상권분석할때 소비자들 반응 보기 위해 자주 사용됨
# selenium 설치
!pip install selenium
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin# 한글 깨짐 방지
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()라이브러리 임포트
#라이브러리 임포트
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
유튜브 댓글 크롤링
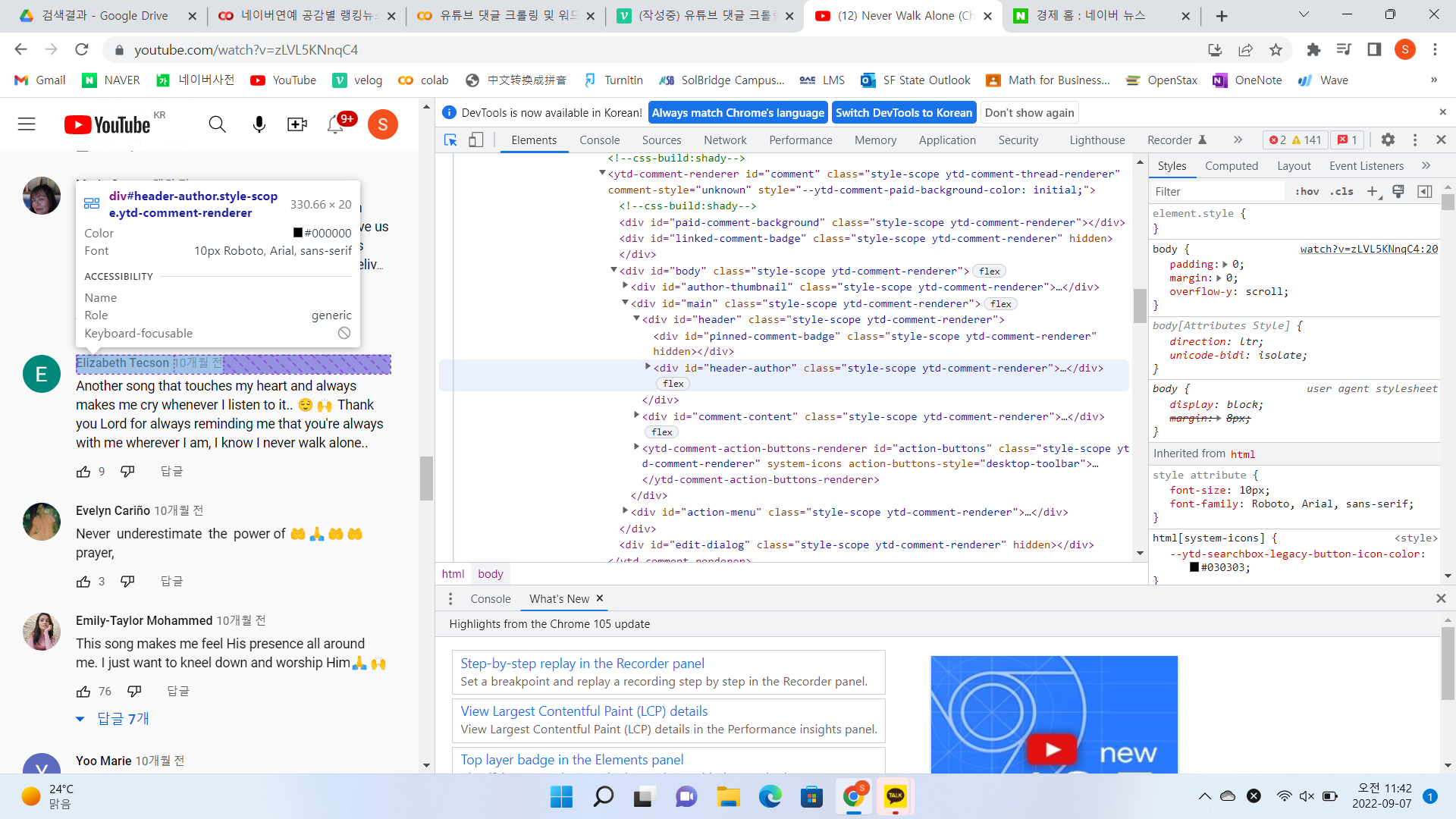
^ 댓글크롤링) header-author > h3 > #author-text > span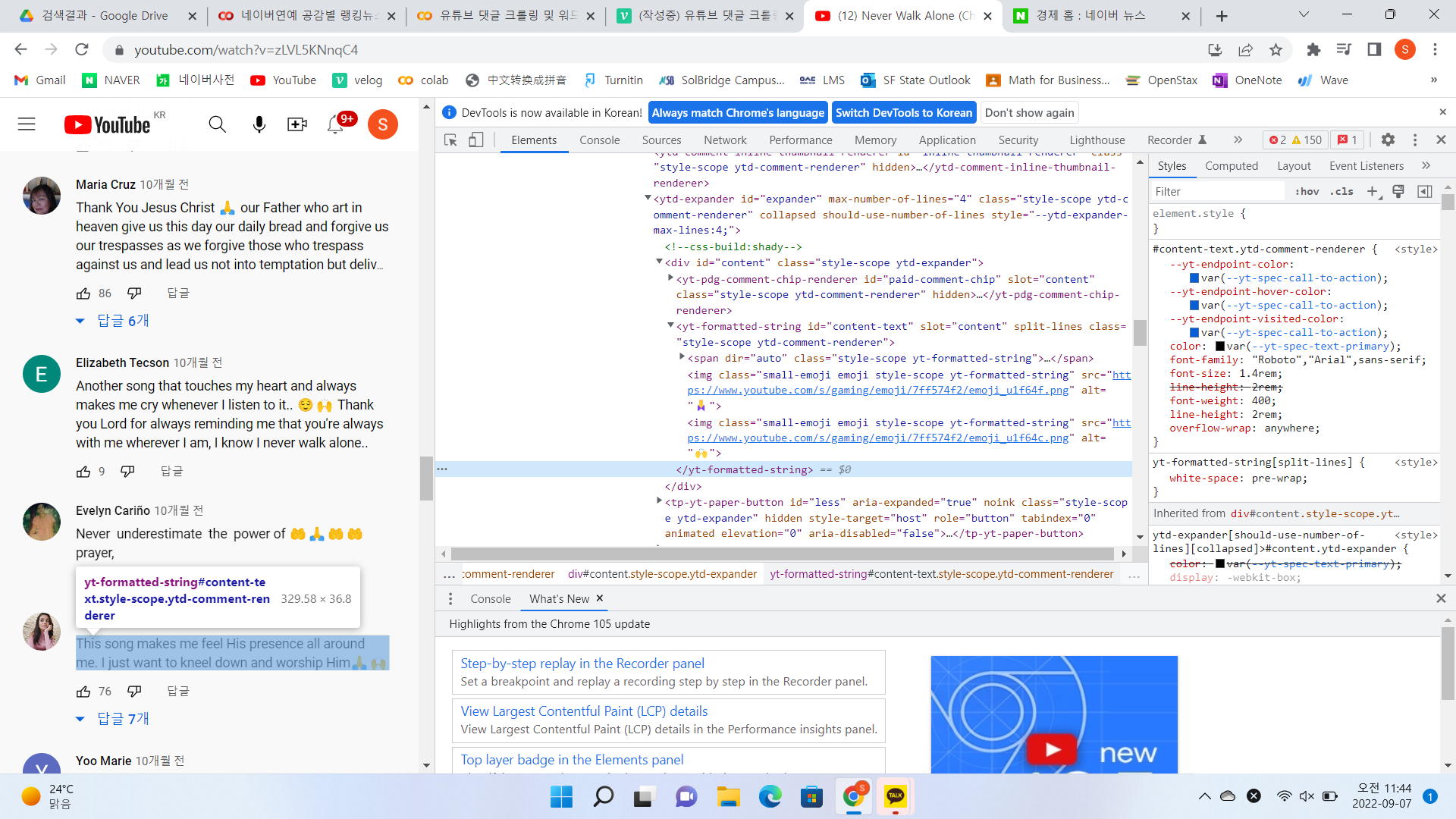
^ 댓글크롤링) yt-formatted-string#content-text코드:
from typing_extensions import ParamSpecKwargs
from io import BufferedIOBase
# https://youtu.be/QXsgwMjF_z4 #유튜브의 공유버튼 링크
options = webdriver.ChromeOptions()
options.add_argument('--headless') #head-less 설정
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
driver = webdriver.Chrome('chromedriver', options=options)
driver.get('https://youtu.be/QXsgwMjF_z4')
driver.implicitly_wait(3)
time.sleep(1.5) #로딩되는 시간 기다렸다가 스크롤 내리기
driver.execute_script("window.scrollTo(0, 800)") #명령어
time.sleep(3)
# 댓글 수집을 위한 스크롤 내리기
last_height = driver.execute_script("return document.documentElement.scrollHeight") #return함) 최초 접속시 스크롤 높이 초기화
while True: # 조심) 이거 안 닫아주면 껏다 다시 켜야함
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);") #추가 작업) 0부터 document~ 까지 스크롤해라
time.sleep(1.5)
new_height = driver.execute_script("return document.documentElement.scrollHeight")
