1. JOIN
-
서로 다른 데이터 테이블을 연결하는 것
-
공통적으로 존재하는 컬럼(=Key)이 있다면, JOIN할 수 있다
- 보통 id 컬럼을 Key로 많이 사용
- 특정 범위(예: Date)로도 JOIN이 가능
1.1. 왜 JOIN을 사용할까?
-> 이는 데이터가 저장되는 형태에 대한 이해가 필요하다
- 관계형 데이터베이스(RDBMS) 설계 시 정규화 과정을 거친다
- 정규화 : 중복을 최소화 하도록 데이터를 구조화 시키는 것
- 예) User Table에는 유저 데이터만, Order Table에는 주문 데이터만 저장
- 개발 관점에서, 중복된 데이터를 많이 가지고 있으면
-> Row 수 증가
-> 서비스가 느려질 수 있다
-> 때문에 데이터를 분리해 다양한 Table에 저장해 놓는다
- 정규화 : 중복을 최소화 하도록 데이터를 구조화 시키는 것
-
따라서 데이터 분석할 때, 다양한 Table에 분리되어 저장된 데이터들을 필요할 때 JOIN해서 사용
-
최근엔 "데이터 마트"를 만들어서 활용하기도 한다
- '마트'처럼, 필요한 데이터 테이블을 가져와 JOIN한 후, 목적에 맞게 가공하는 것
- 데이터 웨어하우스에서 -> 필요한 데이터 테이블 가져와 -> JOIN한 후 -> 필요한 연산(가공)
-> 데이터 마트 생성
1.2. 다양한 JOIN 방법
-
(INNER) JOIN : 두 테이블의 공통 요소만 연결
-
LEFT/RIGHT (OUTER) JOIN : 왼쪽/오른쪽 테이블 기준으로 연결
-
FULL (OUTER) JOIN : 양쪽 기준으로 연결
-
CROSS JOIN : 두 테이블의 각각의 요소를 곱하기
- 처음엔 LEFT JOIN 주로 사용해서 익숙해지기
그림으로 이해하기)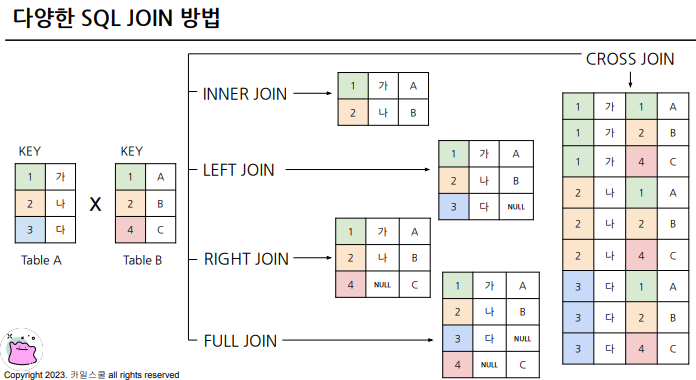
집합으로 이해하기) 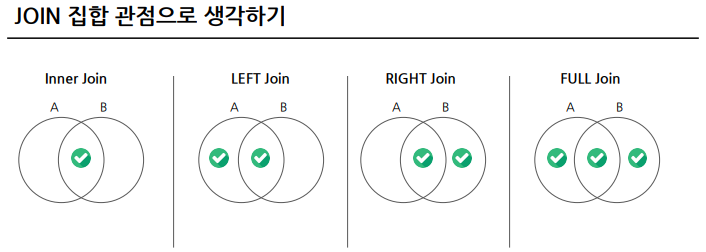
1.3. JOIN 쿼리 작성 흐름
1) 테이블 확인 : 테이블에 저장된 데이터, 컬럼 확인
=> 2) 기준 테이블 정의 : 가장 많이 참고할 기준(basd) 테이블 정의
예) LEFT JOIN의 경우 : 기준 테이블 즉, 가장 LEFT 테이블에 무엇을 둘 것인가?
=> Row 수가 적으면서, 원하는 값을 다 포함하는 테이블 (절대적 답은 아니다!)
