2022.07.18 연구실 공부(PyTorch). 'PyTorch로 시작하는 딥 러닝 입문'< 이 글은 이 책의 내용을 요약 정리한 것임.>(내 저작물이 아니고 저 위 링크에 있는 것이 원본임)
10 순환 신경망(Recurrent Neural Network, RNN)
Summary
- Recurrent Neural Network(RNN)
- Long Short-Term Memory(LSTM)
1. Recurrent Neural Network(RNN)
1-1. Sequence
- 이 부분은 '우노'님 블로그의 내용입니다.
- Sequence model : 연속적인 입력(Sequential Input)으로부터 연속적인 출력(Sequential Output)을 생성하는 모델
- Sequence Datas
- Speech recognition(Many-to-Many, len(Input)=len(Output))
- Music generation(One-to-Many)
- Sentiment Classification(Many-to-One)
- DNA sequence analysis(Many-to-Many, len(Input)=len(Output))
- Machine translation(Many-to-Many, len(Input)!=len(Output))
- Video activity recognition(Many-to-One)
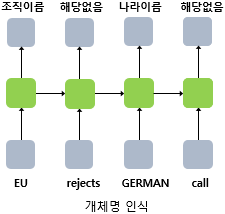
- Name entity recognition(Many-to-Many, len(Input)=len(Output))

- Input과 Output이 모두 Sequence Data이거나 하나만 Sequence Data일 수 있다.
- 모두 Sequence Data인 경우, Input과 Output의 길이가 같을 수도(len(Input)=len(Output)), 다를 수도(len(Input)!=len(Output)) 있다.
1-2. Recurrent Neural Network, RNN
- Feed Forward Neural Network : 전부 은닉층에서 활성화 함수를 지난 값이 오직 출력층 방향으로만 향하는 신경망
- RNN(Recurrent Neural Network) : Feed Forward가 아님, 은닉층(Hidden Layer)의 노드에서 활성화 함수를 통해 나온 결과값을 출력층(Output Layer) 방향으로도 보내면서 다시 은닉층(Hidden Layer) 노드의 다음 계산의 입력으로 보내는 특징

- x : 입력층의 입력 벡터, y : 출력층의 출력 벡터
- 셀(Cell, Memory Cell, RNN Cell) : RNN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드 => 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동
- 은닉 상태(hidden state) : 메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값
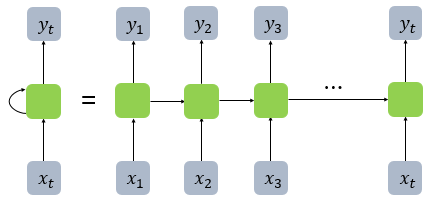
- 좌측과 우측 모두 동일한 RNN을 표현
- Neuron in Feed Forward NN == Input vector, Output vector, Hidden state in RNN
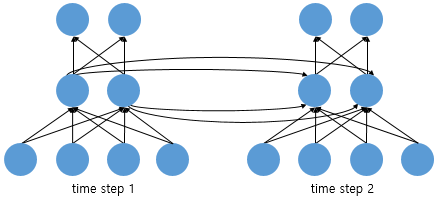
- 위 그림의 경우, Input vector=4(dimension), Output vector=2(dimension), Hidden state=2(size)
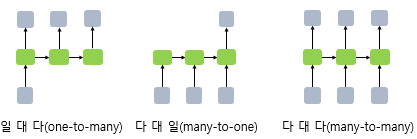
- Many-to-Many
- One-to-Many
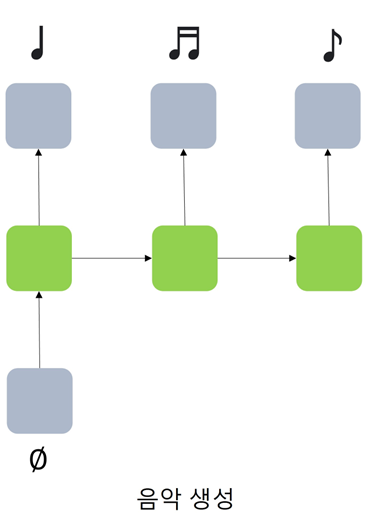
- Many-to-One
- RNN 수식
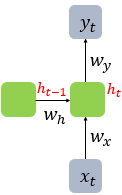
