AutoEncoder
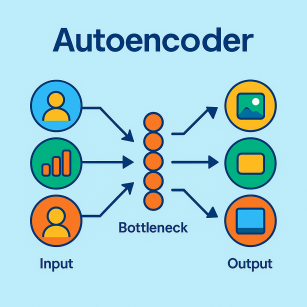
AutoEncoder는 입력 데이터가 들어왔을 때, 해당 데이터를 최대한 압축시킨 후, 데이터의 특징을 추출하여 다시 본래의 입력 형태로 복원시키는 신경망이다.
이때, 데이터를 압축하는 부분을 Encoder, 복원하는 부분을 Decoder라고 한다.
오토인코더가 적합한 상황
- 데이터 압축 도는 차원 축소 필요시
- 노이즈 제거, 이상 탐지, 이미지 복원 등
- 지도 학습 데이터가 부족한 경우
AutoEncoder는 크게 인코더(Encoder)와 디코더(Decoder), 잠재 공간(Latent Space)
인코더는 입력 데이터를 압축하여 잠재 공간에 표현하는 역할을 한다. 이 과정에서 입력 데이터의 중요한 특징만 추출하고, 불필요한 정보를 제거한다. 예를 들어, 고차원 데이터에서 주요 패턴만 학습하는 역할을 합니다.
반대로 디코더는 잠재 공간에서 압축된 표현을 다시 원래 데이터로 복원하는 역할을 한다. 디코더는 인코더가 학습한 특징을 기반으로 데이터의 세부 정보를 복원하며, 입력 데이터와 유사한 출력을 생성하는 데 초점이 맞춰져 있다.
인코더와 디코더의 차이점은 작업의 방향성이다. 인코더는 데이터를 축소하고 특징을 학습하며, 디코더는 축소된 데이터를 기반으로 복원하는 작업을 수행한다. 이 두 과정은 서로 연결되어 입력 데이터와 복원된 데이터 간의 차이를 최소화하는 것을 목표로 한다.
잠재 공간은 입력 데이터의 중요한 특징을 저차원 벡터 형태로 표현한다.
인코더와 디코더 사이의 중간 레이어이다.

개발자