2022.07.14 연구실 공부(PyTorch). 'PyTorch로 시작하는 딥 러닝 입문'< 이 글은 이 책의 내용을 요약 정리한 것임.>(내 저작물이 아니고 저 위 링크에 있는 것이 원본임)
08 자연어 처리의 전처리
Summary
- Tokenization
- Generating Vocabulary
- Torchtext Basic
1. Tokenization
1-1. Tokenization in English
- spaCy 사용
!pip install spacy
!python -m spacy download enen_text = "A Dog Run back corner near spare bedrooms"
import spacy
spacy_en = spacy.load('en_core_web_sm')
def tokenize(en_text):
return [tok.text for tok in spacy_en.tokenizer(en_text)]
print(tokenize(en_text))['A', 'Dog', 'Run', 'back', 'corner', 'near', 'spare', 'bedrooms']- NLTK 사용
!pip install nltkimport nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
print(word_tokenize(en_text))['A', 'Dog', 'Run', 'back', 'corner', 'near', 'spare', 'bedrooms']- 띄어쓰기로 토큰화
print(en_text.split())['A', 'Dog', 'Run', 'back', 'corner', 'near', 'spare', 'bedrooms']1-2. Tokenization in Korean
kor_text = "사과의 놀라운 효능이라는 글을 봤어. 그래서 오늘 사과를 먹으려고 했는데 사과가 썩어서 슈퍼에 가서 사과랑 오렌지 사왔어"
print(kor_text.split())['사과의', '놀라운', '효능이라는', '글을', '봤어.', '그래서', '오늘', '사과를', '먹으려고', '했는데', '사과가', '썩어서', '슈퍼에', '가서', '사과랑', '오렌지', '사왔어']- 한국어의 띄어쓰기 모두 '의', '를', '가', '랑' 등이 붙어있어 이를 제거해주지 않으면 기계는 전부 다른 단어로 인식
- 한국어는 형태소로 분석하는 것이 단순히 글자 단위로 분해하는 것보다 더 적합
- 책에서는 'Mecab'을 사용하지만 파이썬 3.8까지만 사용가능하고 윈도우에서는 설치가 어려움 -> Okt를 사용
!pip install --upgrade pip
!pip install JPype1-0.5.7-cp27-none-win_amd64.whl
!pip install konlpyfrom konlpy.tag import Okt
tokenizer = Okt()
# 한국어 형태소로 나눈 경우 1
print(tokenizer.morphs(kor_text))['사과', '의', '놀라운', '효능', '이', '라는', '글', '을', '봤', '어', '.', '그래서', '오늘', '사과', '를', '먹', '으려고', '했', '는데', '사과', '가', '썩', '어서', '슈퍼', '에', '가', '서', '사과', '랑', '오렌지', '사', '왔', '어']# 한국어 형태소로 나눈 경우 2
print(tokenizer.morphs(u'단독입찰보다 복수입찰의 경우'))['단독', '입찰', '보다', '복수', '입찰', '의', '경우']- 한국어 명사로 나눈 경우
# 한국어 명사로 나눈 경우
print(tokenizer.nouns(u'유일하게 항공기 체계 종합개발 경험을 갖고 있는 KAI는'))['항공기', '체계', '종합', '개발', '경험']- 한국어 구문으로 나눈 경우
# 한국어 구문으로 나눈 경우
print(tokenizer.phrases(u'날카로운 분석과 신뢰감 있는 진행으로'))['날카로운 분석', '날카로운 분석과 신뢰감', '날카로운 분석과 신뢰감 있는 진행', '분석', '신뢰', '진행']- 품사 태깅
# 한국어 품사 태깅의 경우
print(tokenizer.pos(u'이것도 되나욬ㅋㅋ'))[('이', 'Determiner'), ('것', 'Noun'), ('도', 'Josa'), ('되나욬', 'Noun'), ('ㅋㅋ
', 'KoreanParticle')]- 정규화
# normalize tokens=True 정규화(되나욬 -> 되나요)
print(tokenizer.pos(u'이것도 되나욬ㅋㅋ', norm=True))[('이', 'Determiner'), ('것', 'Noun'), ('도', 'Josa'), ('되나요', 'Verb'), ('ㅋㅋ
', 'KoreanParticle')]- 어간 추출
# stem tokens=True 어간 추출(되나요 -> 되다)
print(tokenizer.pos(u'이것도 되나욬ㅋㅋ', norm=True, stem=True))[('이', 'Determiner'), ('것', 'Noun'), ('도', 'Josa'), ('되다', 'Verb'), ('ㅋㅋ', 'KoreanParticle')]1-3. Tokenization by Character