- h_t : t시점에서의 Hidden state, memory cell : w_h(이전 시점 t-1의 Hidden state인 h_t-1을 위한 가중치), w_x(입력층에서 입력값을 위한 가중치) for h_t
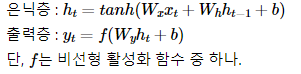
- 은닉층 연산(각 벡터와 행렬의 크기)
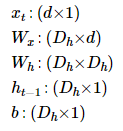
- x_t : RNN의 입력(NLP에서는 주로 Word vector), d : word vector의 dimension, D_h : hidden state size
- 배치 크기가 1이고, 와 두 값 모두를 4로 가정한 경우

- h_t를 계산하기 위한 활성화 함수로는 주로 하이퍼볼릭탄젠트 함수(tanh)가 사용되지만, ReLU로 바꿔 사용하는 시도도 있음
- 위 식에서 W_x, W_h의 값은 모든 시점에서 동일하게 공유, Hidden Layer가 2개 이상일 경우 Hidden Layer 2개의 가중치는 서로 다름
- Output Layer의 경우 결과값인 y_t를 계산하기 위한 활성화 함수로 이진 분류에는 Sigmoid를, multi-class에서는 Softmax를 사용
1-3. 파이썬으로 RNN 구현
- 계산 식
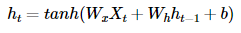
1-3-1. Numpy로 직접 RNN 구현
import numpy as np
timesteps = 10 # 시점의 수. NLP에서는 보통 문장의 길이가 된다.
input_size = 4 # 입력의 차원. NLP에서는 보통 단어 벡터의 차원이 된다.
hidden_size = 8 # 은닉 상태의 크기. 메모리 셀의 용량이다.
inputs = np.random.random((timesteps, input_size)) # 입력에 해당되는 2D 텐서
hidden_state_t = np.zeros((hidden_size,)) # 초기 은닉 상태는 0(벡터)로 초기화
# 은닉 상태의 크기 hidden_size로 은닉 상태를 만듬.
print(hidden_state_t) # 8의 크기를 가지는 은닉 상태. 현재는 초기 은닉 상태로 모든 차원이 0의 값을 가짐.[0. 0. 0. 0. 0. 0. 0. 0.]- 가중치와 편향을 정의
Wx = np.random.random((hidden_size, input_size)) # (8, 4)크기의 2D 텐서 생성. 입력에 대한 가중치.
Wh = np.random.random((hidden_size, hidden_size)) # (8, 8)크기의 2D 텐서 생성. 은닉 상태에 대한 가중치.
b = np.random.random((hidden_size,)) # (8,)크기의 1D 텐서 생성. 이 값은 편향(bias).
# 크기 확인
print(np.shape(Wx))
print(np.shape(Wh))
print(np.shape(b))(8, 4)
(8, 8)
(8,)- W_x는 (은닉 상태의 크기 × 입력의 차원), W_h는 (은닉 상태의 크기 × 은닉 상태의 크기), b는 (은닉 상태의 크기)의 크기
- RNN 층
total_hidden_states = []
# 메모리 셀 동작
for input_t in inputs: # 각 시점에 따라서 입력값이 입력됨.
output_t = np.tanh(np.dot(Wx,input_t) + np.dot(Wh,hidden_state_t) + b) # Wx * Xt + Wh * Ht-1 + b(bias)
total_hidden_states.append(list(output_t)) # 각 시점의 은닉 상태의 값을 계속해서 축적
print(np.shape(total_hidden_states)) # 각 시점 t별 메모리 셀의 출력의 크기는 (timestep, output_dim)
hidden_state_t = output_t
total_hidden_states = np.stack(total_hidden_states, axis = 0)
