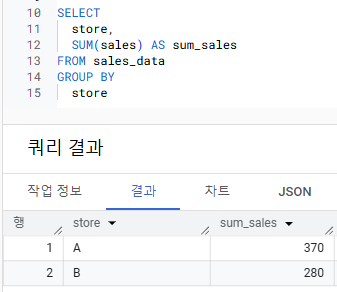
윈도우 함수
-
윈도우 함수(Window Function)은 분석 함수(Analytics Function)로 불리기도 함
- Oracle에서는 분석 함수라 불리고
- Postgre SQL, BigQuery에서는 윈도우 함수라 불림
-
윈도우 함수는 다음과 같은 경우에 유용한 함수
- "A 유저의 전 주문 수량은 얼마나 될까?"
- "B 유저가 물건 구입하기 전에 몇 번이나 상세보기를 방문했을까?"
- "C 유저의 이전/다음 앱 접속시간이 얼마나 될까?"
- "D 고객의 특정 구매 시점에 총 누적 구매 횟수는?"
-
이런 경우, 윈도우 함수를 사용하지 않으면 서브쿼리나 JOIN 등을 사용해서 구해야 함
윈도우 함수 쿼리 작성
윈도우 함수 이름(컬럼, 순서) OVER (PARTITION BY 파티션_컬럼 ORDER BY 정렬__컬럼 윈도우 프레임)
- 윈도우 함수 이름:
- 탐색 함수: LEAD, LAG, FIRST_VALUE, LAST_VALUE
- 번호 지정 함수: RANK, ROW_NUMBER 등
- 집계 분석 함수: 집계 함수들, COUNT, SUM, AVG, MAX, MIN 등
- 컬럼: 윈도우 함수를 적용할 컬럼
- 순서: 값을 가져올 행의 위치. 기본 값은 1이고 생략 가능
- OVER: ~에 걸쳐서, ~에 대해서
- PARTITION BY: 파티션의 기준이 될 컬럼. 필요에 따라 생략 가능
- ORDER BY: 정렬의 기준이 될 컬럼. 필요에 따라 생략 가능
- 윈도우 프레임: 윈도우 함수가 작동하는 범위.
- 데이터의 범위를 제한하고 싶은 경우 Frame 설정
윈도우 함수
1. 탐색 함수
- LEAD, LAG, FIRST_VALUE, LAST_VALUE
- 탐색함수는 Row들을 탐색하며 값을 반환하는 함수
- 정렬이 항상 필요 => ORDER BY 필수
1) LEAD
- 다음 행의 값을 반환하는 탐색 함수
- 유저 별로 방문 주기를 파악하고 싶을 때
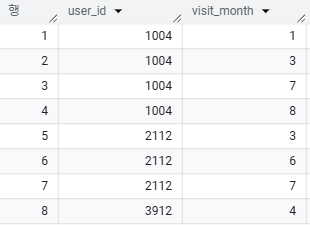
1) 유저 별 다음 방문 월은?
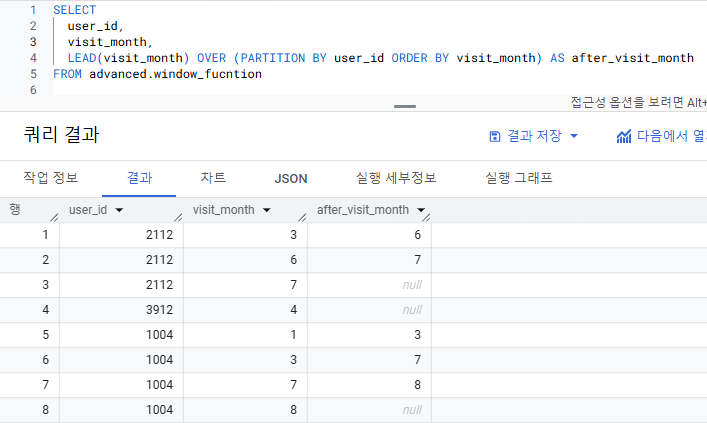
2) 유저 별 방문 이후 두번째 방문 월은?
-
LEAD(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month)
- LEAD(visit_month) : 컬럼 visit_month를 행 별로 탐색하면서 다음 행의 값을 반환하겠다
- PARTITION BY user_id: 컬럼 user_id가 파티션으로 작동 => user_id 1004/2112/3912 별로 탐색함수가 작용한다
- ORDER BY visit_month : 컬럼 visit_month가 정렬 기준으로 작동 => user_id 1004인 유저는 visit_month가 1->3->7->8 순서로 정렬되고 => 이 정렬에 따라 탐색함수 LEAD가 작용한다
-
LEAD(visit_month, 2) OVER (PARTITION BY user_id ORDER BY visit_month)
- LEAD(visit_month, 2) : 컬럼 visit_moth를 행 별로 탐색하면서 다다음 행의 값을 반환하겠다
-
LEAD함수의 반환된 값이 NULL = 더 이상 방문한 월이 없다 = 해당 visit_month가 유저의 마지막 방문 월이다
2) LAG
- 이전 행의 값을 반환하는 탐색 함수
- 유저 별 이전 방문 월은?
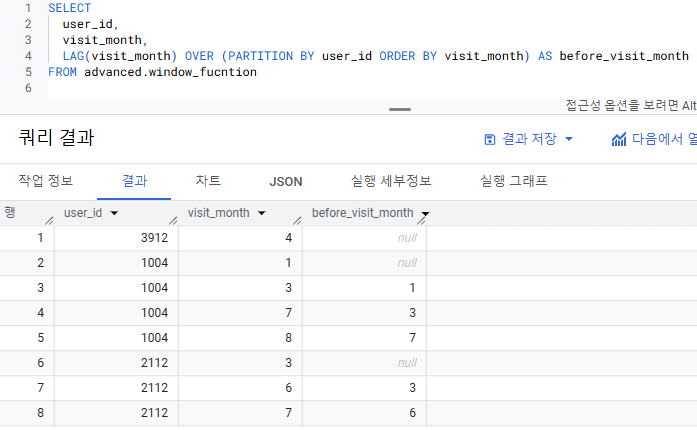
-
LAG(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month)
- LAG(visit_month) : 컬럼 visit_month를 행 별로 탐색하면서 이전 행의 값을 반환하겠다
- PARTITION BY user_id : 컬럼 user_id가 파티션으로 작동 => user_id 1004/2112/3912 별로 탐색함수가 작용한다
- ORDER BY visit_month : 컬럼 visit_month가 정렬 기준으로 작동 => user_id 2112인 유저는 visit_month가 3->6->7 순서로 정렬되고 => 이 정렬에 따라 탐색함수 LAG가 작용한다
-
LAG함수의 반환된 값이 NULL = 이전에 방문한 월이 없다 = 해당 visit_month가 유저의 첫 방문 월이다
-
LEAD, LAG 함수는 숫자를 지정해서 바로 앞, 뒤, 2번째 앞, 3번째 뒤 등을 지정할 수 있음
- LEAD(visit_month, 3) : 3번째 뒤의 행의 값을 반환
- LAG(visit_month, 2) : 2번째 이전 행의 값을 반환
3) FIRST_VALUE
- 첫 번째 행의 값을 반환하는 탐색 함수
- 유저들의 첫 방문 월은?
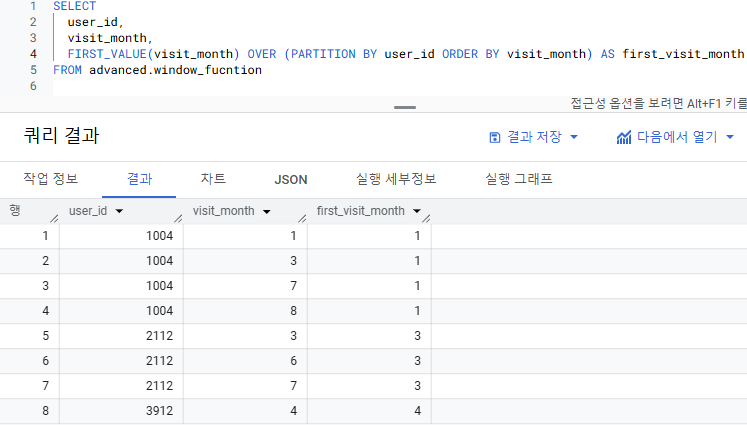
- FIRST_VALUE(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month)
- FIRST_VALUE(visit_month) : 컬럼 visit_month를 행 별로 탐색하면서 첫번째 행의 값을 반환하겠다
- PARTITION BY user_id : 이때 user_id가 파티션으로 작동하여 => user_id 1004/2112/3912 별로 탐색함수가 작용한다
- ORDER BY visit_month : 컬럼 visit_month가 정렬 기준으로 작동하여 => 유저 1004는 visit_month가 1->3->7->8로 정렬되고 => 이 정렬에 따라 첫 번째 행의 값인 1이 유저 1004의 첫 방문 월로 반환된다
4) LAST_VALUE
- 마지막 행의 값을 반환하는 탐색 함수
- 유저들의 마지막 방문 월은?
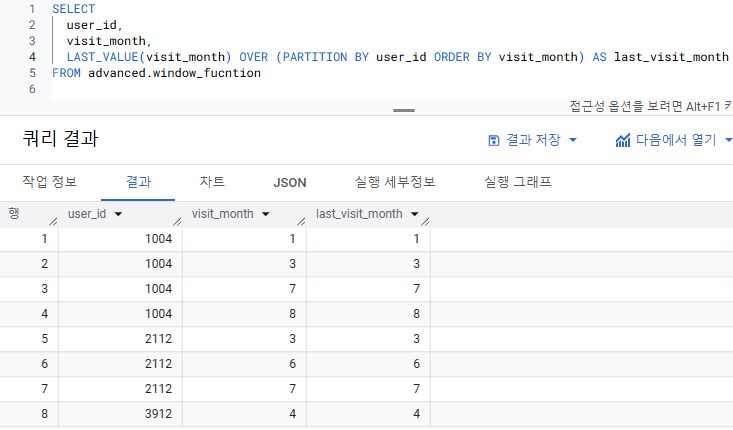
- LAST_VALUE(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month)
- LAST_VALUE(visit_month) : 컬럼 visit_month를 행 별로 탐색하면서 마지막 행의 값을 반환하겠다
- PARTITION BY user_id : 이때 user_id가 파티션으로 작동하여 => user_id 1004/2112/3912 별로 탐색함수가 작용한다
- ORDER BY visit_month : 컬럼 visit_month가 정렬 기준으로 작동하여 => 유저 1004는 visit_month가 1->3->7->8 정렬되고 => 이 정렬에 따라 마지막 행의 값이 8이 유저 1004의 마지막 방문 월로 반환된다
- 주의) 마지막의 기준은 데이터가 최신화되면서 바뀜 -> '최신 방문 월'과 같은 마지막 값에 대한 정보는 쿼리 실행 시점에 따라 달라질 수 있는 값임
FIRST_VALUE와 LAST_VALUE의 NULL 처리
- GROUP BY와 사용되는 일반적인 집계 함수(AVG, SUM 등)는 NULL을 제외해서 연산
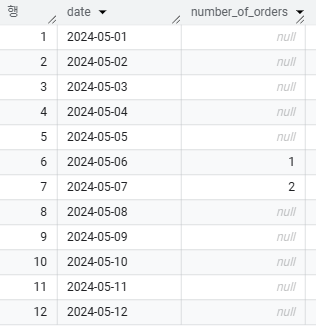 | 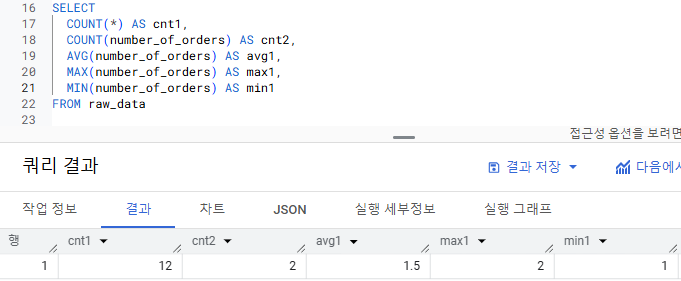 |
|---|
- 윈도우 함수 FIRST_VALUE와 LAST_VALUE는 NULL을 포함해서 연산
- 파티션 내의 첫 번째 값/마지막 값이 NULL이면 그대로 NULL을 반환
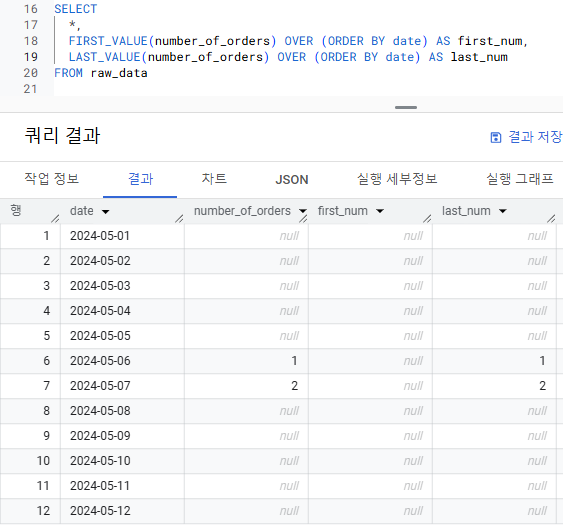
- NULL을 제외하고 싶으면 IGNORE NULLS 사용
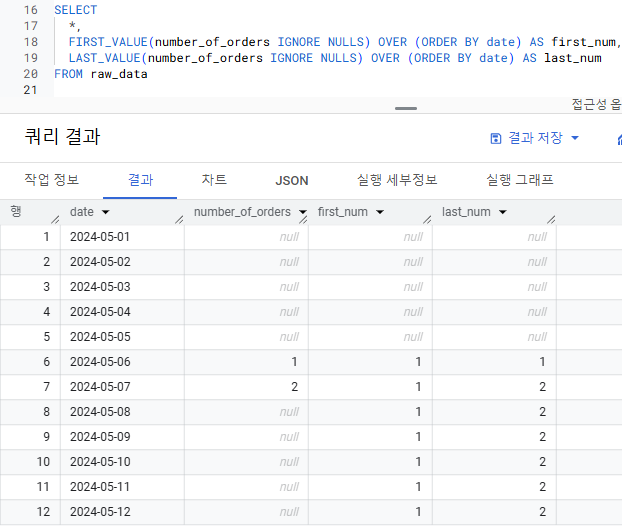
-
탐색 함수 활용 예시
-
유저 A가 앱에 접속한 후, 어떤 화면으로 이동했는지 알 수 있음
- 다음 row의 page를 확인하면 됨
SELECT user_id, event_timestamp, event_name, event_parameter, LEAD(event_name) OVER (PARTITION BY user_id ORDER BY event_timestamp) AS next_page FROM app_logs WHERE user_id = "A"
- 다음 row의 page를 확인하면 됨
-
유저 A의 앱 로그 상에서 같은 page를 연속으로 접근한 경우 하나로 처리해서 퍼널을 구하라
- LEAD한 값과 기존 컬럼의 값을 비교해서
- 직전 이벤트와 현재 이벤트가 동일한 것들을 필터링
-
리텐션 쿼리를 작성할 때 기준점을 만들 수 있음
- 유저의 첫 접속일 => FIRST_VALUE
-
2. 번호 지정 함수
- RANK, ROW_NUMBER
- 번호 지정 함수는 파티션 내의 Row들에 순위를 지정하는 함수
1) RANK
- 값에 중복이 있으면 공동 순위를 부여. 그 다음 순위는 패스 (GAP이 있다)
- 공동 2등이 있으면 => 1등/2등/2등/4등
- NO GAP을 원하면 => DENSE_RANK
2) ROW_NUMBER
-
값에 중복이 있으면 랜덤으로 순위 부여.