=> 3) JOIN Key 찾기 : 여러 Table과 연결할 Key(ON) 정리
=> 4) 결과 예상하기 : 결과 테이블을 예상해서 손, 엑셀로 작성해보기
=> 5) 쿼리 작성/검증 : 예상한 결과와 동일한 결과가 나오는지 확인1.4. JOIN 문법
FROM Table_a AS a
LEFT JOIN Table_b AS b
ON a.key = b.key
- FROM 하단에 JOIN할 Table 작성
- ON 뒤에 공통된 컬럼(Key) 작성
- 테이블 이름이 긴 경우 별칭(Alias) 정의해서 사용
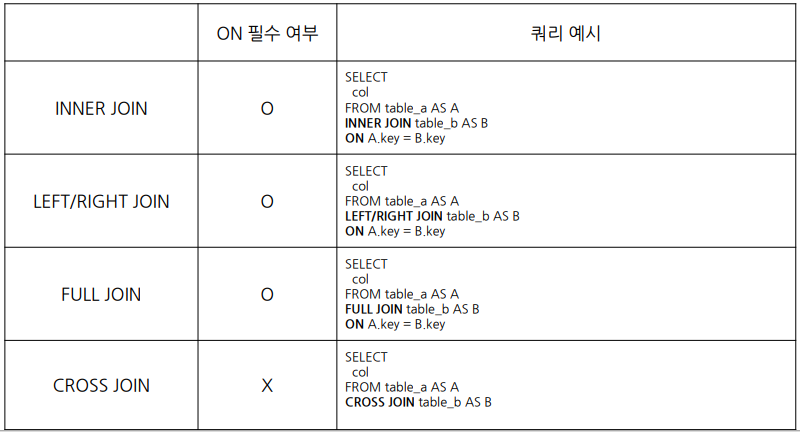
1.5. JOIN할 때 참고 사항
1.5.1. 어떤 Table을 왼쪽에 두고, 어떤 Table을 오른쪽에 둬야할까?
-
풀어야 하는 문제의 기준을 생각해야 한다
(LEFT JOIN의 경우)
-
기준이 되는 Table을 왼쪽에 두기
-
기준값이 존재하는 기준 테이블 <- 우측에 데이터를 계속 추가
-
기준값 : 내가 보려는 데이터의 요소들이 빠짐없이 존재하는가?
- 예) Order 테이블 : 주문한 고객의 정보만 들어있음.
User 테이블 : 주문하거나 주문을 한 번도 하지 않은 모든 고객의 정보가 들어있음 - '주문한' 유저의 정보를 보고싶은 경우 -> Order 테이블의 user_id가 기준값
-> Order 테이블[왼쪽(기준)] + User 테이블[LEFT JOIN해서 우측에 추가하는 테이블] - '주문하지 않은' 유저의 정보를 보고싶은 경우 -> User 테이블의 user_id가 기준값
-> User 테이블[왼쪽(기준)] + Order 테이블[LEFT JOIN해서 우측에 추가하는 테이블]
-> JOIN 테이블 order컬럼이 NULL인 값 반환
- 예) Order 테이블 : 주문한 고객의 정보만 들어있음.
-
-
1.5.2. 여러 Table을 연결?
- JOIN의 개수에 한계는 없다
- 하지만 너무 많은 테이블 JOIN하는 것을 비추천 -> 최대 3~5개까지
1.5.3. 컬럼 선택은 어떻게?
-
추출하는 컬럼 선택은 데이터를 추출해서 '무엇을 하고자' 하는지에 따라 다르다
-
사용하지 않을 컬럼은 선택하지 않는 것이 효율적이다 (BigQuery는 비용도 고려해야 한다)
-
id 같은 값은 자주 사용한다 -> COUNT id, DISTINCT id 등으로 자주 활용
-
사용할 컬럼만 추출하는 방법
1) EXCEPT 사용
: 필요하지 않은 컬럼 빼고 모두 추출SELECT a.* EXCEPT(필요하지 않은 컬럼) FROM Table_a AS a2) 서브쿼리
: 제일 안쪽 쿼리에 필요한 컬럼만 명시FROM ( SELECT * FROM ( SELECT a.a_id, b.b_id, a.order ) )
-
연습문제
- 트레이너가 보유한 포켓몬들은 얼마나 있는지 알 수 있는 쿼리를 작성해주세요.
