#ABC부트캠프 #유클리드소프트 #2022청년ESG지원사업 #코딩 #대전부트캠프 #대전청년 #ESG경영 #파이썬 #빅데이터 #대전IT교육 #프로그래밍 #개발자 #진로탐색 #데이터교육 #ESG교육딥러닝 모델 - 챗봇 문답
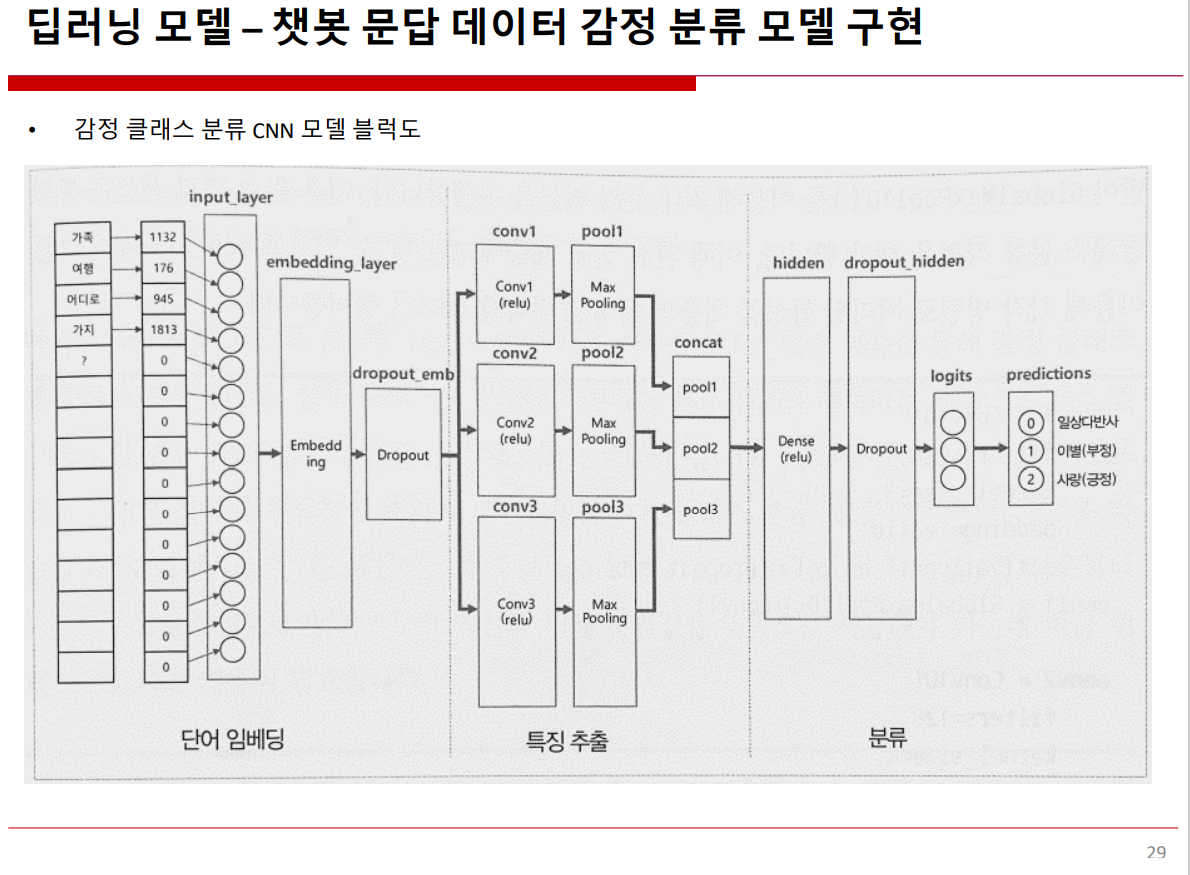
^ 챗봇 문답 데이터 감정 분류 모델 구현
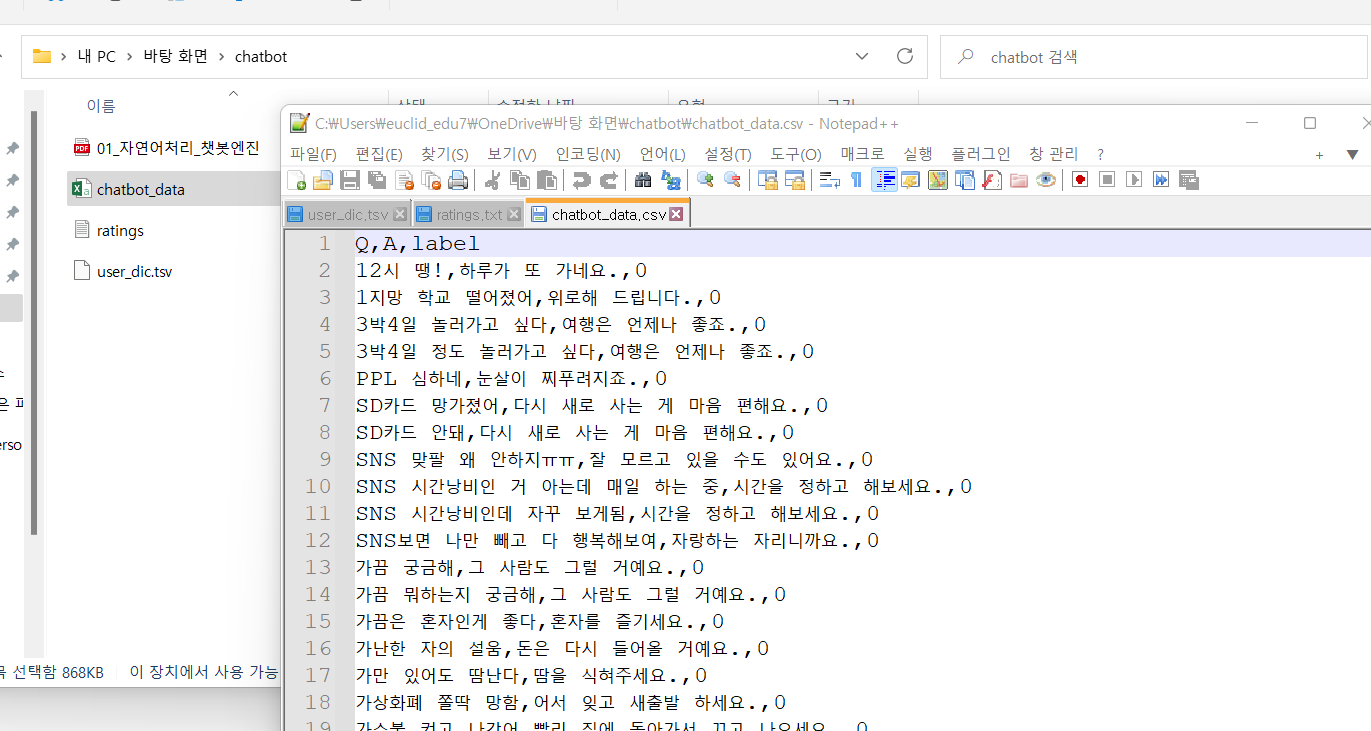
^ chatbot data 파일 Notepadd ++ 로 열어보기.