-
랜덤이기 때문에 순위가 변경될 수 있음
=> 고정된 순위를 얻고 싶다면 ORDER BY에 id 기준을 추가SELECT *, ROW_NUMBER() OVER (PARTITION BY product_type ORDER BY revenue DESC, id) AS row_num FROM Table- ORDER BY revenue DESC, id : 값에 중복이 생기면 id로 정렬하겠다. id는 보통 유니크한 값이기 때문
- 매출 데이터에서 product_type 별로 매출 순위를 알고 싶은 경우
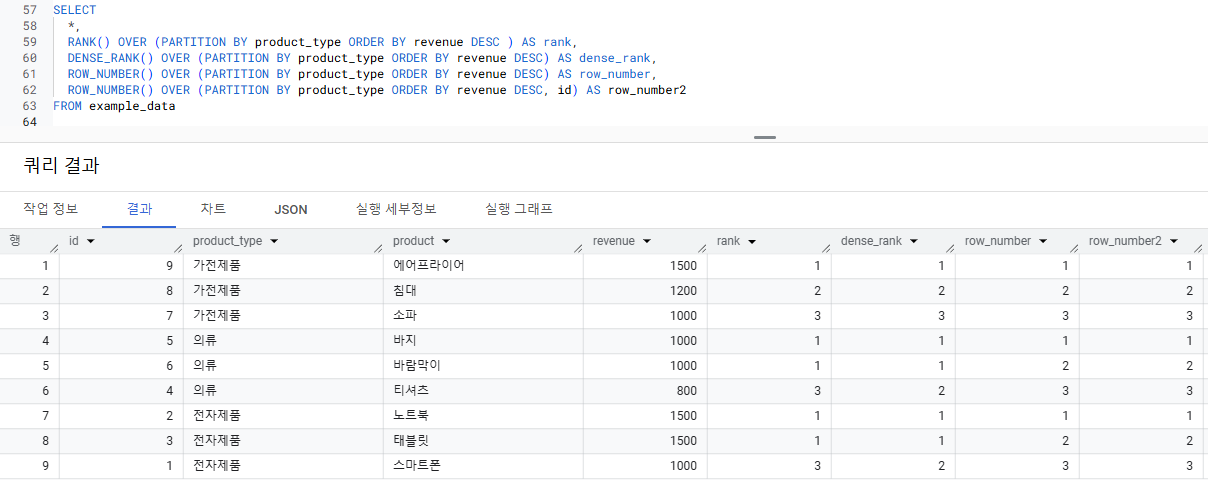
- PARTITION BY product_type : product_type이 파티션으로 작동 => product_type 가전제품/의류/전자제품 별로 번호 지정 함수가 작용한다
- ORDER BY revenue DESC : 컬럼 revenue가 정렬 기준으로 작동하고 => desc는 내림차순이므로 revenue가 큰 순서대로 정렬되어 => product_type 가전제품은 revenue가 1500->1200->1000으로 정렬되고 => 이 정렬에 따라 순위가 지정된다
-
RANK, ROW_NUMBER 선택 방법
- 파티션 내에서 고유한 순서가 필요한 경우 => ROW_NUMBER
- 고정된 값이 필요할 땐 ORDER BY에 id 기준도 추가
- 파티션 내에서 동일한 값을 가진 행에 동일한 순서가 필요한 경우 => RANK
- 상위 30%의 그룹화를 위해 랭킹을 뽑고 싶은 경우 => RANK
- RANK의 순위는 gap이 존재하기 때문
- 파티션 내에서 고유한 순서가 필요한 경우 => ROW_NUMBER
3. 집계 분석 함수
- 윈도우 함수의 집계 분석 함수는 GROUP BY처럼 집계 함수들을 사용할 수 있음
- 집계 함수(Aggregation Function)는 AVG, COUNT, SUM, MAX, MIN 등처럼 여러 값을 가지고 계산하는 함수를 말함
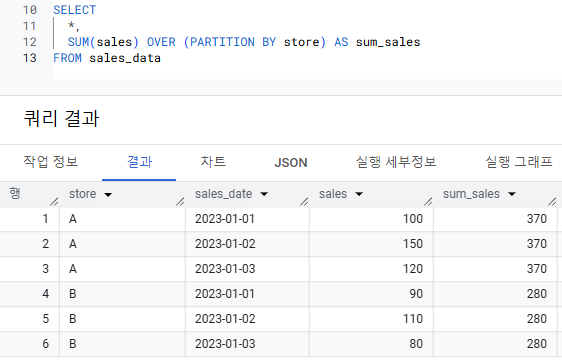
- 윈도우 함수와 GROUP BY의 차이
- GROUP BY : 여러 Row의 값을 집계해서 1개의 Row로 하나의 값을 반환
- 윈도우 함수 : 각각의 Row마다 값을 계산해서 각 Row에 단일 값을 반환
 |   |
|---|
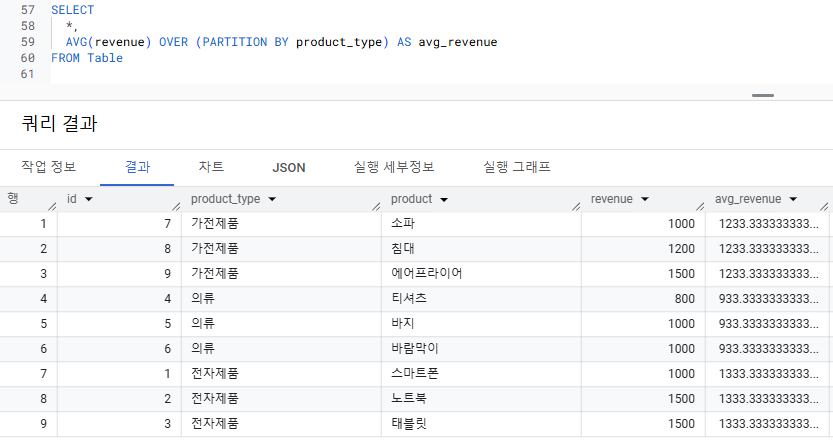
- product_type 별로 평균 매출을 구하려면?
- product_type 별로 매출 합을 구하려면?
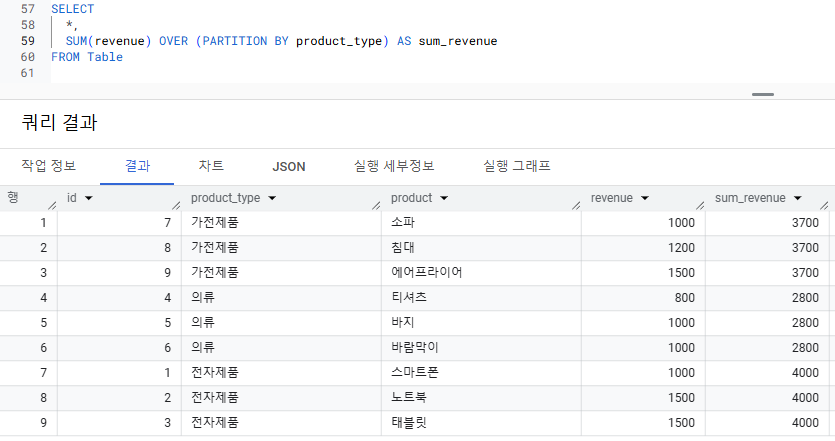
- SUM, AVG는 정렬이 필요 없기 때문에 => OVER 절에 ORDER BY가 생략됨
윈도우 함수 Frame 설정
- 윈도우 함수에서 데이터의 범위를 제한하고 싶은 경우 => Frame 설정
- 예) 이동 평균(Moving Average)를 구할 때
- 이동 평균: 이동하면서 구해지는 평균
- 특정 Row 기준으로 이전 3번째부터 이후 2번째 데이터의 평균
- 예) 3달 전 데이터부터 현재 Row까지의 SUM
- 예) 이동 평균(Moving Average)를 구할 때
-
Frame 설정 방법
-
1) ROWS
- Row 수를 기준으로 경계를 지정
- 이전 2개의 행, 이후 3개의 행 등을 지정할 수 있음
- ROWS Frame을 더 자주 사용
-
2) RANGE
- 논리적인 값의 범위를 기준으로 지정
- 특정 값의 3일 전, 3일 후 등을 지정할 수 있음
-
-
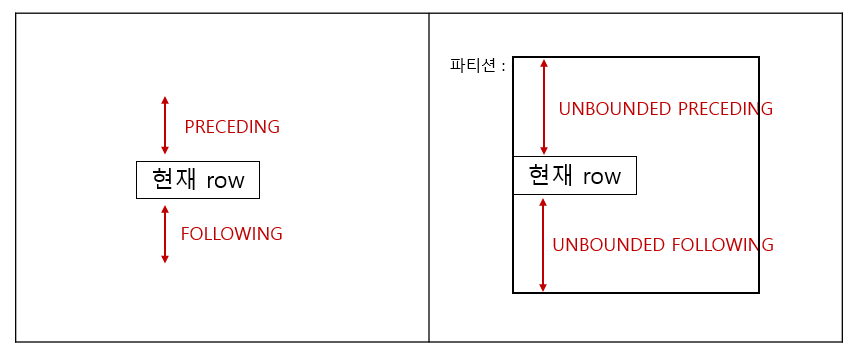
Frame의 시작과 끝 지점 명시하기
- PRECEDING : 현재 행 기준으로 이전 행
- CURRENT ROW : 현재 행
- FOLLOWING : 현재 행 기준으로 이후 행
- UNBOUNDED : 처음부터 또는 끝까지
-
Frame 쿼리 작성
현재 행과 이전 행 1개, 이후 행 3개를 포함해서 평균
- AVG(컬럼) OVER (PARTITION BY product_type ORDER BY event_timestamp ROWS BETWEEN 1 PRECEDING AND 3 FOLLOWING)
파티션의 처음부터 현재 행을 포함한 평균
- AVG(컬럼) OVER (PARTITION BY product_type ORDER BY event_timestamp ROWS UNBOUNDED PRECEDING AND CURRENT ROW)
-
Frame 예시)
1) 우리 회사의 모든 주문량은?