# English character tokenization
en_text = "A Dog Run back corner near spare bedrooms"
print(list(en_text))
# 한국어 문자 토큰화
kor_text = "사과의 놀라운 효능이라는 글을 봤어. 그래서 오늘 사과를 먹으려고 했는데 사과가 썩어서 슈퍼에 가서 사과랑 오렌지 사왔어"
print(list(kor_text))2. Generating Vocabulary
- 단어 집합(vocabuary)이란 중복을 제거한 텍스트의 총 단어의 집합(set)을 의미
import urllib.request
import pandas as pd
from konlpy.tag import Okt
from nltk import FreqDist
import numpy as np
import matplotlib.pyplot as plt
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
data = pd.read_table('ratings.txt') # 데이터프레임에 저장
print(data[:10])- 샘플 수 확인 후 데이터 정제
print('전체 샘플의 수 : {}'.format(len(data)))
sample_data = data[:100] # 임의로 100개만 저장
sample_data['document'] = sample_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
# 한글과 공백을 제외하고 모두 제거
print(sample_data[:10])- 불용어 제거를 위한 불용어 정의
# 불용어 정의
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']- 형태소 분석기는 Okt 사용
tokenizer = Okt()
tokenized=[]
for sentence in sample_data['document']:
temp = tokenizer.morphs(sentence) # 토큰화
temp = [word for word in temp if not word in stopwords] # 불용어 제거
tokenized.append(temp)
print(tokenized[:10])[['어릴', '때', '보고', '지금', '다시', '봐도', '재밌어요', 'ㅋㅋ'], ['디자인', '을', '배우는', '학생', '외국', '디자이너', '그', '일군', '전통', '을', '통해', '발전', '해가는', '문화', '산업', '부러웠는데', '사실', '
우리나라', '에서도', '그', '어려운', '시절', '끝', '까지', '열정', '을', '지킨', '노라노', '같은', '전통', '있어', '저', '같은', '사람', '꿈', '을', '꾸고', '이뤄', '나갈', '수', '있다는', '것', '감사합니다'], ['폴리스
스토리', '시리즈', '부터', '뉴', '까지', '버릴께', '하나', '없음', '최고'], ['연기', '진짜', '개', '쩔구나', '지루할거라고', '생각', '했는데', '몰입', '해서', '봤다', '그래', '이런게', '진짜', '영화', '지'], ['안개', '자욱한', '밤하늘', '떠', '있는', '초승달', '같은', '영화'], ['사랑', '을', '해본', '사람', '라면', '처음', '부터', '끝', '까지', '웃을수', '있는', '영화'], ['완전', '감동', '입니다', '다시', '봐도', '감동'], ['개', '전
쟁', '나오나요', '나오면', '빠', '로', '보고', '싶음'], ['굿'], ['바보', '아니라', '병', '쉰', '인듯']]- 빈도 계산
vocab = FreqDist(np.hstack(tokenized))
print('단어 집합의 크기 : {}'.format(len(vocab)))단어 집합의 크기 : 761- 단어는 키(Key), 단어에 대한 빈도수는 값(Value)으로 저장 -> '진짜'라는 단어는 7번 등장
print(vocab['진짜'])7- 등장 빈도수 상위 500개의 단어만 단어 집합으로 저장
vocab_size = 500
# 상위 vocab_size개의 단어만 보존
vocab = vocab.most_common(vocab_size)
print('단어 집합의 크기 : {}'.format(len(vocab)))- 각 단어에 고유한 정수 부여(인덱스 0과 1은 다른 용도 -> 0은 pad, 1은 unk)
word_to_index = {word[0] : index + 2 for index, word in enumerate(vocab)}
word_to_index['pad'] = 1
word_to_index['unk'] = 0encoded = []
for line in tokenized: #입력 데이터에서 1줄씩 문장을 읽음
temp = []
for w in line: #각 줄에서 1개씩 글자를 읽음
try:
temp.append(word_to_index[w]) # 글자를 해당되는 정수로 변환
except KeyError: # 단어 집합에 없는 단어일 경우 unk로 대체된다.