^ pycharm 어제 한거 열어서 models파일 생성 후 데이터 파일 넣기
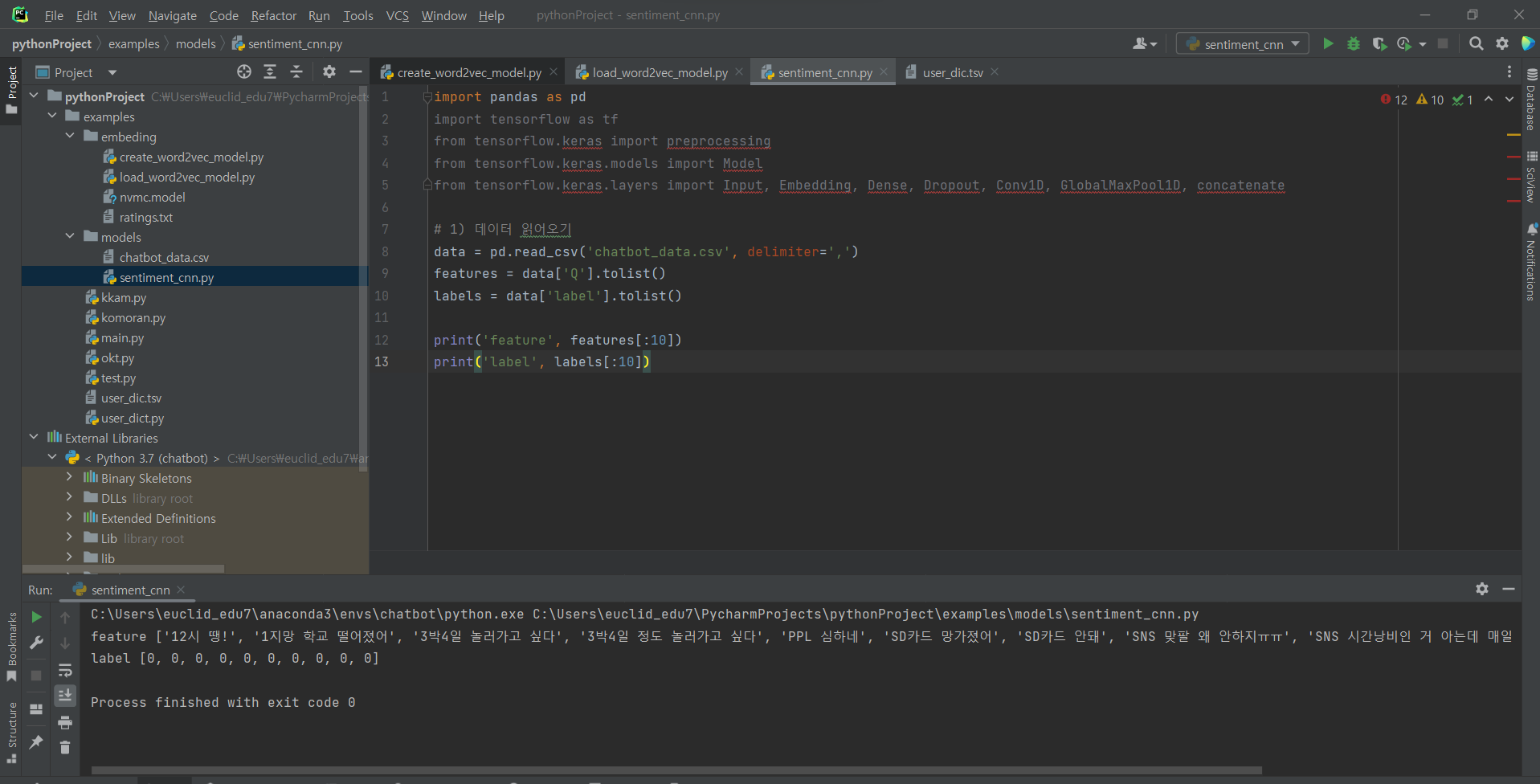
^ (1) 데이터 읽어오기: 파일 생성 후 코드 입력
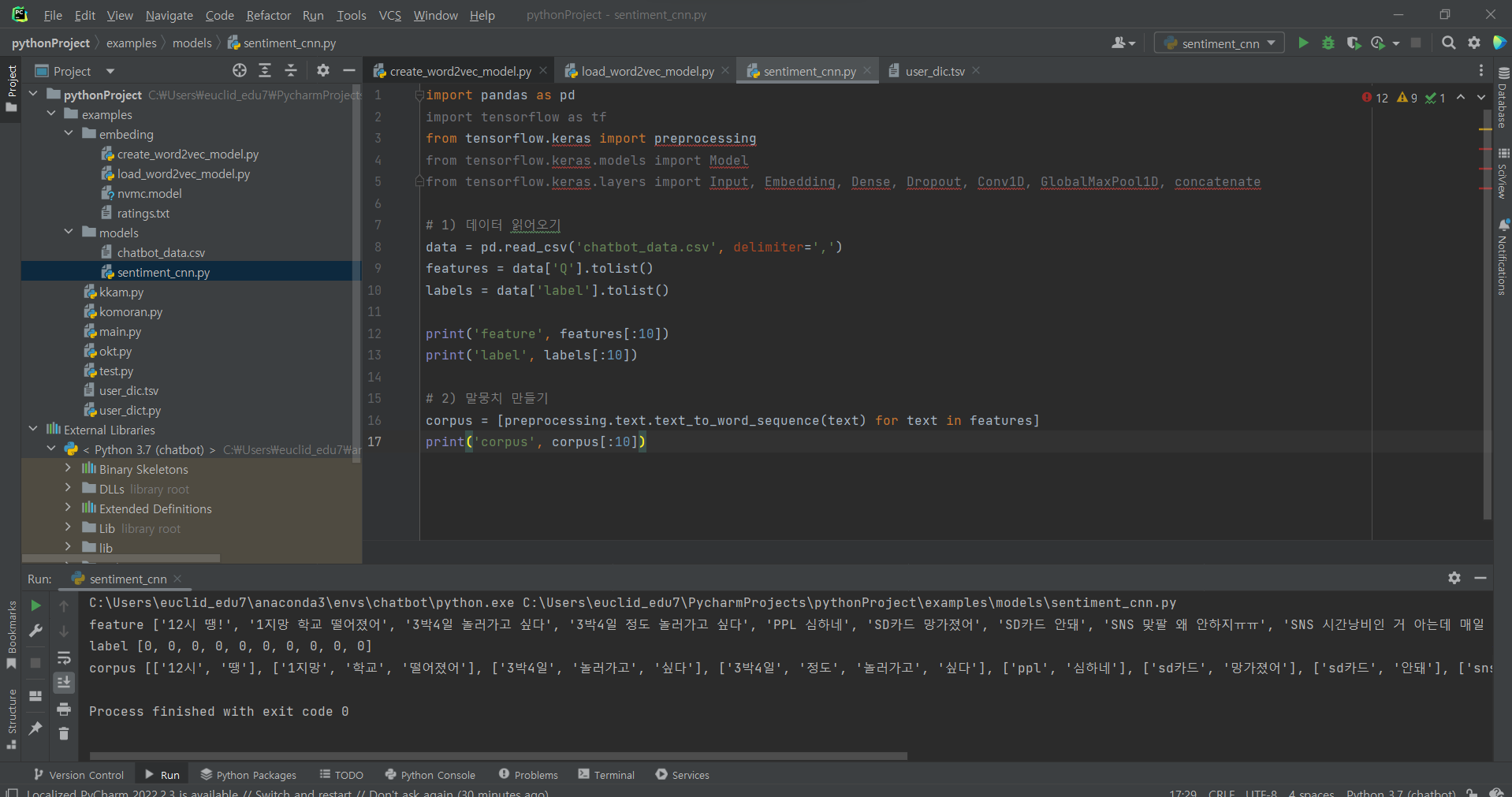
^ (2) 말뭉치 만들기: 단어를 떼어 하나의 리스트로 담아줌.
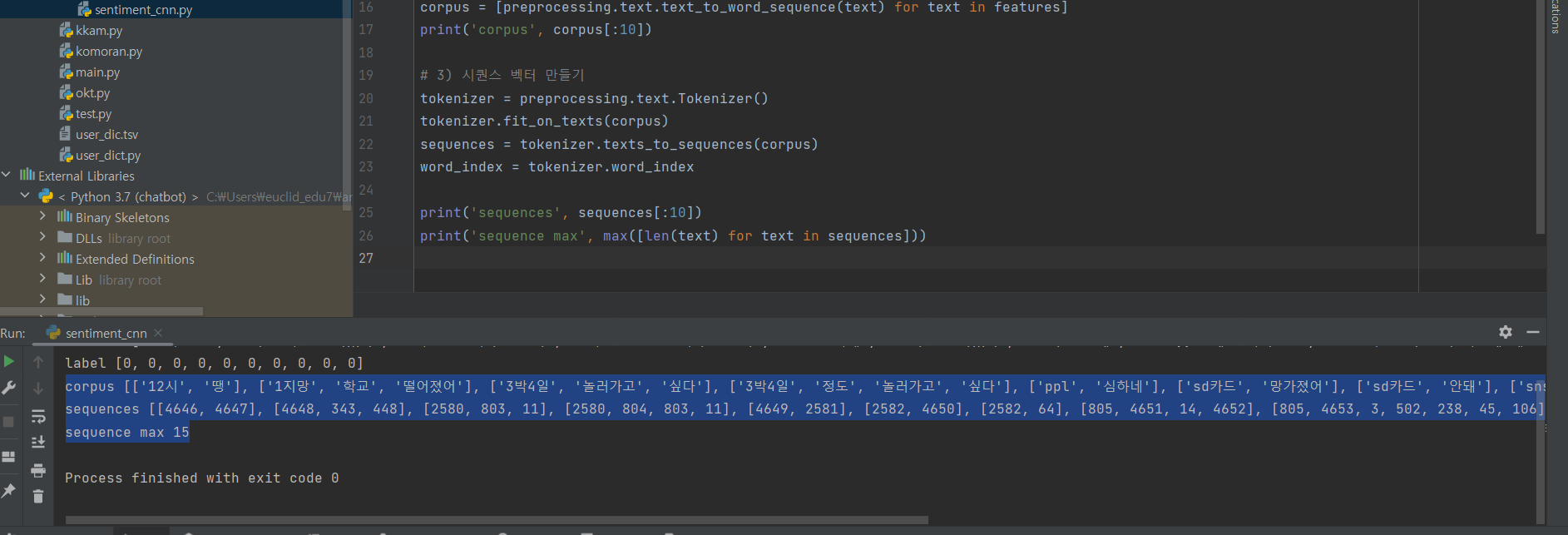
^ (3) 시퀀스 벡터 만들기
^ 부가 설명
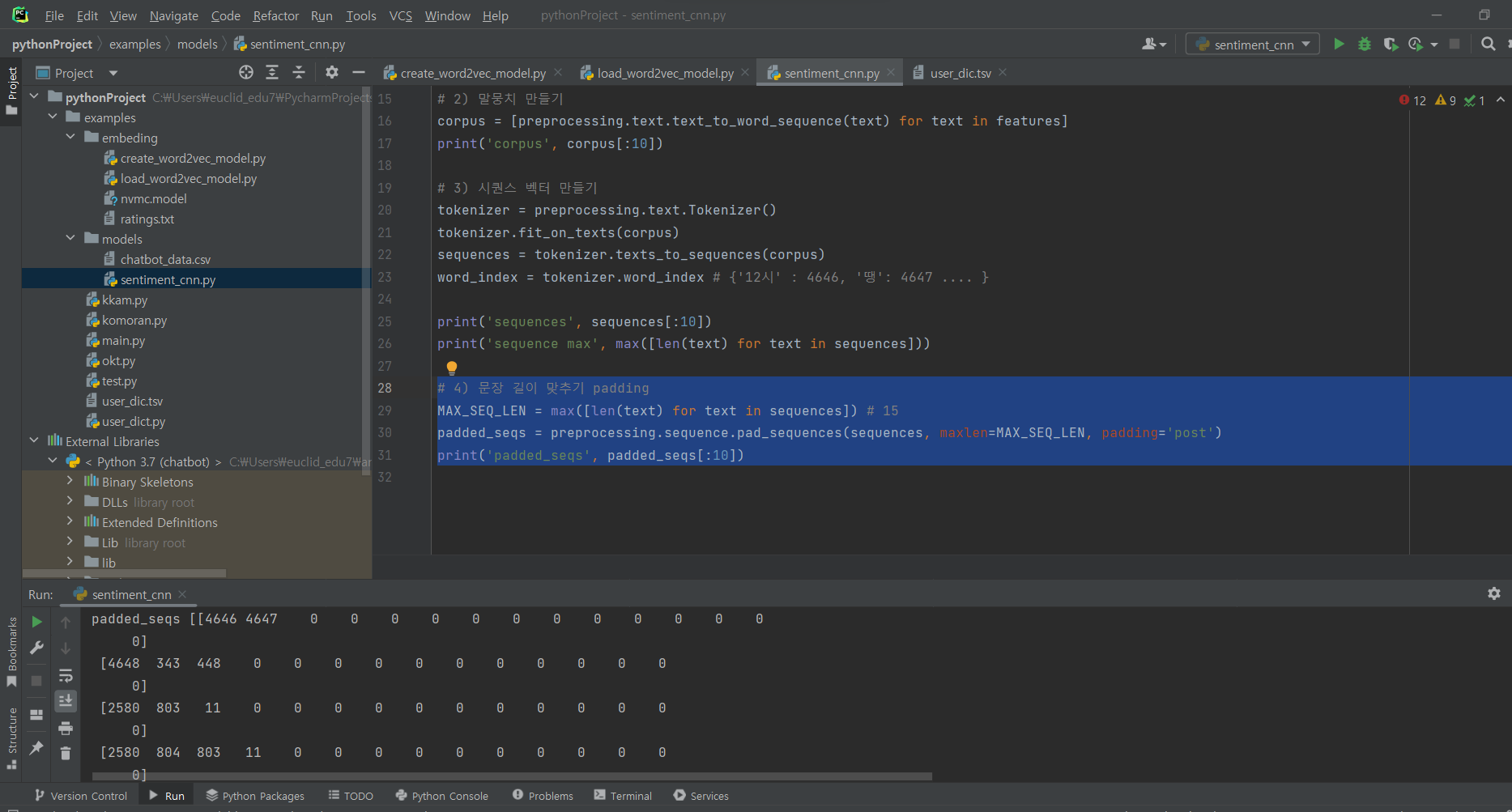
^ (4) 문장 길이 맞추기 padding
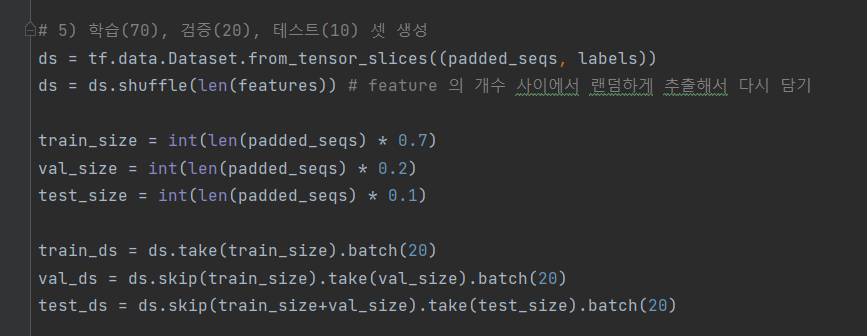
^ (5) 학습(70), 검증(20), 테스트(10) 셋 생성
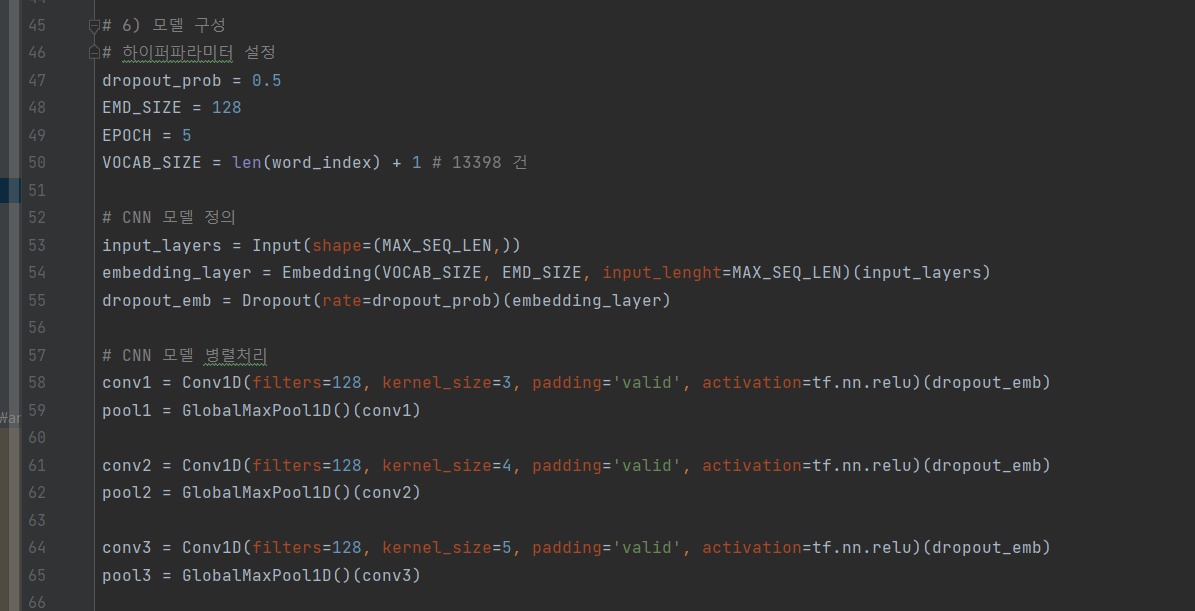
^ (6) 모델 구성: 하이퍼파라미터 설정, CNN 모델 정의, CNN 모델 병렬처리
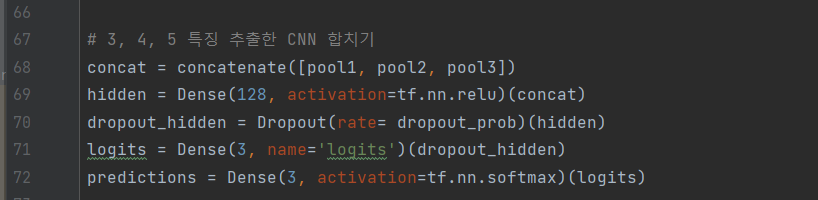
^ (6-1) 특징 추출한 CNN 합치기
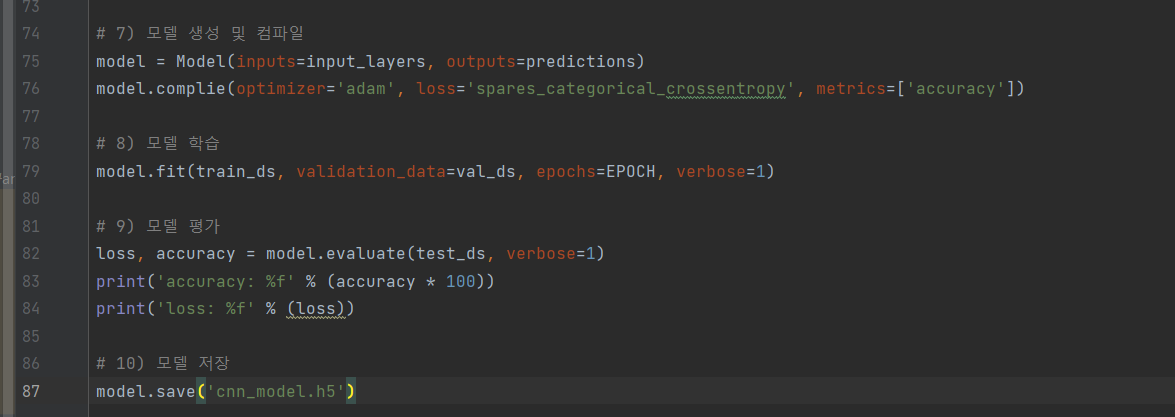
^ (7) 모델 생성 및 컴파일
(8) 모델 학습
(9) 모델 평가
(10) 모델 저장
**근데 오타 많아서 ..... 잘 수정 후 해줘
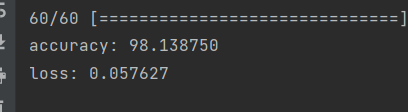
^ 결과
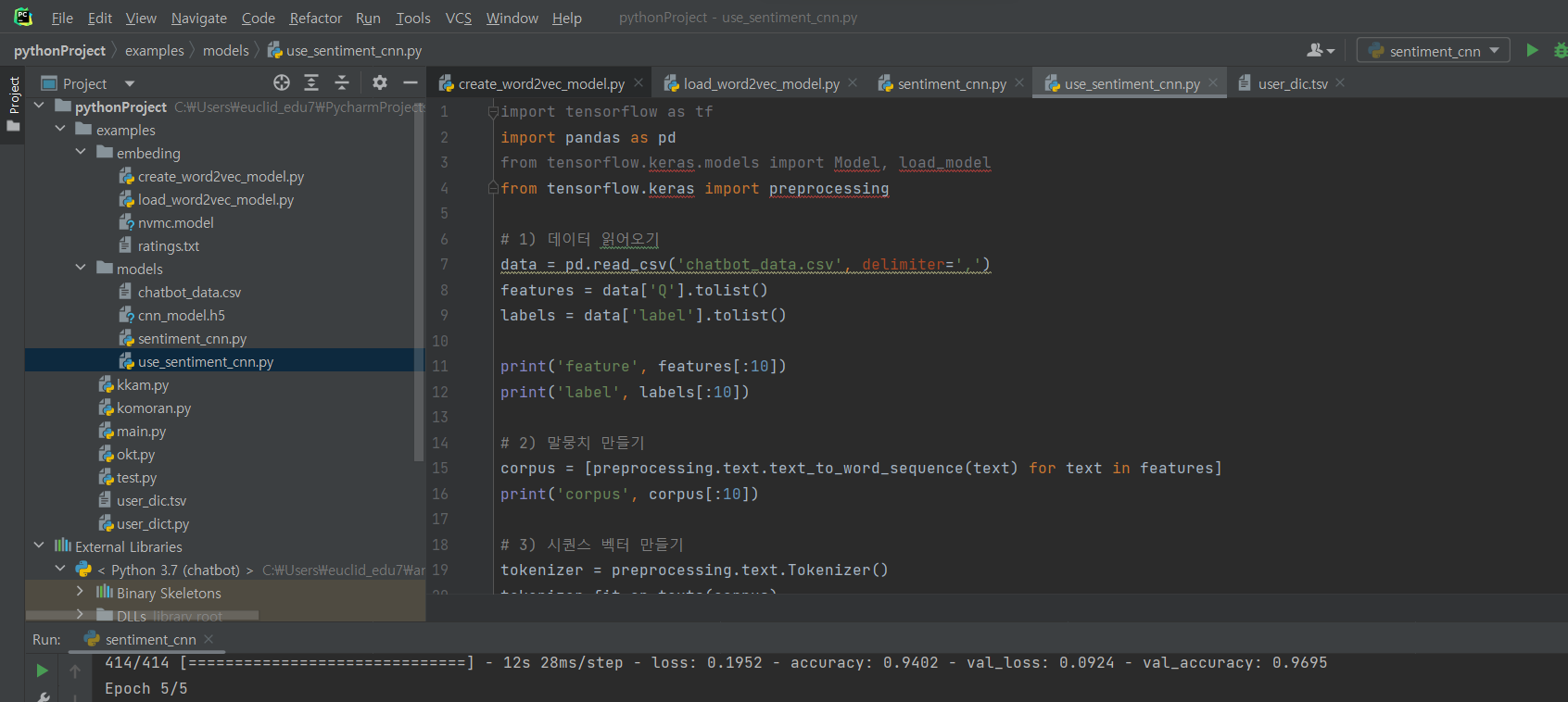
^ 파일 새로 만들고 import 하고 sentiment_cnn.py 에서 4번까지 복붙하기
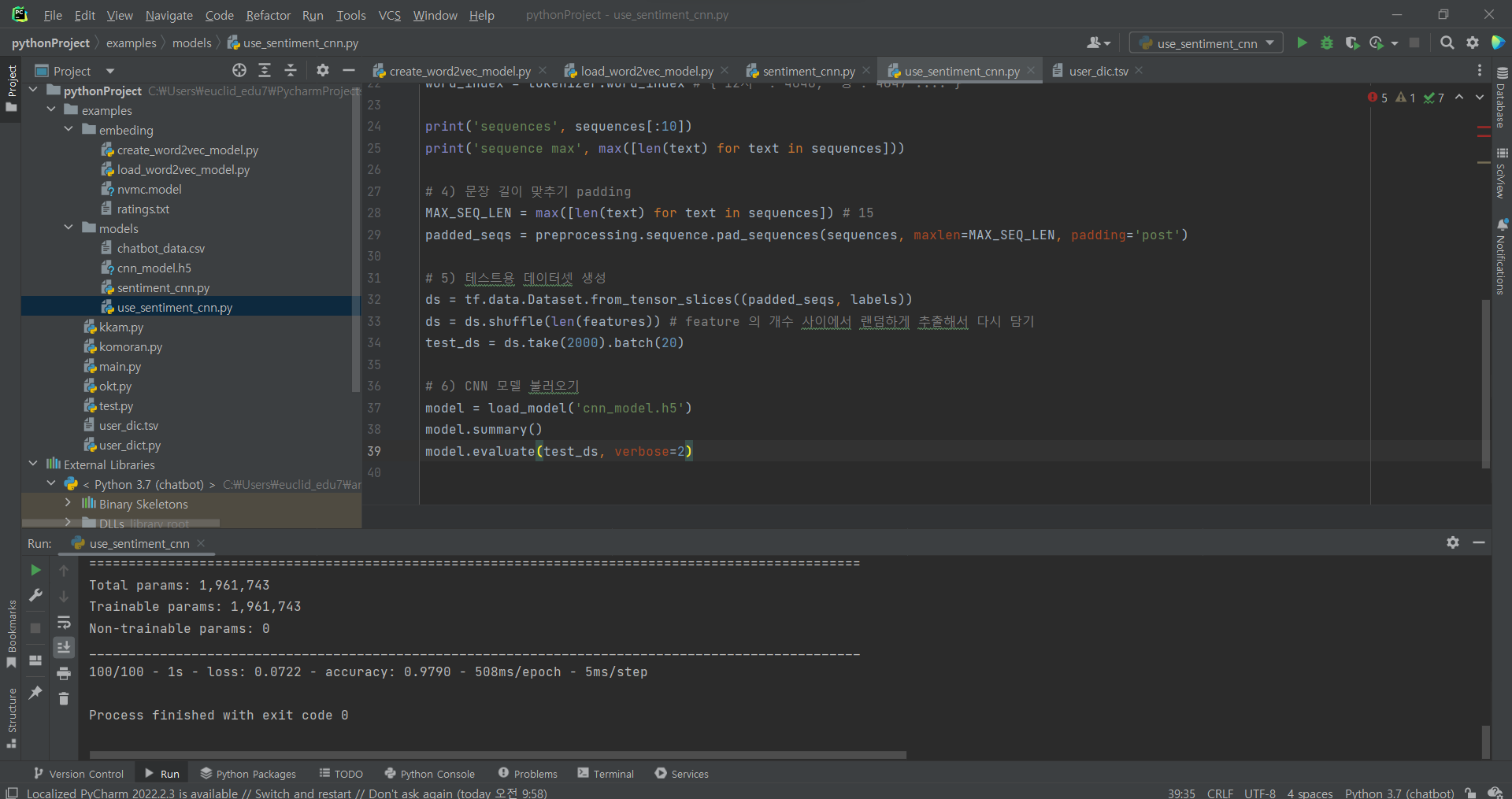
^ 코드 추가 입력 5,6
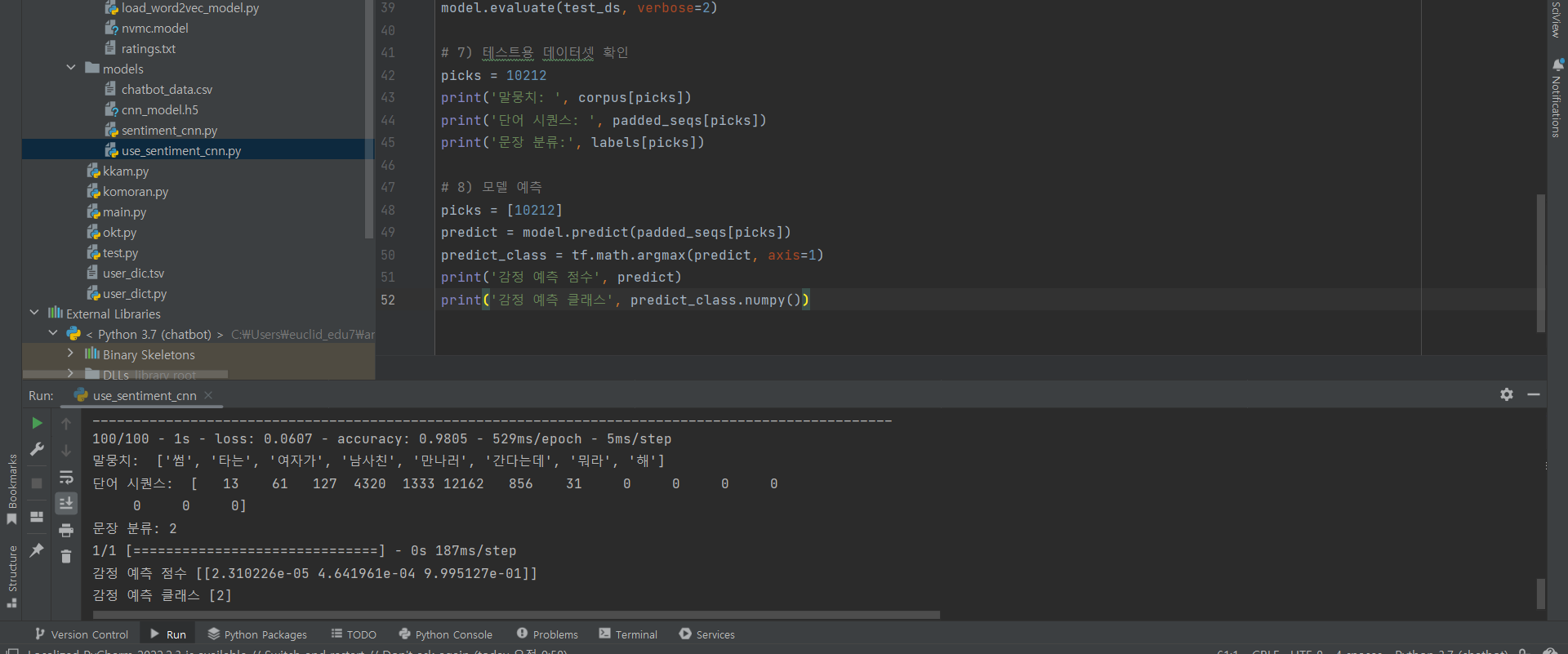