2) 특정 주문 시점에서 누적 주문량은?
3) 고객 별 주문 시점에서 누적 주문량은?
4) 최근 직전 5개의 평균 주문량은?
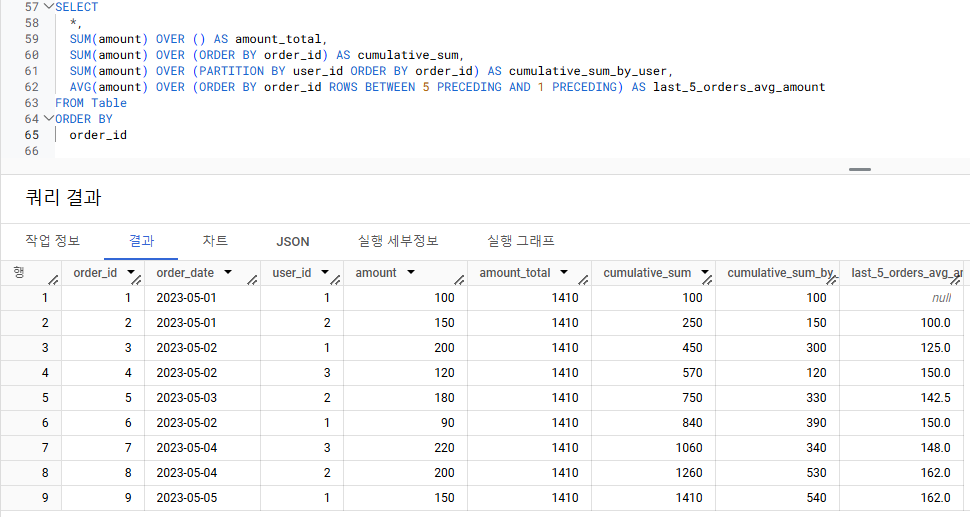
-
SUM(amount) OVER () AS amount_total
- 모든 주문량(total amount) = 주문 시점, 고객, 날짜 등 상관 없이 모든 주문량의 합
=> 1. 윈도우 집계 분석 함수에서 SUM 사용
=> 2. SUM에 필요한 컬럼은 amount
=> 3. 파티션과 정렬 필요 없으므로 OVER 절에 PARTITION BY와 ORDER BY 생략- => OVER절에 아무것도 들어가지 않는 경우도 있다
- 모든 주문량(total amount) = 주문 시점, 고객, 날짜 등 상관 없이 모든 주문량의 합
-
SUM(amount) OVER (ORDER BY order_id) AS cumulative_sum
- 특정 주문 시점에서 누적 주문량(cumulative sum) = 주문 시점을 나타내는 컬럼의 row를 지날수록 누적되는 주문량의 합
=> 1. 윈도우 집계 분석 함수에서 SUM 사용
=> 2. SUM에 필요한 컬럼은 amount
=> 3. 특정 컬럼의 정렬에 따라 행이 지날수록 주문량의 합이 누적되어야 함 -> 정렬되어야 하는 그 특정 컬럼은 주문 시점을 나타내야 함
=> 4. 정렬이 필요하므로 OVER절에 ORDER BY. 정렬되는 컬럼은 주문 시점을 나타내는 order_id.- ORDER BY order_date가 아닌 ORDER BY order_id인 이유)
- order_date는 'year-month-day' 의 날짜 정보만 가지고 있는 컬럼 => ORDER BY order_date 한다면 주문일자에 따른 누적 주문량이 반환됨
- order_ id는 주문 자체의 정보를 나타내는 컬럼 => 고객의 order 정보 + timestamp 정보까지 나타냄
- 따라서 특정 주문 시점에 따른 누적 합계량이 보고 싶을 땐 OVER절에서 컬럼 order_id를 정렬
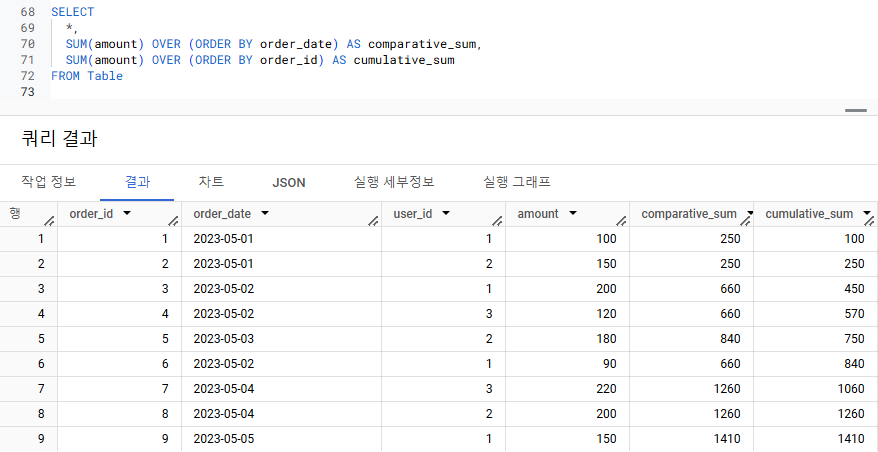
- ORDER BY order_date가 아닌 ORDER BY order_id인 이유)
- 특정 주문 시점에서 누적 주문량(cumulative sum) = 주문 시점을 나타내는 컬럼의 row를 지날수록 누적되는 주문량의 합
-
SUM(amount) OVER (PARTITION BY user_id ORDER BY order_id) AS cumulative_sum_by_user
- 고객 별 주문시점에서 누적 주문량 = 각 고객의 파티션 내에서 주문 시점을 나타내는 컬럼의 row를 지날수록 누적되는 주문량의 합
=> 1. 윈도우 집계 분석 함수에서 SUM 사용
=> 2. SUM에 필요한 컬럼은 amount
=> 3. 주문 시점을 나타내는 컬럼의 정렬에 따라 행이 지날수록 주문량의 합이 누적되어야 함
=> 4. 각 고객의 파티션 내에서 누적되는 주문량의 합을 보고싶음
=> 5. 파티션이 필요하므로 OVER 절에 PARTITION BY. 파티션에 해당하는 컬럼은 고객 정보를 나타내는 user_id.
=> 6. 정렬이 필요하므로 OVER절에 ORDER BY. 정렬되는 컬럼은 주문 시점을 나타내는 order_id.
- 고객 별 주문시점에서 누적 주문량 = 각 고객의 파티션 내에서 주문 시점을 나타내는 컬럼의 row를 지날수록 누적되는 주문량의 합
-
AVG(amount) OVER (ORDER BY order_id ROWS BETWEEN 5 PRECEDING AND 1 PRECEDING) AS last_5_orders_avg_amount
- 최근 직전 5개의 평균 주문량 = 현재 행으로부터 이전 5개의 행~이전 1개의 행의 주문량의 평균
=> 1. 윈도우 집계 분석 함수에서 AVG 사용
=> 2. AVG에 필요한 컬럼은 amount
=> 3. 최근 직전 5개 -> 보고싶은 데이터의 범위를 제한 -> Frame 사용 -> 현재 행으로부터 ROWS BETWEEN 5 PRECEDING AND 1 PRECEDING
=> 4. 현재 행의 이전 5개의 행~이전 1개의 행을 구분하기 위해 정렬이 필요 -> OVER 절에 ORDER BY order_id
- 최근 직전 5개의 평균 주문량 = 현재 행으로부터 이전 5개의 행~이전 1개의 행의 주문량의 평균
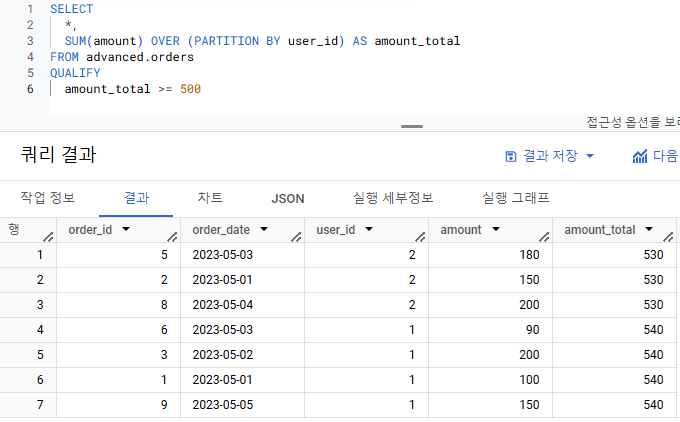
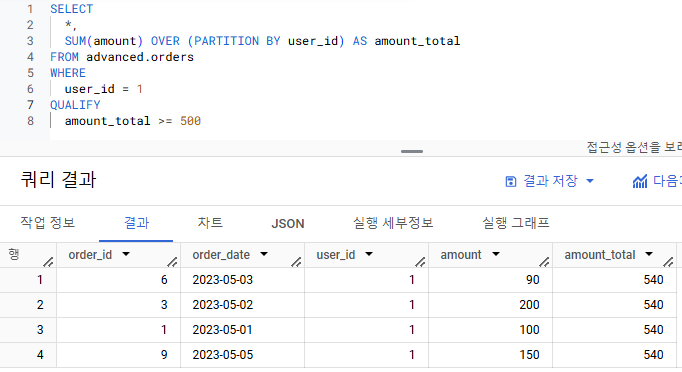
윈도우 함수 조건 설정 Qualify
-
QUALIFY를 통해 윈도우 함수로 만든 컬럼에 바로 조건 설정이 가능함
-
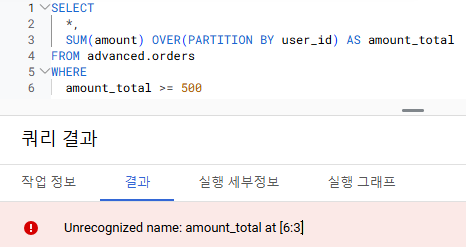
2021.04 까지만 해도
- 윈도우 함수로 만든 컬럼에 조건을 설정하고 싶으면
- 서브쿼리를 만들고 WHERE절에 조건을 추가해야 했음
 |  |
|---|
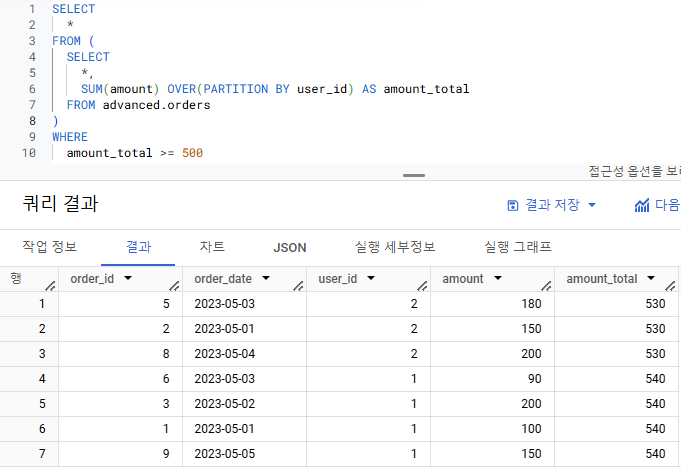
- 2021.04 이후
- QUALIFY 기능이 생겨
- 윈도우 함수로 만든 컬럼에 바로 조건 설정 가능해짐
- WHERE 절과 같이 사용하는 경우엔 WHERE 절 아래에 작성
 |  |
|---|
연습문제
데이터 1.
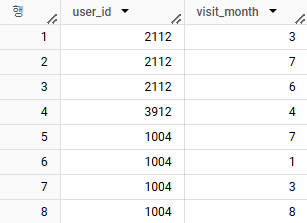
-
유저가 접속했을 때, 다음 접속까지의 간격을 구하시오.
