict/chatbot_dict.bin',
userdic='utils/user_dic.tsv')
# 의도 파악 모델
intent = IntentModel(model_name='models/intent/intent_model.h5', proprocess=p)
# 개체명 인식 모델
ner = NerModel(model_name='models/ner/ner_model.h5', proprocess=p)
def to_client(conn, addr, params):
db = params['db']
try:
db.connect() # 디비 연결
# 데이터 수신
read = conn.recv(2048) # 수신 데이터가 있을 때 까지 블로킹
print('===========================')
print('Connection from: %s' % str(addr))
if read is None or not read:
# 클라이언트 연결이 끊어지거나, 오류가 있는 경우
print('클라이언트 연결 끊어짐')
exit(0)
# json 데이터로 변환
recv_json_data = json.loads(read.decode())
print("데이터 수신 : ", recv_json_data)
query = recv_json_data['Query']
# 의도 파악
intent_predict = intent.predict_class(query)
intent_name = intent.labels[intent_predict]
# 개체명 파악
ner_predicts = ner.predict(query)
ner_tags = ner.predict_tags(query)
# 답변 검색
try:
f = FindAnswer(db)
answer_text, answer_image = f.search(intent_name, ner_tags)
answer = f.tag_to_word(ner_predicts, answer_text)
except:
answer = "죄송해요 무슨 말인지 모르겠어요. 조금 더 공부 할게요."
answer_image = None
send_json_data_str = {
"Query" : query,
"Answer": answer,
"AnswerImageUrl" : answer_image,
"Intent": intent_name,
"NER": str(ner_predicts)
}
message = json.dumps(send_json_data_str)
conn.send(message.encode())
except Exception as ex:
print(ex)
finally:
if db is not None: # db 연결 끊기
db.close()
conn.close()
if __name__ == '__main__':
# 질문/답변 학습 디비 연결 객체 생성
db = Database(
host=DB_HOST, user=DB_USER, password=DB_PASSWORD, db_name=DB_NAME
)
print("DB 접속")
port = 5050
listen = 100
# 봇 서버 동작
bot = BotServer(port, listen)
bot.create_sock()
print("bot start")
while True:
conn, addr = bot.ready_for_client()
params = {
"db": db
}
client = threading.Thread(target=to_client, args=(
conn,
addr,
params
))
client.start()
^ 파일 넣어주기
import socket
import json
# 챗봇 엔진 서버 접속 정보
host = "127.0.0.1" # 챗봇 엔진 서버 IP 주소
port = 5050 # 챗봇 엔진 서버 통신 포트
# 클라이언트 프로그램 시작
while True:
print("질문 : ")