^ 코드 추가 입력 7, 8
LSTM
^ train 파일 다음 위치에 넣어줌
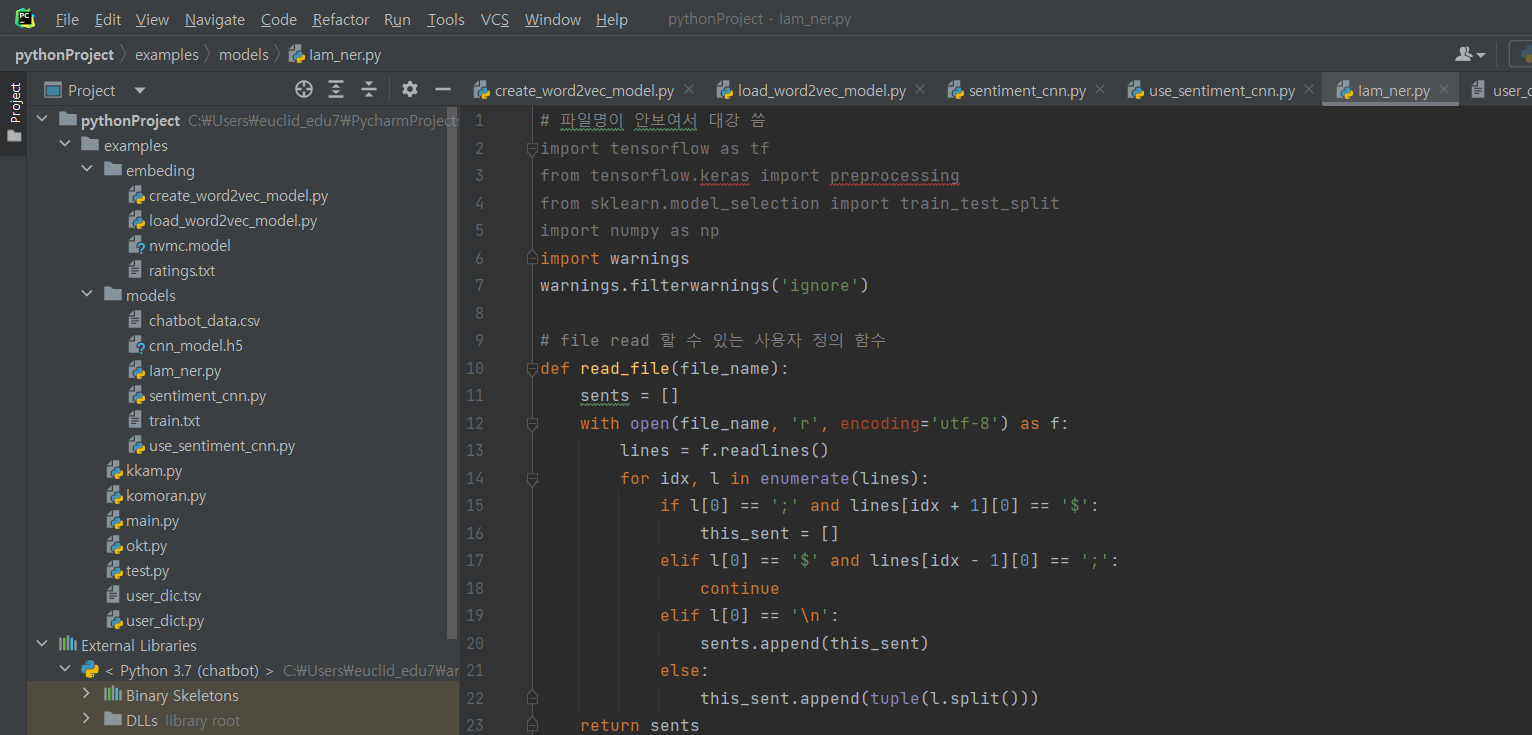
^ (1) 파일 생성 후 코드 입력
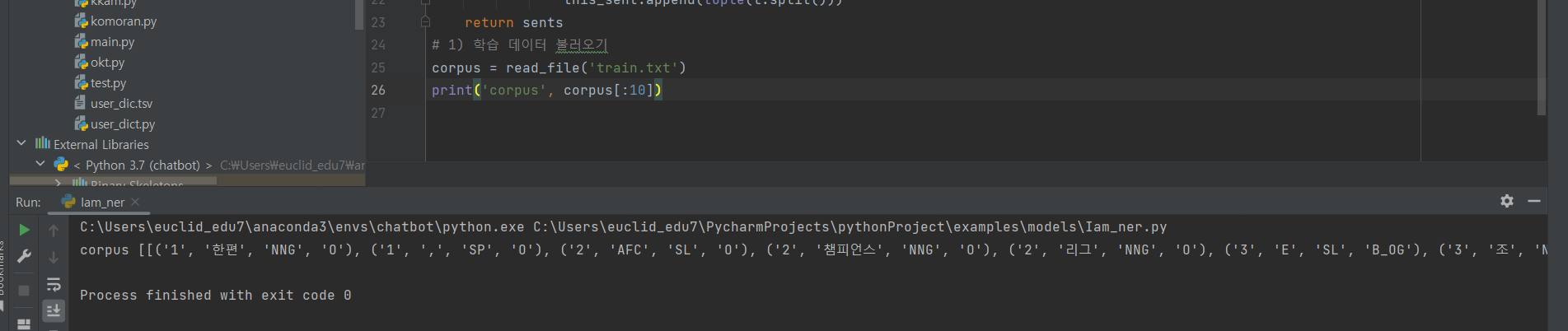
^ (2) 코드 추가 입력 (학습 데이터 불러오기)
장문 텍스트 2줄은 저장 x, id, 단어, 형태소, BIO만 튜플타입으로 가지고 왔다.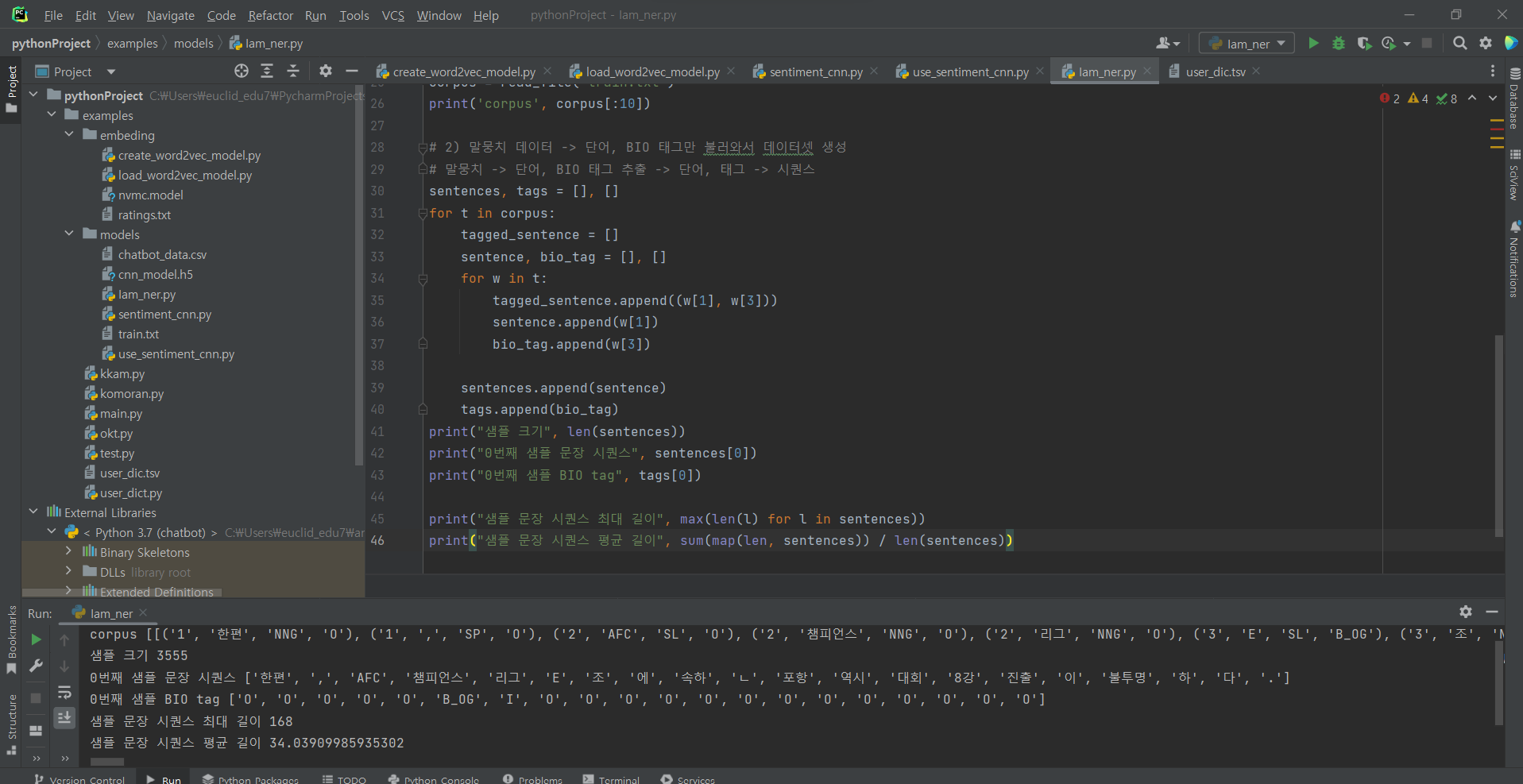
^ (3) 코드 추가 입력 (말뭉치 데이터)
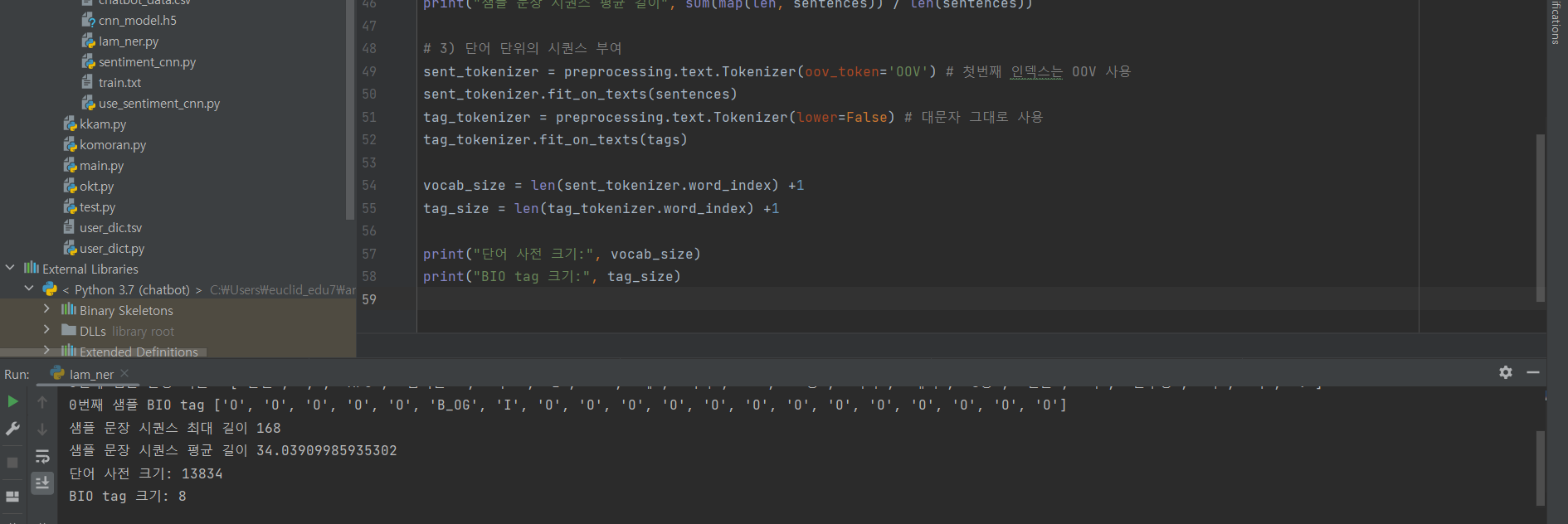
^ (4) 단어 단위의 시퀀스 부여

^ 부가적으로 어떠하게 이루어져 있는지 확인
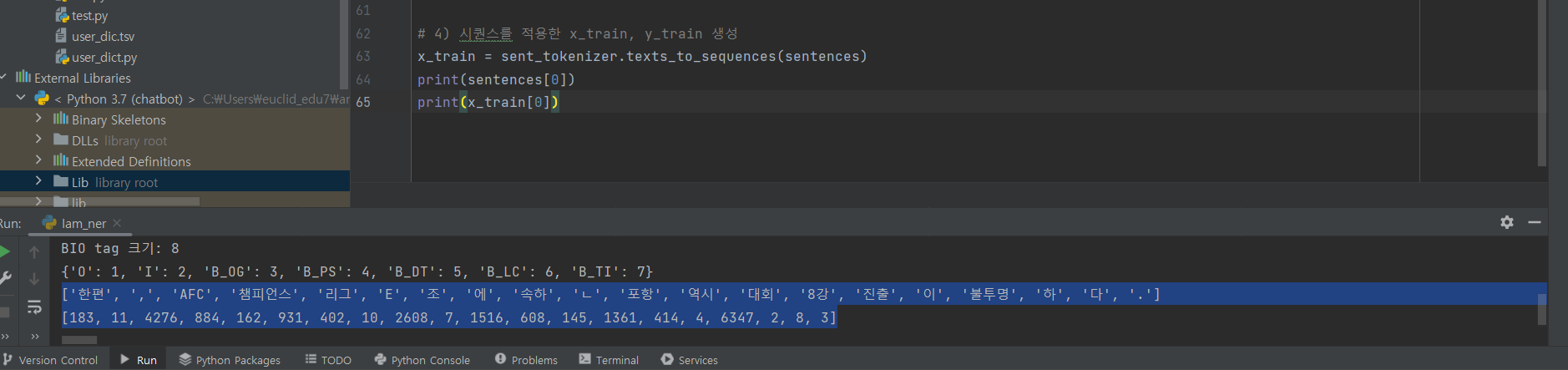
^ (5) 시퀀스를 적용한 x_train, y_train 생성
x_train 확인해보기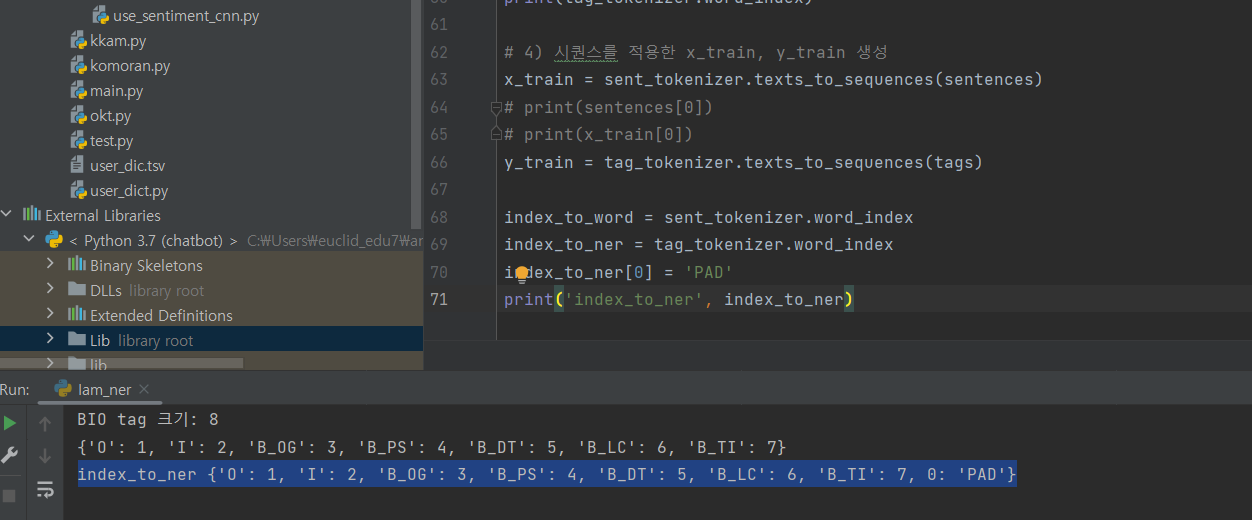
^ (5-1) 시퀀스를 적용한 x_train, y_train 생성
0: PAD
^ (6) 문장 패딩 처리

^ (7) 학습데이터, 테스트 데이터 분리
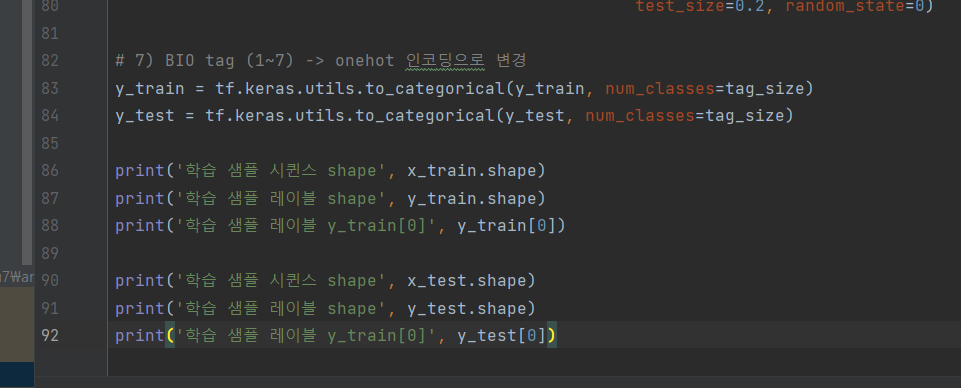
^ (8) BIO tag (1~7) -> onehot 인코딩으로 변경

^ 결과: TRAIN

^ 결과: TEST
Bidirectional LSTM
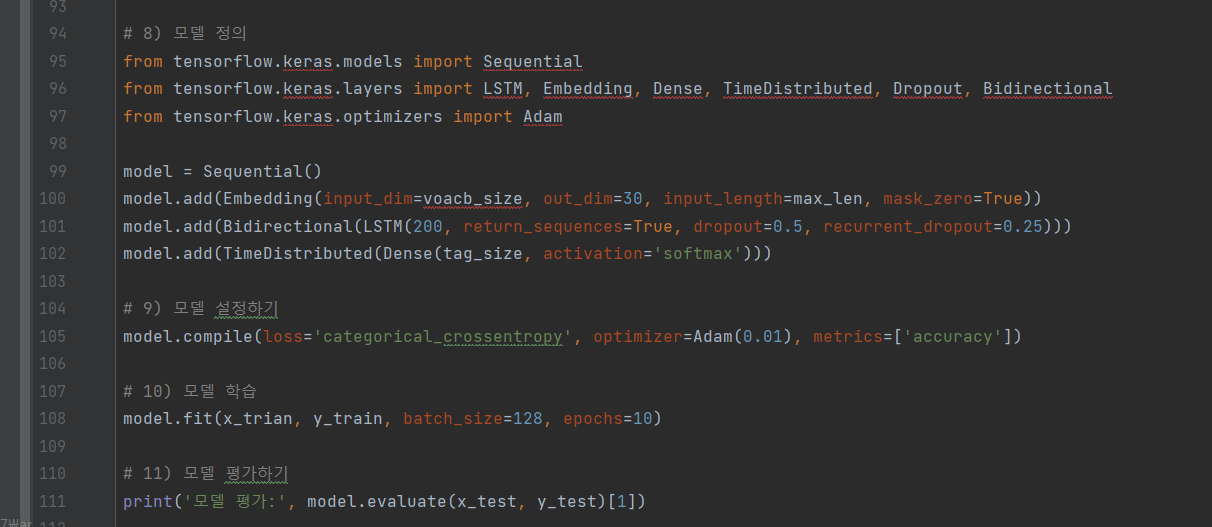
^ (9) 모델 정의 ~ 모델 평가하기
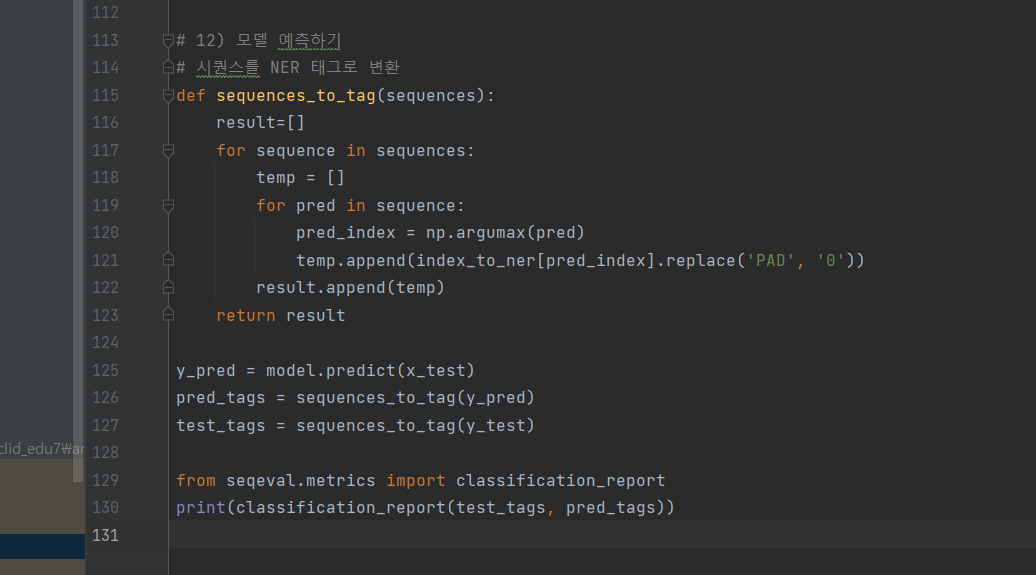
^ (10) 모델 예측하기
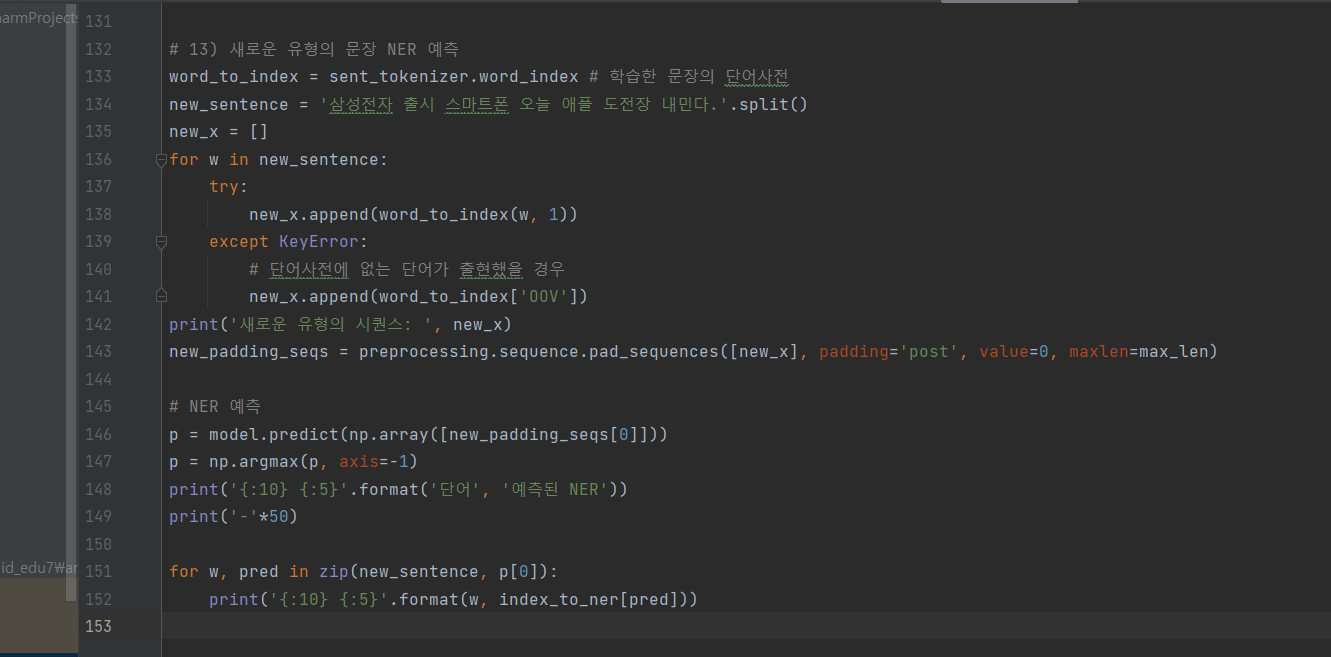
^ (11) 새로운 유형의 문장 NER 예측