- 기대하는 ouput :
user_id | visit_month | after_visit_month | diff_month
-
유저의 다음 접속까지의 간격을 나타내는 diff_month를 구하기 위해선
-
다음 접속 시기를 나타내는 after_visit_month에서 기존 접속 시기 visit_month를 빼는(-) 연산이 필요해보임
-
연산을 위한 쿼리를 생각해보면
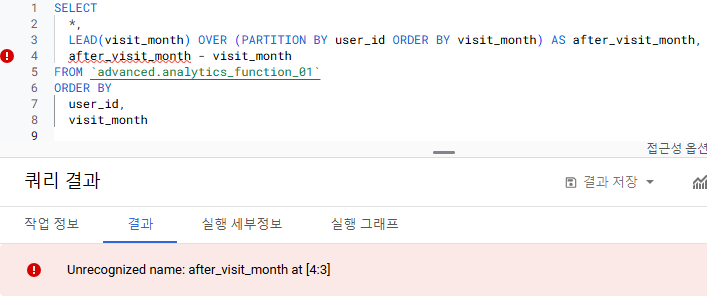
1) select 절에서 윈도우 함수 alias를 직접 연산하는 경우
=> 오류
=> select 절은 제일 마지막에 실행됨 -> after_visit_month - visit_month를 실행할 때 after_visit_month를 인식하지 못함
2) 중복된 윈도우 함수 쿼리를 연산하는 경우
=> 중복 쿼리는 최대한 줄이는 것이 좋음
=> 나중에 쿼리를 수정할 상황이 생길 수 있음 -> 중복된 쿼리가 있으면 해당 쿼리를 수정할 때 -> 2번 수정해야 함
=> 이런 중복 쿼리가 많아지면 쿼리가 복잡해지고 실수하기 쉬워짐
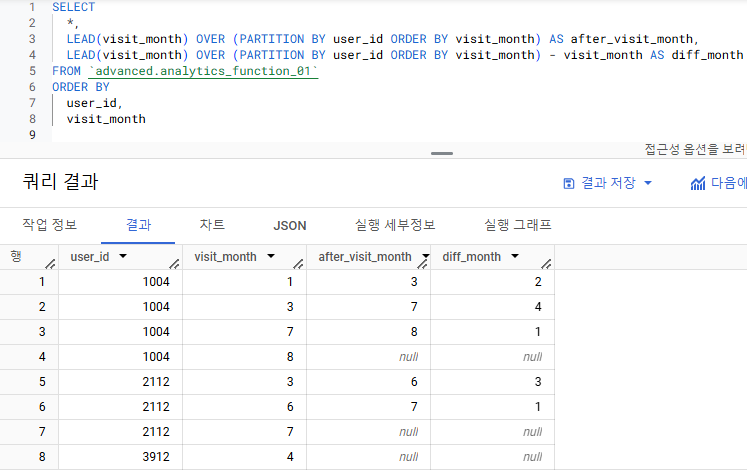
3) 서브 쿼리 이용해서 연산
- 서브 쿼리 이용할 때, 쿼리가 길어지는 것을 걱정하곤 함
- 그러나 쿼리가 길어지는 것을 무서워하지 말고, 쿼리를 덜 수정할 수 있는 구조를 만드는 것이 중요함
-
- 기대하는 ouput :
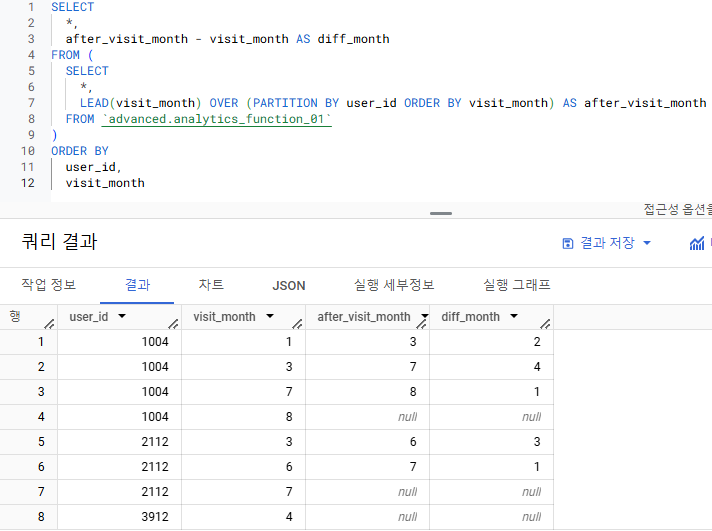
데이터 2.
-
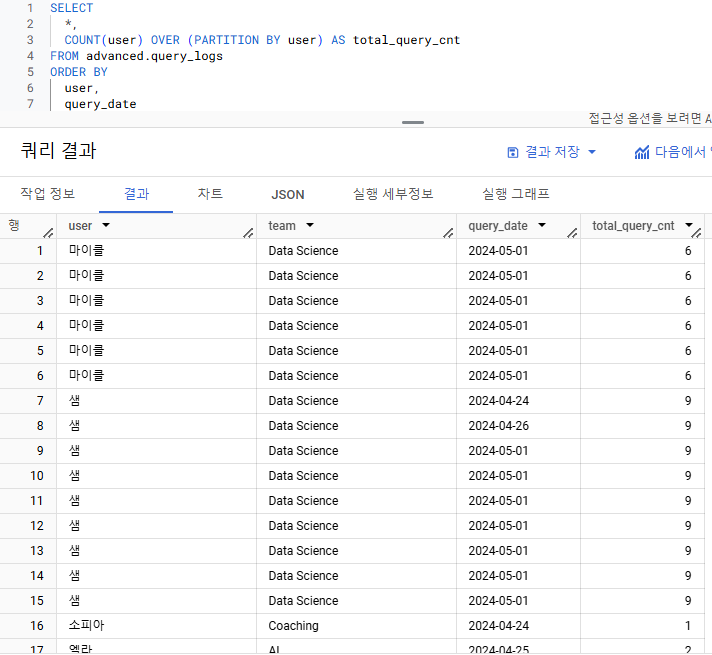
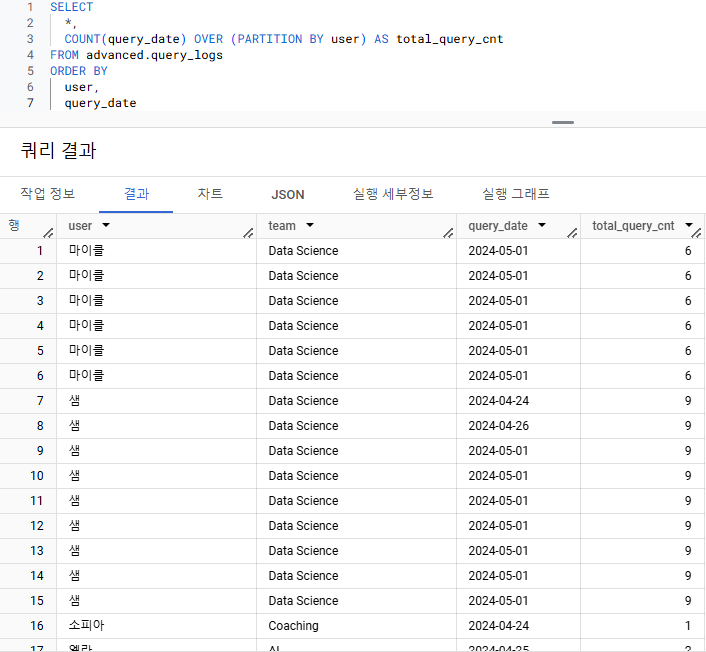
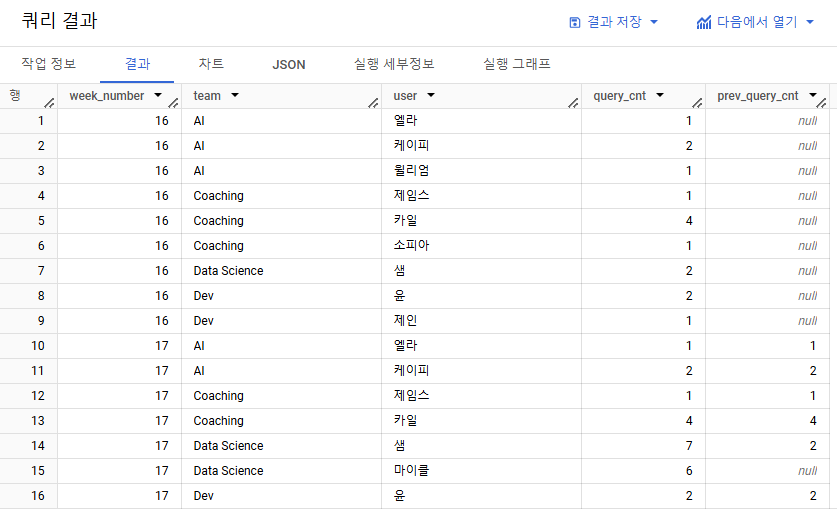
- 사용자별 쿼리를 실행한 총 횟수를 구하는 쿼리를 작성해주세요. 단, group by가 아닌 데이터 우측에 새로운 컬럼으로 나타내주세요.
- 기대하는 output :
user | team | query_date | total_query_cnt
- group by가 아닌 집계 함수 => 윈도우 집계 분석 함수
- 쿼리를 실행한 총 횟수 => COUNT
- 집계할 컬럼은 user나 query_date
=> 해당 데이터는 유저가 쿼리를 실행한 일자를 나타낸 데이터
=> 여기서 각 행은 쿼리를 실행한 수를 나타낼 수 있는 지표- user : 유저의 이름 정보 나타냄
- team : 유저가 속한 팀 정보 나타냄
- query_date : 유저가 쿼리를 실행한 일자를 나타냄
- 집계할 컬럼은 user나 query_date
- 사용자 별 쿼리를 실행한 총 횟수 => 파티션 필요
- 파티션이 될 컬럼은 user
- 총 횟수를 나타내는 COUNT이므로 over절에 ORDER BY는 필요하지 않음
 |  |
|---|
-
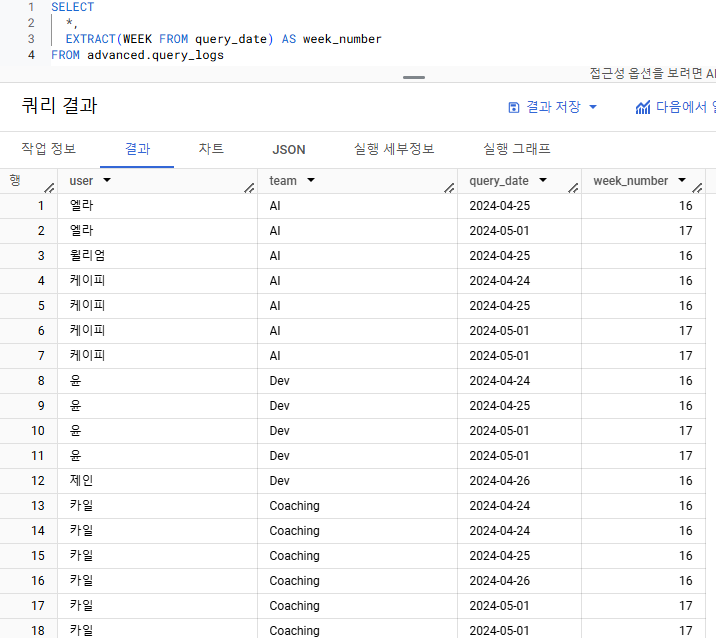
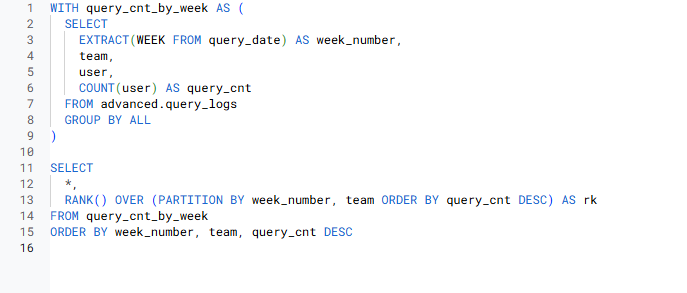
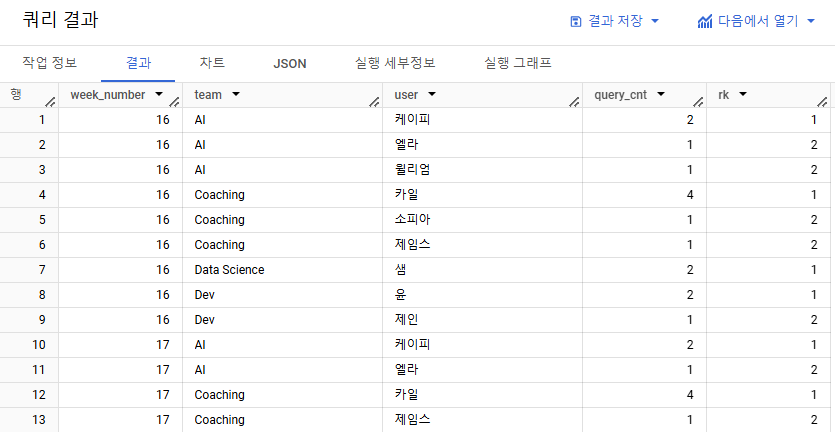
- 주차별로 팀 내에서 쿼리를 많이 실행한 수를 구한 후, 실행한 수를 활용해 랭킹을 구해주세요. 단, 랭킹이 1등인 사람만 결과가 보이도록 해주세요.
