ANSI SQL
DBMS(Oracle, My-SQL, DB2 등등)들에서 각기 다른 SQL를 사용하므로, 미국 표준 협회(American National Standards Institute)에서 이를 표준화하여 표준 SQL문을 정립 시켜 놓은 것이다.
ANSI SQL 특징
표준 SQL문이기 때문에 DBMS의 종류에 제약을 받지 않는다. (MySQL, Oracle..)
즉, 특정 벤더에 종속적이지 않아 다른 벤더의 DBMS로 교체하더라도 빠르게 다른 벤더사를 이동할 수 있다.
특정 DBMS의 이탈이 가속되는 것도 ANSI SQL의 영향이 크다고 할 수 있다.
테이블간의 Join 관계가 FROM 에서 명시되기 때문에 WHERE 문에서 조건만 확인하면 된다.
즉, 가독성이 일반 Query문보다 좋다.
ANSI SQL 비교 예제
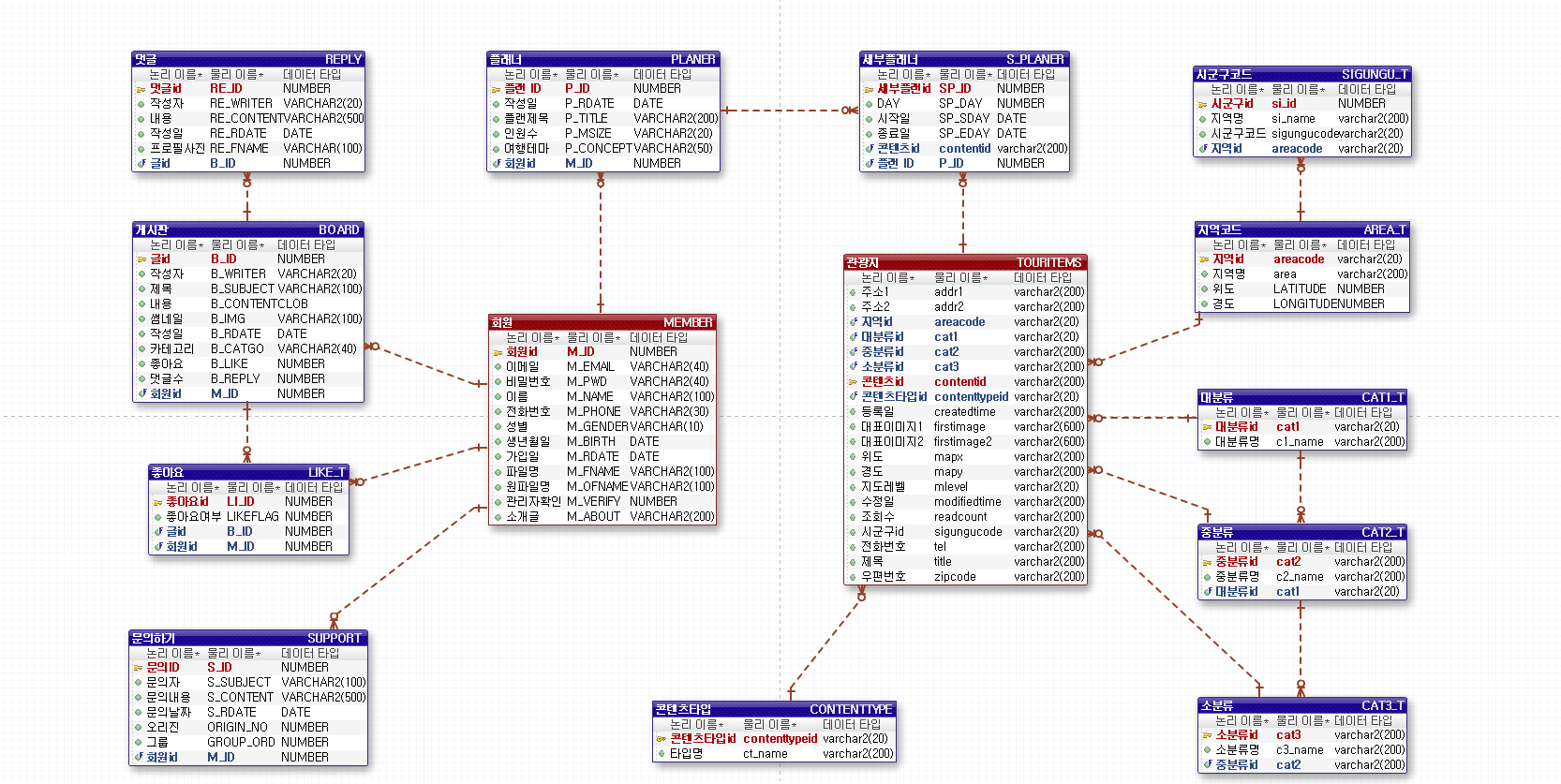
Sample Data
create table TB1
(
num int,
name varchar(10)
)
insert into Test1 values ( 1, '삼성');
insert into Test1 values ( 2, '엘지');
insert into Test1 values ( 3, '애플');
insert into Test1 values ( 4, '레노버');
create table TB2
(
num int,
name varchar(20)
)
insert into Test2 values ( 1, '갤럭시 플립');
insert into Test2 values ( 2, '그램');