temp.append(word_to_index['unk']) # unk의 인덱스로 변환
encoded.append(temp)
print(encoded[:10])[[44, 9, 36, 24, 25, 45, 149, 26], [150, 3, 151, 152, 153, 154, 10, 155, 75, 3, 156, 157, 158, 76, 159, 160, 37, 77, 78, 10, 161, 162, 79, 16, 163, 3, 164, 165, 27, 75, 166, 28, 27, 17, 167, 3, 168, 169, 170, 18, 171,
46, 172], [173, 174, 29, 175, 16, 176, 80, 81, 4], [19, 11, 82, 177, 178, 12, 47, 179, 83, 84, 180, 181, 11, 2, 85], [182, 183, 184, 185, 86, 186, 27, 2], [87, 3, 187, 17, 88, 89, 29, 79, 16, 188, 86, 2], [90, 13, 189, 25, 45, 13], [82, 190, 191, 192, 193, 20, 36, 194], [91], [195, 196, 197, 198, 199]]- 길이가 다른 문장들을 모두 동일한 길이로 바꿔주는 패딩(padding)
max_len = max(len(l) for l in encoded)
print('리뷰의 최대 길이 : %d' % max_len)
print('리뷰의 최소 길이 : %d' % min(len(l) for l in encoded))
print('리뷰의 평균 길이 : %f' % (sum(map(len, encoded))/len(encoded)))
plt.hist([len(s) for s in encoded], bins=50)
plt.xlabel('length of sample')
plt.ylabel('number of sample')
plt.show()리뷰의 최대 길이 : 48
리뷰의 최소 길이 : 1
리뷰의 평균 길이 : 11.350000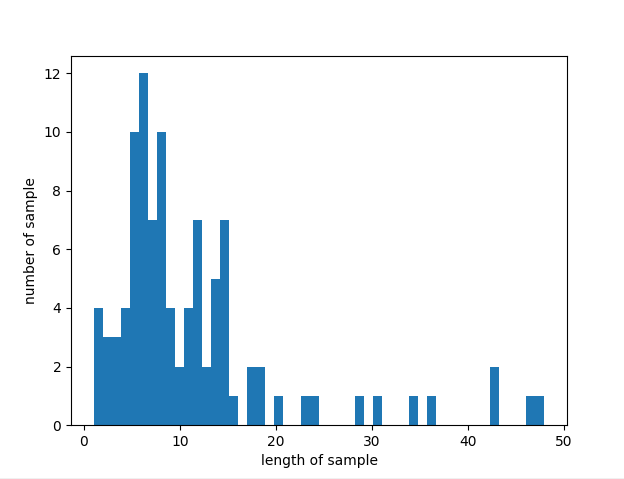
- 가장 길이가 긴 리뷰는 48이므로 모든 리뷰 길이를 48로 통일
for line in encoded:
if len(line) < max_len: # 현재 샘플이 정해준 길이보다 짧으면
line += [word_to_index['pad']] * (max_len - len(line)) # 나머지는 전부 'pad' 토큰으로 채운다.
print('리뷰의 최대 길이 : %d' % max(len(l) for l in encoded))
print('리뷰의 최소 길이 : %d' % min(len(l) for l in encoded))
print('리뷰의 평균 길이 : %f' % (sum(map(len, encoded))/len(encoded)))- 상위 3개의 샘플들만 출력해보기
print(encoded[:3])3. Torchtext Basic
3-1. Set up
- 현재 최신버전은 0.13.0인데 이 버전으로는 기존 코드가 상당부분 호환이 안됨(특히, Field 생성에 관한 부분이 거의 안 통하는 듯?)