- 기대하는 output :
week_number | team | user | query_cnt | team_rank
- 기대하는 output :
-
주차 별 => 주차별 정보를 나타내는 컬럼이 필요해보임 => EXTRACT 함수 사용
-
주차별로 팀 내에서 쿼리를 많이 실행한 수
=> 먼저 각 유저들이 주차별로 쿼리를 실행한 횟수를 구해보면- 쿼리를 실행한 횟수 => COUNT
- 집계 함수를 이용하는 방법 두가지. GROUP BY와 윈도우 함수 => 이번에는 GROUP BY 사용
- 집계되는 컬럼 => 쿼리 실행 정보를 나타내는 컬럼 user 나 query_date 사용
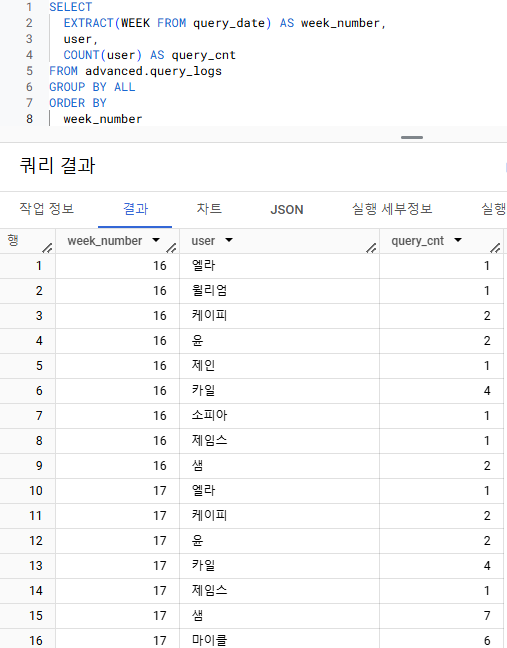
- 쿼리를 실행한 횟수 => COUNT
-
이제 주차별로 팀 내에서 각 유저들이 쿼리를 실행한 횟수를 구해보면
=> GROUP BY 기준에 컬럼 team을 추가하면
=> 1) 주차별 2) 팀 별 3) 유저 별
=> 쿼리 실행 횟수를 나타낼 수 있음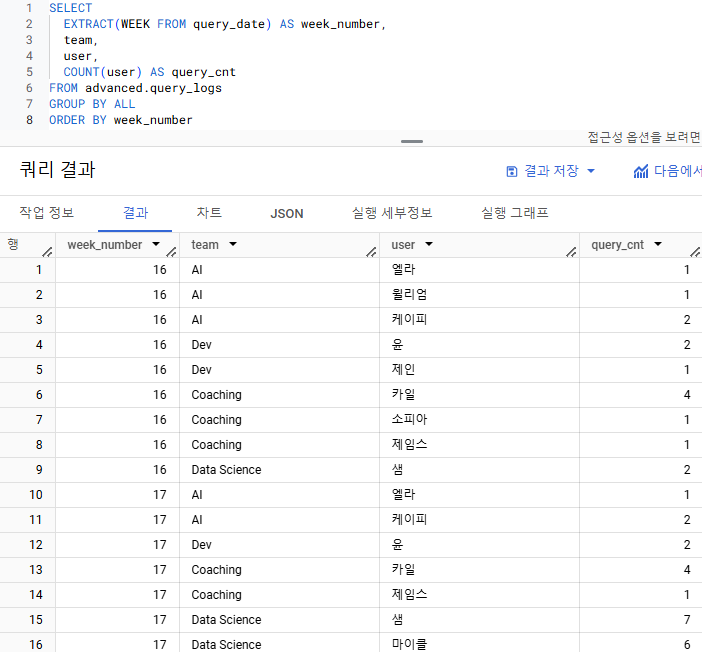
-
주차별로 팀 내에서 쿼리를 실행한 횟수에 대한 랭킹을 구한 후, 랭킹 1등만 나타내기
- 랭킹 => 윈도우 랭킹 함수
- 주차별, 팀 내에서 랭킹 구함 => 파티션 필요해보임
=> 파티션 컬럼으로는 week_number, team 사용 - 랭킹 함수 => 정렬 필요 => 쿼리 실행 횟수에 따라 랭킹을 매기므로
=> 정렬할 컬럼에는 query_cnt 사용
=> 쿼리 실행 횟수가 많을수록 랭킹이 높으므로 DESC 정렬
- 주차별로 팀 내에서 쿼리를 많이 실행한 수를 구한 후, 실행한 수를 활용해 랭킹을 구해주세요. 단, 랭킹이 1등인 사람만 결과가 보이도록 해주세요.
 |  |
|---|
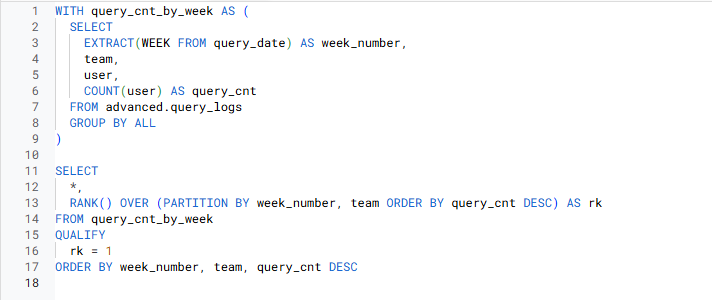
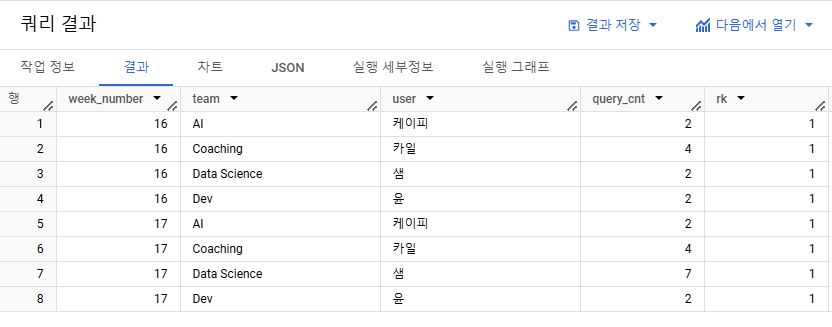
- 랭킹 1등만 나타내기
=> 윈도우 함수를 바로 필터링 할 수 있는 QUALIFY 사용
- 랭킹 1등만 나타내기
 |  |
|---|
-
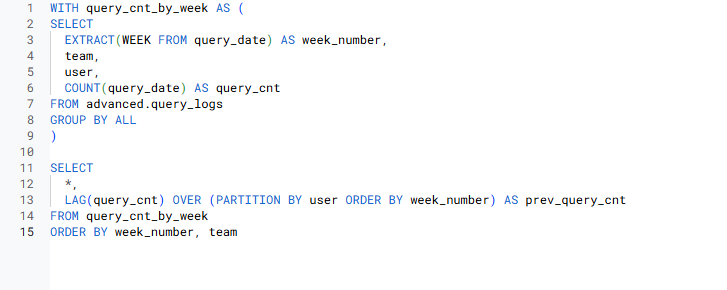
- 쿼리를 실행한 시점 기준 1주 전 쿼리 실행 수를 별도의 컬럼으로 확인할 수 있는 쿼리를 작성해주세요.
-
위에서 with문으로 정의한 query_cnt_by_week 사용
-
쿼리 실행 시점 1주 전 쿼리 실행 수 => LAG 함수 사용
=> LAG함수를 적용할 컬럼은 query_cnt- 각 유저의 1주 전 쿼리 실행 수를 보려 함 => PARTITION BY user
- 쿼리 실행 시점, 즉 현재 row로부터 1주 전 값이 궁금함 => ORDER BY week_number
 |  |
|---|
-
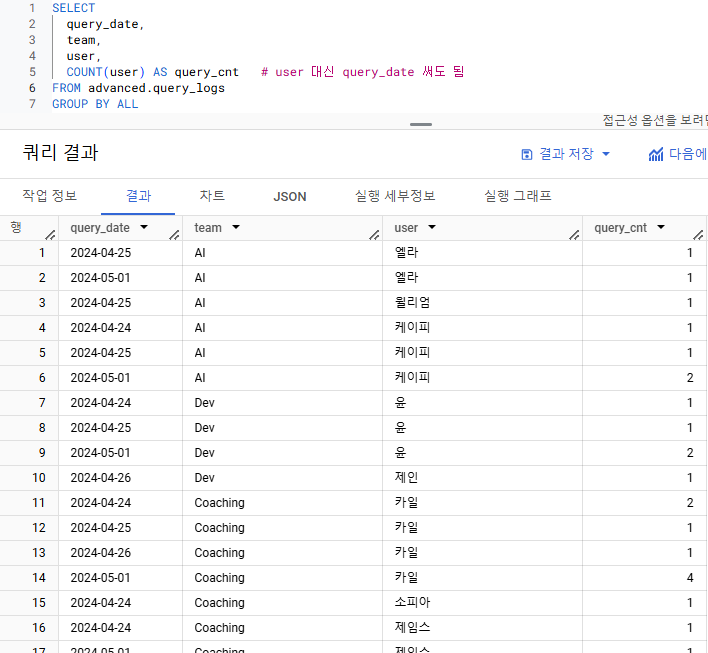
- 시간의 흐름에 따라, 일자 별로 유저가 실행한 누적 쿼리 수를 작성해주세요.
-
누적 쿼리 수 => 윈도우 집계 함수 SUM + 프레임
- 쿼리 실행 수에 대한 누적 합을 구해야 함
=> 쿼리 실행 수를 나타내는 컬럼은 COUNT 함수를 사용해 새로 만들어야 함
-
query_cnt를 구한 쿼리 -> 서브 쿼리로 사용 or WITH문으로 정의
=> 해당 문제처럼 연산할 게 하나정도 있다면, 서브 쿼리로 사용하는 것이 나음 -
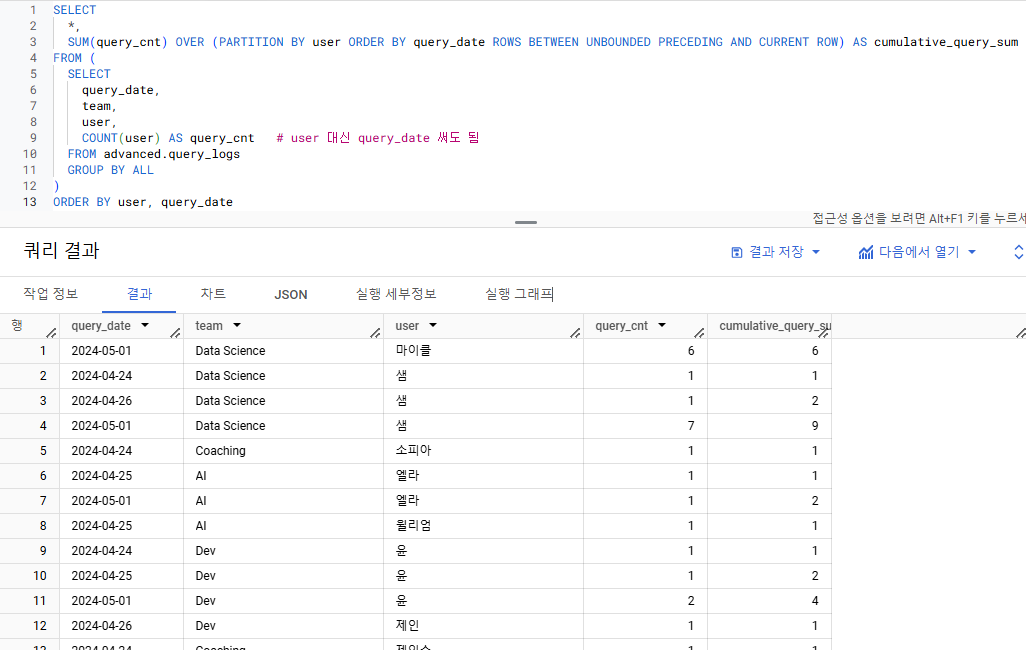
시간의 흐름에 따라 일자 별로 유저가 실행한 누적 쿼리 수
- SUM(query_cnt)
- 각 유저 별 누적 쿼리 수를 알고 싶으므로 => PARTITION BY user
(문제에 표기된 '일자 별'이란 말 때문에 PARTITION 기준이 헷갈린다면, 쿼리를 직접 실행해보면서 결과를 비교해보기) - 일자 순서대로 쿼리 실행 수의 합을 구하려 하므로 => ORDER BY query_date
- 이때 문제가 의도한 누적 쿼리 수 = 파티션 내에서 처음 쿼리를 실행한 수부터 현재 행까지 실행한 쿼리 수의 합
=> UNBOUDED PRECEDING ~ CURRENT ROW
- 이때 문제가 의도한 누적 쿼리 수 = 파티션 내에서 처음 쿼리를 실행한 수부터 현재 행까지 실행한 쿼리 수의 합
-
OVER 절에 프레임을 쓰지 않아도 동일한 결과가 나옴
=> Default Frame : UNBOUNDED PRECEDING AND CURRENT ROW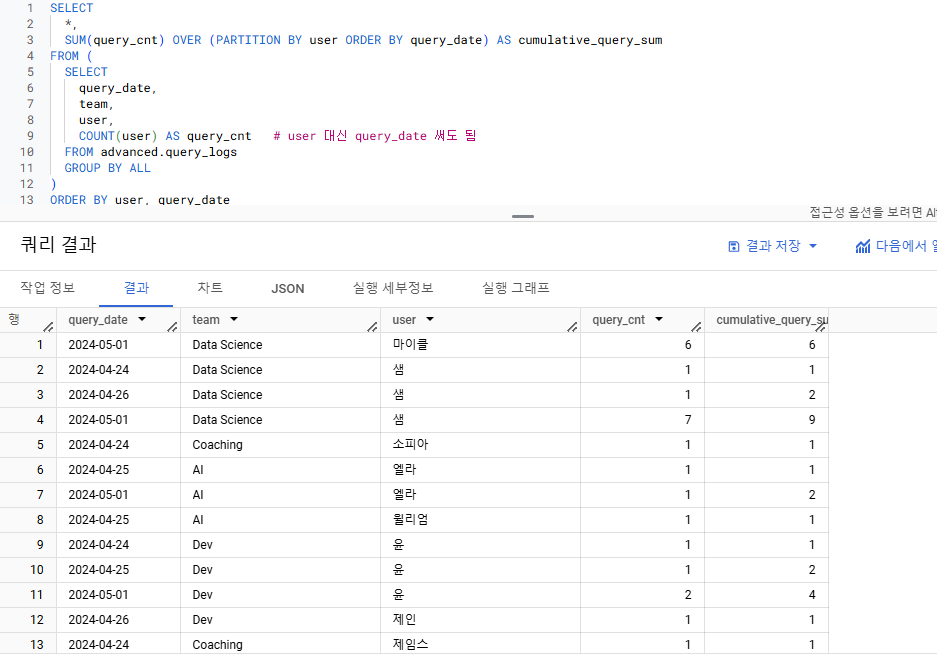
-
누적 쿼리 수를 구할 때 COUNT가 아닌 SUM을 사용하는 이유
- 문제가 의도한 누적 쿼리 수 => 각 유저가 실행한 쿼리 수를 일자 순대로 누적합한 값
- 집계함수로 COUNT를 쓴다면 쿼리 실행 수 query_cnt 자체를 누적 count한 값을 나타냄
데이터 3.
