Gradient Boosting이란
Gradient
- 기울기(gradient)
경사하강법(Gradient Descent)의 목적은 손실함수(loss function)의 최적화(Optimization)이다.
최적화는 손실 함수를 최소화 하는 파라미터 조합을 구하는 과정을 말한다.
경사하강법이란
함수의 기울기를 이용해 x값을 어디로 옮겼을때 함수가 최소값을 찾는지 알아보는 방법으로, 반복적인 방법(iterative)으로 해를 구하면 효율적이기 때문에 사용한다
손실함수란?
머신러닝에서 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수
대체로 이 값은 0에 가까울수록 모델의 정확도가 높고, 반대로 0에서 멀어질수록 모델의 정확도가 낮다.손실함수의 결과값(오차)를 가장 작게 만드는 것이 신경망 학습의 목표이고 손실 함수의 결과값을 작게 만들기 위해서 가중치 매개변수를 조작해 나가는 과정이 학습, 각각의 가중치 매개변수를 어디로 얼마나 조절해야 손실함수의 결과값이 적어질지를 결정할 때 참고하는 것이 미분값(기울기)이다.
출처: https://umbum.tistory.com/210
- 학습률(learning rate, step size)
경사하강법으로 최적화를 진행할 시 학습률 설정이 매우 중요하다.
학습률이 높으면 발산하는 현상이 나타날 수 있고, 반대로 낮으면 수렴하는 시간이 오래 걸릴 수 있다.
Boosting
배깅 VS 부스팅
부스팅은 배깅에 비해 성능이 좋지만, 속도가 느리고 오버피팅이 될 가능성이 있다.
공부했던 내용 https://dogplot42-6.tistory.com/52
Gradient Boosting
그라디언트 부스팅 프로세스 참고 링크
- 예측 값과 실제값의 차이 구함 -> Residual
- Residual(잔차) 예측하여 활용
- 학습률 조정
GB를 사용한 모델 특징 정리
GBT(Gradient Boosting Tree)
- 랜덤 포레스트와 다르게 무작위성이 없다
- 매개변수를 잘 조정해야하고 훈련 시간이 길다
- 아래 모델들이 GBT의 단점을 보완하고 개선한 비교적 최신 모델들이다.
XGBoost
- Extreme Gradient Boosting 모델은 손실 함수가 최대한 감소하도록 하는 split point(분할점)를 찾는 모델
- 과적합 규제(Regularization)
- 기존 GBT에선 과적합 규제기능이 없으나 XGBoost는 자체적으로 과적합 규제 기능을 가지고 있음
- 분류와 회귀 영역에서 뛰어난 예측 성능 발휘 (광범위한 영역)
- Early stopping(조기 종료) 기능 탑재
- 다양한 파라미터와 Customizing 용이
- GBM 대비 빠른 수행시간(병렬 처리)
- 그러나 최신모델 중 상대적으로 느린편으로, 파라미터 튜닝시 더욱 시간이 오래 걸림
- 학습률(Learning rate)이 높을수록 과적합되기 쉬움
- 다른 앙상블 계열 알고리즘과 같이 해석이 어려움
파라미터 튜닝 (출처)
과적합 방지를 위한 파라미터 조정 방법
- eta 낮추기 (반대로 num_boost_round/n_estimators는 높여주기)
- max_depth 낮추기
- min_child_weight 높이기
- gamma 높이기
- subs_ample, colsample_bytree 낮추기
xgb.XGBClassifier(
# General Parameter
booster='gbtree' # 트리,회귀(gblinear) 트리가 항상
# 더 좋은 성능을 내기 때문에 수정할 필요없다고한다.
silent=True # running message출력안한다.
# 모델이 적합되는 과정을 이해하기위해선 False으로한다.
min_child_weight=10 # 값이 높아지면 under-fitting 되는
# 경우가 있다. CV를 통해 튜닝되어야 한다.
max_depth=8 # 트리의 최대 깊이를 정의함.
# 루트에서 가장 긴 노드의 거리.
# 8이면 중요변수에서 결론까지 변수가 9개거친다.
# Typical Value는 3-10.
gamma =0 # 노드가 split 되기 위한 loss function의 값이
# 감소하는 최소값을 정의한다. gamma 값이 높아질 수록
# 알고리즘은 보수적으로 변하고, loss function의 정의
#에 따라 적정값이 달라지기때문에 반드시 튜닝.
nthread =4 # XGBoost를 실행하기 위한 병렬처리(쓰레드)
#갯수. 'n_jobs' 를 사용해라.
colsample_bytree=0.8 # 트리를 생성할때 훈련 데이터에서
# 변수를 샘플링해주는 비율. 보통0.6~0.9
colsample_bylevel=0.9 # 트리의 레벨별로 훈련 데이터의
#변수를 샘플링해주는 비율. 보통0.6~0.9
n_estimators =(int) #부스트트리의 양
# 트리의 갯수.
objective = 'reg:linear','binary:logistic','multi:softmax',
'multi:softprob' # 4가지 존재.