insert into Test2 values ( 3, '맥북 프로');LEFT OUTER JOIN
FROM 절에 LEFT OUTER JOIN을 명시해주면 된다.
이때 OUTER를 생략하고 LEFT JOIN을 명시해도 적용 된다.
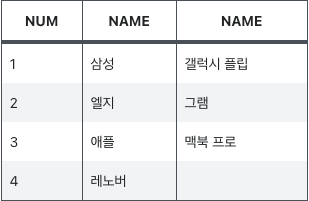
왼쪽 테이블을 기준으로 데이터가 출력되고 조건에 맞는 오른쪽 테이블의 컬럼이 같이 출력된다.
왼쪽 테이블은 전체가 출력되므로, 오른쪽 테이블에 참조할 값이 없으면 NULL이 나온다.
만약 조건에 맞는 오른쪽 컬럼 값이 다수인 경우 오른쪽 컬럼이 여러개 출력된다.
Query 문
Oracle
SELECT TB1.*, TB2.NAME
FROM TB1, TB2
WHERE TB1.NUM = TB2.NUM(+)ANSI SQL
SELECT TB1.*, TB2.NAME
FROM TB1 LEFT OUTER JOIN TB2
ON TB1.NUM = TB2.NUM실행결과
RIGHT OUTER JOIN
FROM 절에 RIGHT OUTER JOIN을 명시해주면 된다.
이때 OUTER를 생략하고 RIGHT JOIN을 명시해도 적용 된다.
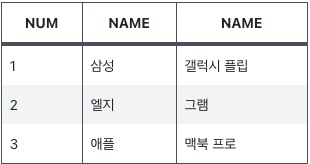
오른쪽 테이블을 기준으로 데이터가 출력되고 조건에 맞는 왼쪽 테이블의 컬럼이 같이 출력된다.
오른쪽 테이블은 전체가 출력되므로, 왼쪽 테이블에 참조할 값이 없으면 NULL이 나온다.
만약 조건에 맞는 왼쪽 컬럼 값이 다수인 경우 왼쪽 컬럼이 여러개 출력된다.