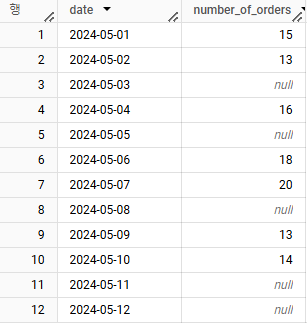
-
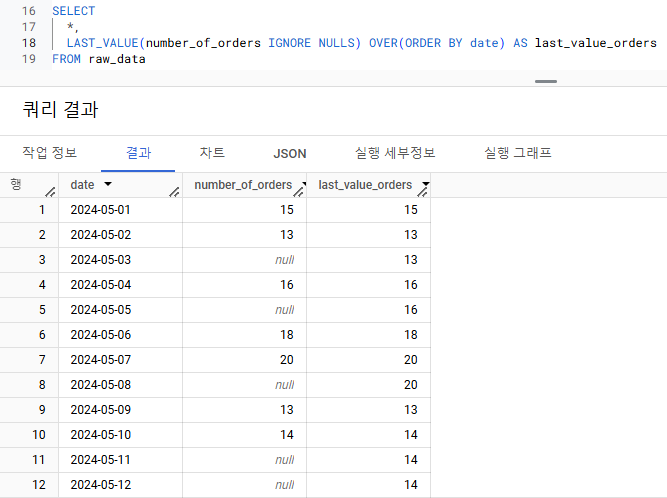
- 다음 데이터는 주문 횟수를 나타낸 데이터입니다. 만약 주문 횟수가 없으면 NULL로 기록합니다. 이런 데이터에서 NULL 값이라고 되어 있는 부분을 바로 이전 날짜의 값으로 채워주는 쿼리를 작성해주세요.
-
NULL값을 이전 값으로 채우기
=> 떠올릴 수 있는 방법 : 1) LAG 2) LAST_VALUE + IGNORE NULLS
1) LAG 함수로 직전 날짜의 값 가져오기
=> NULL값이 연속인 경우에 대해 또 따로 작성해줘야 함
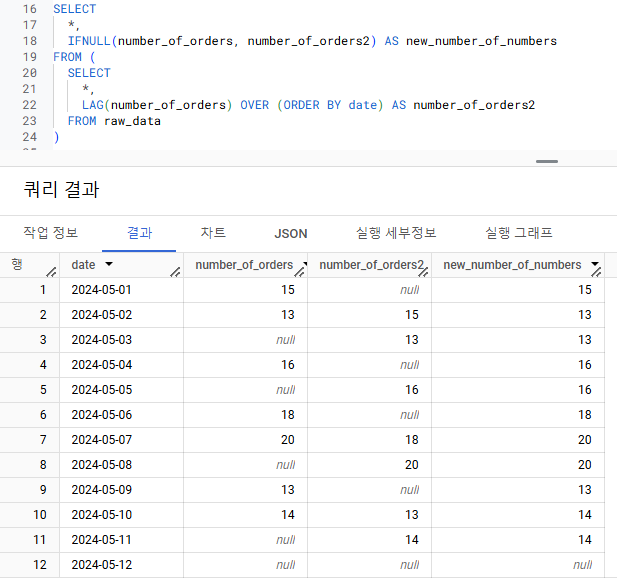
2) LAST_VALUE + IGNORE NULLS
- LAST_VALUE : 마지막 행의 값을 반환
- IGNORE NULLS : LAST_VALUE 함수가 NULL값을 제외하고 연산하게 해줌
- ORDER BY date
=> 일자 순서대로 각 행마다의 마지막 행의 값을 반환해줌
=> 일자 순서대로 정렬했을 때, 각 행에서 현재 행의 값이 마지막 행의 값이 되므로 -> LAST_VALUE = 현재 행의 값을 반환함
=> 현재 행의 값이 null 값이 있는 경우, null값은 제외하고 연산되므로
-> LAST_VALUE = 가장 마지막 행의 값인 직전 날짜의 값을 반환함
-
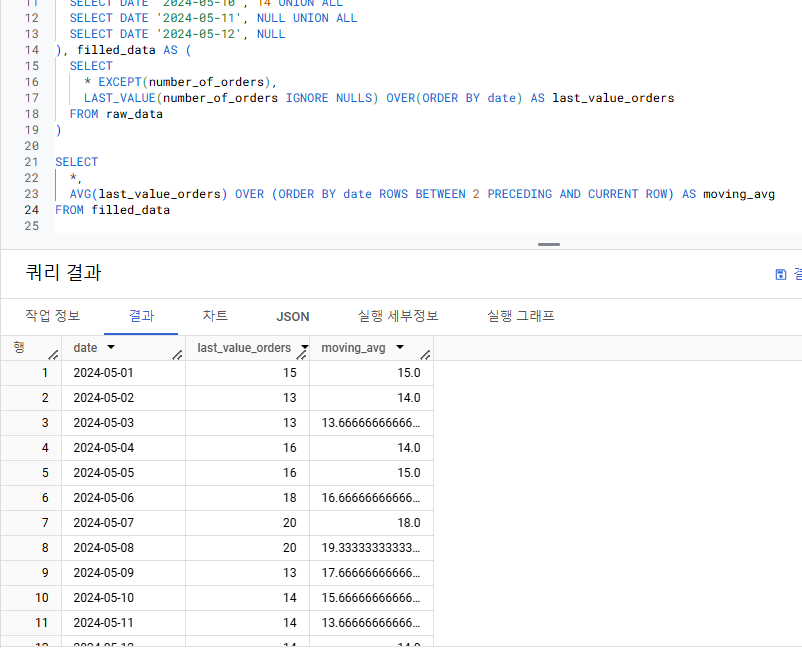
- 주문 횟수 데이터에서 null을 채운 후, 2일 전~현재 데이터의 평균을 구해주세요. (이동 평균)
- 이동 평균 => 윈도우 AVG 함수 + 프레임
- 평균을 집계하는 AVG 함수를 ORDER BY가 필요없지만,
- 프레임(2일 전~현재 데이터)을 구분하기 위해선 ORDER BY date가 필요
- WITH 문을 두 개 이상 작성할 때는 쉼표( , ) 연결
데이터 4.
-
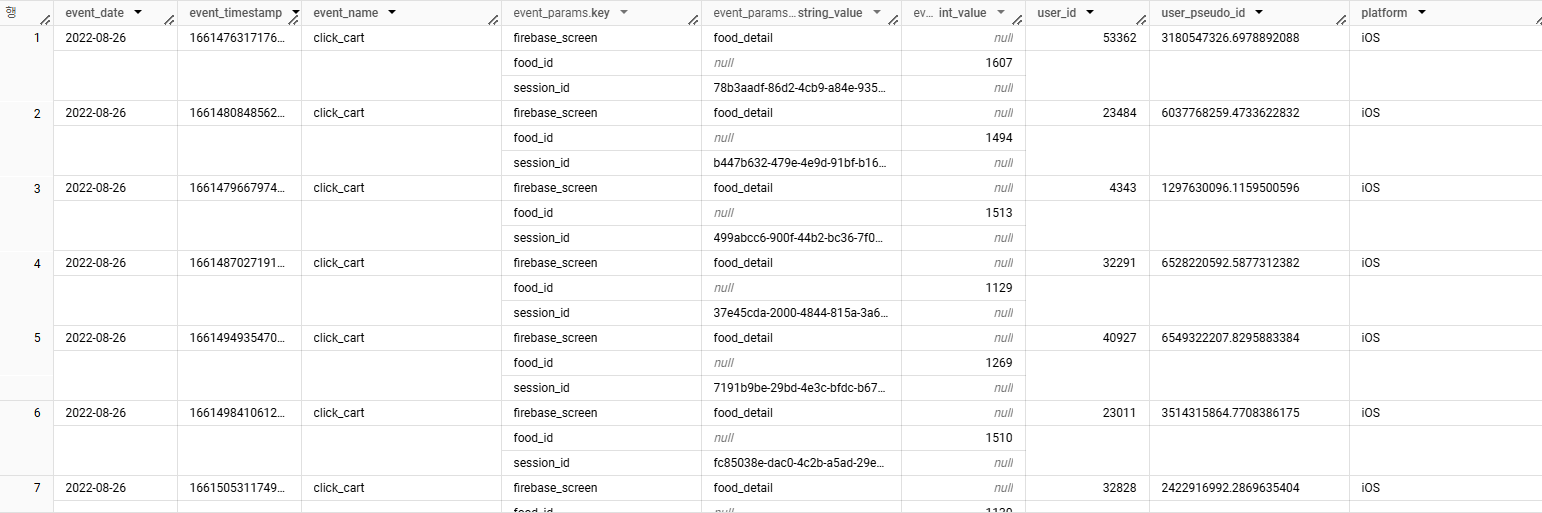
앱 로그 테이블에서 Custom Session을 만들어주세요. 이전 이벤트 로그와 20초가 지나면 새로운 Session을 만들어주세요. Session은 숫자로 표시해도 됩니다.