# 출력 시 값을 깔끔하게 해준다.
print(total_hidden_states) # (timesteps, output_dim)의 크기. 이 경우 (10, 8)의 크기를 가지는 메모리 셀의 2D 텐서를 출력.(1, 8)
(2, 8)
(3, 8)
(4, 8)
(5, 8)
(6, 8)
(7, 8)
(8, 8)
(9, 8)
(10, 8)
[[0.85575076 0.71627213 0.87703694 0.83938496 0.81045543 0.86482715 0.76387233 0.60007514]
[0.99982366 0.99985897 0.99928638 0.99989791 0.99998252 0.99977656 0.99997677 0.9998397 ]
[0.99997583 0.99996057 0.99972541 0.99997993 0.99998684 0.99954936 0.99997638 0.99993143]
[0.99997782 0.99996494 0.99966651 0.99997989 0.99999115 0.99980087 0.99999107 0.9999622 ]
[0.99997231 0.99996091 0.99976218 0.99998483 0.9999955 0.99989239 0.99999339 0.99997324]
[0.99997082 0.99998754 0.99962158 0.99996278 0.99999331 0.99978731 0.99998831 0.99993414]
[0.99997427 0.99998367 0.99978331 0.99998173 0.99999579 0.99983689 0.99999058 0.99995531]
[0.99992591 0.99996115 0.99941212 0.99991593 0.999986 0.99966571 0.99995842 0.99987795]
[0.99997139 0.99997192 0.99960794 0.99996751 0.99998795 0.9996674 0.99998177 0.99993016]
[0.99997659 0.99998915 0.99985392 0.99998726 0.99999773 0.99988295 0.99999316 0.99996326]]1-3-2. PyTorch의 nn.RNN()
- 필요한 도구 임포트
import torch
import torch.nn as nn- 입력의 크기와 은닉 상태의 크기를 정의
input_size = 5 # 입력의 크기
hidden_size = 8 # 은닉 상태의 크기- 입력 텐서를 정의(배치 크기 × 시점의 수 × 매 시점마다 들어가는 입력)
# (batch_size, time_steps, input_size)
inputs = torch.Tensor(1, 10, 5)- nn.RNN()을 사용하여 RNN의 셀 만들기(인자로 입력의 크기와 은닉 상태의 크기를 정의, batch_first=True를 통해서 입력 텐서의 첫번째 차원이 배치 크기)
cell = nn.RNN(input_size, hidden_size, batch_first=True)- 입력 텐서를 RNN 셀에 입력하여 출력을 확인
outputs, _status = cell(inputs)- 첫번째 리턴값에 대해서 크기를 확인
print(outputs.shape) # 모든 time-step의 hidden_statetorch.Size([1, 10, 8])- 두번째 리턴값에 대해서 은닉 상태의 크기를 확인
print(_status.shape) # 최종 time-step의 hidden_statetorch.Size([1, 1, 8])1-3-3. 깊은 순환 신경망(Deep Recurrent Neural Network)
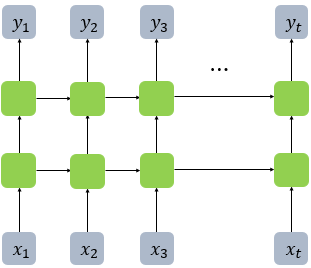