query = input() # 질문 입력
if(query == "exit"):
exit(0)
print("-" * 40)
# 챗봇 엔진 서버 연결
mySocket = socket.socket()
mySocket.connect((host, port))
# 챗봇 엔진 질의 요청
json_data = {
'Query': query,
'BotType': "MyService"
}
message = json.dumps(json_data)
mySocket.send(message.encode())
# 챗봇 엔진 답변 출력
data = mySocket.recv(2048).decode()
ret_data = json.loads(data)
print("답변 : ")
print(ret_data['Answer'])
print(ret_data)
print(type(ret_data))
print("\n")
# 챗봇 엔진 서버 연결 소켓 닫기
mySocket.close()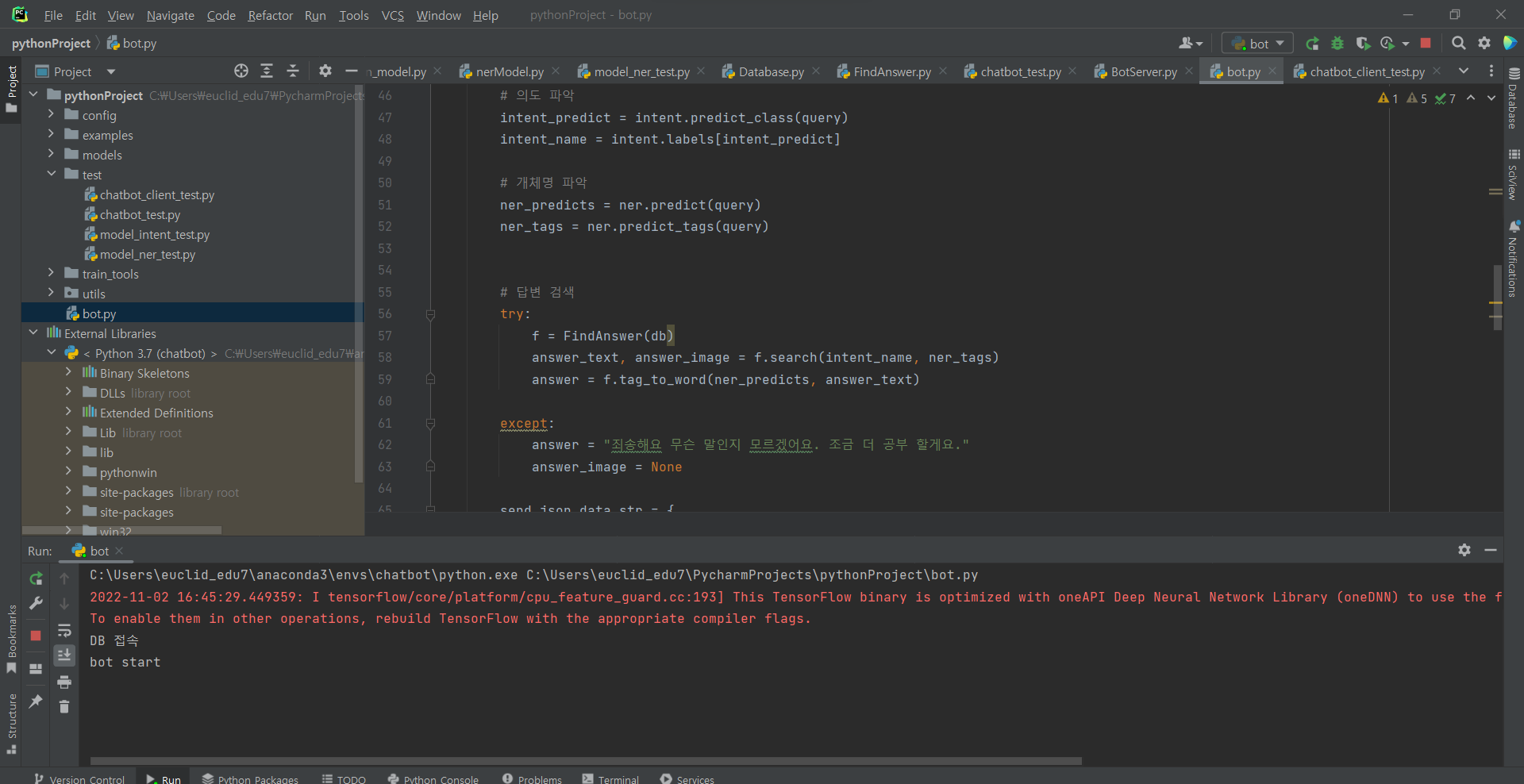
^ 실행 후 엑세스 허용
이 파일에서 코드 조금 수정함 --
import threading
import json
from config.DatabaseConfig import *
from utils.Database import Database
from utils.BotServer import BotServer
from utils.Preprocess import Preprocess
from models.indent.IntentModel import IntentModel
from models.ner.nerModel import NerModel
from utils.FindAnswer import FindAnswer
# 전처리 객체 생성
p = Preprocess(word2index_dic='train_tools/dict/chatbot_dict.bin',
userdic='utils/user_dic.tsv')
# 의도 파악 모델
intent = IntentModel(model_name='models/indent/intent_model.h5', preprocess=p)
# 개체명 인식 모델
ner = NerModel(model_name='models/ner/ner_model.h5', preprocess=p)
def to_client(conn, addr, params):
db = params['db']
try:
db.connect() # 디비 연결
# 데이터 수신
read = conn.recv(2048) # 수신 데이터가 있을 때 까지 블로킹
print('===========================')
print('Connection from: %s' % str(addr))
if read is None or not read:
# 클라이언트 연결이 끊어지거나, 오류가 있는 경우
print('클라이언트 연결 끊어짐')
exit(0)
# json 데이터로 변환
recv_json_data = json.loads(read.decode())
print("데이터 수신 : ", recv_json_data)
query = recv_json_data['Query']
# 의도 파악
intent_predict = intent.predict_class(query)
intent_name = intent.labels[intent_predict]
# 개체명 파악
ner_predicts = ner.predict(query)
ner_tags = ner.predict_tags(query)
# 답변 검색
try:
f = FindAnswer(db)
answer_text, answer_image = f.search(intent_name, ner_tags)
answer = f.tag_to_word(ner_predicts, answer_text)
except:
answer = "죄송해요 무슨 말인지 모르겠어요. 조금 더 공부 할게요."