- 따라서 여기서는 책의 코드를 최대한 잘 따라해보기 위해 0.6.0버전으로 Torchtext를 설치하였음
pip install -U torchtext==0.6.0- Torchtext 등 필요한 라이브러리 임포트
import torch
import torchtext as torchtext
from torchtext import data
from torchtext import datasets
from torchtext.data import TabularDataset
from torchtext.data import Iterator
import urllib.request
import pandas as pd3-2. 훈련 데이터와 테스트 데이터로 분리하기
- IMDB 리뷰 데이터를 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/LawrenceDuan/IMDb-Review-Analysis/master/IMDb_Reviews.csv", filename="IMDb_Reviews.csv")- 다운로드한 IMDB 리뷰 데이터를 데이터프레임에 저장, 상위 5개의 행만 출력
df = pd.read_csv('IMDb_Reviews.csv', encoding='latin1')
df.head()- 첫 번째 열은 review로, 두 번째 열은 sentiment로 긍정(1)인지 부정(0)인지 나타냄

- 전체 샘플의 개수
print('전체 샘플의 개수 : {}'.format(len(df)))전체 샘플의 개수 : 50000- 전체 샘플의 개수는 50,000개 -> 25,000개씩 분리하여 훈련 데이터와 테스트 데이터로 분리
train_df = df[:25000]
test_df = df[25000:]- 이 둘을 각각 훈련 데이터는 train_data.csv 파일에 테스트 데이터는 test_data.csv 파일에 저장(index=False를 하면 인덱스를 저장)
train_df.to_csv("train_data.csv", index=False)
test_df.to_csv("test_data.csv", index=False)3-3. 필드 정의
- 필드(torchtext.data의 Field)를 통해 앞으로 어떤 전처리를 할 것인지 정의
- 하나는 실제 텍스트를 위한 TEXT 객체, 하나는 레이블 데이터를 위한 LABEL 객체
# 필드 정의
TEXT = data.Field(sequential=True,
use_vocab=True,
tokenize=str.split,
lower=True,
batch_first=True,
fix_length=20)
LABEL = data.Field(sequential=False,
use_vocab=False,
batch_first=False,
is_target=True)- 각 인자의 의미는 다음과 같다
| 인자 | 설명 | Default 값 |
|---|---|---|
| sequential | 시퀀스 데이터 여부 | True |
| use_vocab | 단어 집합을 만들 것인지 여부 | True |
| tokenize | 어떤 토큰화 함수를 사용할 것인지 지정 | string.split |
| lower | 영어 데이터를 전부 소문자화 | False |
| batch_first | 미니 배치 차원을 맨 앞으로 하여 데이터를 불러올 것인지 여부 | False |
| is_target | 레이블 데이터 여부 | False |
| fix_length | 최대 허용 길이. 이 길이에 맞춰서 패딩 작업(Padding)이 진행 | False |
3-4. 데이터셋 만들기
train_data, test_data = TabularDataset.splits(
path='.', train='train_data.csv', test='test_data.csv', format='csv',
fields=[('text', TEXT), ('label', LABEL)], skip_header=True)| 인자 | 설명 |
|---|---|
| path | 파일이 위치한 경로 |
| format | 데이터의 포맷 |
| fields | 위에서 정의한 필드를 지정. 첫번째 원소는 데이터 셋 내에서 해당 필드를 호칭할 이름, 두번째 원소는 지정할 필드. |
| skip_header | 데이터의 첫번째 줄은 무시. |
- 훈련 데이터와 테스트 데이터를 csv 파일로 불러와 분리해서 저장해주었는데, 데이터의 크기를 다시 확인
print('훈련 샘플의 개수 : {}'.format(len(train_data)))
print('테스트 샘플의 개수 : {}'.format(len(test_data)))훈련 샘플의 개수 : 25000
테스트 샘플의 개수 : 25000- vars()를 통해서 주어진 인덱스의 샘플을 확인
print(vars(train_data[0])){'text': ['my', 'family', 'and', 'i', 'normally', 'do', 'not', 'watch', 'local',
'movies', 'for', 'the', 'simple', 'reason', 'that', 'they', 'are', 'poorly', 'made,', 'they', 'lack', 'the', 'depth,', 'and', 'just', 'not', 'worth', 'our', 'time.<br', '/><br', '/>the', 'trailer', 'of', '"nasaan', 'ka', 'man"', 'caught', 'my', 'attention,', 'my', 'daughter', 'in', "law's", 'and', "daughter's", 'so', 'we', 'took', 'time', 'out', 'to', 'watch', 'it', 'this', 'afternoon.', 'the', 'movie', 'exceeded', 'our', 'expectations.', 'the', 'cinematography', 'was', 'very', 'good,', 'the', 'story', 'beautiful', 'and', 'the', 'acting', 'awesome.', 'jericho', 'rosales', 'was', 'really', 'very', 'good,', "so's", 'claudine', 'barretto.', 'the', 'fact', 'that', 'i', 'despised', 'diether', 'ocampo', 'proves', 'he', 'was', 'effective', 'at', 'his', 'role.', 'i', 'have', 'never', 'been', 'this', 'touched,', 'moved', 'and', 'affected', 'by', 'a', 'local', 'movie', 'before.', 'imagine', 'a', 'cynic', 'like', 'me', 'dabbing', 'my', 'eyes', 'at', 'the', 'end', 'of', 'the', 'movie?', 'congratulations', 'to', 'star', 'cinema!!', 'way', 'to', 'go,', 'jericho', 'and', 'claudine!!'], 'label': '1'}- TabularDataset의 fields 인자로 TEXT 필드는 text로 호칭하고, LABEL 필드는 label로 호칭한다고 지정