- RNN도 다수의 은닉층을 가질 수 있다 -> 은닉층이 1개 더 추가 -> 은닉층이 2개인 깊은(deep) 순환 신경망의 모습
- nn.RNN()의 인자인 num_layers에 값을 전달하여 층 쌓음
# (batch_size, time_steps, input_size)
inputs = torch.Tensor(1, 10, 5)
cell = nn.RNN(input_size = 5, hidden_size = 8, num_layers = 2, batch_first=True)
print(outputs.shape) # 모든 time-step의 hidden_statetorch.Size([1, 10, 8])print(_status.shape) # (층의 개수, 배치 크기, 은닉 상태의 크기)torch.Size([2, 1, 8])1-4. Bidirectional Recurrent Neural Network
- 시점 t에서의 출력값을 예측할 때 이전 시점의 데이터뿐만 아니라, 이후 데이터로도 예측할 수 있다는 아이디어에 기반
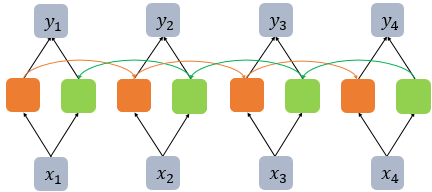
- 첫번째 메모리 셀(주황색 메모리 셀)은 앞 시점의 은닉 상태(Forward States)를 전달 -> 현재의 은닉 상태를 계산
- 두번째 메모리 셀(초록색 메모리 셀)은 앞 시점의 은닉 상태가 아니라 뒤 시점의 은닉 상태(Backward States)를 전달 받아 현재의 은닉 상태를 계산
- 다수의 은닉층을 가진 양방향 RNN
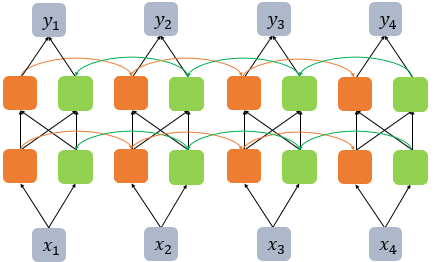
- 단, 은닉층을 추가하면 학습할 수 있는 양이 많아지지만 또한 반대로 훈련 데이터 또한 그만큼 많이 필요하므로 무조건 추가하는 것은 좋지 않음
- PyTorch로 구현할 때는 nn.RNN()의 인자인 bidirectional에 값을 True로 전달
# (batch_size, time_steps, input_size)
inputs = torch.Tensor(1, 10, 5)
cell = nn.RNN(input_size = 5, hidden_size = 8, num_layers = 2, batch_first=True, bidirectional = True)
outputs, _status = cell(inputs)
print(outputs.shape) # (배치 크기, 시퀀스 길이, 은닉 상태의 크기 x 2)torch.Size([1, 10, 16])- 첫번째 리턴값의 크기는 단뱡 RNN 셀 때보다 은닉 상태의 크기의 값이 두 배 -> (배치 크기, 시퀀스 길이, 은닉 상태의 크기 x 2)의 크기 -> 양방향의 은닉 상태 값들이 연결(concatenate)되었기 때문
print(_status.shape) # (층의 개수 x 2, 배치 크기, 은닉 상태의 크기)torch.Size([4, 1, 8])2. Long Short-Term Memory(LSTM)
2-1. 바닐라 RNN의 한계
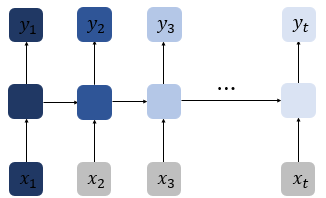
- 바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존 -> 바닐라 RNN은 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점 존재 -> 바닐라 RNN의 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생
- 위 그림에서 짙은 남색(정보량 많음)이 점점 옅어짐(정보량 적음) -> 장기 의존성 문제(the problem of Long-Term Dependencies)
2-2. 바닐라 RNN 내부

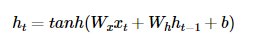
- 바닐라 RNN은 x_t와 h_t-1이라는 두 개의 입력이 각각의 가중치와 곱해져서 메모리 셀의 입력이 됨 -> 하이퍼볼릭탄젠트 함수의 입력으로 사용 -> 은닉층의 출력인 은닉 상태