Query 문
Oracle
SELECT TB1.*, TB2.NAME
FROM TB1, TB2
WHERE TB1.NUM(+) = TB2.NUMANSI SQL
SELECT TB1.*, TB2.NAME
FROM TB1 RIGHT͛4 OUTER JOIN TB2
ON TB1.NUM = TB2.NUM실행결과
배운 내용
select * from tm_mnu_mst;
select * from tn_usr_mnu_atrt; -- 메뉴 권한
select * from tb_userinfo;
-- 유저 타입이 C 인 메뉴명, 메뉴 ID
select mm.MNU_ID, mm.MNU_NM
from tn_usr_mnu_atrt ma -- 데이터가 일치하기 때문에 inner join 변경해도 같다.
inner join tm_mnu_mst mm on ma.MNU_ID = mm.MNU_ID and ma.user_type = 'C'; -- on 뒤에 and로 조건을 걸어준다. 이중 조건
-- where ~
-- 유저 타입이 C
-- 모든 쿼리문 작성시 // * from 절 -> join -> where -> 추출 할 컬럼 순으로 작성하기 !
select *
from tn_usr_mnu_atrt ma
left outer join tm_mnu_mst mm on ma.MNU_ID = mm.MNU_ID
where ma.user_type = 'C';
-- dbserver 사용자가 사용할 수 있는 메뉴명
select ll.MNU_ID , ll.MNU_NM
from tb_userinfo ui
left outer join(
select mm.MNU_ID , mm.MNU_NM, ma.user_type
from tn_usr_mnu_atrt ma
inner join tm_mnu_mst mm on ma.MNU_ID = mm.MNU_ID -- mm Alias는 서브쿼리 안에서만 통용된다.
) ll on ll.user_type = ui.user_type
where ui.loginId = 'dbserver';
-- 같은 개선된 쿼리문
select mm.MNU_ID, mm.MNU_NM, ma.user_type
from tn_usr_mnu_atrt ma -- 데이터가 일치하기 때문에 inner join 변경해도 같다.
inner join tm_mnu_mst mm on ma.MNU_ID = mm.MNU_ID
and ma.user_type in (
select user_type
from tb_userinfo
where loginId = 'dbserver'
);-- from 절에 서브쿼리 쓰는게 가장 좋다.
-- <Query 순서>
-- 1. select
-- 2. from
-- 3. where
-- 4. group by -> group by A, B 함수 ( max() min() avg() sum() )
-- 5. order by
-- 6. having -> 그룹함수 결과에 검색 조건을 걸 때
-- * group by 에 있는 부분이 select 하는 데이터 값에 꼭 포함되어있어야 한다. 예) 그룹 지어진 부서별 평균 급여가 2000 이상인 부서의 번호와 부서별 평균 급여를 출력하는 쿼리문
-- SQL> SELECT DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO;
-- SQL> SELECT DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO HAVING AVG(SAL) >= 2000;[Database] 식별관계와 비 식별관계
RDBMS의 테이블을 생성하고, 각 테이블마다 관계를 설정해 줄 때 일반적으로 외래 키를 사용하곤 합니다. 외래 키를 통해 다른 테이블과 같은 키를 공유하고 이를 이용하여 조인하여 관계를 이용하는 방식을 사용합니다. 외래 키를 사용하여 테이블 간 관계를 정립해 줄 때 사용하는 전략은 크게 식별 관계, 비식별 관계 전략이 있습니다.
식별 관계
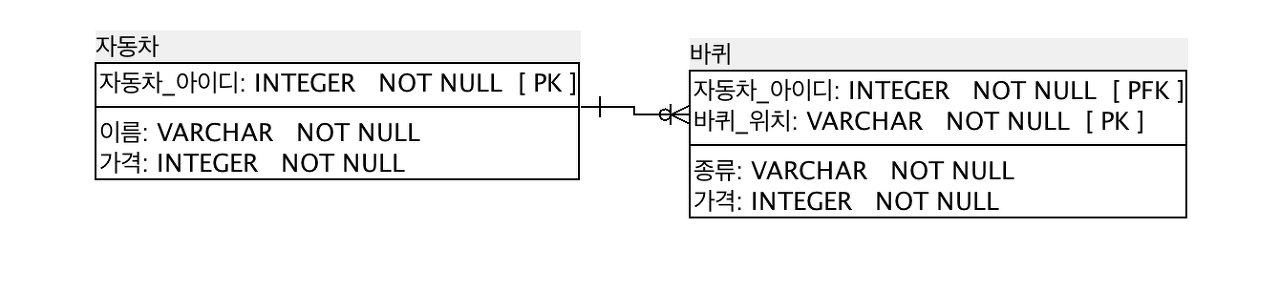
식별 관계란, 부모 테이블의 기본키 또는 유니크 키를 자식 테이블이 자신의 기본키로 사용하는 관계입니다. 부모 테이블의 키가 자신의 기본키에 포함되기 때문에 반드시 부모 테이블에 데이터가 존재해야 자식 테이블에 데이터를 입력할 수 있습니다. 즉, 부모 데이터가 없다면 자식 데이터는 생길 수 없습니다.