# 회귀 경우 'reg', binary분류의 경우 'binary',
# 다중분류경우 'multi'- 분류된 class를 return하는 경우 'softmax'
# 각 class에 속할 확률을 return하는 경우 'softprob'
random_state = # random number seed.
# seed 와 동일.
)
[출처] 파이썬 Scikit-Learn형식 XGBoost 파라미터|작성자 현무
LightGBM
-
속도가 빠르고 가볍다. (큰 사이즈의 데이터를 다룰 수 있고 적은 메모리 차지)
-
더 나은 정확도, 결과의 정확도에 초점을 맞춤
-
영향 요인의 중요도 제시(해석적인 측면에서 유용)
-
병렬, 분산 및 GPU 학습 지원
-
리프 중심 분할 트리(Leaf-wise)방식 사용
- 리프 중심 트리 분할(leaf-wise)이란
트리의 균형을 맞추지 않고 최대 손실값(max delta loss)를 가지는 리프 노드를 지속적으로 분할하며 트리 깊이 확장하면서 트리의 깊이가 깊어지고 비대칭적 규칙 트리를 생성한다.
→ 학습을 반복할 수록 균형트리분할방식보다 예측 오류 손실을 최소화할 수 있다.
→ Light GBM은 leaf-wise 방식을 취하고 있기 때문에 수렴이 굉장히 빠르지만, 파라미터 조정에 실패할 경우 과적합을 초래할 수 있다.
출처_https://velog.io/@dbj2000/ML
- 리프 중심 트리 분할(leaf-wise)이란
-
Overfitting (과적합)에 민감하고 작은 데이터에 대해서 과적합되기 쉬움: 적은 데이터셋에는 비추천
-
구현은 쉬우나 파라미터 튜닝이 복잡하다 (100개 이상의 파라미터 커버)
파라미터 튜닝 (출처)
더 빠른 속도를 원할 때 :
- bagging_fraction과 baggin_freq 을 설정하여 bagging 적용하기
- feature_fraction을 설정하여 feature sub-sampling 하기
- 작은 max_bin 값 사용하기
- save_binary 를 값을 통해 다가오는 학습에서 데이터 로딩 속도 줄이기
- parallel learning 병렬 학습을 적용하기
더 나은 정확도를 원할 때:
- 큰 max_bin 값 사용하기 (속도는 느려질 수 있음)
- 작은 learning_rate 값을 큰 num_iterations 값과 함께 사용하기
- 큰 num_leaves 값 사용하기 (과적합 유발할 수도 있음)
- 더 큰 트레이닝 데이터 사용하기
- dart 사용하기
- 범주형 feature 사용하기
과적합을 해결하고 싶을 때 :
- 작은 max_bin 값 사용하기
- 작은 num_leaves 값 사용하기
- min_data_in_leaf 와 min_sum_hessian_in_leaf 파라미터 사용하기
- bagging_fraction 과 bagging_freq 을 사용하여 bagging 적용하기
- feature_fraction을 세팅하여 feature sub-sampling 하기
- lambda_l1, lambda_l2 그리고 min_gain_to_split 파라미터를 이용해 regularization (정규화) 적용하기
- max_depth 를 설정해 Deep Tree 가 만들어지는 것을 방지하기
CatBoost
- 기존 GBM 알고리즘의 한계 극복, 빠른 속도
- 빠른 GPU 훈련
- 모델 및 기능 분석을 위한 시각화 및 도구
- 범주형 기능에 대한 기본 처리 (Target Encoding, One-hot encoding, Categorical Feature Combinations 등)
- 하이퍼 파라미터 튜닝을 지정하지 않아도 모델이 최적화해서 잘 돌아간다
- 수평 트리 (level-wise): 대칭으로 나누어지는 것이 특징
- 정렬된 부스팅 (Ordered Boosting)
Catboost 는 일부 데이터 만 가지고 잔차계산을 한 뒤, 이걸로 모델을 만들고, 그 뒤 데이터의 잔차는 이 모델로 예측한 값을 사용한다.