# 필드 구성 확인.
print(train_data.fields.items())dict_items([('text', <torchtext.data.field.Field object at 0x0000029363E8B8B0>),
('label', <torchtext.data.field.Field object at 0x0000029345AD7FA0>)])3-5. 단어 집합(Vocabulary) 만들기
- 토큰화 전처리 -> 각 단어에 고유한 정수를 맵핑(정수 인코딩, Integer enoding)
- 정의한 필드에 .build_vocab() 도구를 사용하면 단어 집합을 생성
TEXT.build_vocab(train_data, min_freq=10, max_size=10000)| 인자 | 설명 |
|---|---|
| min_freq | 단어 집합에 추가 시 단어의 최소 등장 빈도 조건을 추가 |
| max_size | 단어 집합의 최대 크기를 지정 |
- 생성된 단어 집합의 크기를 확인
print('단어 집합의 크기 : {}'.format(len(TEXT.vocab)))단어 집합의 크기 : 10002- 생성된 단어 집합 내의 단어들은 .stoi를 통해서 확인 가능
print(TEXT.vocab.stoi)defaultdict(<bound method Vocab._default_unk_index of <torchtext.vocab.Vocab object at 0x0000029363DDE170>>, {'<unk>': 0, '<pad>': 1, 'the': 2, 'a': 3, 'and': 4,
'of': 5, 'to': 6, 'is': 7, 'in': 8, 'i': 9, 'this': 10, 'it': 11, 'that': 12, '/><br': 13, 'was': 14, 'as': 15, 'for': 16, 'with': 17, 'but': 18, 'on': 19, 'movie': 20, 'his': 21, 'not': 22, 'are': 23, 'you': 24, 'film': 25, 'have': 26, 'he':
27, ... 생략- 토치텍스트가 임의로 특별 토큰인 < unk >(0)와 < pad >(1)를 추가 -> 실제 생성된 단어 집합의 크기는 0번 단어부터 10,001번 단어까지 총 10,002개
batch_size = 5
train_loader = Iterator(dataset=train_data, batch_size = batch_size)
test_loader = Iterator(dataset=test_data, batch_size = batch_size)
print('훈련 데이터의 미니 배치 수 : {}'.format(len(train_loader)))
print('테스트 데이터의 미니 배치 수 : {}'.format(len(test_loader)))훈련 데이터의 미니 배치 수 : 5000
테스트 데이터의 미니 배치 수 : 5000- 25,000개의 샘플을 배치 크기 5씩 묶음 -> 훈련 데이터와 테스트 데이터 모두 미니 배치의 수가 5,000개 -> 첫번째 미니 배치를 batch 변수에 저장
batch = next(iter(train_loader)) # 첫번째 미니배치
print(type(batch))<class 'torchtext.data.batch.Batch'>- 일반적인 dataloader는 미니 배치를 텐서(tensor)로 가져오지만 Torchtext의 dataloader는 torchtext.data.batch.Batch 객체를 가져옴 -> 실제 데이터 텐서에 접근하기 위해서는 정의한 필드명을 사용
- 첫번째 미니 배치의 text 필드를 호출
print(batch.text)tensor([[ 287, 42, 10, 25, 14, 1798, 6, 384, 17, 10, 25, 64,
3, 172, 56, 219, 4, 9, 152, 11],