answer_image = None
send_json_data_str = {
"Query" : query,
"Answer": answer,
"AnswerImageUrl" : answer_image,
"Intent": intent_name,
"NER": str(ner_predicts)
}
message = json.dumps(send_json_data_str)
conn.send(message.encode())
except Exception as ex:
print(ex)
finally:
if db is not None: # db 연결 끊기
db.close()
conn.close()
if __name__ == '__main__':
# 질문/답변 학습 디비 연결 객체 생성
db = Database(
host=DB_HOST, user=DB_USER, password=DB_PASSWORD, db_name=DB_NAME
)
print("DB 접속")
port = 5050
listen = 100
# 봇 서버 동작
bot = BotServer(port, listen)
bot.create_sock()
print("bot start")
while True:
conn, addr = bot.ready_for_client()
params = {
"db": db
}
client = threading.Thread(target=to_client, args=(
conn,
addr,
params
))
client.start()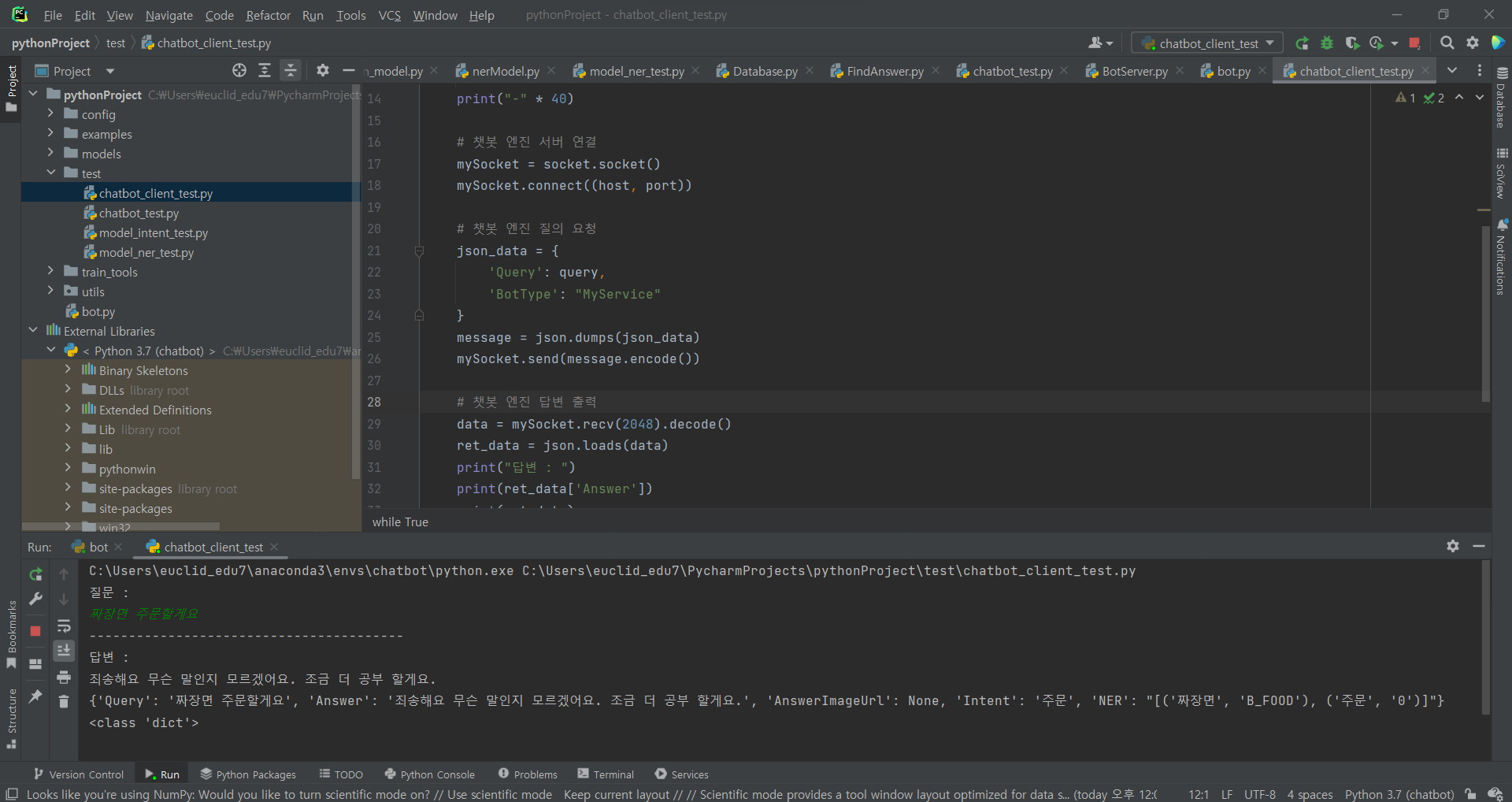
^ 실행 후 질문을 넣어주기