(참고) 보유했다: status가 Active, Training한 경우. Released는 방출했다는 것을 의미# 쿼리를 작성하는 목표, 확인할 지표 : 포켓몬의 수(이름 명시) # 쿼리 계산 방법 : trainer_pokemon(status가 Active, Training) + pokemon => GROUP BY 집계(COUNT) # 데이터의 기간 : X # 사용할 테이블 : trainer_pokemon, pokemon # Join KEY : trainer_pokemon.pokemon_id = pokemon.id # 데이터 특징 : 보유했다:status가 Active, Training한 경우. Released는 방출했다는 것을 의미 -(회사에선, 이러한 정의를 알려주지 않고 직접 물어봐야 한다) _______________________________________________________________________________________________________________ / 쿼리 예상: 1) trainer_pokemon에서 status가 Active, Training인 경우만 필터링(where) 필터링을 먼저 하는 것이 좋을까? 혹은 JOIN을 하고 그 후에 Active, Training을 필터링하는 것이 좋을까? ->JOIN을 할 테이블들을 일단 줄이고 (Row 수를 줄인다) 그 후에 JOIN을 한다 ->연산량 관점에서 먼저 줄이고 JOIN이 효율적 JOIN을 한 후에 WHERE 조건을 건다고 하면 : 379 Row * pokemon JOIN WHERE 조건을 건 후에 JOIN을 한다고 하면 : 333 Row * pokemon JOIN =>핵심 : Table을 그대로 사용해야 하는가? 혹은 줄이고 쓰는 게 내 목적에 맞는가? 생각해보는 것 2) 필터링한 결과를 pokemo table 과 JOIN 3) 2)의 결과에서 pokemon_name, COUNT(pokemon_id) AS pokemon_cnt _______________________________________________________________________________________________________________ / SELECT -- tp.*, -- p.id, -- p.kor_name kor_name, COUNT(tp.id) AS pokemon_cnt -- join할 때 자주 나올 수 있는 에러 <Column name id is ambiguous at [6:9]> id가 모호하다. 더 구체적으로 말해달라 -- join에서 사용하는 테이블에 중복된 컬럼 이름이 있으면 꼭 어떤 테이블의 컬럼인지 명시해야 함 -- id => tp.id FROM ( SELECT id, trainer_id, pokemon_id, status FROM basic.trainer_pokemon WHERE status IN ("Active", "Training") ) AS tp LEFT JOIN basic.pokemon AS p ON tp.pokemon_id = p.id WHERE 1=1 -- 1=1은 무조건 TRUE를 반환 => 모든 ROW를 출력해라! -- 쿼리를 작성할 때 값을 바꿔가면서 실행해야 함 => 빨리 주석처리 하기 위해서 앞에 TRUE인 1=1을 넣고, AND쓰고 빠르게 주석처리하기도 함 GROUP BY kor_name ORDER BY pokemon_cnt DESC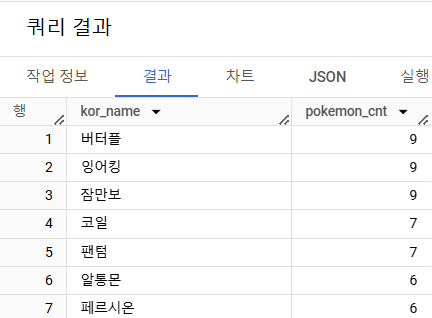
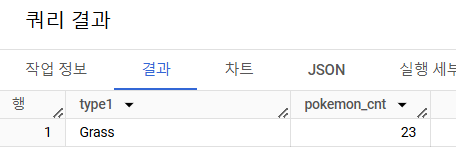
- 각 트레이너가 가진 포켓몬 중에서 'Grass'타입의 포켓몬 수를 계산해주세요. (단, 편의를 위해 type1 기준으로 계산해주세요.)