if new_height == last_height: #if 최초 스크롤화면이랑 newest 화면이랑 같으면 break 벗어나라
break #while에 대한 break
last_height = new_height
time.sleep(1.5)
#선택적 코드) 광고와 같은거 나올때 닫아주기
try:
driver.find_element_by_css_selector('#dismiss-button > a').click() #유튜브 1달 무료 팝업 닫기
time.sleep(1.5)
except:
pass
# 댓글 크롤링
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
id_list = soup.select('div#header-author > h3 > #author-text > span') #사이트 F12해서 코드 보고 입력
comment_list = soup.select('yt-formatted-string#content-text') #사이트 F12해서 코드 보고 입력
id_final = []
comment_final = []
for i in range(len(comment_list)): #댓글의 갯수많큼 for문 돌겠다
#댓글 작성자 수집
temp_id = id_list[i].text
temp_id = temp_id.replace('\n', '').replace('\t', '').replace(' ', '').strip()
id_final.append(temp_id)
#댓글 내용 수집
temp_comment = comment_list[i].text
temp_comment = temp_comment.replace('\n', '').replace('\t', '').replace(' ', '').strip()
comment_final.append(temp_comment)
#dataframe 만들기 (list -> dic -> dataframe)
youtube_dic = {"아이디": id_final, "댓글 내용": comment_final}
youtube_pd = pd.DataFrame(youtube_dic)
youtube_pd.head()youtube_pd.info()크롤링 데이터 저장
youtube_pd.to_csv('파일저장이름.csv', encoding = 'utf-8-sig', index=False)워드 클라우드 시각화
df = pd.read_csv('파일저장이름.csv')
df.info()BUT, 워드 클라우드 하기 전 장애물을 찾았다.

^ youtube_pd['댓글 내용'][0] #댓글 내용 확인해보니 방해되는 csv찾았다