[ 10, 20, 14, 362, 5763, 17, 0, 0, 506, 59, 8, 1822,
9, 217, 284, 35, 41, 99, 257, 2],
[ 655, 2, 82, 156, 279, 5, 10, 5799, 3078, 70, 794, 12,
0, 7, 3, 948, 6365, 955, 35, 7672],
[ 147, 3, 349, 5, 2, 5911, 238, 4, 42, 974, 279, 72,
10, 1238, 9, 652, 6, 98, 10, 14],
[ 8, 1987, 6, 2, 236, 12, 10, 7, 39, 32, 0, 95,
25, 0, 676, 3, 8932, 6, 2, 970]])- 배치 크기가 5 -> 5개의 샘플이 출력
- 필드를 정의할 때 fix_length를 20으로 지정 -> 각 샘플의 길이는 20 -> 하나의 미니 배치의 크기는 (배치 크기 × fix_length)
- 각 샘플은 정수 시퀀스(단어 집합에서 정해진대로 각 단어에 맵핑되는 고유한 정수로 변환된 상태)
- < pad >가 사용되는 경우 : fix_length를 20이 아니라 150으로 정의할 때, 기존 샘플의 길이가 150이 되지 않기 때문에 숫자 1(< pad >)을 채워서 샘플의 길이를 150으로 맞춰줌 -> 서로 다른 길이의 샘플들을 동일한 길이로 맞춰추는 작업을 패딩 작업(Padding)이라 함.
4. Torchtext Basic with Korean
4-1. Setting train_data and test_data
- 필요한 라이브러리 임포트
import urllib.request
import pandas as pd- 네이버 영화 리뷰 데이터를 다운로드(훈련 데이터는 ratings_train.txt, 테스트 데이터는 ratings_test.txt)
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")- 데이터의 구성을 확인하기 위해서 훈련 데이터는 train_df, 테스트 데이터는 test_df에 저장
train_df = pd.read_table('ratings_train.txt')
test_df = pd.read_table('ratings_test.txt')- 훈련 데이터의 상위 5개의 행을 출력
print(train_df.head())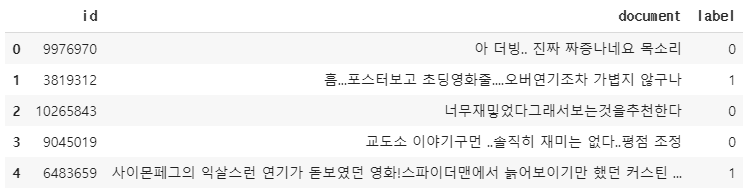
- 테스트 데이터의 상위 5개의 행을 출력
print(test_df.head())
- 훈련 데이터와 테스트 데이터 모두 id, document, label이라는 3개의 열로 구성(document 열은 영화 리뷰, label 열은 해당 리뷰가 긍정인지 부정인지에 대한 레이블, id 열은 여기서는 불필요)
print('훈련 데이터 샘플의 개수 : {}'.format(len(train_df)))
print('테스트 데이터 샘플의 개수 : {}'.format(len(test_df)))훈련 데이터 샘플의 개수 : 150000
테스트 데이터 샘플의 개수 : 50000- 훈련 데이터의 리뷰는 15만개, 테스트 데이터의 리뷰는 5만개
4-2. 필드 정의
from torchtext import data # torchtext.data 임포트
from konlpy.tag import Okt- 토큰화 도구로는 형태소 분석기 Okt를 사용
- 네이버 영화 리뷰 데이터는 3개의 열로 구성되어져 있으므로 3개의 필드를 정의
tokenizer = Okt()
# 필드 정의
ID = data.Field(sequential = False,
use_vocab = False) # 실제 사용은 하지 않을 예정
TEXT = data.Field(sequential=True,
use_vocab=True,
tokenize=tokenizer.morphs, # 토크나이저로는 Okt 사용.