식별관계는 ERD상에서 실선으로 표시합니다. 자식 테이블에 데이터가 존재한다면 부모 데이터가 반드시 존재하는 상태가 됩니다. 바퀴는 자동차 테이블에 데이터가 존재해야 생성할 수 있습니다. 즉, 부모 테이블에 자식 테이블이 종속됩니다.
비식별 관계
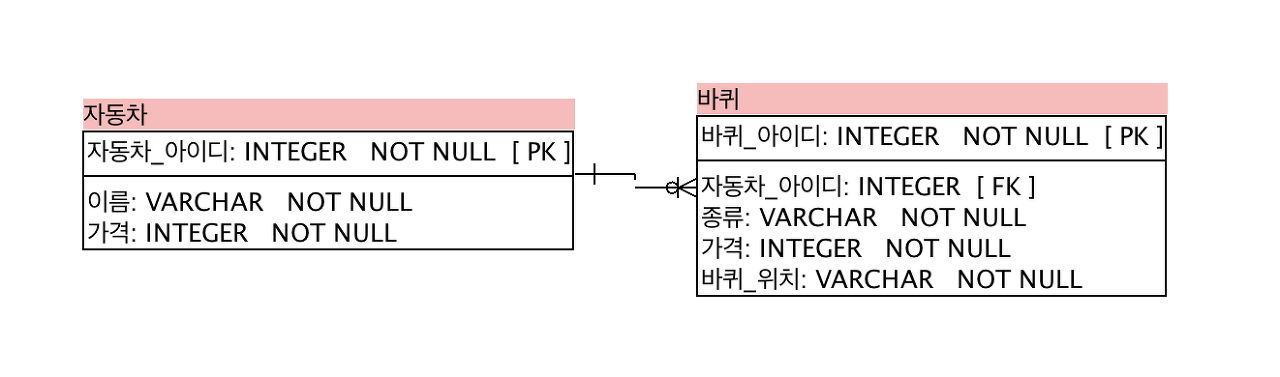
비 식별 관계란 부모 테이블의 기본키 또는 유니크 키를 자신의 기본키로 사용하지 않고, 외래 키로 사용하는 관계입니다. 자식 데이터는 부모 데이터가 없어도 독립적으로 생성될 수 있습니다. 부모와의 의존성을 줄일 수 있기 때문에 조금 더 자유로운 데이터 생성과 수정이 가능합니다.
장단점
식별 관계의 장점
- 데이터의 정합성 유지를 DB에서 한번 더 할 수 있다
- 자식 테이블에 데이터가 존재한다면 부모 데이터도 반드시 존재한다고 보장할 수 있다
식별 관계의 단점
- 요구사항이 변경되었을 경우 구조 변경이 어렵다
비식별 관계의 장점
- 변경되는 요구사항을 유동적으로 수용할 수 있다
- 부모 데이터와 독립적인 자식 데이터를 생성할 수 있다
비식별 관계의 단점
- 데이터 정합성을 지키기 위해서는 별도의 비즈니스 로직이 필요하다.
- 자식 데이터가 존재해도 부모 데이터가 존재하지 않을 수 있다
- 즉, 데이터 무결성을 보장하지 않는다

와우!!!! 이렇게 정리를 잘 할 수가!!!!!