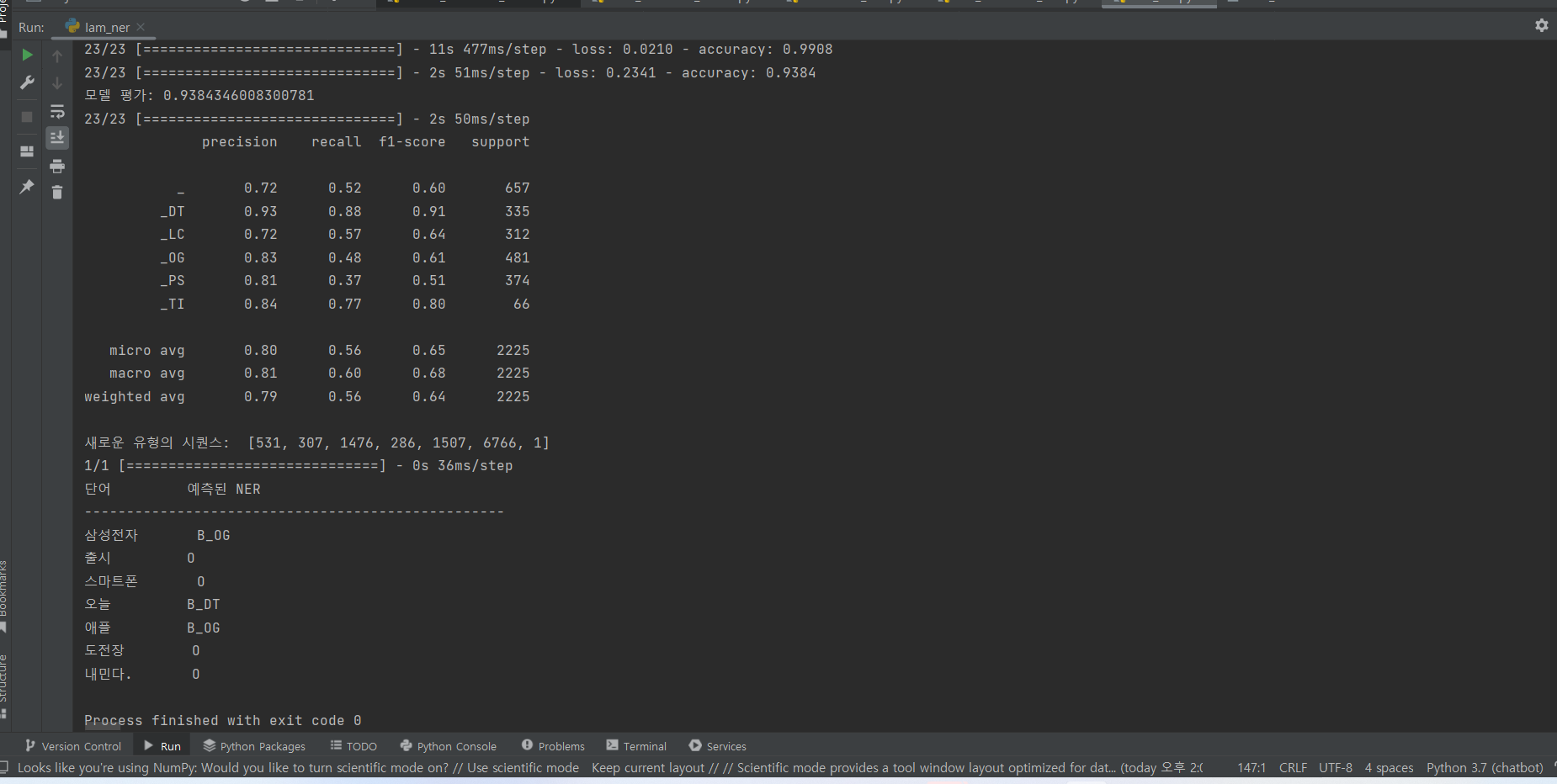
^ 결과
lam_ner.py 전체 코드
# 파일명이 안보여서 대강 씀
import tensorflow as tf
from tensorflow.keras import preprocessing
from sklearn.model_selection import train_test_split
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# file read 할 수 있는 사용자 정의 함수
def read_file(file_name):
sents = []
with open(file_name, 'r', encoding='utf-8') as f:
lines = f.readlines()
for idx, l in enumerate(lines):
if l[0] == ';' and lines[idx + 1][0] == '$':
this_sent = []
elif l[0] == '$' and lines[idx - 1][0] == ';':
continue
elif l[0] == '\n':
sents.append(this_sent)
else:
this_sent.append(tuple(l.split()))
return sents
# 1) 학습 데이터 불러오기 (장문 텍스트 2줄은 저장 x, id, 단어, 형태소, BIO만 튜플타입으로 가지고 왔다.)
corpus = read_file('train.txt')
print('corpus', corpus[:10])
# 2) 말뭉치 데이터 -> 단어, BIO 태그만 불러와서 데이터셋 생성
# 말뭉치 -> 단어, BIO 태그 추출 -> 단어, 태그 -> 시퀀스
sentences, tags = [], []
for t in corpus:
tagged_sentence = []