예를 들어 2022-08-18의 user_pseudo_id(1997494153.8491999091)은 새로운 session_id가 4까지 나옵니다.- 기대하는 output :
event_date | event_timestamp | event_datetime | event_name | user_id | user_pseudo_id | prev_event_datetime | second_diff | session_start | session_id
- 기대하는 output :
-
1) 데이터 탐색
- 필터링을 통해 탐색비용을 아끼기
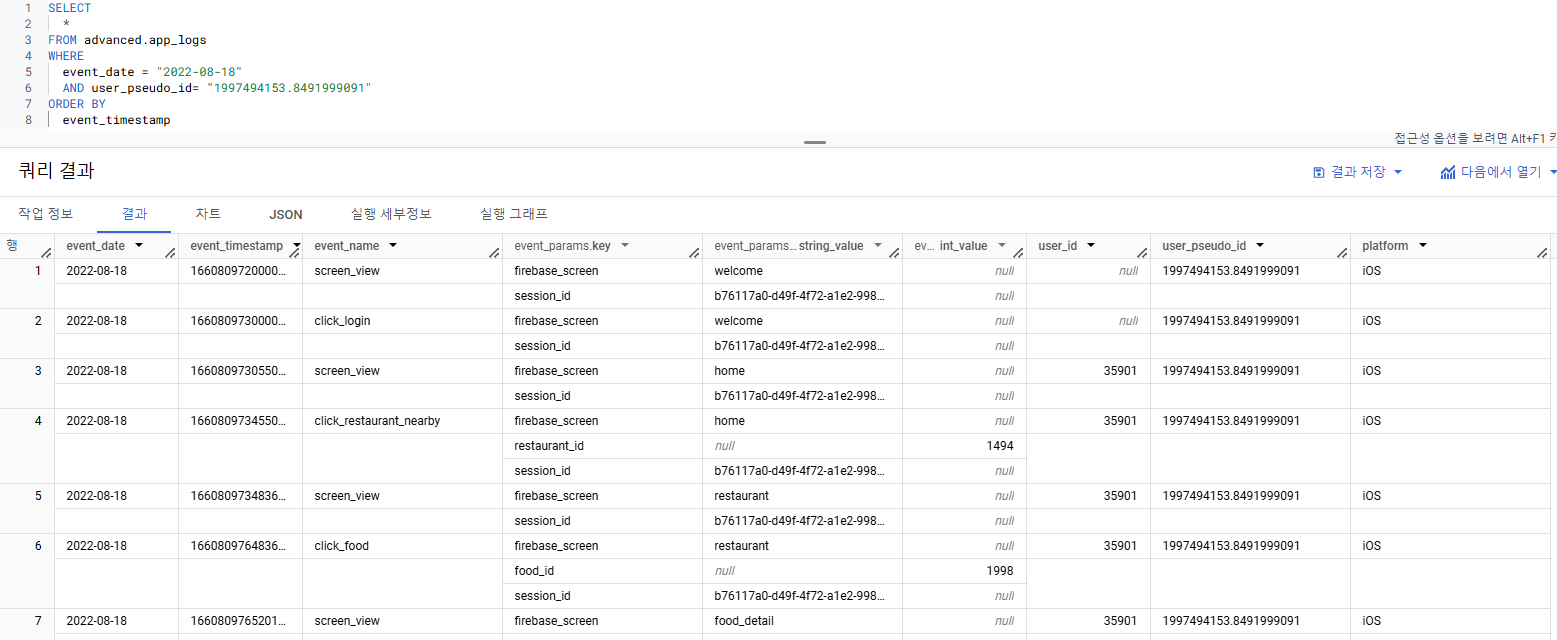
- 해당 문제에서 필요한 컬럼
=> event_date, event_timestamp, event_name, user_id, user_pseudo_id - event_timestamp => micro second 형태 => 보기 쉬운 형태로 변환 필요해보임
- 필터링을 통해 탐색비용을 아끼기
-
2) event_timestamp 변환
- event_timestamp : micro second 형태 => TIMESTAMP_MICRO 사용
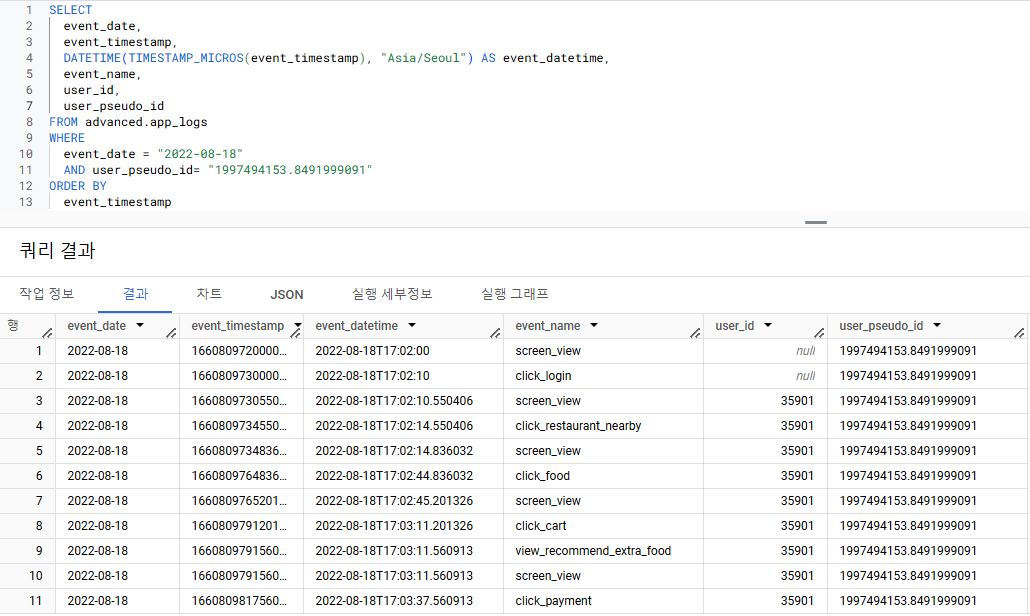
- 잘 변환되었다면 -> WITH 문으로 정의
- event_timestamp : micro second 형태 => TIMESTAMP_MICRO 사용
-
3) 새로운 Session 만들기
- 이전 이벤트 로그와 20초가 지나면 새로운 Session으로 생성 = 현재 이벤트 로그 시점과 직전 이벤트 로그 시점의 차이가 20초 이상이면 새로운 Session으로 생성
=> 먼저 현재 이벤트 로그 시점, 즉 현재 행의 직전 이벤트 로그에 대한 컬럼을 만든 후
=> 현재 이벤트 로그 시점 - 직전 이벤트 로그 시점의 차이를 구해
=> 차이가 20초 이상일 때마다 새로운 Session으로 만들기
- 이전 이벤트 로그와 20초가 지나면 새로운 Session으로 생성 = 현재 이벤트 로그 시점과 직전 이벤트 로그 시점의 차이가 20초 이상이면 새로운 Session으로 생성
-
3-1) 직전 이벤트 로그 시점을 나타내는 컬럼 만들기
- LAG 함수 사용
- 직전 이벤트 로그 시점을 구하고 싶으므로, LAG 함수를 반환할 컬럼으로는 event_datetime 사용
- 각 유저 별 이벤트에 대한 정보가 필요하므로 => PARTITION BY user_pseudo_id
- LAG 함수는 정렬 필요 => event_datetime 기준으로 직전 이벤트 로그에 대한 정보가 필요하므로 => ORDER BY event_datetime