# 쿼리를 작성하는 목표, 확인할 지표 : 트레이너가 보유한 포켓몬 중에서 Grass 타입의 포켓몬 수 # 쿼리 계산 방법 : 트레이너가 보유한 포켓몬 조건 설정 => JOIN => Grass 타입으로 WHERE 조건 걸어서 COUNT -- 이 경우, Grass조건이 기준 테이블인 trainer_pokemon에 없는 컬럼-> JOIN후에 WHERE조건 설정 # 데이터의 기간 : X # 사용할 테이블 : trainer_pokemon + pokemon -- 어느 테이블을 왼쪽(기준)에 둘까? ->trainer_pokemon 테이블 : 트레이너가 포켓몬을 포획한 히스토리가 저장된 테이블. ->pokemon 테이블 : 포켓몬의 메타 정보. 트레이너가 포획을 하거나, 하지 않은 모든 포켓몬의 정보가 저장됨. ->pokemon 테이블을 왼쪽에 두면 -> pokemon 중에 포획되지 않았던 포켓몬들은 trainer_pokemon에 없을 것. -> NULL ->trainer_pokemon 테이블을 왼쪽에 두면 -> 트레이너가 보유했던 포켓몬들을 기반으로 포켓몬 데이터만 추가. -> NULL이 추가되지 않음 -- 핵심 : 기준이 되는 테이블은 내가 구하고자 하는 데이터가 어디에 제일 잘 저장되어 있는가? 를 기반으로 생각 # Join KEY : trainer_pokemon.pokemon_id = pokemon.id # 데이터 특징 : 1번 문제와 동일 _______________________________________________________________________________________________________________ / SELECT -- tp.*, # 확인용 p.type1, COUNT(tp.id) AS pokemon_cnt FROM ( SELECT id, trainer_id, pokemon_id, status FROM basic.trainer_pokemon WHERE status IN ("Active", "Training") ) AS tp LEFT JOIN basic.pokemon AS p ON tp.pokemon_id = p.id WHERE type1 = "Grass" GROUP BY type1 ORDER BY 2 DESC # 2 대신에 pokemon_cnt도 가능
-
트레이너의 고향(hometown)과 포켓몬을 포획한 위치(location)을 비교하여, 자신의 고향에서 포켓몬을 포획한 트레이너의 수를 계산해주세요. (status 상관없이 구해주세요.)
# 쿼리를 작성하는 목표, 확인할 지표 : 트레이너 고향과 포켓몬 포획 위치가 같은 트레이너의 수 계산하기 # 쿼리 계산 방법 : trainer(hometown), trainer_pokemon(locatoin) JOIN => hometown = location => 트레이너 수 COUNT # 데이터의 기간 : X # 사용할 테이블 : trainer, trainer_pokemon # Join KEY : trainer.id = trainer_pokemon.trainer_id -- 어디를 왼쪽에 써야할까? 상관없지만, trainer_pokemon을 LEFT로 할 것 같음(실제로 푼다면) ->trainer_pokemon테이블이 JOIN할만 한(trainer_id,pokemon_id처럼) 더 많은 정보를 가지고 있기 때문 ->이번엔 trainer 테이블을 LEFT로 둬보겠음 # 데이터 특징 : status 상관없이 구해주세요. _______________________________________________________________________________________________________________ / SELECT -- COUNT(tp.trainer_id) AS trainer_id, # 트레이너와 포켓몬이 같은 건이 43개 COUNT(DISTINCT tp.trainer_id) AS trainer_id_unique # 트레이너의 수 => 28명 : 이번 문제의 목적은 트레이너 수 구하기! FROM basic.trainer AS t LEFT JOIN basic.trainer_pokemon AS tp ON t.id = tp.trainer_id WHERE tp.location IS NOT NULL -- trainer중에 포켓몬을 잡아보지 못한 trainer가 있으면 null조건을 걸어줘야 함. -- 지금 데이터는 trainer테이블에 있는 trainer들은 모두 포켓몬을 잡아봐서(=null이 없어서) 신경쓰지 않아도 됨 -- 현업에서는 이부분을 꼭 체크해 봐야 함 AND t.hometown = tp.location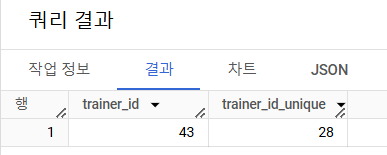
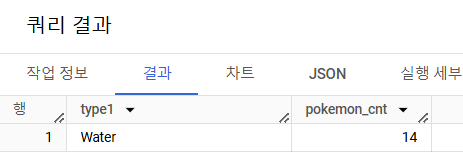
- Master 등급인 트레이너들은 어떤 타입의 포켓몬을 제일 많이 보유하고 있을까?