sentence, bio_tag = [], []
for w in t:
tagged_sentence.append((w[1], w[3]))
sentence.append(w[1])
bio_tag.append(w[3])
sentences.append(sentence)
tags.append(bio_tag)
print("샘플 크기", len(sentences))
print("0번째 샘플 문장 시퀀스", sentences[0])
print("0번째 샘플 BIO tag", tags[0])
print("샘플 문장 시퀀스 최대 길이", max(len(l) for l in sentences))
print("샘플 문장 시퀀스 평균 길이", sum(map(len, sentences)) / len(sentences))
# 3) 단어 단위의 시퀀스 부여
sent_tokenizer = preprocessing.text.Tokenizer(oov_token='OOV') # 첫번째 인덱스는 OOV 사용
sent_tokenizer.fit_on_texts(sentences)
tag_tokenizer = preprocessing.text.Tokenizer(lower=False) # 대문자 그대로 사용
tag_tokenizer.fit_on_texts(tags)
vocab_size = len(sent_tokenizer.word_index) +1
tag_size = len(tag_tokenizer.word_index) +1
print("단어 사전 크기:", vocab_size)
print("BIO tag 크기:", tag_size)
print(tag_tokenizer.word_index)
# 4) 시퀀스를 적용한 x_train, y_train 생성
x_train = sent_tokenizer.texts_to_sequences(sentences)
