Stramlit, FastAPI와 Triton 기반 추론 서버 통합하기
“Triton은 완전히 분리된 추론 전용 서버 → FastAPI는 게이트웨이/비즈니스 계층 → Streamlit은 UI만”
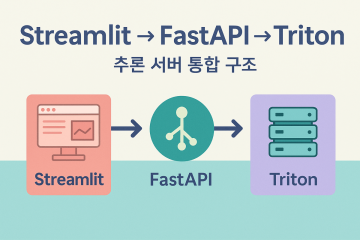
Streamlit ↔ FastAPI(BFF) ↔ Triton Inference Server
UI는 API만 두드리고, API가 Triton을 두드린다.
[User Browser]
|
v (HTTP)
[Streamlit Service] --> 단순 UI/업로드/시각화
|
v (REST/JSON, sometimes WebSocket)
[FastAPI Service] --> 인증, 요청 검증(Pydantic), 전처리, 후처리, 모델선택, 캐싱, 비동기 큐
|
v (HTTP or gRPC)
[Triton Inference Server] --> 모델 로딩, 배칭, GPU 자원 관리
|
v
[Model Repository (S3/NFS/GCS/...)]- Streamlit → FastAPI: POST /infer, GET /models, POST /upload 같은 얇은 호출만.
- FastAPI → Triton: 보통 2가지 방식
• 간단: Triton의 HTTP/REST v2로 바로 호출
• 성능 위주: gRPC로 호출 (멀티모델·배칭을 더 안정적으로)
왜 이렇게 쪼개야 하나?
- Triton은 모델·GPU 자원에만 집중시켜야 안정적인 스루풋/배칭/멀티모델이 살아남. Triton 자체가 모델 리포지토리, 스케줄러, 배칭을 갖고 있으니 다른 애플리케이션 로직이 섞이면 이점이 사라짐.
- FastAPI는 인증/전처리/후처리/멀티모델 라우팅을 넣기 좋음. Triton까지 직접 노출시키면 클라이언트마다 입력 포맷이 제각각이라 관리가 안 됨. FastAPI가 포맷을 Triton 스타일로 정규화해주면 클라이언트는 단순 REST만 쓰면 됨.
- Streamlit은 앱/데모/UI에 최적화돼 있지, 고QPS 추론엔 안 맞음. Streamlit 쪽에 추론 로직을 넣으면 스케일링이 Streamlit 수만큼 늘어버림. UI는 그냥 FastAPI만 호출하는 게 공식적인 모듈화 권장과도 맞음.
| 서비스 | 이미지 예시 | 포트 | 스케일 전략 |
|---|---|---|---|
| Streamlit | myorg/streamlit:latest | 8501 | UI 부하 따라 수평확장 |
| FastAPI | myorg/fastapi:latest | 8000 | 대부분의 요청이 여기 → 오토스케일 |
| Triton | nvcr.io/nvidia/tritonserver:<tag> | 8001(HTTP), 8000(gRPC) | GPU 수/메모리 따라 조정 |
| 모델 스토리지 | S3/GCS/NFS | - | Triton이 읽기 |

개발자