2-3. LSTM(Long Short-Term Memory)
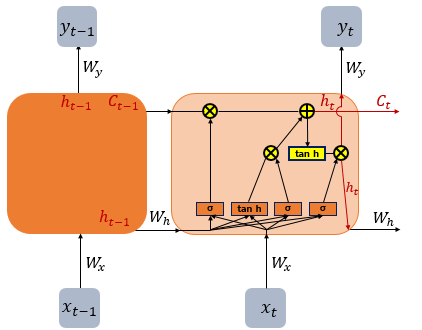
- 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가 -> 불필요한 기억 삭제
- 셀 상태(cell state, C_t)라는 값을 추가
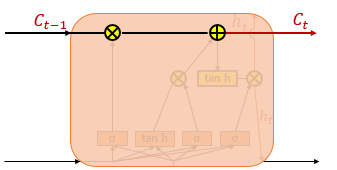

- (1) 입력 게이트
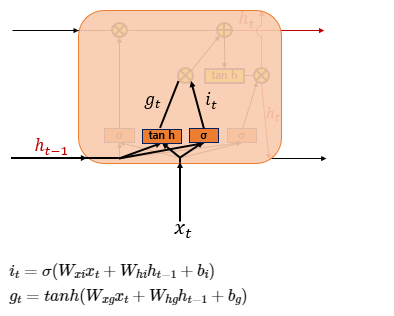
- 입력 게이트 : 현재 정보를 기억하기 위한 게이트
- 현재 시점 t의 값과 입력 게이트로 이어지는 가중치 W_xi를 곱한 값과 이전 시점 t-1의 은닉 상태가 입력 게이트로 이어지는 가중치 W_hi를 곱한 값을 더하여 시그모이드 함수를 지남 = i_t(0 ~ 1)
- 현재 시점 t의 값과 입력 게이트로 이어지는 가중치 W_xi를 곱한 값과 이전 시점 t-1의 은닉 상태가 입력 게이트로 이어지는 가중치 W_hg를 곱한 값을 더하여 하이퍼볼릭탄젠트 함수를 지남 = g_t(-1 ~ 1)
- i_t, g_t로 선택된 기억할 정보의 양을 결정
- (2) 삭제 게이트
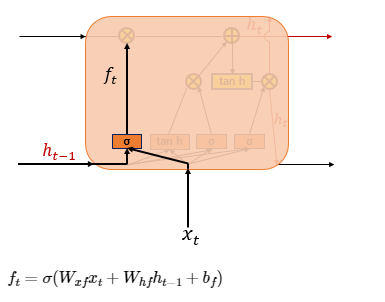
- 삭제 게이트 : 기억을 삭제하기 위한 게이트
- 현재 시점 t의 값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지나게 됨(0 ~ 1) = 삭제 과정을 거친 정보의 양
- 0에 가까울수록 정보가 많이 삭제, 1에 가까울수록 정보를 온전히 기억 -> 이를 통해 셀 상태 구함
- (3) 셀 상태(장기 상태)
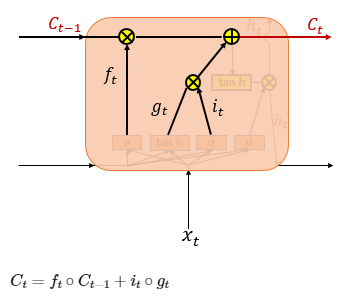
- 셀 상태 C_t = LSTM의 장기 상태
- 입력 게이트의 i_t, g_t에 대해 원소별 곱(entrywise product, 같은 크기의 두 행렬이 있을 때 같은 위치의 성분끼리 곱하는 것) -> 입력 게이트에서 선택된 기억을 삭제 게이트의 결과값과 더함 -> 현재 시점 t의 셀 상태 -> 다음 t+1 시점의 LSTM 셀로 전달
- 삭제 게이트의 출력(f_t)가 0 -> 이전 시점의 셀 상태값인 C_t는 현재 시점의 셀 상태값을 결정하기 위한 영향력이 0 -> 입력 게이트의 결과만이 현재 시점의 셀 상태값 C_t를 결정 -> 삭제 게이트가 완전히 닫히고 입력 게이트를 연 상태
- 입력 게이트의 i_t값이 0 -> 현재 시점의 셀 상태값 C_t는 오직 이전 시점의 셀 상태값 C_t-1의 값에만 의존 -> 입력 게이트를 완전히 닫고 삭제 게이트만을 연 상태
- 결국 삭제 게이트는 이전 시점의 입력을 얼마나 반영할지를 의미하고, 입력 게이트는 현재 시점의 입력을 얼마나 반영할지를 결정
- (4) 출력 게이트와 은닉 상태(단기 상태)
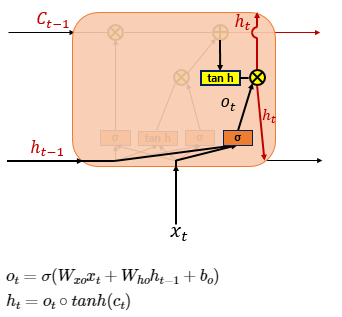
- 은닉 상태 = 단기 상태 : 장기 상태의 값이 하이퍼볼릭탄젠트 함수를 지난 값(-1 ~ 1)
- 출력 게이트 : 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값 -> 현재 시점 t의 은닉 상태를 결정하는 일에 사용 -> 출력 게이트의 값과 연산되면서, 값이 걸러지는 효과가 발생
- 단기 상태의 값은 또한 출력층으로도 향함
2-4. PyTorch의 nn.LSTM()
nn.LSTM(input_dim, hidden_size, batch_fisrt=True) - nn.RNN() 사용법과 유사함
출처 : 'PyTorch로 시작하는 딥 러닝 입문' <이 책의 내용을 요약 정리한 것임.>

매일 매일 새로워지는 나 자신을 꿈꾸며