# 쿼리를 작성하는 목표, 확인할 지표 : Master등급의 트레이너들이 가장 많이 보유하고 있는 타입 # 쿼리 계산 방법 : trainer + pokemon + trainer_pokemon => Master 조건 설정(WHERE) => type1 GROUP BY + COUNT # 데이터의 기간 : X # 사용할 테이블 : trainer, pokemon, trainer_pokemon # Join KEY : trainer.id = trainer_pokemon.trainer_id, pokemon.id = trainer_pokemon.pokemon_id -- Key값에 2번 모두 나오는 trainer_pokemon을 LEFT 테이블로 # 데이터 특징 : 보유했다의 정의는 1번 문제의 정의와 동일 _______________________________________________________________________________________________________________ / SELECT type1, COUNT(tp.id) AS pokemon_cnt FROM ( SELECT id, trainer_id, pokemon_id, status FROM basic.trainer_pokemon WHERE status IN ("Active", "Training") ) AS tp LEFT JOIN basic.pokemon AS p ON tp.pokemon_id = p.id LEFT JOIN basic.trainer AS t ON tp.trainer_id = t.id -- LEFT JOIN을 연속해서 N번 사용할 수 있다 WHERE t.achievement_level = "Master" GROUP BY type1 ORDER BY 2 DESC LIMIT 1
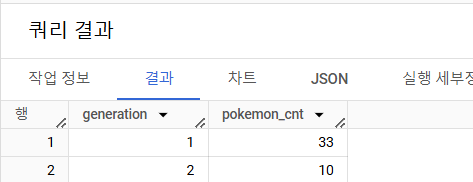
- Incheon 출신 트레이너들은 1세대, 2세대 포켓몬을 각각 얼마나 보유하고 있나?
# 쿼리를 작성하는 목표, 확인할 지표 : Incheon 출신 트레이너들이 보유하고 있는 포켓몬 중에 세대 구분(1세대,2세대) # 쿼리 계산 방법 : trainer + pokemon + trainer_pokemon => Incheon 조건 (WHERE) => 세대(generation)로 GROUP BY + COUNT # 데이터의 기간 : X # 사용할 테이블 : trainer_pokemon, trainer, pokemon # Join KEY : t.id, tp.trainer_id, tp.pokemon_id, p.id # 데이터 특징 : 보유하다의 정의 _______________________________________________________________________________________________________________ / SELECT generation, COUNT(tp.id) AS pokemon_cnt FROM ( SELECT id, trainer_id, pokemon_id, status FROM basic.trainer_pokemon WHERE status in ("Active", "Training") ) AS tp LEFT JOIN basic.trainer AS t ON tp.trainer_id = t.id LEFT JOIN basic.pokemon AS p ON tp.pokemon_id = p.id WHERE t.hometown = "Incheon" GROUP BY generation _______________________________________________________________________________________________________________ / -- 만약 세대가 점점 데이터 늘어나서 1, 2세대가 아니라 3세대도 생기면 어떻게 할 것인가? -- 3세대도 생기면, 3세대도 나오게 해줘! => 쿼리를 그대로 사용하면 됨 -- 3세대가 생겨도, 1, 2세대만 나오게 해줘! => WHERE 조건에 generation IN (1, 2) -- 지금은 데이터가 고정데이터지만, 회사는 계속 추가되는 살아있는 데이터 -- => 쿼리를 REFACTORING 안할 수 있도록 미래에 어떤 요구조건이 있을까 생각하는 것이 중요!