^ 방해되는 친구들 찾았으니 위에가서 replace('\r','') 코드 추가해줘df.head(20)text = " ".join(li for li in df['댓글 내용'].astype(str))
text#워드클라우드
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
plt.subplots(figsize=(25, 15))
wordcloud = WordCloud(background_color ='black', width = 1000, height = 700, font_path=fontpath).generate(text)
plt.axis('off')
plt. imshow(wordcloud, interpolation='bilinear')
plt.show()me-time

# 특정 모양을 가진 워드 클라우드 만들기
from PIL import Image
import numpy as np
from wordcloud import WordCloud, STOPWORDS,ImageColorGenerator
import matplotlib
import matplotlib.pyplot as plt # Python Imaging Library
from matplotlib.colors import LinearSegmentedColormap
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (16.0, 9.0)
mask = Image.open('/content/kelly.jpg')
mask = np.array(mask)
stopwords = set(STOPWORDS)
# Custom Colormap
colors = ["blue", "red"]
cmap = LinearSegmentedColormap.from_list("mycmap", colors)
#워드클라우드
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
wordcloud = WordCloud(background_color ='white',width = 1000, height = 700,mask = mask,stopwords = set(STOPWORDS), font_path = r"/content/Lobster-Regular.ttf",colormap=cmap).generate(text)
plt.figure()
plt.axis('off')
plt. imshow(wordcloud, interpolation='bilinear')
plt.show()^ 사이트에서 폰트 다운로드 후 경로복사하여 글씨체 변경해줌
font_path = r"/content/Lobster-Regular.ttf"