- LAG 함수 사용
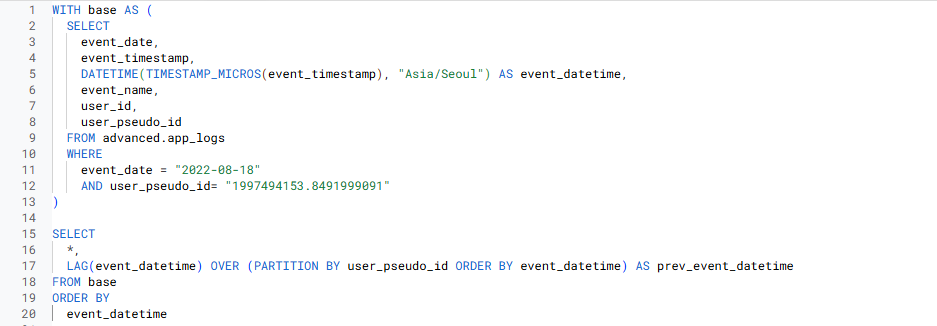
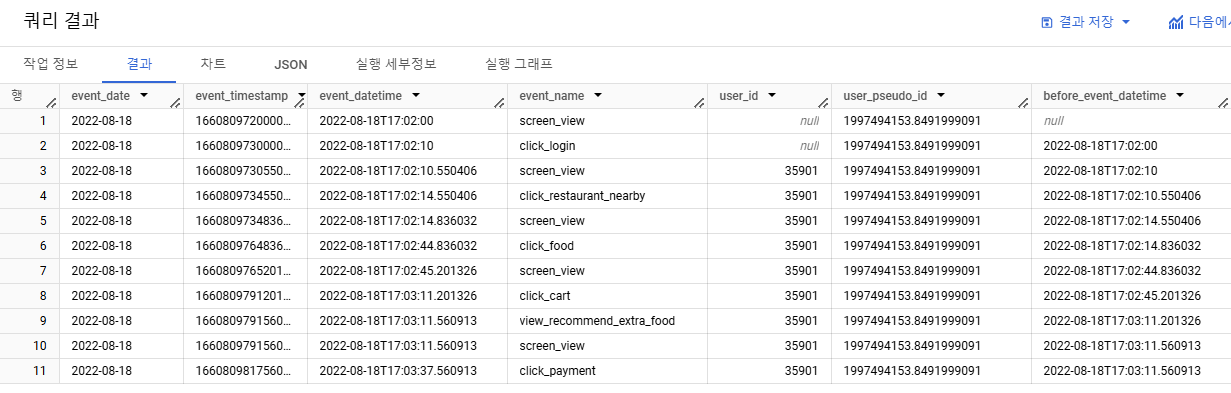
- 3-2) event_datetime - prev_datetime 구하기
- DATE_DIFF 함수 사용
- DATE_DIFF(선행 컬럼, 후행 컬럼, 단위)
- DATE_DIFF 함수 사용
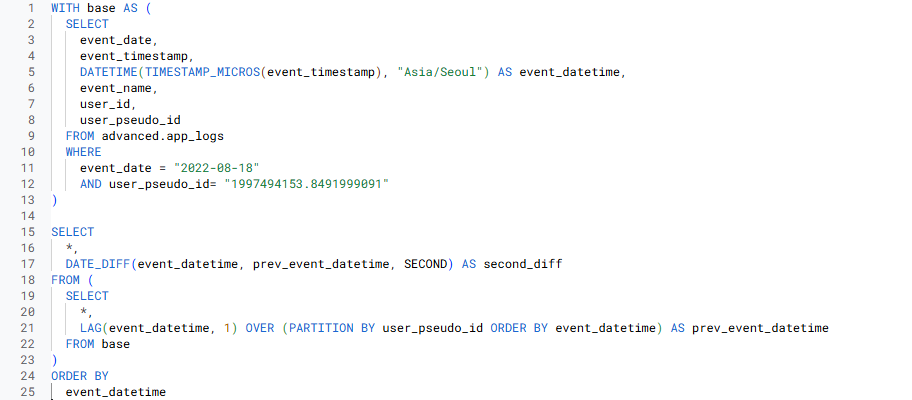
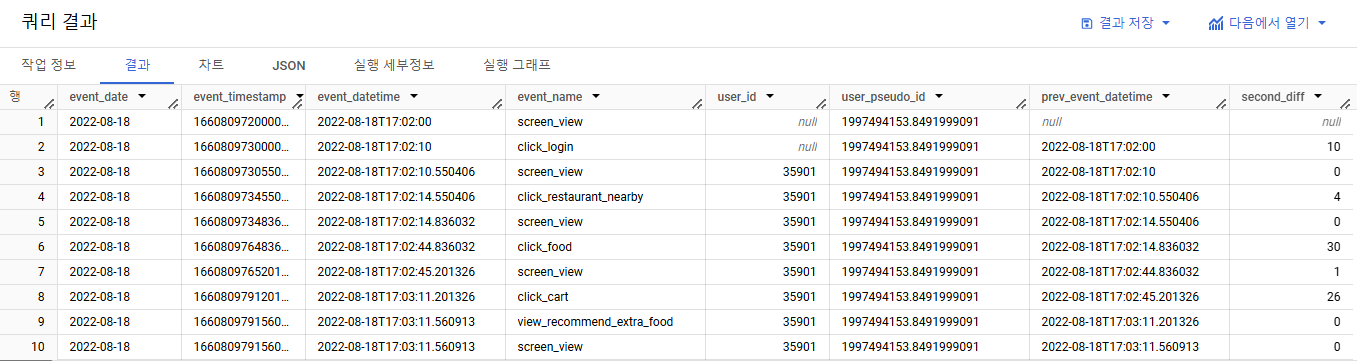
- 3-3) second_diff >= 20을 기준으로 새로운 세션의 시작인지 아닌지를 나타내기
- 조건문 + 새로운 컬럼으로 만들기 => CASE WHEN 사용
- prev_event_datatime이 NULL인 경우도 고려해야 함
( 유저가 로그인 하기 전인 경우 = NULL 값)
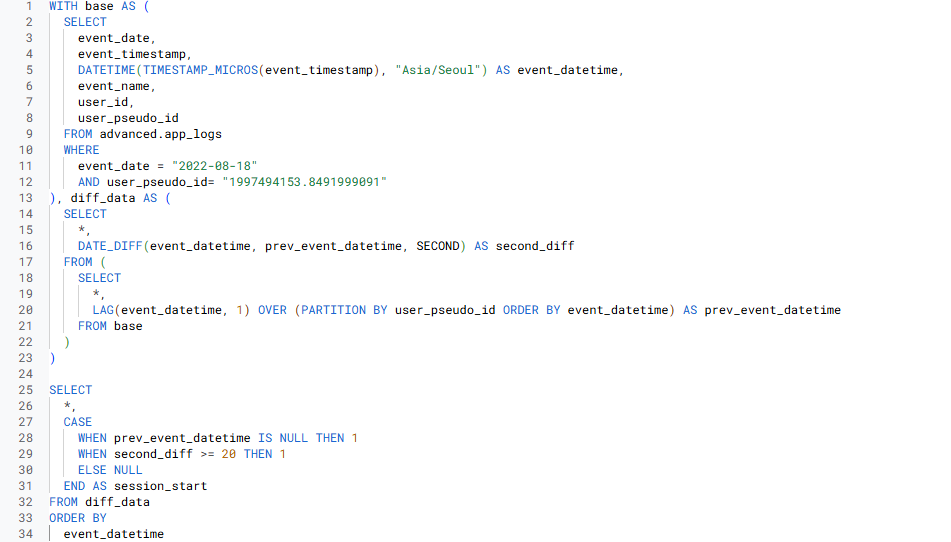
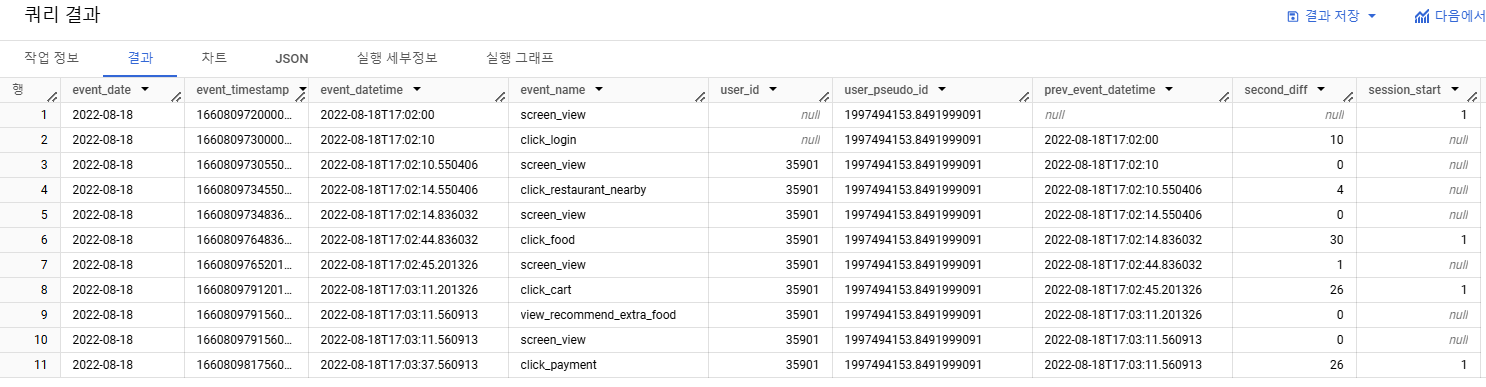
- 3-4) second_diff >= 20 일 때마다 새로운 Session으로 만들기
- session_start의 누적합을 구해 이벤트 로그가 20초 지날 때마다 새로운 session id를 가지도록 만듦
- 누적합 => SUM(session_start)
- 각 유저 별 이벤트 세션을 구하고 싶으므로 => PARTITION BY user_pseudo_id
- 각 이벤트 로그 시점이 지남에 따라 누적합을 구해 새로운 이벤트 세션을 생성하므로 => ORDER BY event_datetime
- session_start의 누적합을 구해 이벤트 로그가 20초 지날 때마다 새로운 session id를 가지도록 만듦
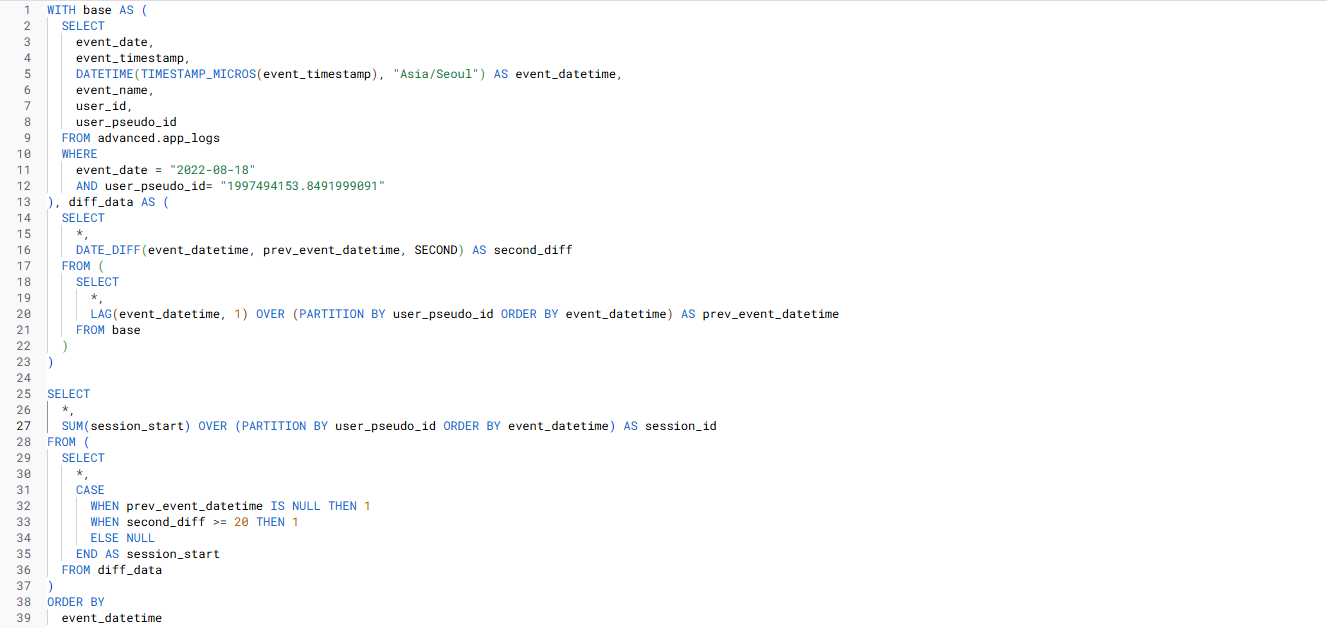
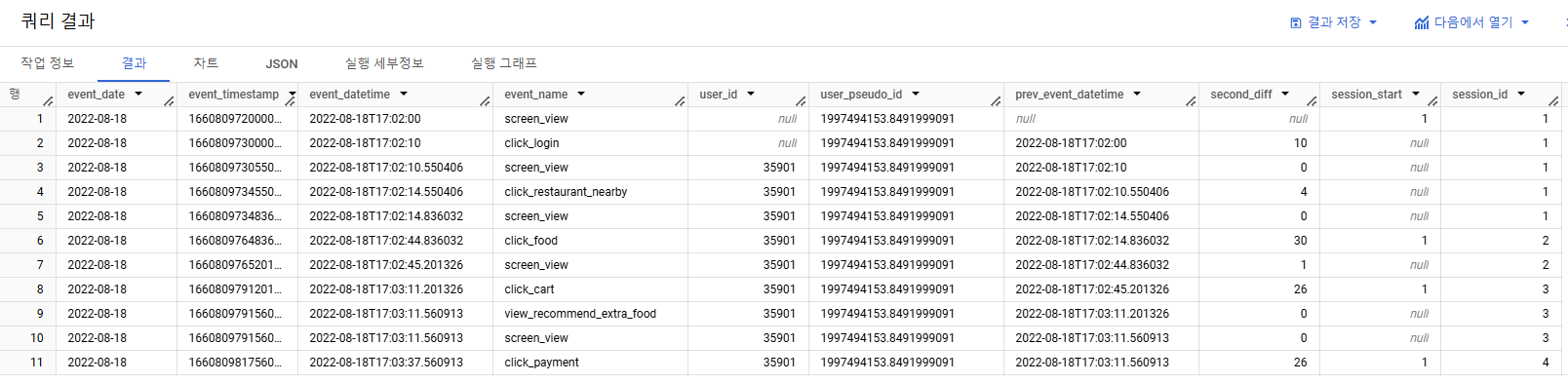
- 4) 쿼리가 알맞은지 검증이 되었다면, 필터링을 풀어 전체 데이터에 적용
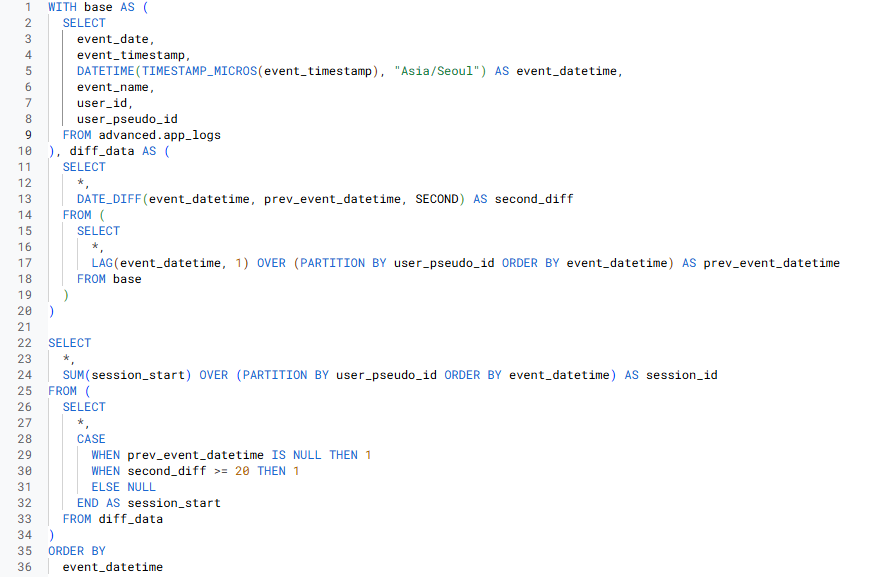
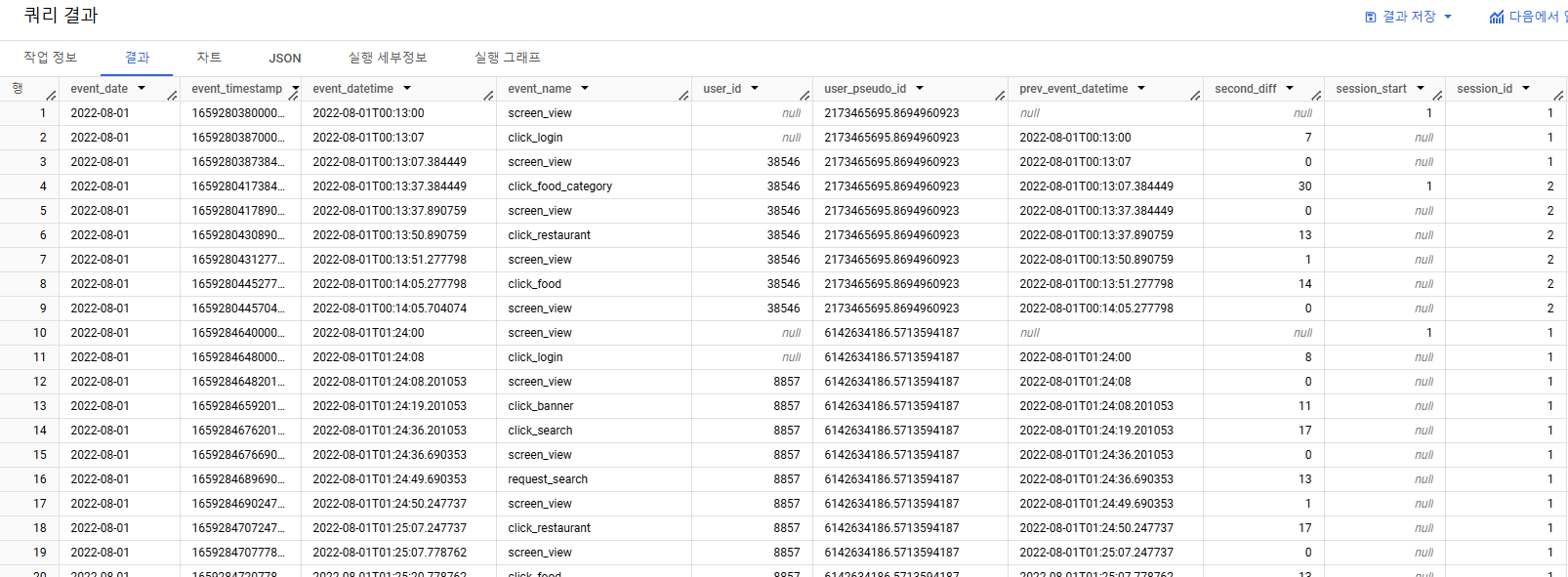
-
해당 문제는 세션 별 집계를 할 때
seesion_id기 없는 경우
=> 유저 로그 기반으로 세션을 직접 생성한 것
=> 유저의 미활동 시간을 '20초 이상'으로 임의 설정 -
세션을 직접 만들면 해당 쿼리처럼, 쿼리가 복잡해지기 때문에
=> 해결하려는 문제의 목적에 따라
=> 유저 별 집계를 할지, 세셜 별 집계를 할지를 정하는 것이 좋음