- 임의 순열(random permutaions) 부스팅 계열 단점인 과적합을 방지
CatBoost는 주어진 전체 데이터를 임의적으로 N개의 Fold로 나눠 각 Fold에 속한 데이터 셋에 Ordered Boosting을 적용한다. (K-fold Cross Validation 과정과 유사)
- 수치형 데이터가 많을때 lightBGM보다 훈련 시간이 길다
- 결측치가 매우 많은 데이터셋에는 부적합하다
CatBoost, LightGBM, XGBoost 비교
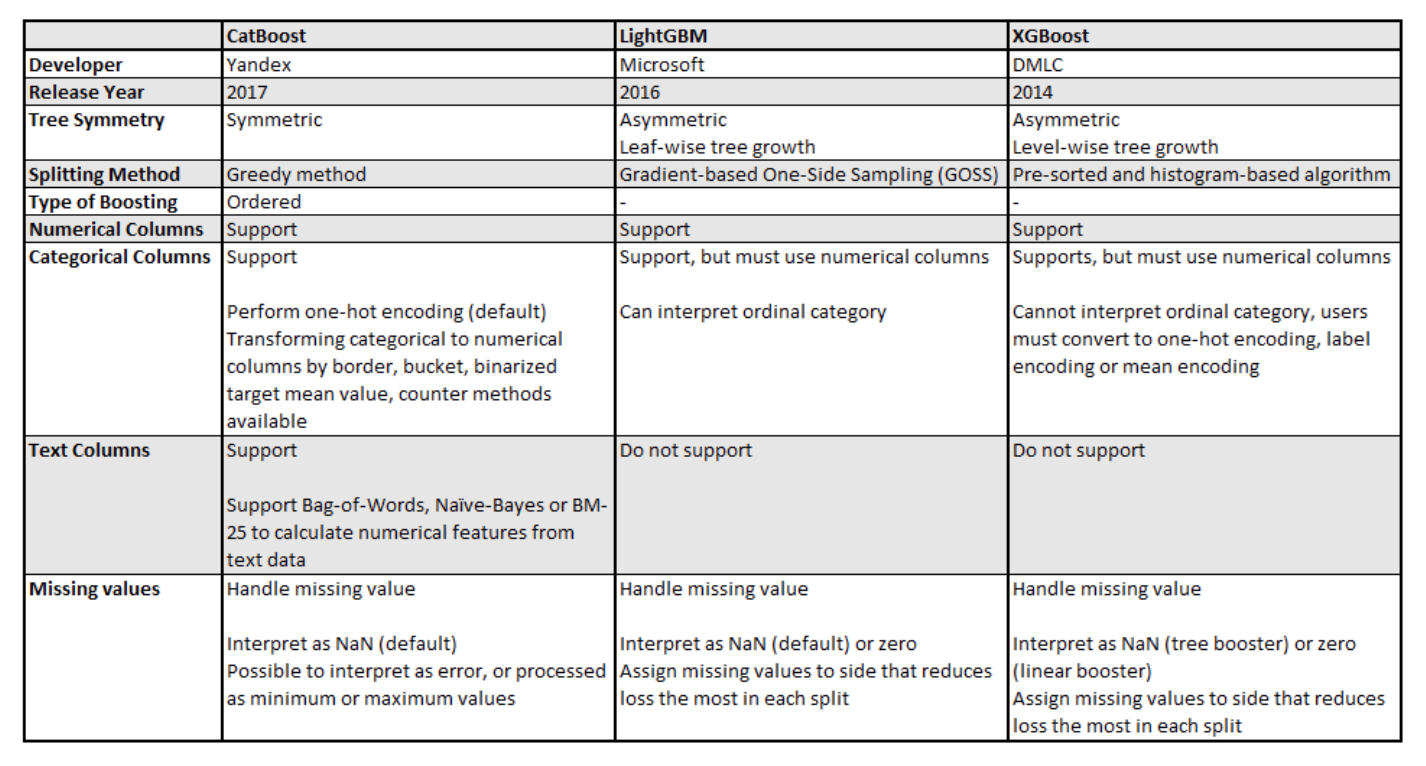 이미지출처
이미지출처
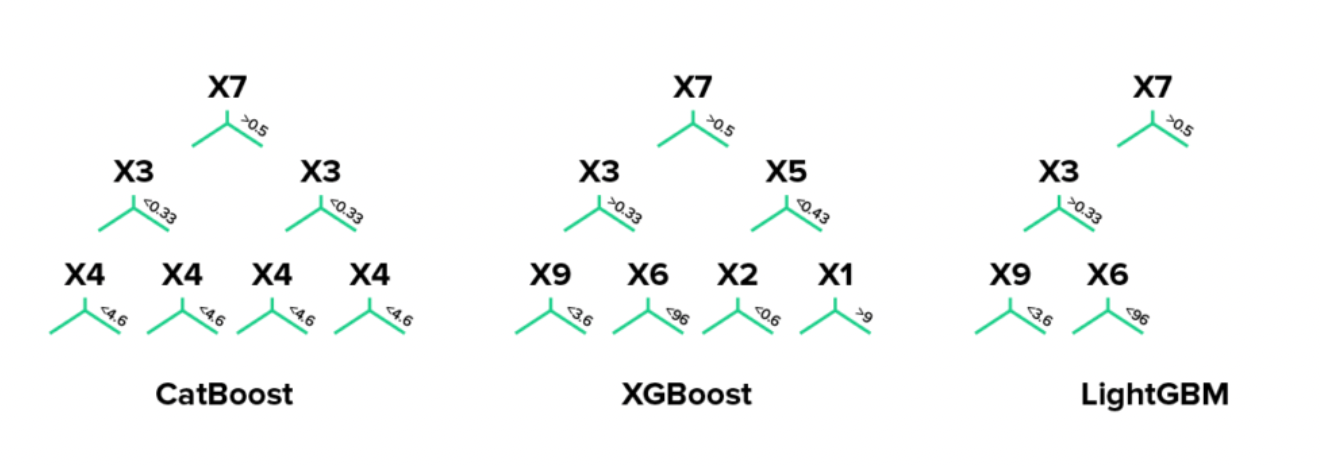
대칭트리vs 너비 우선 vs 깊이 우선 이미지출처
표기된 출처 외 내용 참고 출처