# print(sentences[0])
# print(x_train[0])
y_train = tag_tokenizer.texts_to_sequences(tags)
# 검증을 위한 단어사전
index_to_word = sent_tokenizer.index_word ###KeyError 난 곳 index 랑 word 를 반대로 입력해서 오류났었던 것임.
index_to_ner = tag_tokenizer.index_word
index_to_ner[0] = 'PAD' # key : value
print('index_to_ner', index_to_ner)
# 5) 문장 패딩 처리
max_len = 40 # 평균 값으로 처리
x_train = preprocessing.sequence.pad_sequences(x_train, padding='post', maxlen=max_len)
y_train = preprocessing.sequence.pad_sequences(y_train, padding='post', maxlen=max_len)
# 6) 학습데이터(80), 테스트 데이터(20) 분리
x_trian, x_test, y_train, y_test = train_test_split(x_train, y_train,
test_size=0.2, random_state=0)
# 7) BIO tag (1~7) -> onehot 인코딩으로 변경
y_train = tf.keras.utils.to_categorical(y_train, num_classes=tag_size)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=tag_size)
print('학습 샘플 시퀸스 shape', x_train.shape)
print('학습 샘플 레이블 shape', y_train.shape)
print('학습 샘플 레이블 y_train[0]', y_train[0])
print('학습 샘플 시퀸스 shape', x_test.shape)
print('학습 샘플 레이블 shape', y_test.shape)
print('학습 샘플 레이블 y_train[0]', y_test[0])
# 8) 모델 정의
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=30, input_length=max_len, mask_zero=True))
model.add(Bidirectional(LSTM(200, return_sequences=True, dropout=0.5, recurrent_dropout=0.25)))
model.add(TimeDistributed(Dense(tag_size, activation='softmax')))
# 9) 모델 설정하기
model.compile(loss='categorical_crossentropy', optimizer=Adam(0.01), metrics=['accuracy'])
# 10) 모델 학습
model.fit(x_trian, y_train, batch_size=128, epochs=10)
# 11) 모델 평가하기
print('모델 평가:', model.evaluate(x_test, y_test)[1])
# 12) 모델 예측하기
# 시퀀스를 NER 태그로 변환
def sequences_to_tag(sequences):
result = []
for sequence in sequences:
temp = []
for pred in sequence:
pred_index = np.argmax(pred)
temp.append(index_to_ner[pred_index].replace("PAD", "O"))
result.append(temp)
return result
y_pred = model.predict(x_test)
pred_tags = sequences_to_tag(y_pred)
test_tags = sequences_to_tag(y_test)
from seqeval.metrics import classification_report
print(classification_report(test_tags, pred_tags))
# 13) 새로운 유형의 문장 NER 예측
word_to_index = sent_tokenizer.word_index # 학습한 문장의 단어사전
new_sentence = '삼성전자 출시 스마트폰 오늘 애플 도전장 내민다.'.split()
new_x = []
for w in new_sentence:
try:
new_x.append(word_to_index.get(w, 1))
except KeyError:
# 단어사전에 없는 단어가 출현했을 경우
new_x.append(word_to_index['OOV'])
print('새로운 유형의 시퀀스: ', new_x)
new_padding_seqs = preprocessing.sequence.pad_sequences([new_x], padding='post', value=0, maxlen=max_len)
# NER 예측
p = model.predict(np.array([new_padding_seqs[0]]))
p = np.argmax(p, axis=-1)
print('{:10} {:5}'.format('단어', '예측된 NER'))
print('-'*50)
for w, pred in zip(new_sentence, p[0]):
print('{:10} {:5}'.format(w, index_to_ner[pred]))
태그 어디갔습니까?!
태그 넣어주세요~