위클리페이퍼 #16
Streamlit로 AI 모델을 웹앱 구축
- 모델 로드 (Model Loading)
• 역할: 학습된 모델과 전처리기를 메모리에 올리고, 재실행 시 재사용해 지연을 줄인다.
• st.cache_resource로 모델(전역 리소스) 캐시 → 여러 세션/리런에서 공유되므로 로드 비용 절감. 모델처럼 변이 가능한 객체는 cache_resource를 쓰고, 순수 계산 결과(데이터프레임 등)는 cache_data를 사용한다.
• 프레임워크별 로드:- scikit-learn: joblib.load("model.pkl")로 복원(버전 불일치 경고 주의).
- PyTorch: 동일 아키텍처 인스턴스 생성 → load_state_dict()로 가중치 로드(가능하면 weights_only=True).
주의점: 캐시된 리소스는 스레드 세이프해야 하며, 변경(변이)이 모든 세션에 퍼질 수 있다. 세션별 격리를 원하면 st.session_state를 활용.
⸻
- 사용자 입력 (User Input)
• 역할: 예측에 필요한 특징값/파일/텍스트를 UI 위젯으로 받는다.
• 탭/사이드바로 입력 영역 정리: st.tabs, st.sidebar
• 수치/선택/텍스트: st.number_input, st.selectbox, st.text_input 등
• 파일 업로드: st.file_uploader(이미지/오디오/CSV 등). 업로드된 바이트는 RAM(메모리) 상의 버퍼로 보관되므로, 재실행 간 보존이 필요하면 캐시/세션 상태로 관리.
• 폼 제출: 여러 입력을 모아 한 번에 처리하려면 st.form/form_submit_button 패턴을 사용.
• 상태 관리: 리런 간 값 유지/워크플로 제어는 st.session_state.
⸻
- 결과 출력 (Results & Feedback)
• 역할: 예측값, 확률, 시각화, 로그를 사용자에게 명확히 보여줍니다.
• 기본 출력: st.write, st.metric, st.table/st.dataframe
• 이미지/차트: st.image, st.pyplot
• 진행 상태: st.spinner(로딩 표시)
• 성능 팁: 반복되는 전처리/특징 생성은 st.cache_data로 메모이제이션하여 응답시간을 줄인다(순수 함수에 적합). 모델 그 자체는 st.cache_resource.
출처
streamlit_docs
streamlit_docs
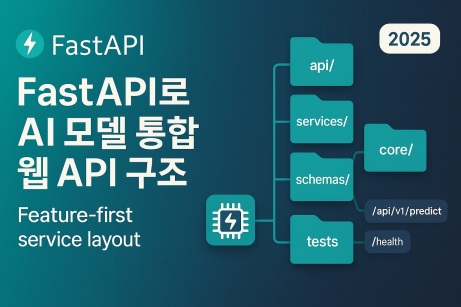
FastAPI 구조 설계
레이어 + 기능 혼합형 구조: api/(라우터)·services/(비즈/모델)·schemas/(입출력 모델)·core/(설정/라이프사이클)·tests/.
디렉터리 구조
app/
main.py
core/
config.py
lifespan.py
api/
deps.py
v1/
router.py
endpoints/
health.py
predict.py
services/
model_service.py
schemas/
prediction.py
tests/
test_predict.py
.env.example
requirements.txt (또는 pyproject.toml)
Dockerfile전체 아키텍처 작성
- 프론트: Streamlit 대시보드(업로드/상태표시/WebSocket 실시간 캡션)
- 백엔드: FastAPI(REST+WebSocket), JWT 인증, CORS, Rate limit
- 추론 워커: Celery(+Redis/RabbitMQ) 비동기 큐 소비, ONNX Runtime/TensorRT 최적화
- 스토리지/DB: 오브젝트 스토리지(S3/GCS), 메타데이터(Postgres)
- 배포: 단일 서버(Compose) → 확장 시 K8s(+KEDA)로 큐 길이에 따라 워커 오토스케일
- 관측성: Prometheus(+Grafana) 메트릭, OpenTelemetry 트레이싱, 구조화 로깅

개발자