lower=True,
batch_first=True,
fix_length=20)
LABEL = data.Field(sequential=False,
use_vocab=False,
is_target=True)4-3. 데이터셋 만들기
from torchtext.data import TabularDataset- 데이터를 데이터 셋의 형식으로 바꾸고, 동시에 토큰화 수행
train_data, test_data = TabularDataset.splits(
path='.', train='ratings_train.txt', test='ratings_test.txt', format='tsv',
fields=[('id', ID), ('text', TEXT), ('label', LABEL)], skip_header=True)- 데이터셋으로 변환된 샘플의 개수를 확인
print('훈련 샘플의 개수 : {}'.format(len(train_data)))
print('테스트 샘플의 개수 : {}'.format(len(test_data)))훈련 샘플의 개수 : 150000
테스트 샘플의 개수 : 50000- 토큰화가 되었는지 확인하기위해 훈련 데이터의 첫번째 샘플을 출력
print(vars(train_data[0])){'id': '9976970', 'text': ['아', '더빙', '..', '진짜', '짜증나네요', '목소리'], 'label': '0'}4-4. 단어 집합(Vocabulary) 만들기
TEXT.build_vocab(train_data, min_freq=10, max_size=10000)| 인자 | 설명 |
|---|---|
| min_freq | 단어 집합에 추가 시 단어의 최소 등장 빈도 조건을 추가 |
| max_size | 단어 집합의 최대 크기를 지정 |
- 생성된 단어 집합의 크기를 확인
print('단어 집합의 크기 : {}'.format(len(TEXT.vocab)))단어 집합의 크기 : 10002- 생성된 단어 집합 내의 단어들은 .stoi를 통해서 확인 가능
print(TEXT.vocab.stoi){'<unk>': 0, '<pad>': 1, '.': 2, '이': 3, '영화': 4,
'의': 5, '..': 6, '가': 7, '에': 8, '을': 9, '...': 10, '도': 11, '들': 12, ',':
13, '는': 14, '를': 15, '은': 16, '너무': 17, '?': 18, '한': 19, '다': 20, '정말': 21, '적': 22, '만': 23, '!': 24, '진짜': 25, ... 생략4-5. 토치텍스트의 데이터로더 만들기
- 데이터로더는 데이터셋에서 미니 배치만큼 데이터를 로드하게 만들어주는 역할
- 토치텍스트에서는 Iterator를 사용하여 데이터로더 생성
from torchtext.data import Iterator- 임의로 배치 크기를 5로 정할 때
batch_size = 5
train_loader = Iterator(dataset=train_data, batch_size = batch_size)
test_loader = Iterator(dataset=test_data, batch_size = batch_size)
print('훈련 데이터의 미니 배치 수 : {}'.format(len(train_loader)))
print('테스트 데이터의 미니 배치 수 : {}'.format(len(test_loader)))훈련 데이터의 미니 배치 수 : 30000
테스트 데이터의 미니 배치 수 : 10000- 훈련 데이터와 테스트 데이터터를 배치 크기 5씩 묶음 -> 훈련 데이터의 미니 배치 수는 30,000개, 테스트 데이터의 미니 배치 수는 10,000개
- 첫번째 미니 배치를 받아와서 batch라는 변수에 저장 -> 첫번째 미니 배치의 text 필드를 호출
batch = next(iter(train_loader)) # 첫번째 미니배치
print(batch.text)tensor([[ 272, 10, 5619, 23, 9598, 130, 2, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1],
[ 5, 105, 729, 16, 1639, 63, 90, 8, 47, 427, 13, 1613,
0, 8, 18, 264, 29, 42, 229, 229],
[ 114, 45, 30, 763, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1],
[ 70, 40, 97, 101, 22, 287, 105, 97, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1],
[ 168, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1]])- 배치 크기가 5이기 때문에 5개의 샘플이 출력
- 필드를 정의할 때 fix_length를 20으로 정함 -> 각 샘플의 길이는 20 -> 미니 배치의 크기는 (배치 크기 × fix_length)
- 숫자 0은 < unk >, 숫자 1은 < pad >
출처 : 'PyTorch로 시작하는 딥 러닝 입문' <이 책의 내용을 요약 정리한 것임.>

매일 매일 새로워지는 나 자신을 꿈꾸며